Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этом руководстве представлен полный пример рабочего процесса Обработки и анализа данных Synapse в Microsoft Fabric. В этом сценарии мы создадим модель обнаружения мошенничества в R с алгоритмами машинного обучения, обученными на исторических данных. Затем мы используем модель для обнаружения будущих мошеннических транзакций.
В этом руководстве рассматриваются следующие действия.
- Установка пользовательских библиотек
- Загрузка данных
- Понять и обработать данные с помощью исследовательского анализа данных и показать использование функции Wrangler для данных Fabric.
- Обучение моделей машинного обучения с помощью LightGBM
- Использование моделей машинного обучения для оценки и прогнозирования
Необходимые условия
Получите подписку Microsoft Fabric. Или зарегистрируйтесь на бесплатную пробную версию Microsoft Fabric.
Войдите в Microsoft Fabric.
Используйте переключатель интерфейса в левой нижней части домашней страницы, чтобы перейти на Fabric.

- При необходимости создайте озеро Microsoft Fabric, как описано в разделе Создание озера в Microsoft Fabric.
Следуйте инструкциям в записной книжке
Вы можете выбрать один из следующих вариантов для выполнения в записной книжке:
- Откройте и запустите встроенную записную книжку в интерфейсе Обработки и анализа данных Synapse
- Отправка записной книжки из GitHub в интерфейс Обработки и анализа данных Synapse
Открытие встроенной записной книжки
Образец блокнота для обнаружения мошенничества сопровождает это руководство.
Чтобы открыть пример записной книжки для этого руководства, следуйте инструкциям в Подготовке системы для учебников по обработке и анализу данных.
Перед началом выполнения кода обязательно подключить lakehouse к записной книжке.
Импорт записной книжки из GitHub
Этот учебник сопровождается блокнотом AIsample - R Fraud Detection.ipynb.
Чтобы открыть сопровождающую записную книжку к этому руководству, следуйте инструкциям в разделе Подготовьте вашу систему для учебных пособий по науке о данных для импорта записной книжки в ваше рабочее пространство.
Если вы хотите скопировать и вставить код на этой странице, можно создать новую записную книжку.
Не забудьте подключить lakehouse к блокноту перед началом выполнения кода.
Шаг 1. Установка пользовательских библиотек
Для разработки моделей машинного обучения или нерегламентированного анализа данных может потребоваться быстро установить пользовательскую библиотеку для сеанса Apache Spark. Существует два варианта установки библиотек.
- Используйте встроенные ресурсы установки, например
install.packagesиdevtools::install_version, для установки только в текущем ноутбуке. - Кроме того, можно создать среду Fabric, установить библиотеки из общедоступных источников или отправить в нее пользовательские библиотеки, а затем администратор рабочей области может присоединить среду в качестве значения по умолчанию для рабочей области. Все библиотеки в среде будут доступны для использования в любых записных книжках и определениях заданий Spark в рабочей области. Дополнительные сведения о средах см. в разделе создание, настройка и использование среды в Microsoft Fabric.
В этом руководстве используйте install.version() для установки библиотеки несбалансированного обучения:
# Install dependencies
devtools::install_version("bnlearn", version = "4.8")
# Install imbalance for SMOTE
devtools::install_version("imbalance", version = "1.0.2.1")
Шаг 2. Загрузка данных
Набор данных обнаружения мошенничества содержит транзакции кредитной карты с сентября 2013 года, что европейские держатели карт сделали в течение двух дней. Набор данных содержит только числовые функции из-за преобразования основного анализа компонентов (PCA), примененного к исходным функциям. PCA преобразовал все функции, кроме Time и Amount. Чтобы защитить конфиденциальность, мы не можем предоставить исходные функции или дополнительные фоновые сведения о наборе данных.
