Маршрутизация потоков данных на основе содержимого в потоках событий Fabric (предварительная версия)
В этой статье показано, как маршрутизировать события на основе содержимого в потоках событий Microsoft Fabric.
Теперь вы можете использовать редактор без кода в потоке событий Fabric основной холст для создания сложной логики потоковой обработки без написания кода. Эта функция позволяет упростить настройку, преобразование и управление потоками данных. После настройки операций обработки потоков вы можете плавно отправлять потоки данных в разные места назначения в соответствии с конкретной схемой и данными потока.
Внимание
Расширенные возможности потоков событий Fabric в настоящее время находятся в предварительной версии.
Поддерживаемые операции
Ниже приведен список операций, поддерживаемых для обработки данных в режиме реального времени:
Агрегат: поддержка функций SUM, AVG, MIN и MAX, выполняющих вычисления в столбце значений, возвращая один результат.
Разверните значение массива и создайте новую строку для каждого значения в массиве.
Фильтр. Выбор или фильтрация определенных строк из потока данных на основе условия.
Группа по: агрегирование всех данных событий в течение определенного периода времени с параметром группировки одного или нескольких столбцов.
Управление полями: добавление, удаление или изменение типа данных поля или столбца потоков данных.
Объединение: Подключение два или более потоков данных с общими полями одного и того же имени и типа данных в один поток данных. Поля, которые не соответствуют, удаляются.
Присоединение: объединение данных из двух потоков на основе соответствующего условия между ними.
Поддерживаемые назначения
Поддерживаемые назначения:
Lakehouse: Это назначение обеспечивает возможность преобразования событий в режиме реального времени перед приемом в озеро. События в режиме реального времени преобразуются в формат Delta Lake, а затем хранятся в назначенных таблицах lakehouse. Это назначение помогает с сценариями хранения данных.
База данных KQL: это назначение позволяет получать данные событий в режиме реального времени в базу данных KQL, где можно использовать мощные язык запросов Kusto (KQL) для запроса и анализа данных. С помощью данных в базе данных KQL вы можете получить более подробные сведения о данных о событиях и создавать расширенные отчеты и панели мониторинга.
Рефлектор: это назначение позволяет напрямую подключать данные событий в режиме реального времени к рефлектору. Рефлектор — это тип интеллектуального агента, который содержит всю информацию, необходимую для подключения к данным, мониторинга условий и действий. Когда данные достигают определенных пороговых значений или соответствуют другим шаблонам, Рефлектор автоматически принимает соответствующие действия, такие как оповещение пользователей или запуск рабочих процессов Power Automate.
Пользовательская конечная точка (прежнее пользовательское приложение): с помощью этого назначения можно легко направлять события в режиме реального времени в пользовательское приложение. Это назначение позволяет подключать собственные приложения к потоку событий и использовать данные событий в режиме реального времени. Полезно, если вы хотите исходящие данные в режиме реального времени во внешнюю систему за пределами Microsoft Fabric.
Stream: это назначение представляет необработанный поток событий по умолчанию, преобразованный рядом операций, также называемый производным потоком. После создания вы можете просмотреть поток из концентратора реального времени.
В следующем примере показано, как три отдельных назначения событий Fabric могут служить отдельным функциям для одного источника потока данных. Одна база данных KQL предназначена для хранения необработанных данных, вторая база данных KQL предназначена для хранения отфильтрованных потоков данных, а Lakehouse используется для хранения агрегированных значений.
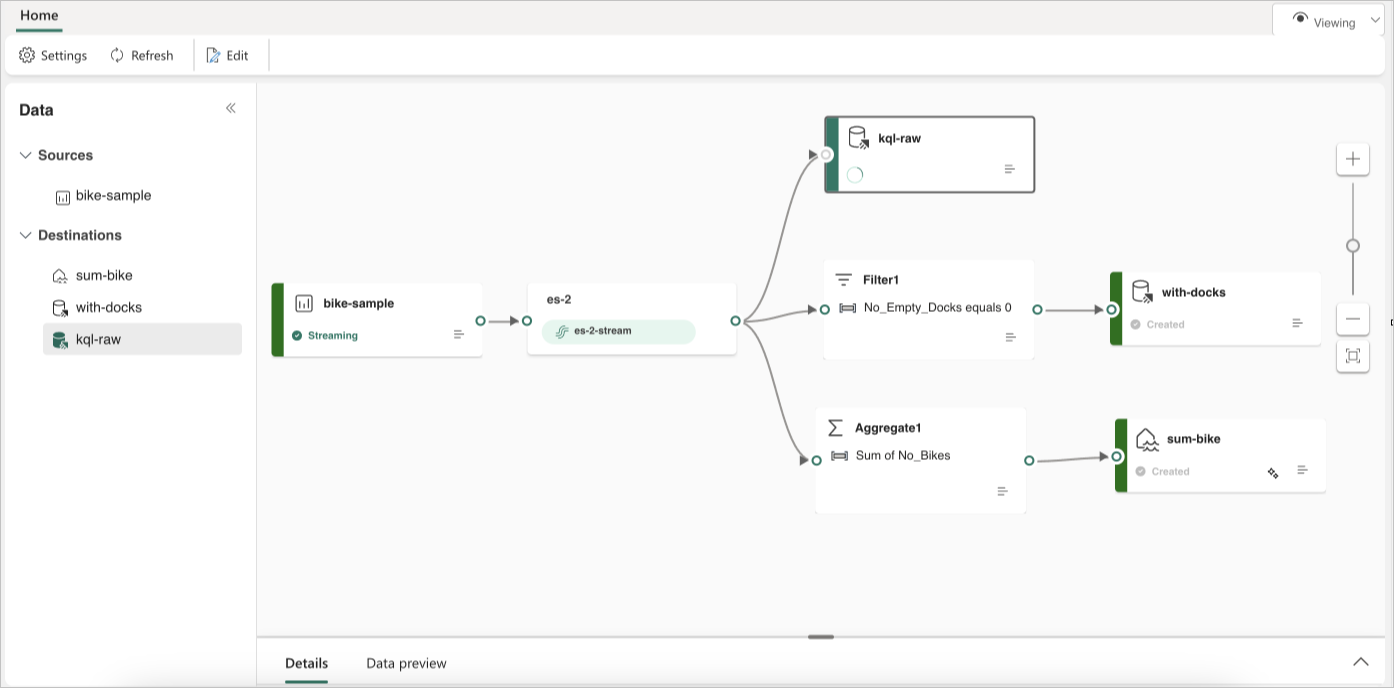
Чтобы преобразовать и направить поток данных на основе содержимого, выполните действия, описанные в разделе "Изменение и публикация потока событий " и начало разработки логики потоковой обработки для потока данных.
Связанный контент
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по