Добавочная загрузка данных из хранилища данных в Lakehouse
В этом руководстве вы узнаете, как добавочно загружать данные из хранилища данных в Lakehouse.
Обзор
Ниже приведена общая схема решения.

Ниже приведены важные действия для создания этого решения.
Выберите столбец для предела. Выберите один столбец в исходной таблице данных, который можно использовать для среза новых или обновленных записей для каждого запуска. Как правило, данные в этом выбранном столбце (например, последнее_время_изменения или идентификатор) продолжают увеличиваться по мере создания или обновления строк. В качестве предела используется максимальное значение в этом столбце.
Подготовьте таблицу для хранения последнего значения водяного знака в хранилище данных.
Создайте конвейер, используя следующий рабочий процесс:
Конвейер в этом решении содержит следующие действия:
- Создание двух действий поиска. Используйте первое действие поиска для получения последнего значения предела, а второе для получения нового значения предела. Эти значения предела передаются в действие копирования.
- Создайте действие копирования, которое копирует строки из исходной таблицы данных со значением столбца подложки больше старого значения водяного знака и меньше нового значения водяного знака. Затем он копирует данные из хранилища данных в Lakehouse в виде нового файла.
- Создайте действие хранимой процедуры, которое обновляет последнее значение водяного знака для следующего запуска конвейера.
Необходимые компоненты
- Хранилище данных. Хранилище данных используется в качестве исходного хранилища данных. Если у вас его нет, см. статью "Создание хранилища данных", чтобы выполнить действия по его созданию.
- Лейкхаус. Вы используете Lakehouse в качестве целевого хранилища данных. Если у вас его нет, см. статью "Создать Lakehouse ", чтобы создать ее. Создайте папку с именем IncrementalCopy для хранения скопированных данных.
Подготовка источника
Ниже приведены некоторые таблицы и хранимые процедуры, которые необходимо подготовить в исходном хранилище данных перед настройкой конвейера добавочного копирования.
1. Создание таблицы источника данных в хранилище данных
Выполните следующую команду SQL в хранилище данных, чтобы создать таблицу с именем data_source_table в качестве таблицы источника данных. В этом руководстве вы будете использовать его в качестве примера данных для добавочного копирования.
create table data_source_table
(
PersonID int,
Name varchar(255),
LastModifytime DATETIME2(6)
);
INSERT INTO data_source_table
(PersonID, Name, LastModifytime)
VALUES
(1, 'aaaa','9/1/2017 12:56:00 AM'),
(2, 'bbbb','9/2/2017 5:23:00 AM'),
(3, 'cccc','9/3/2017 2:36:00 AM'),
(4, 'dddd','9/4/2017 3:21:00 AM'),
(5, 'eeee','9/5/2017 8:06:00 AM');
Данные в таблице источника данных показаны ниже.
PersonID | Name | LastModifytime
-------- | ---- | --------------
1 | aaaa | 2017-09-01 00:56:00.000
2 | bbbb | 2017-09-02 05:23:00.000
3 | cccc | 2017-09-03 02:36:00.000
4 | dddd | 2017-09-04 03:21:00.000
5 | eeee | 2017-09-05 08:06:00.000
В этом руководстве в качестве столбца подложки используется LastModifytime .
2. Создайте другую таблицу в хранилище данных для хранения последнего значения водяного знака
Выполните следующую команду SQL в хранилище данных, чтобы создать таблицу с именем водяной знак , чтобы сохранить последнее значение водяного знака:
create table watermarktable ( TableName varchar(255), WatermarkValue DATETIME2(6), );Задайте значение по умолчанию последнего водяного знака с именем таблицы источника данных. В этом руководстве имя таблицы — data_source_table, а значение по умолчанию —
1/1/2010 12:00:00 AM.INSERT INTO watermarktable VALUES ('data_source_table','1/1/2010 12:00:00 AM')Просмотрите данные в подложке таблицы.
Select * from watermarktableВыходные данные:
TableName | WatermarkValue ---------- | -------------- data_source_table | 2010-01-01 00:00:00.000
3. Создание хранимой процедуры в хранилище данных
Выполните следующую команду, чтобы создать хранимую процедуру в хранилище данных. Эта хранимая процедура используется для обновления последнего значения водяного знака после последнего запуска конвейера.
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET [WatermarkValue] = @LastModifiedtime
WHERE [TableName] = @TableName
END
Настройка конвейера для добавочной копии
Шаг 1. Создание конвейера
Перейдите в Power BI.
Щелкните значок Power BI в нижней левой части экрана, а затем выберите фабрику данных, чтобы открыть домашнюю страницу фабрики данных.

Перейдите в рабочую область Microsoft Fabric.
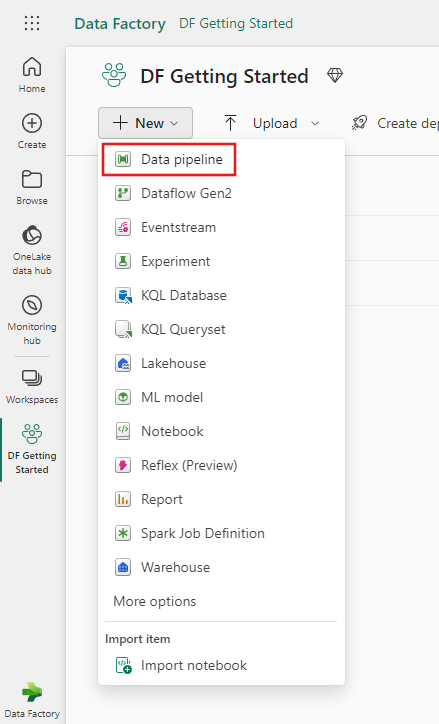
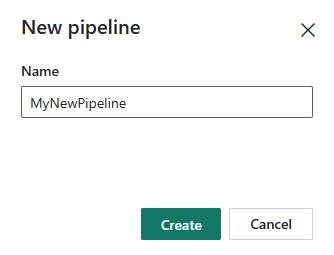
Выберите конвейер данных и введите имя конвейера для создания нового конвейера.
