Использование потока данных в конвейере
В этом руководстве вы создадите конвейер данных для перемещения OData из источника Northwind в место назначения Lakehouse и отправки уведомления по электронной почте при завершении конвейера.
Необходимые компоненты
Чтобы приступить к работе, необходимо выполнить следующие предварительные требования:
- Убедитесь, что у вас есть рабочая область с поддержкой Microsoft Fabric, которая не является стандартной моей рабочей областью.
Создание Lakehouse
Чтобы начать, сначала необходимо создать лейкхаус. Lakehouse — это озеро данных, оптимизированное для аналитики. В этом руководстве вы создадите lakehouse, который используется в качестве назначения для потока данных.
Перейдите к интерфейсу Инжиниринг данных.

Перейдите в рабочую область с поддержкой Fabric.
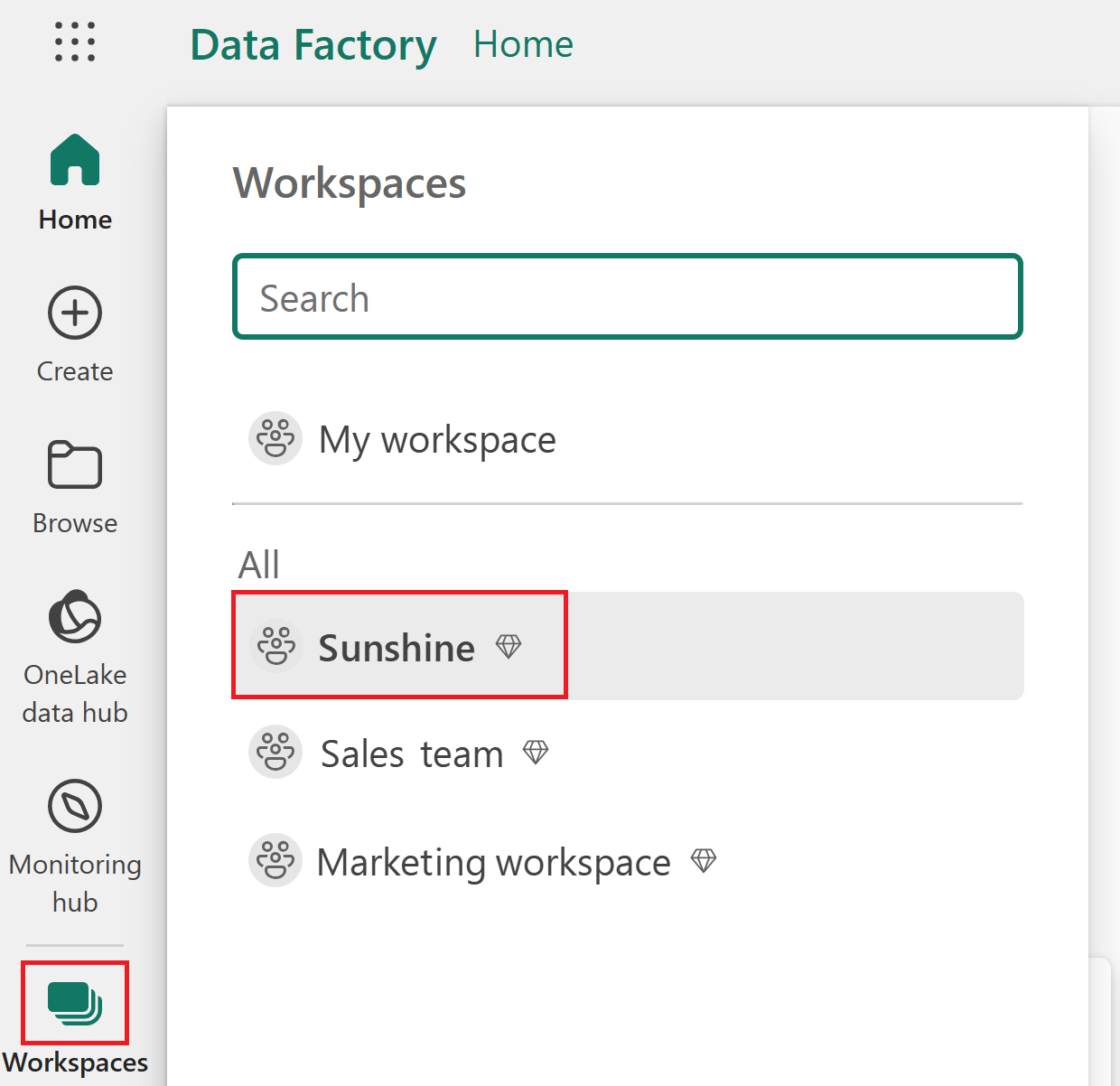
Выберите Lakehouse в меню создания.
Введите имя озера.
