Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этом руководстве вы узнаете, как проводить анализ аналитических данных (EDA), чтобы изучить и исследовать данные при обобщении ключевых характеристик с помощью методов визуализации данных.
Вы будете использовать seaborn, библиотеку визуализации данных Python, которая предоставляет высокоуровневый интерфейс для создания визуальных элементов на кадрах данных и массивах. Дополнительные сведения о seabornсм. в разделе Seaborn: визуализация статистических данных.
Вы также будете использовать Data Wrangler, инструмент на основе записной книжки, который предоставляет иммерсивный опыт для проведения исследовательского анализа и очистки данных.
Ниже приведены основные действия, описанные в этом руководстве.
- Считывать данные, хранящиеся из разностной таблицы в lakehouse.
- Преобразуйте кадр данных Spark в кадр данных Pandas, поддерживаемый библиотеками визуализации на Python.
- Используйте Wrangler для выполнения начальной очистки и преобразования данных.
- Выполните исследовательский анализ данных с помощью
seaborn.
Необходимые условия
Получите подписку Microsoft Fabric. Или зарегистрируйтесь для бесплатной пробной версии Microsoft Fabric.
Войдите в Microsoft Fabric.
Перейдите в Fabric с помощью переключателя интерфейса в левой нижней части домашней страницы.

Это часть 2 из 5 в серии учебников. Чтобы завершить работу с этим руководством, сначала выполните указанные ниже действия.
Следуйте инструкциям в записной книжке
2-explore-cleanse-data.ipynb — это записная книжка, сопровождающая это руководство.
Чтобы открыть сопровождающую записную книжку для этого руководства, выполните инструкции из раздела по подготовке вашей системы для учебных пособий по науке о данных для импорта записной книжки в рабочую область.
Если вы хотите скопировать и вставить код на этой странице, можно создать новую записную книжку.
Не забудьте подключить lakehouse к записной книжке перед началом выполнения кода.
Важный
Прикрепите тот же лейкхаус, который вы использовали в части 1.
Чтение необработанных данных из lakehouse
Чтение необработанных данных из раздела "Файлы" платформы lakehouse. Вы добавили эти данные в предыдущую записную книжку. Перед запуском этого кода убедитесь, что вы подключили к этой записной книжке тот же lakehouse, который вы использовали в части 1.
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
Создайте DataFrame pandas из набора данных
Преобразуйте Spark DataFrame в pandas DataFrame для упрощения обработки и визуализации.
df = df.toPandas()
Отображение необработанных данных
Изучите необработанные данные с помощью display, проведите некоторые основные статистические анализы и выполните отображение диаграмм. Обратите внимание, что сначала необходимо импортировать необходимые библиотеки, такие как Numpy, PnadasSeaborn, Seabornи для анализа и визуализации данных.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
# Code generated by Data Wrangler for pandas DataFrame
def clean_data(df):
# Drop duplicate rows in columns: 'CustomerId', 'RowNumber'
df = df.drop_duplicates(subset=['CustomerId', 'RowNumber'])
# Drop rows with missing data across all columns
df = df.dropna()
# Drop columns: 'CustomerId', 'RowNumber', 'Surname'
df = df.drop(columns=['CustomerId', 'RowNumber', 'Surname'])
return df
df_clean = clean_data(df.copy())
df_clean.head()
Используйте Data Wrangler для выполнения начальной очистки данных
Чтобы изучить и преобразовать кадры данных Pandas в записной книжке, запустите Data Wrangler непосредственно из записной книжки.
Заметка
Программу Data Wrangler нельзя открыть, пока ядро записной книжки занято. Выполнение ячейки должно завершиться до запуска Data Wrangler.
- На вкладке Данные ленты блокнота выберите Запустить Data Wrangler. Вы увидите список активированных pandas DataFrame, доступных для редактирования.
- Выберите кадр данных, который вы хотите открыть в Data Wrangler. Так как эта записная книжка содержит только один кадр данных,
dfвыберитеdf.
Data Wrangler запускает и создает описательный обзор ваших данных. В таблице в середине показан каждый столбец данных. На панели Сводка рядом с таблицей отображается информация о DataFrame. При выборе столбца в таблице сводка обновляется со сведениями о выбранном столбце. В некоторых случаях отображаемые и суммированные данные будут усечённым видом вашего DataFrame. В этом случае вы увидите изображение предупреждения в области сводки. Наведите указатель мыши на это предупреждение, чтобы просмотреть текст, объясняющий ситуацию.

