Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этом рецепте показано, как использовать службы SynapseML и Azure AI в Apache Spark для многовариантного обнаружения аномалий. Многовариантное обнаружение аномалий позволяет обнаруживать аномалии среди многих переменных или временных рядов, учитывая все межконференции и зависимости между разными переменными. В этом сценарии мы используем SynapseML для обучения модели для многовариантного обнаружения аномалий с помощью служб ИИ Azure, а затем мы используем для вывода многовариантных аномалий в наборе данных, содержащего искусственные измерения из трех датчиков Интернета вещей.
Внимание
Начиная с 20 сентября 2023 г. вы не сможете создавать новые Детектор аномалий ресурсы. Служба Детектор аномалий отменяется 1 октября 2026 года.
Дополнительные сведения о Детектор аномалий ИИ Azure см. на этой странице документации.
Необходимые компоненты
- подписка Azure — создайте бесплатную учетную запись.
- Подключите записную книжку к lakehouse. В левой части нажмите кнопку "Добавить ", чтобы добавить существующее озеро или создать озеро.
Настройка
Следуйте инструкциям по созданию Anomaly Detector ресурса с помощью портал Azure или альтернативной версии, вы также можете использовать Azure CLI для создания этого ресурса.
После настройки Anomaly Detectorможно изучить методы обработки данных различных форм. Каталог служб в Azure AI предоставляет несколько вариантов: Визуальное распознавание, речь, язык, веб-поиск, решение, перевод и аналитика документов.
Создание ресурса Детектора аномалий
- В портал Azure выберите "Создать" в группе ресурсов и введите Детектор аномалий. Выберите ресурс Детектор аномалий.
- Присвойте ресурсу имя и в идеале используйте тот же регион, что и остальная часть группы ресурсов. Используйте параметры по умолчанию для остальных, а затем нажмите кнопку "Просмотр и создание".
- После создания Детектор аномалий ресурса откройте его и выберите
Keys and Endpointsпанель в левой навигации. Скопируйте ключ для ресурса Детектор аномалий вANOMALY_API_KEYпеременную среды или сохраните его в переменнойanomalyKey.
Создание ресурса учетной записи хранения
Чтобы сохранить промежуточные данные, необходимо создать учетную запись Хранилище BLOB-объектов Azure. В этой учетной записи хранения создайте контейнер для хранения промежуточных данных. Запишите имя контейнера и скопируйте строка подключения в этот контейнер. Для заполнения переменной containerName и переменной BLOB_CONNECTION_STRING среды потребуется позже.
Введите ключи службы
Начнем с настройки переменных среды для ключей службы. Следующая ячейка задает ANOMALY_API_KEY переменные среды и BLOB_CONNECTION_STRING переменные среды на основе значений, хранящихся в azure Key Vault. Если вы используете это руководство в собственной среде, перед продолжением установите эти переменные среды.
import os
from pyspark.sql import SparkSession
from synapse.ml.core.platform import find_secret
# Bootstrap Spark Session
spark = SparkSession.builder.getOrCreate()
Теперь позволяет считывать ANOMALY_API_KEY переменные среды и BLOB_CONNECTION_STRING задавать containerName переменные и location переменные.
# An Anomaly Dectector subscription key
anomalyKey = find_secret("anomaly-api-key") # use your own anomaly api key
# Your storage account name
storageName = "anomalydetectiontest" # use your own storage account name
# A connection string to your blob storage account
storageKey = find_secret("madtest-storage-key") # use your own storage key
# A place to save intermediate MVAD results
intermediateSaveDir = (
"wasbs://madtest@anomalydetectiontest.blob.core.windows.net/intermediateData"
)
# The location of the anomaly detector resource that you created
location = "westus2"
Сначала мы подключимся к нашей учетной записи хранения, чтобы детектор аномалий смог сохранить промежуточные результаты там:
spark.sparkContext._jsc.hadoopConfiguration().set(
f"fs.azure.account.key.{storageName}.blob.core.windows.net", storageKey
)
Давайте импортируем все необходимые модули.
import numpy as np
import pandas as pd
import pyspark
from pyspark.sql.functions import col
from pyspark.sql.functions import lit
from pyspark.sql.types import DoubleType
import matplotlib.pyplot as plt
import synapse.ml
from synapse.ml.cognitive import *
Теперь давайте считываем примеры данных в кадр данных Spark.
