Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этом руководстве представлен полный пример рабочего процесса Обработки и анализа данных Synapse в Microsoft Fabric. Он использует как ресурс данных nycflights13 , так и R, чтобы предсказать, прибывает ли самолет более 30 минут поздно. Затем он использует результаты прогнозирования для создания интерактивной панели мониторинга Power BI.
В этом руководстве описано, как:
Использование пакетов tidymodels
обработка данных и обучение модели машинного обучения
Запишите выходные данные в лейкхаус в виде delta-таблицы
Создайте визуальный отчет Power BI для прямого доступа к данным в данном хранилище данных (lakehouse)
Необходимые условия
Получите подписку Microsoft Fabric. Или подпишитесь на бесплатную пробную версию Microsoft Fabric.
Войдите в Microsoft Fabric.
Используйте переключатель интерфейса в левой нижней части домашней страницы, чтобы перейти на Fabric.

Откройте или создайте записную книжку. Дополнительные сведения см. в статье Использование записных книжек Microsoft Fabric.
Установите параметр языка на SparkR (R), чтобы изменить основной язык.
Подключите ваш ноутбук к lakehouse. В левой части выберите Добавить, чтобы добавить существующий лейкхаус или создать новый.
Установка пакетов
Установите пакет nycflights13, чтобы использовать код в этом руководстве.
install.packages("nycflights13")
# Load the packages
library(tidymodels) # For tidymodels packages
library(nycflights13) # For flight data
Изучение данных
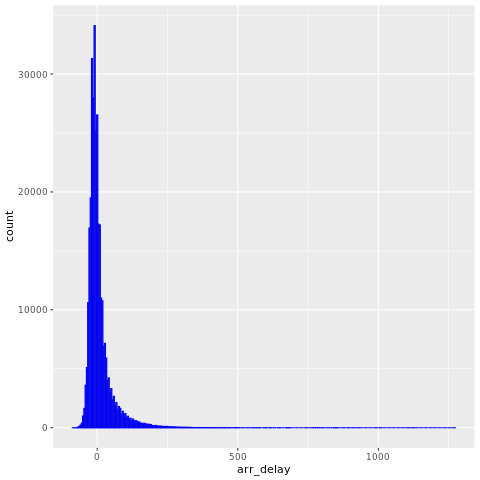
Данные nycflights13 содержат сведения о 325 819 рейсах, которые прибыли недалеко от Нью-йорка в 2013 году. Во-первых, изучите распределение задержек рейсов. Следующая ячейка кода создает график, показывающий, что распределение задержки прибытия смещено вправо.
ggplot(flights, aes(arr_delay)) + geom_histogram(color="blue", bins = 300)
У него длинный хвост в области высоких значений, как показано на следующем рисунке:
Загрузите данные и внесите несколько изменений в переменные:
set.seed(123)
flight_data <-
flights %>%
mutate(
# Convert the arrival delay to a factor
arr_delay = ifelse(arr_delay >= 30, "late", "on_time"),
arr_delay = factor(arr_delay),
# You'll use the date (not date-time) for the recipe that you'll create
date = lubridate::as_date(time_hour)
) %>%
# Include weather data
inner_join(weather, by = c("origin", "time_hour")) %>%
# Retain only the specific columns that you'll use
select(dep_time, flight, origin, dest, air_time, distance,
carrier, date, arr_delay, time_hour) %>%
# Exclude missing data
na.omit() %>%
# For creating models, it's better to have qualitative columns
# encoded as factors (instead of character strings)
mutate_if(is.character, as.factor)
Прежде чем создавать модель, рассмотрите несколько определенных переменных, которые имеют важность как для предварительной обработки, так и для моделирования.
