Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Потоки данных — это облачное средство, которое помогает подготавливать и преобразовывать данные без написания кода. Они предоставляют интерфейс low-code для приема данных из сотен источников, преобразования ваших данных с помощью более чем 300 преобразований и загрузки полученных данных в множество мест назначения. Подумайте о них в качестве помощника по персональным данным, который может подключаться к сотням различных источников данных, очищать грязные данные и доставлять их точно там, где вам нужно. Независимо от того, являетесь ли вы гражданином или профессиональным разработчиком, потоки данных позволяют использовать современный интерфейс интеграции данных для приема, подготовки и преобразования данных из богатого набора источников данных, включая базы данных, data warehouse, Lakehouse, данные в режиме реального времени и многое другое.
Поток данных 2-го поколения является более новой, более мощной версией, которая работает вместе с исходным Power BI потоком данных (теперь называется 1-го поколения). Созданная с помощью знакомого опыта Power Query, доступного в нескольких продуктах и службах Microsoft, таких как Excel, Power BI, Power Platform и Dynamics 365, Dataflow Gen2 предоставляет расширенные функции, улучшенную производительность и возможности быстрого копирования для быстрого приема и преобразования данных. Если вы начинаете с нуля, мы рекомендуем Dataflow Gen2 за его расширенные возможности и улучшенную производительность.
Это важно
По состоянию на апрель 2026 года возможность создания новых элементов Dataflow Gen2 без поддержки интеграции CI/CD и Git (ранее известного как Dataflow Gen2 Классика) больше недоступна. Все новые элементы потока данных 2-го поколения теперь создаются с поддержкой интеграции CI/CD и Git по умолчанию. Существующие элементы потока данных 2-го поколения без поддержки CI/CD продолжают работать должным образом. Чтобы преобразовать существующий классический поток данных, используйте функцию "Сохранить как".
Что можно сделать с потоками данных?
С помощью потоков данных можно:
- Подключитесь к данным: извлечение сведений из баз данных, файлов, веб-служб и т. д. Вы также можете повторно подключиться к недавно используемым источникам.
- Преобразуйте ваши данные: очищайте, фильтруйте, объединяйте и изменяйте форму ваших данных с помощью визуального интерфейса.
- Загрузить данные где угодно. Отправка преобразованных данных в базы данных, хранилища данных или облачные хранилища.
- Автоматизируйте процесс: настройте расписания, чтобы данные оставались свежими и up-to-date.
Функции потока данных
Ниже приведены функции, доступные между потоком данных 2-го поколения и 1-го поколения:
| Функция | Поток данных 2-го поколения | Поток данных 1-го поколения |
|---|---|---|
| Создание потоков данных с помощью Power Query | ✓ | ✓ |
| Более простой процесс создания | ✓ | |
| Автосохранение и фоновая публикация | ✓ | |
| Несколько назначений выходных данных | ✓ | |
| Улучшение мониторинга и отслеживания обновлений | ✓ | |
| Работает с конвейерами | ✓ | |
| Высокопроизводительные вычисления | ✓ | |
| Подключение через соединитель потока данных | ✓ | ✓ |
| Прямой запрос через соединитель потока данных | ✓ | |
| Обновляйте только измененные данные | ✓ | ✓ |
| Инсайты на основе ИИ | ✓ | ✓ |
| Последние сочетания клавиш с данными для ранее используемых источников | ✓ |
Обновления для Dataflow Gen2
В следующих разделах приведены некоторые основные улучшения потока данных 2-го поколения по сравнению с 1-го поколения, чтобы упростить и повысить эффективность задач подготовки данных.
Создание и использование 2-го поколения проще
Поток данных второго поколения покажется вам знакомым, если вы раньше использовали Power Query. Мы упростили процесс, чтобы ускорить работу и повысить производительность. Вы будете получать пошаговые инструкции при вводе данных в ваш поток данных, и мы уменьшили количество шагов, необходимых для создания ваших потоков данных.

Автосохранение сохраняет вашу работу в безопасности
Dataflow Gen2 автоматически сохраняет ваши изменения, пока вы работаете. Вы можете отойти от компьютера, закрыть браузер или потерять подключение к Интернету, не беспокоясь о потере хода выполнения. Когда вы вернетесь, все будет на своих местах.
После завершения создания потока данных вы можете опубликовать изменения. Публикация сохраняет вашу работу и запускает фоновые подтверждения, так что вам не нужно ждать, перед тем как переходить к следующему заданию.