df = (
spark.read.format("csv")
.option("header", "true")
.load("wasbs://publicwasb@mmlspark.blob.core.windows.net/MVAD/sample.csv")
)
df = (
df.withColumn("sensor_1", col("sensor_1").cast(DoubleType()))
.withColumn("sensor_2", col("sensor_2").cast(DoubleType()))
.withColumn("sensor_3", col("sensor_3").cast(DoubleType()))
)
# Let's inspect the dataframe:
df.show(5)
Теперь мы можем создать estimator объект, который используется для обучения модели. Мы указываем время начала и окончания для обучающих данных. Кроме того, мы указываем используемые входные столбцы и имя столбца, содержащего метки времени. Наконец, мы указываем количество точек данных, используемых в скользящем окне обнаружения аномалий, и мы зададим строка подключения для учетной записи Хранилище BLOB-объектов Azure.
trainingStartTime = "2020-06-01T12:00:00Z"
trainingEndTime = "2020-07-02T17:55:00Z"
timestampColumn = "timestamp"
inputColumns = ["sensor_1", "sensor_2", "sensor_3"]
estimator = (
FitMultivariateAnomaly()
.setSubscriptionKey(anomalyKey)
.setLocation(location)
.setStartTime(trainingStartTime)
.setEndTime(trainingEndTime)
.setIntermediateSaveDir(intermediateSaveDir)
.setTimestampCol(timestampColumn)
.setInputCols(inputColumns)
.setSlidingWindow(200)
)
Теперь, когда мы создали объект estimator, давайте поместим его в данные:
model = estimator.fit(df)
```parameter
Once the training is done, we can now use the model for inference. The code in the next cell specifies the start and end times for the data we would like to detect the anomalies in.
```python
inferenceStartTime = "2020-07-02T18:00:00Z"
inferenceEndTime = "2020-07-06T05:15:00Z"
result = (
model.setStartTime(inferenceStartTime)
.setEndTime(inferenceEndTime)
.setOutputCol("results")
.setErrorCol("errors")
.setInputCols(inputColumns)
.setTimestampCol(timestampColumn)
.transform(df)
)
result.show(5)
При вызове .show(5) в предыдущей ячейке она показала нам первые пять строк в кадре данных. Результаты были все null потому, что они не находились в окне вывода.
Чтобы отобразить результаты только для выводимых данных, можно выбрать нужные столбцы. Затем можно упорядочить строки в кадре данных по возрастанию и отфильтровать результат, чтобы отобразить только строки, которые находятся в диапазоне окна вывода. В нашем случае inferenceEndTime это то же самое, что и последняя строка в кадре данных, поэтому это может игнорироваться.
Наконец, чтобы лучше отобразить результаты, можно преобразовать кадр данных Spark в кадр данных Pandas.
rdf = (
result.select(
"timestamp",
*inputColumns,
"results.contributors",
"results.isAnomaly",
"results.severity"
)
.orderBy("timestamp", ascending=True)
.filter(col("timestamp") >= lit(inferenceStartTime))
.toPandas()
)
rdf
contributors Отформатируйте столбец, который хранит оценку вклада от каждого датчика до обнаруженных аномалий. Следующая ячейка форматирует эти данные и разбивает оценку вклада каждого датчика на собственный столбец.
def parse(x):
if type(x) is list:
return dict([item[::-1] for item in x])
else:
return {"series_0": 0, "series_1": 0, "series_2": 0}
rdf["contributors"] = rdf["contributors"].apply(parse)
rdf = pd.concat(
[rdf.drop(["contributors"], axis=1), pd.json_normalize(rdf["contributors"])], axis=1
)
rdf
Отлично! Теперь у нас есть оценки вкладов датчиков 1, 2 и 3 в series_0series_1столбцах, соответственноseries_2.
Выполните следующую ячейку, чтобы отобразить результаты. Параметр minSeverity задает минимальную степень серьезности аномалий, которые необходимо провести.
minSeverity = 0.1
####### Main Figure #######
plt.figure(figsize=(23, 8))
plt.plot(
rdf["timestamp"],
rdf["sensor_1"],
color="tab:orange",
linestyle="solid",
linewidth=2,
label="sensor_1",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_2"],
color="tab:green",
linestyle="solid",
linewidth=2,
label="sensor_2",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_3"],
color="tab:blue",
linestyle="solid",
linewidth=2,
label="sensor_3",
)
plt.grid(axis="y")
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.legend()
anoms = list(rdf["severity"] >= minSeverity)
_, _, ymin, ymax = plt.axis()
plt.vlines(np.where(anoms), ymin=ymin, ymax=ymax, color="r", alpha=0.8)
plt.legend()
plt.title(
"A plot of the values from the three sensors with the detected anomalies highlighted in red."
