Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Эта функция dbscan_fl() представляет собой определяемую пользователем функцию (определяемую пользователем функцию), которая кластеризует набор данных с помощью алгоритма DBSCAN.
Необходимые компоненты
- Подключаемый модуль Python должен быть включен в кластере. Это необходимо для встроенного Python, используемого в функции.
- Подключаемый модуль Python должен быть включен в базе данных. Это необходимо для встроенного Python, используемого в функции.
Синтаксис
T | invoke dbscan_fl(функции, cluster_col epsilon, min_samples, метрики metric_params, , )
Дополнительные сведения о соглашениях синтаксиса.
Параметры
| Имя (название) | Type | Обязательно | Описание |
|---|---|---|---|
| features | dynamic |
✔️ | Массив, содержащий имена столбцов компонентов, используемых для кластеризации. |
| cluster_col | string |
✔️ | Имя столбца для хранения идентификатора выходного кластера для каждой записи. |
| epsilon | real |
✔️ | Максимальное расстояние между двумя образцами, которые следует рассматривать как соседи. |
| min_samples | int |
Количество выборок в районе для точки, который следует рассматривать как основную точку. | |
| метрический | string |
Метрика, используемая при вычислении расстояния между точками. | |
| metric_params | dynamic |
Дополнительные аргументы ключевых слов для функции метрики. |
- Подробное описание параметров см . в документации по DBSCAN
- Список метрик см . в вычислениях расстояния
Определение функции
Вы можете определить функцию, внедрив код как определяемую запросом функцию или создав ее в качестве хранимой функции в базе данных следующим образом:
Определите функцию с помощью следующей инструкции let. Разрешения не требуются.
Внимание
Инструкция let не может выполняться самостоятельно. За ним следует оператор табличного выражения. Пример выполнения рабочего примера kmeans_fl()см . в примере.
let dbscan_fl=(tbl:(*), features:dynamic, cluster_col:string, epsilon:double, min_samples:int=10,
metric:string='minkowski', metric_params:dynamic=dynamic({'p': 2}))
{
let kwargs = bag_pack('features', features, 'cluster_col', cluster_col, 'epsilon', epsilon, 'min_samples', min_samples,
'metric', metric, 'metric_params', metric_params);
let code = ```if 1:
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
features = kargs["features"]
cluster_col = kargs["cluster_col"]
epsilon = kargs["epsilon"]
min_samples = kargs["min_samples"]
metric = kargs["metric"]
metric_params = kargs["metric_params"]
df1 = df[features]
mat = df1.values
# Scale the dataframe
scaler = StandardScaler()
mat = scaler.fit_transform(mat)
# see https://docs.scipy.org/doc/scipy/reference/spatial.distance.html for the various distance metrics
dbscan = DBSCAN(eps=epsilon, min_samples=min_samples, metric=metric, metric_params=metric_params) # 'minkowski', 'chebyshev'
labels = dbscan.fit_predict(mat)
result = df
result[cluster_col] = labels
```;
tbl
| evaluate python(typeof(*),code, kwargs)
};
// Write your query to use the function here.
Пример
В следующем примере для запуска функции используется оператор вызова.
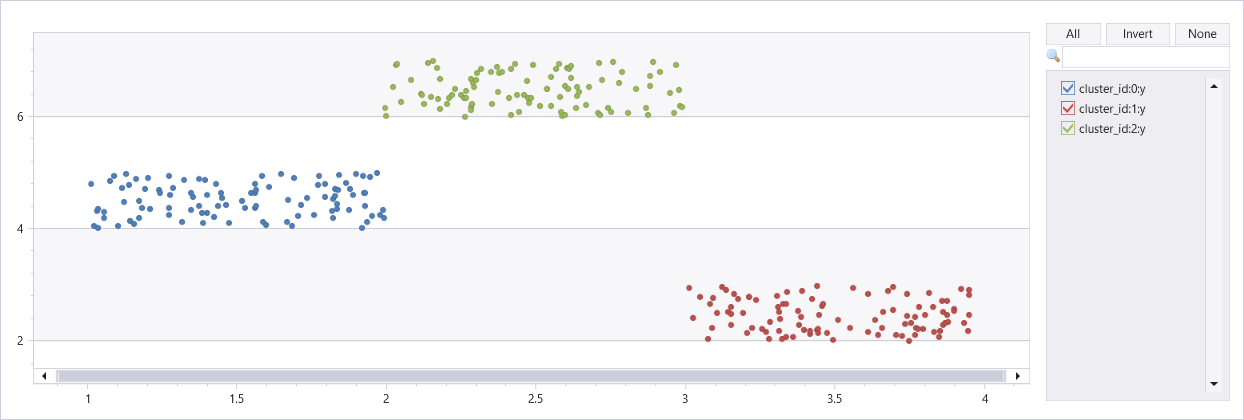
Кластеризация искусственного набора данных с тремя кластерами
Чтобы использовать определяемую запросом функцию, вызовите ее после внедренного определения функции.
let dbscan_fl=(tbl:(*), features:dynamic, cluster_col:string, epsilon:double, min_samples:int=10,
metric:string='minkowski', metric_params:dynamic=dynamic({'p': 2}))
{
let kwargs = bag_pack('features', features, 'cluster_col', cluster_col, 'epsilon', epsilon, 'min_samples', min_samples,
'metric', metric, 'metric_params', metric_params);
let code = ```if 1:
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
features = kargs["features"]
cluster_col = kargs["cluster_col"]
epsilon = kargs["epsilon"]
min_samples = kargs["min_samples"]
metric = kargs["metric"]
metric_params = kargs["metric_params"]
df1 = df[features]
mat = df1.values
# Scale the dataframe
scaler = StandardScaler()
mat = scaler.fit_transform(mat)
# see https://docs.scipy.org/doc/scipy/reference/spatial.distance.html for the various distance metrics
dbscan = DBSCAN(eps=epsilon, min_samples=min_samples, metric=metric, metric_params=metric_params) # 'minkowski', 'chebyshev'
labels = dbscan.fit_predict(mat)
result = df
result[cluster_col] = labels
```;
tbl
| evaluate python(typeof(*),code, kwargs)
};
union
(range x from 1 to 100 step 1 | extend x=rand()+3, y=rand()+2),
(range x from 101 to 200 step 1 | extend x=rand()+1, y=rand()+4),
(range x from 201 to 300 step 1 | extend x=rand()+2, y=rand()+6)
| extend cluster_id=int(null)
| invoke dbscan_fl(pack_array("x", "y"), "cluster_id", epsilon=0.6, min_samples=4, metric_params=dynamic({'p':2}))
| render scatterchart with(series=cluster_id)