Чтобы узнать больше о том, как работает сохранение, ознакомьтесь с документом "Сохранить черновик потока данных".
Отправляйте данные туда, где они необходимы
Хотя поток данных 1-го поколения хранит преобразованные данные в собственном внутреннем хранилище (к которому можно получить доступ через коннектор Dataflow), Dataflow 2-го поколения позволяет использовать это хранилище или отправлять данные в различные целевые места.
Эта гибкость открывает новые возможности. Например, доступны следующие возможности:
- Используйте поток данных для загрузки данных в lakehouse, а затем проанализируйте их с помощью записной книжки.
- Загрузка данных в базу данных Azure SQL, а затем используйте конвейер для перемещения данных в хранилище данных.
В настоящее время поток данных 2-го поколения поддерживает следующие назначения:
- базы данных Azure SQL
- Azure Data Explorer (Kusto)
- Azure Datalake 2-го поколения
- таблицы Fabric Lakehouse
- Файлы Fabric Lakehouse
- Склад Fabric
- база данных Fabric KQL
- база данных SQL Fabric
- файлы SharePoint
- База данных Snowflake
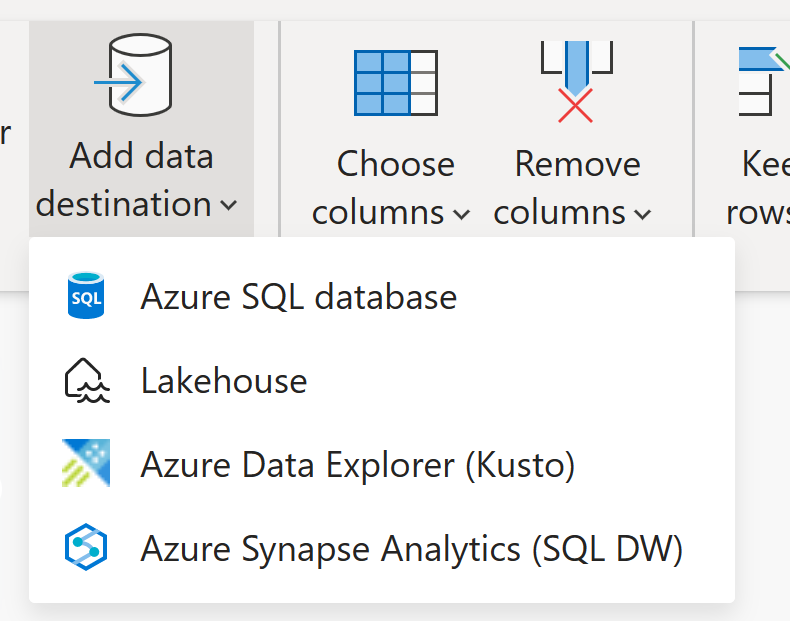
Дополнительные сведения о доступных назначениях данных см. в разделе назначений данных Dataflow Gen2 и управляемых параметров.