)
plt.show()
####### Severity Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.plot(
rdf["timestamp"],
rdf["severity"],
color="black",
linestyle="solid",
linewidth=2,
label="Severity score",
)
plt.plot(
rdf["timestamp"],
[minSeverity] * len(rdf["severity"]),
color="red",
linestyle="dotted",
linewidth=1,
label="minSeverity",
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("Severity of the detected anomalies")
plt.show()
####### Contributors Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.bar(
rdf["timestamp"], rdf["series_0"], width=2, color="tab:orange", label="sensor_1"
)
plt.bar(
rdf["timestamp"],
rdf["series_1"],
width=2,
color="tab:green",
label="sensor_2",
bottom=rdf["series_0"],
)
plt.bar(
rdf["timestamp"],
rdf["series_2"],
width=2,
color="tab:blue",
label="sensor_3",
bottom=rdf["series_0"] + rdf["series_1"],
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("The contribution of each sensor to the detected anomaly")
plt.show()
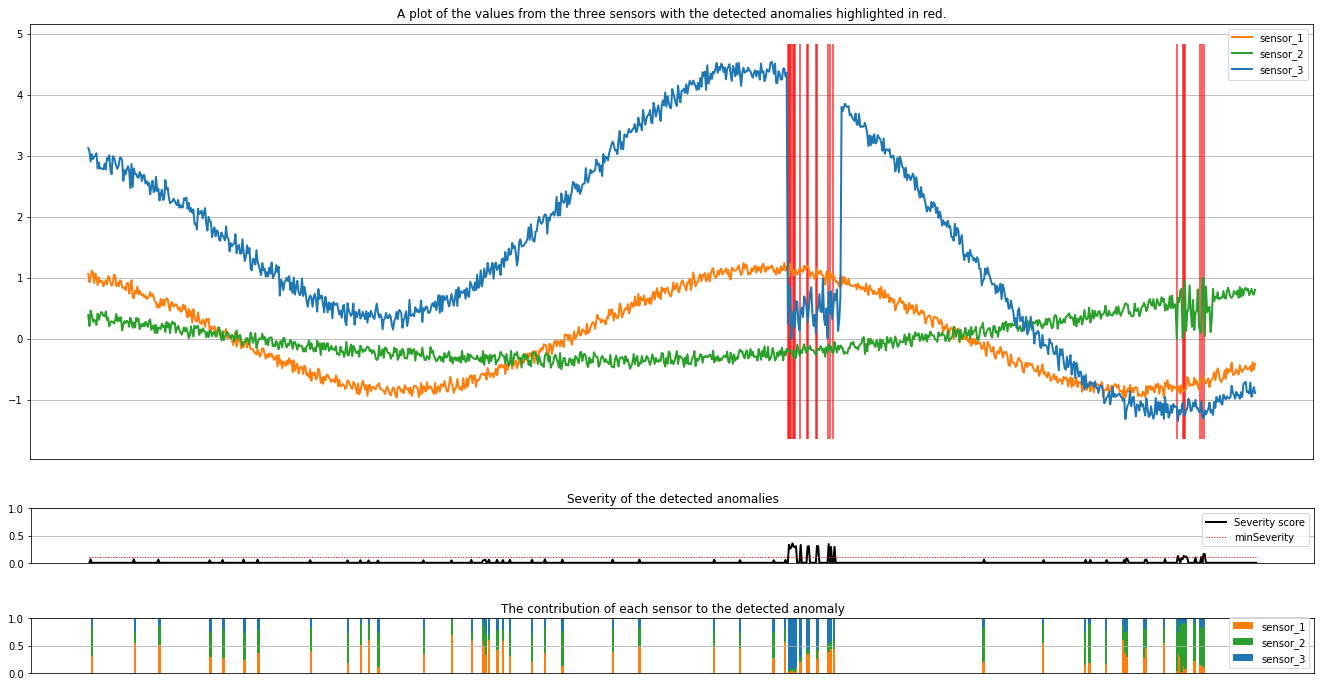
На графиках показаны необработанные данные датчиков (внутри окна вывода) в оранжевый, зеленый и синий. Красные вертикальные линии на первом рисунке показывают обнаруженные аномалии, которые имеют степень серьезности больше или равно minSeverity.
Второй график показывает оценку серьезности всех обнаруженных аномалий с minSeverity пороговым значением, показанным в пунктирной красной линии.
Наконец, последний график показывает вклад данных каждого датчика в обнаруженные аномалии. Это помогает нам диагностировать и понимать наиболее вероятные причины каждой аномалии.