Интеграция OneLake с Azure Synapse Analytics
Azure Synapse — это служба безграничной аналитики, объединяющая хранилища корпоративные данных и аналитику больших данных. В этом руководстве показано, как подключиться к OneLake с помощью Azure Synapse Analytics.
Запись данных из Synapse с помощью Apache Spark
Выполните следующие действия, чтобы использовать Apache Spark для записи примеров данных в OneLake из Azure Synapse Analytics.
Откройте рабочую область Synapse и создайте пул Apache Spark с предпочитаемыми параметрами.
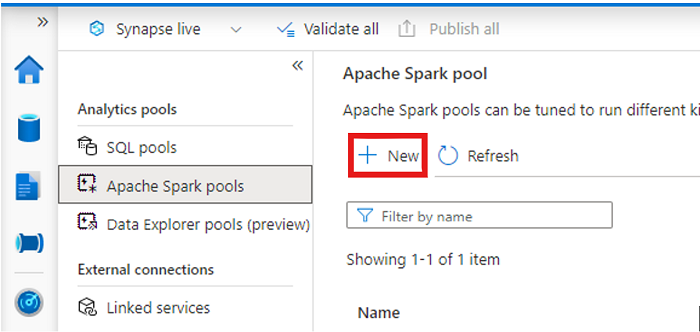
Создайте записную книжку Apache Spark.
Откройте записную книжку, задайте язык PySpark (Python) и подключите его к только что созданному пулу Spark.
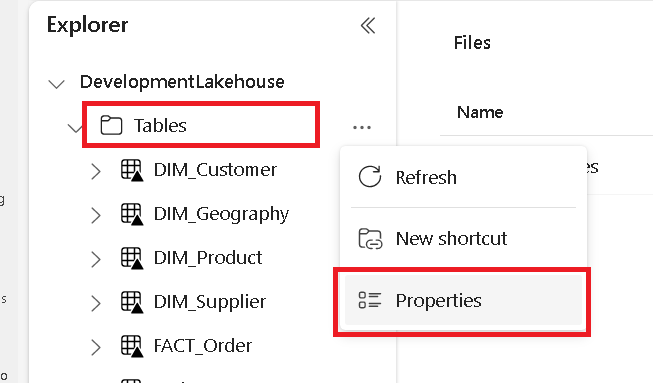
На отдельной вкладке перейдите к microsoft Fabric lakehouse и найдите папку таблиц верхнего уровня.
Щелкните правой кнопкой мыши папку "Таблицы" и выберите "Свойства".
Скопируйте путь ABFS из области свойств.
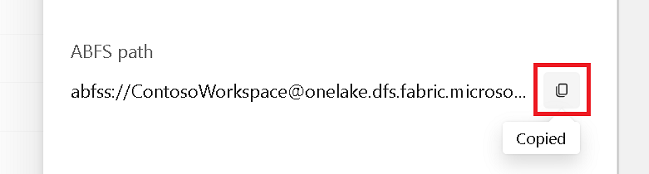
Вернитесь в записную книжку Azure Synapse в первой новой ячейке кода, укажите путь lakehouse. В этом лейкхаусе данные записываются позже. Запустите ячейку.
# Replace the path below with the ABFS path to your lakehouse Tables folder. oneLakePath = 'abfss://WorkspaceName@onelake.dfs.fabric.microsoft.com/LakehouseName.lakehouse/Tables'В новой ячейке кода загрузите данные из открытого набора данных Azure в кадр данных. Этот набор данных — это тот, который вы загружаете в lakehouse. Запустите ячейку.
yellowTaxiDf = spark.read.parquet('wasbs://nyctlc@azureopendatastorage.blob.core.windows.net/yellow/puYear=2018/puMonth=2/*.parquet') display(yellowTaxiDf.limit(10))В новой ячейке кода, фильтре, преобразовании или подготовке данных. В этом сценарии можно обрезать набор данных для ускорения загрузки, объединения с другими наборами данных или фильтрации до определенных результатов. Запустите ячейку.
filteredTaxiDf = yellowTaxiDf.where(yellowTaxiDf.tripDistance>2).where(yellowTaxiDf.passengerCount==1) display(filteredTaxiDf.limit(10))В новой ячейке кода, используя путь OneLake, напишите отфильтрованный кадр данных в новую таблицу Delta-Parquet в azure Fabric lakehouse. Запустите ячейку.
filteredTaxiDf.write.format("delta").mode("overwrite").save(oneLakePath + '/Taxi/')Наконец, в новой ячейке кода проверьте успешность записи данных, прочитав только что загруженный файл из OneLake. Запустите ячейку.
lakehouseRead = spark.read.format('delta').load(oneLakePath + '/Taxi/') display(lakehouseRead.limit(10))
Поздравляем. Теперь вы можете читать и записывать данные в OneLake с помощью Apache Spark в Azure Synapse Analytics.
Чтение данных из Synapse с помощью SQL
Выполните следующие действия, чтобы использовать SQL serverless для чтения данных из OneLake из Azure Synapse Analytics.
Откройте Lakehouse Fabric и определите таблицу, которую вы хотите запросить из Synapse.
Щелкните таблицу правой кнопкой мыши и выберите пункт "Свойства".
Скопируйте путь ABFS для таблицы.
Откройте рабочую область Synapse в Synapse Studio.
Создайте новый скрипт SQL.
В редакторе sql-запросов введите следующий запрос, заменив
ABFS_PATH_HEREпуть, скопированный ранее.SELECT TOP 10 * FROM OPENROWSET( BULK 'ABFS_PATH_HERE', FORMAT = 'delta') as rows;Запустите запрос, чтобы просмотреть первые 10 строк таблицы.
Поздравляем. Теперь вы можете считывать данные из OneLake с помощью SQL serverless в Azure Synapse Analytics.