Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Это руководство занимает 15 минут и описывает, как постепенно накапливать данные в lakehouse с помощью Dataflow Gen2.
Для постепенного накопления данных в хранилище данных требуется метод загрузки только новых или обновленных данных. Этот метод можно выполнить с помощью запроса для фильтрации данных на основе назначения данных. В этом руководстве показано, как создать поток данных для загрузки данных из источника OData в озеро и добавление запроса в поток данных для фильтрации данных на основе назначения данных.
Ниже приведены шаги высокого уровня, описанные в этом руководстве.
- Создайте поток данных для загрузки данных из источника OData в озеро.
- Добавьте запрос в поток данных, чтобы отфильтровать данные на основе назначения данных.
- (Необязательно) перезагрузка данных с использованием ноутбуков и пайплайнов.
Требования
У вас должна быть рабочая область с поддержкой Microsoft Fabric. Если у вас еще нет одного, обратитесь к статье "Создание рабочей области". Кроме того, в этом руководстве предполагается, что вы используете представление схемы в Dataflow 2-го поколения. Чтобы проверить, используете ли вы представление диаграммы, на верхней ленте перейдите к представлению и убедитесь, что выбрано представление схемы.
Создайте поток данных для загрузки данных из источника OData в lakehouse
В этом разделе описано, как создать поток данных для загрузки данных из источника OData в озеро.
Создайте новый lakehouse в рабочей области.
Создайте поток данных 2-го поколения в рабочей области.
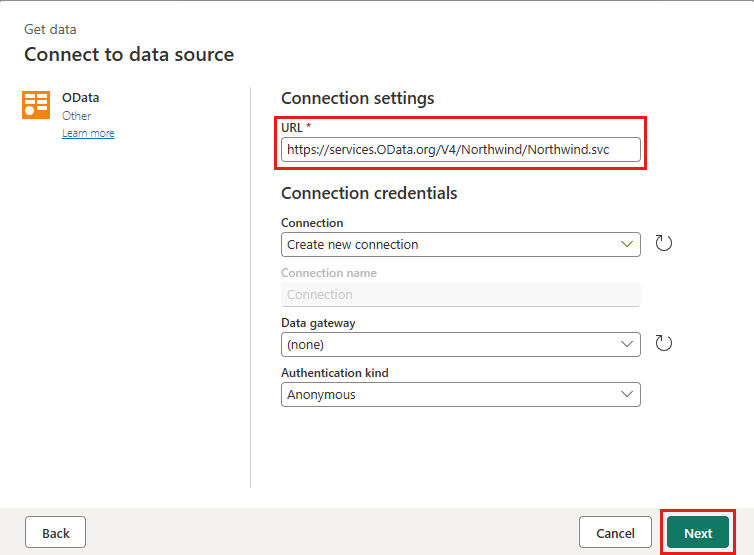
Добавьте новый источник в поток данных. Выберите источник OData и введите следующий URL-адрес:
https://services.OData.org/V4/Northwind/Northwind.svc
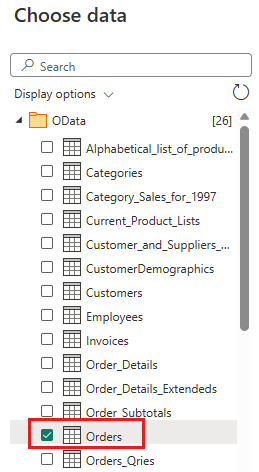
Выберите таблицу "Заказы" и нажмите кнопку "Далее".
