Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Из этой статьи вы узнаете, как получить данные из хранилища Azure (контейнер ADLS 2-го поколения, контейнер BLOB-объектов или отдельные BLOB-объекты). Вы можете загружать данные в таблицу непрерывно или единоразово. После принятия данные становятся доступными для запроса.
Непрерывное поглощение (предварительная версия): непрерывное поглощение включает в себя настройку конвейера приема данных, который позволяет событийному центру прослушивать события службы хранилища Azure. Конвейер уведомляет хранилище событий о том, чтобы получить сведения при возникновении подписываемых событий. События : BlobCreated и BlobRenamed.
Это важно
Эта функция доступна в предварительной версии.
Заметка
Поток непрерывного приема может повлиять на ваши счета. Дополнительные сведения см. в разделе "Eventhouse" и "Использование базы данных KQL".
Однократный прием: используйте этот метод для извлечения данных из службы хранилища Azure как одноразовую операцию.
Необходимые условия
- Рабочая область с емкостью , поддерживающей Microsoft Fabric.
- База данных KQL с разрешениями на редактирование.
- Учетная запись хранения.
Для непрерывного приема также требуется:
Идентификатор рабочей области. Моя рабочая область не поддерживается. При необходимости создайте новую рабочую область.
Включите иерархическое пространство имен в учетной записи хранения.

Роль читателя данных BLOB-объектов хранилища, назначенная удостоверению рабочей области.
Контейнер для хранения файлов данных.
Файл данных, отправленный в контейнер. Структура файла данных используется для определения схемы таблицы. Дополнительные сведения см. в форматах данных, поддерживаемыханалитикой Real-Time.
Заметка
Необходимо отправить файл данных:
- Перед настройкой конфигурации , чтобы определить схему таблицы во время настройки.
- После настройки для активации непрерывного приема данных для предварительного просмотра данных и проверки подключения.
Добавьте назначение роли удостоверения рабочей области в учетную запись хранения
Скопируйте идентификатор рабочей области из параметров рабочей области в Fabric.

На портале Azure перейдите к учетной записи хранения Azure и выберите "Управление доступом" (IAM)>Добавить>назначение ролей.
Выберите средство чтения данных BLOB-объектов хранилища.
В диалоговом окне "Добавление назначения ролей " выберите +Выбрать участников.
Вставьте идентификатор удостоверения рабочей области, выберите приложение и нажмите кнопку ">Проверить и назначить".
Создание контейнера с файлом данных
В учетной записи хранения выберите контейнеры.
Выберите +Контейнер, введите имя контейнера и нажмите кнопку "Сохранить".
Введите контейнер, выберите отправку и отправьте файл данных, подготовленный ранее.
Дополнительные сведения см. в поддерживаемых форматах и поддерживаемых сжатиях.
В контекстном меню [...], выберите свойства контейнера и скопируйте URL-адрес в входные данные во время настройки.

Источник
Задайте источник для получения данных.
В рабочей области откройте EventHouse и выберите базу данных.
На ленте базы данных KQL выберите "Получить данные".
Выберите источник данных из доступного списка. В этом примере вы получаете данные из хранилища Azure.


Настройка
Выберите целевую таблицу. Если вы хотите принять данные в новую таблицу, выберите + Создать таблицу и введите имя таблицы.
Заметка
Имена таблиц могут содержать до 1024 символов, включая пробелы, буквенно-цифровые символы, дефисы и символы подчеркивания. Специальные символы не поддерживаются.
В конфигурации подключения к хранилищу BLOB по хранению Azure убедитесь, что включен непрерывный ввод данных. Он включен по умолчанию.
Настройте подключение, создав новое подключение или используя существующее подключение.
Чтобы создать новое подключение, выполните приведенные действия.
Выберите "Подключиться к учетной записи хранения".

Чтобы заполнить поля, используйте следующие описания.
настройка описание поля Подписка Подписка на учетную запись хранения. Учетная запись Blob-хранилища Имя учетной записи хранения. Контейнер Контейнер хранилища, содержащий файл, который требуется импортировать. В поле "Подключение" откройте раскрывающийся список и нажмите кнопку +Создать подключение, а затем сохраните>закрытие. Параметры подключения уже заполнены.
Заметка
Создание нового подключения приводит к созданию нового потока событий. Имя определяется как <storate_account_name>_eventstream. Убедитесь, что не удаляйте поток событий непрерывного приема из рабочей области.
Чтобы использовать существующее подключение:
Выберите существующую учетную запись хранения.