Шаг 2. Добавление действия подстановки для последнего водяного знака
На этом шаге вы создадите действие подстановки, чтобы получить последнее значение водяного знака. Значение по умолчанию 1/1/2010 12:00:00 AM , заданное до получения.
Выберите " Добавить действие конвейера" и выберите "Поиск " из раскрывающегося списка.
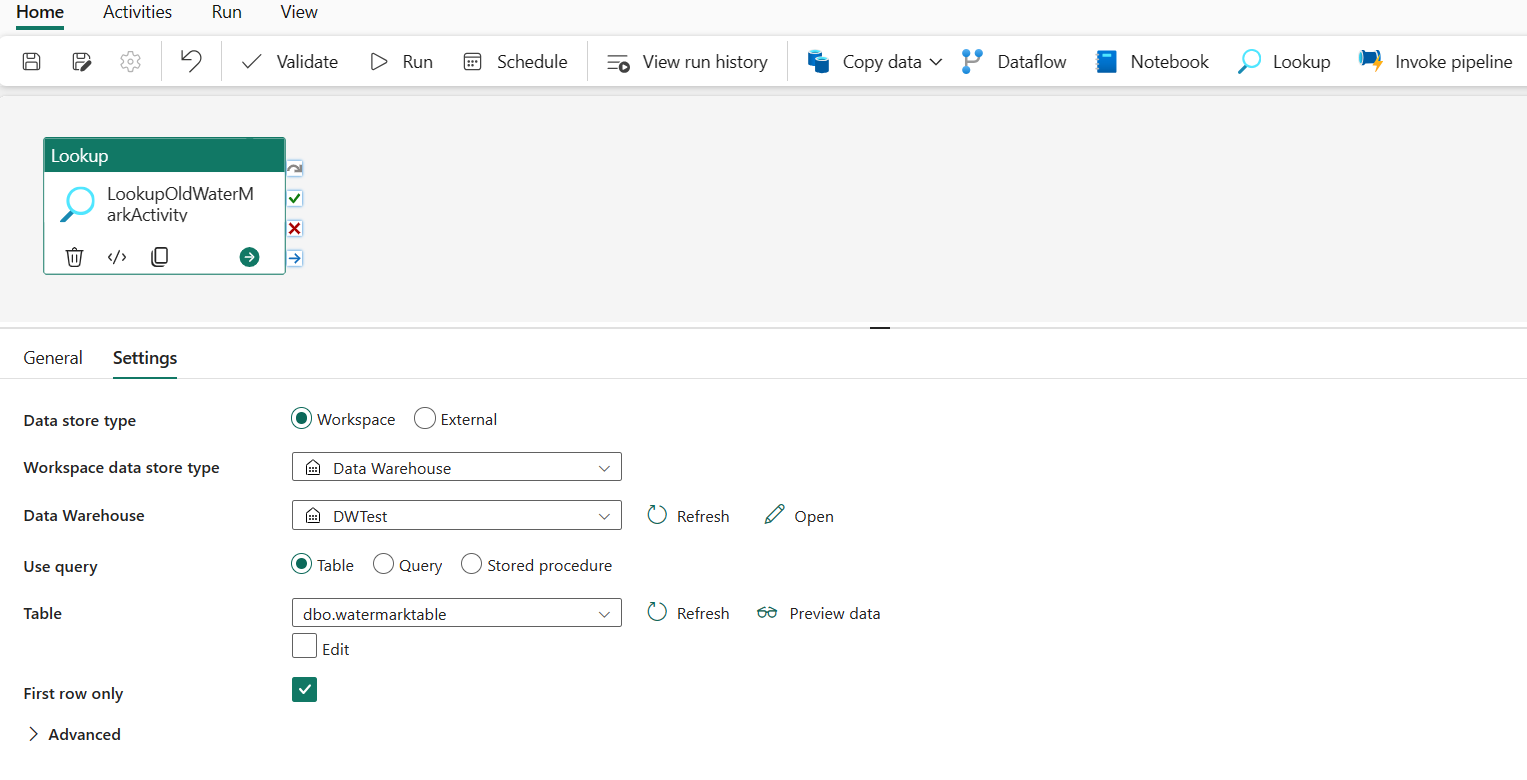
На вкладке "Общие " переименуйте это действие в LookupOldWaterMarkActivity.
На вкладке Параметры выполните следующую конфигурацию:
- Тип хранилища данных: выбор рабочей области.
- Тип хранилища данных рабочей области: выбор хранилища данных.
- Хранилище данных: выберите хранилище данных.
- Использование запроса: выбор таблицы.
- Таблица. Выберите dbo.watermarktable.
- Только первая строка: выбрано.
Шаг 3. Добавление действия подстановки для нового водяного знака
На этом шаге вы создадите действие подстановки, чтобы получить новое значение водяного знака. Вы будете использовать запрос для получения нового водяного знака из исходной таблицы данных. Будет получено максимальное значение в столбце LastModifytime в data_source_table.
На верхней панели выберите " Поиск " на вкладке "Действия ", чтобы добавить второе действие подстановки.