Нажмите кнопку создания.
Теперь вы создали lakehouse и теперь можете настроить поток данных.
Создание потока данных
Поток данных — это повторно используемое преобразование данных, которое можно использовать в конвейере. В этом руководстве вы создадите поток данных, который получает данные из источника OData и записывает данные в место назначения Lakehouse.
Переключитесь на интерфейс Фабрики данных.
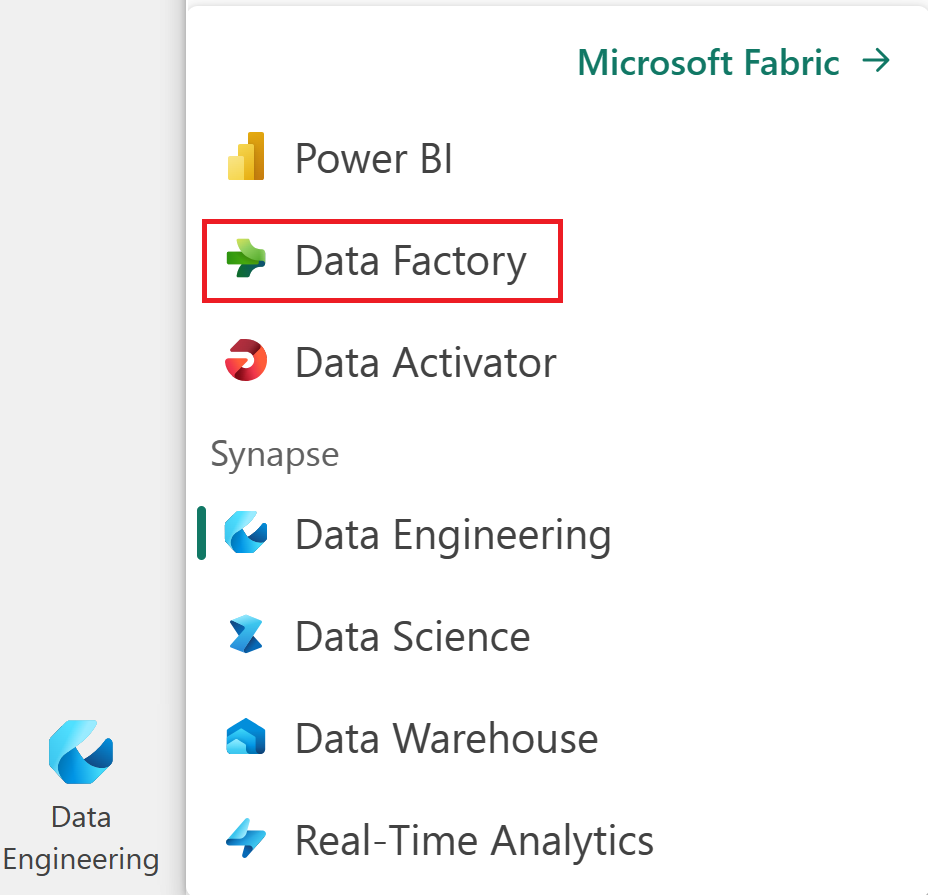
Перейдите в рабочую область с поддержкой Fabric.
Выберите поток данных 2-го поколения в меню создания.
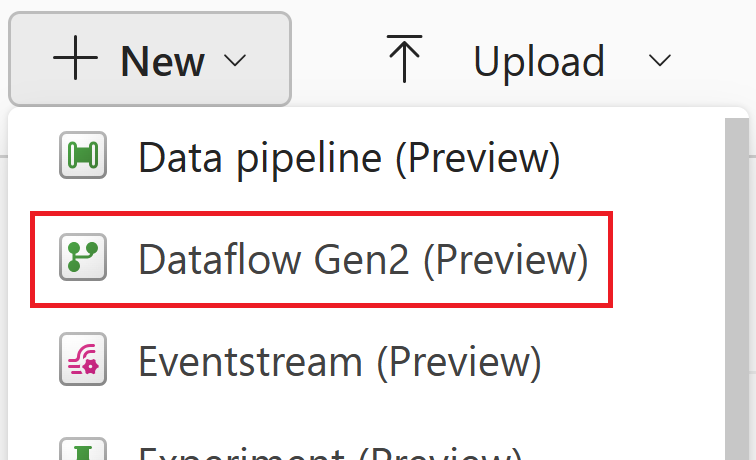
Прием данных из источника OData.
Выберите " Получить данные" и нажмите кнопку "Дополнительно".