Эти сведения описывают набор данных:
- Функции
V1,V2,V3, ...,V28являются основными компонентами, полученными с помощью PCA - Функция
Timeсодержит прошедшие секунды между транзакцией и первой транзакцией в наборе данных. - Функция
Amount— это сумма транзакции. Эту функцию можно использовать для обучения, зависящего от примеров и затрат. - Столбец
Class— это ответная (целевая) переменная. Оно имеет значение1для мошенничества и0в противном случае
Только 492 транзакции, из 284 807 транзакций, являются мошенническими. Набор данных сильно несбалансирован, так как класс меньшинства (мошеннический) учитывает только около 0,172% данных.
В этой таблице показана предварительная версия данных creditcard.csv:
| Время | Версия 1 | Версия 2 | Версия 3 | V4 | V5 | V6 | V7 | V8 | V9 | V10 | Версия 11 | V12 | V13 | V14 | V15 | V16 | V17 | V18 | V19 | Версия 20 | В21 | Версия 22 | Версия 23 | Версия 24 | V25 | V26 | V27 | V28 | Количество | Класс |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -1.3598071336738 | -0.0727811733098497 | 2.53634673796914 | 1.37815522427443 | -0.338320769942518 | 0.462387777762292 | 0.239598554061257 | 0.0986979012610507 | 0.363786969611213 | 0.0907941719789316 | -0.551599533260813 | -0.617800855762348 | -0.991389847235408 | -0.311169353699879 | 1.46817697209427 | -0.470400525259478 | 0.207971241929242 | 0.0257905801985591 | 0.403992960255733 | 0.251412098239705 | -0.018306777944153 | 0.277837575558899 | -0.110473910188767 | 0.0669280749146731 | 0.128539358273528 | -0.189114843888824 | 0.133558376740387 | -0.0210530534538215 | 149.62 | "0" |
| 0 | 1,19185711131486 | 0.26615071205963 | 0.16648011335321 | 0.448154078460911 | 0.0600176492822243 | -0.0823608088155687 | -0.0788029833323113 | 0.0851016549148104 | -0.255425128109186 | -0.166974414004614 | 1,61272666105479 | 1.06523531137287 | 0.48909501589608 | -0.143772296441519 | 0.635558093258208 | 0.463917041022171 | -0.114804663102346 | -0.183361270123994 | -0.145783041325259 | -0.0690831352230203 | -0.225775248033138 | -0.638671952771851 | 0.101288021253234 | -0.339846475529127 | 0.167170404418143 | 0.125894532368176 | -0.00898309914322813 | 0.0147241691924927 | 2.69 | "0" |
Скачайте набор данных и отправьте его в lakehouse
Определите эти параметры, чтобы использовать эту записную книжку с различными наборами данных:
IS_CUSTOM_DATA <- FALSE # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE <- FALSE # If TRUE, use only rows of data for training; otherwise, use all data
SAMPLE_ROWS <- 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT <- "/lakehouse/default"
DATA_FOLDER <- "Files/fraud-detection" # Folder with data files
DATA_FILE <- "creditcard.csv" # Data file name
Этот код загружает общедоступную версию набора данных, а затем сохраняет ее в Fabric Lakehouse.
Важный
Перед запуском записной книжки обязательно добавить lakehouse. В противном случае вы получите ошибку.
if (!IS_CUSTOM_DATA) {
# Download data files into a lakehouse if they don't exist
library(httr)
remote_url <- "https://synapseaisolutionsa.blob.core.windows.net/public/Credit_Card_Fraud_Detection"
fname <- "creditcard.csv"
download_path <- file.path(DATA_ROOT, DATA_FOLDER, "raw")
dir.create(download_path, showWarnings = FALSE, recursive = TRUE)
if (!file.exists(file.path(download_path, fname))) {
r <- GET(file.path(remote_url, fname), timeout(30))
writeBin(content(r, "raw"), file.path(download_path, fname))
}
message("Downloaded demo data files into lakehouse.")