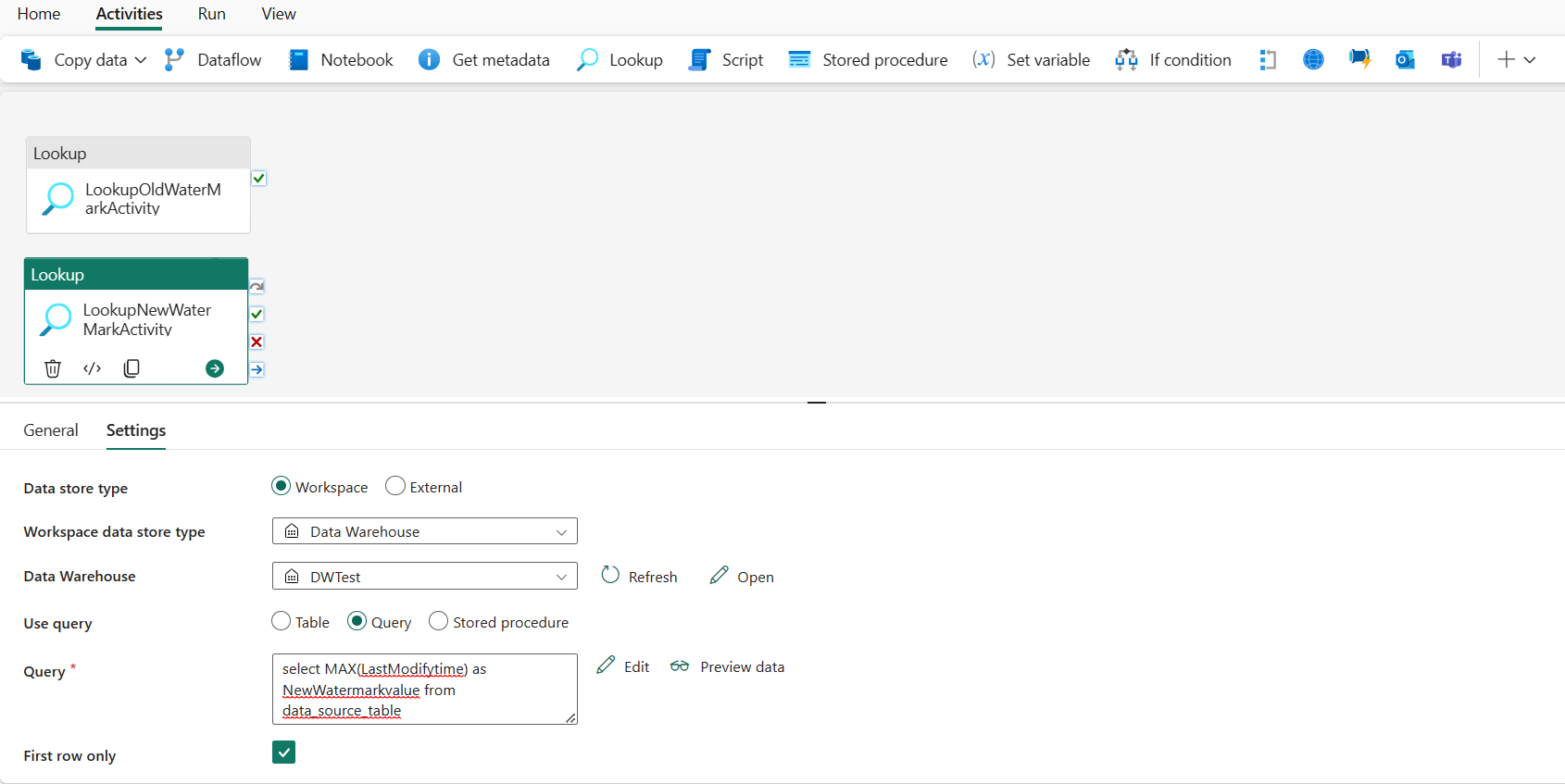
На вкладке "Общие " переименуйте это действие в LookupNewWaterMarkActivity.
На вкладке Параметры выполните следующую конфигурацию:
Тип хранилища данных: выбор рабочей области.
Тип хранилища данных рабочей области: выбор хранилища данных.
Хранилище данных: выберите хранилище данных.
Используйте запрос: выберите запрос.
Запрос: введите следующий запрос, чтобы выбрать максимальное время последнего изменения в качестве нового водяного знака:
select MAX(LastModifytime) as NewWatermarkvalue from data_source_tableТолько первая строка: выбрано.
Шаг 4. Добавление действия копирования для копирования добавочных данных
На этом шаге вы добавите действие копирования для копирования добавочных данных между последним подложкой и новым подложкой из хранилища данных в Lakehouse.
Выберите "Действия " на верхней панели и нажмите кнопку "Копировать данные ">Добавить на холст ", чтобы получить действие копирования.
На вкладке "Общие" переименуйте это действие в IncrementalCopyActivity.
Подключение оба действия подстановки в действие копирования путем перетаскивания зеленой кнопки (при успешном выполнении) к действиям подстановки в действие копирования. Отпустите кнопку мыши при отображении цвета границы действия копирования на зеленый.

На вкладке "Источник" выполните следующую конфигурацию:
Тип хранилища данных: выбор рабочей области.
Тип хранилища данных рабочей области: выбор хранилища данных.
Хранилище данных: выберите хранилище данных.
Используйте запрос: выберите запрос.
Запрос. Введите следующий запрос, чтобы скопировать добавочные данные между последним подложкой и новым подложкой.