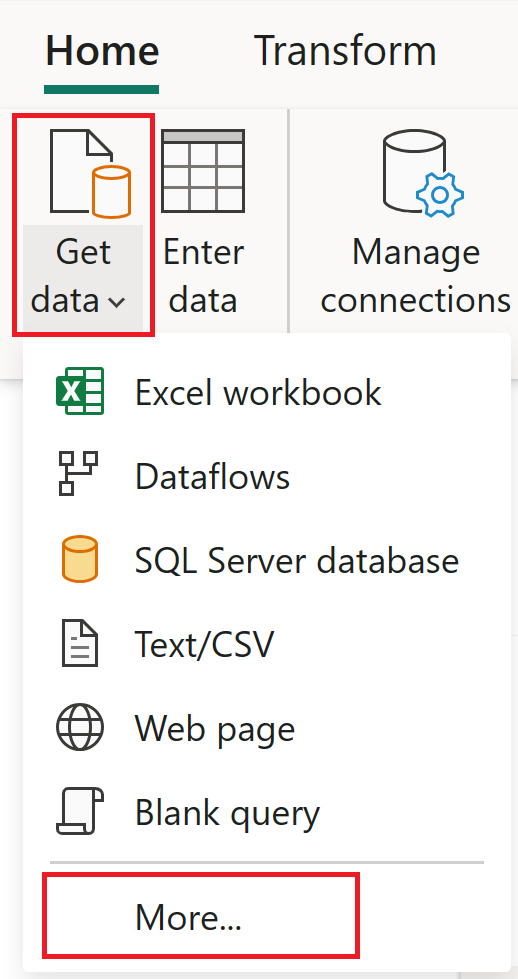
В разделе "Выбор источника данных" найдите OData и выберите соединитель OData.
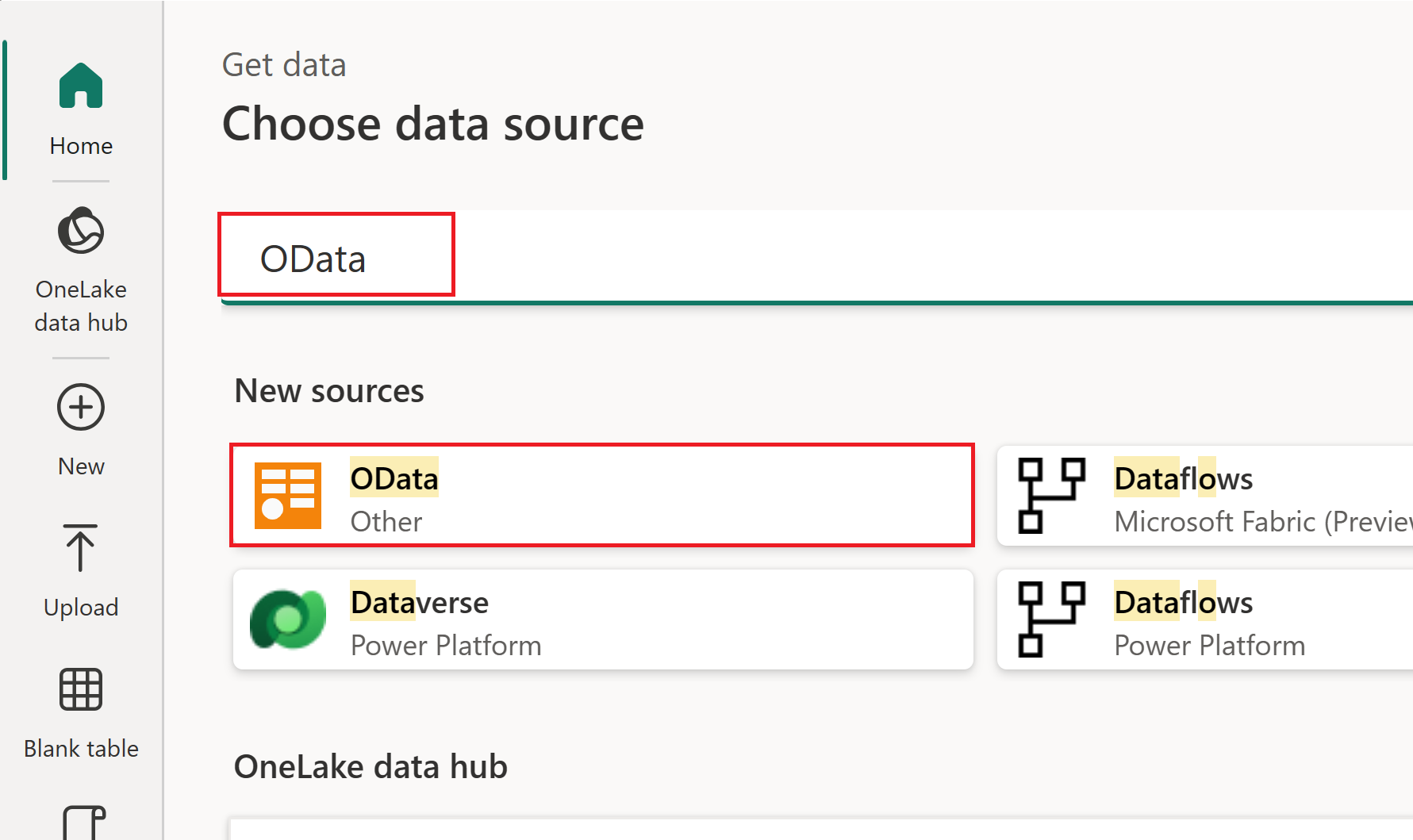
Введите URL-адрес источника OData. В этом руководстве используйте пример службы OData.