}
Чтение необработанных данных даты из lakehouse
Этот код считывает необработанные данные из раздела "Files" в lakehouse:
data_df <- read.csv(file.path(DATA_ROOT, DATA_FOLDER, "raw", DATA_FILE))
Шаг 3. Выполнение анализа аналитических данных
Используйте команду display для просмотра высокоуровневой статистики набора данных:
display(as.DataFrame(data_df, numPartitions = 3L))
# Print dataset basic information
message(sprintf("records read: %d", nrow(data_df)))
message("Schema:")
str(data_df)
# If IS_SAMPLE is True, use only SAMPLE_ROWS of rows for training
if (IS_SAMPLE) {
data_df = sample_n(data_df, SAMPLE_ROWS)
}
Вывести распределение классов в наборе данных:
# The distribution of classes in the dataset
message(sprintf("No Frauds %.2f%% of the dataset\n", round(sum(data_df$Class == 0)/nrow(data_df) * 100, 2)))
message(sprintf("Frauds %.2f%% of the dataset\n", round(sum(data_df$Class == 1)/nrow(data_df) * 100, 2)))
Это распределение классов показывает, что большинство транзакций являются нефрудулентными. Таким образом, перед обучением модели требуется предварительная обработка данных, чтобы избежать избыточности.
Просмотр распределения мошеннических и нефрудулентных транзакций
Просмотрите распределение мошеннических и нефрудулентных транзакций с графиком, чтобы показать дисбаланс класса в наборе данных:
library(ggplot2)
ggplot(data_df, aes(x = factor(Class), fill = factor(Class))) +
geom_bar(stat = "count") +
scale_x_discrete(labels = c("no fraud", "fraud")) +
ggtitle("Class Distributions \n (0: No Fraud || 1: Fraud)") +
theme(plot.title = element_text(size = 10))
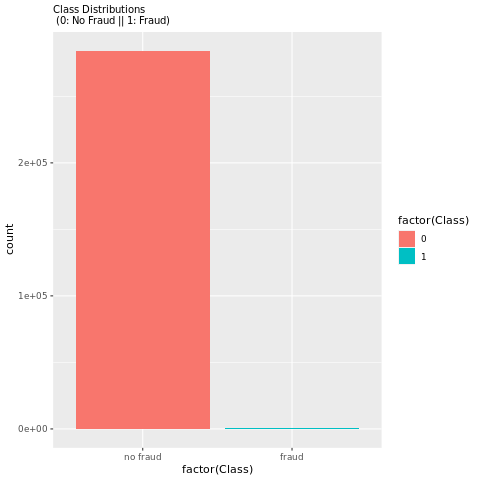
График четко показывает дисбаланс набора данных:
Покажите пятичисловую сводку
Отображение сводки с пятью числами (минимальная оценка, первая квартиль, медиана, третий квартиль и максимальная оценка) для суммы транзакции с графиками полей:
library(ggplot2)
library(dplyr)
ggplot(data_df, aes(x = as.factor(Class), y = Amount, fill = as.factor(Class))) +
geom_boxplot(outlier.shape = NA) +
scale_x_discrete(labels = c("no fraud", "fraud")) +
ggtitle("Boxplot without Outliers") +
coord_cartesian(ylim = quantile(data_df$Amount, c(0.05, 0.95)))
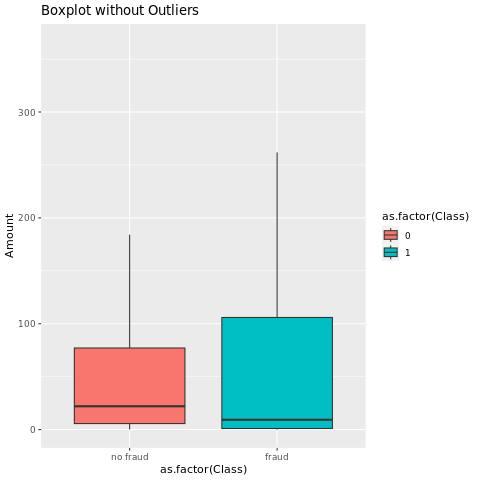
Для данных с высоким дисбалансом диаграммы полей могут не отображать точные аналитические сведения. Однако сначала можно решить проблему дисбаланса Class, а затем создать те же графики для более точной аналитики.