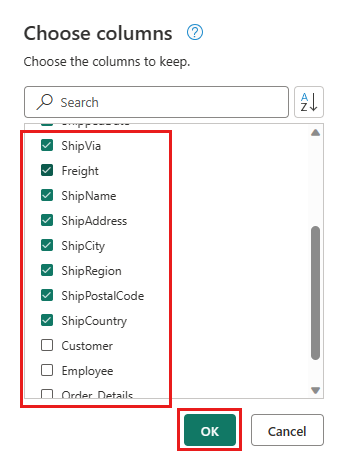
Выберите следующие столбцы, чтобы сохранить:
OrderIDCustomerIDEmployeeIDOrderDateRequiredDateShippedDateShipViaFreightShipNameShipAddressShipCityShipRegionShipPostalCodeShipCountry
Измените тип данных
OrderDate,RequiredDateиShippedDateнаdatetime.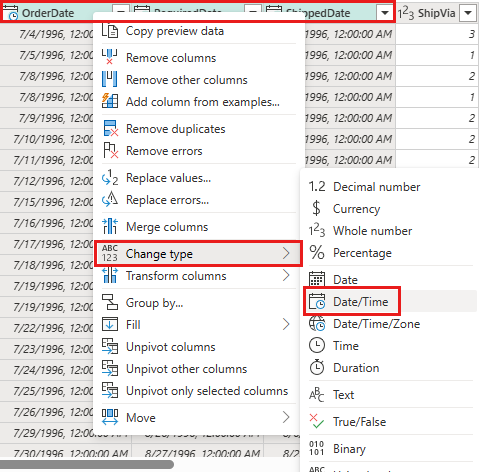
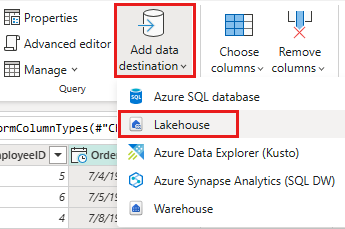
Настройте место назначения данных для вашего lakehouse, используя следующие параметры:
- Назначение данных:
Lakehouse - Lakehouse: Выберите озеро, созданное на шаге 1.
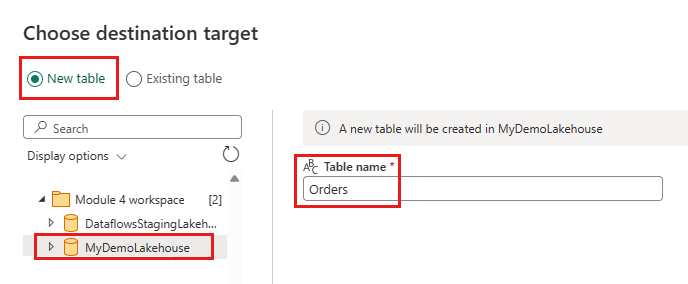
- Новое имя таблицы:
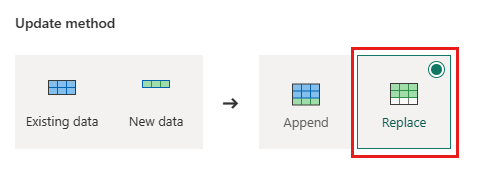
Orders - Метод Update:
Replace
- Назначение данных:
Нажмите кнопку "Далее" и опубликуйте поток данных.



Теперь вы создали поток данных для загрузки данных из источника OData в озеро. Этот поток данных используется в следующем разделе для добавления запроса в поток данных для фильтрации данных на основе назначения данных. После этого можно использовать поток данных для перезагрузки данных с помощью записных книжек и конвейеров.
Добавление запроса в поток данных для фильтрации данных на основе назначения данных
В этом разделе добавляется запрос к потоку данных для фильтрации данных на основе данных в целевом лейкхаусе. Запрос получает максимальный OrderID в lakehouse в начале обновления потока данных и использует максимальный идентификатор OrderId, чтобы выбрать заказы с более высоким OrderId из источника и добавить их в назначение данных. Предполагается, что заказы добавляются в исходные данные в порядке возрастания OrderID. Если это не так, можно использовать другой столбец для фильтрации данных. Например, можно использовать столбец OrderDate для фильтрации данных.
Примечание.
Фильтры OData применяются в Fabric после получения данных из источника данных, однако для таких источников баз данных, как SQL Server, фильтр применяется в запросе, отправленном в серверный источник данных, и только отфильтрованные строки возвращаются в службу.
После обновления потока данных снова откройте поток данных, созданный в предыдущем разделе.