select * from data_source_table where LastModifytime > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}' and LastModifytime <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'
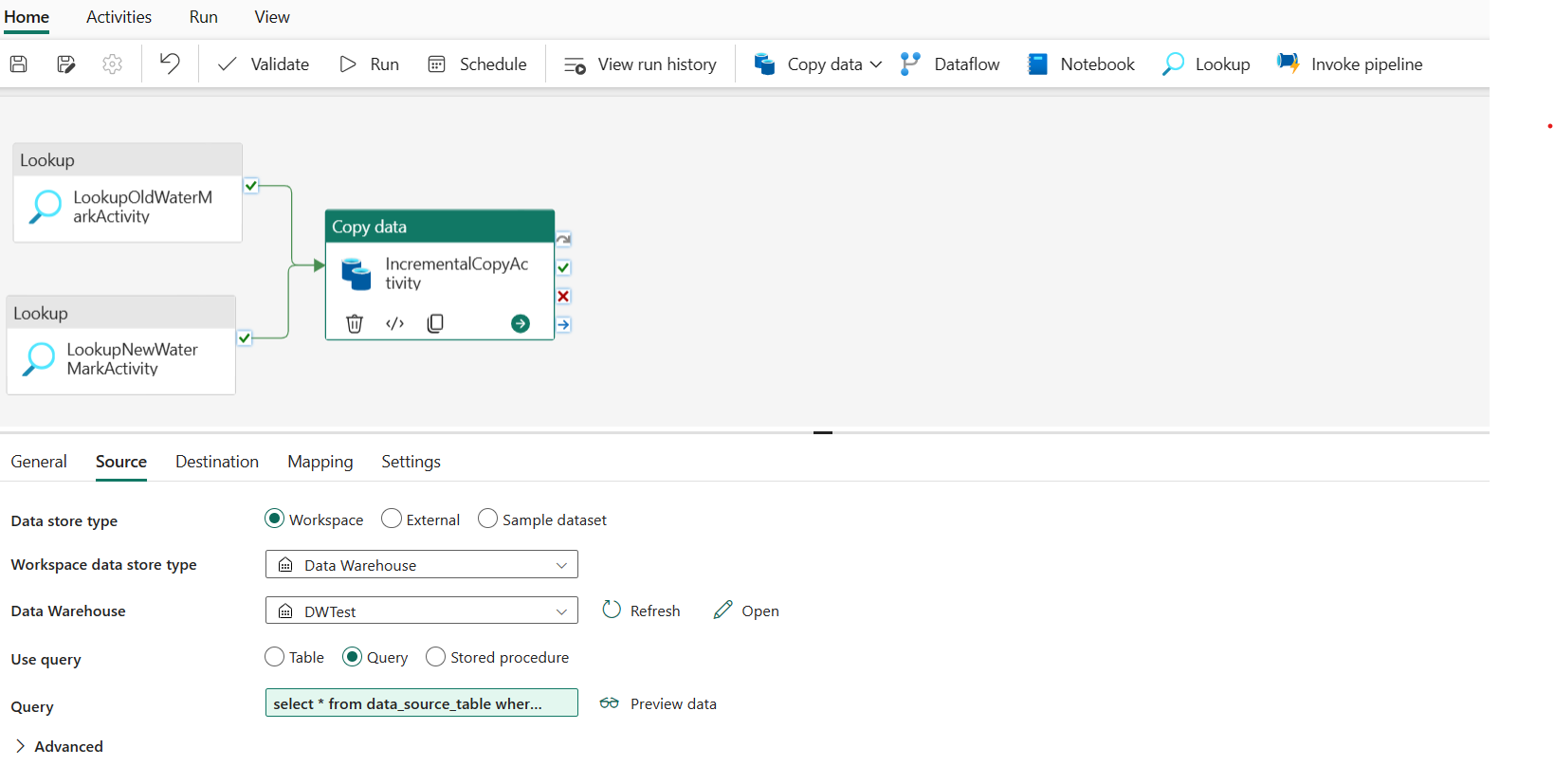
На вкладке "Назначение" выполните следующую конфигурацию:
- Тип хранилища данных: выбор рабочей области.
- Тип хранилища данных рабочей области: Select Lakehouse.
- Lakehouse: Выберите lakehouse.
- Корневая папка: выбор файлов.
- Путь к файлу: укажите папку, которую требуется сохранить скопированные данные. Нажмите кнопку "Обзор", чтобы выбрать папку. Для имени файла откройте динамический контент и введите
@CONCAT('Incremental-', pipeline().RunId, '.txt')в открывшемся окне, чтобы создать имена файлов для скопированного файла данных в Lakehouse. - Формат файла: выберите тип формата данных.
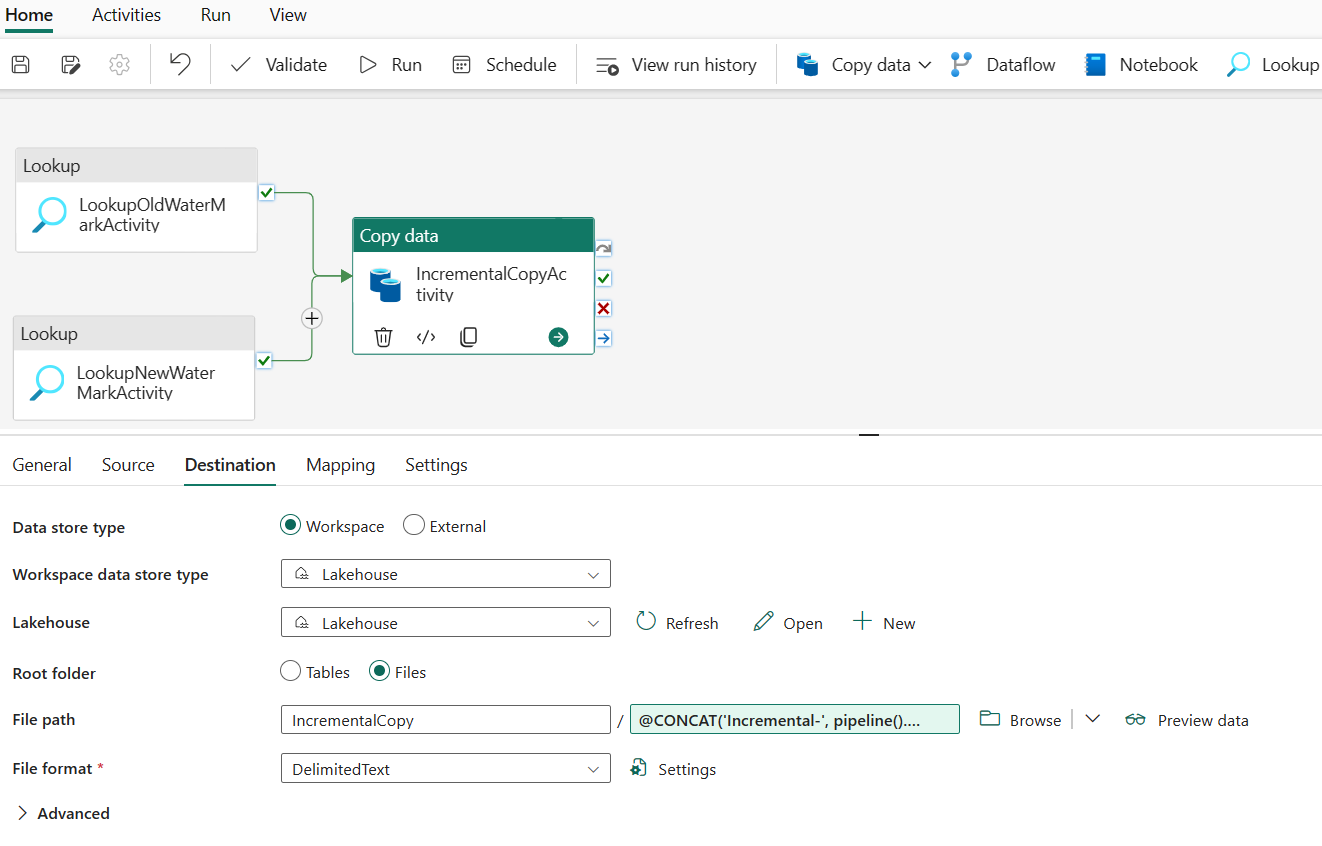
Шаг 5.Добавление действия хранимой процедуры
На этом шаге вы добавите действие хранимой процедуры, чтобы обновить последнее значение водяного знака для следующего запуска конвейера.