Шаг 4. Обучение и оценка моделей
Здесь вы обучаете модель LightGBM для классификации транзакций мошенничества. Вы обучаете модель LightGBM как на несбалансированном наборе данных, так и на сбалансированном наборе данных. Затем вы сравниваете производительность обеих моделей.
Подготовка обучающих и тестовых наборов данных
Перед обучением разделите данные на наборы данных для обучения и тестирования:
# Split the dataset into training and test datasets
set.seed(42)
train_sample_ids <- base::sample(seq_len(nrow(data_df)), size = floor(0.85 * nrow(data_df)))
train_df <- data_df[train_sample_ids, ]
test_df <- data_df[-train_sample_ids, ]
Примените SMOTE к обучающему набору данных
Несбалансированная классификация имеет проблему. В нем слишком мало примеров классов меньшинств для эффективного изучения границы принятия решений. Метод синтетического увеличения выборки меньшинств (SMOTE) может справиться с этой проблемой. SMOTE является наиболее широко используемым подходом для синтеза новых образцов для класса меньшинства. Доступ к SMOTE можно получить с помощью библиотеки imbalance, установленной на шаге 1.
Примените SMOTE только к набору обучающих данных вместо тестового набора данных. При оценке модели на тестовых данных необходимо получить представление о производительности модели на невидимых данных при промышленной эксплуатации. Для допустимого приближения тестовые данные используют исходное несбалансированное распределение, чтобы представить рабочие данные как можно ближе.
# Apply SMOTE to the training dataset
library(imbalance)
# Print the shape of the original (imbalanced) training dataset
train_y_categ <- train_df %>% select(Class) %>% table
message(
paste0(
"Original dataset shape ",
paste(names(train_y_categ), train_y_categ, sep = ": ", collapse = ", ")
)
)
# Resample the training dataset by using SMOTE
smote_train_df <- train_df %>%
mutate(Class = factor(Class)) %>%
oversample(ratio = 0.99, method = "SMOTE", classAttr = "Class") %>%
mutate(Class = as.integer(as.character(Class)))
# Print the shape of the resampled (balanced) training dataset
smote_train_y_categ <- smote_train_df %>% select(Class) %>% table
message(
paste0(
"Resampled dataset shape ",
paste(names(smote_train_y_categ), smote_train_y_categ, sep = ": ", collapse = ", ")
)
)
Дополнительные сведения о SMOTE см. в пакете "дисбаланс" и работе с несбалансированными наборами данных на веб-сайте CRAN.
Обучение модели с помощью LightGBM
Обучите модель LightGBM как несбалансированному набору данных, так и сбалансированному набору данных (через SMOTE). Затем сравните их производительность:
# Train LightGBM for both imbalanced and balanced datasets and define the evaluation metrics
library(lightgbm)
# Get the ID of the label column
label_col <- which(names(train_df) == "Class")
# Convert the test dataset for the model
test_mtx <- as.matrix(test_df)
test_x <- test_mtx[, -label_col]
test_y <- test_mtx[, label_col]
# Set up the parameters for training
params <- list(
objective = "binary",