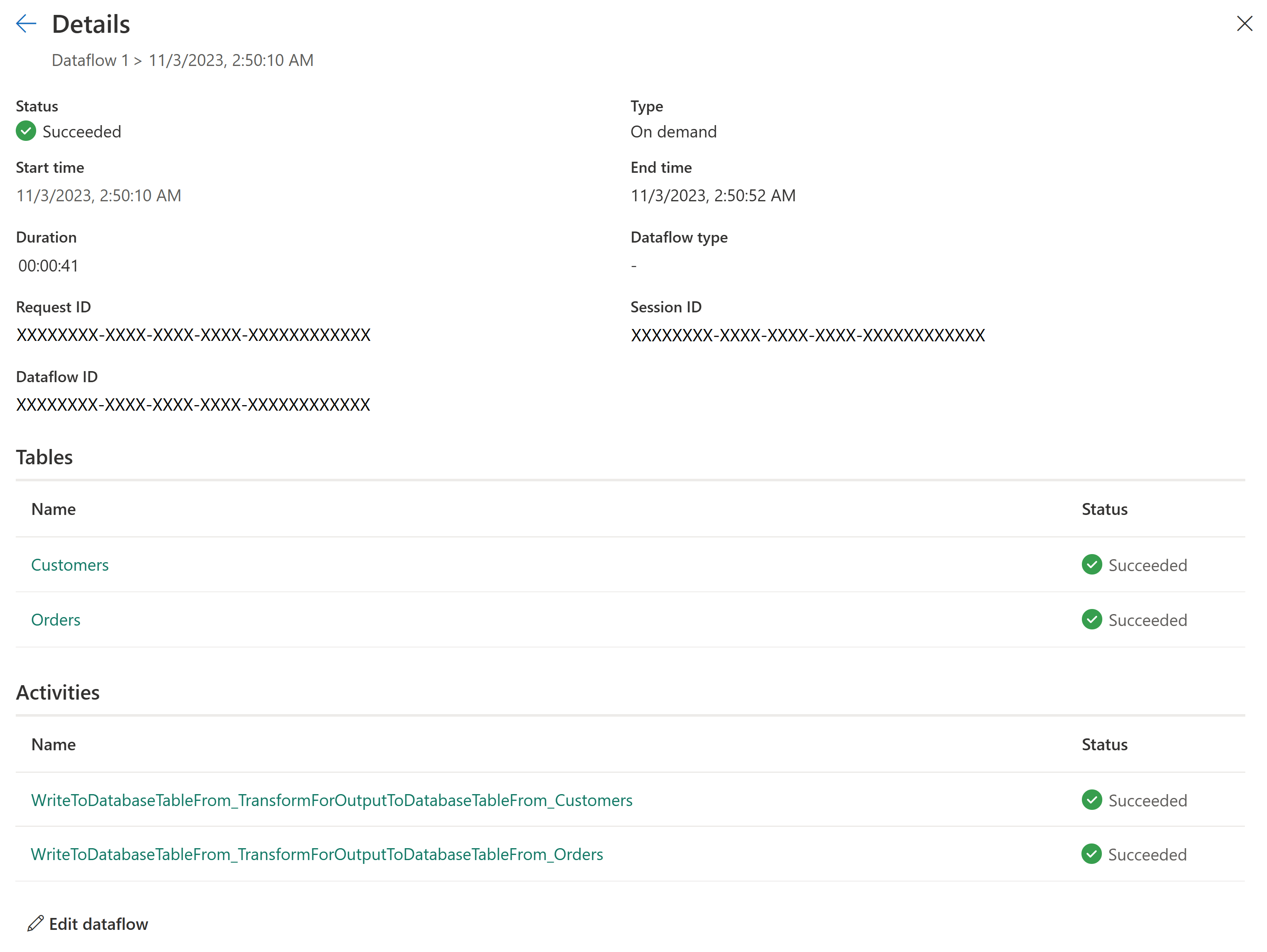
Улучшение мониторинга и отслеживания обновлений
Поток данных 2-го поколения дает более четкое представление о том, что происходит с обновлением данных. Мы интегрированы с Центром мониторинга и улучшили возможности журнала обновления , чтобы отслеживать состояние и производительность потоков данных.
Работает бесшовно с конвейерами
Pipelines позволяет группировать действия вместе для выполнения более крупных задач. Думайте о них как о рабочих процессах, которые могут копировать данные, выполнять SQL-запросы, выполнять хранимые процедуры или запускать ноутбуки Python.
Вы можете подключить несколько действий в конвейере и задать его для выполнения по расписанию. Например, каждый понедельник можно использовать конвейер для извлечения данных из Azure Blob и их очистки, а затем активировать Dataflow Gen2 для анализа данных журнала. Или в конце месяца вы можете скопировать данные из хранилища BLOB Azure в базу данных Azure SQL, а затем запустить хранимую процедуру в этой базе данных.
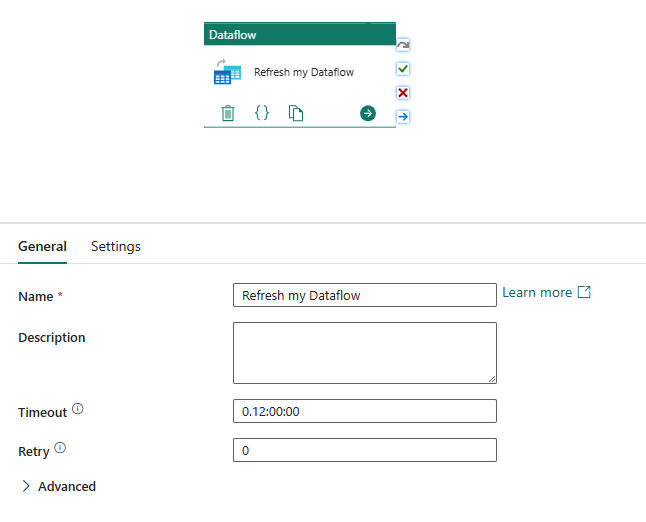
Дополнительные сведения о подключении потоков данных с помощью pipelines см. в статье dataflow activities.