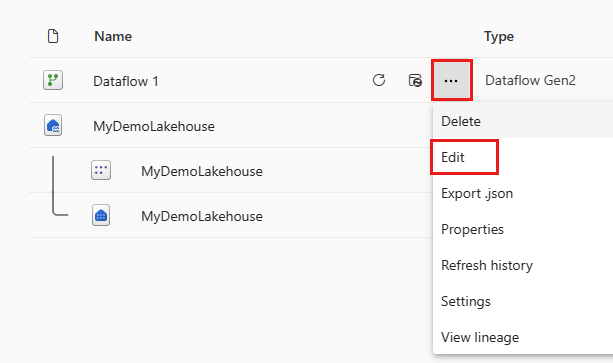
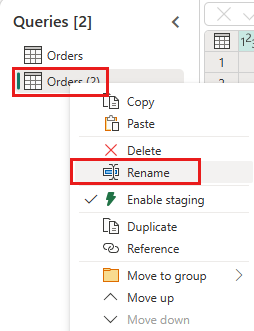
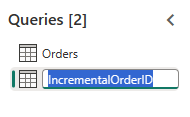
Создайте новый запрос с именем
IncrementalOrderIDи получите данные из таблицы Orders в lakehouse, созданной в предыдущем разделе.
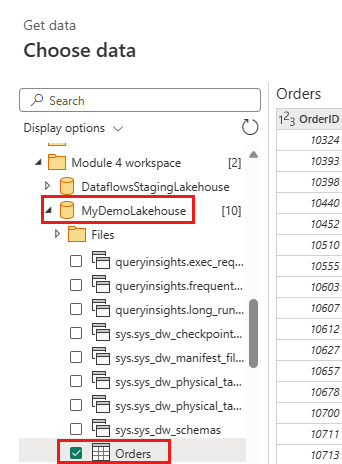
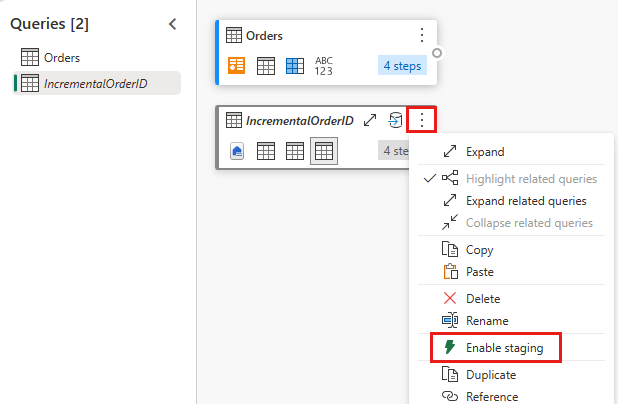
Отключите промежуточное выполнение этого запроса.
В предварительном просмотре данных щелкните правой кнопкой мыши
OrderIDстолбец и выберите " Детализация".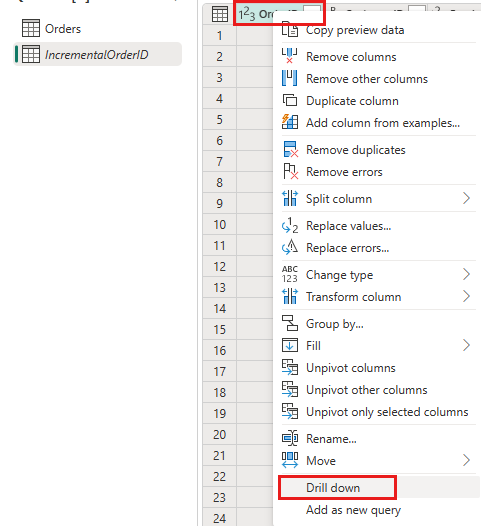
На ленте выберите Средства списка -> ->.
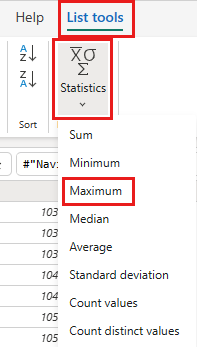
Теперь у вас есть запрос, который возвращает максимальный идентификатор OrderID в lakehouse. Этот запрос используется для фильтрации данных из источника OData. В следующем разделе добавляется запрос к потоку данных для фильтрации данных из источника OData на основе максимального значения OrderID в lakehouse.