Выберите действия на верхней панели и выберите хранимую процедуру, чтобы добавить действие хранимой процедуры .
На вкладке "Общие " переименуйте это действие в StoredProceduretoWriteWatermarkActivity.
Подключение выходные данные действия копирования в действие хранимой процедуры зеленым цветом (при успешном выполнении).
На вкладке Параметры выполните следующую конфигурацию:
Тип хранилища данных: выбор рабочей области.
Хранилище данных: выберите хранилище данных.
Имя хранимой процедуры: укажите хранимую процедуру, созданную в хранилище данных: [dbo].[ usp_write_watermark].
Разверните параметры хранимой процедуры. Чтобы указать значения параметров хранимой процедуры, выберите "Импорт" и введите следующие значения для параметров:
Имя. Тип значение LastModifiedtime Дата/время @{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue} TableName Строка @{activity('LookupOldWaterMarkActivity').output.firstRow.TableName}
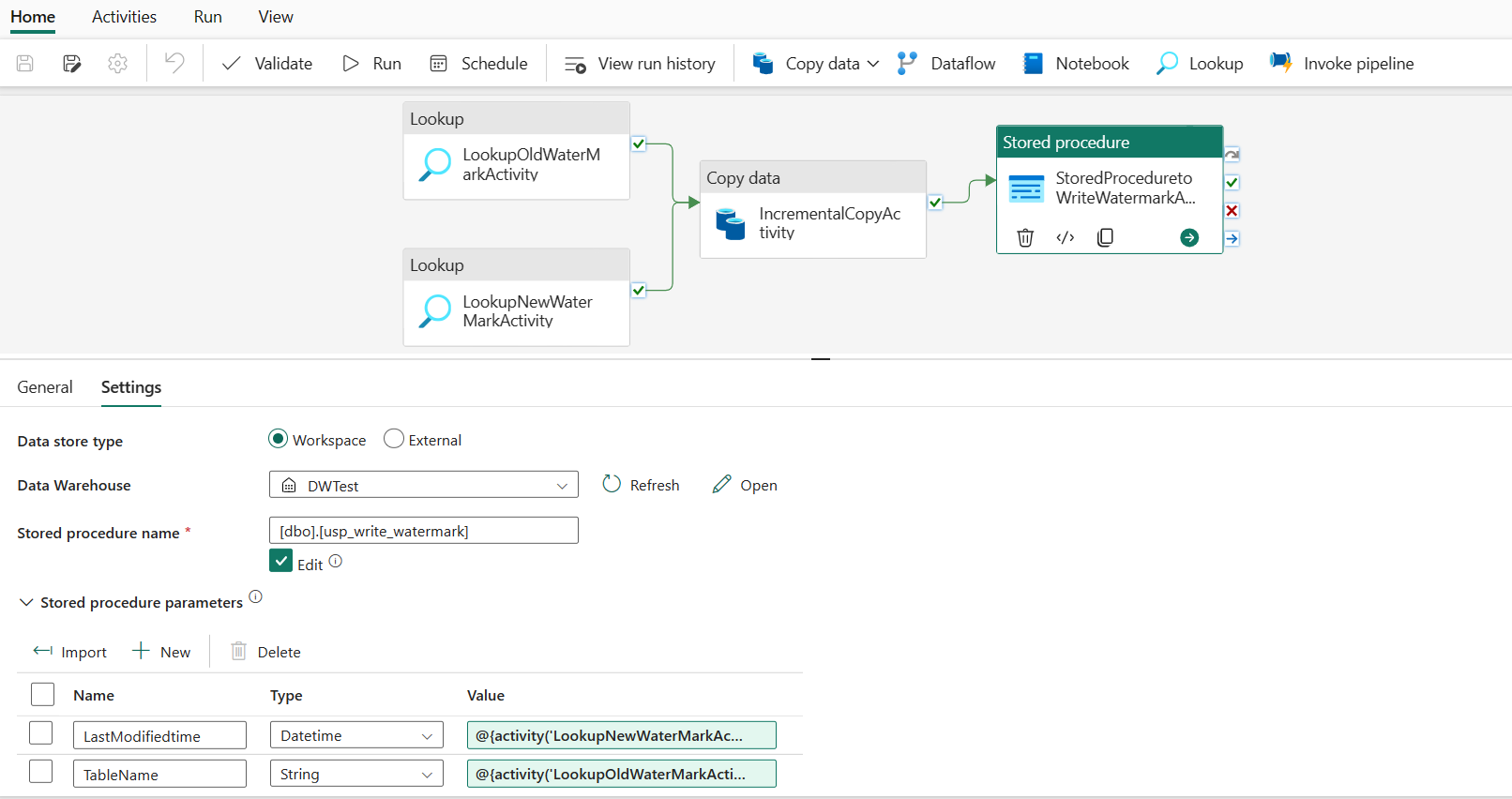
Шаг 6.Запуск конвейера и мониторинг результата
На верхней панели выберите "Запустить " на вкладке "Главная ". Затем нажмите кнопку "Сохранить и запустить". Конвейер запускается, и вы можете отслеживать конвейер на вкладке "Выходные данные ".