Высокопроизводительные вычисления
Dataflow Gen2 использует передовые вычислительные механизмы SQL на архитектуре Fabric для эффективной обработки больших объемов данных. Чтобы это работало, Dataflow Gen2 создает элементы Lakehouse и хранилища в вашей рабочей области и использует их для хранения и доступа к данным, улучшая производительность всех потоков данных.
Поиск и повторное использование последних источников данных
Поток данных 2-го поколения включает в себя модуль последних данных , который записывает элементы, которые вы ранее использовали ( например, таблицы, файлы, папки, базы данных и листы) и позволяет загружать их непосредственно в холст редактирования потока данных 2-го поколения. Вы можете получить доступ к последним данным на ленте Power Query или из современного интерфейса получения данных, чтобы быстро вернуться к нужным данным без перенастройки подключений.
В любой записи с последними данными можно также выбрать "Обзор расположения ", чтобы изучить и выбрать дополнительные связанные элементы в одной папке или базе данных, что упрощает работу с несколькими ресурсами в одном расположении.
Copilot для потока данных 2-го поколения
Dataflow Gen2 интегрируется с Microsoft Copilot в Fabric, чтобы предоставить AI-поддержку при создании решений для интеграции данных с использованием подсказок на естественном языке. Copilot помогает упростить процесс разработки потока данных, позволяя использовать язык общения для выполнения преобразований и операций с данными.
- Получение данных из источников: используйте начальный запрос "Получить данные из" для подключения к различным источникам данных, таким как OData, базы данных и файлы
-
Преобразование данных с помощью естественного языка: применение преобразований с помощью диалоговых запросов, таких как:
- "Сохранить только европейских клиентов"
- "Подсчет общего числа сотрудников по городу"
- "Храните только заказы, количество которых выше медианного значения"
- Create sample data: используйте Azure OpenAI для создания примеров данных для тестирования и разработки
- Отмена операций: введите или выберите "Отменить", чтобы удалить последний примененный шаг.
- Проверить и просмотреть: каждое действие Copilot отображается в качестве карточки ответа с соответствующими шагами в списке примененных шагов.
Дополнительные сведения см. в разделе Copilot для потока данных 2-го поколения.
Что необходимо для использования потоков данных?
Для Dataflow Gen2 требуется емкость Fabric, триальная емкость Fabric или ресурсная емкость Power BI Premium. Чтобы понять, как работает лицензирование для потоков данных, ознакомьтесь с понятиями и лицензиями Microsoft Fabric.
Переход из потока данных 1-го поколения в 2-го поколения
Если у вас уже есть потоки данных, созданные с помощью 1-го поколения, не волнуйтесь, вы можете легко перенести их в 2-го поколения. У нас есть несколько вариантов, которые помогут вам переключиться:
Экспорт и импорт запросов
Вы можете экспортировать запросы потока данных 1-го поколения и сохранить их в PQT-файле, а затем импортировать их в поток данных 2-го поколения. Пошаговые инструкции см. в разделе "Использование функции шаблона экспорта".
Копирование и вставка в Power Query
Если у вас есть поток данных в Power BI или Power Apps, можно скопировать запросы и вставить их в редактор dataflow 2-го поколения. Этот подход позволяет выполнять миграцию без необходимости перестроить запросы с нуля. Дополнительные сведения: копирование и вставка существующих запросов Dataflow Gen1.
Использование функции "Сохранить как"
Если у вас уже есть любой тип потока данных (1-го или 2-го поколения), фабрика данных включает функцию "Сохранить как". Это позволяет сохранить существующий поток данных в виде нового элемента потока данных 2-го поколения с поддержкой интеграции CI/CD и Git только в одном действии. Дополнительные сведения: Переход на Dataflow Gen2 с помощью команды "Сохранить как".
Организация элементов в рабочей области
В некоторых интерфейсах в рабочей области могут отображаться системные элементы, такие как DataflowsStagingLakehouse или DataflowsStagingWarehouse . Это внутренние промежуточные элементы, используемые потоком данных 2-го поколения и не предназначены для прямого взаимодействия. Вы можете безопасно игнорировать их.
Связанный контент
Хотите узнать больше? Ознакомьтесь с этими полезными ресурсами:
- Мониторинг потоков данных — отслеживание журнала обновления и производительности
- Сохранение черновиков при работе — сведения о функции автосохранение
- Миграция из 1-го поколения в 2-го поколения — пошаговое руководство по миграции