Переменная arr_delay является переменной фактора. Для обучения модели логистической регрессии важно, чтобы переменная результата была переменной фактора.
glimpse(flight_data)
Около 16% рейсов из этого набора данных прибыли с опозданием более чем на 30 минут.
flight_data %>%
count(arr_delay) %>%
mutate(prop = n/sum(n))
Эта dest функция имеет 104 направления полета:
unique(flight_data$dest)
Существует 16 различных перевозчиков:
unique(flight_data$carrier)
Разделение данных
Разделить один набор данных на два набора: набор обучения и набор тестирования. Храните большую часть строк в исходном наборе данных (как случайно выбранное подмножество) в наборе обучающих данных. Используйте набор данных обучения для соответствия модели и используйте тестовый набор данных для измерения производительности модели.
Используйте пакет rsample для создания объекта, содержащего сведения о том, как разделить данные. Затем используйте еще две функции rsample для создания DataFrame для наборов обучения и тестирования.
set.seed(123)
# Keep most of the data in the training set
data_split <- initial_split(flight_data, prop = 0.75)
# Create DataFrames for the two sets:
train_data <- training(data_split)
test_data <- testing(data_split)
Создайте рецепт и роли
Создайте рецепт для простой модели логистической регрессии. Перед обучением модели используйте рецепт для создания новых прогнозаторов и провести предварительную обработку, которую требует модель.
Используйте функцию update_role() с пользовательской ролью с именем ID, чтобы рецепты знали, что flight и time_hour являются переменными. Роль может иметь любое символьное значение. Формула включает все переменные из обучающего набора в качестве предикторов, за исключением arr_delay. Рецепт сохраняет эти две переменные идентификатора, но не использует их в качестве результатов или прогнозаторов:
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID")
Чтобы просмотреть текущий набор переменных и ролей, используйте функцию summary():
summary(flights_rec)
Создание функций
Проектирование функций может улучшить модель. Дата полета может оказать разумное влияние на вероятность позднего прибытия:
flight_data %>%
distinct(date) %>%
mutate(numeric_date = as.numeric(date))
Это может помочь добавить модельные термины, полученные из даты, которые могут иметь потенциальное значение для модели. Выведем следующие значимые признаки из одной переменной даты:
- День недели
- Месяц
- Независимо от того, соответствует ли дата празднику
Добавьте три шага в рецепт:
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID") %>%
step_date(date, features = c("dow", "month")) %>%
step_holiday(date,
holidays = timeDate::listHolidays("US"),
keep_original_cols = FALSE) %>%
step_dummy(all_nominal_predictors()) %>%
step_zv(all_predictors())
Настроить модель, используя рецепт
Используйте логистическую регрессию для моделирования данных полета. Сначала создайте спецификацию модели с помощью пакета parsnip:
lr_mod <-
logistic_reg() %>%
set_engine("glm")
Используйте пакет workflows для объединения модели parsnip (lr_mod) с рецептом (flights_rec):
flights_wflow <-
workflow() %>%
add_model(lr_mod) %>%
add_recipe(flights_rec)
flights_wflow
Обучение модели
Эта функция может подготовить рецепт и обучить модель из полученных предикторов.
flights_fit <-
flights_wflow %>%
fit(data = train_data)
Используйте вспомогательные функции xtract_fit_parsnip() и extract_recipe() для извлечения объектов модели или рецептов из рабочего процесса. В этом примере извлеките объект устроенной модели, затем используйте функцию broom::tidy(), чтобы получить упорядоченный список коэффициентов модели в формате tibble.
flights_fit %>%
extract_fit_parsnip() %>%
tidy()
Прогнозирование результатов
Один вызов predict() использует обученный рабочий процесс (flights_fit) для прогнозирования с помощью невидимых тестовых данных. Метод predict() применяет рецепт к новым данным, а затем передает результаты в соответствующую модель.
predict(flights_fit, test_data)
Получите выходные данные из predict() для возврата прогнозируемого класса: late и on_time. Однако для прогнозируемых вероятностей класса для каждого полета используйте augment() вместе с моделью и тестовыми данными, чтобы сохранить их вместе.
flights_aug <-
augment(flights_fit, test_data)
Просмотрите данные:
glimpse(flights_aug)
Оценка модели
Теперь у нас есть таблица с вероятностями прогнозируемых классов. В первых нескольких строках модель правильно предсказала пять рейсов без задержек (значения .pred_on_time равны p > 0.50). Однако нам нужны прогнозы для общей сложности 81 455 строк.