Выберите Далее.
Выберите сущность, которую требуется принять. В этом руководстве используйте сущность Orders .
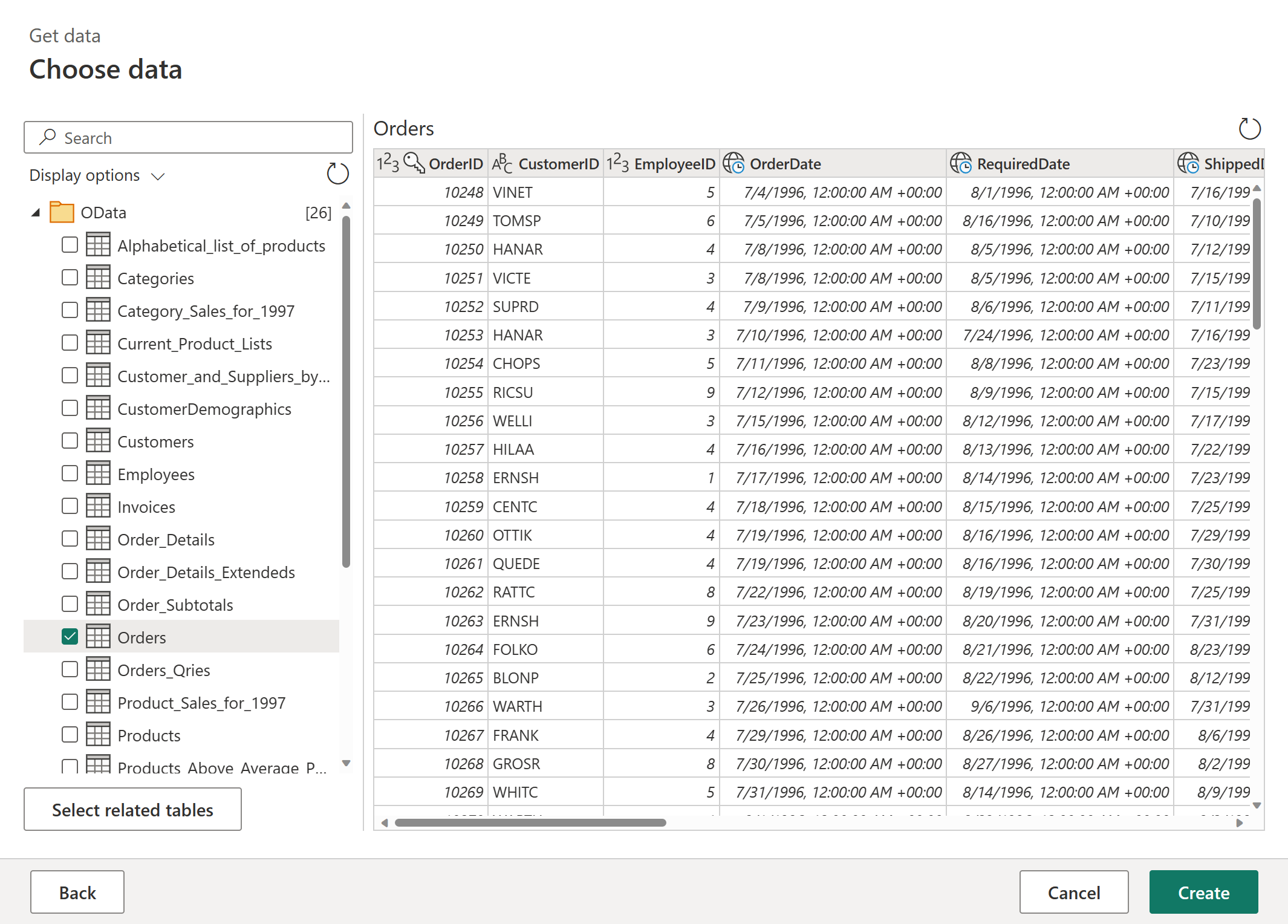
Нажмите кнопку создания.

Теперь, когда вы получили данные из источника OData, вы можете настроить назначение Lakehouse.
Чтобы принять данные в место назначения lakehouse, выполните следующие действия.
Выберите " Добавить назначение данных".
Выберите Lakehouse.