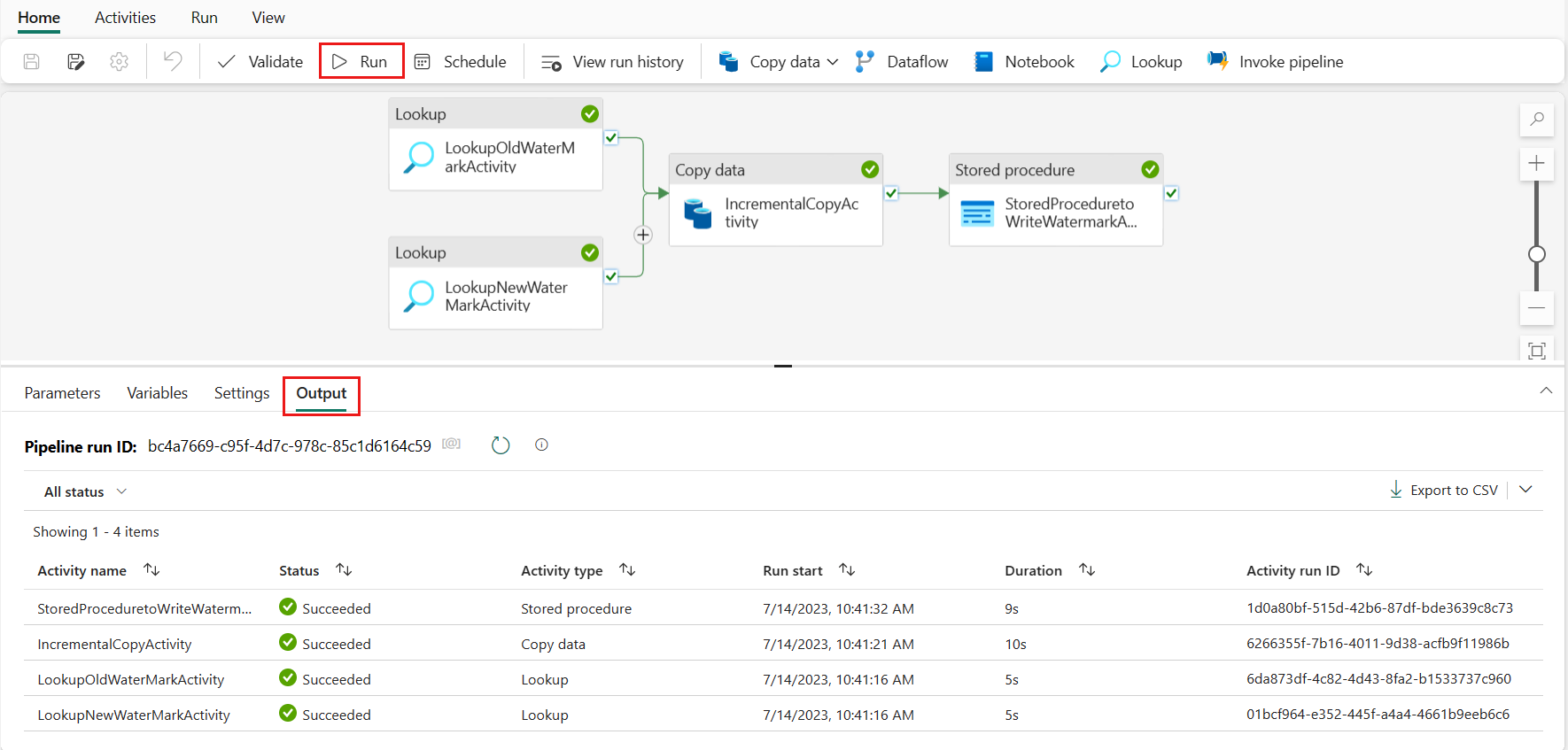
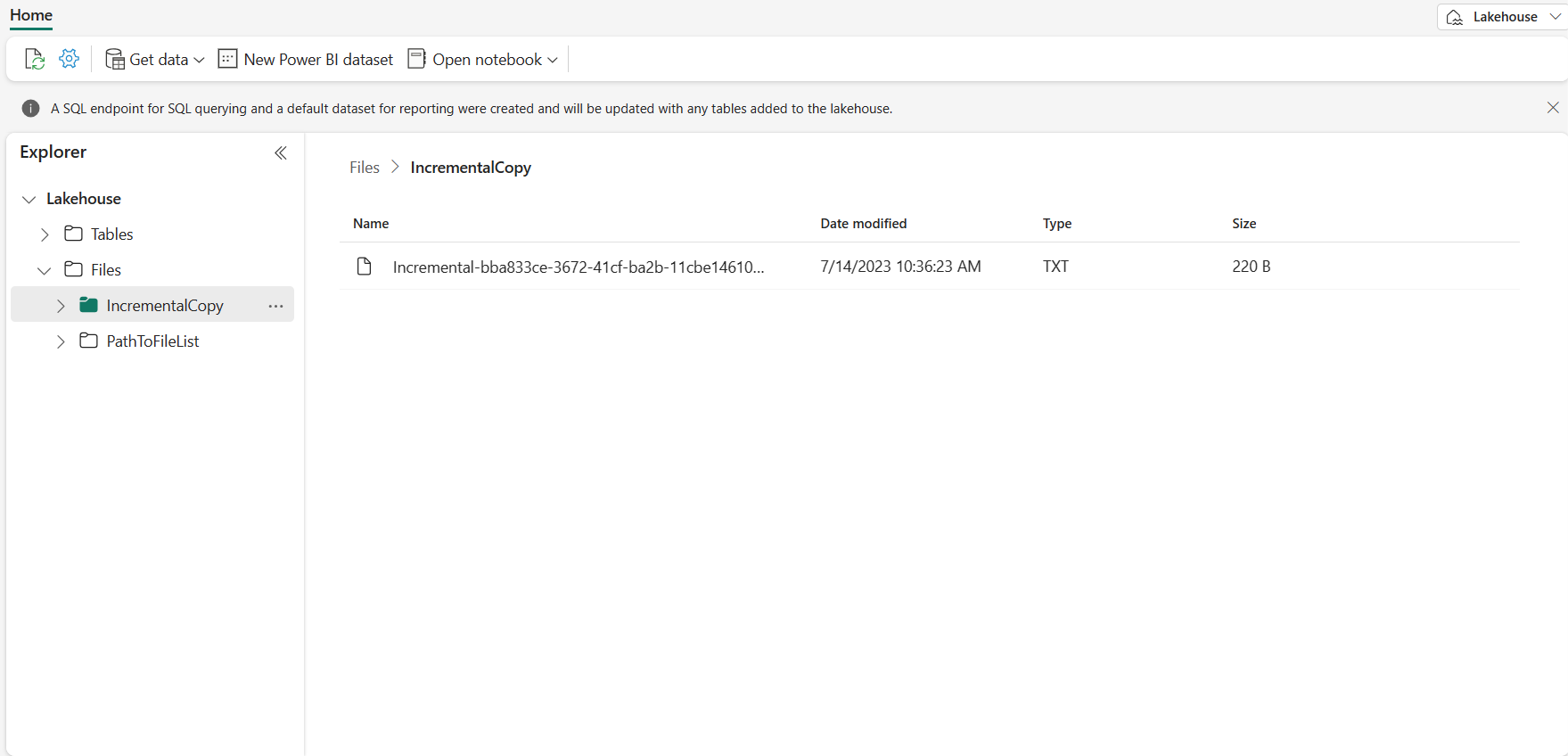
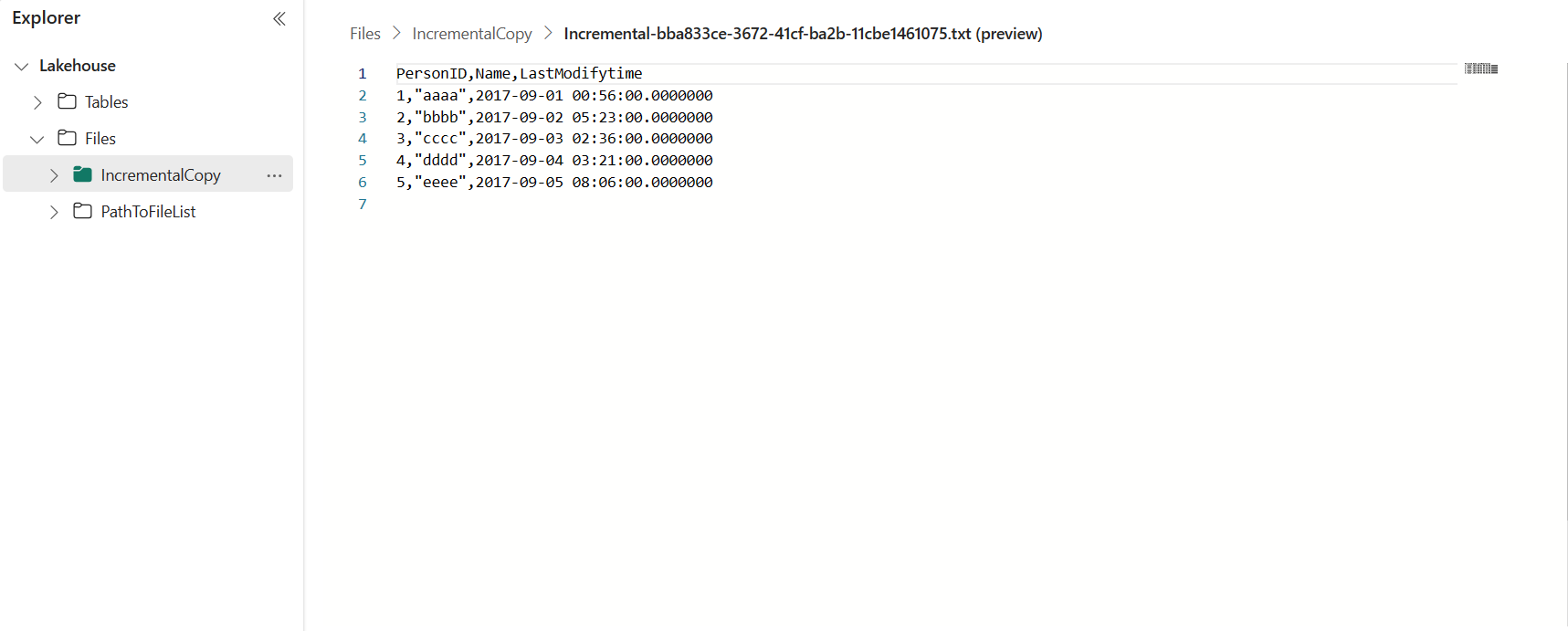
Перейдите в Lakehouse, найдите файл данных в указанной папке, и вы можете выбрать файл для предварительного просмотра скопированных данных.
Добавление дополнительных данных для просмотра результатов добавочного копирования
После завершения первого запуска конвейера давайте попытаемся добавить дополнительные данные в исходную таблицу хранилища данных, чтобы узнать, может ли этот конвейер скопировать добавочные данные.