Нам нужна метрика, которая указывает, насколько хорошо модель прогнозировала поздние поступления, по сравнению с истинным состоянием переменной arr_delay результата.
Используйте область под операционной характеристикой приемника кривой (AUC-ROC) в качестве метрики. Вычислить его с помощью roc_curve() и roc_auc()из пакета yardstick:
flights_aug %>%
roc_curve(truth = arr_delay, .pred_late) %>%
autoplot()
Создание отчета Power BI
Результат модели выглядит хорошо. Используйте результаты прогнозирования задержки полета для создания интерактивной панели мониторинга Power BI. На панели мониторинга отображается количество рейсов по перевозчику и количество рейсов по назначению. Панель мониторинга может фильтроваться по результатам прогнозирования задержки.

Включите имя оператора и имя аэропорта в набор данных результатов прогнозирования:
flights_clean <- flights_aug %>%
# Include the airline data
left_join(airlines, c("carrier"="carrier"))%>%
rename("carrier_name"="name") %>%
# Include the airport data for origin
left_join(airports, c("origin"="faa")) %>%
rename("origin_name"="name") %>%
# Include the airport data for destination
left_join(airports, c("dest"="faa")) %>%
rename("dest_name"="name") %>%
# Retain only the specific columns you'll use
select(flight, origin, origin_name, dest,dest_name, air_time,distance, carrier, carrier_name, date, arr_delay, time_hour, .pred_class, .pred_late, .pred_on_time)
Просмотрите данные:
glimpse(flights_clean)
Переведите данные в DataFrame Spark.
sparkdf <- as.DataFrame(flights_clean)
display(sparkdf)
Запишите данные в delta-таблицу в вашем lakehouse.
# Write data into a delta table
temp_delta<-"Tables/nycflight13"
write.df(sparkdf, temp_delta ,source="delta", mode = "overwrite", header = "true")