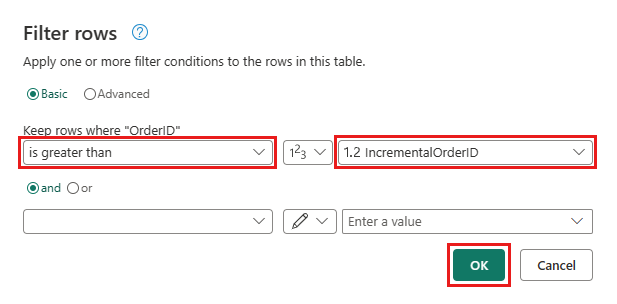
Вернитесь к запросу "Заказы" и добавьте новый шаг для фильтрации данных. Используйте следующие параметры:
- Столбец:
OrderID - Операция:
Greater than - Значение: параметр
IncrementalOrderID

- Столбец:
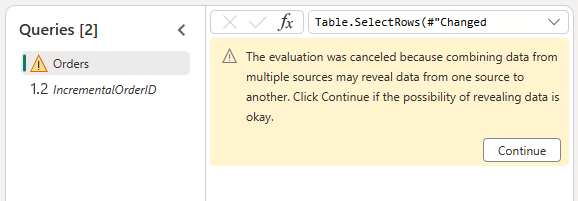
Разрешить объединение данных из источника OData и lakehouse, подтвердив следующее диалоговое окно:
Обновите назначение данных, чтобы использовать следующие параметры:
- Метод Update:
Append

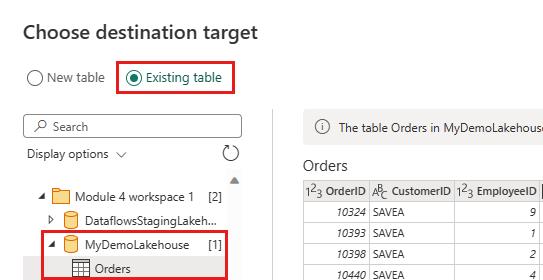
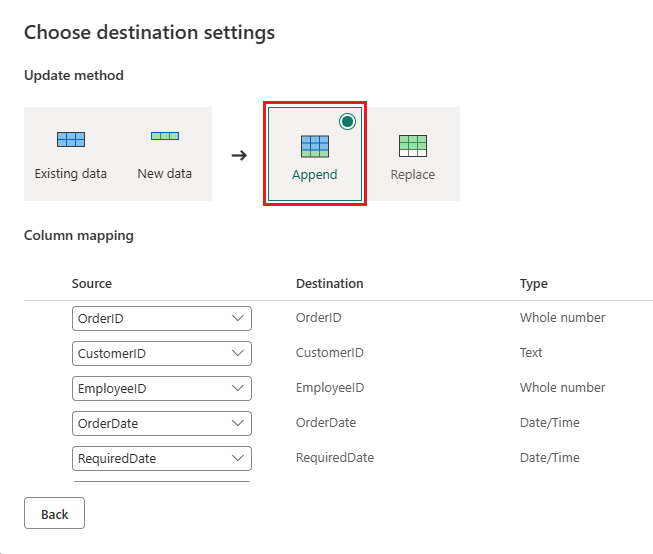
- Метод Update:
Опубликуйте поток данных.
Поток данных теперь содержит запрос, который фильтрует данные из источника OData на основе максимального значения OrderID в lakehouse. Это означает, что в lakehouse загружаются только новые или обновленные данные. Следующий раздел использует поток данных для перезагрузки данных с помощью ноутбуков и конвейеров.