Шаг 1. Добавление дополнительных данных в источник
Вставьте новые данные в хранилище данных, выполнив следующий запрос:
INSERT INTO data_source_table
VALUES (6, 'newdata','9/6/2017 2:23:00 AM')
INSERT INTO data_source_table
VALUES (7, 'newdata','9/7/2017 9:01:00 AM')
Обновленные данные для data_source_table :
PersonID | Name | LastModifytime
-------- | ---- | --------------
1 | aaaa | 2017-09-01 00:56:00.000
2 | bbbb | 2017-09-02 05:23:00.000
3 | cccc | 2017-09-03 02:36:00.000
4 | dddd | 2017-09-04 03:21:00.000
5 | eeee | 2017-09-05 08:06:00.000
6 | newdata | 2017-09-06 02:23:00.000
7 | newdata | 2017-09-07 09:01:00.000
Шаг 2. Запуск другого конвейера и мониторинг результата
Вернитесь на страницу конвейера. На верхней панели снова нажмите кнопку "Запустить " на вкладке "Главная ". Конвейер запускается, и вы можете отслеживать конвейер в разделе "Выходные данные".
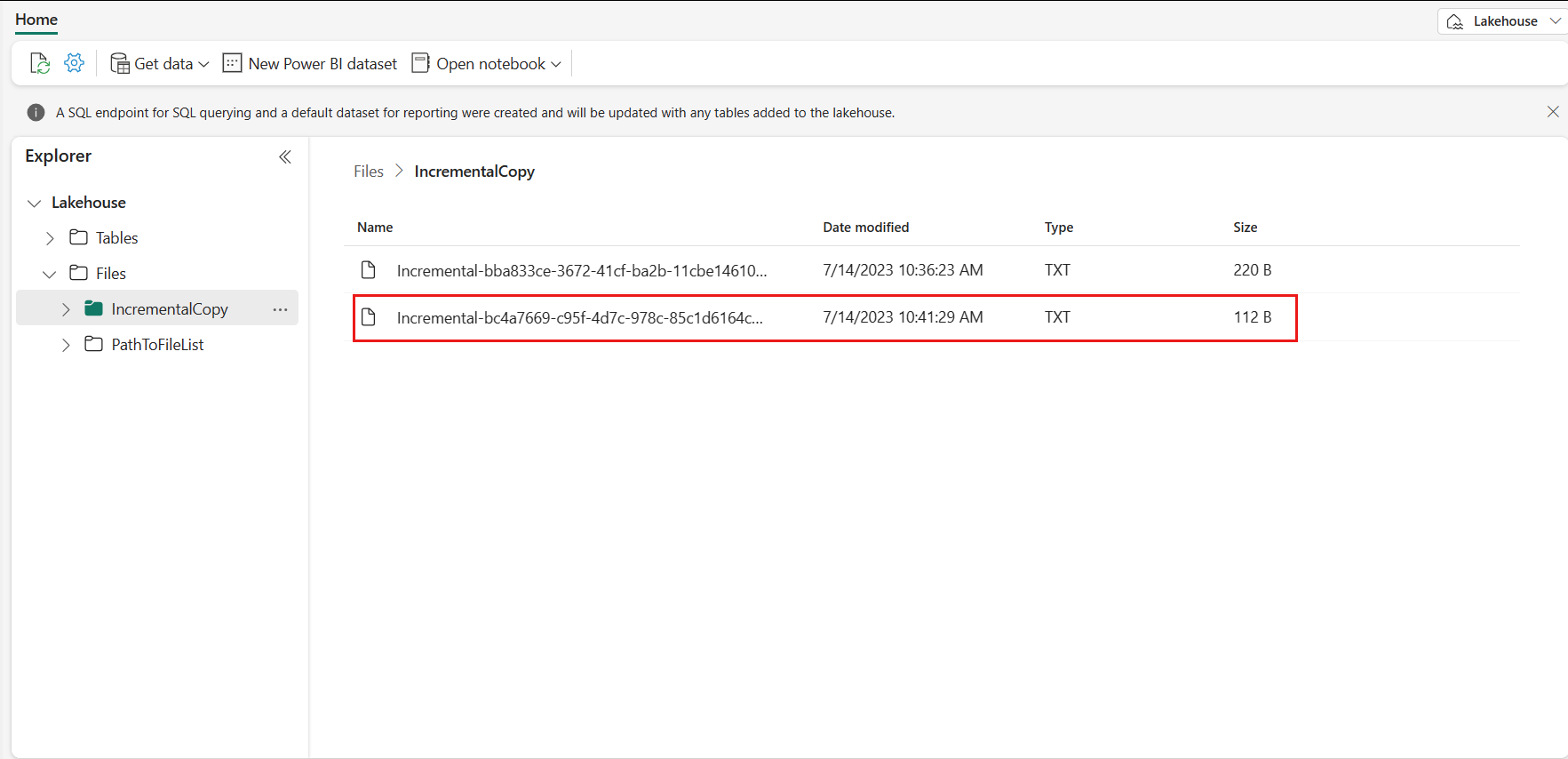
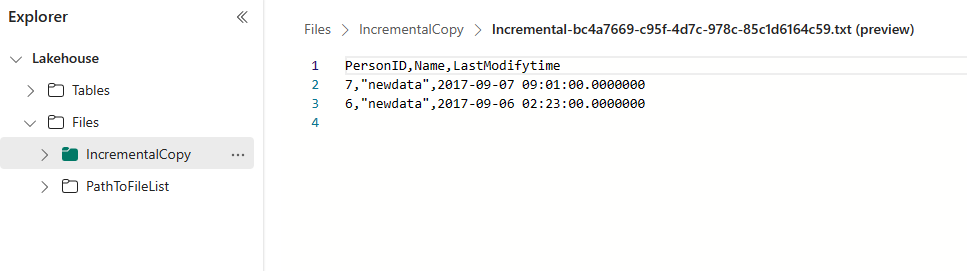
Перейдите в Lakehouse, найдите новый скопированный файл данных находится в указанной папке, и вы можете выбрать файл для предварительного просмотра скопированных данных. В этом файле отображаются добавочные данные.
Связанный контент
Затем перейдите к дополнительным сведениям о копировании из Хранилище BLOB-объектов Azure в Lakehouse.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по