Используйте разностную таблицу для создания семантической модели.
В левой области навигации выберите вашу рабочую область, а в правом верхнем текстовом поле введите имя lakehouse, который вы связали с вашей записной книжкой. На следующем снимку экрана показано, что выбрана моя рабочая область:
Введите название «lakehouse», который вы подключили к своей записной книжке. Введите test_lakehouse1, как показано на следующем снимке экрана:
В области отфильтрованных результатов выберите "lakehouse", как показано на следующем снимке экрана.
Выберите новую семантику модели , как показано на следующем снимке экрана:
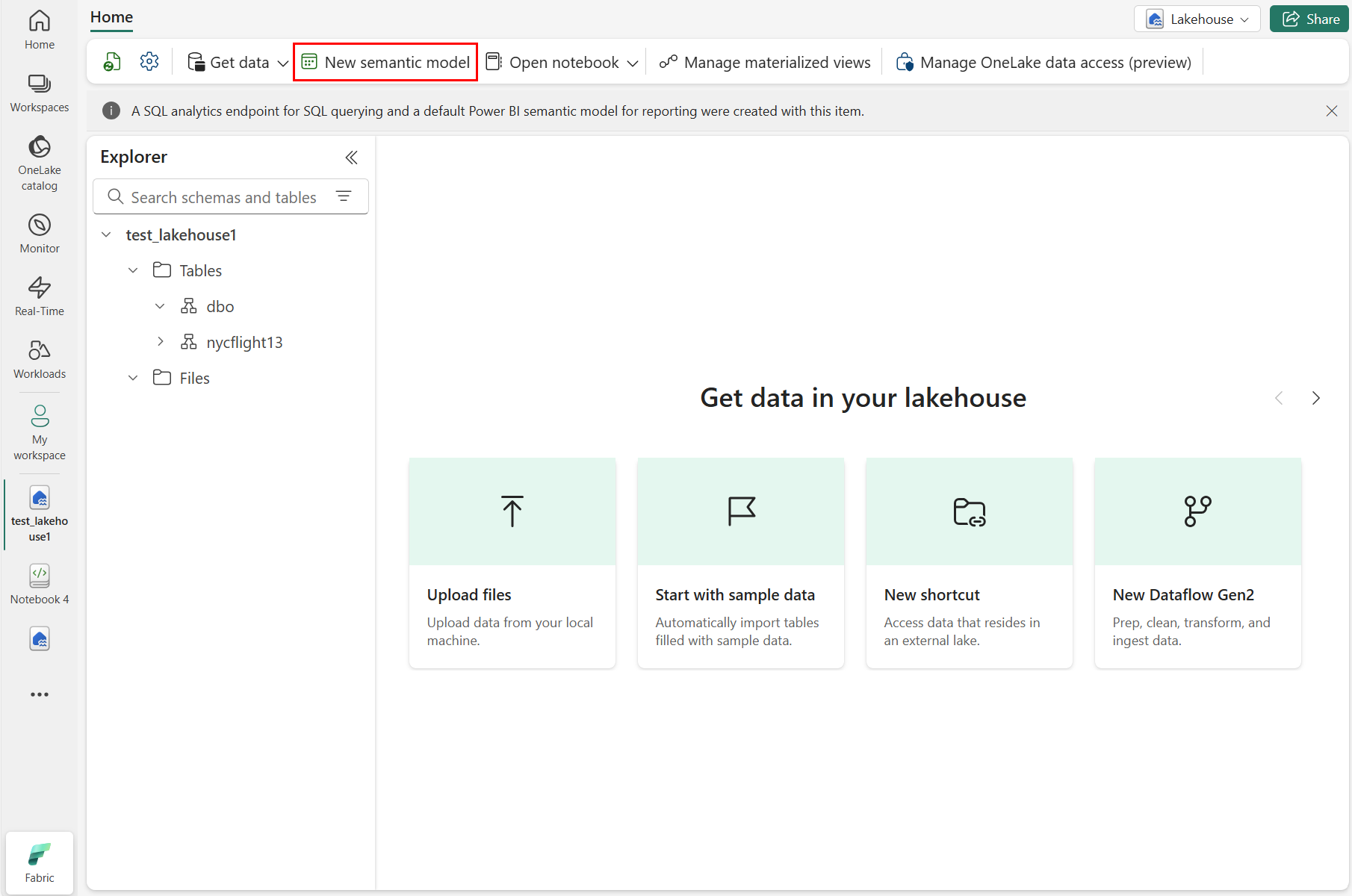
В области "Новая семантическая модель" введите имя новой семантической модели, выберите рабочую область и выберите таблицы, используемые для этой новой модели, а затем нажмите кнопку "Подтвердить", как показано на следующем снимке экрана:
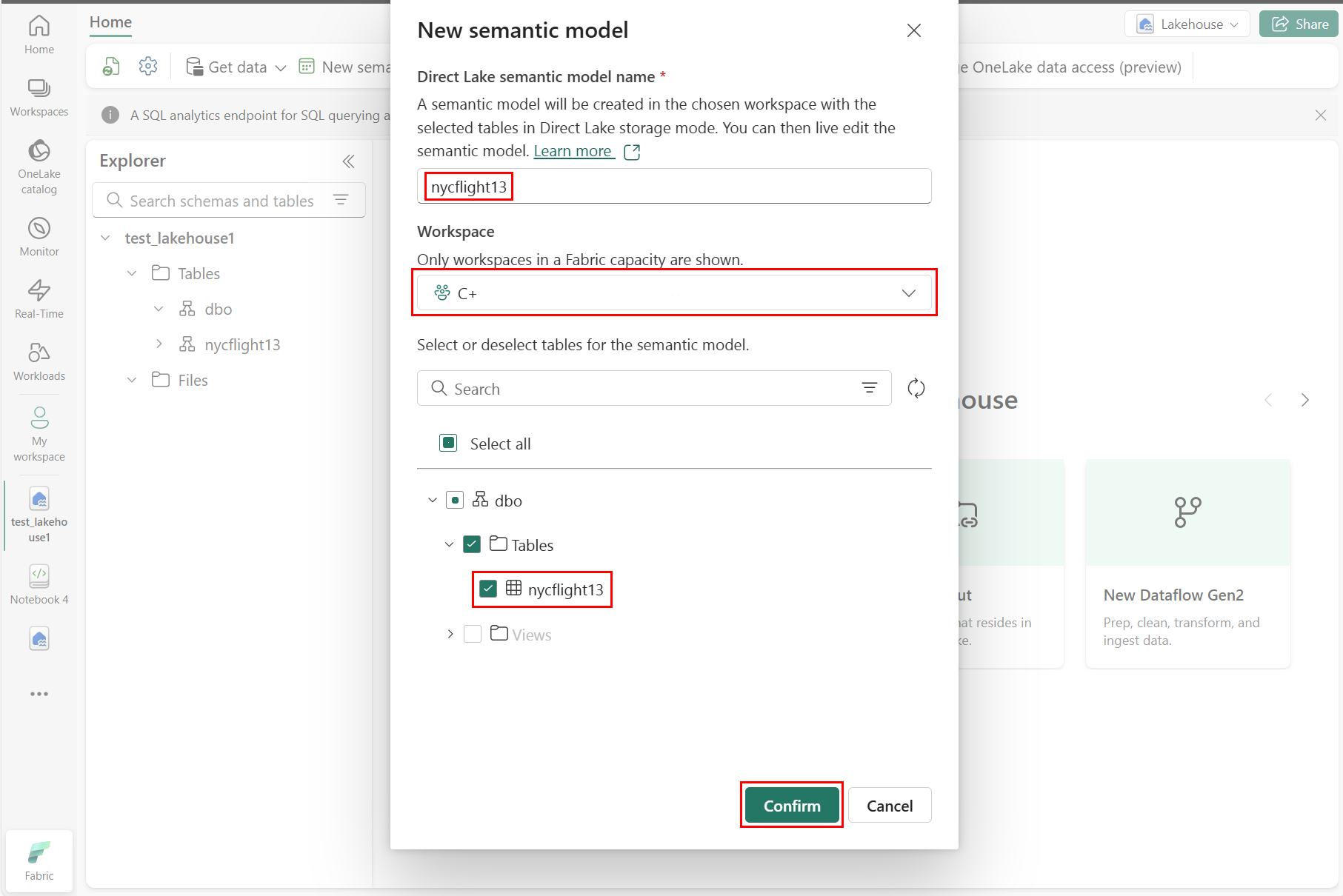
Чтобы создать отчет, выберите "Создать отчет", как показано на следующем снимке экрана:
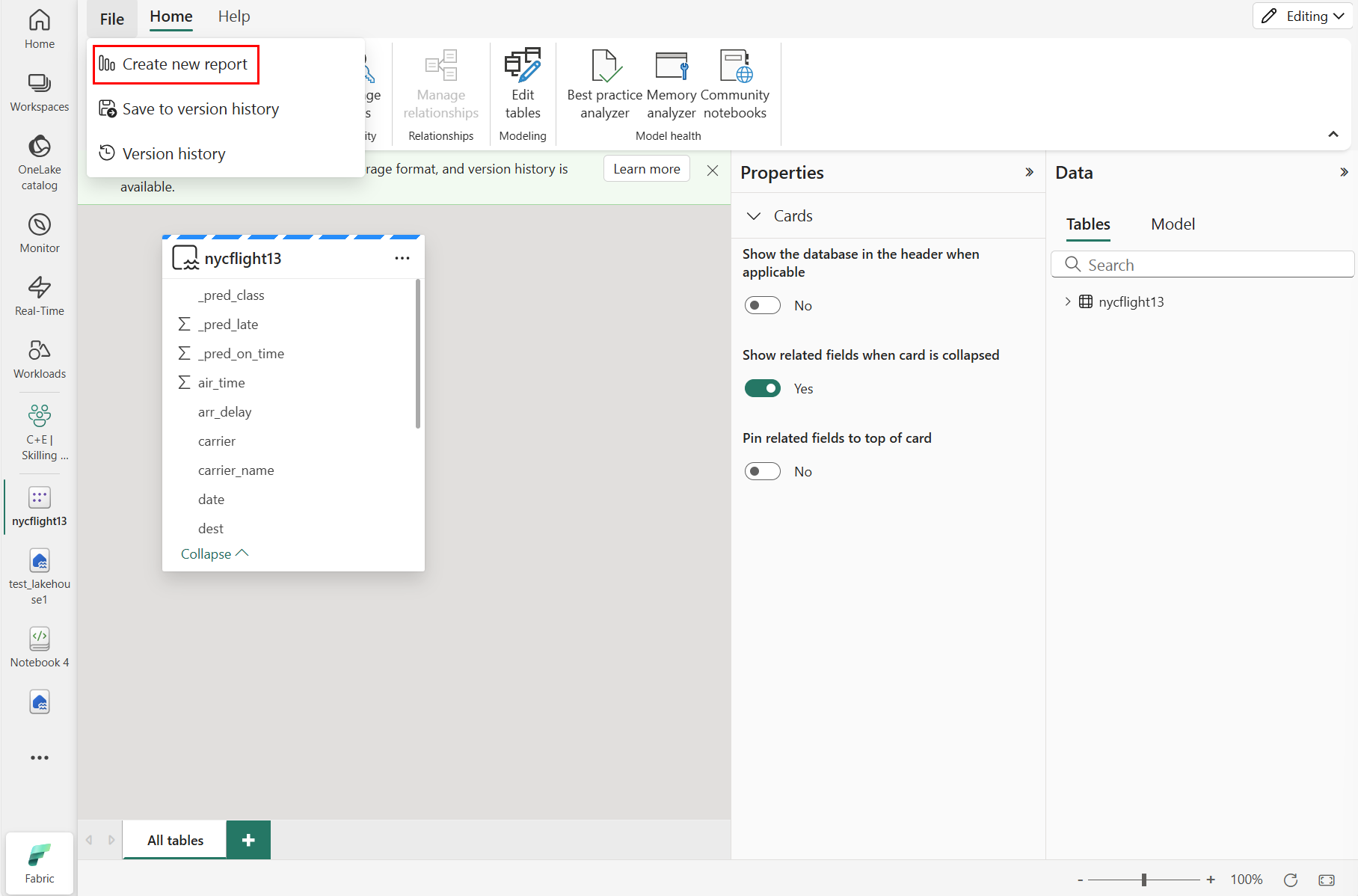
Выберите или перетащите поля из области данных и области визуализаций на холст, чтобы создать отчет.
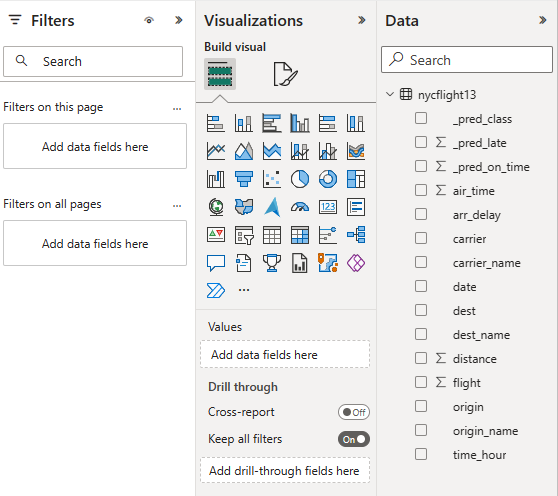






Чтобы создать отчет, показанный в начале этого раздела, используйте следующие визуализации и данные:
-
 накопленная столбчатая диаграмма:
накопленная столбчатая диаграмма: - Ось Y: carrier_name
- Ось X: полет . Выберите , для агрегирования.
- Легенда: origin_name
-
накопленная столбчатая диаграмма:
- Ось Y: dest_name
- Ось X: полет . Выберите , для агрегирования.
- Легенда: origin_name
- срез
 с помощью:
с помощью: - Поле: _pred_class
- срез с помощью:
- Поле: _pred_late