learning_rate = 0.05,
first_metric_only = TRUE
)
# Train for the imbalanced dataset
message("Start training with imbalanced data:")
train_mtx <- as.matrix(train_df)
train_x <- train_mtx[, -label_col]
train_y <- train_mtx[, label_col]
train_data <- lgb.Dataset(train_x, label = train_y)
valid_data <- lgb.Dataset.create.valid(train_data, test_x, label = test_y)
model <- lgb.train(
data = train_data,
params = params,
eval = list("binary_logloss", "auc"),
valids = list(valid = valid_data),
nrounds = 300L
)
# Train for the balanced (via SMOTE) dataset
message("\n\nStart training with balanced data:")
smote_train_mtx <- as.matrix(smote_train_df)
smote_train_x <- smote_train_mtx[, -label_col]
smote_train_y <- smote_train_mtx[, label_col]
smote_train_data <- lgb.Dataset(smote_train_x, label = smote_train_y)
smote_valid_data <- lgb.Dataset.create.valid(smote_train_data, test_x, label = test_y)
smote_model <- lgb.train(
data = smote_train_data,
params = params,
eval = list("binary_logloss", "auc"),
valids = list(valid = smote_valid_data),
nrounds = 300L
)
Определение важности признаков
Определите важность признаков для модели, обученной в несбалансированном наборе данных:
imp <- lgb.importance(model, percentage = TRUE)
ggplot(imp, aes(x = Frequency, y = reorder(Feature, Frequency), fill = Frequency)) +
scale_fill_gradient(low="steelblue", high="tomato") +
geom_bar(stat = "identity") +
geom_text(aes(label = sprintf("%.4f", Frequency)), hjust = -0.1) +
theme(axis.text.x = element_text(angle = 90)) +
xlim(0, max(imp$Frequency) * 1.1)
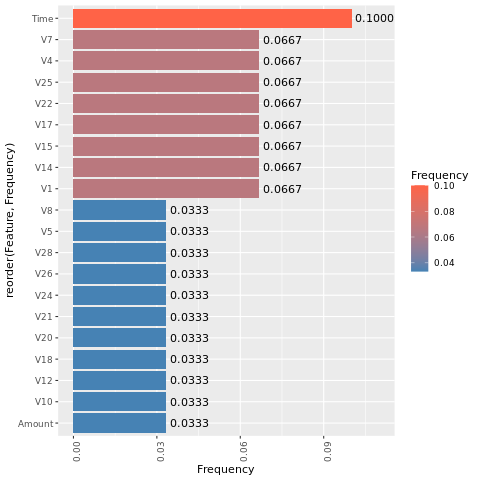
Для модели, обученной на сбалансированном наборе данных (с помощью SMOTE), вычислите важность функции:
smote_imp <- lgb.importance(smote_model, percentage = TRUE)
ggplot(smote_imp, aes(x = Frequency, y = reorder(Feature, Frequency), fill = Frequency)) +
geom_bar(stat = "identity") +
scale_fill_gradient(low="steelblue", high="tomato") +
geom_text(aes(label = sprintf("%.4f", Frequency)), hjust = -0.1) +
theme(axis.text.x = element_text(angle = 90)) +
xlim(0, max(smote_imp$Frequency) * 1.1)
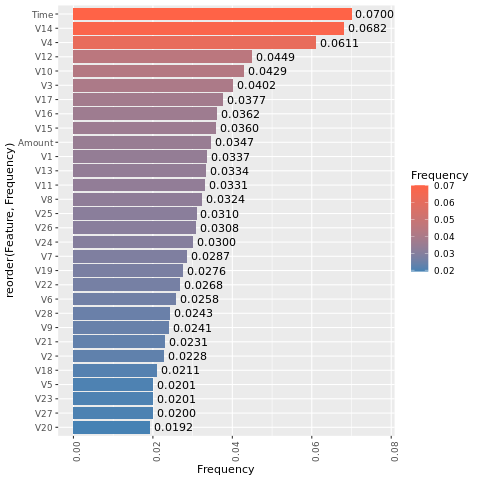
Сравнение этих графиков четко показывает, что сбалансированные и несбалансированные наборы данных для обучения имеют большие различия в важности признаков.
Оценка моделей
Здесь вы оцениваете две обученные модели:
-
modelобучен на необработанных, несбалансированных данных -
smote_modelобучен на сбалансированных данных
preds <- predict(model, test_mtx[, -label_col])
smote_preds <- predict(smote_model, test_mtx[, -label_col])
Оценка производительности модели с помощью матрицы путаницы
Матрица путаницы отображает количество
- истинно положительные (TP)
- истинные отрицательные значения (TN)
- ложные положительные результаты (FP)
- ложные отрицания (FN)
эта модель создает при оценке с помощью тестовых данных. Для двоичной классификации модель возвращает матрицу путаницы 2x2. Для многоклассовой классификации модель возвращает матрицу путаницы nxn, где n — это количество классов.