Каждая операция, которую вы выполняете, может быть применена в пару кликов, обновляя отображение данных в режиме реального времени и генерируя код, который можно сохранить обратно в записную книжку в качестве повторно используемой функции.
В остальной части этого раздела описаны действия по очистке данных с помощью Wrangler.
Удаление повторяющихся строк
На левой панели находится список операций (например, Поиск и замена, Форматирование, Формулы, Числовые), которые можно выполнять с набором данных.
Разверните Найти и заменить и выберите Удалить повторяющиеся строки.
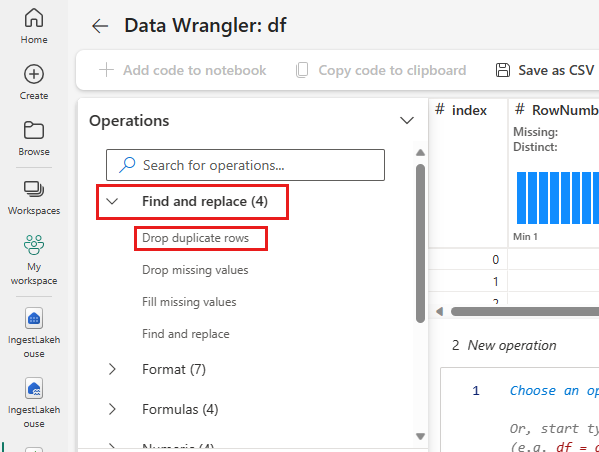
Откроется панель для выбора списка столбцов, которые нужно сравнить, чтобы определить повторяющиеся строки. Выберите RowNumber и CustomerId.
На средней панели отображается предварительный просмотр результатов этой операции. Под предварительным просмотром находится код для выполнения операции. В этом случае данные, кажется, не изменились. Но так как вы смотрите на усеченное представление, всё же имеет смысл применить операцию.
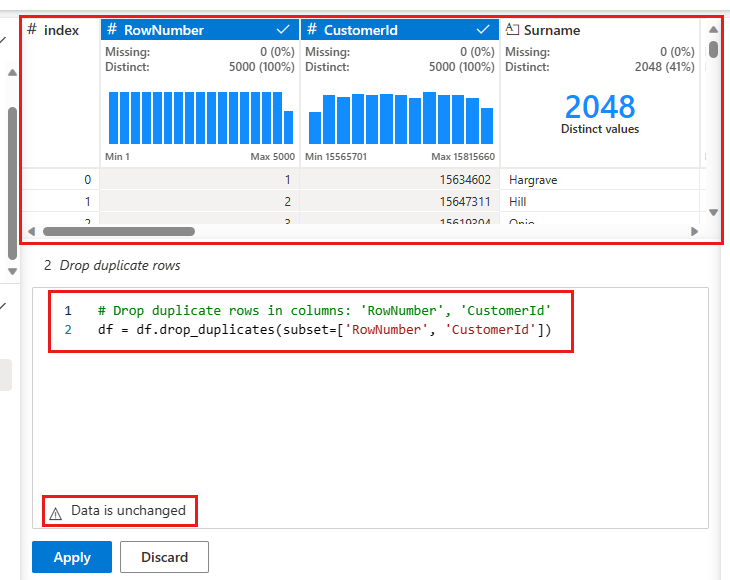
Выберите Применить (сбоку или внизу), чтобы перейти к следующему шагу.

Удаление строк с отсутствующими данными
Используйте Data Wrangler для удаления строк, в которых отсутствуют данные во всех столбцах.
Выберите Удалить отсутствующие значения из Найти и заменить.
Выберите Выбрать все из целевых столбцов.
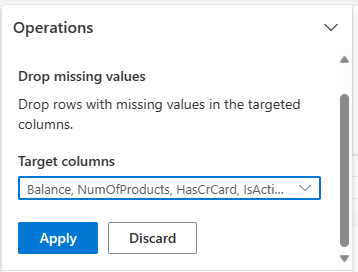
Выберите Применить, чтобы перейти к следующему шагу.

Удалить столбцы
Используйте Data Wrangler для удаления столбцов, которые вам не нужны.
Разверните схему и выберите Удалить столбцы.
Выберите НомерСтроки, ИдентификаторКлиента, фамилию. Эти столбцы отображаются красным цветом в предварительном просмотре, чтобы показать, что они изменены кодом (в данном случае удалены).
Выберите Применить, чтобы перейти к следующему шагу.