Настройте подключение, которое вы хотите использовать для подключения к lakehouse. Параметры по умолчанию хорошо.
Выберите Далее.
Перейдите в рабочую область, в которой вы создали lakehouse.
Выберите озеро, созданное на предыдущих шагах.
Подтвердите имя таблицы.
Выберите Далее.
Подтвердите метод обновления и выберите "Сохранить параметры".
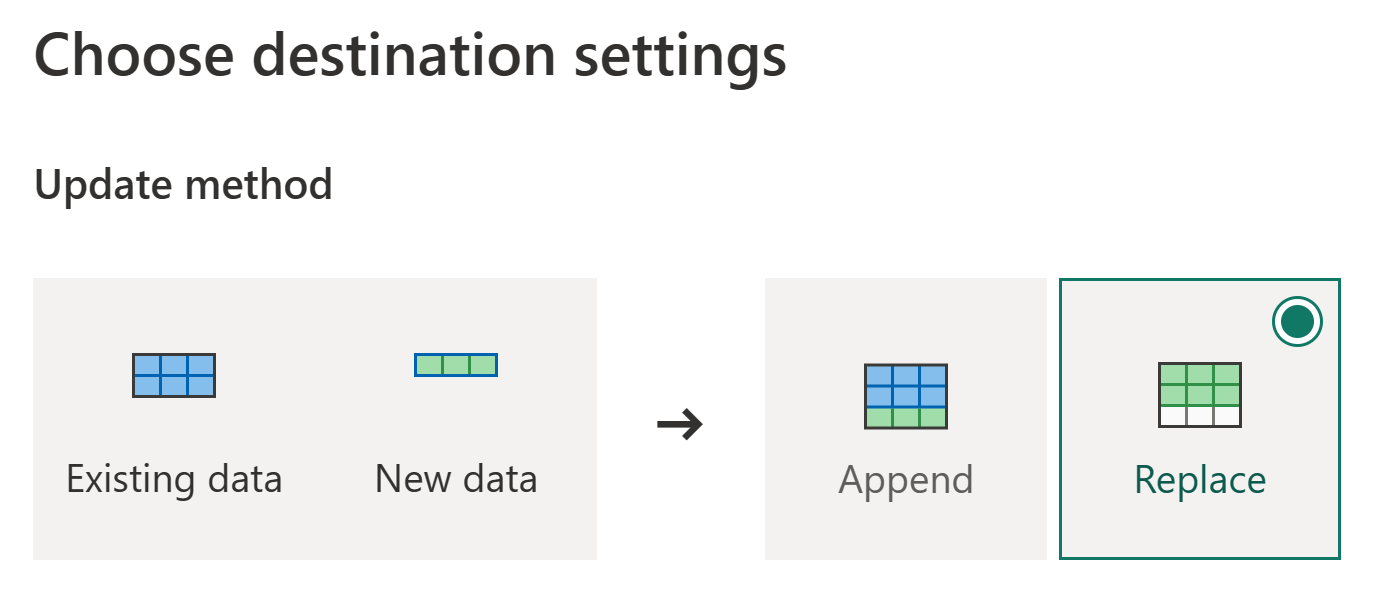
Опубликуйте поток данных.
Важно!
При создании первого поколения Dataflow 2-го поколения в рабочей области элементы Lakehouse и Warehouse подготавливаются вместе с соответствующими конечными точками аналитики SQL и семантической моделями. Эти элементы разделяются всеми потоками данных в рабочей области и требуются для работы потока данных 2-го поколения, не следует удалять и не предназначены для непосредственного использования пользователями. Элементы — это сведения о реализации потока данных 2-го поколения. Элементы не отображаются в рабочей области, но могут быть доступны в других интерфейсах, таких как записная книжка, конечная точка SQL, Lakehouse и хранилище. Элементы можно распознать по их префиксу в имени. Префикс элементов — DataflowsStaging.
Теперь, когда вы получили данные в место назначения Lakehouse, можно настроить конвейер данных.
Создание конвейера данных
Конвейер данных — это рабочий процесс, который можно использовать для автоматизации обработки данных. В этом руководстве вы создадите конвейер данных, который запускает поток данных 2-го поколения, созданный в предыдущей процедуре.
Вернитесь на страницу обзора рабочей области и выберите "Конвейеры данных" в меню создания.