Используйте матрицу путаницы для суммы производительности обученных моделей машинного обучения на тестовых данных:
plot_cm <- function(preds, refs, title) { library(caret) cm <- confusionMatrix(factor(refs), factor(preds)) cm_table <- as.data.frame(cm$table) cm_table$Prediction <- factor(cm_table$Prediction, levels=rev(levels(cm_table$Prediction))) ggplot(cm_table, aes(Reference, Prediction, fill = Freq)) + geom_tile() + geom_text(aes(label = Freq)) + scale_fill_gradient(low = "white", high = "steelblue", trans = "log") + labs(x = "Prediction", y = "Reference", title = title) + scale_x_discrete(labels=c("0", "1")) + scale_y_discrete(labels=c("1", "0")) + coord_equal() + theme(legend.position = "none") }Настроите матрицу путаницы для модели, обученной на несбалансированном наборе данных:
# The value of the prediction indicates the probability that a transaction is fraud # Use 0.5 as the threshold for fraud/no-fraud transactions plot_cm(ifelse(preds > 0.5, 1, 0), test_df$Class, "Confusion Matrix (Imbalanced dataset)")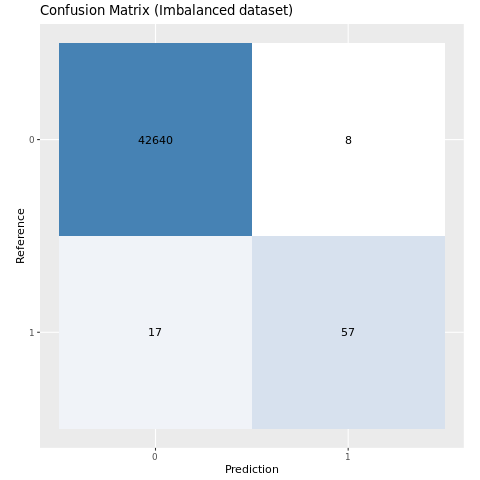
Постройте матрицу путаницы для модели, обученной на сбалансированном наборе данных.
plot_cm(ifelse(smote_preds > 0.5, 1, 0), test_df$Class, "Confusion Matrix (Balanced dataset)")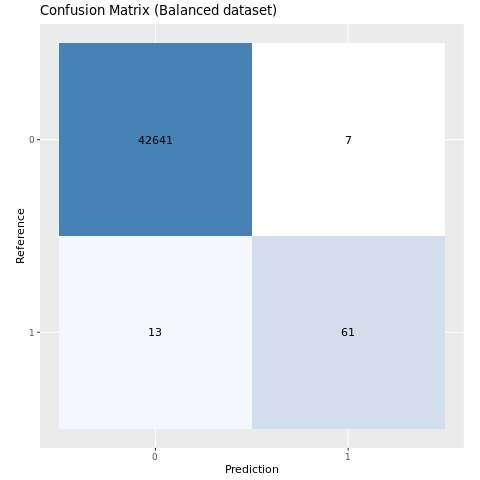
Оценка производительности модели с помощью метрик AUC-ROC и AUPRC
Область под операционной характеристикой приемника кривой (AUC-ROC) оценивает производительность двоичных классификаторов. Диаграмма AUC-ROC визуализирует компромисс между истинной положительной скоростью (TPR) и ложноположительной скоростью (FPR).
В некоторых случаях лучше оценить классификатор на основе области под мерой Precision-Recall кривой (AUPRC). Кривая AUPRC объединяет следующие ставки:
- Точность или положительное прогнозное значение (PPV)
- Отзыв продукции, или TPR
# Use the PRROC package to help calculate and plot AUC-ROC and AUPRC
install.packages("PRROC", quiet = TRUE)
library(PRROC)
Вычисление метрик AUC-ROC и AUPRC
Вычислите и постройте графики метрик AUC-ROC и AUPRC для двух моделей.
Несбалансированный набор данных
Вычислите прогнозы:
fg <- preds[test_df$Class == 1]
bg <- preds[test_df$Class == 0]
Напечатать область под кривой AUC-ROC:
# Compute AUC-ROC
roc <- roc.curve(scores.class0 = fg, scores.class1 = bg, curve = TRUE)
print(roc)
Постройте кривую AUC-ROC.