Чтобы заполнить поля, используйте следующие описания.
настройка описание поля RTAStorageAccount Поток событий, подключенный к вашей учетной записи хранения из Fabric. Контейнер Контейнер хранилища, содержащий файл, который требуется импортировать. Подключение Это поле предварительно заполнено строкой подключения В поле "Подключение" откройте раскрывающийся список и выберите существующую строку подключения из списка. Затем нажмите кнопку "Сохранить>закрыть".
При необходимости разверните фильтры файлов и укажите следующие фильтры:
настройка описание поля Путь к папке Фильтрует данные для импорта файлов с конкретным путем к папке. Расширение файла Фильтрует данные для приема файлов только с определенным расширением файла. В разделе «Параметры Eventstream» вы можете выбрать события для мониторинга в расширенных параметрах>типы событий. По умолчанию выбрано создание Blob. Вы также можете выбрать переименованный BLOB-объект.

Нажмите «Далее», чтобы просмотреть данные.




Инспектировать
Откроется вкладка "Проверка" с предварительным просмотром данных.
Чтобы завершить процесс приема, нажмите кнопку Готово.

Заметка
Чтобы обеспечить непрерывное потребление и предварительный просмотр данных, убедитесь, что после настройки вы добавили новый большой двоичный объект хранилища.
Необязательно:
Используйте раскрывающийся список файла определения схемы, чтобы изменить файл, из который выводится схема.
Используйте раскрывающийся список типов файлов для изучения дополнительных параметров на основе типа данных.
Используйте раскрывающийся список Table_mapping для определения нового сопоставления.
Выберите <или> откройте средство просмотра команд, чтобы просмотреть и скопировать автоматические команды, созданные из входных данных. Вы также можете открыть команды в наборе запросов.
Щелкните значок карандаша, чтобы изменить столбцы.
Изменение столбцов
Заметка
- Для табличных форматов (CSV, TSV, PSV) невозможно сопоставить столбец дважды. Чтобы сопоставить данные с существующим столбцом, сначала удалите новый столбец.
- Невозможно изменить существующий тип столбца. При попытке выполнить сопоставление для столбца, имеющего другой формат, могут отобразиться пустые столбцы.
Изменения, которые можно внести в таблицу, зависят от следующих параметров:
- тип таблицы является новым или существующим
- Тип сопоставления является новым или существующим

Трансформации картирования
Некоторые сопоставления форматов данных (Parquet, JSON и Avro) поддерживают простые преобразования на этапе загрузки данных. Чтобы применить преобразования маппинга, создайте или обновите столбец в окне Редактирование столбцов.
Преобразования сопоставления можно выполнять в столбце типа string или datetime, если источник имеет тип данных int или long. Дополнительные сведения см. в полном списке поддерживаемых трансформаций отображения .
Дополнительные параметры на основе типа данных
таблица (CSV, TSV, PSV):
При приеме табличных форматов в существующей таблице можно выбрать Расширенные возможности>. Табличные данные не обязательно включают имена столбцов, которые используются для сопоставления исходных данных с существующими столбцами. При проверке этого параметра сопоставление выполняется по порядку, а схема таблицы остается той же. Если этот параметр снят, для входящих данных создаются новые столбцы независимо от структуры данных.

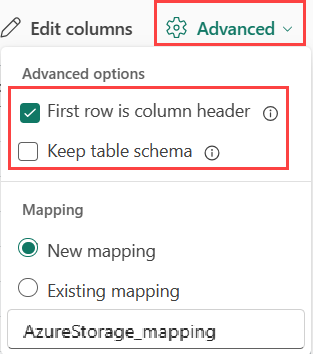
Табличные данные не обязательно включают имена столбцов, которые используются для сопоставления исходных данных с существующими столбцами. Чтобы использовать первую строку в качестве имен столбцов, выберите Первая строка — это заголовок столбца.

таблица (CSV, TSV, PSV):
При приеме табличных форматов в существующей таблице можно выбрать Table_mapping>Использовать существующую схему. Табличные данные не обязательно включают имена столбцов, которые используются для сопоставления исходных данных с существующими столбцами. При проверке этого параметра сопоставление выполняется по порядку, а схема таблицы остается той же. Если этот параметр снят, для входящих данных создаются новые столбцы независимо от структуры данных.
Чтобы использовать первую строку в качестве имен столбцов, выберите заголовок первой строки.
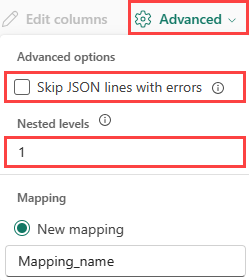
JSON:
Чтобы определить деление данных JSON по уровням вложенности, выберите вложенные уровни от 1 до 100.
Сводка
В окне сводки все шаги помечаются зелеными галочками, когда прием данных завершается успешно. Вы можете выбрать карточку, чтобы изучить данные, удалить загруженные данные или создать панель мониторинга с ключевыми метриками.

При закрытии окна вы увидите подключение на вкладке "Обозреватель" в разделе "Потоки данных". Здесь можно отфильтровать потоки данных и удалить поток данных.


Связанное содержимое
- Сведения об управлении базой данных см. в статье Управление данными
- Сведения о создании, хранении и экспорте запросов см. в разделе Запрос данных в наборе запросов KQL