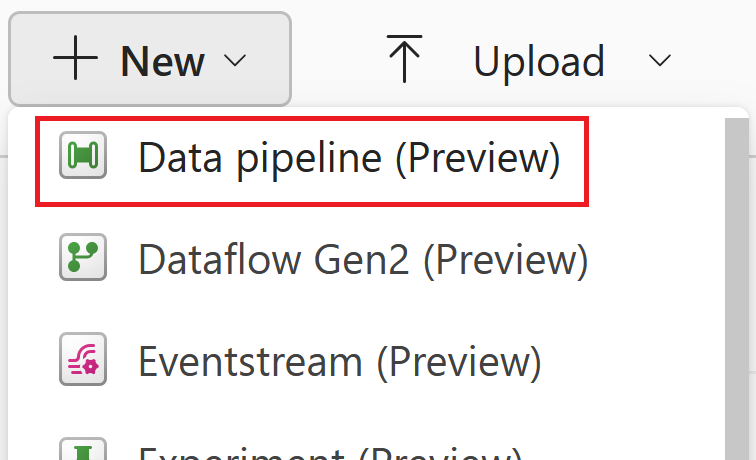
Укажите имя конвейера данных.
Выберите действие потока данных.

Выберите поток данных, созданный в предыдущей процедуре, в раскрывающемся списке потока данных в Параметры.
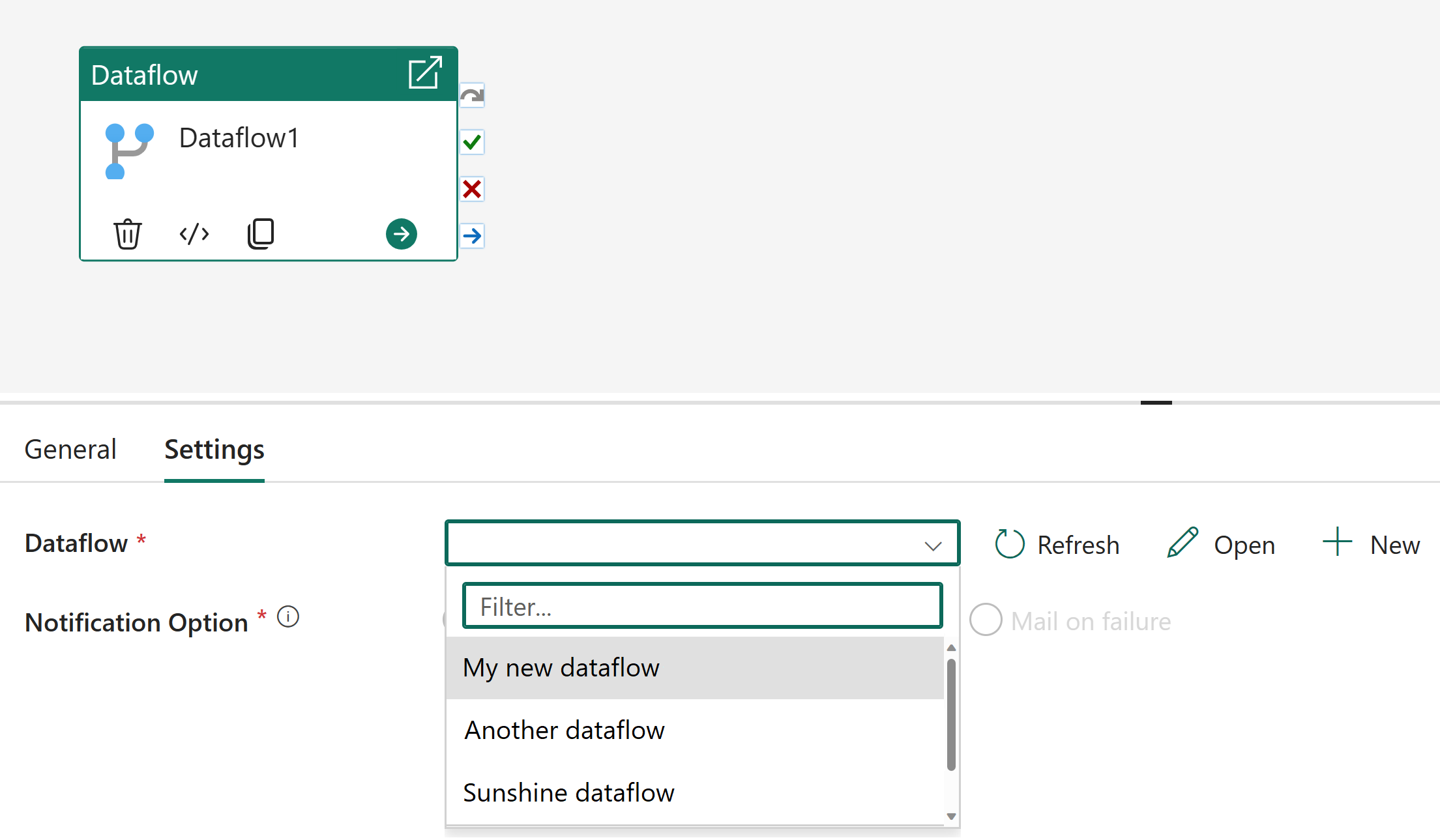
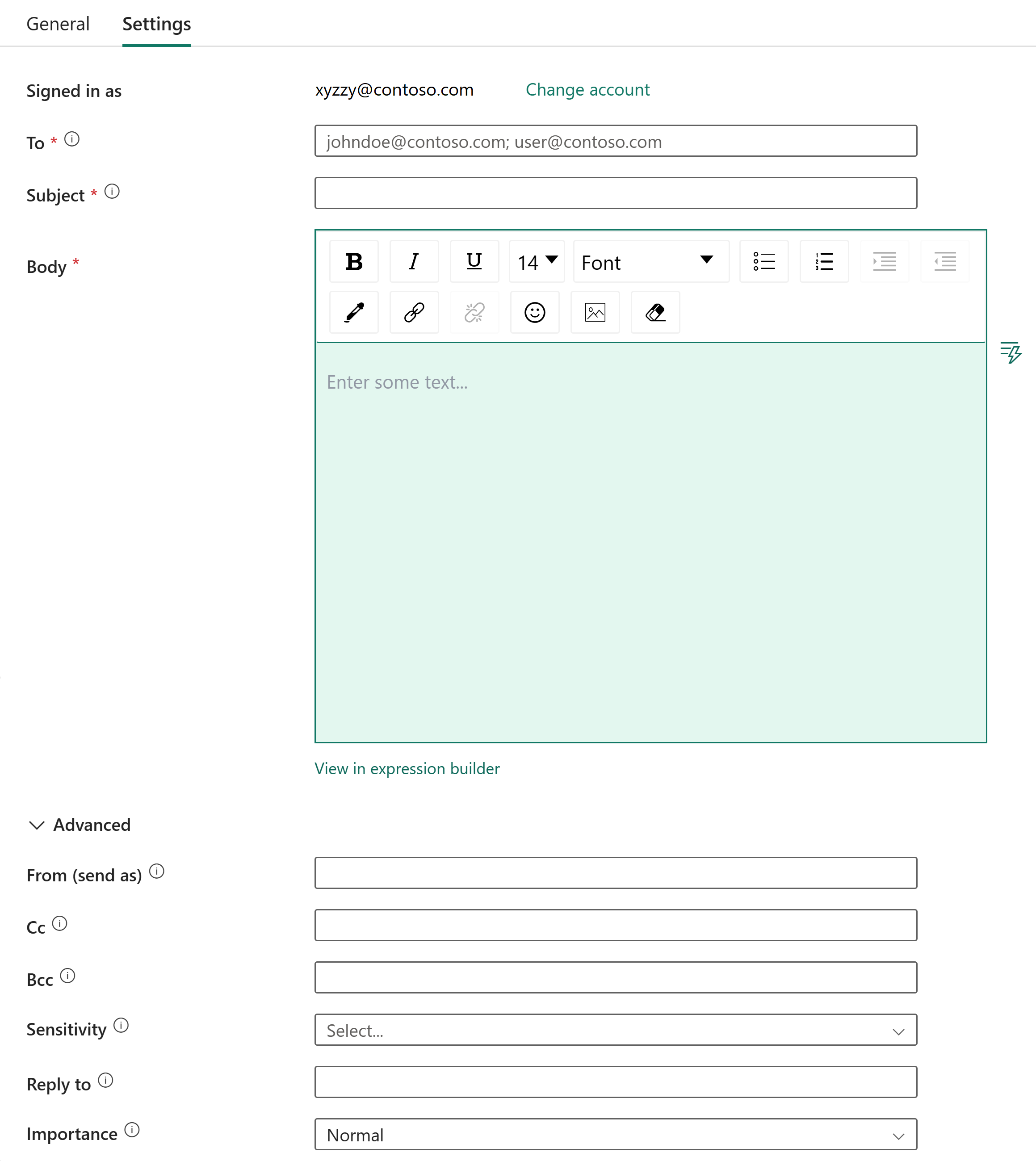
Добавьте действие Office 365 Outlook.

Настройте действие Office 365 Outlook для отправки уведомлений по электронной почте.
Проверка подлинности с помощью учетной записи Office 365.
Выберите адрес электронной почты, на который вы хотите отправить уведомление.
Введите тему для сообщения электронной почты.
Введите текст сообщения электронной почты.

Запуск и планирование конвейера данных
В этом разделе описано, как запустить и запланировать конвейер данных. Это расписание позволяет запускать конвейер данных по расписанию.
Перейдите в рабочую область.
Откройте раскрывающееся меню конвейера данных, созданного в предыдущей процедуре, и выберите "Расписание".
В запланированном запуске нажмите кнопку "Вкл.".