# Plot AUC-ROC
plot(roc)
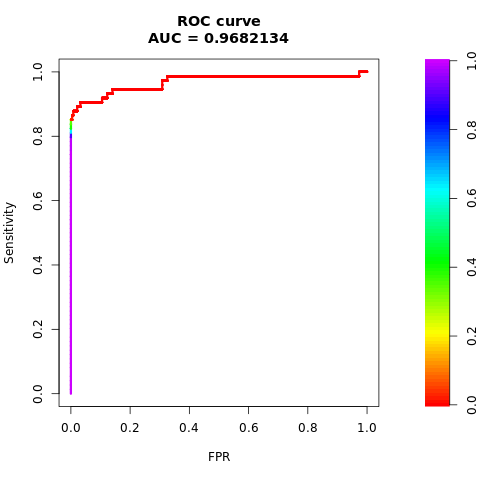
Напечатать кривую AUPRC:
# Compute AUPRC
pr <- pr.curve(scores.class0 = fg, scores.class1 = bg, curve = TRUE)
print(pr)
Постройте кривую AUPRC.
# Plot AUPRC
plot(pr)
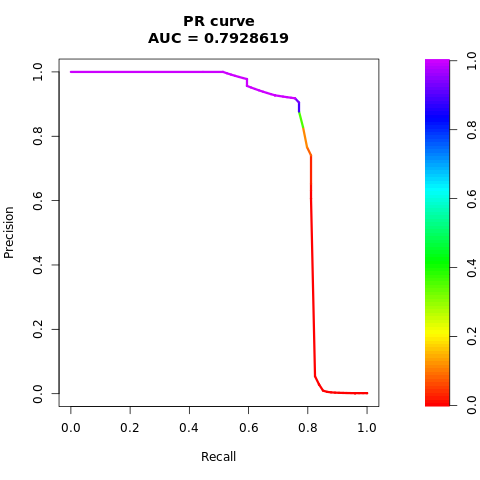
Сбалансированный набор данных (с помощью SMOTE)
Вычислите прогнозы:
smote_fg <- smote_preds[test_df$Class == 1]
smote_bg <- smote_preds[test_df$Class == 0]
Печать кривой AUC-ROC:
# Compute AUC-ROC
smote_roc <- roc.curve(scores.class0 = smote_fg, scores.class1 = smote_bg, curve = TRUE)
print(smote_roc)
Постройте кривую AUC-ROC:
# Plot AUC-ROC
plot(smote_roc)
Вывести кривую AUPRC:
# Compute AUPRC
smote_pr <- pr.curve(scores.class0 = smote_fg, scores.class1 = smote_bg, curve = TRUE)
print(smote_pr)
Постройте кривую AUPRC.
# Plot AUPRC
plot(smote_pr)
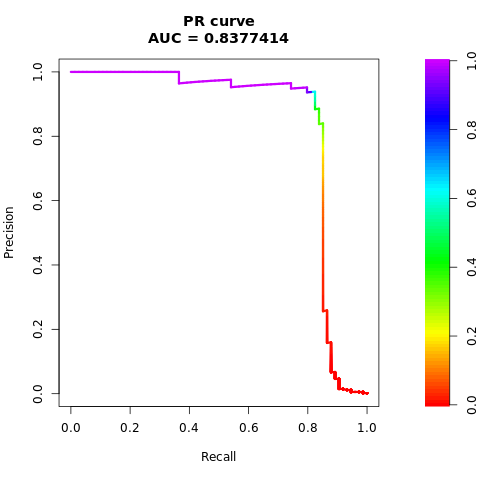
Более ранние цифры четко показывают, что модель, обученная на сбалансированном наборе данных, опережает модель, обученную на несбалансированном наборе данных, как для AUC-ROC, так и для оценки AUPRC. Этот результат предполагает, что SMOTE эффективно повышает производительность модели при работе с очень несбалансированными данными.
Связанное содержимое
- модель машинного обучения в Microsoft Fabric
- Обучение моделей машинного обучения
- эксперименты машинного обучения в Microsoft Fabric