Добавление кода в записную книжку
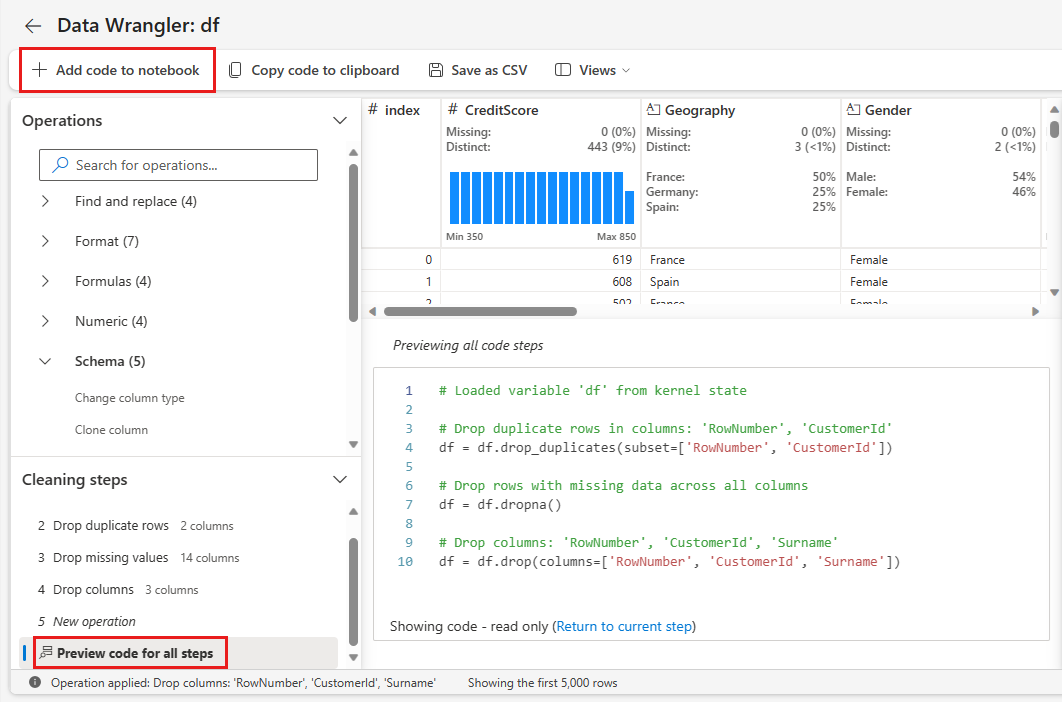
Каждый раз, когда вы выбираете Применить, создается новый шаг в секции Шаги по очистке панели, расположенной в левом нижнем углу. В нижней части панели выберите просмотр кода в предварительном режиме для всех шагов, чтобы просмотреть сочетание всех отдельных шагов.
Выберите Добавить код в записную книжку в левом верхнем углу, чтобы закрыть Data Wrangler и автоматически добавить код. Добавление кода в записную книжку упаковывает код в функцию, а затем вызывает функцию.
Совет
Код, созданный Data Wrangler, не будет применяться, пока не будет вручную запущена новая ячейка.
Если вы не использовали Data Wrangler, вместо этого можно использовать следующую ячейку кода.
Этот код аналогичен коду, созданному Data Wrangler, но добавляется в аргумент inplace=True к каждому созданному шагу. Задав inplace=True, pandas перезаписывает исходный кадр данных вместо создания нового кадра данных в качестве выходных данных.
# Modified version of code generated by Data Wrangler
# Modification is to add in-place=True to each step
# Define a new function that include all above Data Wrangler operations
def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
df_clean.head()
Изучение данных
Отображение некоторых сводок и визуализаций чистых данных.
Определение категориальных, числовых и целевых атрибутов
Используйте этот код для определения категориальных, числовых и целевых атрибутов.
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
Пятичисловая сводка
Отображение сводки с пятью числами (минимальная оценка, первая квартиль, медиана, третий квартиль, максимальная оценка) для числовых атрибутов с помощью графиков полей.
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
fig.delaxes(axes[1,2])
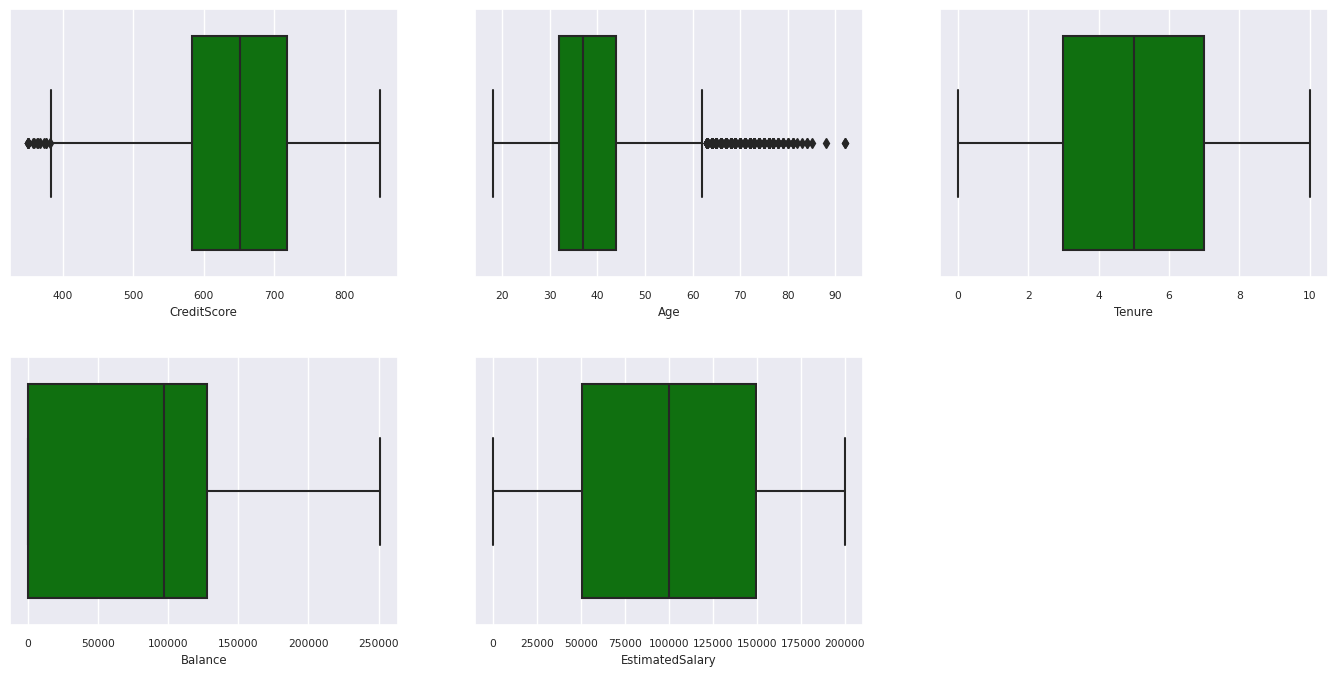
Распределение ушедших и оставшихся клиентов
Показать распределение завершенных и незавершенных клиентов по категориальным атрибутам.
df_clean['Exited'] = df_clean['Exited'].astype(str)
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
df_clean['Exited'] = df_clean['Exited'].astype(str)
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
print(ind, item)
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)
df_clean['Exited'] = df_clean['Exited'].astype(int)