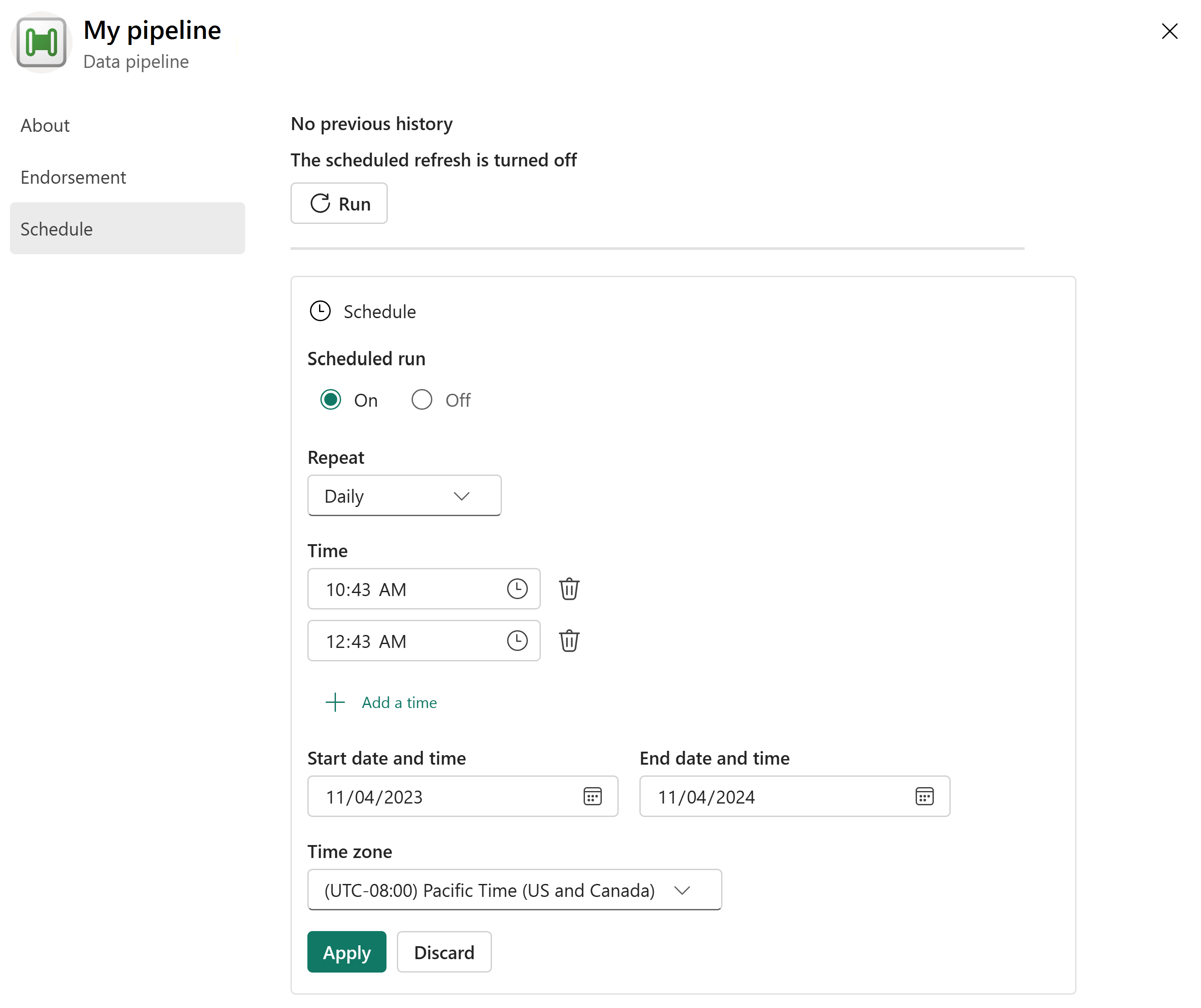
Укажите расписание, которое необходимо использовать для запуска конвейера данных.
- Повторяйте, например, каждый день или каждую минуту.
- При выборе "Ежедневно" можно также выбрать время.
- Начните с определенной даты.
- Окончание определенной даты.
- Выберите часовой пояс.
Нажмите Применить, чтобы применить изменения.

Теперь вы создали конвейер данных, который выполняется по расписанию, обновляет данные в lakehouse и отправляет вам уведомление по электронной почте. Вы можете проверка состояние конвейера данных, перейдя в Центр мониторинга. Вы также можете проверка состояние конвейера данных, перейдя в конвейер данных и выбрав вкладку "Журнал выполнения" в раскрывающемся меню.
Связанный контент
В этом примере показано, как использовать поток данных в конвейере с фабрикой данных в Microsoft Fabric. Вы научились выполнять следующие задачи:
- Создание потока данных.
- Создайте конвейер, вызывающий поток данных.
- Запустите и запланируйте конвейер данных.
Затем перейдите к дополнительным сведениям о мониторинге выполнения конвейера.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по