(Необязательно) перезагрузить данные с помощью ноутбуков и конвейеров
При необходимости можно перезагрузить определенные данные с помощью записных книжек и конвейеров. С помощью пользовательского кода на Python в записной книжке вы удаляете старые данные из системы хранения данных lakehouse. Затем, создав конвейерную систему, в которой вы сначала запускаете записную книжку, а затем последовательно выполняете поток данных, вы перезагружаете данные из источника OData в lakehouse. Блокноты поддерживают несколько языков, однако в данном руководстве используется PySpark. Pyspark — это API Python для Spark и используется в этом руководстве для запуска запросов Spark SQL.
Создайте записную книжку в рабочей области.
Добавьте следующий код PySpark в записную книжку:
### Variables LakehouseName = "YOURLAKEHOUSE" TableName = "Orders" ColName = "OrderID" NumberOfOrdersToRemove = "10" ### Remove Old Orders Reload = spark.sql("SELECT Max({0})-{1} as ReLoadValue FROM {2}.{3}".format(ColName,NumberOfOrdersToRemove,LakehouseName,TableName)).collect() Reload = Reload[0].ReLoadValue spark.sql("Delete from {0}.{1} where {2} > {3}".format(LakehouseName, TableName, ColName, Reload))Запустите записную книжку, чтобы убедиться, что данные удалены из lakehouse.
Создайте конвейер в рабочей области.
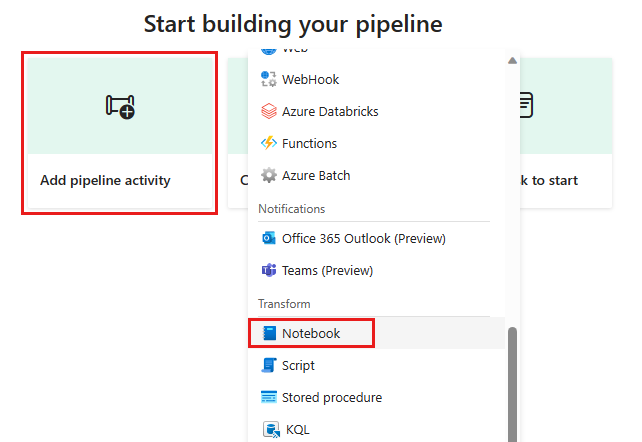
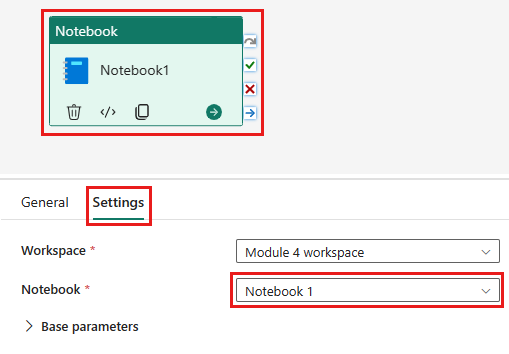
Добавьте новое действие блокнота в поток обработки и выберите блокнот, созданный на предыдущем шаге.
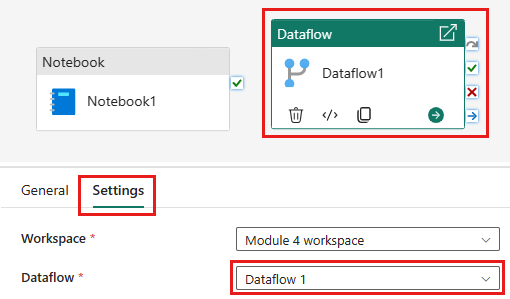
Добавьте новое действие потока данных в конвейер и выберите поток данных, созданный в предыдущем разделе.
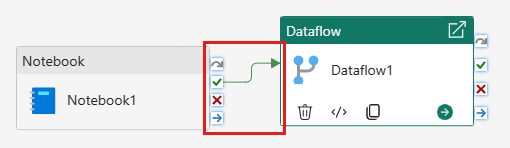
Соедините действие записной книжки с действием потока данных с триггером успешного завершения.
Сохраните и запустите конвейер.


Теперь у вас есть конвейер, который удаляет старые данные из лейкхауса и перезагружает данные из источника OData обратно в лейкхаус. С помощью этой конфигурации можно регулярно загружать данные из источника OData в lakehouse.