Распределение числовых атрибутов
Отображение частоты распределения числовых атрибутов с помощью гистограммы.
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
plt.show()

Выполнение проектирования компонентов
Выполните проектирование функций для создания новых атрибутов на основе текущих атрибутов:
df_clean['Tenure'] = df_clean['Tenure'].astype(int)
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Используйте Data Wrangler для выполнения one-hot кодирования
Data Wrangler также можно использовать для выполнения one-hot кодирования. Для этого повторно откройте Data Wrangler. На этот раз выберите данные df_clean.
- Разверните формулы и выберите одно горячее кодирование.
- Откроется панель для выбора списка столбцов, для которого требуется выполнить одно горячее кодирование. Выберите География и Пол.
Вы можете скопировать созданный код, закрыть Data Wrangler, чтобы вернуться к записной книжке, а затем вставить в новую ячейку. Или выберите Добавить код в записную книжку в левом верхнем углу, чтобы закрыть Data Wrangler и автоматически добавить код.
Если вы не использовали Data Wrangler, можно использовать следующую ячейку кода:
# This is the same code that Data Wrangler will generate
import pandas as pd
def clean_data(df_clean):
# One-hot encode columns: 'Geography', 'Gender'
for column in ['Geography', 'Gender']:
insert_loc = df_clean.columns.get_loc(column)
df_clean = pd.concat([df_clean.iloc[:,:insert_loc], pd.get_dummies(df_clean.loc[:, [column]]), df_clean.iloc[:,insert_loc+1:]], axis=1)
return df_clean
df_clean_1 = clean_data(df_clean.copy())
df_clean_1.head()
# This is the same code that Data Wrangler will generate
import pandas as pd
def clean_data(df_clean):
# One-hot encode columns: 'Geography', 'Gender'
df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
return df_clean
df_clean_1 = clean_data(df_clean.copy())
df_clean_1.head()
Сводка наблюдений по исследовательскому анализу данных
- Большинство клиентов из Франции по сравнению с Испанией и Германией, в то время как Испания имеет самый низкий показатель оттока по сравнению с Францией и Германией.
- Большинство клиентов имеют кредитные карты.
- Есть клиенты, возраст и кредитная оценка которых выше 60 и ниже 400, соответственно, но они не могут рассматриваться как аномалии.
- Очень немногие клиенты имеют более двух продуктов банка.
- Клиенты, не являющиеся активными, имеют более высокую скорость оттока.
- Пол и срок пребывания в должности не влияют на решение клиента закрыть банковский счет.
Создание разностной таблицы для чистых данных
Эти данные будут использоваться в следующей записной книжке этой серии.
table_name = "df_clean"
# Create Spark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean_1)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark dataframe saved to delta table: {table_name}")
Следующий шаг
Обучение и регистрация моделей машинного обучения с помощью этих данных: