Домен безопасности: операционная безопасность
Область операционной безопасности гарантирует, что поставщики программного обеспечения реализуют надежный набор методов защиты от множества угроз, с которыми сталкиваются субъекты угроз. Это предназначено для защиты операционной среды и процессов разработки программного обеспечения для создания безопасных сред.
Обучение по повышению осведомленности
Обучение по повышению осведомленности о безопасности важно для организаций, так как помогает свести к минимуму риски, связанные с человеческой ошибкой, которая связана с более чем 90% нарушений безопасности. Это помогает сотрудникам понять важность мер и процедур безопасности. Обучение по повышению осведомленности о безопасности усиливает важность культуры с учетом безопасности, в которой пользователи знают, как распознавать потенциальные угрозы и реагировать на них. Эффективная программа обучения по повышению осведомленности о безопасности должна включать в себя материалы, охватывающие широкий спектр тем и угроз, с которыми могут столкнуться пользователи, такие как социальная инженерия, управление паролями, конфиденциальность и физическая безопасность.
Элемент управления No 1
Укажите доказательства того, что:
Организация проводит учебные курсы по вопросам безопасности для пользователей информационной системы (включая руководителей, руководителей и подрядчиков):
В рамках начального обучения для новых пользователей.
Когда требуются изменения информационной системы.
Частота обучения осведомленности, определяемая организацией.
Документирует и отслеживает отдельные действия по повышению осведомленности информационной системы о безопасности и сохраняет отдельные обучающие записи в течение определенной организацией частоты.
Намерение: обучение для новых пользователей
В этом подразделе основное внимание уделяется созданию обязательной программы обучения по вопросам безопасности, предназначенной для всех сотрудников и для новых сотрудников, которые присоединяются к организации, независимо от их роли. Сюда входят руководители, руководители высшего звена и подрядчики. Программа осведомленности о безопасности должна включать в себя комплексную учебную программу, предназначенную для распространения базовых знаний о протоколах информационной безопасности организации, политиках и рекомендациях, чтобы обеспечить соответствие всех членов организации единому набору стандартов безопасности, создавая устойчивую среду информационной безопасности.
Рекомендации: обучение для новых пользователей
Большинство организаций будут использовать сочетание платформенного обучения по повышению осведомленности о безопасности и административной документации, такой как документация по политикам и записи, для отслеживания завершения обучения для всех сотрудников в организации. Предоставленные доказательства должны свидетельствовать о том, что сотрудники завершили обучение, и для этого необходимо создать резервную копию с помощью вспомогательных политик и процедур, определяющих требование осведомленности о безопасности.
Пример доказательства: обучение для новых пользователей
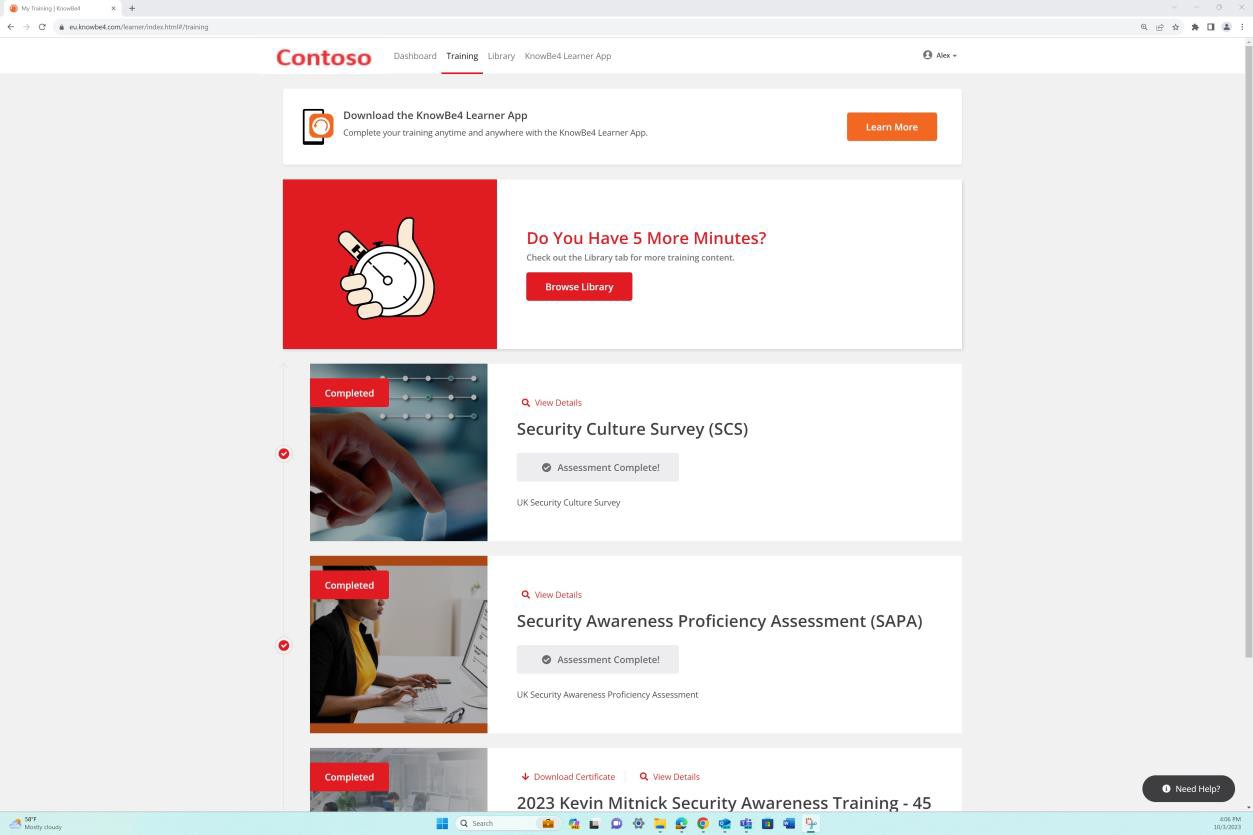
На следующем снимке экрана показана платформа Confluence, используемая для отслеживания адаптации новых сотрудников. Для нового сотрудника был создан билет JIRA, включая его назначение, роль, отдел и т. д. В рамках нового начального процесса сотруднику был выбран и назначен учебный курс по вопросам безопасности, который должен быть завершен до28 февраля 2023 года.
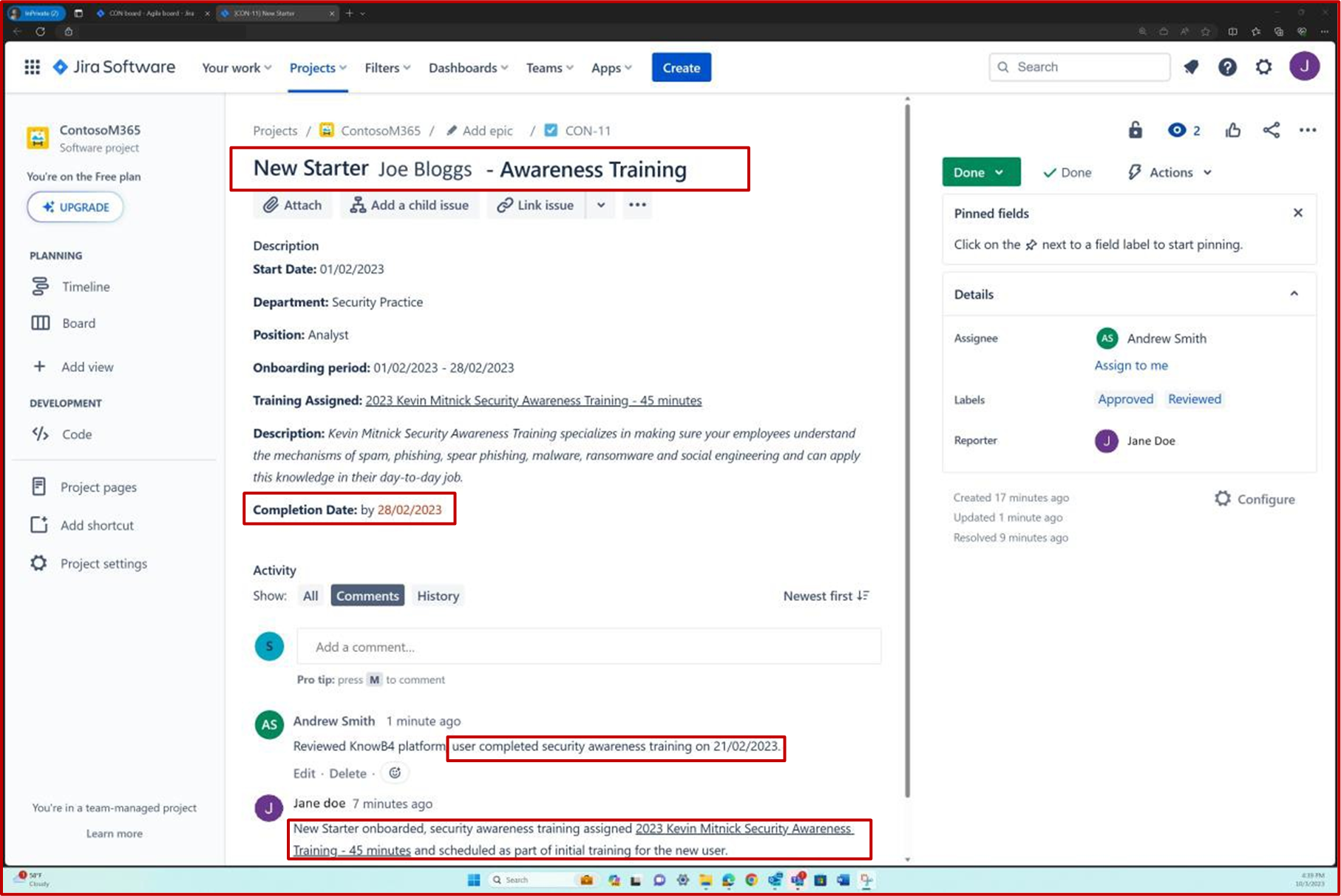
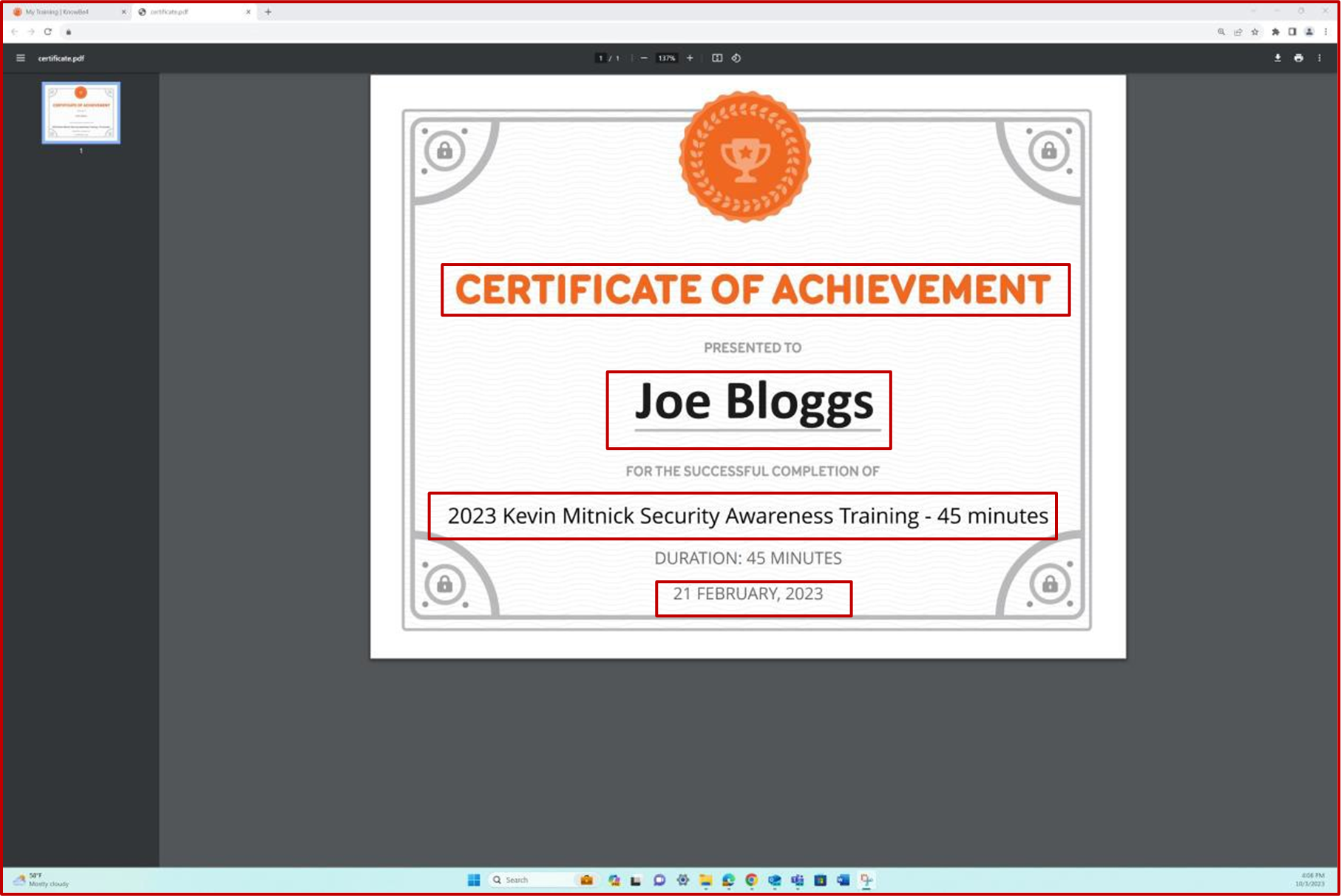
Снимок экрана: сертификат о завершении, созданный Knowb4 после успешного завершения сотрудниками обучения по повышению осведомленности о безопасности. Дата завершения —21 февраля 2023 года, который находится в течение назначенного периода.
Намерение: изменения информационной системы.
Цель этой подтемы заключается в том, чтобы обеспечить, чтобы адаптивное обучение по повышению осведомленности о безопасности инициирулось всякий раз, когда в информационных системах организации произошли значительные изменения. Изменения могут возникнуть из-за обновлений программного обеспечения, изменений архитектуры или новых нормативных требований. Обновленный учебный сеанс гарантирует, что все сотрудники будут проинформированы о новых изменениях и их влиянии на меры безопасности, что позволяет им соответствующим образом адаптировать свои действия и решения. Такой упреждающий подход имеет жизненно важное значение для защиты цифровых активов организации от уязвимостей, которые могут возникнуть в связи с изменениями в системе.
Рекомендации: изменения в информационной системе.
Большинство организаций будут использовать сочетание платформенного обучения по повышению осведомленности о безопасности и административной документации, такой как документация по политикам и записи, для отслеживания завершения обучения для всех сотрудников. Предоставленные доказательства должны продемонстрировать, что различные сотрудники прошли обучение на основе различных изменений в системах организации.
Пример доказательства: изменения в информационной системе.
На следующих снимках экрана показано, как различным сотрудникам назначено обучение по вопросам безопасности, и показано, что симуляции фишинга происходят.
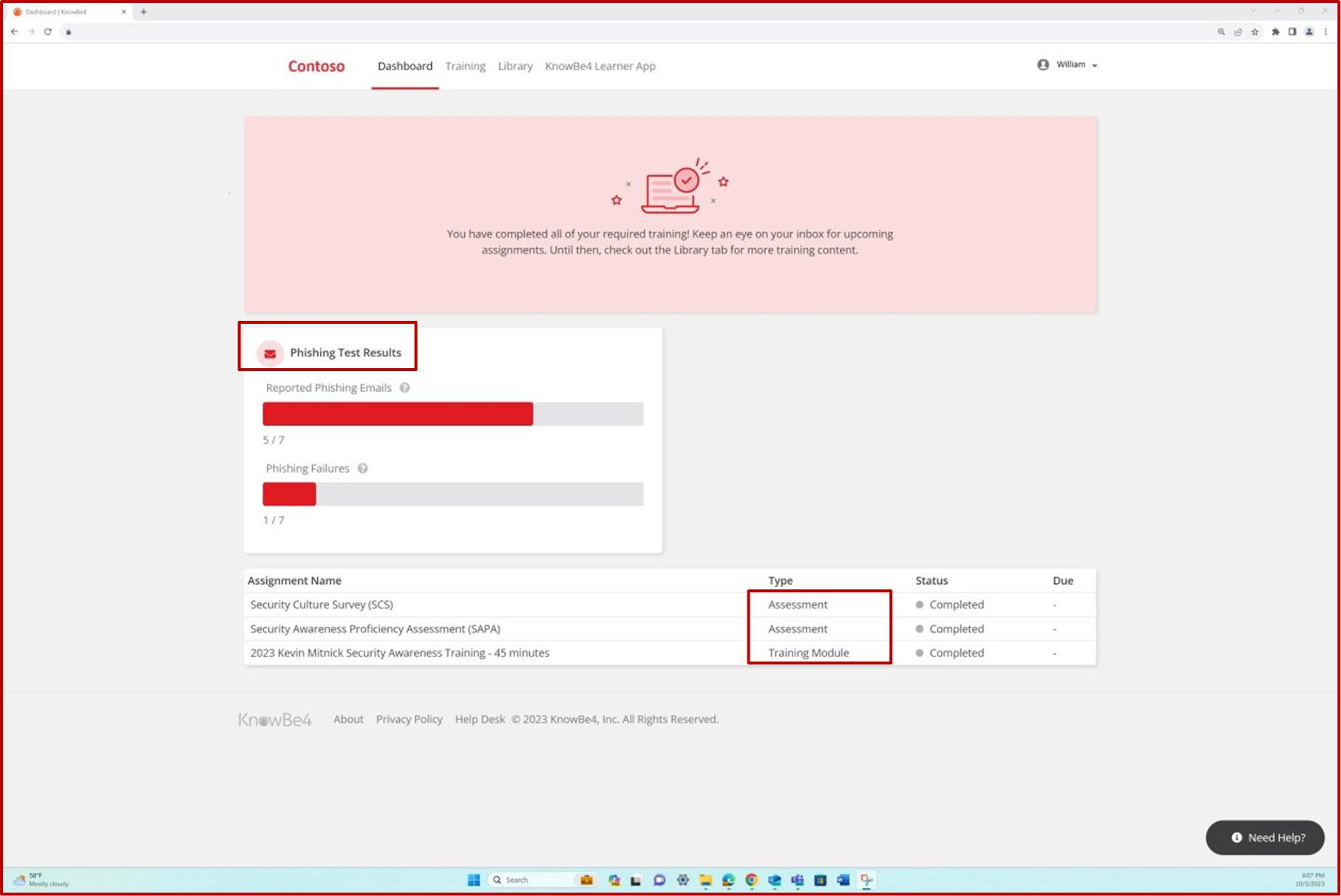
Платформа используется для назначения нового обучения при каждом изменении системы или сбое теста.
Намерение: частота обучения осведомленности.
Цель этой подпочты — определить частоту для конкретной организации для периодического обучения по повышению осведомленности о безопасности. Это может быть запланировано ежегодно, полугодие или через другой интервал, определенный организацией. Задавая частоту, организация обеспечивает регулярное обновление пользователей о меняющемся ландшафте угроз, а также о новых защитных мерах и политиках. Такой подход может помочь сохранить высокий уровень осведомленности всех пользователей о безопасности и укрепить предыдущие компоненты обучения.
Рекомендации: частота обучения по повышению осведомленности.
Большинство организаций будут иметь административную документацию и(или) техническое решение для определения или реализации требований и процедуры обучения по повышению осведомленности о безопасности, а также определения частоты обучения. Предоставленные доказательства должны свидетельствовать о завершении различных учебных курсов по повышению осведомленности в течение определенного периода и о том, что в вашей организации существует определенный период.
Пример доказательства: частота обучения осведомленности.
На следующих снимках экрана показаны моментальные снимки документации по политике осведомленности о безопасности, а также то, что она существует и поддерживается. Политика требует, чтобы все сотрудники организации проходили обучение по вопросам безопасности, как описано в разделе области политики. Обучение должно быть назначено и проходить на ежегодной основе соответствующим департаментом.
Согласно документу политики, все сотрудники организации должны проходить три курса (один курс обучения и две оценки) ежегодно и в течение двадцати дней после назначения. Курсы должны быть отправлены по электронной почте и назначены через KnowBe4.
В приведенном примере показаны только моментальные снимки политики. Обратите внимание, что ожидается, что будет отправлен полный документ политики.

На втором снимку экрана показано продолжение политики. На нем показан раздел документа, в котором требуется ежегодное обучение, и показано, что определенная организацией частота обучения осведомленности устанавливается ежегодно.

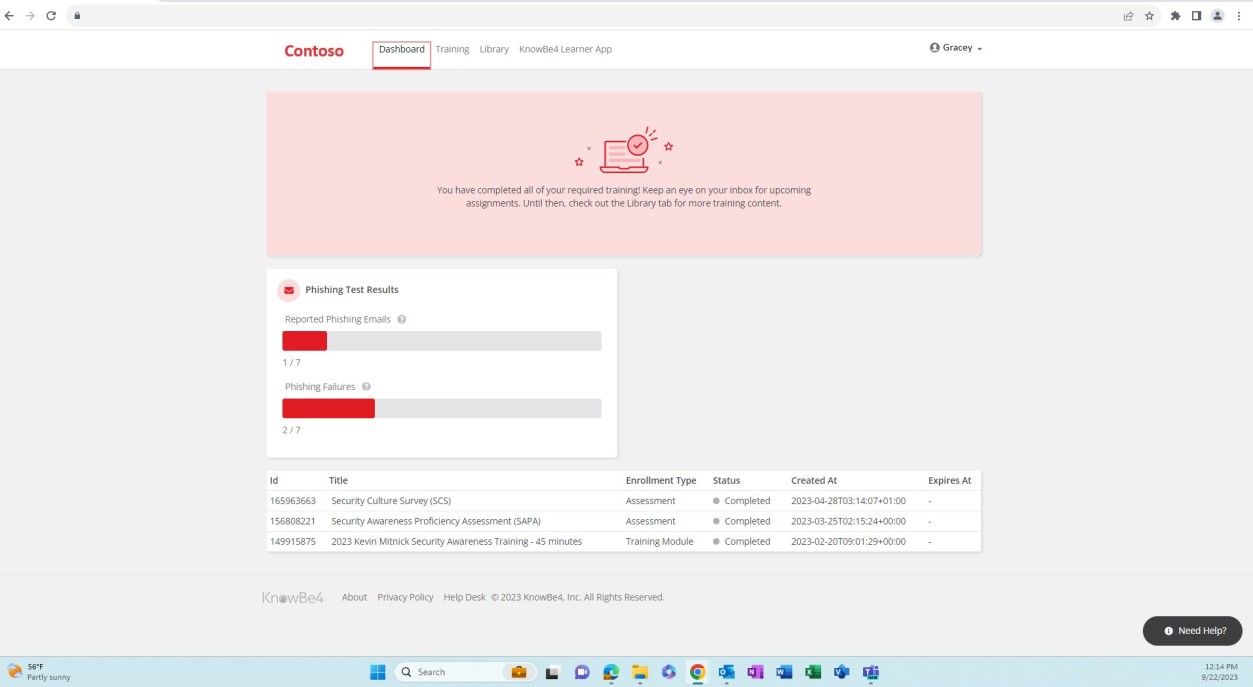
На следующих двух снимках экрана показано успешное завершение упомянутых ранее оценок обучения. Снимки экрана были сделаны от двух разных сотрудников.
Намерение: документация и мониторинг.
Цель этой подсети — создать, поддерживать и отслеживать тщательные записи об участии каждого пользователя в обучении по повышению осведомленности о безопасности. Эти записи должны храниться в течение определенного организацией периода. Эта документация служит проверяемым журналом для соответствия нормативным требованиям и внутренним политикам. Компонент мониторинга позволяет организации оценивать эффективность
обучение, определение областей для улучшения и понимания уровней вовлеченности пользователей. Сохраняя эти записи в течение определенного периода времени, организация может отслеживать долгосрочную эффективность и соответствие требованиям.
Рекомендации: документация и мониторинг.
Доказательства, которые могут быть предоставлены для обучения по повышению осведомленности о безопасности, будут зависеть от того, как обучение реализуется на уровне организации. Это может быть связано с тем, проводится ли обучение через платформу или выполняется внутри организации на основе внутреннего процесса. Предоставленные данные должны свидетельствовать о наличии исторических записей обучения, завершенных для всех пользователей в течение определенного периода, и о том, как это отслеживается.
Примеры доказательств: документация и мониторинг.
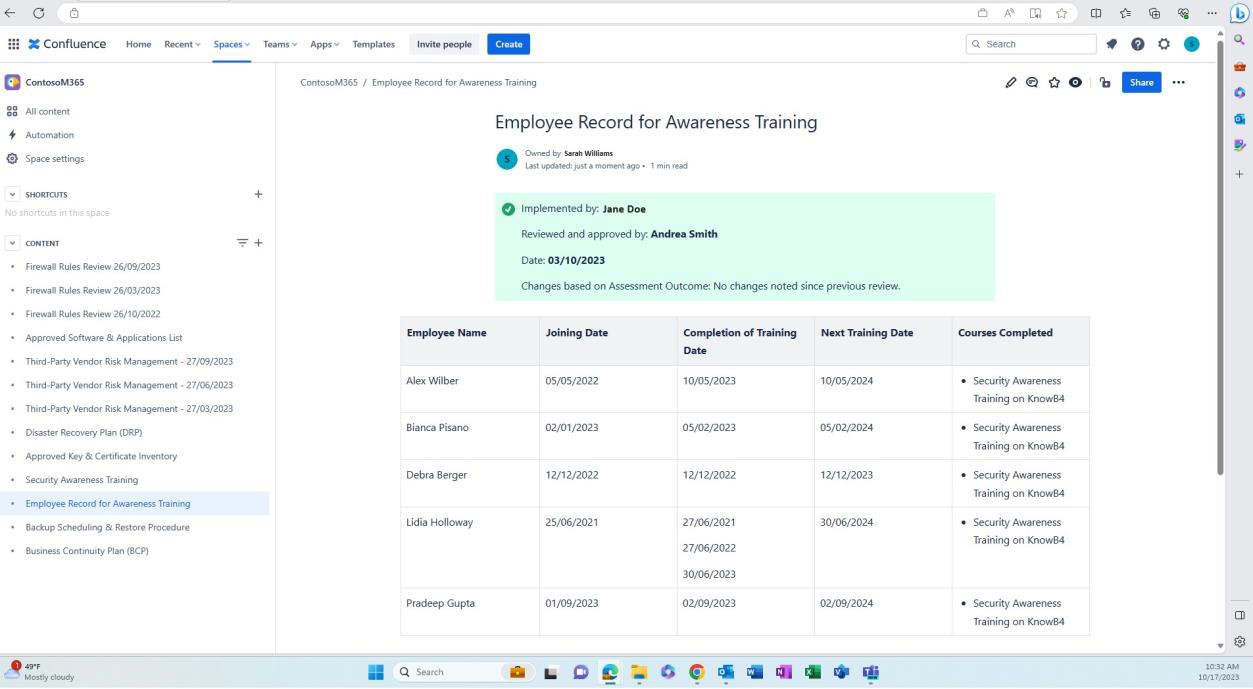
На следующем снимку экрана показана историческая запись обучения для каждого пользователя, включая дату присоединения, завершение обучения и время планирования следующего обучения. Оценка этого документа выполняется периодически и не реже одного раза в год, чтобы обеспечить актуальность учебных записей по вопросам безопасности для каждого сотрудника.
Защита от вредоносных программ и защита от вредоносных программ
Вредоносные программы представляют значительный риск для организаций, которые могут изменять влияние на безопасность операционной среды в зависимости от характеристик вредоносных программ. Субъекты угроз поняли, что вредоносные программы могут быть успешно монетизированы, что было реализовано за счет роста вредоносных атак в стиле программ-шантажистов. Вредоносные программы также могут использоваться для предоставления точки входящего трафика субъекту угрозы, чтобы скомпрометировать среду для кражи конфиденциальных данных, т. е. троянов или rootkits удаленного доступа. Поэтому организациям необходимо внедрить подходящие механизмы для защиты от этих угроз. Средства защиты, которые можно использовать: антивирусная (AV)/Обнаружение конечных точек и реагирование (EDR)/Обнаружение конечных точек и реагирование на них (EDPR)/Эвристическое сканирование с помощью искусственного интеллекта (ИИ). Если вы развернули другую методику для снижения риска вредоносных программ, сообщите аналитику по сертификации, кто будет рад узнать, соответствует ли это намерению.
Элемент управления No 2
Предоставьте доказательства того, что ваше решение для защиты от вредоносных программ активно и включено во всех примерах системных компонентов и настроено в соответствии со следующими критериями:
Значение , если антивирусная программа, которая включена проверка доступа и что сигнатуры обновлены в течение 1 дня.
для антивирусной программы, которая автоматически блокирует вредоносные программы или оповещения и помещает в карантин при обнаружении вредоносных программ;
ИЛИ, если EDR/EDPR/NGAV:
что выполняется периодическое сканирование.
создает журналы аудита.
постоянно обновляется и обладает возможностями самообучения.
он блокирует известные вредоносные программы и определяет и блокирует новые варианты вредоносных программ на основе макрокоманды, а также с полными возможностями квоты.
Намерение: сканирование при доступе
Эта подсеть предназначена для проверки того, что программное обеспечение для защиты от вредоносных программ установлено во всех примерах системных компонентов и активно выполняет проверку доступа. Элемент управления также требует, чтобы база данных сигнатур решения для защиты от вредоносных программ обновлялась в течение одного дня. Актуальная база данных сигнатур имеет решающее значение для выявления и устранения последних угроз вредоносных программ, обеспечивая тем самым надлежащую защиту компонентов системы.
Рекомендации: проверка доступа**.**
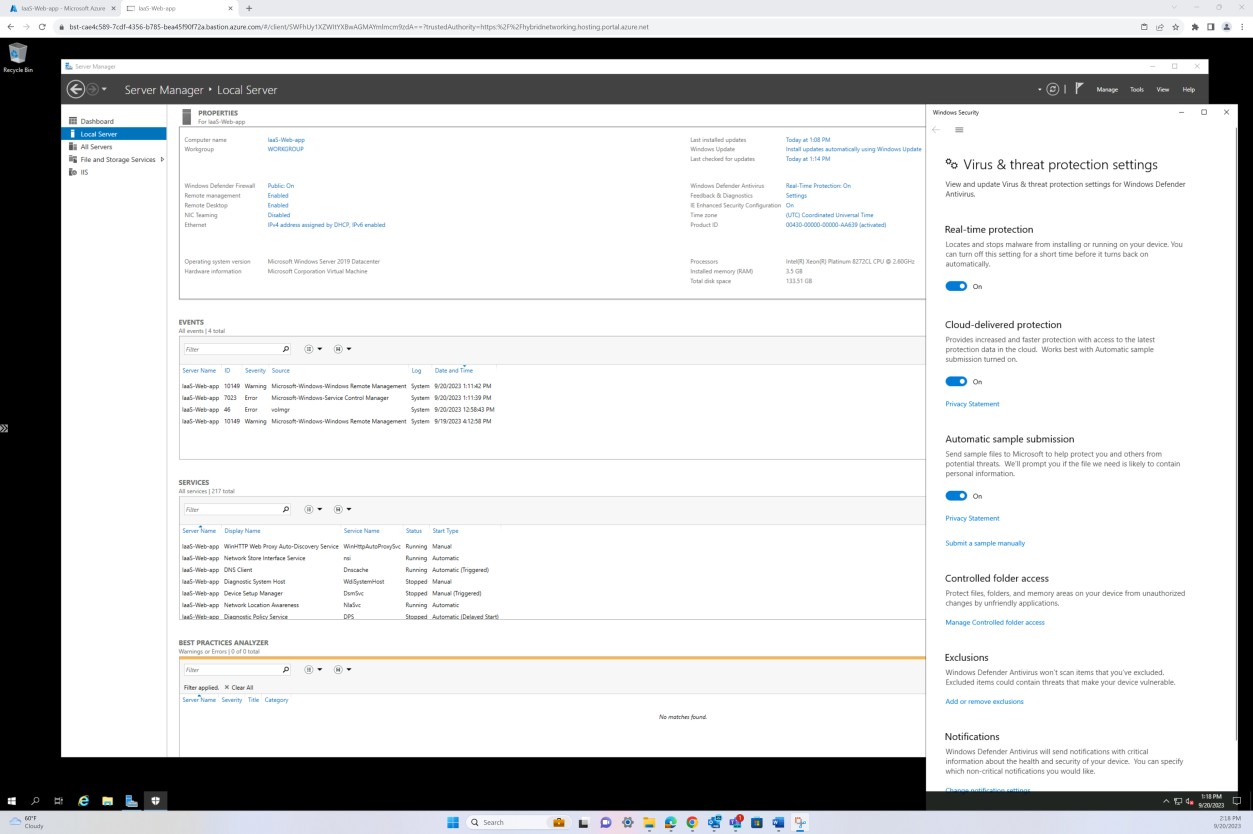
Чтобы продемонстрировать, что активный экземпляр AV работает в оцениваемой среде, предоставьте снимок экрана для каждого устройства в наборе примеров, согласованных с аналитиком, который поддерживает использование защиты от вредоносных программ. На снимку экрана должно быть показано, что программа защиты от вредоносных программ запущена, а также что программа для защиты от вредоносных программ активна. Если существует централизованная консоль управления для защиты от вредоносных программ, могут быть предоставлены доказательства из консоли управления. Кроме того, убедитесь, что укажите снимок экрана, на котором показано, что устройства подключены и работают.
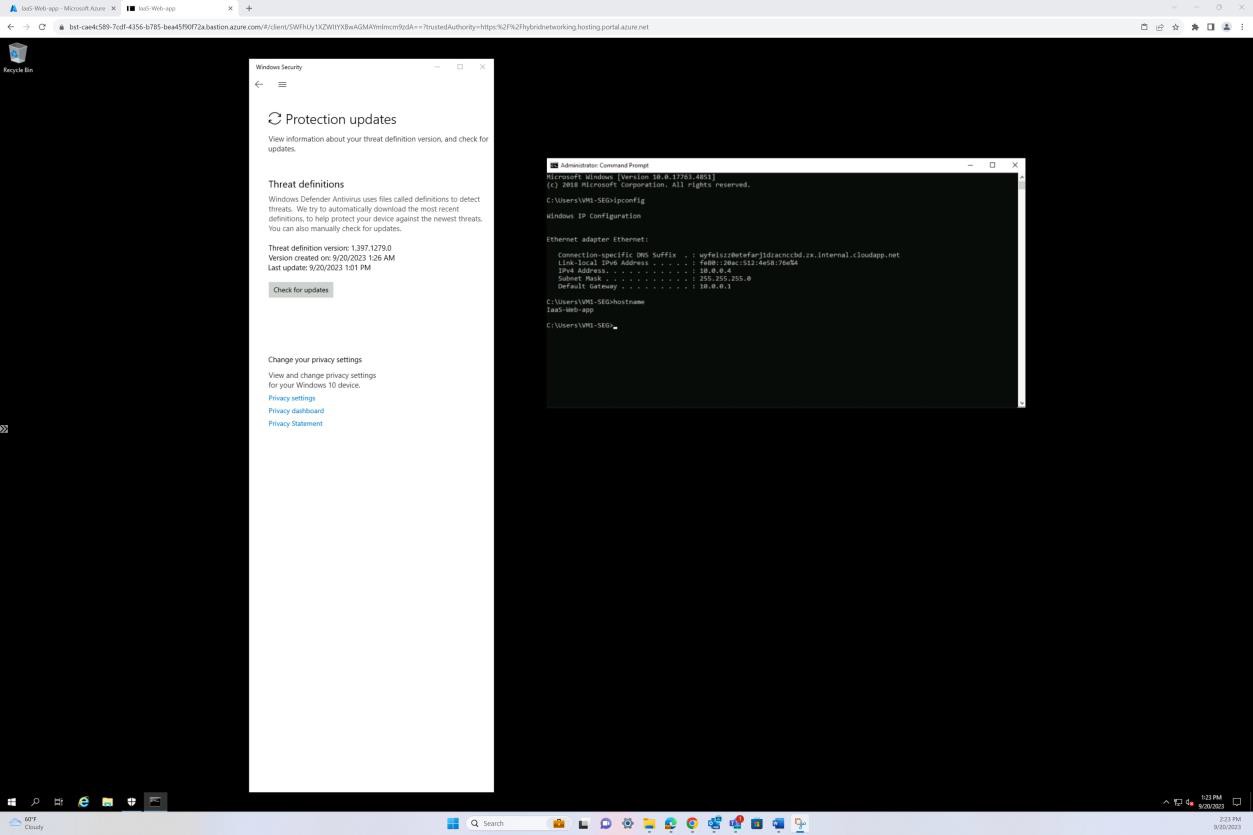
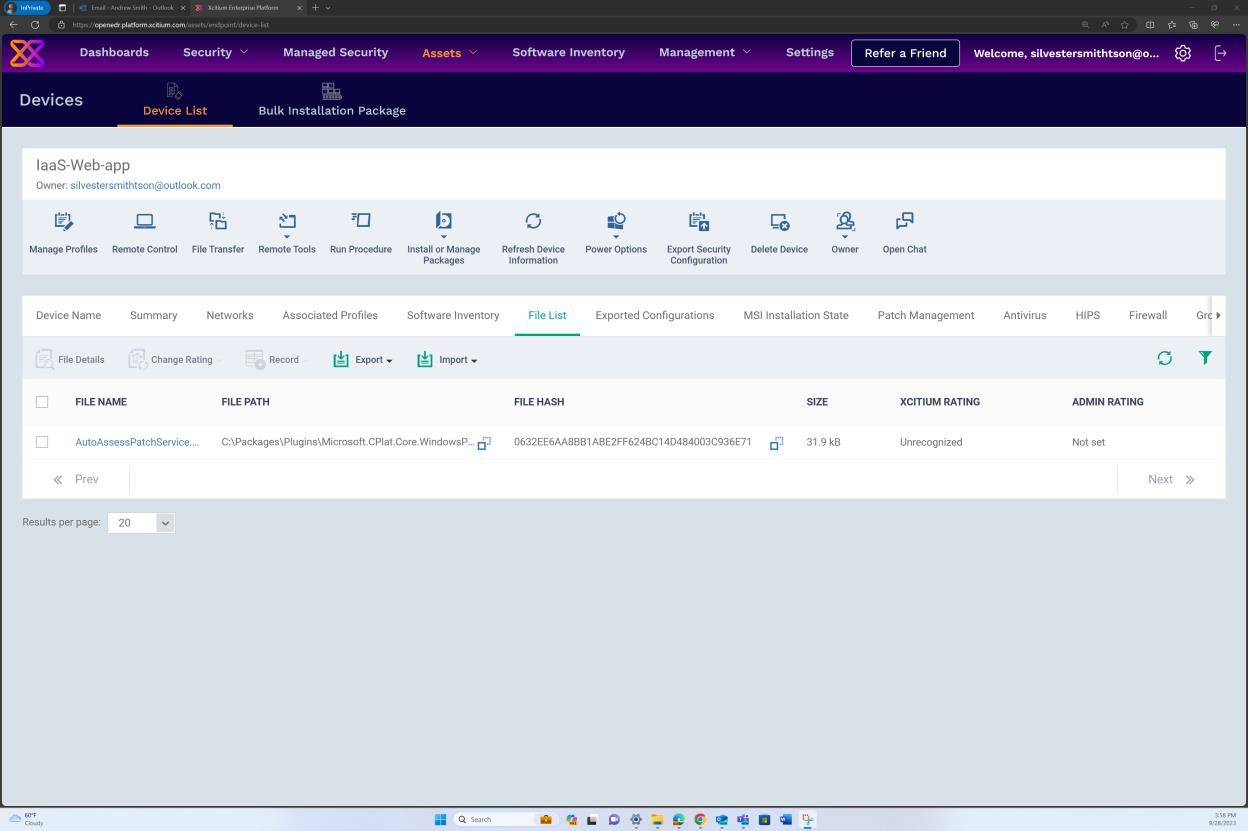
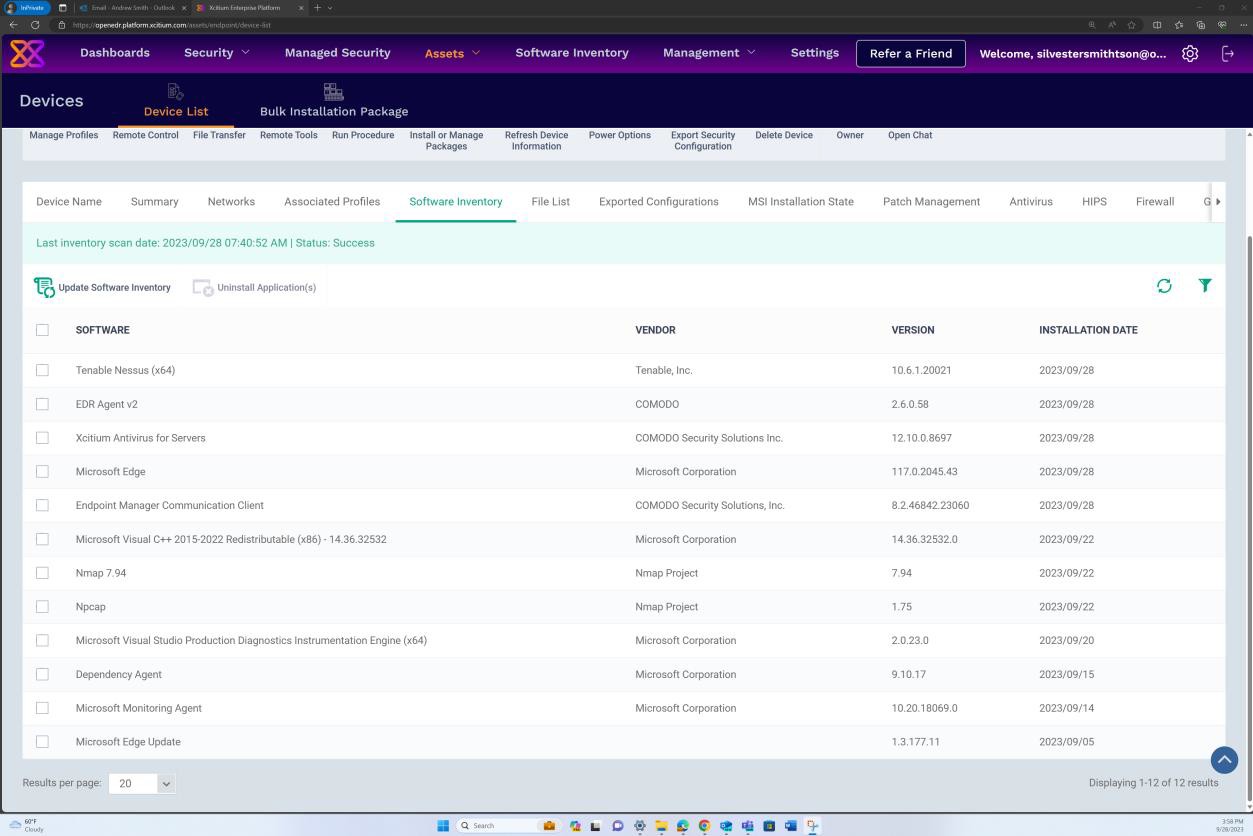
Пример доказательства: сканирование при доступе**.**
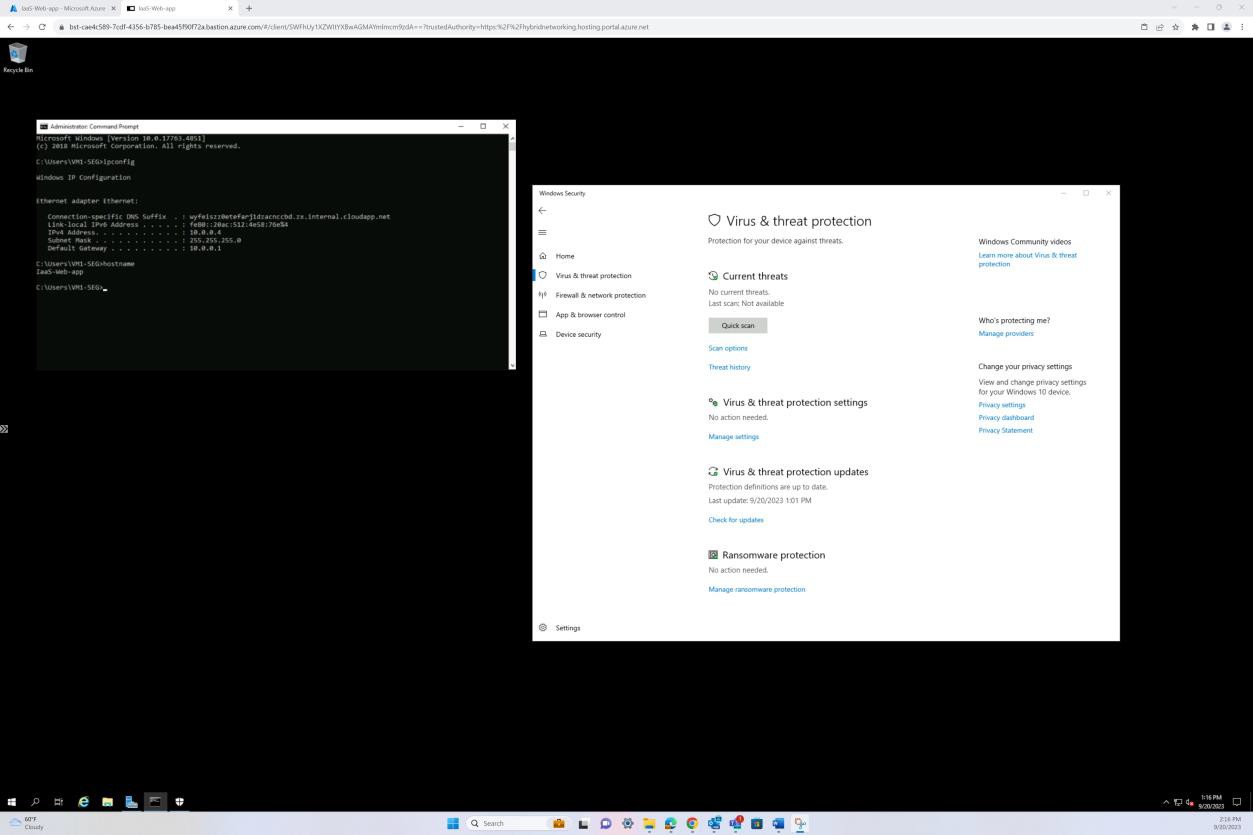
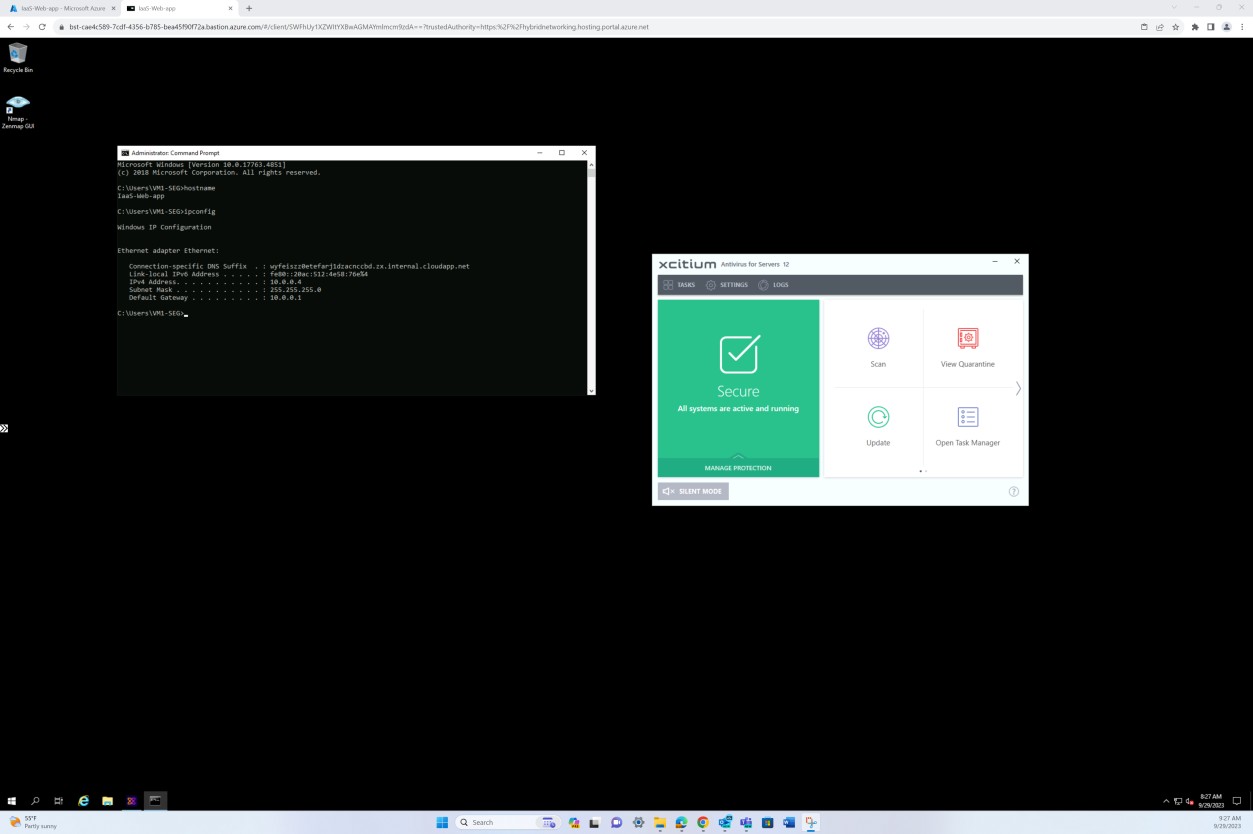
Следующий снимок экрана был сделан с устройства Windows Server, показывающий, что microsoft Defender включен для имени узла IaaS-Web-app.
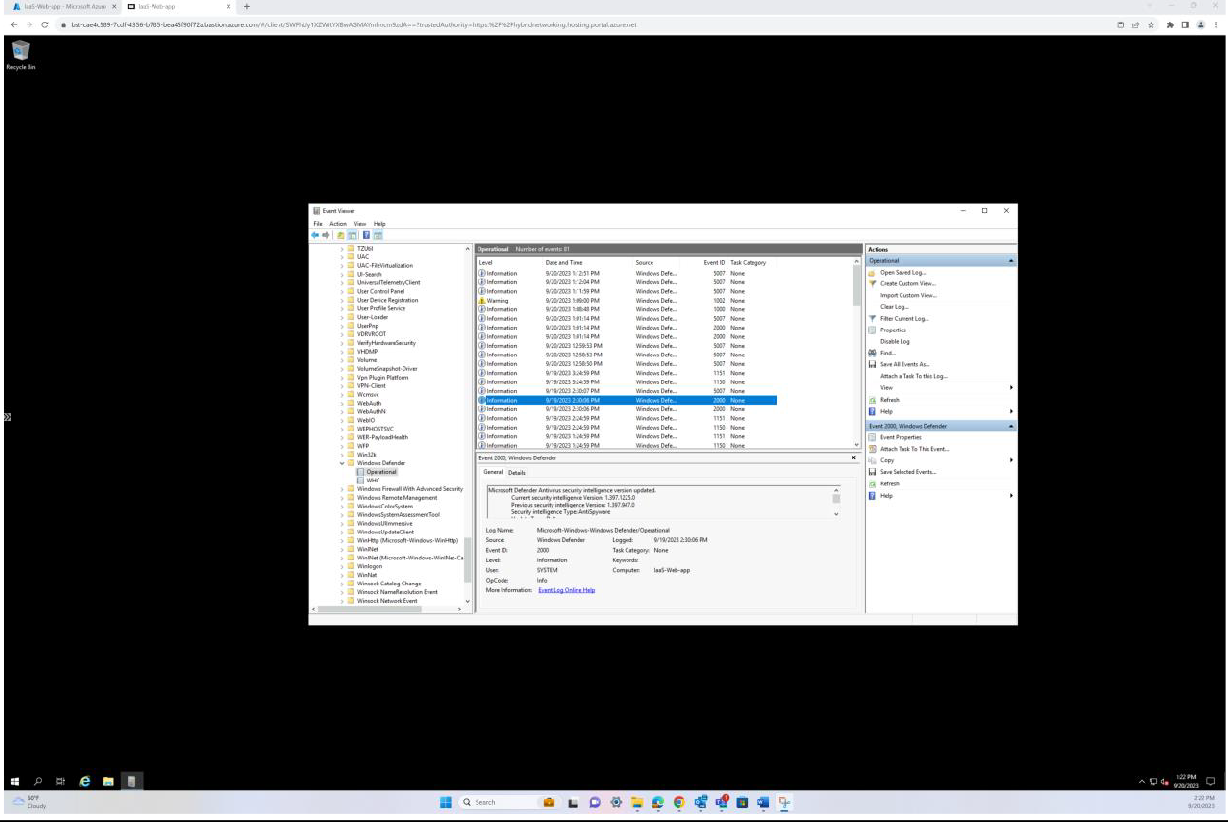
Следующий снимок экрана был сделан с устройства Windows Server, на котором показано, как версия аналитики безопасности в Microsoft Defender для защиты от вредоносных программ обновила журнал из средства просмотра событий Windows. Здесь показаны последние подписи для имени узла IaaS-Web-app.
Этот снимок экрана был сделан с устройства Windows Server, где показаны обновления защиты от вредоносных программ в Microsoft Defender. Здесь четко отображаются версии определений угроз, версии, созданные в и последнее обновление, чтобы продемонстрировать актуальность определений вредоносных программ для имени узла "IaaS-Web-app".
Намерение: блоки защиты от вредоносных программ.
Цель этой подпочты — убедиться, что программа для защиты от вредоносных программ настроена для автоматической блокировки вредоносных программ при обнаружении или создании оповещений и перемещении обнаруженных вредоносных программ в безопасную зону карантина. Это может гарантировать, что при обнаружении угрозы будут приняты немедленные меры, уменьшая окно уязвимостей и сохраняя надежную безопасность системы.
Рекомендации. Блоки защиты от вредоносных программ.
Предоставьте снимок экрана для каждого устройства в примере, которое поддерживает использование защиты от вредоносных программ. Снимок экрана должен показать, что защита от вредоносных программ запущена и настроена для автоматической блокировки вредоносных программ, оповещения или для карантина и оповещения.
Пример доказательства: блоки защиты от вредоносных программ.
На следующем снимку экрана показано, как узел IaaS-Web-app настроен с защитой в режиме реального времени как ON для антивредоносного ПО Microsoft Defender. Как говорится в параметре, это позволяет найти и остановить установку или запуск вредоносных программ на устройстве.
Намерение: EDR/NGAV
Эта подсеть направлена на то, чтобы убедиться, что обнаружение и реагирование конечных точек (EDR) или антивирусная программа следующего поколения (NGAV) активно выполняет периодические проверки всех выборочных системных компонентов. журналы аудита создаются для отслеживания действий и результатов сканирования; решение для сканирования постоянно обновляется и обладает возможностями самостоятельного обучения для адаптации к новым ландшафтам угроз.
Рекомендации: EDR/NGAV
Предоставьте снимок экрана из решения EDR/NGAV, на котором показано, что все агенты из выборки систем сообщают в и что их состояние активно.
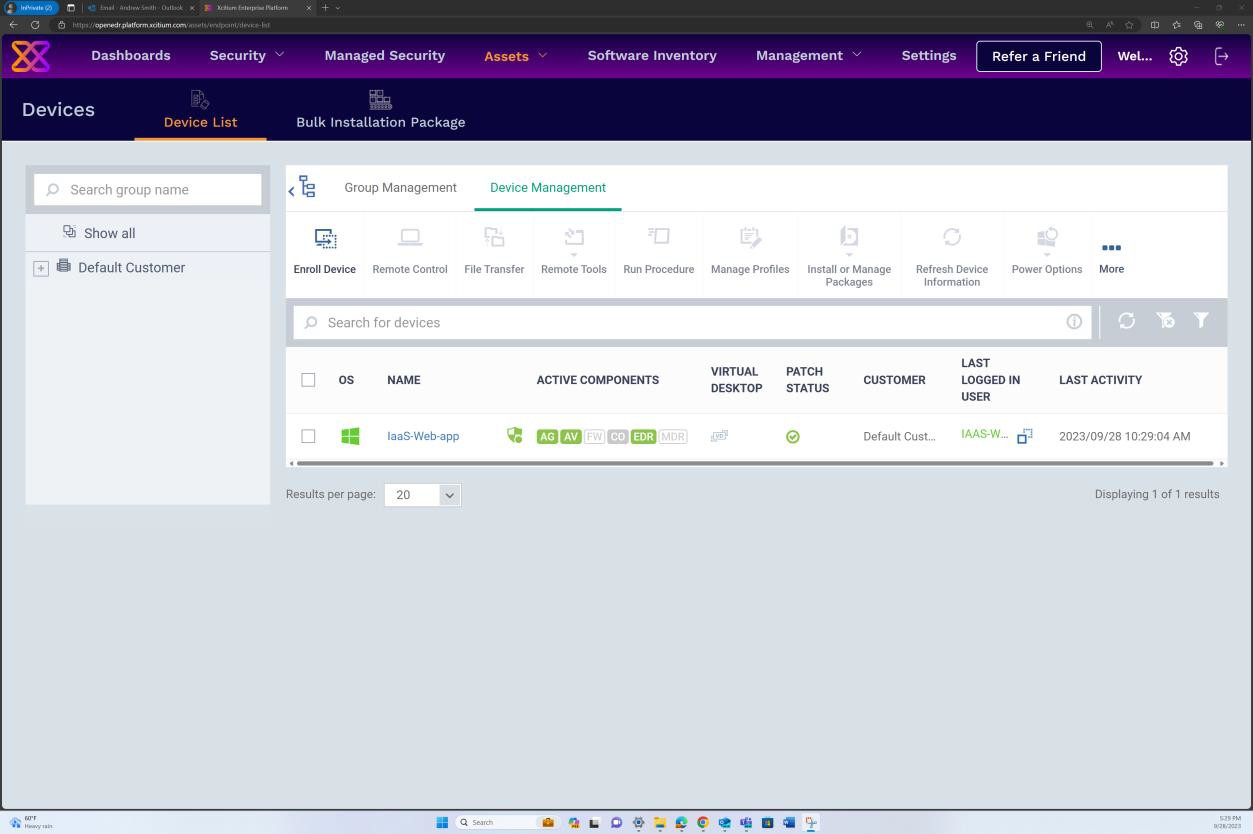
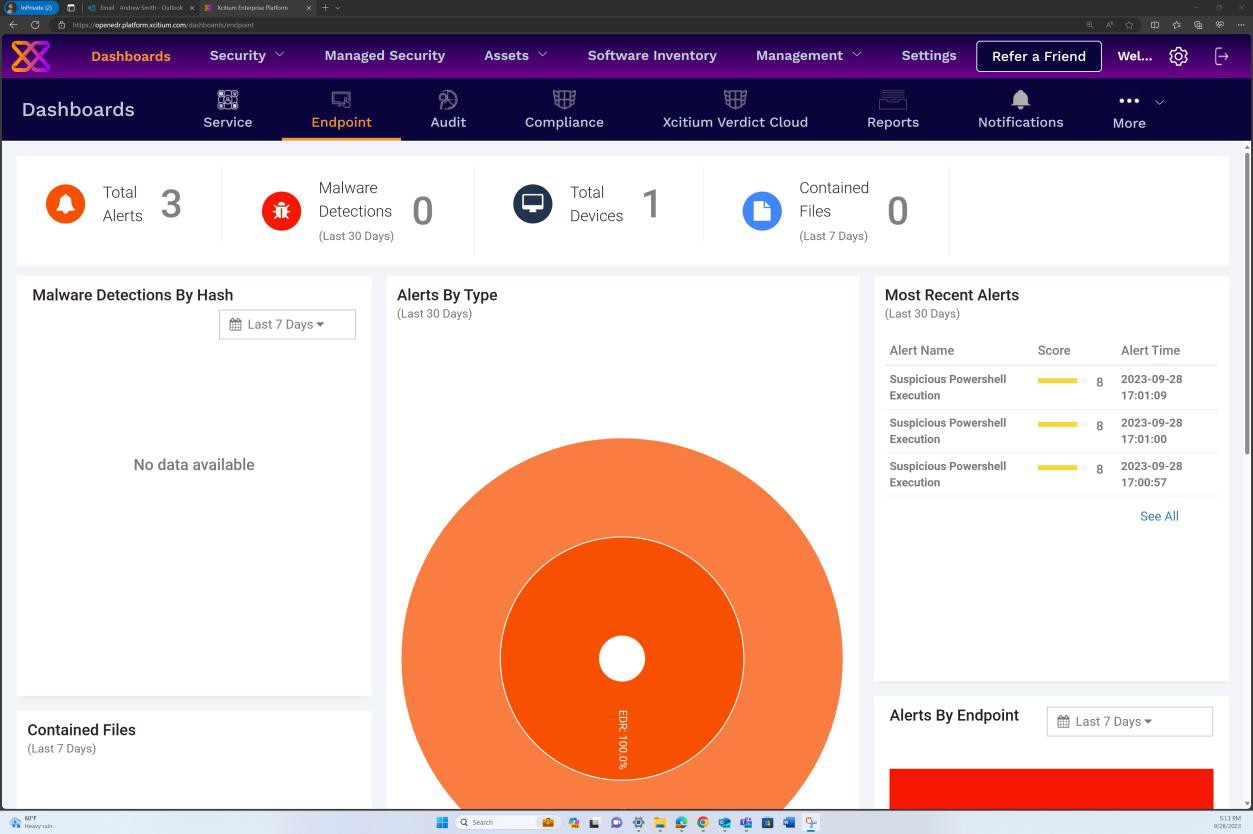
Пример доказательства: EDR/NGAV
На следующем снимке экрана из решения OpenEDR показано, что агент для узла "IaaS-Web-app" активен и сообщает в.
На следующем снимку экрана из решения OpenEDR показано, что сканирование в режиме реального времени включено.
На следующем снимке экрана показано, что оповещения создаются на основе метрик поведения, полученных в режиме реального времени из агента, установленного на уровне системы.
На следующих снимках экрана из решения OpenEDR показана конфигурация и создание журналов аудита и оповещений. На втором изображении показано, что политика включена и события настроены.
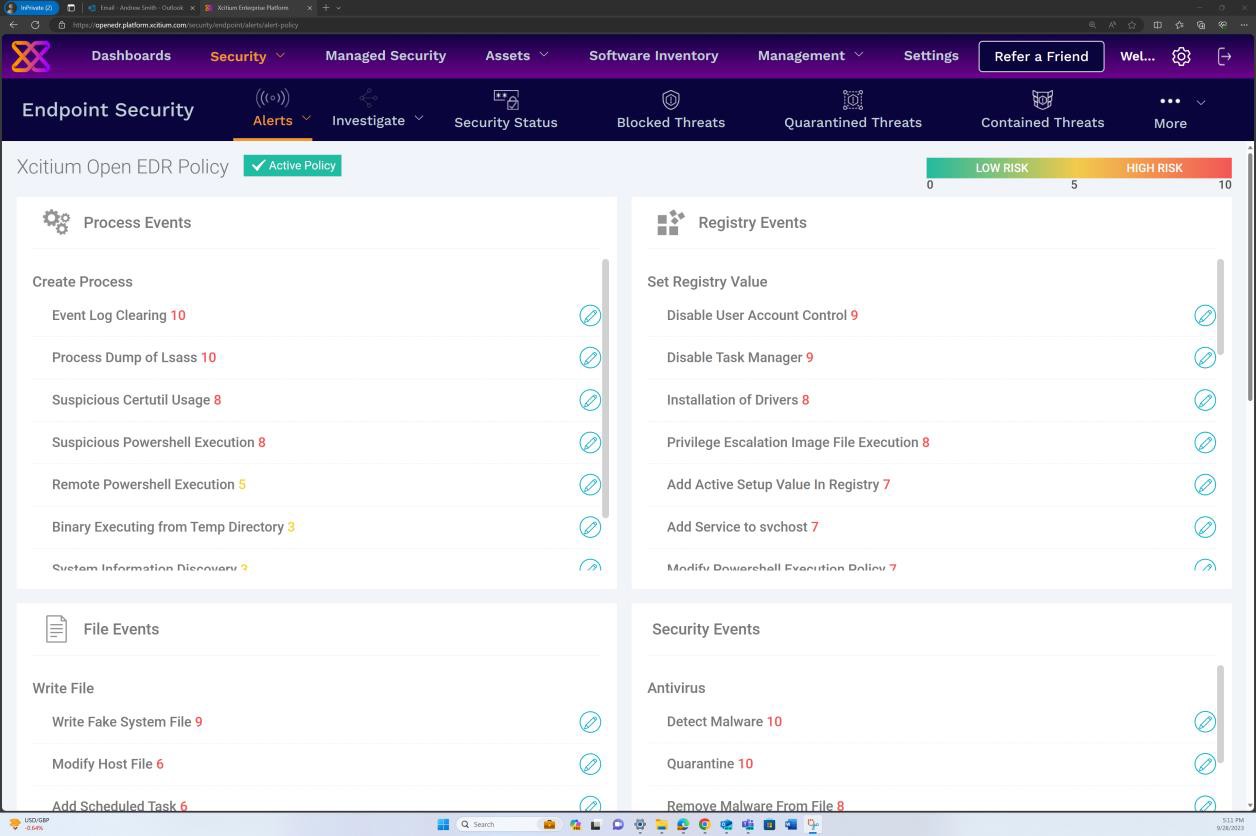
На следующем снимку экрана из решения OpenEDR показано, что решение постоянно обновляется.
Намерение: EDR/NGAV
Основное внимание в этой подзапункте уделяется тому, чтобы EDR/NGAV могли автоматически блокировать известные вредоносные программы, а также выявлять и блокировать новые варианты вредоносных программ на основе макрокоманды. Это также гарантирует, что решение имеет полные возможности утверждения, что позволяет организации разрешать доверенное программное обеспечение, блокируя все остальные, тем самым добавляя дополнительный уровень безопасности.
Рекомендации: EDR/NGAV
В зависимости от типа используемого решения можно предоставить свидетельство о параметрах конфигурации решения и о том, что решение обладает возможностями машинного обучения и эвристики, а также настроено для блокировки вредоносных программ при обнаружении. Если конфигурация реализована по умолчанию в решении, это должно быть проверено документацией поставщика.
Пример доказательства: EDR/NGAV
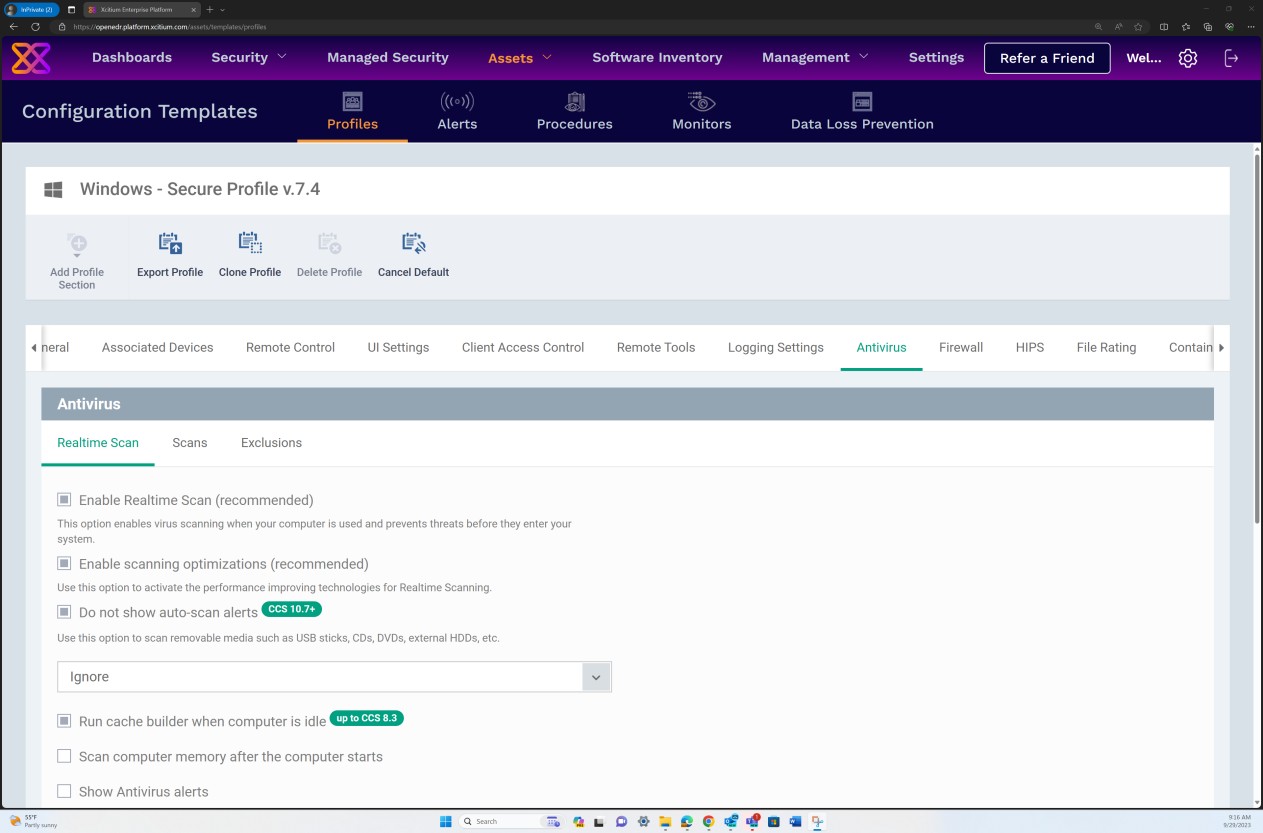
На следующих снимках экрана из решения OpenEDR показано, что защищенный профиль версии 7.4 настроен для принудительного проверки в режиме реального времени, блокировки вредоносных программ и карантина.
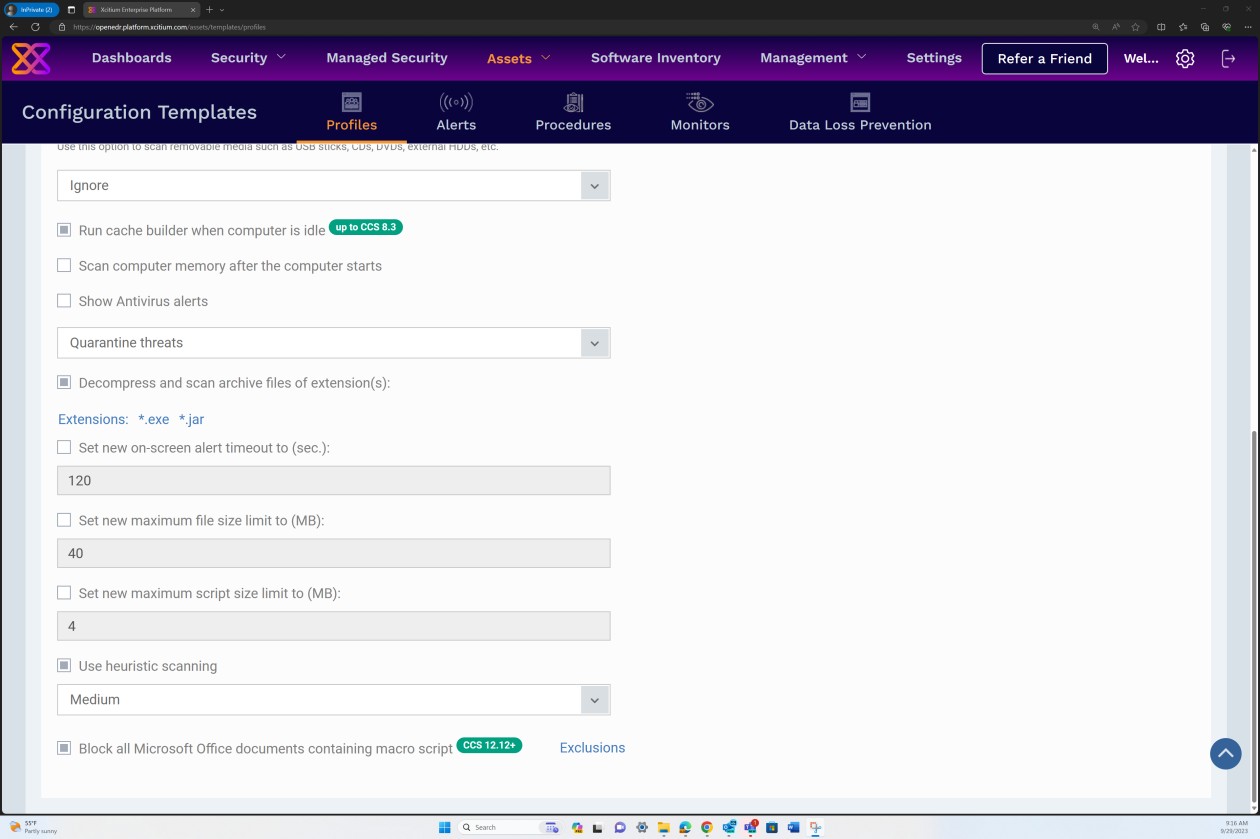
На следующих снимках экрана из конфигурации Secure Profile версии 7.4 показано, что решение реализует проверку в режиме реального времени, основанную на более традиционном подходе защиты от вредоносных программ, который проверяет наличие известных сигнатур вредоносных программ, и проверку "Эвристика", установленную на средний уровень. Решение обнаруживает и удаляет вредоносные программы, проверяя файлы и код, которые ведут себя подозрительным, непредвиденным или вредоносным образом.
Сканер настроен для распаковки архивов и сканирования файлов внутри, чтобы обнаружить потенциальные вредоносные программы, которые могут маскироваться под архивом. Кроме того, средство проверки настроено для блокировки микро-скриптов в файлах Microsoft Office.
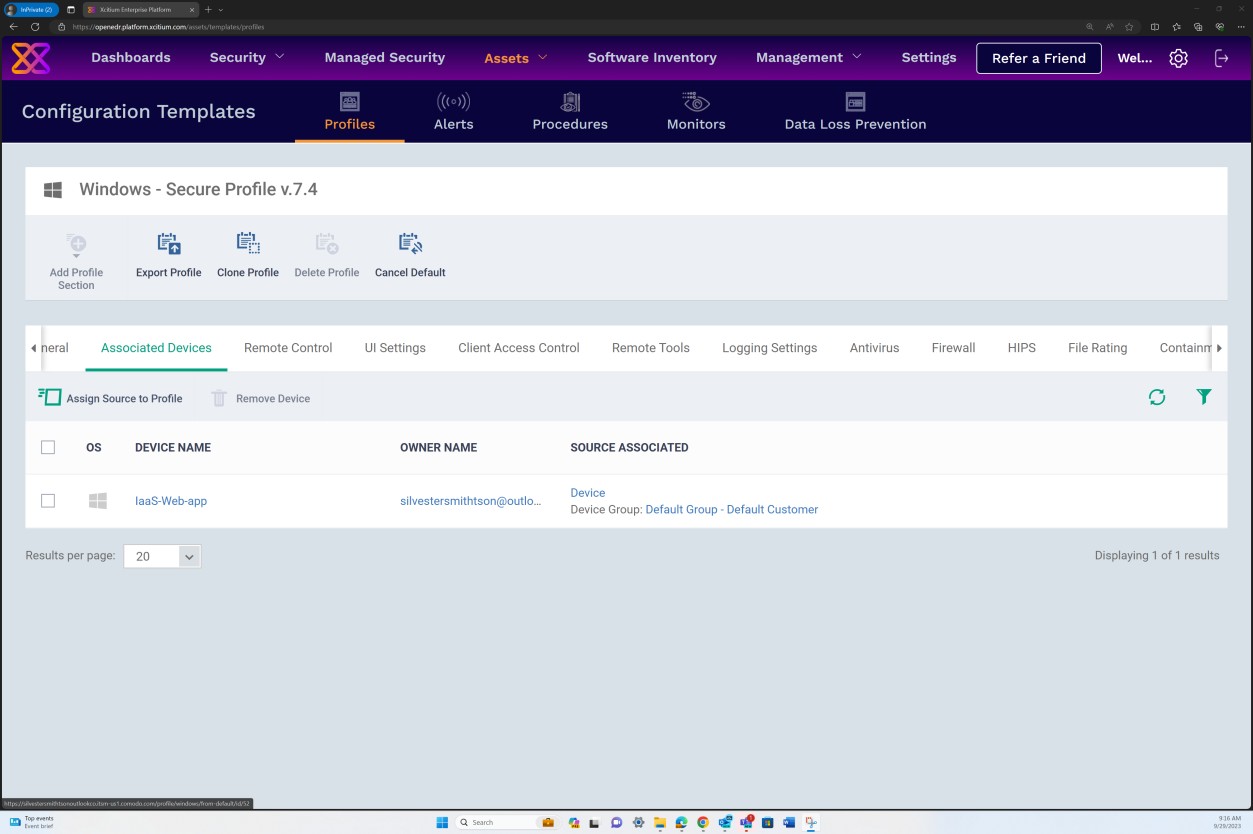
На следующих снимках экрана показано, что защищенный профиль версии 7.4 назначен узлу IaaS-Web-app устройства Windows Server.
Следующий снимок экрана был сделан с устройства Windows Server IaaS-Web-app, на котором показано, что агент OpenEDR включен и работает на узле.
Защита от вредоносных программ и управление приложениями
Управление приложениями — это практика безопасности, которая блокирует или ограничивает выполнение несанкционированных приложений способами, которые подвергают риску данные. Элементы управления приложениями являются важной частью программы корпоративной безопасности и могут помочь предотвратить использование злоумышленниками уязвимостей приложений и снизить риск нарушения безопасности. Реализуя управление приложениями, предприятия и организации могут значительно снизить риски и угрозы, связанные с использованием приложений, так как приложения не могут выполняться, если они подвергают риску сеть или конфиденциальные данные. Средства управления приложениями предоставляют группам операций и безопасности надежный, стандартизированный и систематический подход к снижению кибер-рисков. Они также дают организациям более полное представление о приложениях в их среде, что может помочь ИТ-организациям и организациям безопасности эффективно управлять кибер-рисками.
Элемент управления No 3
Предоставьте доказательства того, что:
У вас есть утвержденный список программного обеспечения или приложений с бизнес-обоснованием:
существует и поддерживается в актуальном состоянии, и
каждое приложение проходит процесс утверждения и подписывается перед развертыванием.
Эта технология управления приложениями активна, включена и настроена во всех примерах системных компонентов, как описано в документе.
Намерение: список программного обеспечения
Эта подпоставка направлена на обеспечение того, чтобы утвержденный список программного обеспечения и приложений существовал в организации и постоянно обновлялся. Убедитесь, что каждое программное обеспечение или приложение в списке имеет задокументированные бизнес-обоснования для проверки их необходимости. Этот список служит авторитетной ссылкой для регулирования развертывания программного обеспечения и приложений, что способствует устранению несанкционированного или избыточного программного обеспечения, которое может представлять угрозу безопасности.
Рекомендации: список программного обеспечения
Документ, содержащий утвержденный список программного обеспечения и приложений, если он хранится в виде цифрового документа (Word, PDF и т. д.). Если утвержденный список программного обеспечения и приложений поддерживается через платформу, необходимо предоставить снимки экрана списка с платформы.
Пример доказательства: список программного обеспечения
На следующих снимках экрана показано, что список утвержденных программ и приложений поддерживается на платформе Confluence Cloud.
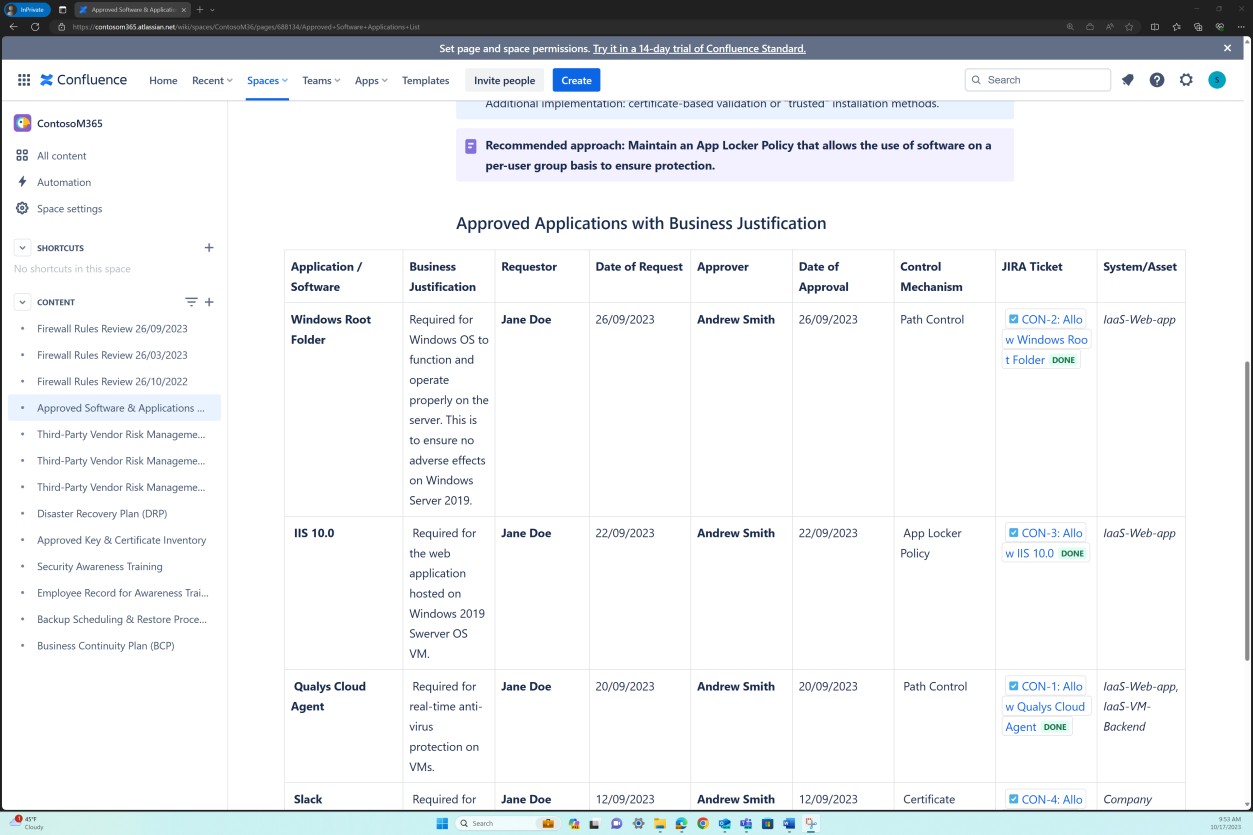
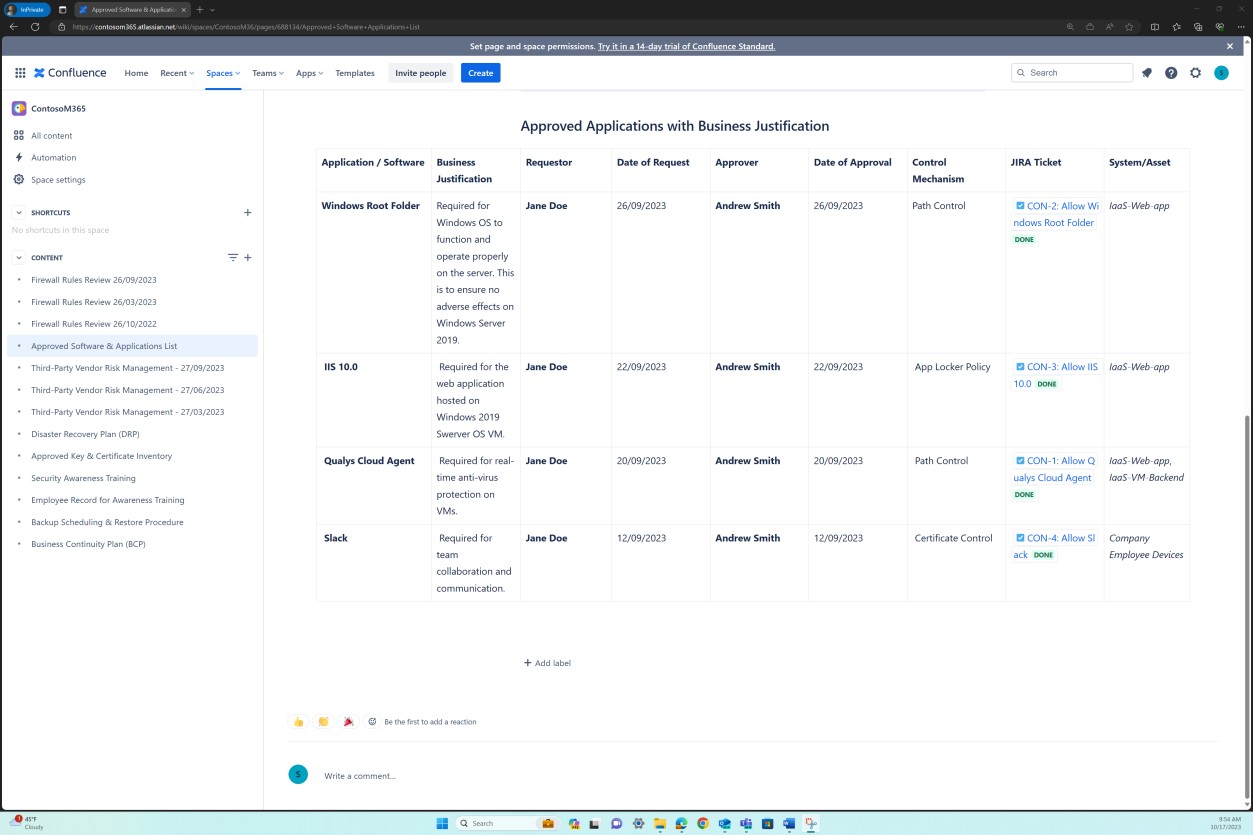
На следующих снимках экрана показано, что список утвержденного программного обеспечения и приложений, включая инициатор запроса, дату запроса, утверждающий, дату утверждения, механизм управления, билет JIRA, систему или ресурс, поддерживается.
Намерение: утверждение программного обеспечения
Цель этой подпочты — подтвердить, что каждое программное обеспечение или приложение проходит формальный процесс утверждения перед развертыванием в организации. Процесс утверждения должен содержать техническую оценку и исполнительный выход, обеспечивающий учет как оперативных, так и стратегических перспектив. Создавая этот строгий процесс, организация обеспечивает развертывание только проверенного и необходимого программного обеспечения, тем самым минимизируя уязвимости системы безопасности и обеспечивая соответствие бизнес-целям.
Рекомендации
Можно предоставить доказательства того, что процесс утверждения выполняется. Это может быть предоставлено с помощью подписанных документов, отслеживания в системах управления изменениями или использования azure DevOps/JIRA для отслеживания запросов на изменение и авторизации.
Пример доказательства
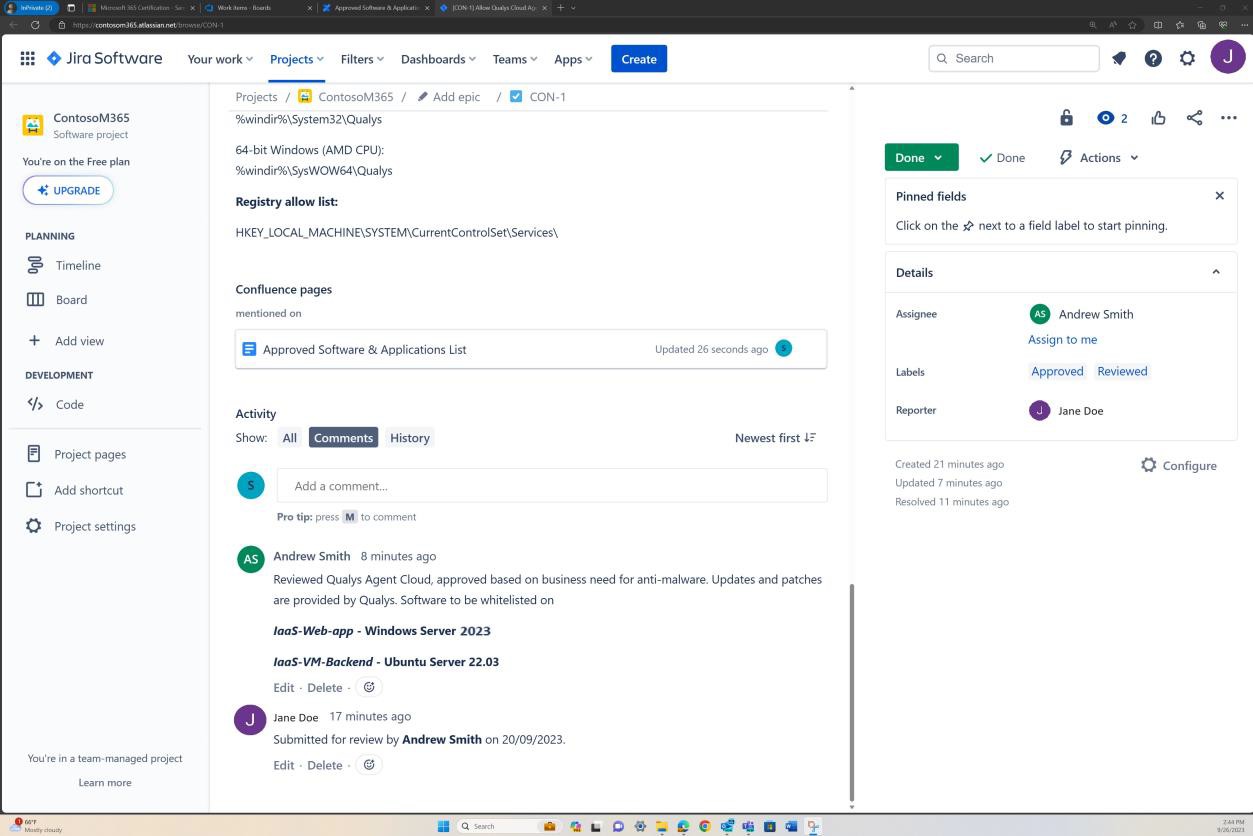
На следующих снимках экрана показан полный процесс утверждения в JIRA Software. Пользователь Jane Doe поднял запрос на установку "Разрешить облачный агент Qualys" на серверах IaaS-Web-app и IaaS-VM- Backend. "Эндрю Смит" рассмотрел запрос и одобрил его с комментарием "утвержден на основе бизнес-потребности в защите от вредоносных программ. Обновления и исправления, предоставляемые Qualys. Программное обеспечение, которое требуется утвердить.
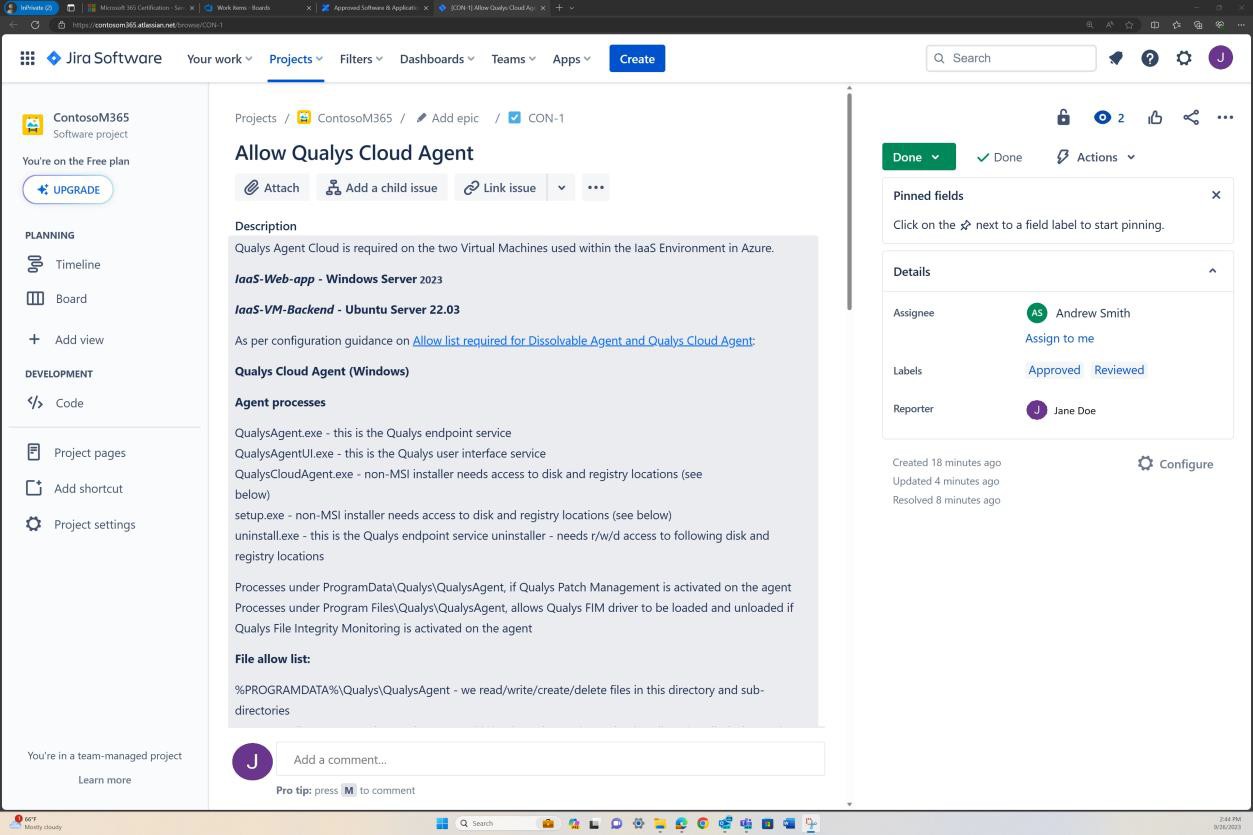
На следующем снимку экрана показано, как утверждение предоставляется с помощью билета, выданного на платформе Confluence, прежде чем разрешить запуск приложения на рабочем сервере.
Намерение: технология управления приложениями
В этом разделе основное внимание уделяется проверке активности, включения и правильности настройки технологии управления приложениями во всех примерах системных компонентов. Убедитесь, что технология работает в соответствии с документироваными политиками и процедурами, которые служат руководящими принципами для ее реализации и обслуживания. Имея активную, включенную и хорошо настроенную технологию управления приложениями, организация может помочь предотвратить выполнение несанкционированного или вредоносного программного обеспечения и повысить общую безопасность системы.
Рекомендации: технология управления приложениями
Предоставьте документацию, в которой подробно описывается настройка управления приложениями, а также сведения о том, как настроено каждое приложение или процесс.
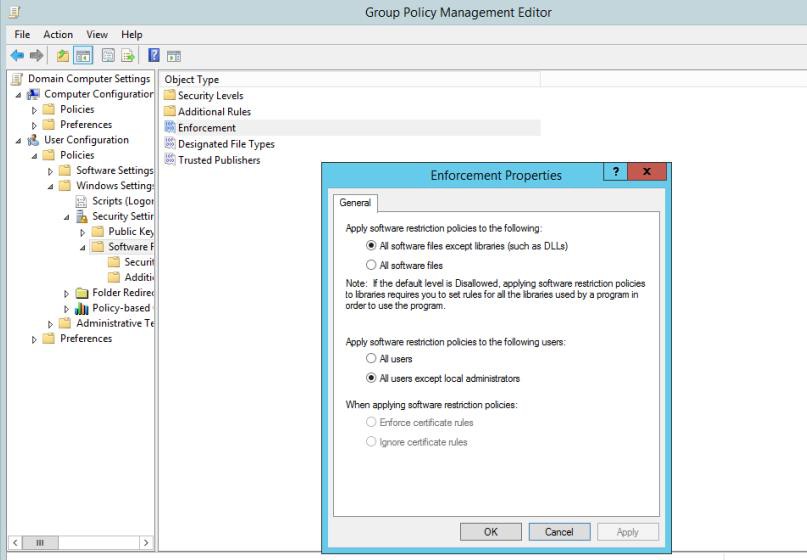
Пример доказательства: технология управления приложениями
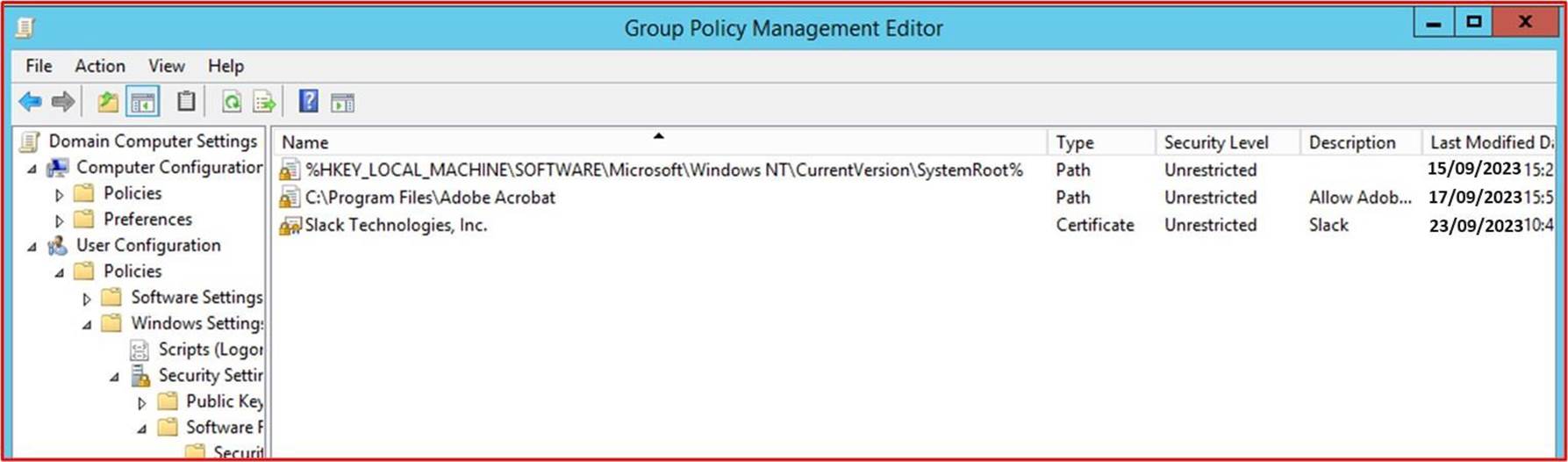
На следующих снимках экрана показано, что групповые политики Windows (GPO) настроены для принудительного применения только утвержденного программного обеспечения и приложений.
На следующем снимку экрана показано программное обеспечение или приложения, которые разрешено запускать с помощью элемента управления путем.
Примечание. В этих примерах полные снимки экрана не использовались, однако все снимки экрана, отправленные isV, должны быть полноэкранными снимками экрана с любым URL-адресом, вошедшего в систему пользователя, а также системным временем и датой.
Управление исправлениями и ранжирование рисков
Управление исправлениями, часто называемое исправлением, является критически важным компонентом любой надежной стратегии кибербезопасности. Она включает систематический процесс выявления, тестирования и применения исправлений или обновлений к программному обеспечению, операционным системам и приложениям. Основная цель управления исправлениями заключается в устранении уязвимостей системы безопасности, обеспечивая устойчивость систем и программного обеспечения к потенциальным угрозам. Кроме того, управление исправлениями включает в себя ранжирование рисков, что является жизненно важным элементом при определении приоритета исправлений. Это предполагает оценку уязвимостей на основе их серьезности и потенциального влияния на состояние безопасности организации. Присваивая оценки риска уязвимостям, организации могут эффективно распределять ресурсы, концентрируя свои усилия на оперативном устранении критически важных уязвимостей и уязвимостей с высоким риском, сохраняя упреждающую позицию по борьбе с новыми угрозами. Эффективная стратегия управления исправлениями и ранжирования рисков не только повышает безопасность, но и способствует общей стабильности и производительности ИТ-инфраструктуры, помогая организациям оставаться устойчивыми в постоянно развивающемся ландшафте угроз кибербезопасности.
Для обеспечения безопасной операционной среды приложения, надстройки и вспомогательные системы должны быть соответствующим образом исправлены. Необходимо управлять подходящим временем между идентификацией (или общедоступным выпуском) и установкой исправлений, чтобы уменьшить окно возможностей для использования уязвимости субъектом угрозы. Сертификация Microsoft 365 не предусматривает "Окно исправлений"; однако аналитики сертификации будут отклонять сроки, которые не являются разумными или не соответствуют лучшим отраслевым методикам. Эта группа управления безопасностью также относится к средам размещения "платформа как услуга" (PaaS), так как сторонние библиотеки программного обеспечения приложений и надстроек должны быть исправлены на основе ранжирования рисков.
Элемент управления No 4
Предоставьте доказательства того, что политика управления исправлениями и документация по процедуре определяют все следующее:
Подходящее минимальное окно исправлений для уязвимостей с критическим или высоким и средним риском.
Вывод из эксплуатации неподдерживаемых операционных систем и программного обеспечения.
Выявление новых уязвимостей системы безопасности и присвоение оценки риска.
Намерение: управление исправлениями
Управление исправлениями требуется для многих платформ соответствия требованиям безопасности, например PCI-DSS, ISO 27001, NIST (SP) 800-53, FedRAMP и SOC 2. Важность правильного управления исправлениями не может быть подчеркнутой
как это может исправить проблемы безопасности и функциональности в программном обеспечении, встроенном ПО и устранить уязвимости, что помогает сократить возможности для эксплуатации. Цель этого элемента управления заключается в том, чтобы свести к минимуму окно возможностей, имеющихся у субъекта угроз, для использования уязвимостей, которые могут существовать в среде в области.
Предоставьте политику управления исправлениями и документацию по процедуре, в которой подробно рассматриваются следующие аспекты:
Подходящее минимальное окно исправлений для уязвимостей с критическим или высоким и средним риском.
Политика управления исправлениями и документация по процедуре организации должны четко определить подходящий минимальный период исправления для уязвимостей, классифицированных как критические, высокие и средние риски. Такое положение устанавливает максимально допустимое время, в течение которого после выявления уязвимости должны применяться исправления, исходя из уровня риска. Явно указав эти временные рамки, организация стандартизировала свой подход к управлению исправлениями, сводя к минимуму риск, связанный с неисправными уязвимостями.
Вывод из эксплуатации неподдерживаемых операционных систем и программного обеспечения.
Политика управления исправлениями включает положения о списании неподдерживаемых операционных систем и программного обеспечения. Операционные системы и программное обеспечение, которые больше не получают обновления системы безопасности, представляют значительный риск для системы безопасности организации. Таким образом, этот элемент управления обеспечивает своевременное выявление и удаление или замену таких систем, как определено в документации по политике.
- Документированные процедуры, в которых описывается выявление новых уязвимостей системы безопасности и присвоение оценки риска.
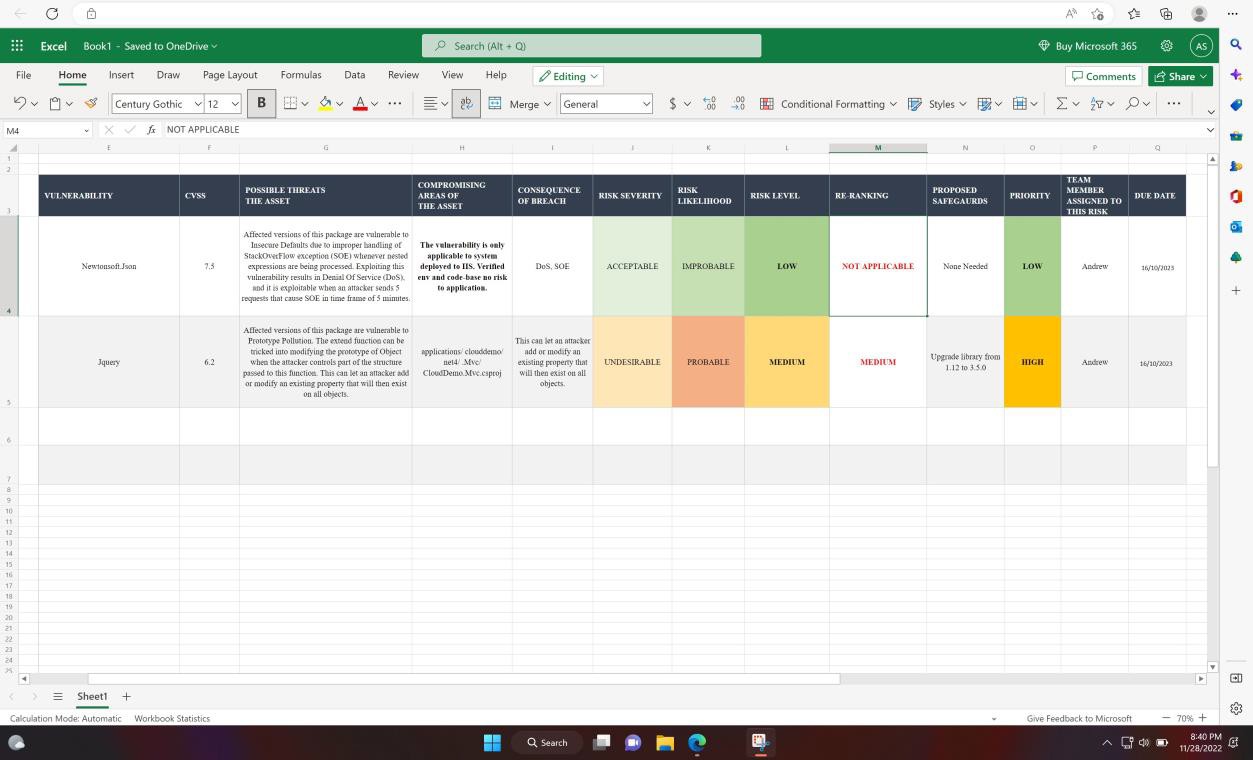
Исправление должно основываться на риске, чем рискнее уязвимость, тем быстрее ее необходимо исправить. Ранжирование рисков для выявленных уязвимостей является неотъемлемой частью этого процесса. Цель этого элемента управления заключается в том, чтобы обеспечить задокументированный процесс ранжирования рисков, который выполняется, чтобы все выявленные уязвимости были надлежащим образом ранжированы на основе риска. Организации обычно используют рейтинг Common Vulnerability Scoring System (CVSS), предоставленный поставщиками или исследователями безопасности. Если организации используют CVSS, рекомендуется включить в процесс механизм повторного ранжирования, позволяющий организации изменять рейтинг на основе внутренней оценки рисков. Иногда уязвимость может быть неприменимой из-за способа развертывания приложения в среде. Например, может быть выпущена уязвимость Java, которая влияет на конкретную библиотеку, которая не используется организацией.
Примечание. Даже если вы работаете в среде PaaS/бессерверной среды "платформа как услуга", вы по-прежнему несете ответственность за выявление уязвимостей в базе кода, т. е. сторонних библиотек.
Рекомендации: управление исправлениями
Укажите документ политики. Необходимо предоставить административные доказательства, такие как документация по политикам и процедурам, в которой подробно описаны определенные в организации процессы, охватывающие все элементы для данного элемента управления.
Примечание. Это логическое свидетельство может быть предоставлено в качестве подтверждающих доказательств, которые помогут получить дополнительные сведения о программе управления уязвимостями (VMP) вашей организации, но они не будут соответствовать этому элементу управления самостоятельно.
Пример доказательства: управление исправлениями
На следующем снимку экрана показан фрагмент политики ранжирования исправлений и рисков, а также различные уровни категорий рисков. За этим следуют интервалы времени классификации и исправления. Обратите внимание: ожидается, что поставщики программного обеспечения будут совместно использовать фактическую документацию по политике или процедуре поддержки, а не просто предоставить снимок экрана.


Пример (необязательно) дополнительных технических доказательств, подтверждающих документ политики
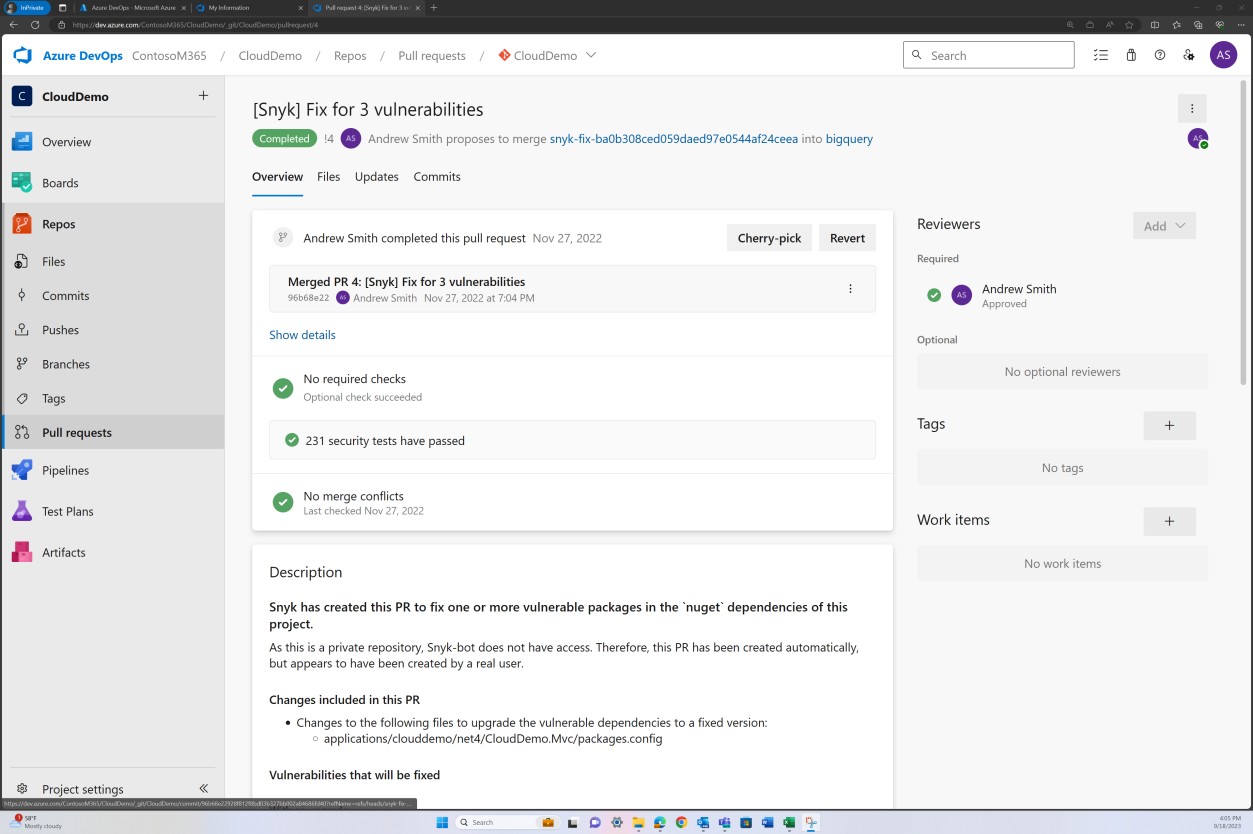
Логические доказательства, такие как электронные таблицы отслеживания уязвимостей, отчеты о технической оценке уязвимостей или снимки экрана билетов, выдвигаемых через сетевые платформы управления, для отслеживания состояния и хода уязвимостей, используемых для поддержки процесса, описанного в документации по политике. На следующем снимке экрана показано, что snyk, представляющий собой средство анализа композиции программного обеспечения (SCA), используется для сканирования базы кода на наличие уязвимостей. За этим следует уведомление по электронной почте.
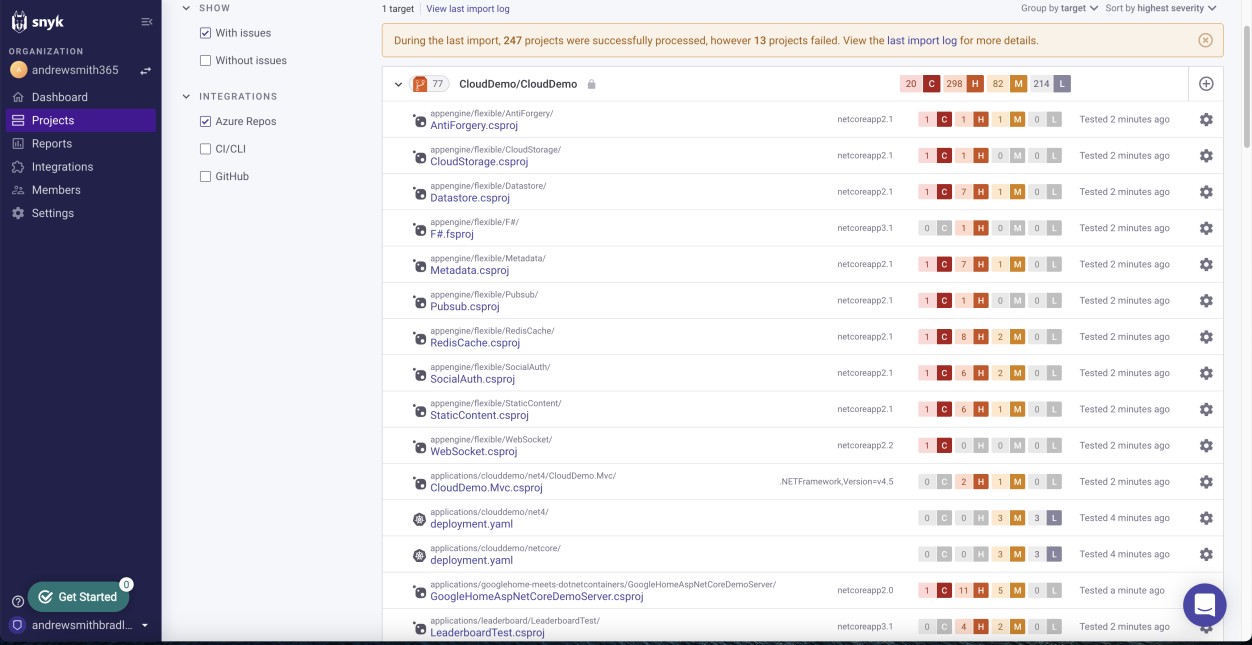
Обратите внимание. В этом примере полный снимок экрана не использовался, однако все снимки экрана, отправленные isv, должны быть полными снимками экрана, показывающими любой URL-адрес, вошедший в систему пользователь, системное время и дату.
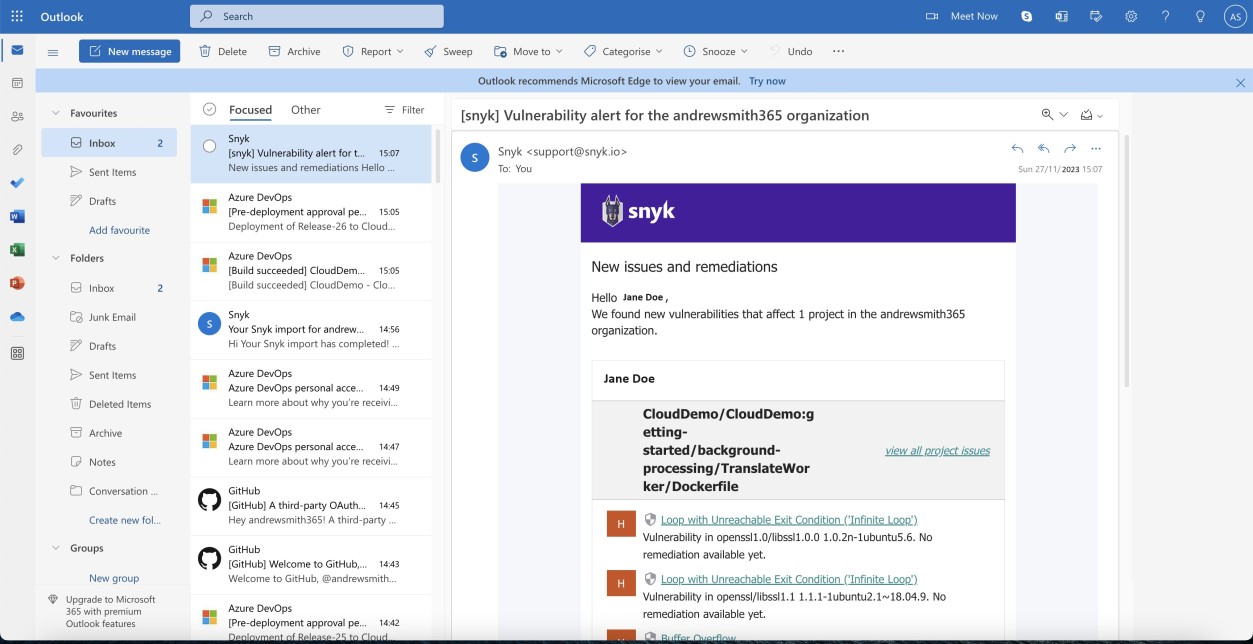
На следующих двух снимках экрана показан пример уведомления по электронной почте, полученного при помечении Snyk новых уязвимостей. Мы видим, что сообщение электронной почты содержит затронутый проект и назначенного пользователя для получения оповещений.
На следующем снимку экрана показаны обнаруженные уязвимости.
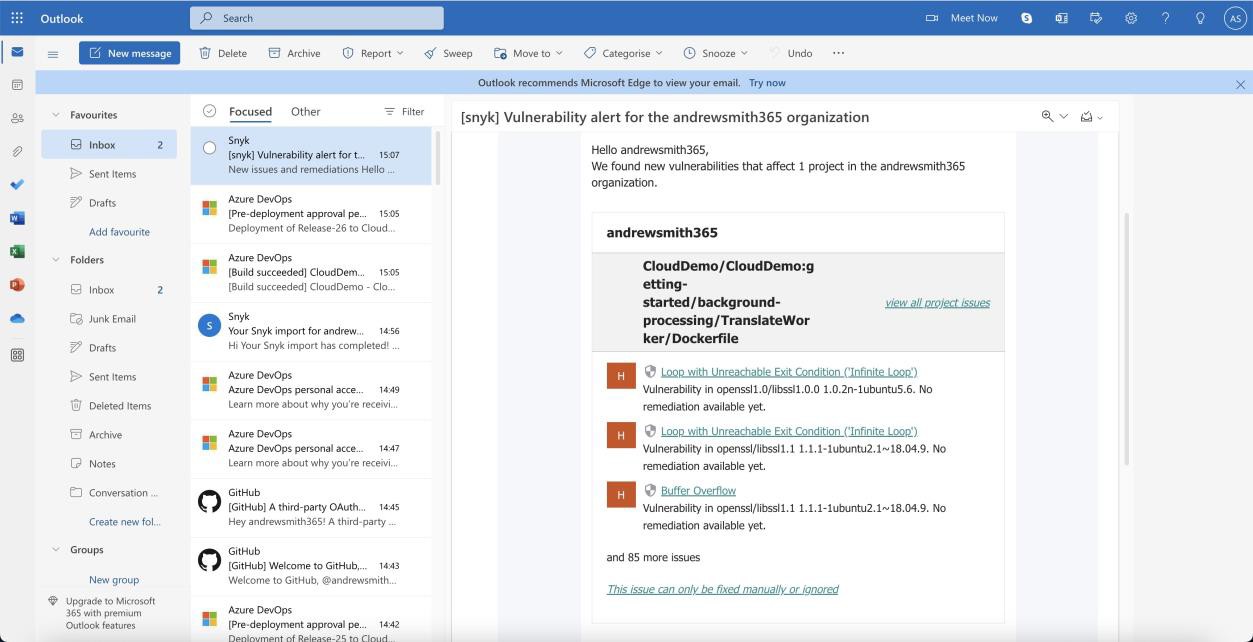
Обратите внимание: в предыдущих примерах полные снимки экрана не использовались, однако все снимки экрана, отправленные isV, должны быть полными снимками экрана с URL-адресом, любым вошедшего в систему пользователем, системным временем и датой.
Пример доказательства
На следующих снимках экрана показаны средства безопасности GitHub, настроенные и включенные для проверки уязвимостей в базе кода, а оповещения отправляются по электронной почте.
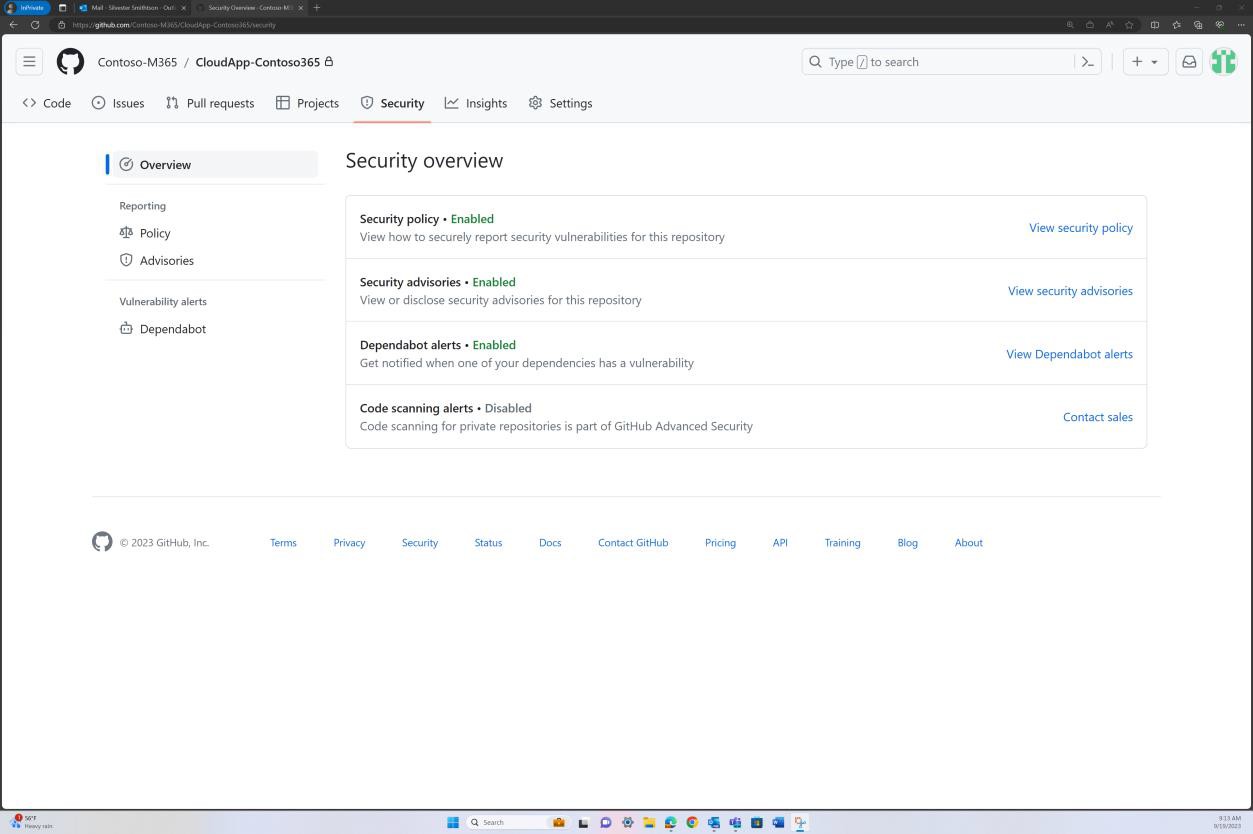
Следующее уведомление по электронной почте является подтверждением того, что помеченные проблемы будут автоматически устранены с помощью запроса на вытягивание.
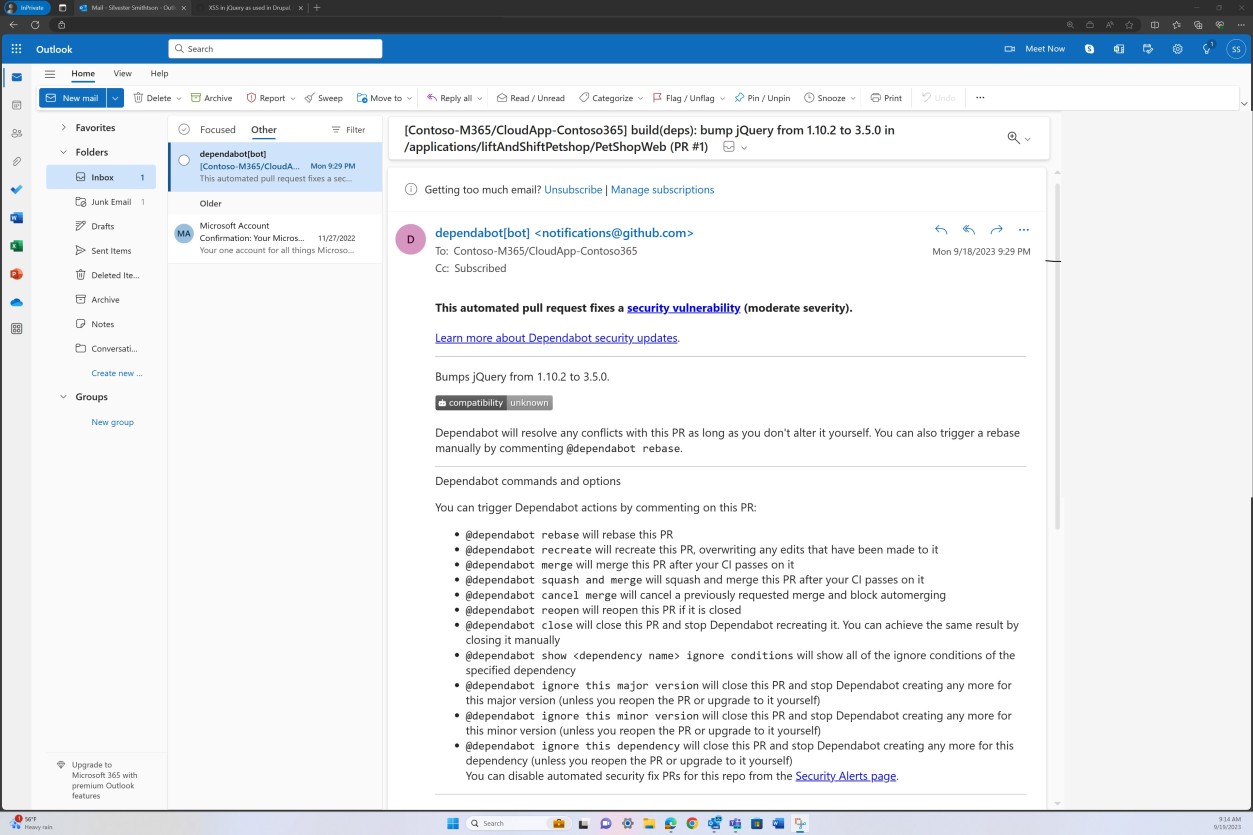
Пример доказательства
На следующем снимок экрана показана внутренняя техническая оценка и ранжирование уязвимостей с помощью электронной таблицы.
Пример доказательства
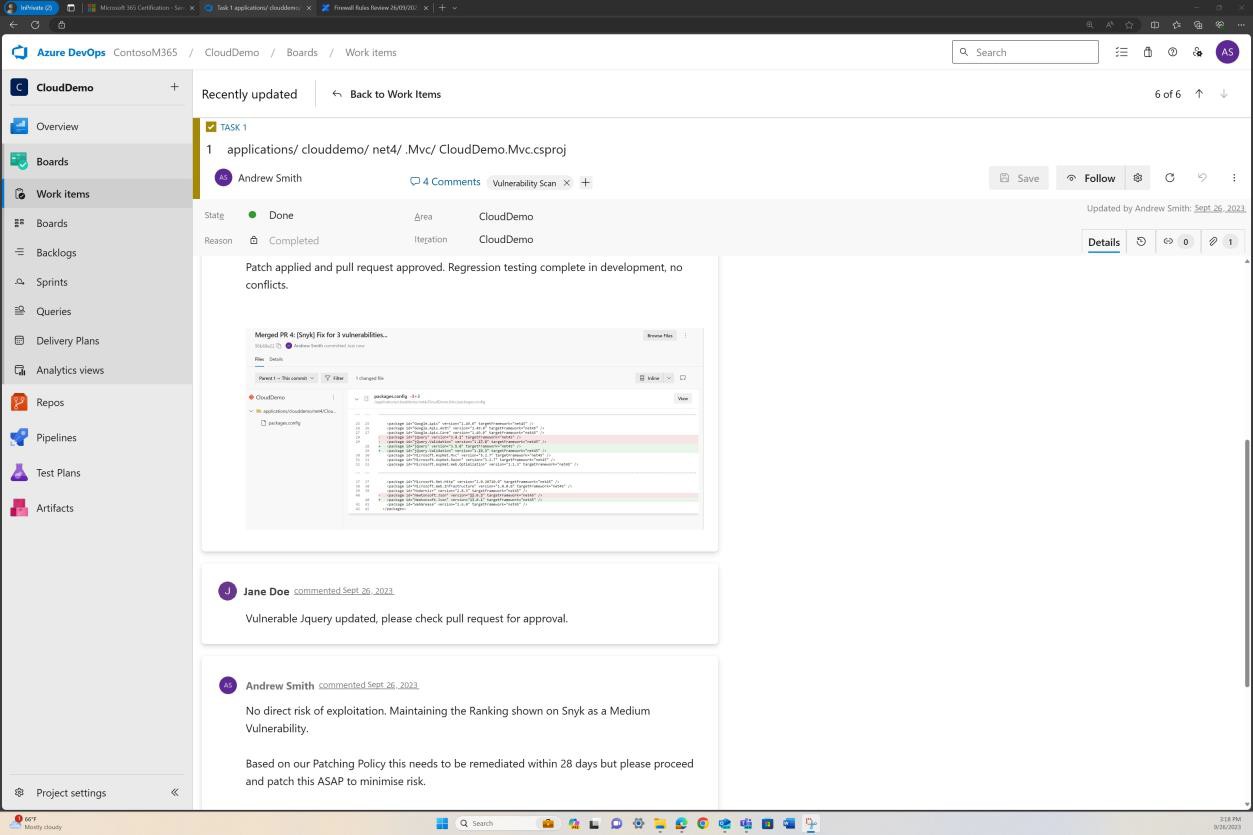
На следующих снимках экрана показаны запросы, которые были созданы в DevOps для каждой обнаруженной уязвимости.
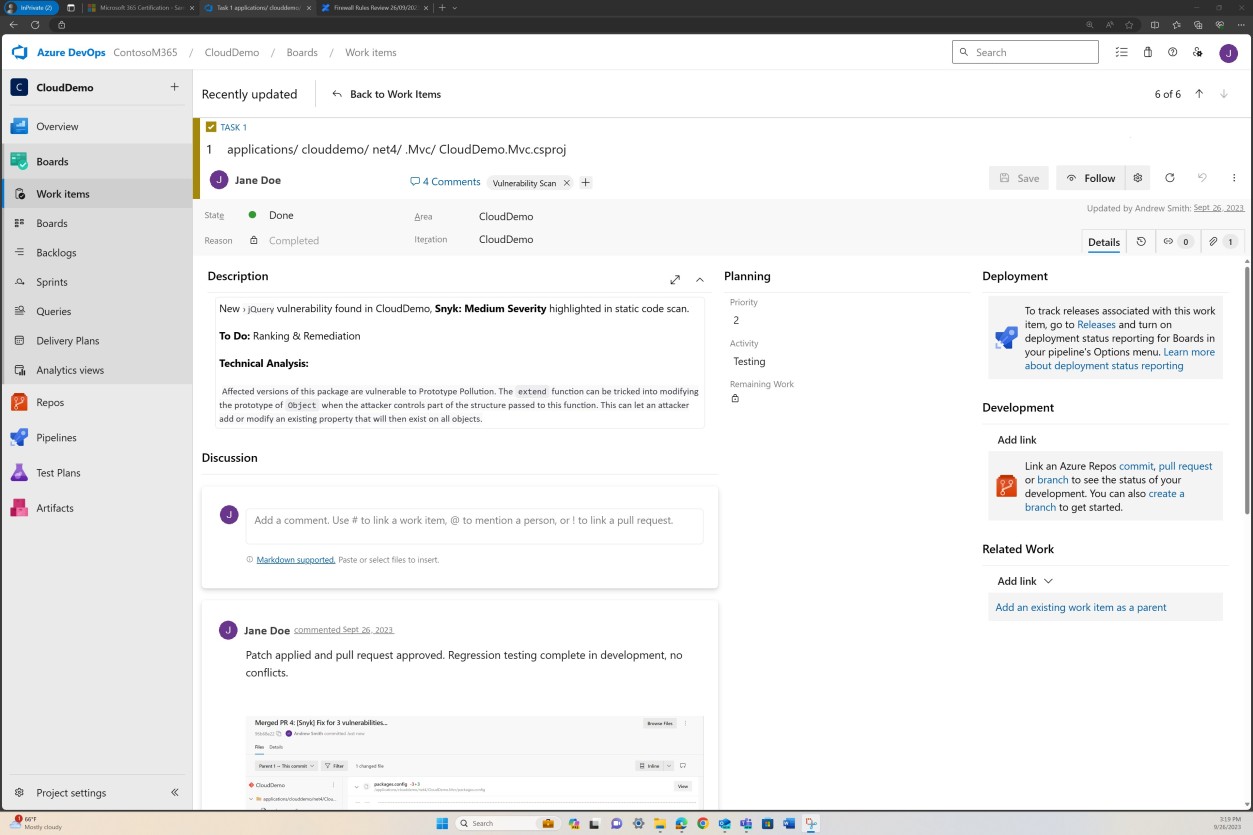
Оценка, ранжирование и проверка отдельным сотрудником происходит перед внедрением изменений.
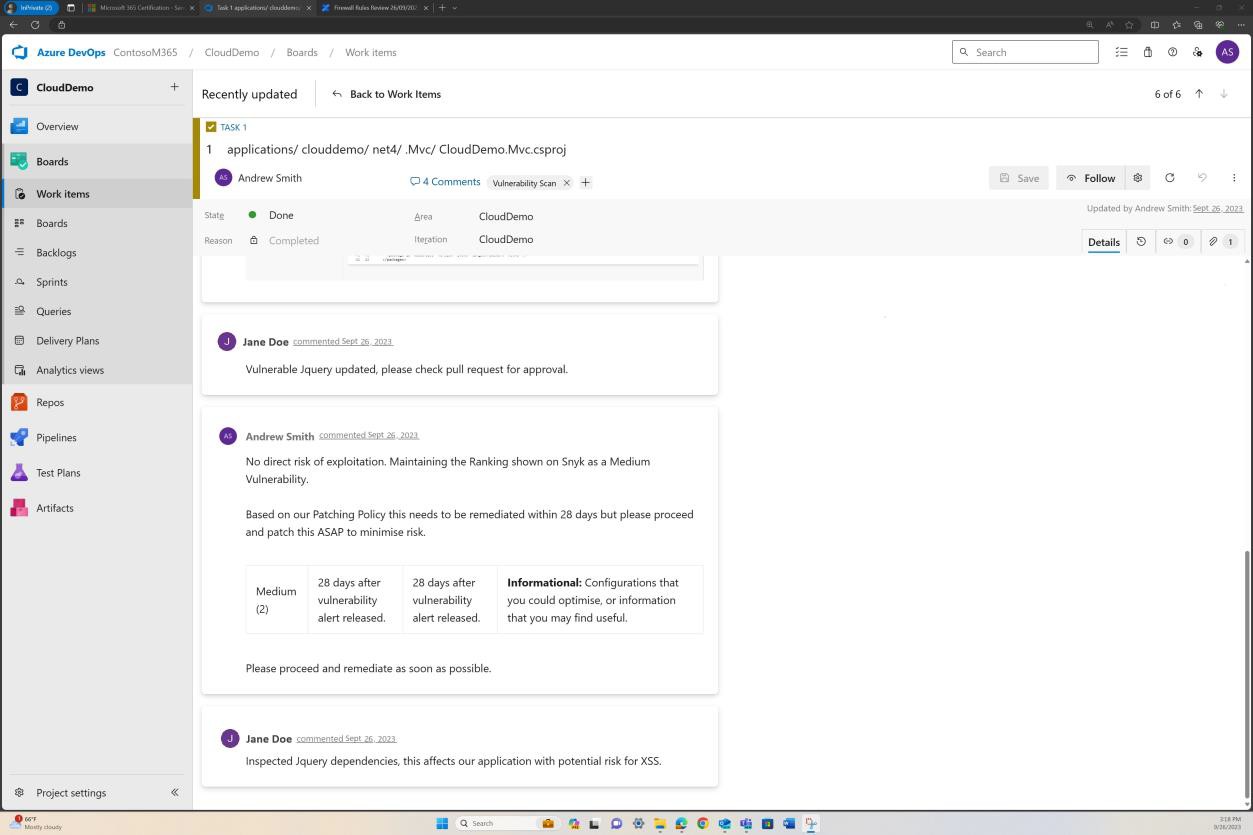
Элемент управления No 5
Предоставьте демонстрируемые доказательства того, что:
Все выборки системных компонентов находятся в исправлении.
Предоставьте доказательства того, что неподдерживаемые операционные системы и программные компоненты не используются.
Намерение: выборка системных компонентов
Эта подсеть направлена на обеспечение предоставления проверяемых доказательств, подтверждающих, что все выборки системных компонентов в организации активно исправляются. Доказательства могут включать, помимо прочего, журналы управления исправлениями, отчеты об аудите системы или задокументированные процедуры, показывающие применение исправлений. Если используется бессерверная технология или платформа как услуга (PaaS), она должна расшириться, чтобы включить базу кода, чтобы убедиться, что используются самые последние и безопасные версии библиотек и зависимостей.
Рекомендации. Выборка системных компонентов
Предоставьте снимок экрана для каждого устройства в примере и вспомогательных компонентов программного обеспечения, показывающих, что исправления устанавливаются в соответствии с документированием процесса установки исправлений. Кроме того, предоставьте снимки экрана, демонстрирующие исправление базы кода.
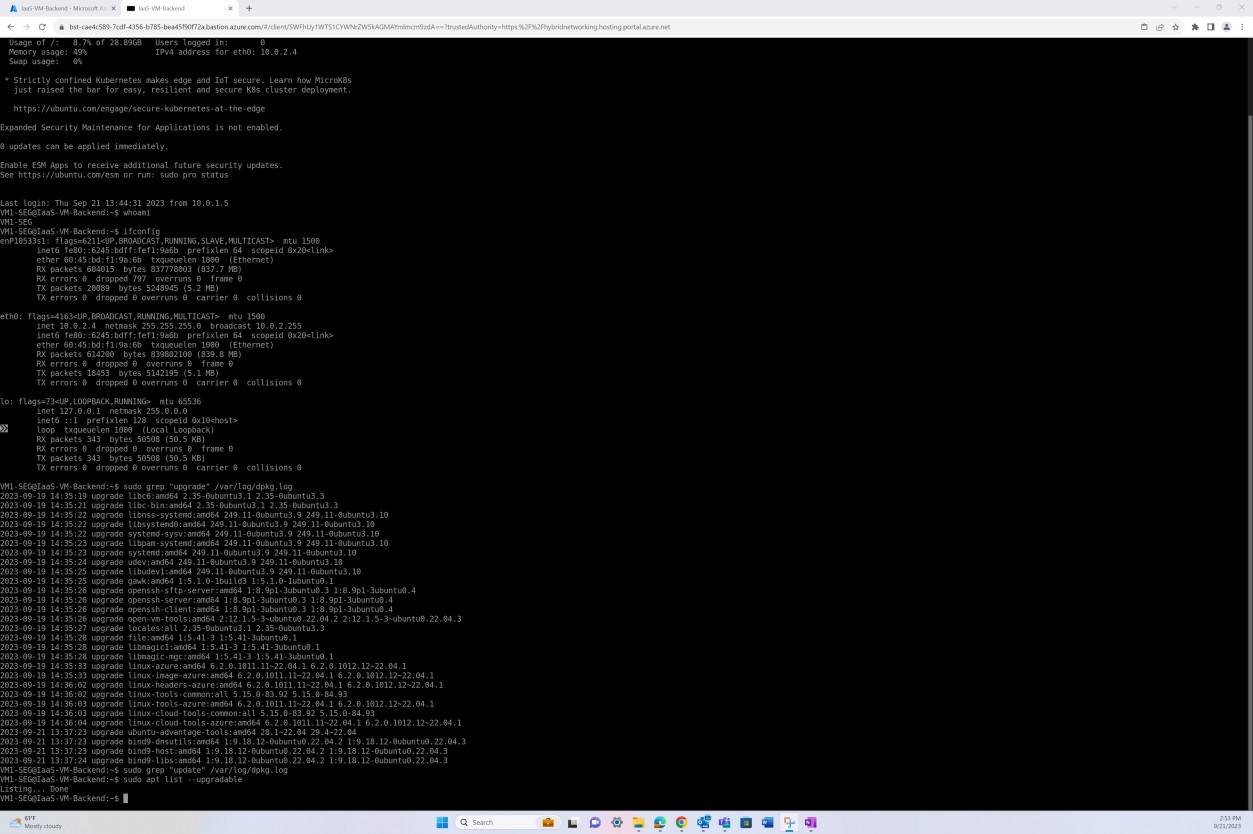
Пример доказательства: выборка системных компонентов
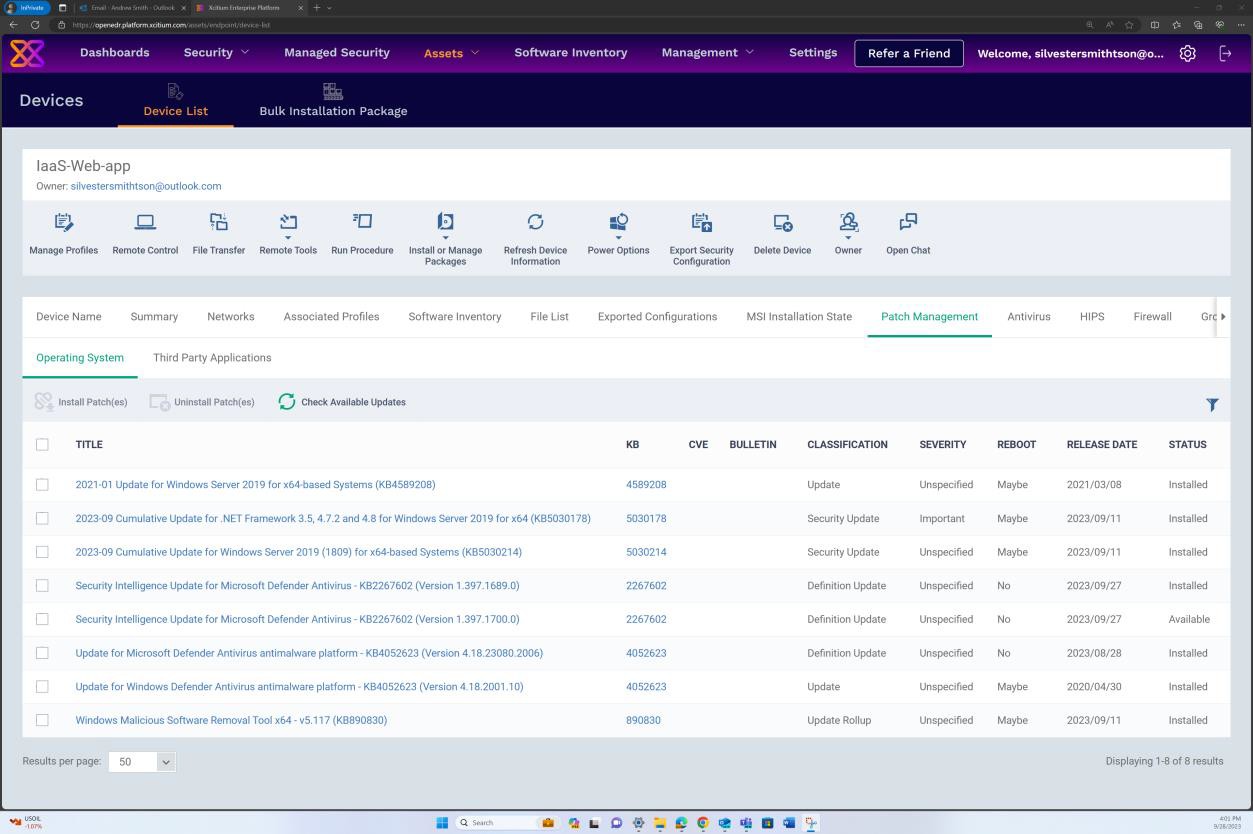
На следующем снимке экрана показано исправление виртуальной машины операционной системы Linux "IaaS- VM-Backend".
Пример доказательства
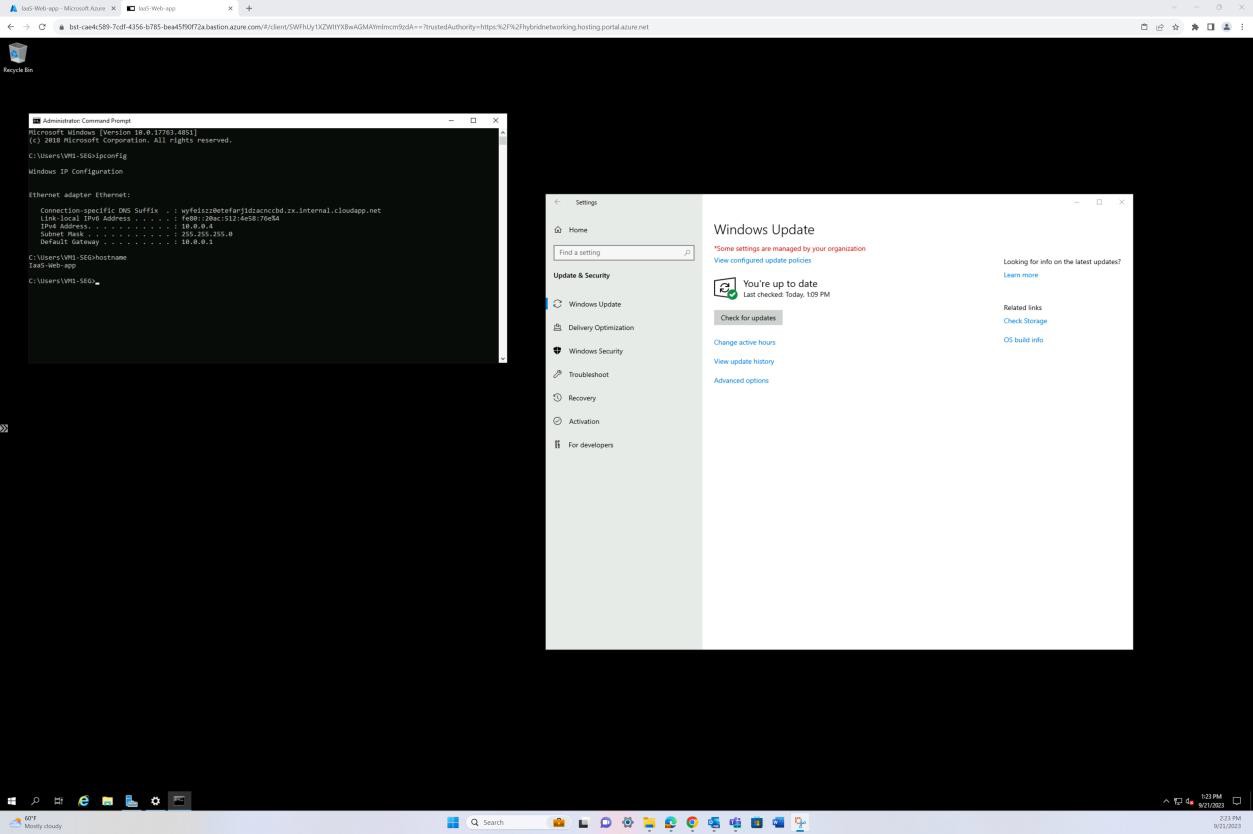
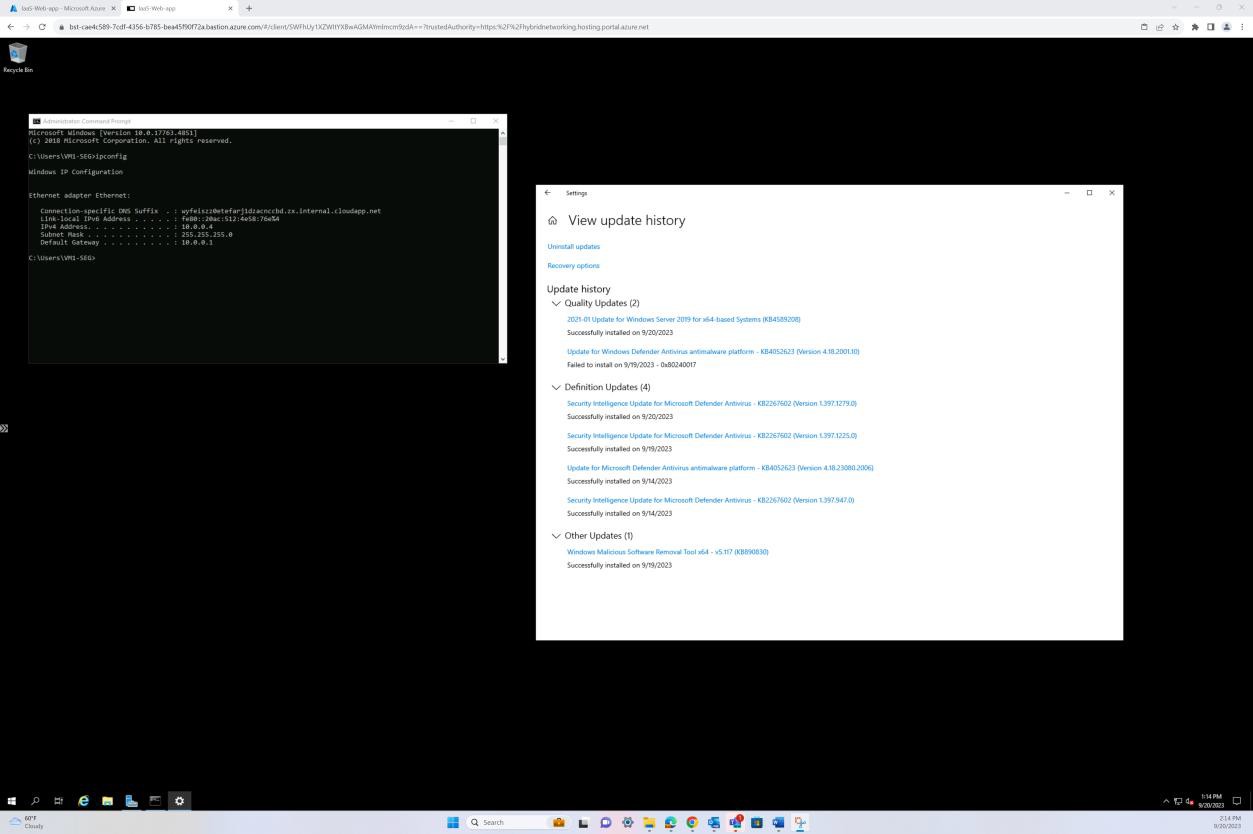
На следующем снимке экрана показано исправление виртуальной машины операционной системы Windows IaaS-Web-app.
Пример доказательства
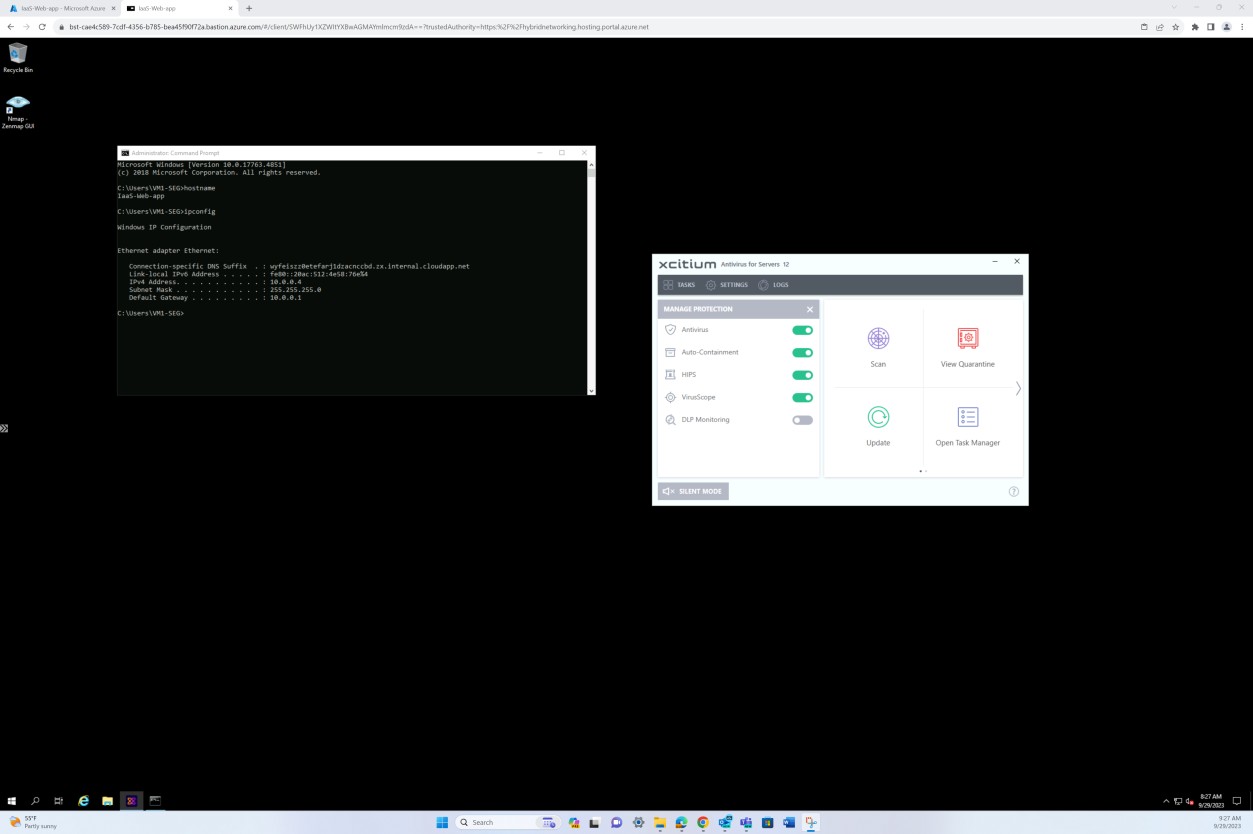
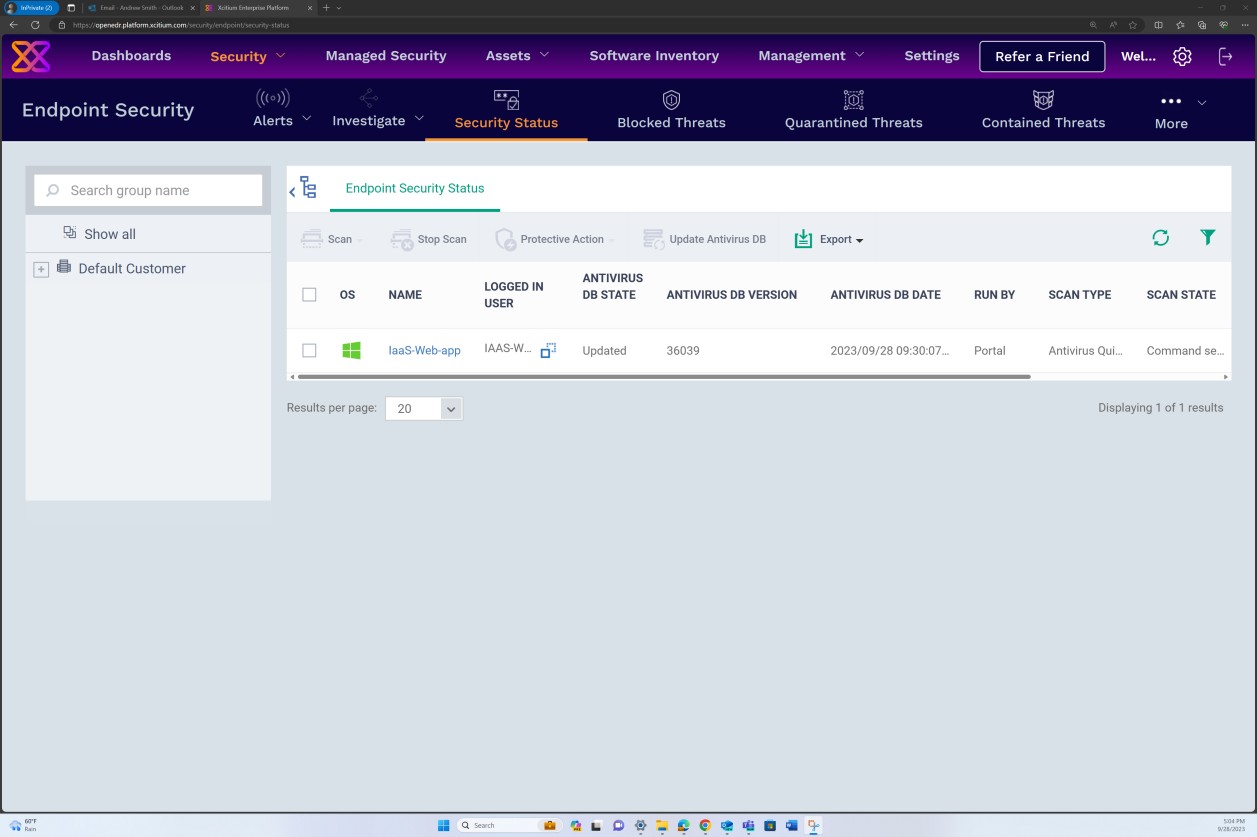
Если вы поддерживаете установку исправлений из любых других средств, таких как Microsoft Intune, Defender для облака и т. д., снимки экрана можно предоставить из этих средств. На следующих снимках экрана из решения OpenEDR показано, что управление исправлениями выполняется через портал OpenEDR.
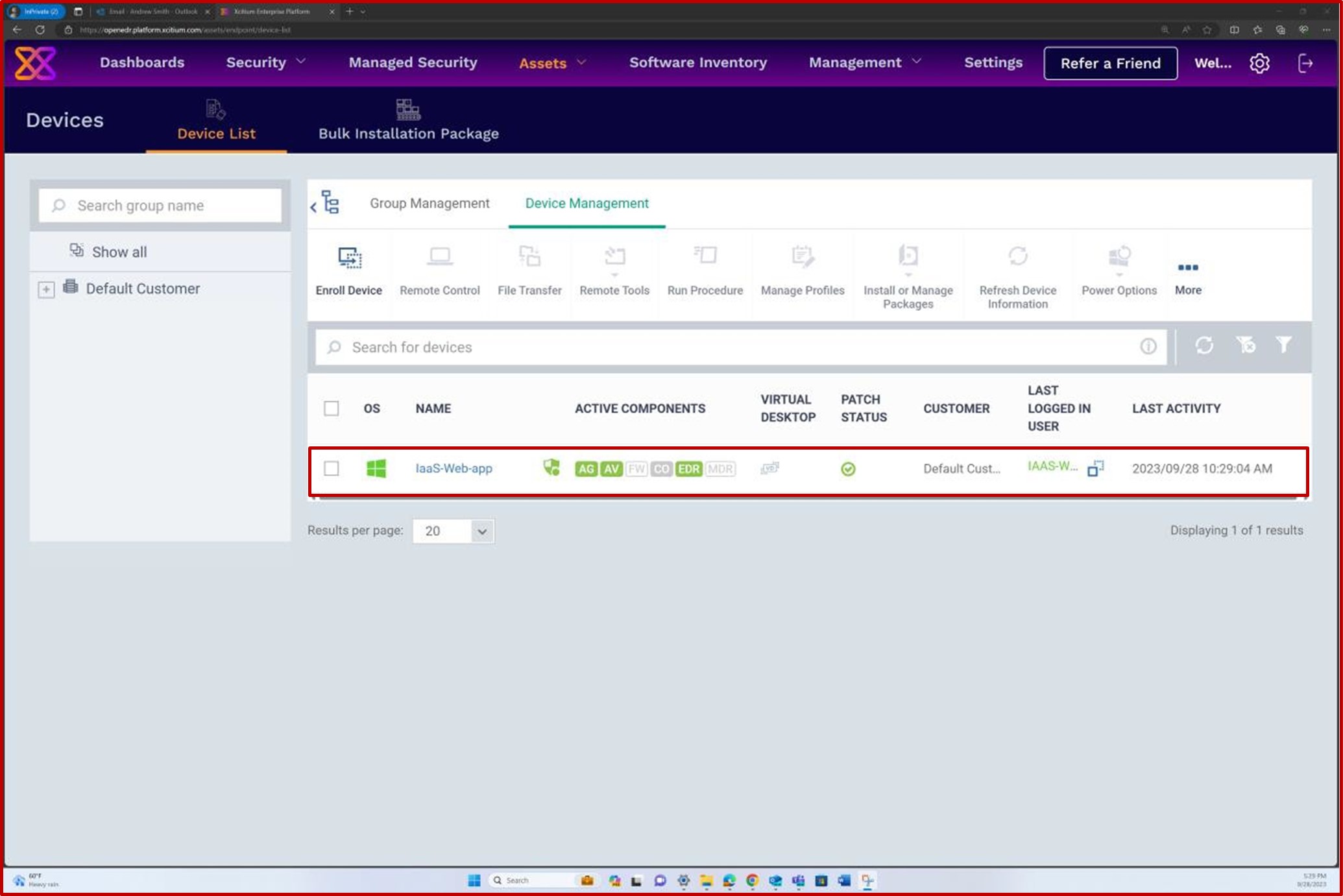
На следующем снимке экрана показано, что управление исправлениями сервера в области выполняется с помощью платформы OpenEDR. Классификация и состояние отображаются ниже, демонстрируя, что происходит исправление.
На следующем снимку экрана показано, что создаются журналы для исправлений, успешно установленных на сервере.
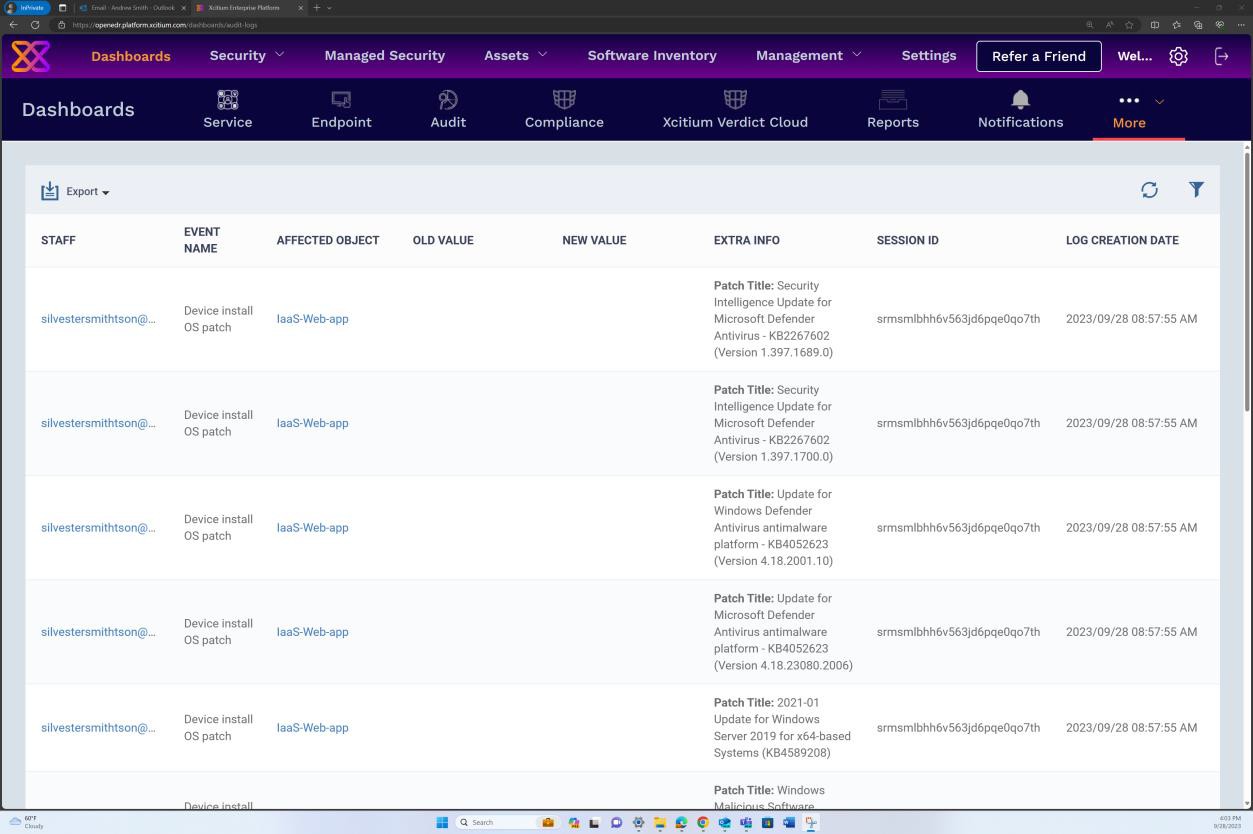
Пример доказательства
На следующем снимку экрана показано, что зависимости базы кода или сторонней библиотеки исправлены с помощью Azure DevOps.
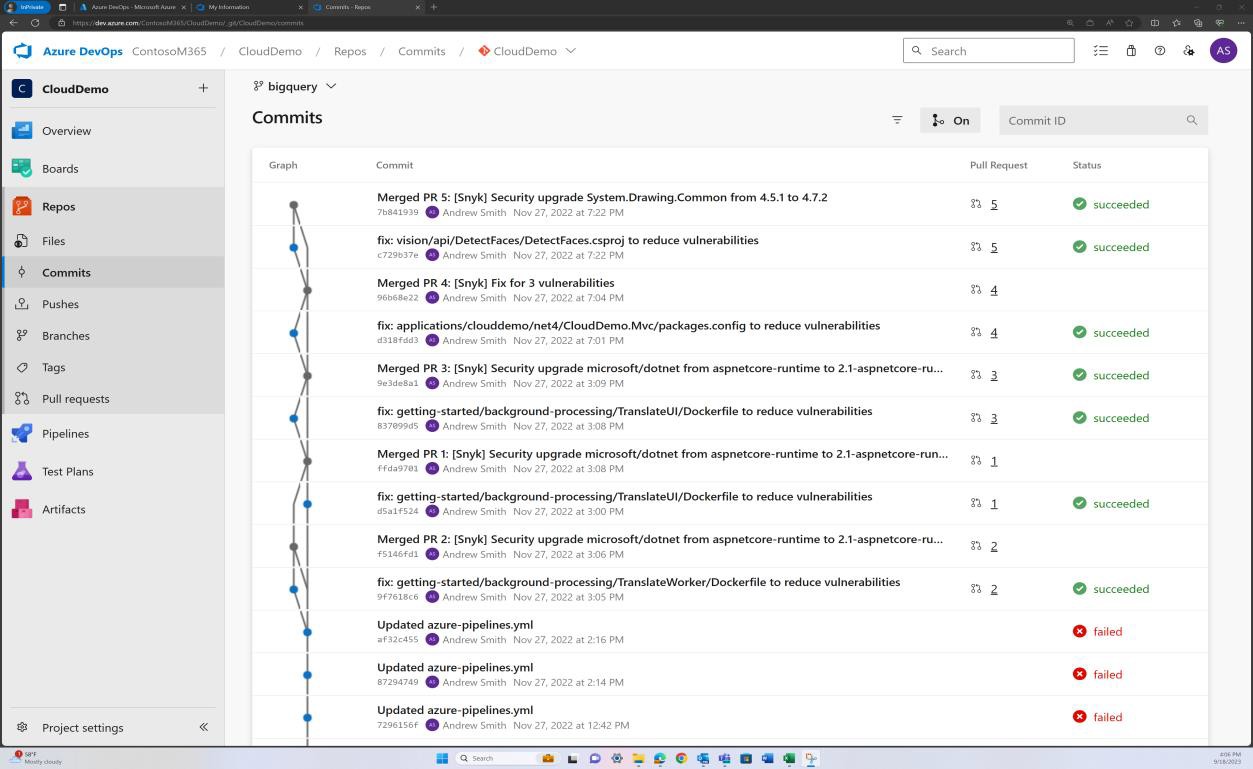
На следующем снимке экрана показано, что исправление уязвимостей, обнаруженных Snyk, фиксируется в ветви для устранения устаревших библиотек.
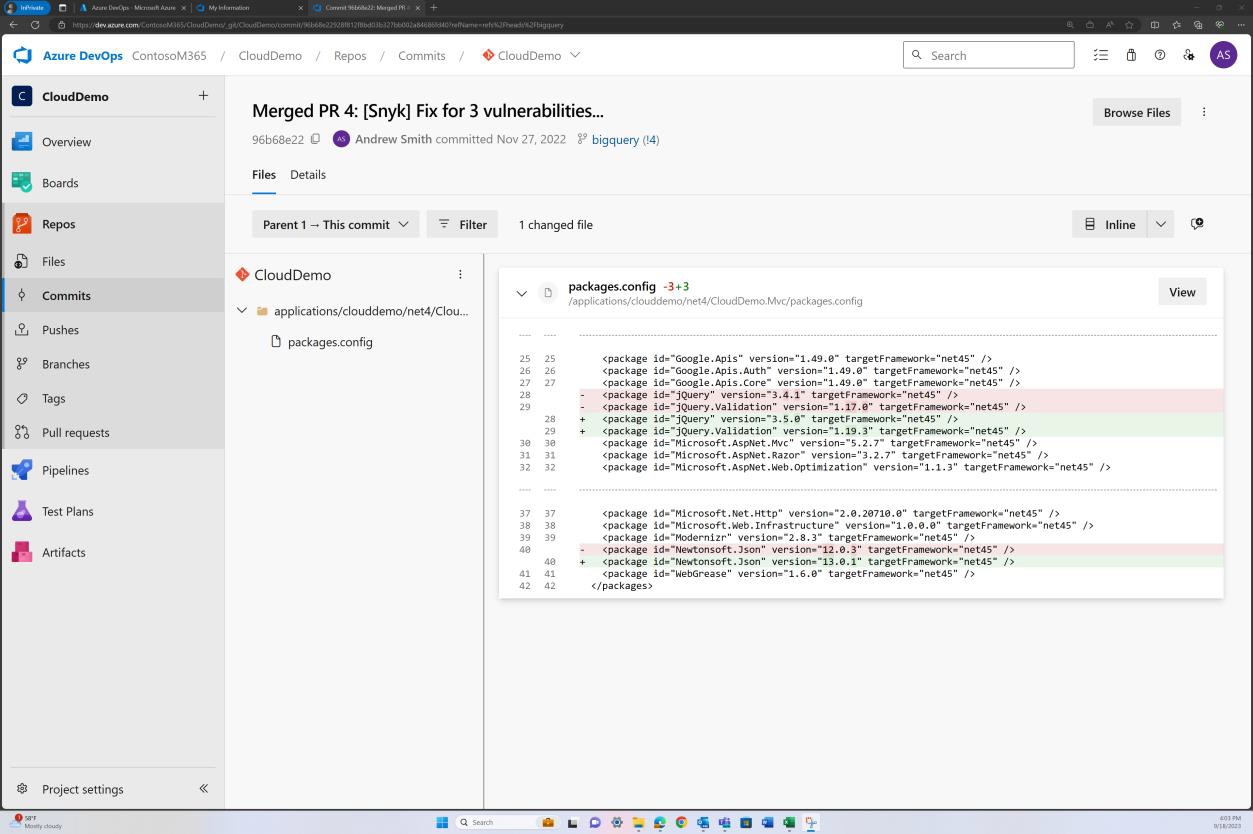
На следующем снимках экрана показано, что библиотеки обновлены до поддерживаемых версий.
Пример доказательства
На следующих снимках экрана показано, что исправление базы кода поддерживается с помощью GitHub Dependabot. Закрытые элементы демонстрируют наличие исправлений и устранение уязвимостей.
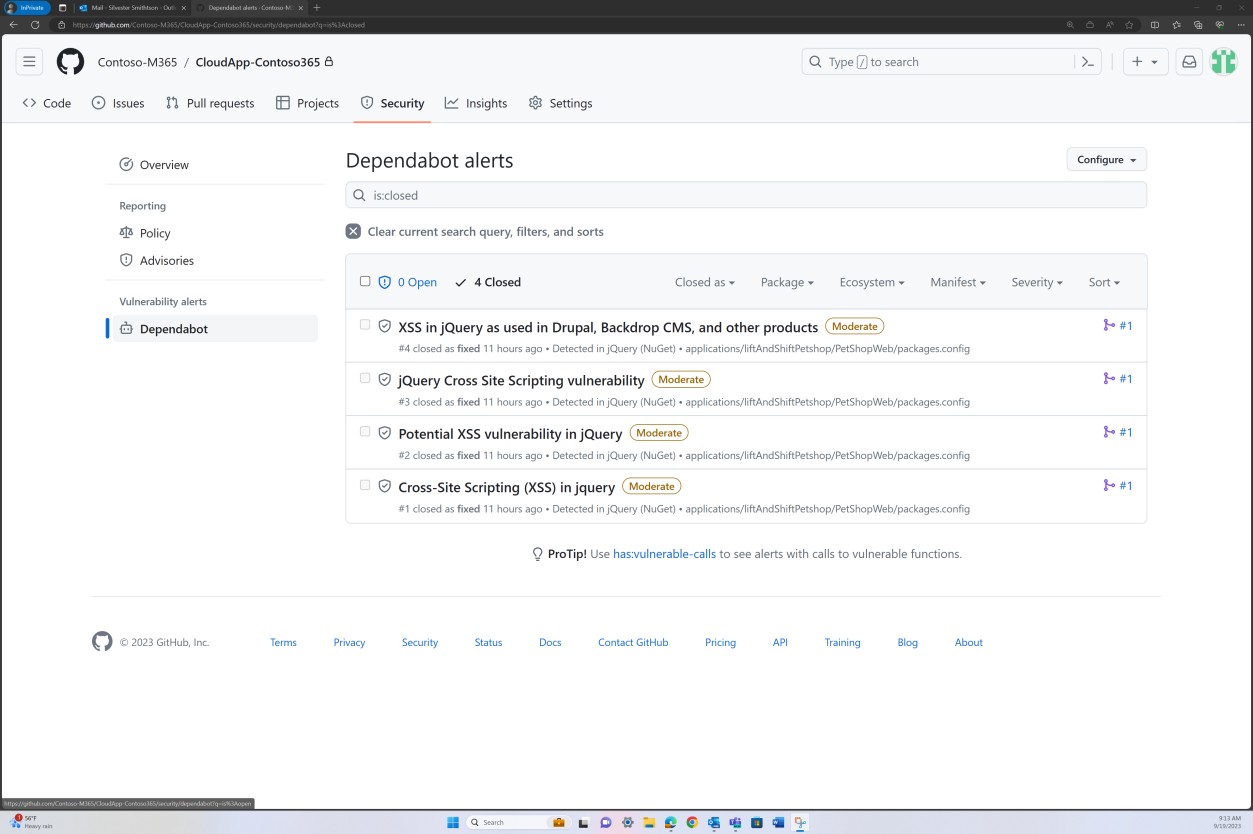
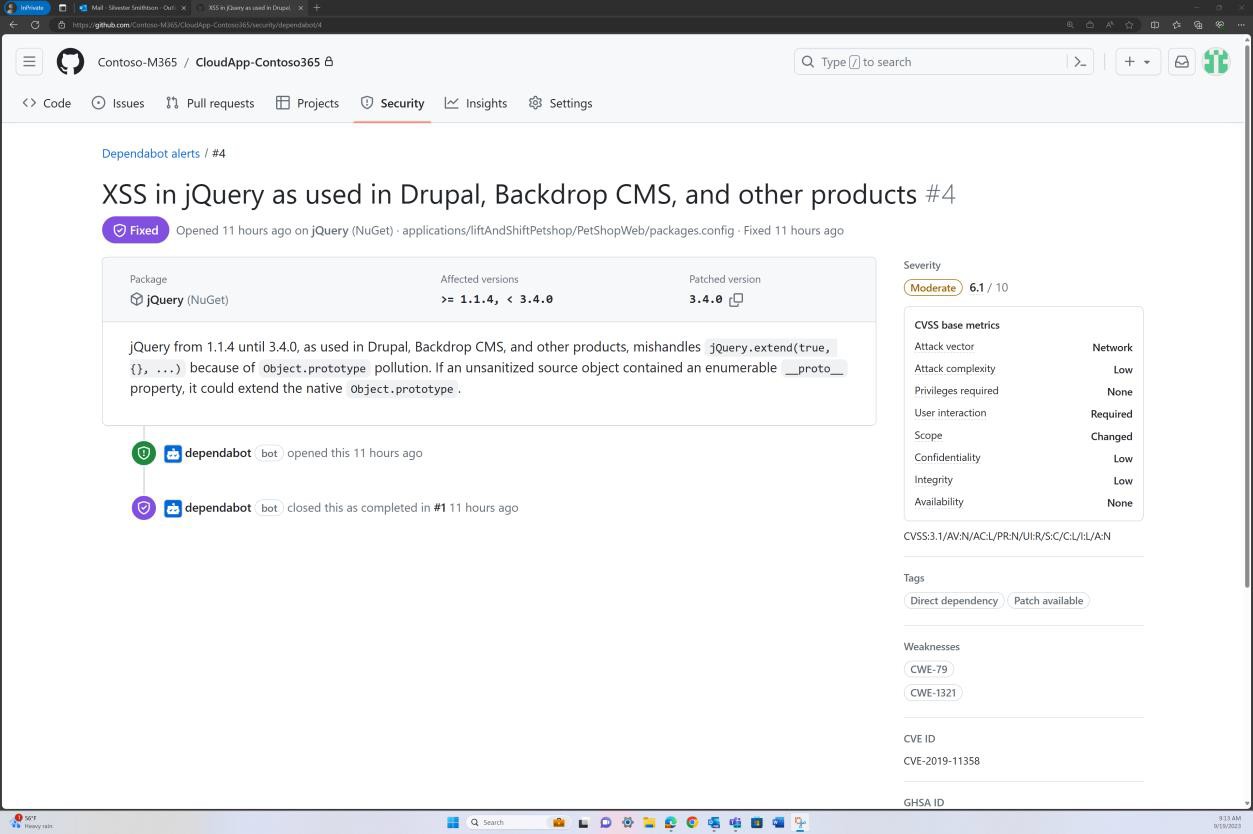
Намерение: неподдерживаемая ОС
Программное обеспечение, которое не обслуживается поставщиками, будет страдать от известных уязвимостей, которые не исправлены. Поэтому использование неподдерживаемых операционных систем и программных компонентов не должно использоваться в рабочих средах. При развертывании инфраструктуры как услуги (IaaS) требование к этой подточии расширяется и включает в себя инфраструктуру и базу кода, чтобы обеспечить соответствие каждого уровня стека технологий политике организации по использованию поддерживаемого программного обеспечения.
Рекомендации: неподдерживаемая ОС
Предоставьте снимок экрана для каждого устройства в выборке набора, выбранного аналитиком, чтобы собрать доказательства против отображения версии операционной системы (включите имя устройства или сервера на снимке экрана). Кроме того, предоставьте доказательства того, что компоненты программного обеспечения, работающие в среде, работают с поддерживаемыми версиями программного обеспечения. Это можно сделать, предоставив выходные данные внутренних отчетов о проверке уязвимостей (включая проверку подлинности) и (или) выходные данные средств, которые проверяют сторонние библиотеки, такие как Snyk, Trivy или NPM Audit. При выполнении в PaaS должны быть охвачены только исправления сторонней библиотеки.
Пример доказательства: неподдерживаемая ОС
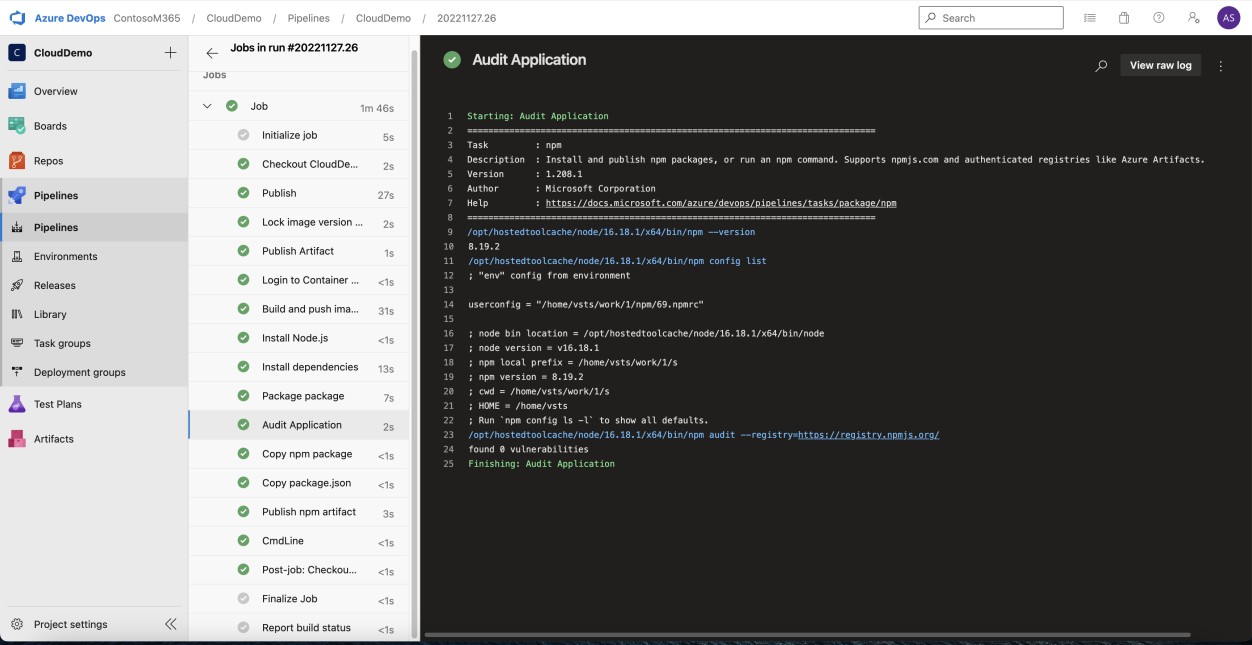
На следующем снимку экрана из аудита NPM Azure DevOps показано, что в веб-приложении не используются неподдерживаемые библиотеки и зависимости.
Примечание. В следующем примере полный снимок экрана не использовался, однако все снимки экрана, отправленные isv, должны быть полными снимками экрана, показывающими URL-адрес, все вошедшие в систему пользователи, системное время и дату.
Пример доказательства
На следующем снимку экрана из GitHub Dependabot показано, что в веб-приложении не используются библиотеки и зависимости.
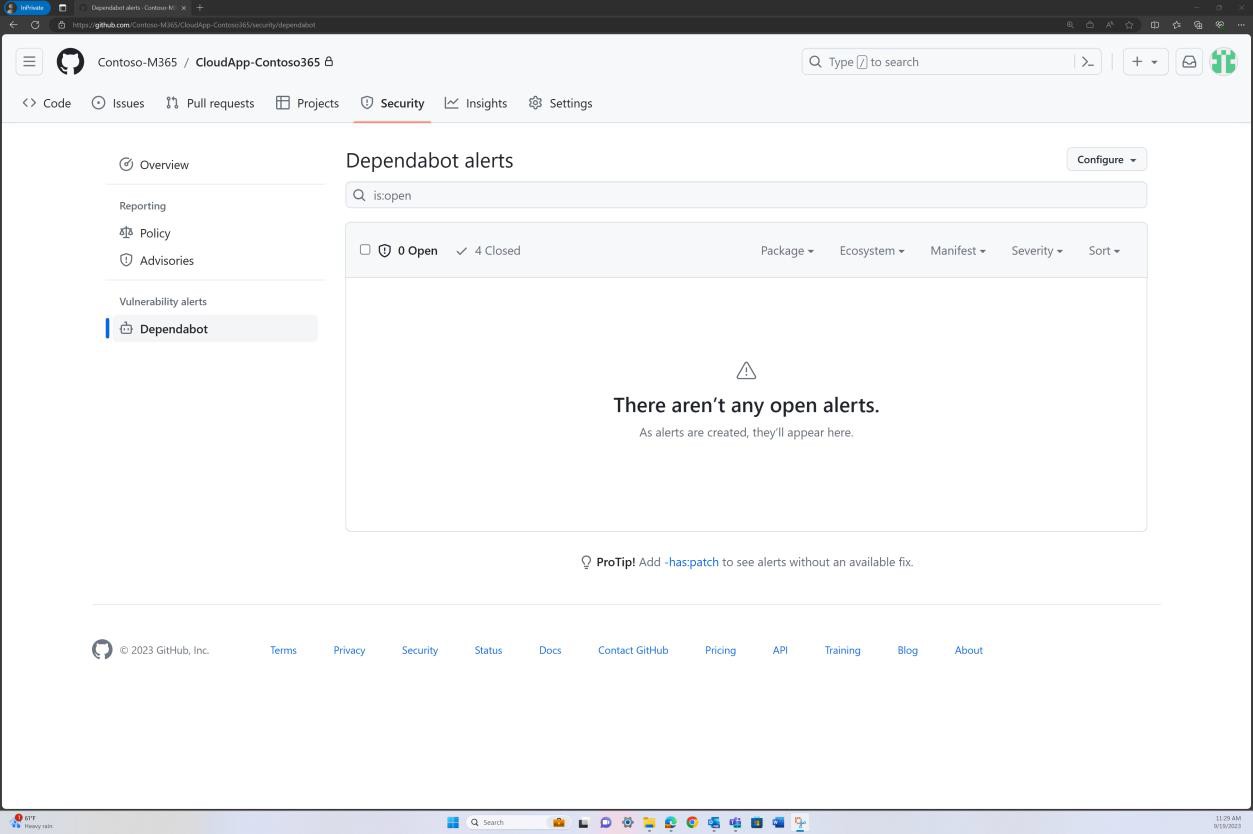
Пример доказательства
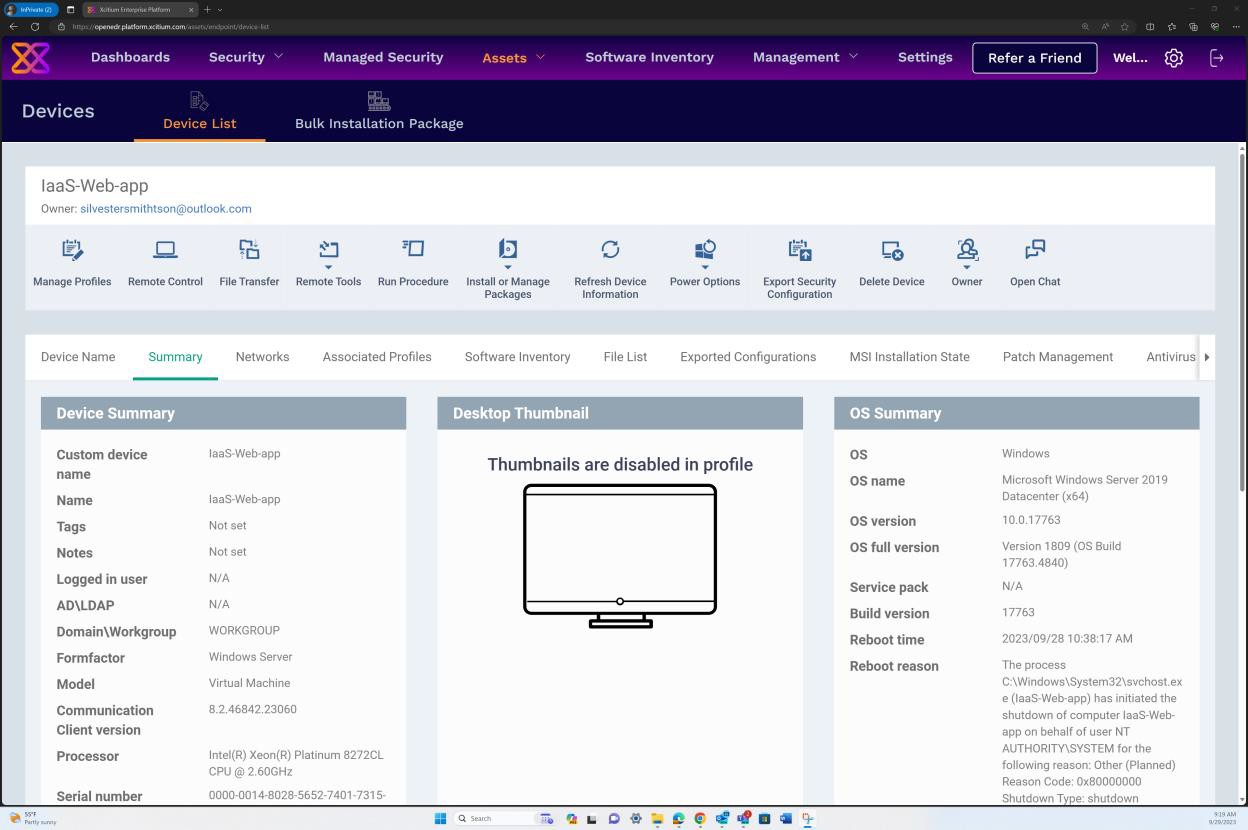
На следующем снимок экрана инвентаризации программного обеспечения для операционной системы Windows через OpenEDR показано, что не найдены неподдерживаемые или устаревшие версии операционной системы и программного обеспечения.
Пример доказательства
Следующий снимок экрана: OpenEDR в разделе "Сводка ОС", где показан полный журнал версий Windows Server 2019 Datacenter (x64) и полный журнал версий ОС, включая пакет обновления, версию сборки и т. д. проверка отсутствия неподдерживаемой операционной системы.
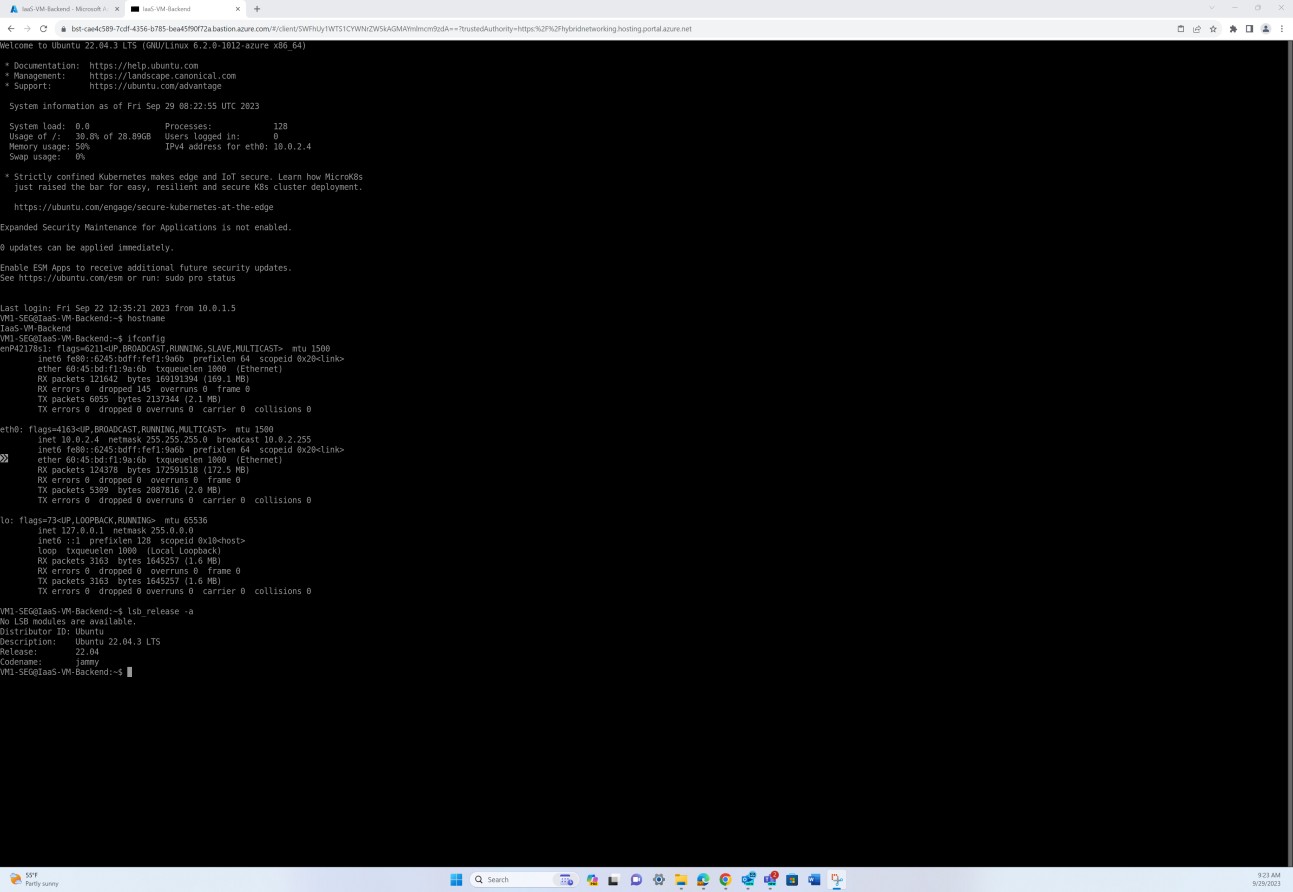
Пример доказательства
На следующем снимку экрана с сервера операционной системы Linux показаны все сведения о версии, включая идентификатор распространителя, описание, выпуск и имя кода, проверяющие отсутствие неподдерживаемой операционной системы Linux.
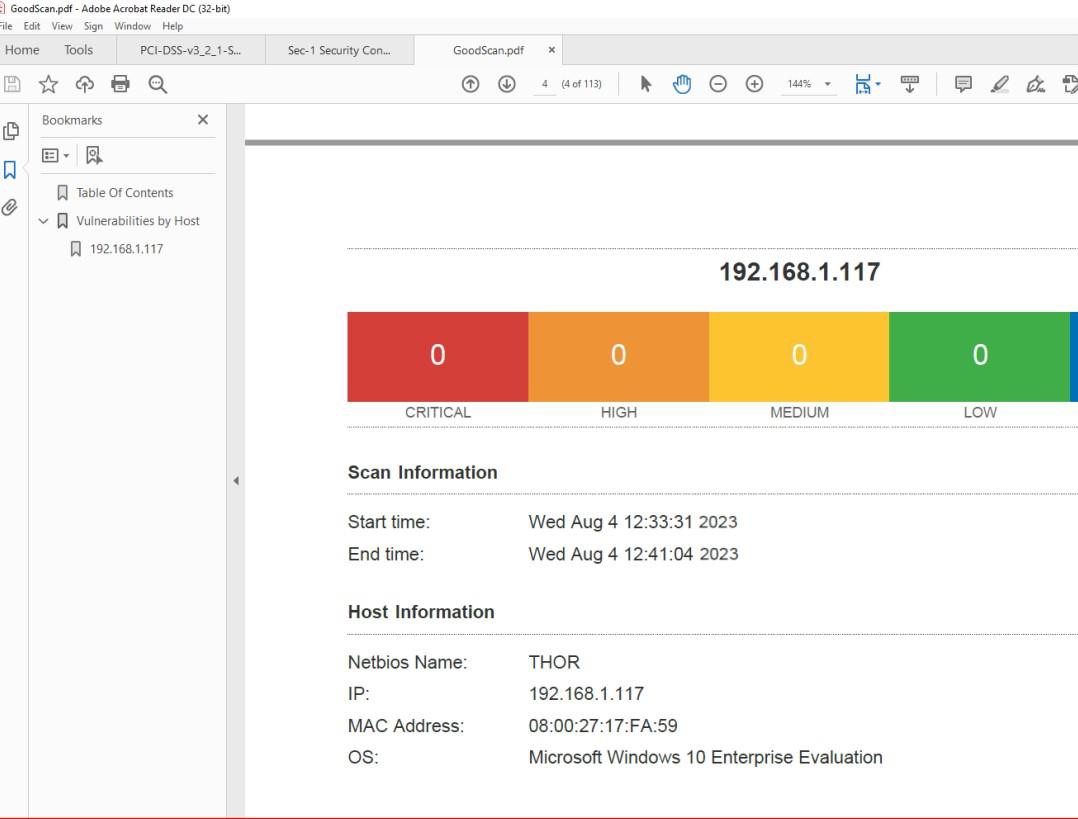
Пример доказательства:
На следующем снимке экрана из отчета о проверке уязвимостей Nessus показано, что на целевом компьютере не найдены неподдерживаемые операционная система (ОС) и программное обеспечение.
Обратите внимание: в предыдущих примерах полный снимок экрана не использовался, однако все снимки экрана, отправленные isV, должны быть полными снимками экрана, показывающими URL-адрес, все вошедшие в систему время и дату входа пользователя.
Сканирование уязвимостей
Сканирование уязвимостей ищет возможные слабые места в компьютерной системе, сетях и веб-приложениях организации, чтобы выявить дыры, которые могут привести к нарушениям безопасности и раскрытию конфиденциальных данных. Сканирование уязвимостей часто требуется отраслевыми стандартами и государственными правилами, например PCI DSS (стандарт безопасности данных индустрии платежных карт).
В отчете Метрики безопасности, озаглавленном "Руководство по метрикам безопасности 2020 года по соответствию PCI DSS", говорится, что "в среднем потребовалось 166 дней с момента обнаружения в организации уязвимостей, чтобы злоумышленник скомпрометировал систему. После компрометации злоумышленники имели доступ к конфиденциальным данным в среднем в течение 127 дней, поэтому этот контроль направлен на выявление потенциальной уязвимости системы безопасности в среде в области.
Внедряя регулярные оценки уязвимостей, организации могут обнаруживать слабые места и неуверенности в своих средах, что может обеспечить точку входа для злоумышленника, чтобы скомпрометировать среду. Сканирование уязвимостей может помочь выявить отсутствующие исправления или неправильные настройки в среде. Регулярно проводя эти проверки, организация может обеспечить соответствующее исправление, чтобы свести к минимуму риск компрометации из-за проблем, которые обычно возникают в этих средствах проверки уязвимостей.
Элемент управления No 6
Предоставьте доказательства того, что:
Ежеквартально выполняется проверка уязвимостей инфраструктуры и веб-приложений.
Сканирование должно выполняться по всем общедоступным (IP-адресам и URL-адресам) и внутренним диапазонам IP-адресов, если среда IaaS, гибридная или локальная.
Примечание. Он должен включать полную область действия среды.
Намерение: проверка уязвимостей
Этот элемент управления направлен на то, чтобы организация ежеквартально проводила проверку уязвимостей, ориентированную как на свою инфраструктуру, так и на веб-приложения. Сканирование должно быть комплексным, охватывающим как общедоступные ip-адреса и URL-адреса, так и внутренние диапазоны IP-адресов. Область сканирования зависит от характера инфраструктуры организации:
Если организация реализует гибридные, локальные модели или модели инфраструктуры как услуги (IaaS), сканирование должно охватывать как внешние общедоступные IP-адреса, так и внутренние диапазоны IP-адресов.
Если в организации реализована платформа как услуга (PaaS), проверка должна охватывать только внешние общедоступные IP-адреса и URL-адреса.
Этот элемент управления также требует, чтобы проверка включала полную область среды, тем самым не закрывая флажок компонента. Цель заключается в выявлении и оценке уязвимостей во всех частях технологического стека организации, чтобы обеспечить комплексную безопасность.
Рекомендации: проверка уязвимостей
Предоставьте полные отчеты о проверке уязвимостей каждого квартала, выполненные за последние 12 месяцев. В отчетах должны быть четко указаны целевые объекты, чтобы убедиться, что включена полная общедоступная подсеть и, если применимо, каждая внутренняя подсеть. Предоставьте все отчеты о проверке за каждый квартал.
Пример доказательства: проверка уязвимостей
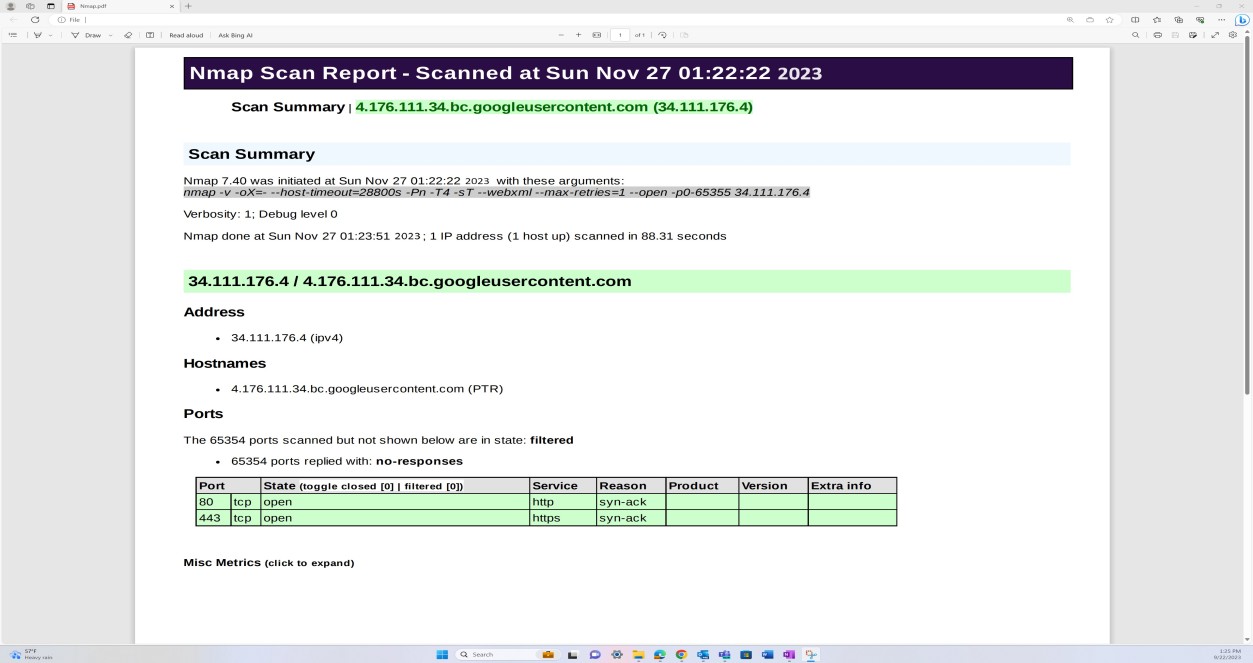
На следующем снимку экрана показано обнаружение сети и проверка портов, выполненная через Nmap во внешней инфраструктуре для выявления незащищенных открытых портов.
Примечание. Nmap не может быть использован для выполнения этого элемента управления, так как ожидается, что необходимо предоставить полное сканирование уязвимостей. Обнаружение портов Nmap является частью процесса управления уязвимостями, показанного ниже, и дополняется проверками OpenVAS и OWASP ZAP внешней инфраструктуры.
Снимок экрана: проверка уязвимостей с помощью OpenVAS для внешней инфраструктуры для выявления ошибок и уязвимостей.
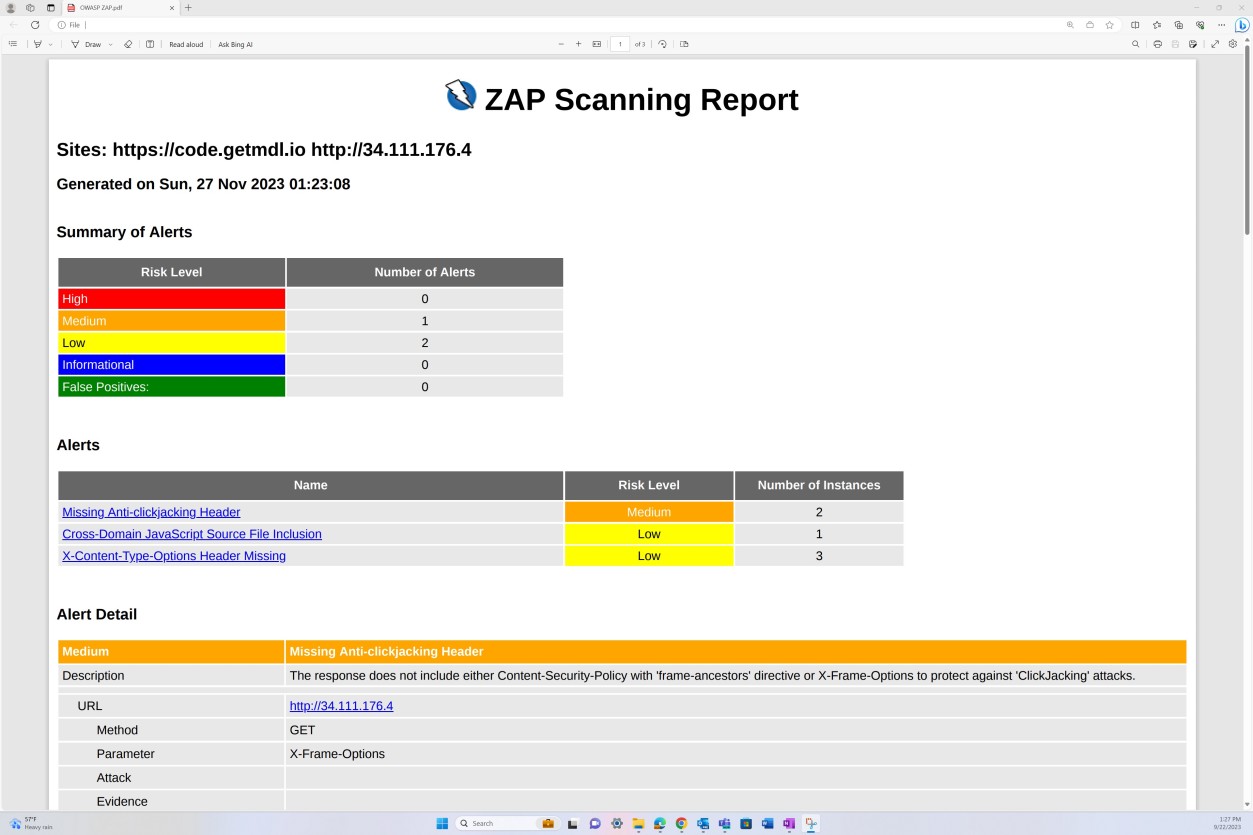
На следующем снимку экрана показан отчет о проверке уязвимостей из OWASP ZAP, демонстрирующий динамическое тестирование безопасности приложений.
Пример доказательства: проверка уязвимостей
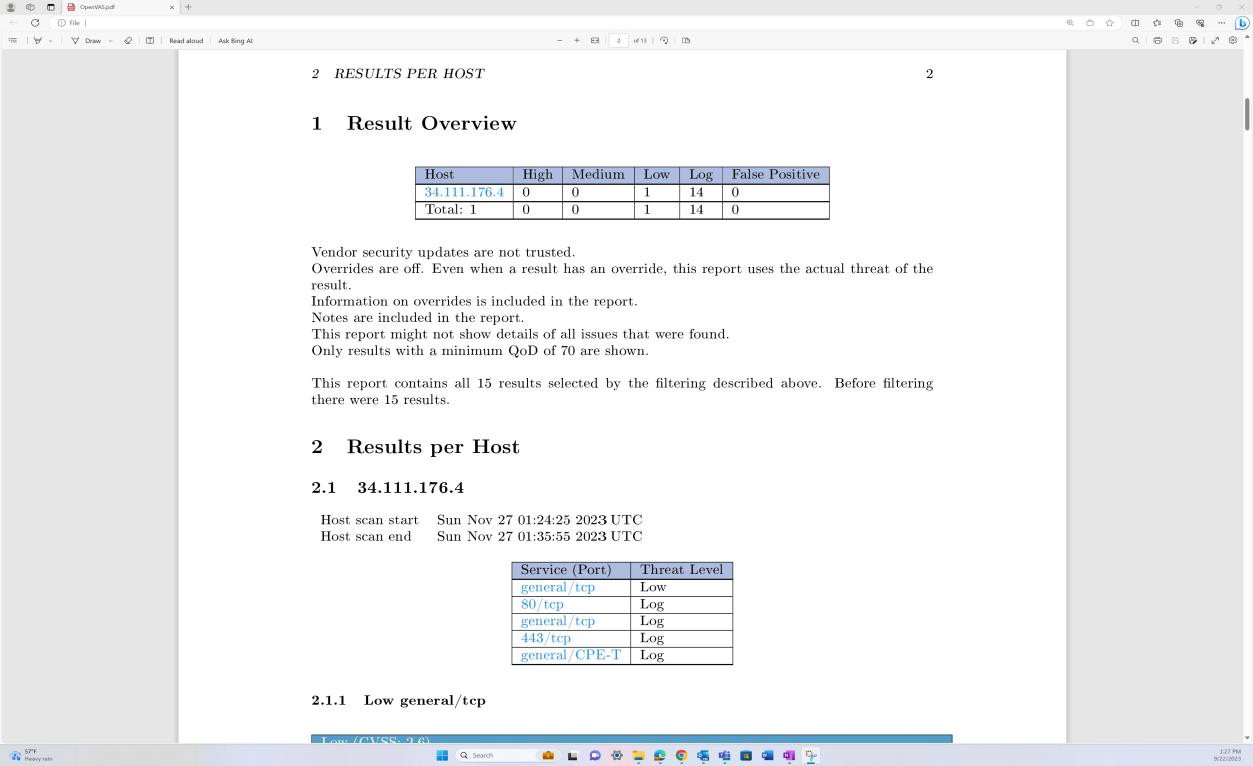
На следующих снимках экрана из отчета о проверке уязвимостей Nessus Essentials показано, что выполняется внутреннее сканирование инфраструктуры.
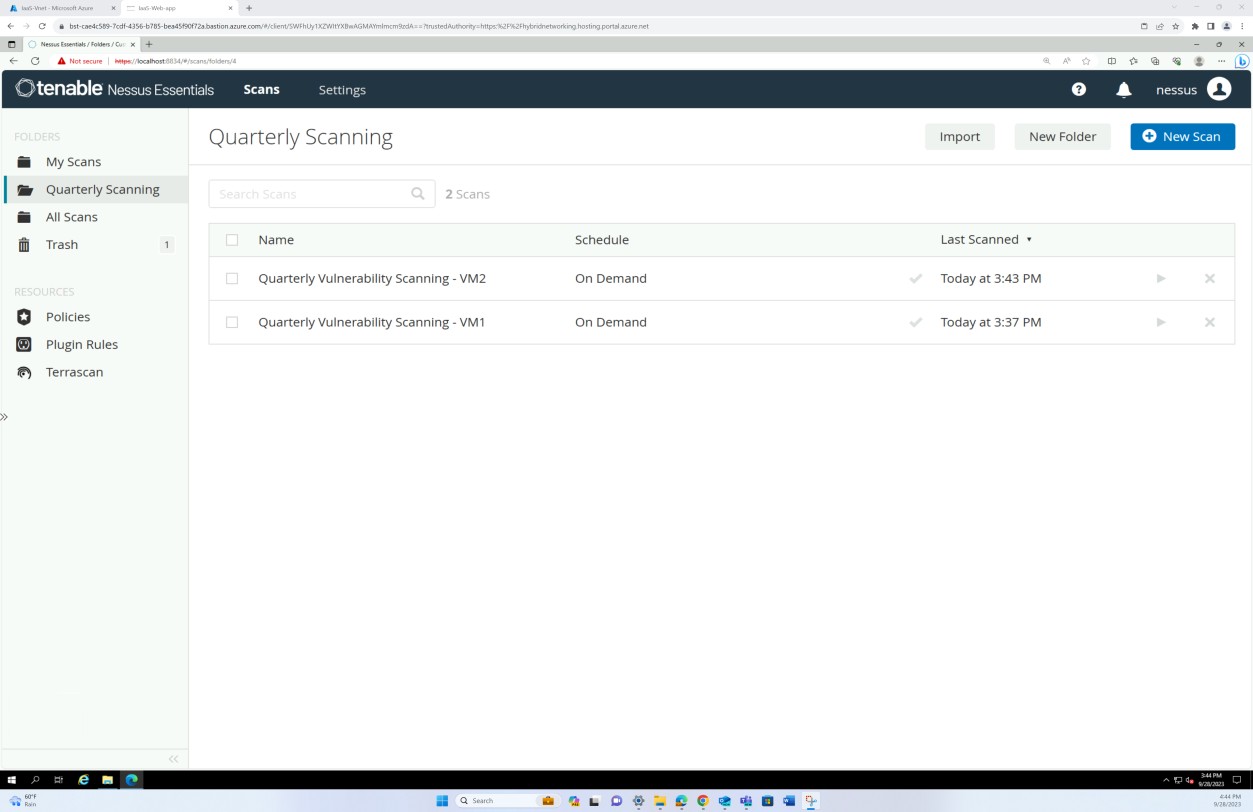
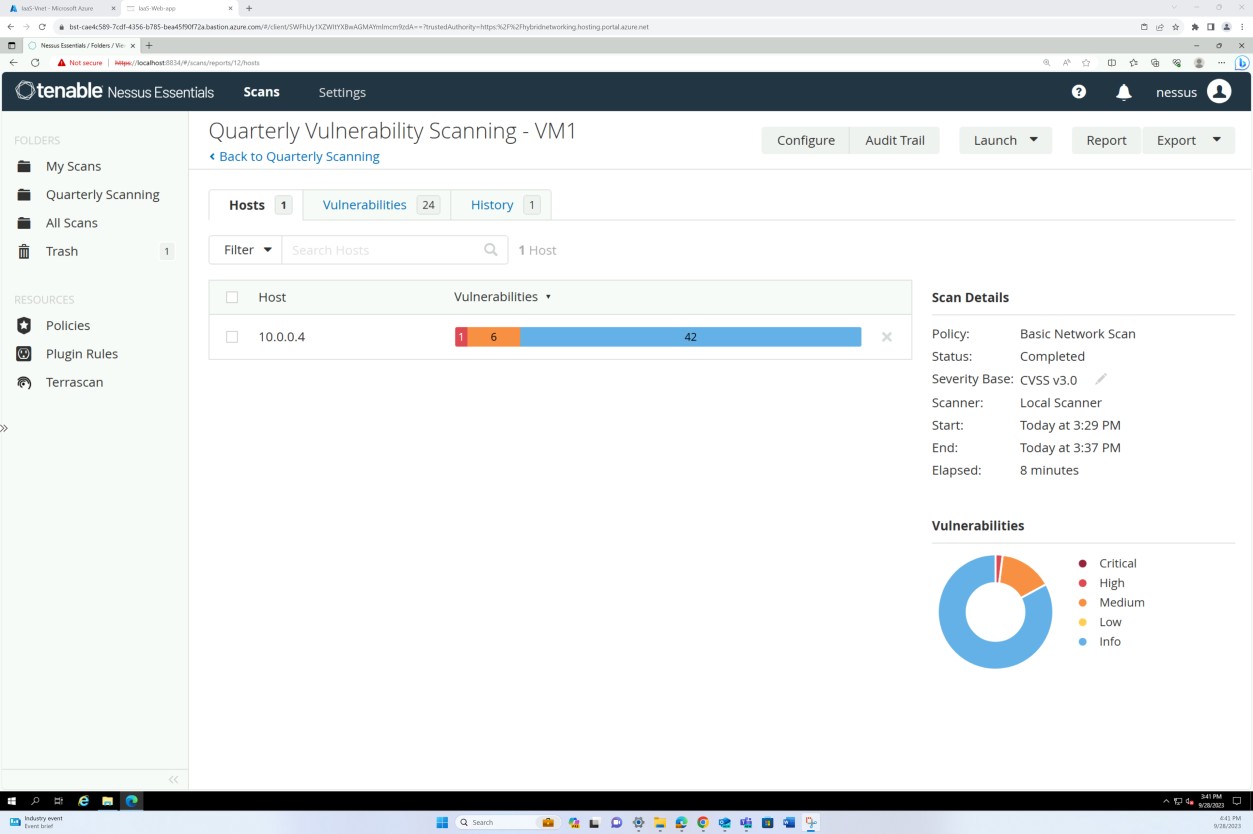
На предыдущих снимках экрана показана настройка папок для ежеквартально сканировать виртуальные машины узла.
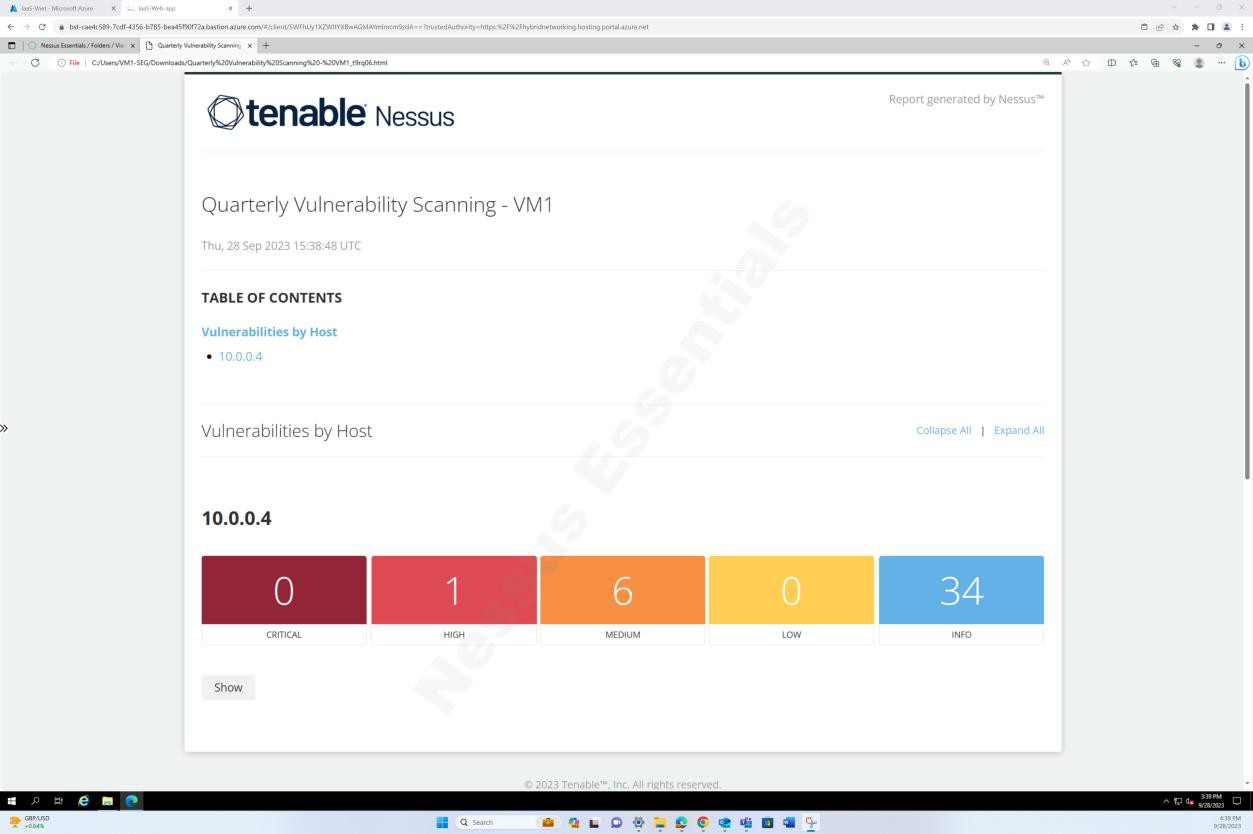
На снимках экрана выше и ниже показаны выходные данные отчета о проверке уязвимостей.
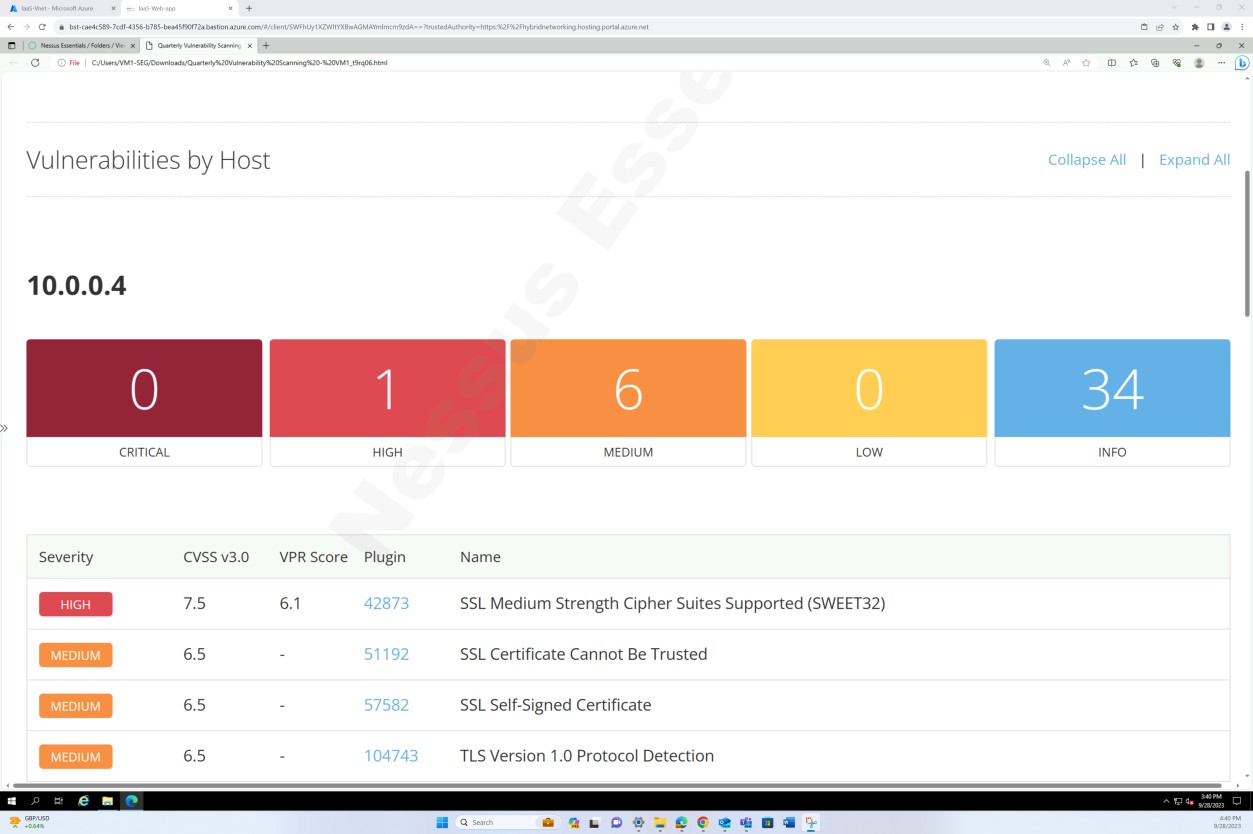
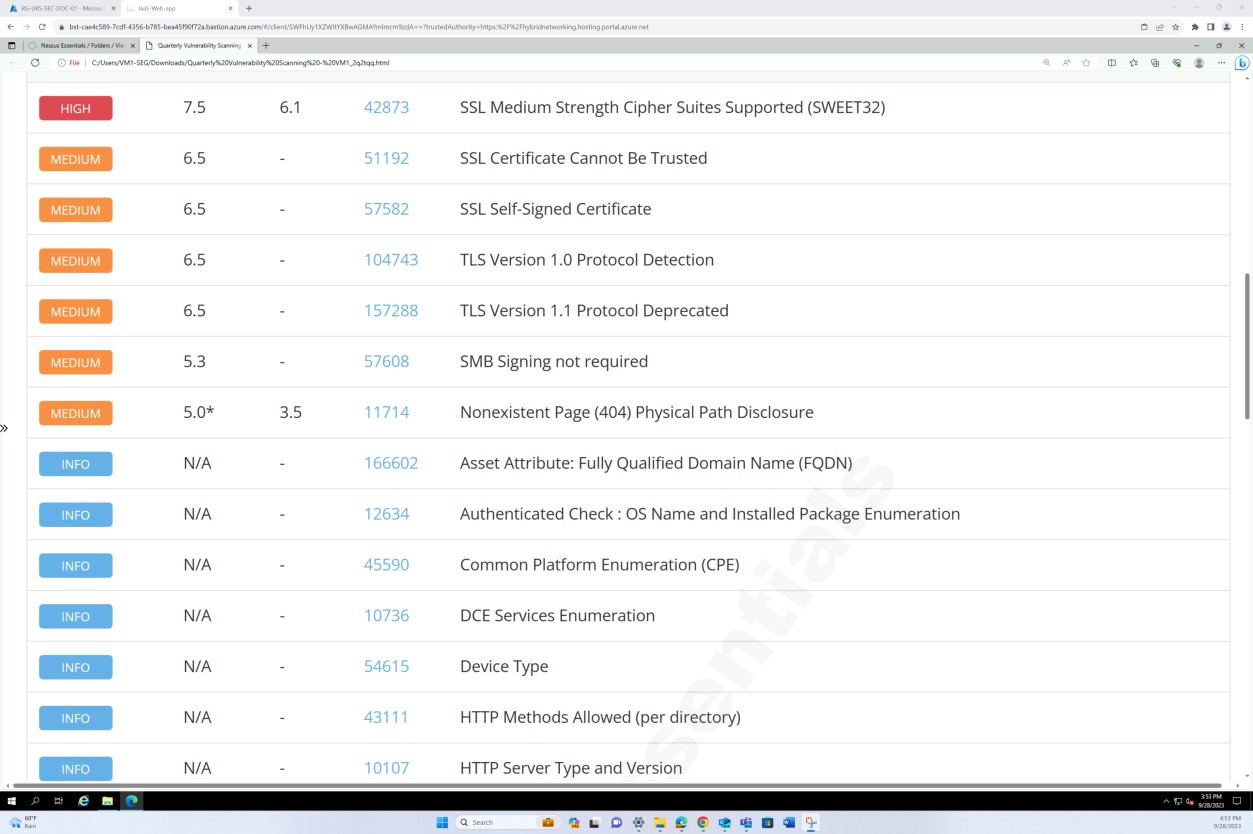
На следующем снимку экрана показано продолжение отчета, охватывающего все обнаруженные проблемы.
Элемент управления No 7
Предоставьте повторное сканирование доказательств, подтверждающих, что:
- Исправление всех уязвимостей, обнаруженных в элементе управления 6, выполняется в соответствии с минимальным окном исправлений, определенным в политике.
Намерение: исправление
Неспособность быстро выявлять, управлять и устранять уязвимости и неправильные настройки может увеличить риск компрометации, приводящей к потенциальному нарушению данных. Правильное выявление и устранение проблем рассматривается как важное значение для общего состояния безопасности и среды организации, что соответствует рекомендациям различных платформ безопасности, например ISO 27001 и PCI DSS.
Цель этого элемента управления заключается в том, чтобы организация предоставляла достоверные доказательства повторного сканирования, демонстрируя, что все уязвимости, обнаруженные в элементе управления 6, были устранены. Исправление должно соответствовать минимальному окну исправления, определенному в политике управления исправлениями организации.
Рекомендации: исправление
Предоставьте отчеты повторного сканирования, проверяющие, что все уязвимости, обнаруженные в элементе управления 6, были устранены в соответствии с окнами исправлений, определенными в элементе управления 4 .
Пример доказательства: исправление
На следующем снимке экрана показана проверка Nessus среды в области (в этом примере один компьютер с именем Thor), показывающая уязвимости2 августа 2023 г.
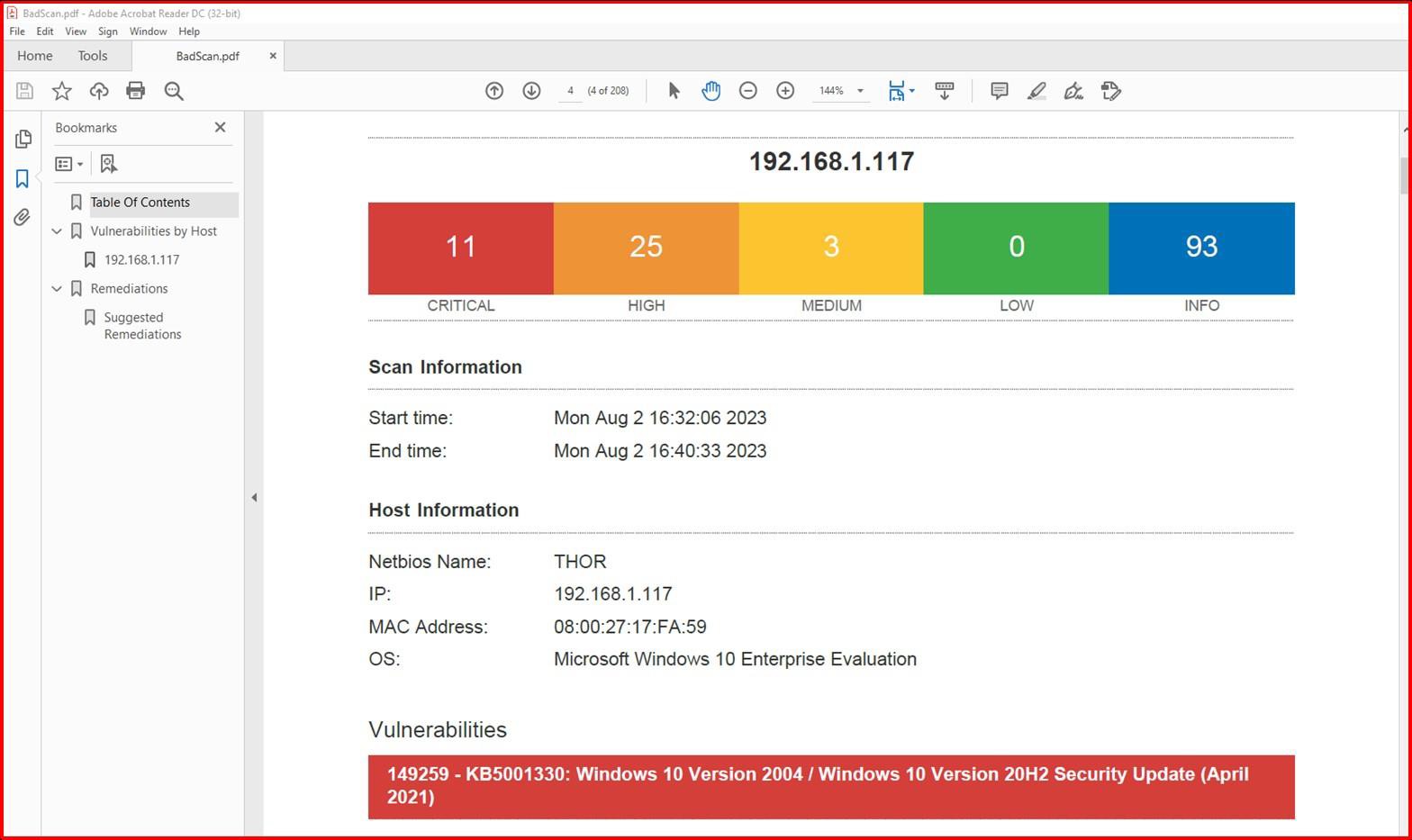
На следующем снимку экрана показано, что проблемы были устранены через 2 дня, которое находится в окне установки исправлений, определенном в политике исправления.
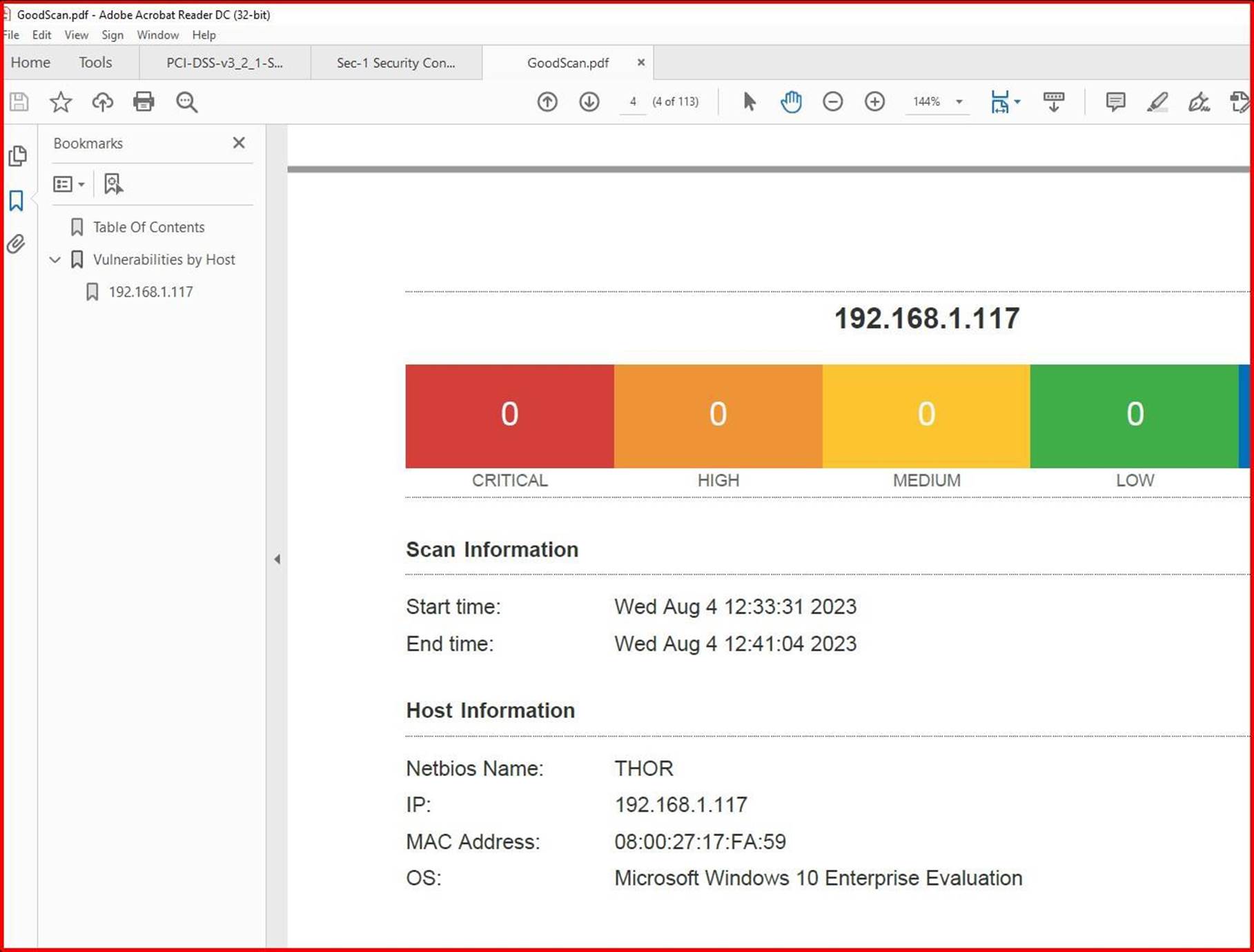
Примечание. В предыдущих примерах полный снимок экрана не использовался, однако отправлено ВСЕ ISV
На снимках экрана должны быть полные снимки экрана, показывающие любой URL-адрес, вошедший в систему пользователь, системное время и дату.
Элементы управления безопасностью сети (NSC)
Средства управления сетевой безопасностью являются важным компонентом платформ кибербезопасности, таких как ISO 27001, элементы управления CIS и NIST Cybersecurity Framework. Они помогают организациям управлять рисками, связанными с киберугрозами, защищать конфиденциальные данные от несанкционированного доступа, соблюдать нормативные требования, своевременно обнаруживать киберугрозы и реагировать на них, а также обеспечивать непрерывность бизнес-процессов. Эффективная сетевая безопасность защищает ресурсы организации от широкого спектра угроз, исходящих из организации или за ее пределами.
Элемент управления No 8
Предоставьте очевидные доказательства того, что:
- Элементы управления безопасностью сети (NSC) устанавливаются на границе среды в области и устанавливаются между сетью периметра и внутренними сетями.
И, если hybrid, on-prem, IaaS также предоставляют доказательства того, что:
- Весь общедоступный доступ прекращается в сети периметра.
Намерение: NSC
Этот элемент управления направлен на подтверждение того, что элементы управления безопасностью сети (NSC) установлены в ключевых расположениях в сетевой топологии организации. В частности, NSC должны размещаться на границе среды в области и между сетью периметра и внутренними сетями. Цель этого контроля заключается в том, чтобы убедиться, что эти механизмы безопасности правильно расположены для максимальной эффективности защиты цифровых активов организации.
Рекомендации: NSC
Необходимо предоставить свидетельство о том, что элементы управления безопасностью сети (NSC) установлены на границе и настроены между периметром и внутренними сетями. Это можно сделать, предоставив снимки экрана из параметров конфигурации из элементов управления сетевой безопасностью (NSC) и область применения, например брандмауэр или эквивалентную технологию, например группы безопасности сети Azure (NSG), Azure Front Door и т. д.
Пример доказательства: NSC
Следующий снимок экрана: веб-приложение PaaS-web-app; в колонке сети показано, что весь входящий трафик проходит через Azure Front Door, в то время как весь трафик из приложения к другим ресурсам Azure направляется и фильтруется через группу безопасности сети Azure через интеграцию с виртуальной сетью.
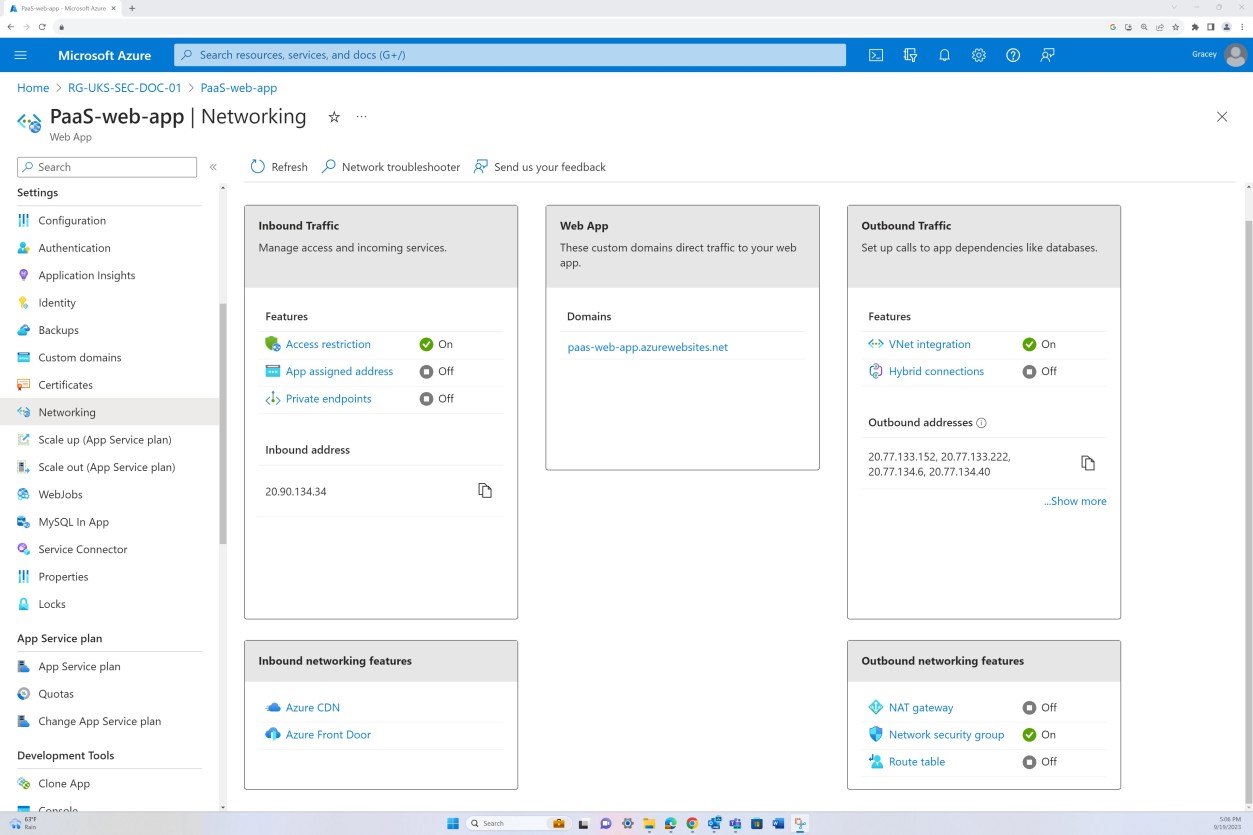
Правила запрета в разделе "Ограничения доступа" предотвращают входящий трафик, кроме Front Door (FD). Трафик направляется через FD до достижения приложения.
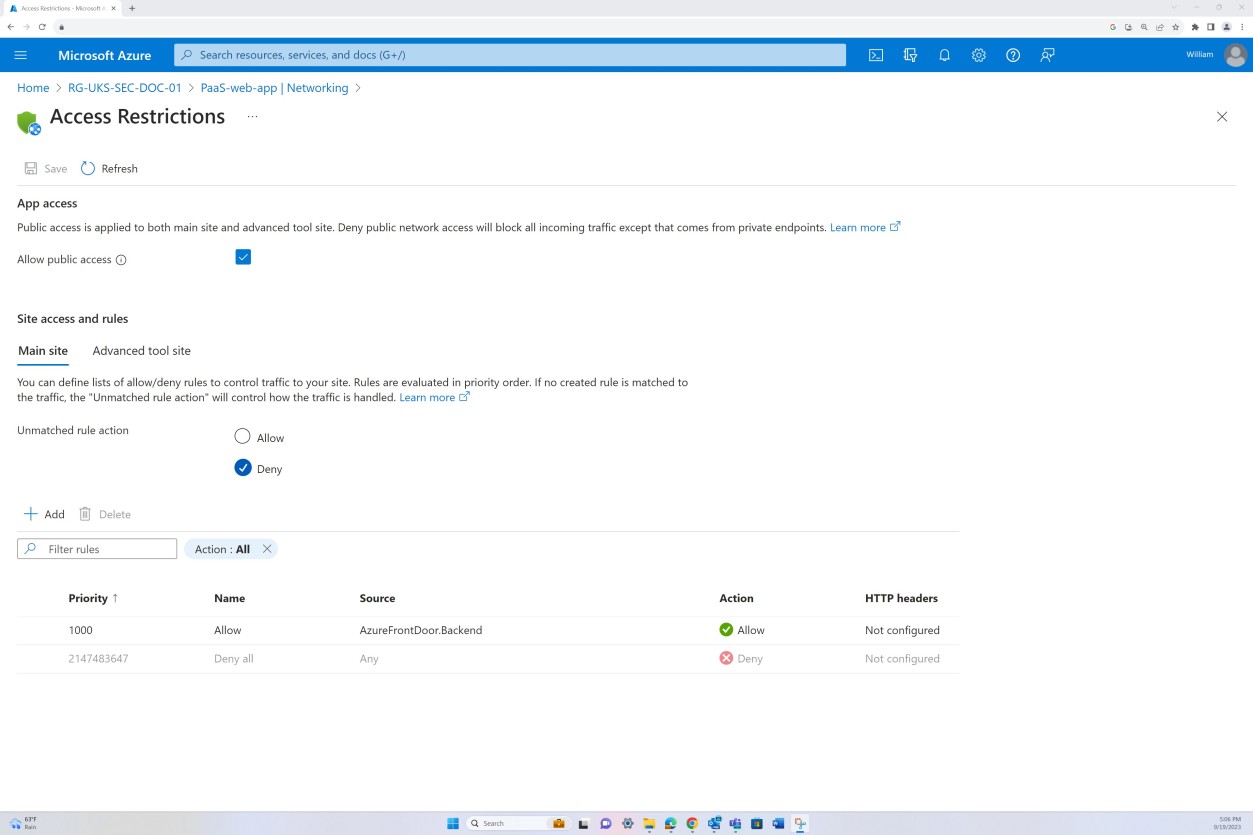
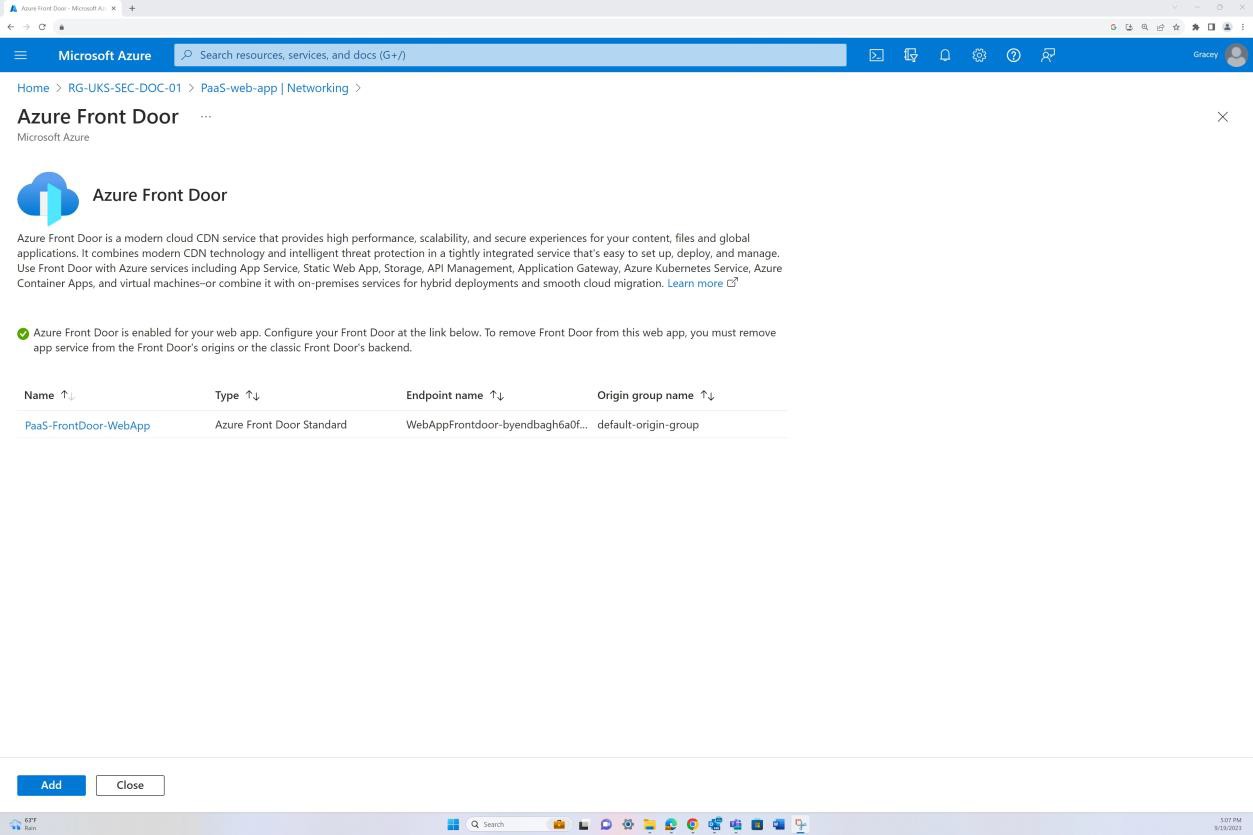
Пример доказательства: NSC
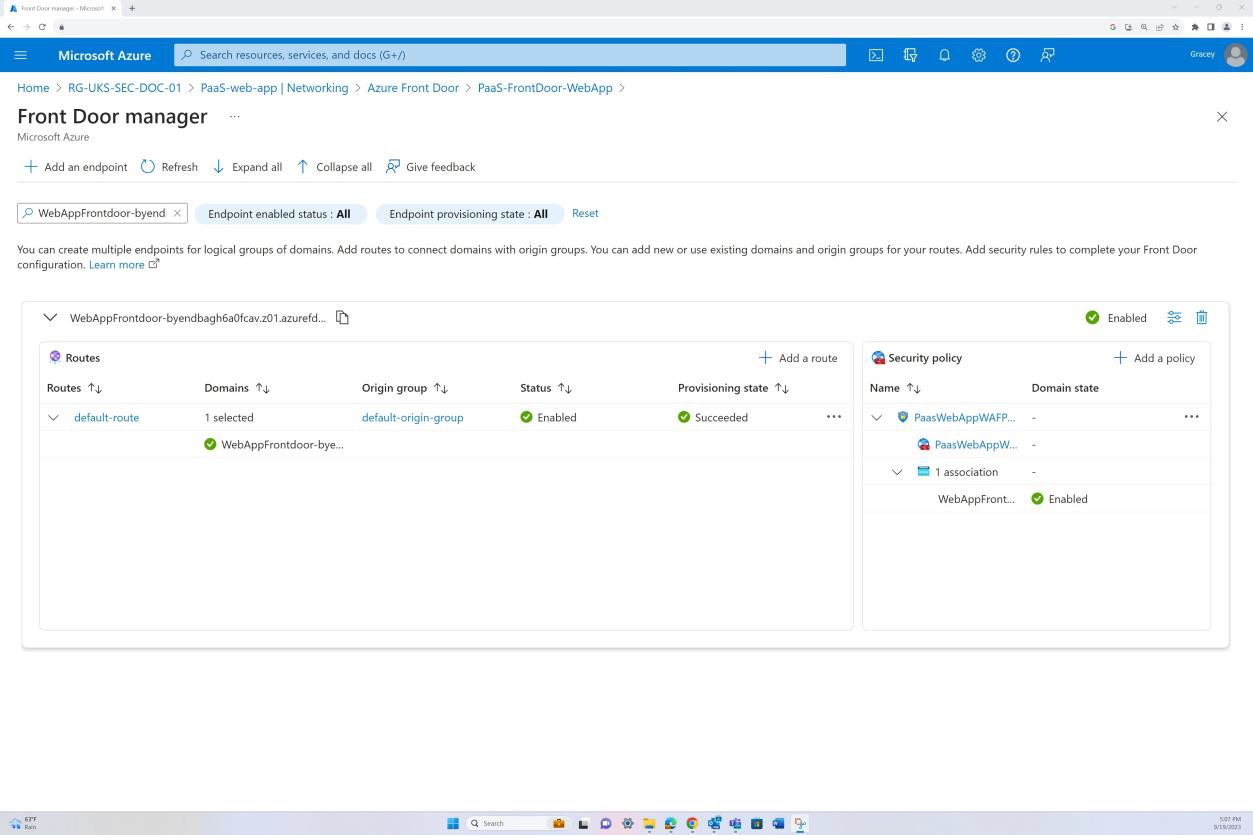
На следующем снимке экрана показан маршрут Azure Front Door по умолчанию, а также то, что трафик направляется через Front Door, прежде чем добраться до приложения. Также применена политика WAF.
Пример доказательства: NSC
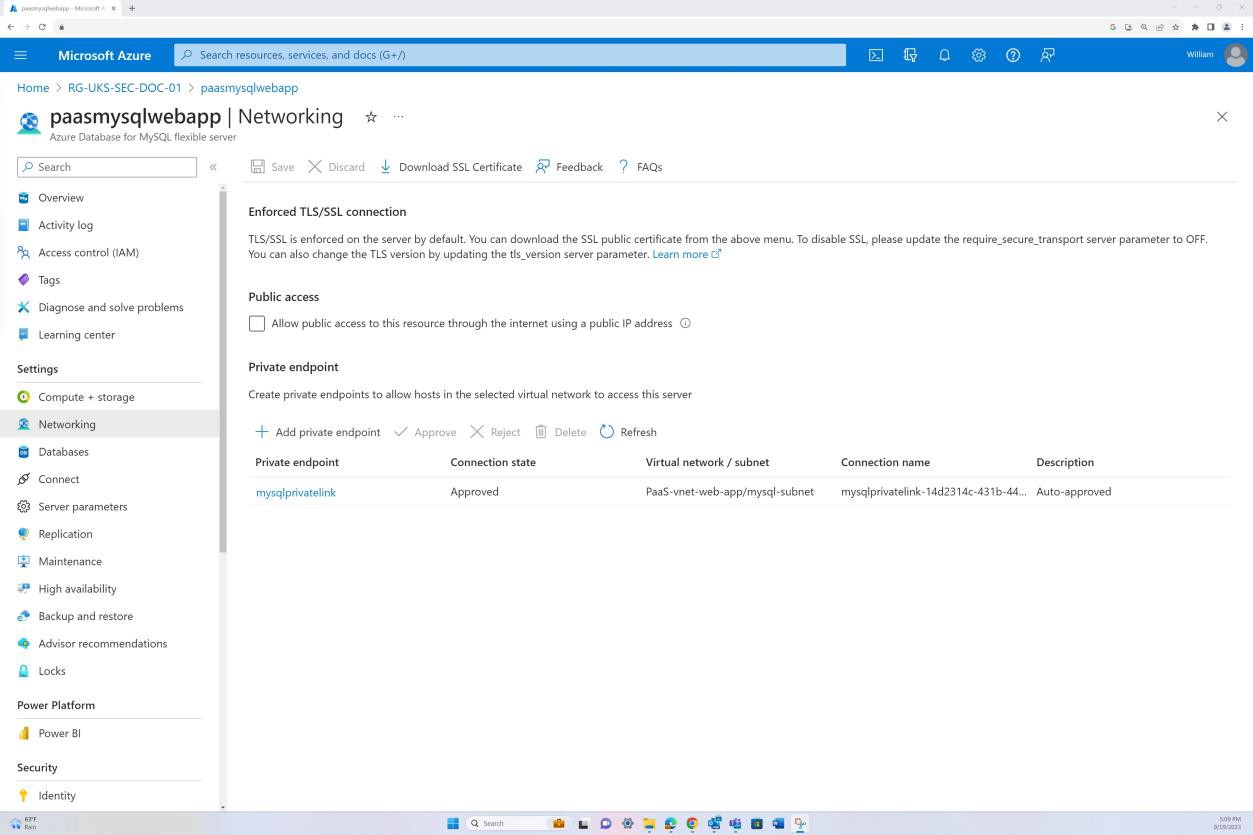
На первом снимке экрана показана группа безопасности сети Azure, применяемая на уровне виртуальной сети для фильтрации входящего и исходящего трафика. На втором снимке экрана показано, что SQL Server не маршрутизируется через Интернет и интегрирован через виртуальную сеть и приватный канал.
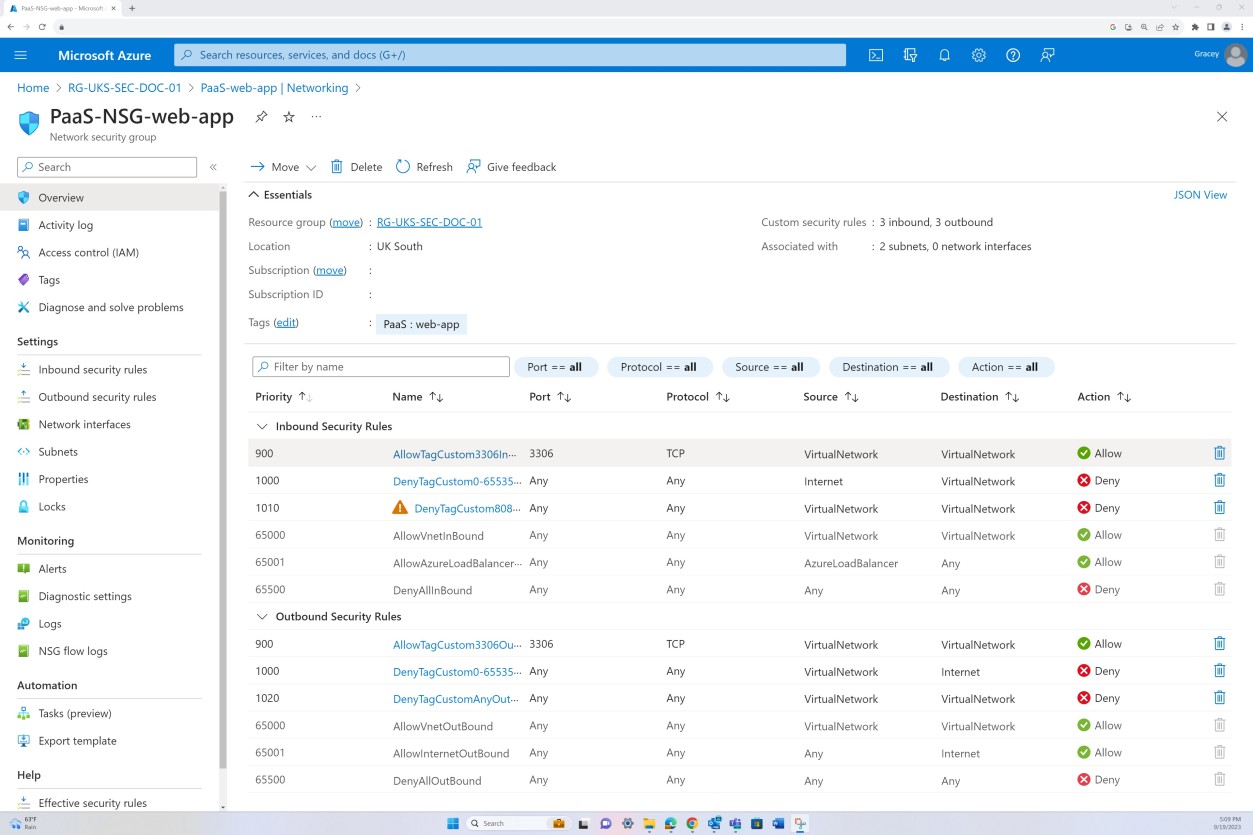
Это гарантирует, что группа безопасности сети фильтрует внутренний трафик и обмен данными, прежде чем достичь сервера SQL Server.
Намерение**:** гибридное, локальное, IaaS
Это важно для организаций, которые используют гибридные, локальные модели или модели IaaS (инфраструктура как услуга). Она направлена на обеспечение прекращения общего доступа в сети периметра, что имеет решающее значение для контроля точек входа во внутреннюю сеть и снижения потенциального воздействия внешних угроз. Свидетельством соответствия могут быть конфигурации брандмауэра, списки управления доступом к сети или другая аналогичная документация, которая может подтвердить утверждение о том, что общий доступ не выходит за пределы сети периметра.
Пример доказательства: гибридная, локальная, IaaS
На снимке экрана показано, что сервер SQL Server не маршрутизируется через Интернет и интегрирован через виртуальную сеть и через приватный канал. Это гарантирует, что разрешен только внутренний трафик.
Пример доказательства: гибридная, локальная, IaaS
На следующих снимках экрана показано, что сегментация сети выполняется в виртуальной сети в области. Виртуальная сеть, как показано ниже, делится на три подсети, к каждой из которых применяется группа безопасности сети.
Общедоступная подсеть выступает в качестве сети периметра. Весь общедоступный трафик направляется через эту подсеть и фильтруется через группу безопасности сети с определенными правилами, и разрешен только явно определенный трафик. Серверная часть состоит из частной подсети без открытого доступа. Доступ ко всем виртуальным машинам разрешен только через узел-бастион, который имеет собственную группу безопасности сети, применяемую на уровне подсети.
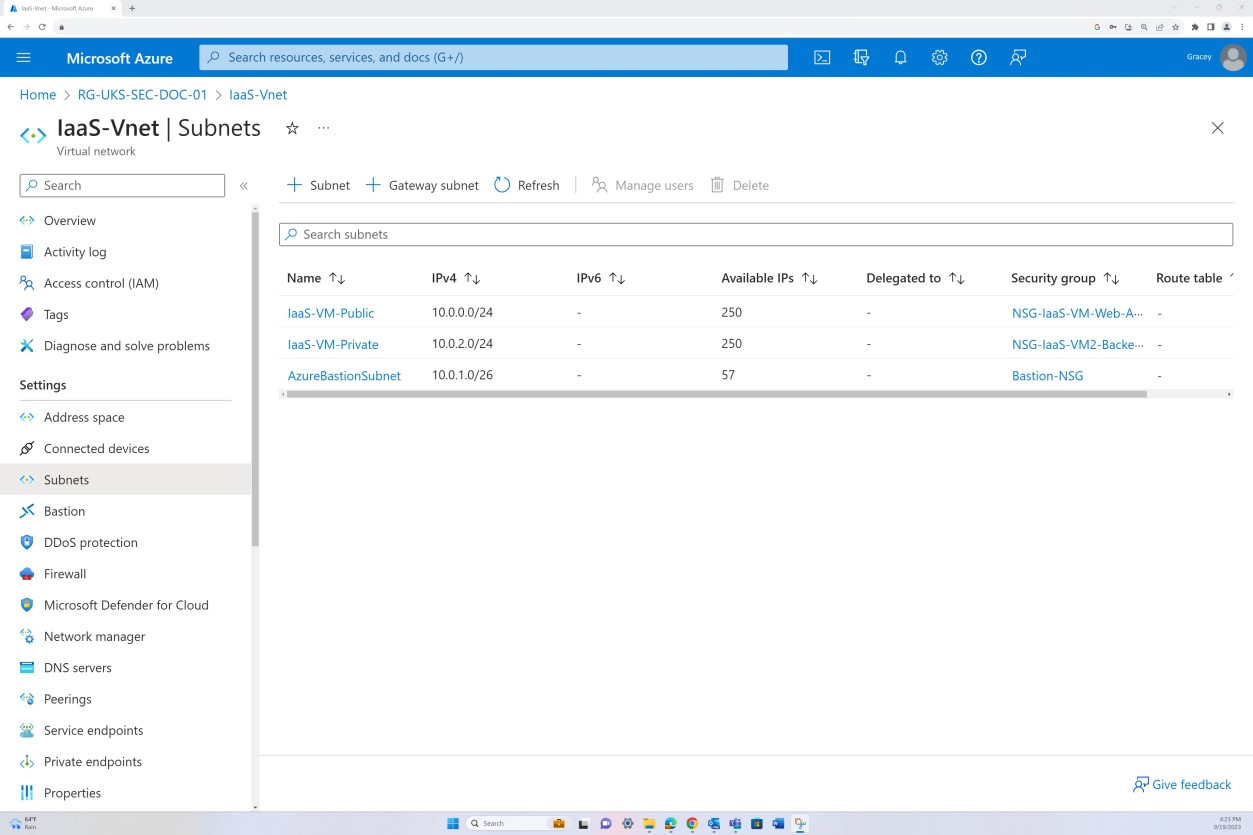
На следующем снимке экрана показано, что трафик из Интернета на определенный IP-адрес разрешен только через порт 443. Кроме того, RDP разрешен только из диапазона IP-адресов Бастиона в виртуальную сеть.
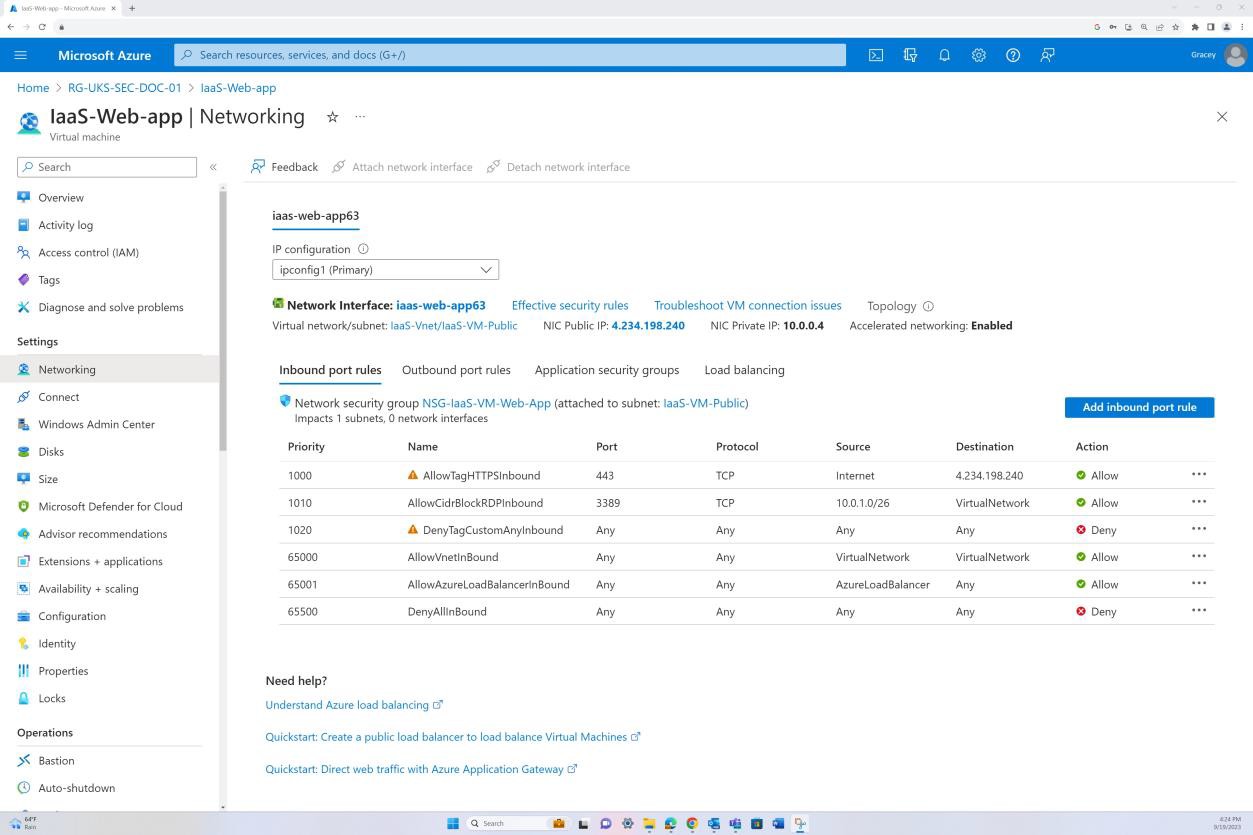
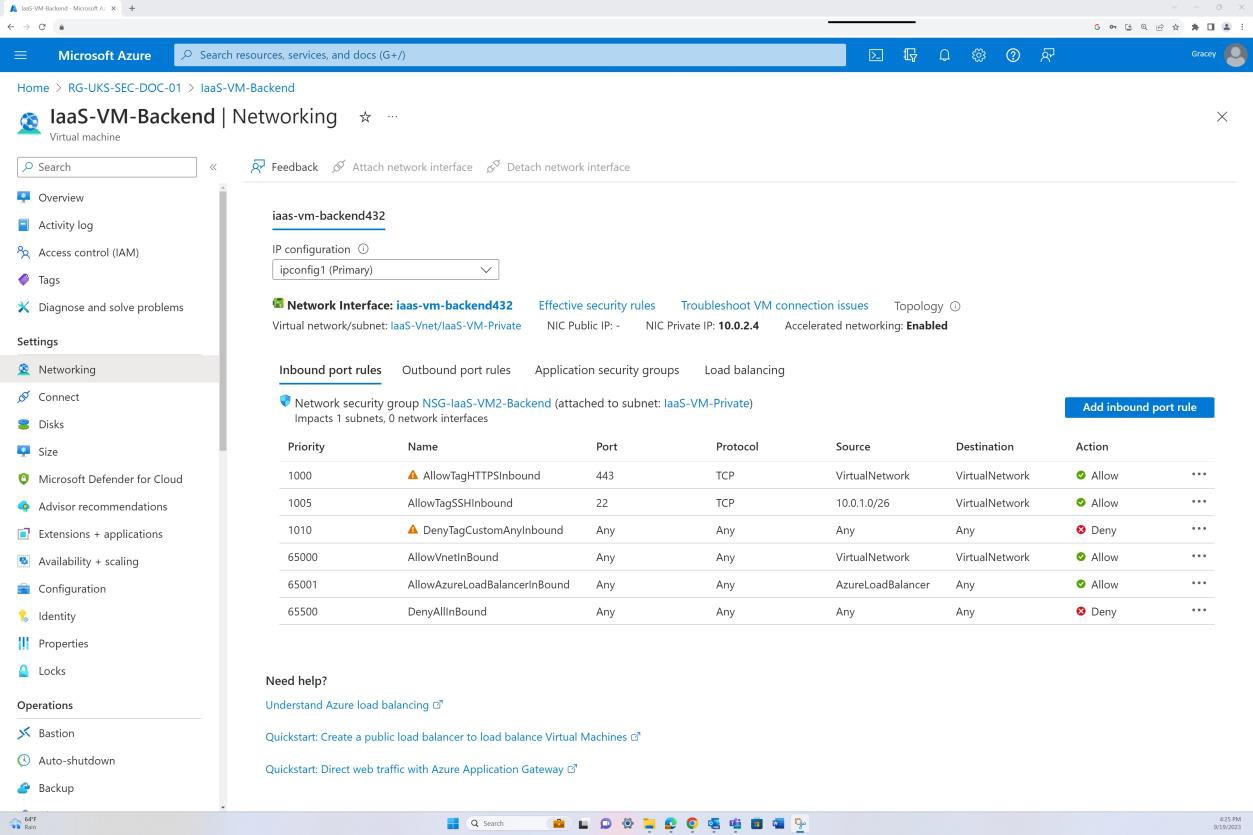
На следующем снимке экрана показано, что серверная часть не маршрутизируется через Интернет (это связано с отсутствием общедоступного IP-адреса сетевого адаптера) и что трафик может исходить только из виртуальной сети и бастиона.
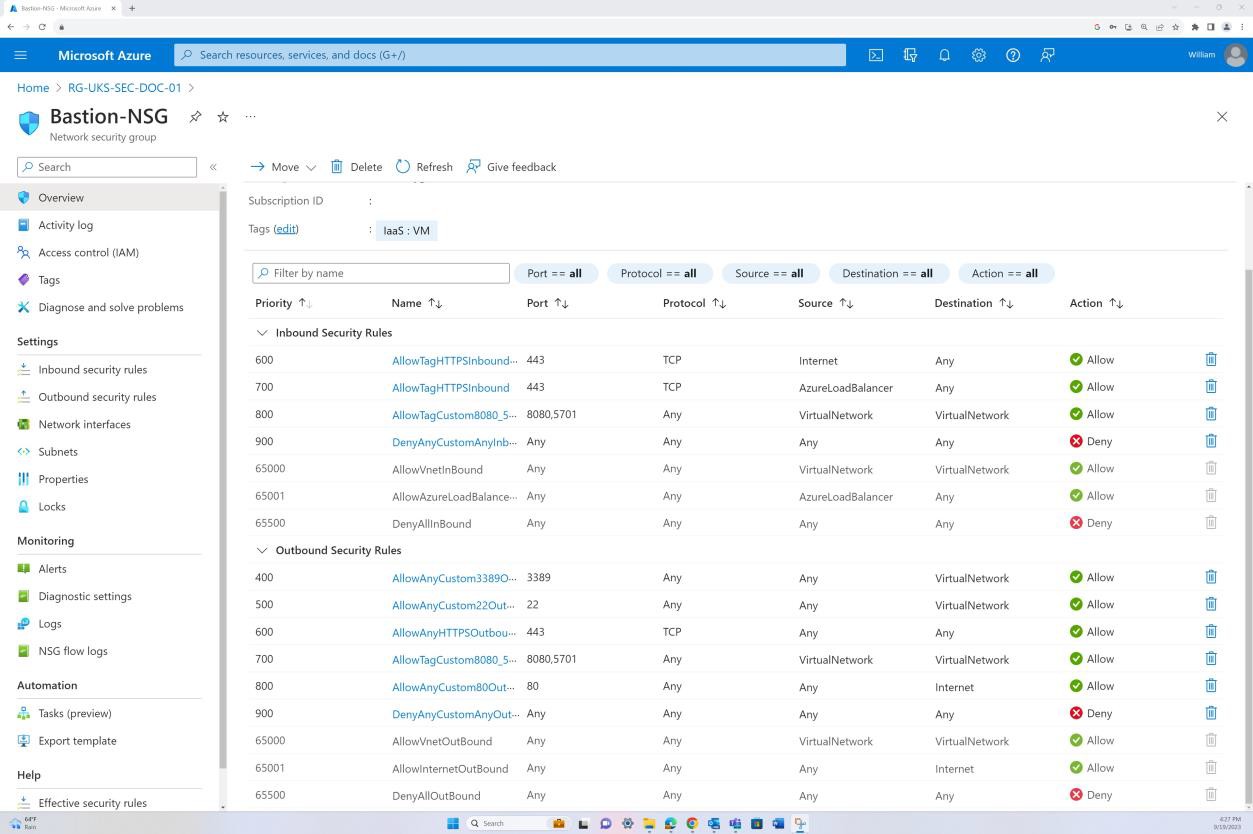
На снимках экрана показано, что узел Бастиона Azure используется для доступа к виртуальным машинам только в целях обслуживания.
Элемент управления No 9
Все элементы управления безопасностью сети (NSC) настроены на удаление трафика, не определенного явным образом в базе правил.
Проверки правил элементов управления безопасностью сети (NSC) выполняются по крайней мере каждые 6 месяцев.
Намерение: NSC
Эта вложенная точка гарантирует, что все элементы управления безопасностью сети (NSC) в организации настроены на удаление любого сетевого трафика, который явно не определен в базе правил. Цель состоит в том, чтобы обеспечить соблюдение принципа минимальных привилегий на сетевом уровне, разрешая только авторизованный трафик, блокируя весь неуказаемый или потенциально вредоносный трафик.
Рекомендации: NSC
Для этого могут быть предоставлены конфигурации правил, в которых показаны правила для входящего трафика и где эти правила завершаются. либо путем маршрутизации общедоступных IP-адресов к ресурсам, либо путем предоставления NAT (преобразование сетевых адресов) для входящего трафика.
Пример доказательства: NSC
На снимке экрана показана конфигурация NSG, включая набор правил по умолчанию и пользовательское правило Deny:All , чтобы сбросить все правила NSG по умолчанию и убедиться, что весь трафик запрещен. В дополнительных настраиваемых правилах правило Deny:All явно определяет разрешенный трафик.
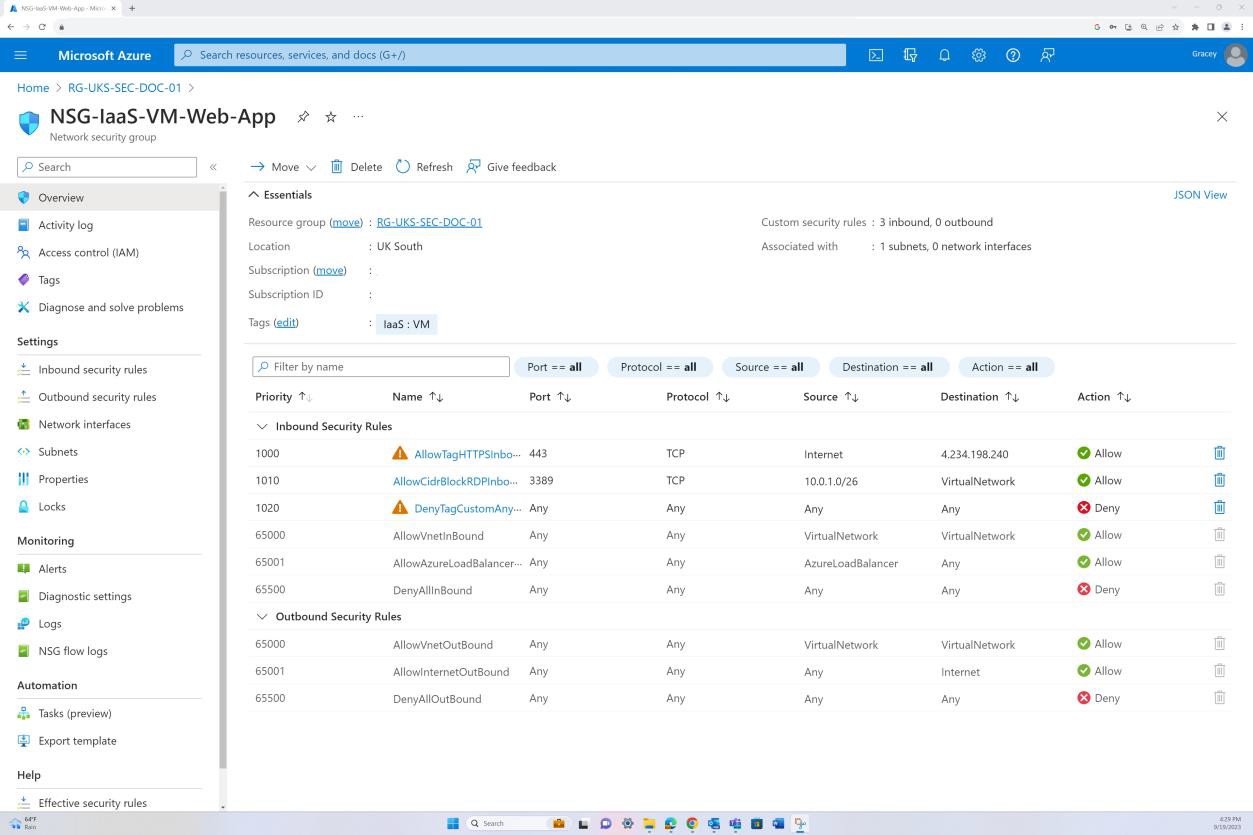
Пример доказательства: NSC
На следующих снимках экрана показано, что Azure Front Door развернута, а весь трафик направляется через Front Door. Применяется политика WAF в режиме предотвращения, которая фильтрует входящий трафик на наличие потенциальных вредоносных полезных данных и блокирует его.
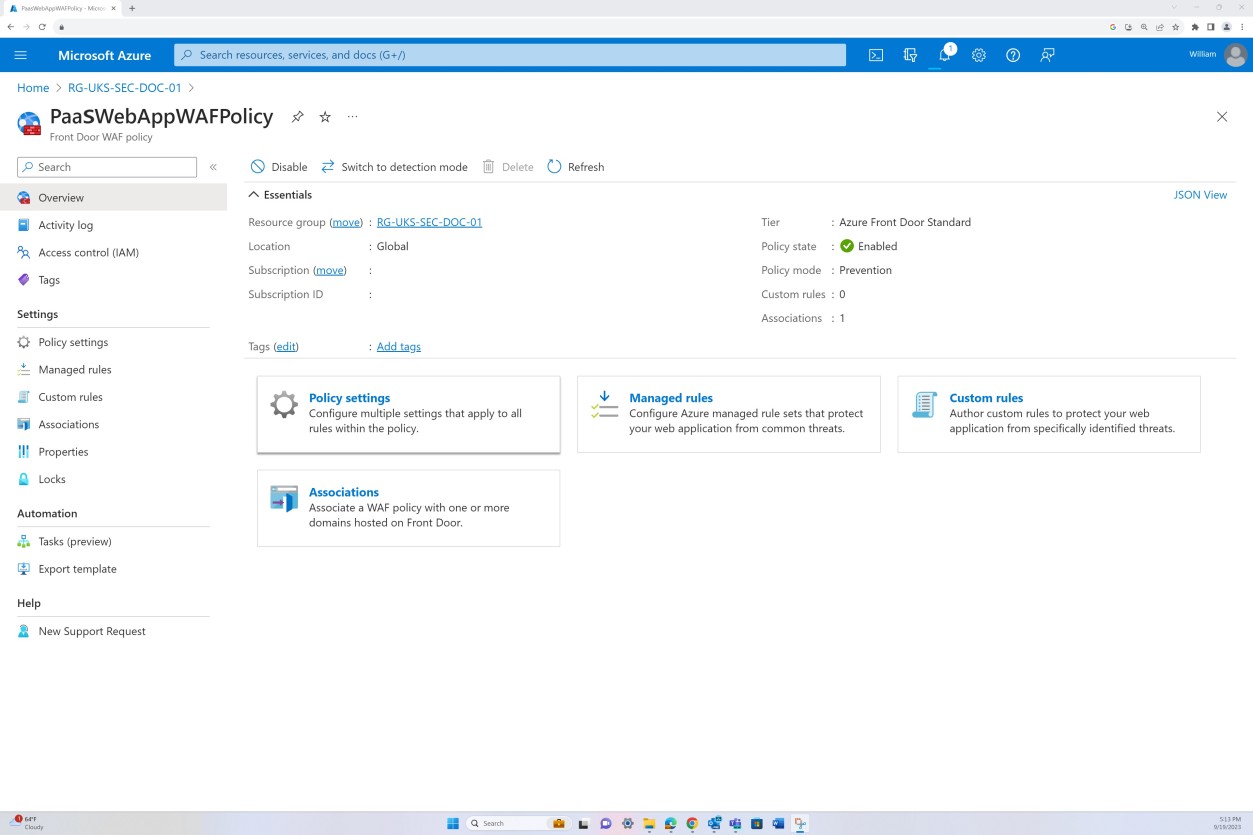
Намерение: NSC
Без регулярных проверок средства управления безопасностью сети (NSC) могут стать устаревшими и неэффективными, в результате чего организация будет уязвима к кибератакам. Это может привести к утечке данных, краже конфиденциальной информации и другим инцидентам кибербезопасности. Регулярные проверки NSC необходимы для управления рисками, защиты конфиденциальных данных, соблюдения нормативных требований, своевременного обнаружения киберугроз и реагирования на них, а также обеспечения непрерывности бизнес-процессов. Для этого необходимо, чтобы элементы управления безопасностью сети (NSC) проходили проверку базы правил по крайней мере каждые шесть месяцев. Регулярные проверки имеют решающее значение для поддержания эффективности и актуальности конфигураций NSC, особенно в динамически изменяющихся сетевых средах.
Рекомендации: NSC
Любые предоставленные доказательства должны быть в состоянии продемонстрировать, что собрания по проверке правил были выполнены. Это можно сделать, поделившись протоколом собрания проверки NSC и любыми дополнительными доказательствами управления изменениями, показывающими все действия, выполненные из проверки. Убедитесь, что указаны даты, так как аналитик по сертификации, рассматривающий вашу заявку, должен будет видеть как минимум два из этих документов о проверке собраний (т. е. каждые шесть месяцев).
Пример доказательства: NSC
На этих снимках экрана показано, что существуют шестимесячные проверки брандмауэра, а сведения сохраняются на платформе Confluence Cloud.
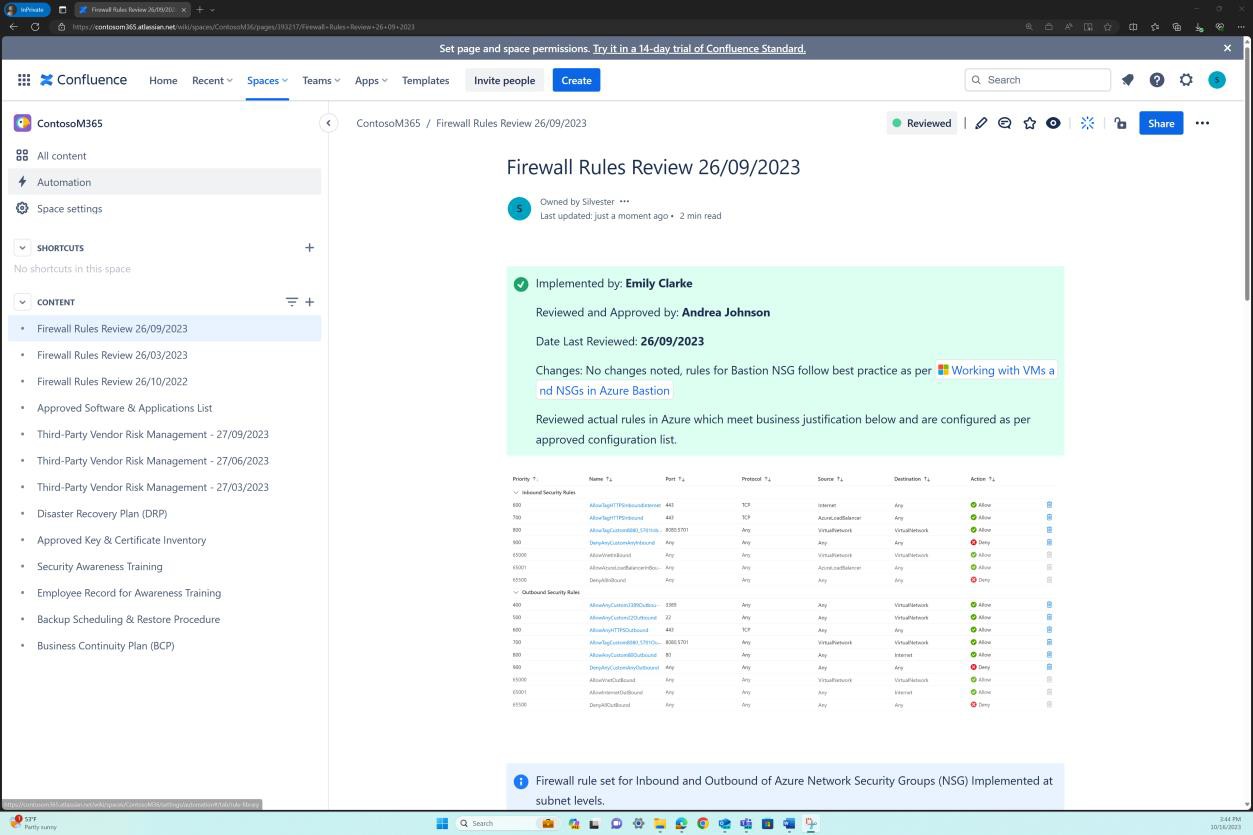
На следующем снимке экрана показано, что каждая проверка правил имеет страницу, созданную в Confluence. Проверка правил содержит утвержденный список наборов правил с описанием разрешенного трафика, номера порта, протокола и т. д., а также бизнес-обоснования.
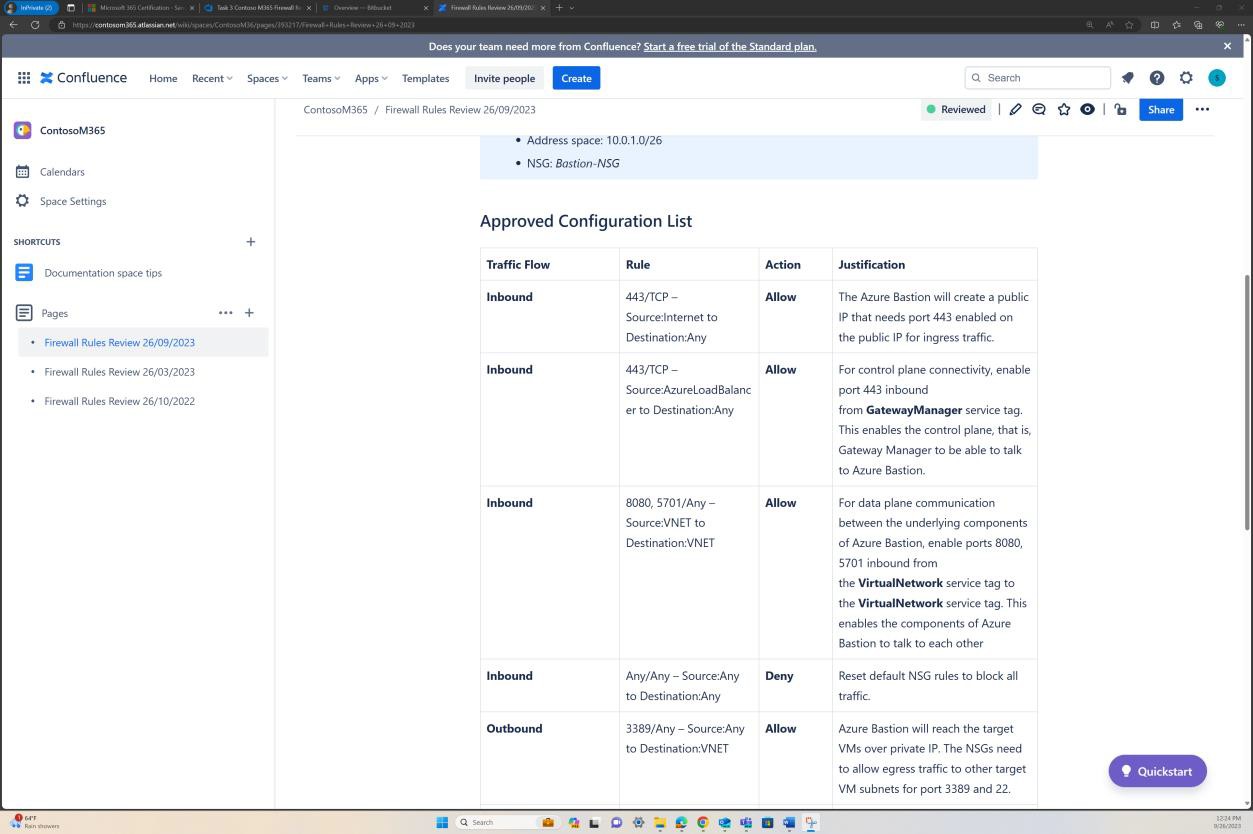
Пример доказательства: NSC
На следующем снимке экрана показан альтернативный пример шестимесячной проверки правил в DevOps.
Пример доказательства: NSC
На этом снимке экрана показан пример проверки правил, выполняемой и записываемой как билет в DevOps.
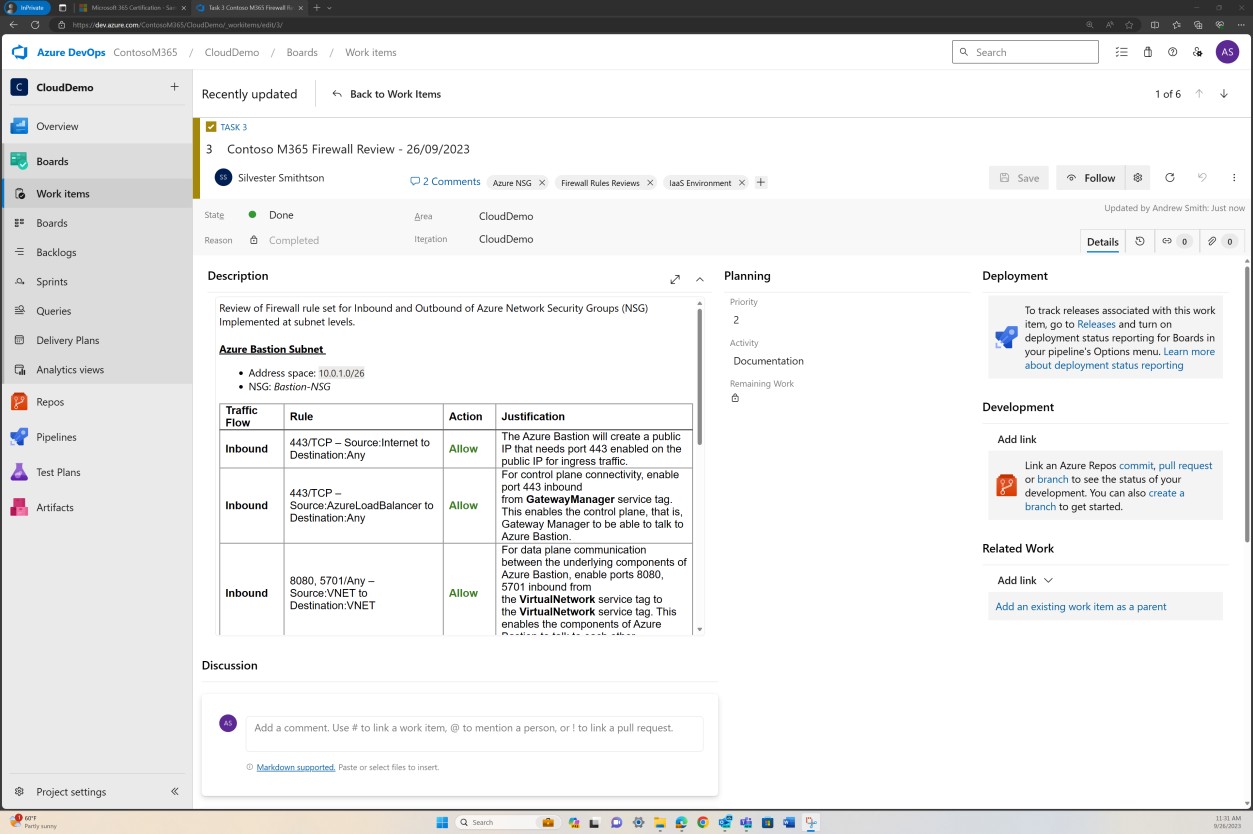
На предыдущем снимке экрана показан установленный список задокументированных правил вместе с бизнес-обоснованием, а на следующем изображении показан моментальный снимок правил в билете из фактической системы.
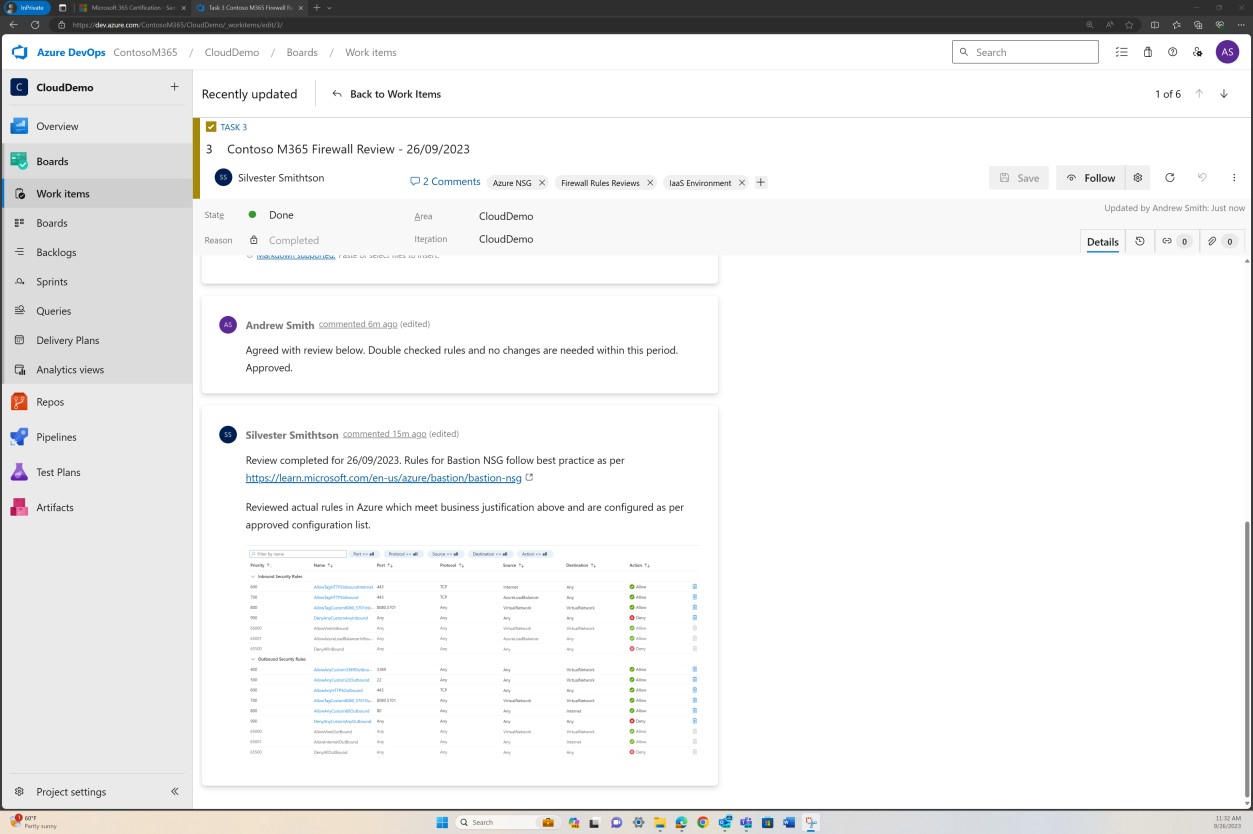
Элемент управления изменениями
Установленный и понятный процесс управления изменениями имеет важное значение для обеспечения того, чтобы все изменения проходили через структурированный процесс, который можно повторять. Гарантируя, что все изменения проходят через структурированный процесс, организации могут обеспечить эффективное управление изменениями, их коллегирующую проверку и адекватную проверку, прежде чем они будут подписаны. Это не только помогает свести к минимуму риск сбоев системы, но и помогает свести к минимуму риск потенциальных инцидентов безопасности за счет внесения неправильных изменений.
Элемент управления No 10
Предоставьте доказательства того, что:
Любые изменения, внесенные в рабочие среды, реализуются с помощью задокументированных запросов на изменение, которые содержат:
влияние изменения.
сведения о процедурах резервного выхода.
тестирование, необходимое для проведения.
проверка и утверждение уполномоченным персоналом.
Намерение: элемент управления изменениями
Цель этого элемента управления заключается в том, чтобы все запрошенные изменения были тщательно рассмотрены и задокументированы. Это включает в себя оценку влияния изменения на безопасность системы или среды, документирование любых процедур обратного выхода, помогающих в восстановлении, если что-то пойдет не так, и подробные сведения о тестировании, необходимом для проверки успешности изменения.
Должны быть реализованы процессы, которые запрещают внесение изменений без надлежащего разрешения и выхода. Изменение должно быть авторизовано перед реализацией, и после его завершения изменение должно быть подписано. Это гарантирует, что запросы на изменение были должным образом проверены и кто-то в властных органах подписал изменение.
Рекомендации: управление изменениями
Доказательства можно предоставить путем предоставления общего доступа к снимкам экрана примера запросов на изменение, демонстрирующих, что сведения о влиянии изменения, процедурах обратного выхода, тестировании хранятся в запросе на изменение.
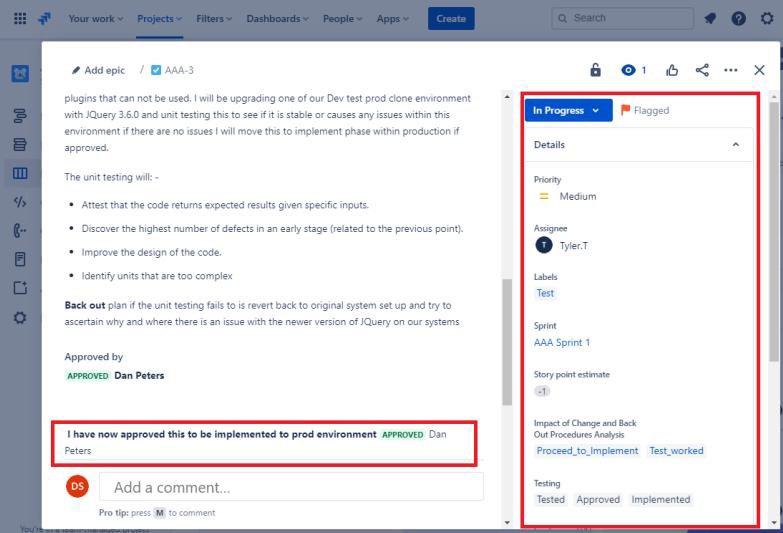
Пример доказательства: элемент управления изменениями
На следующем снимку экрана показана новая уязвимость межсайтовых сценариев (XSS), назначаемая и документ для запроса на изменение. В билетах ниже показаны сведения, которые были заданы или добавлены в билет при его пути к разрешению.
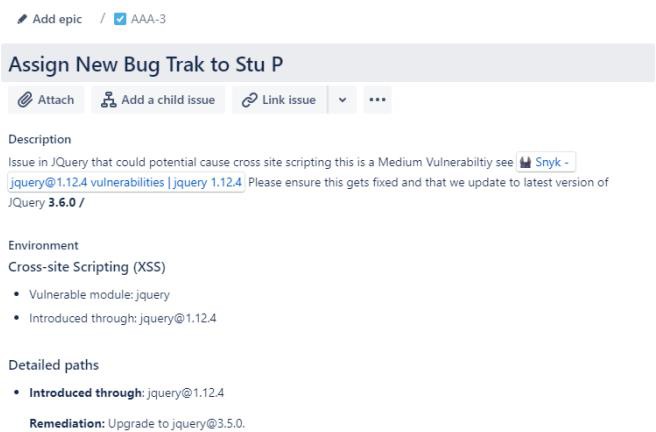
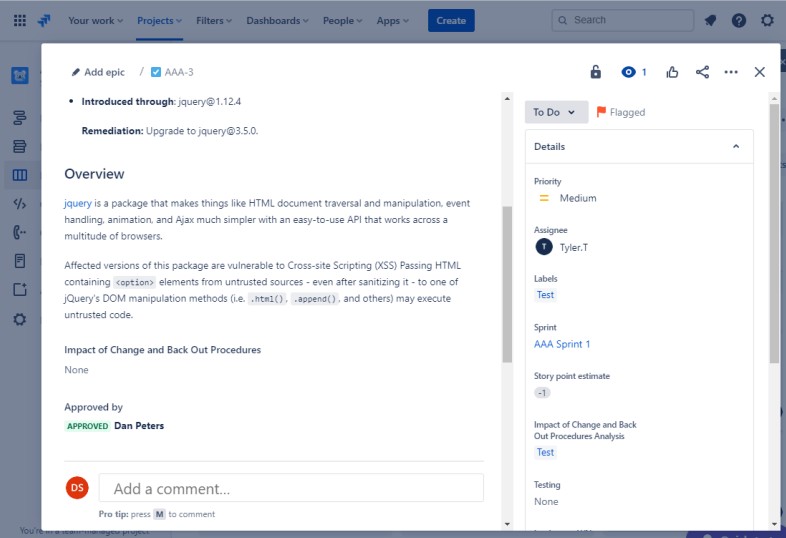
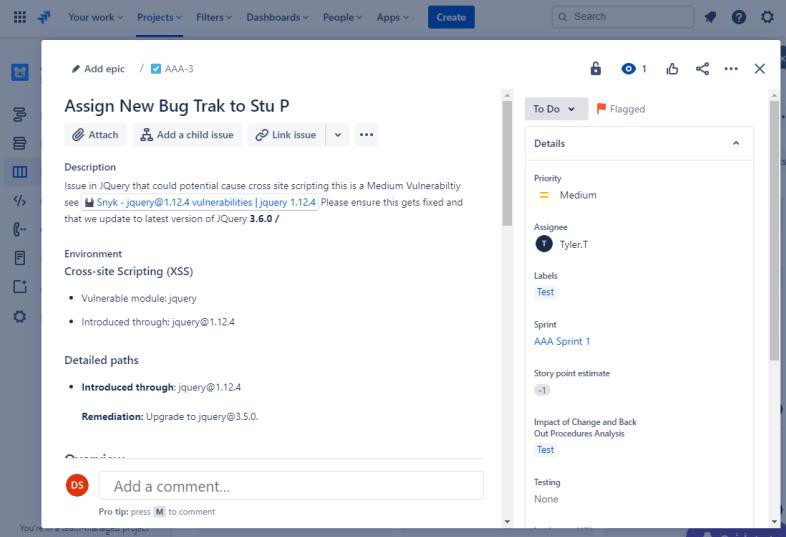
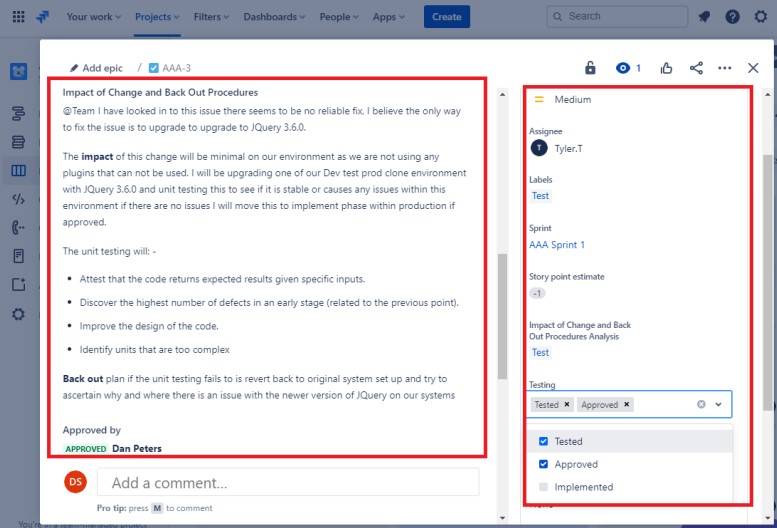
В следующих двух билетах показано влияние изменения на систему и процедуры обратного выхода, которые могут потребоваться в случае возникновения проблемы. Влияние изменений и процедур обратного выхода прошло процесс утверждения и было утверждено для тестирования.
На следующем снимку экрана проверка изменений была утверждена, а справа вы увидите, что изменения утверждены и протестированы.
На протяжении всего процесса обратите внимание, что человек, выполняющий работу, человек, сообщающий о ней, и человек, утверждающий работу, являются разными людьми.
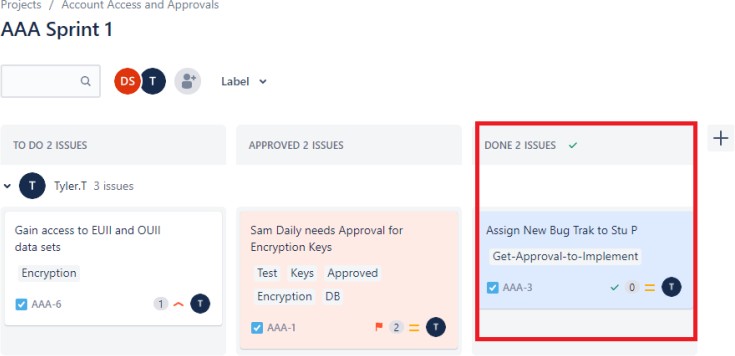
В следующем запросе показано, что изменения утверждены для реализации в рабочей среде. В правой области показано, что тест сработал и прошел успешно, и что изменения теперь реализованы в среде Prod.
Пример доказательства
На следующих снимках экрана показан пример билета Jira, показывающий, что изменение должно быть авторизовано перед реализацией и утверждением кем-либо, кроме разработчика или инициатора запроса. Изменения утверждаются кем-то с полномочиями. В правой части экрана показано, что после завершения изменения было подписано DP.
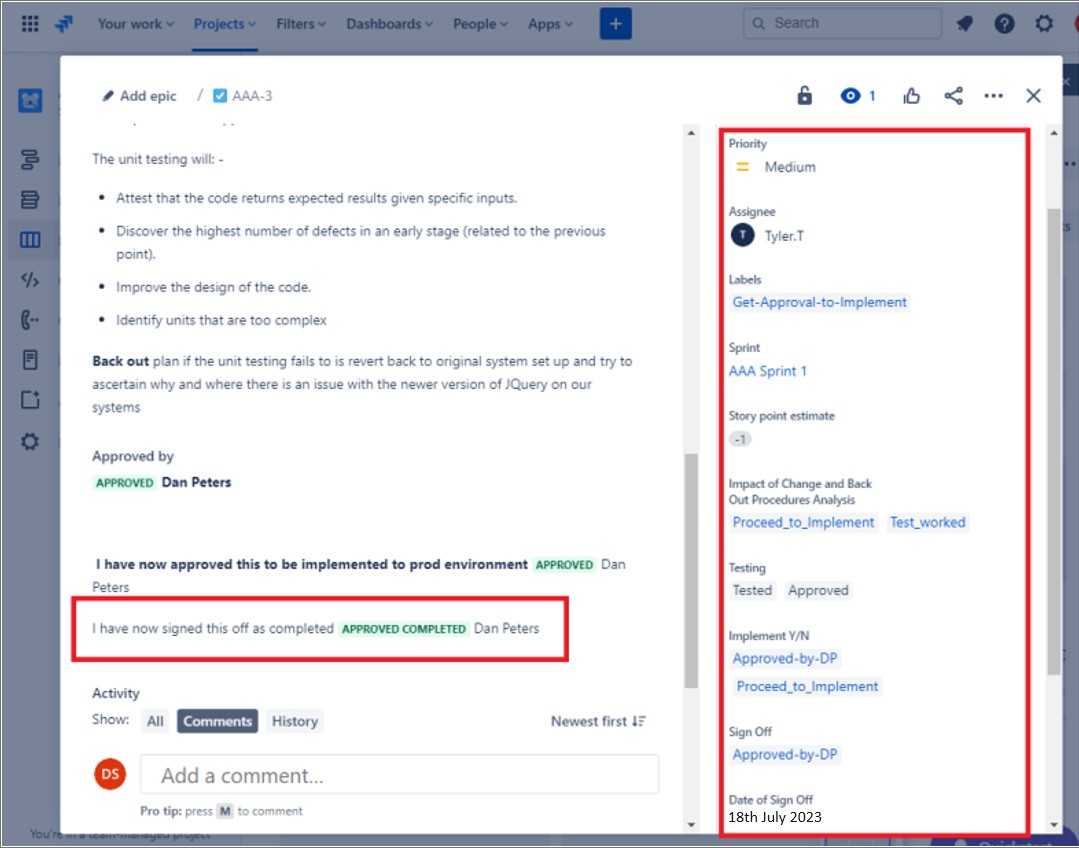
В билете после изменения было выполнено после завершения и отображается задание завершено и закрыто.
Обратите внимание: в этих примерах полный снимок экрана не использовался, однако все снимки экрана, отправленные isV, должны быть полными снимками экрана с любым URL-адресом, вошедшего в систему пользователя, а также системным временем и датой.
Элемент управления No 11
Укажите доказательства того, что:
Существуют отдельные среды, чтобы:
Среды разработки и тестирования и промежуточной среды обеспечивают разделение обязанностей от рабочей среды.
Разделение обязанностей обеспечивается с помощью элементов управления доступом.
Конфиденциальные рабочие данные не используются в средах разработки или тестирования или промежуточной среды.
Намерение: отдельные среды
Среды разработки и тестирования большинства организаций не настроены с той же силой, что и рабочие среды, и поэтому менее безопасны. Кроме того, тестирование не должно выполняться в рабочей среде, так как это может привести к проблемам с безопасностью или нанести ущерб доставке служб для клиентов. Поддерживая отдельные среды, обеспечивающие разделение обязанностей, организации могут гарантировать применение изменений в правильных средах, тем самым уменьшая риск возникновения ошибок путем внедрения изменений в рабочие среды, когда они были предназначены для среды разработки и тестирования.
Элементы управления доступом должны быть настроены таким образом, чтобы сотрудники, отвечающие за разработку и тестирование, не имели лишнего доступа к рабочей среде, и наоборот. Это сводит к минимуму вероятность несанкционированных изменений или раскрытия данных.
Использование рабочих данных в средах разработки и тестирования может повысить риск компрометации и подвергать организацию утечке данных или несанкционированный доступ. Намерение требует, чтобы все данные, используемые для разработки или тестирования, были дезинфицированы, анонимизированы или созданы специально для этой цели.
Рекомендации: отдельные среды
Можно предоставить снимки экрана, демонстрирующие различные среды, используемые для сред разработки и тестирования и рабочих сред. Как правило, у вас есть разные люди или команды с доступом к каждой среде, или если это невозможно, среды будут использовать разные службы авторизации, чтобы пользователи не могли по ошибке войти в неправильную среду для применения изменений.
Пример доказательства: отдельные среды
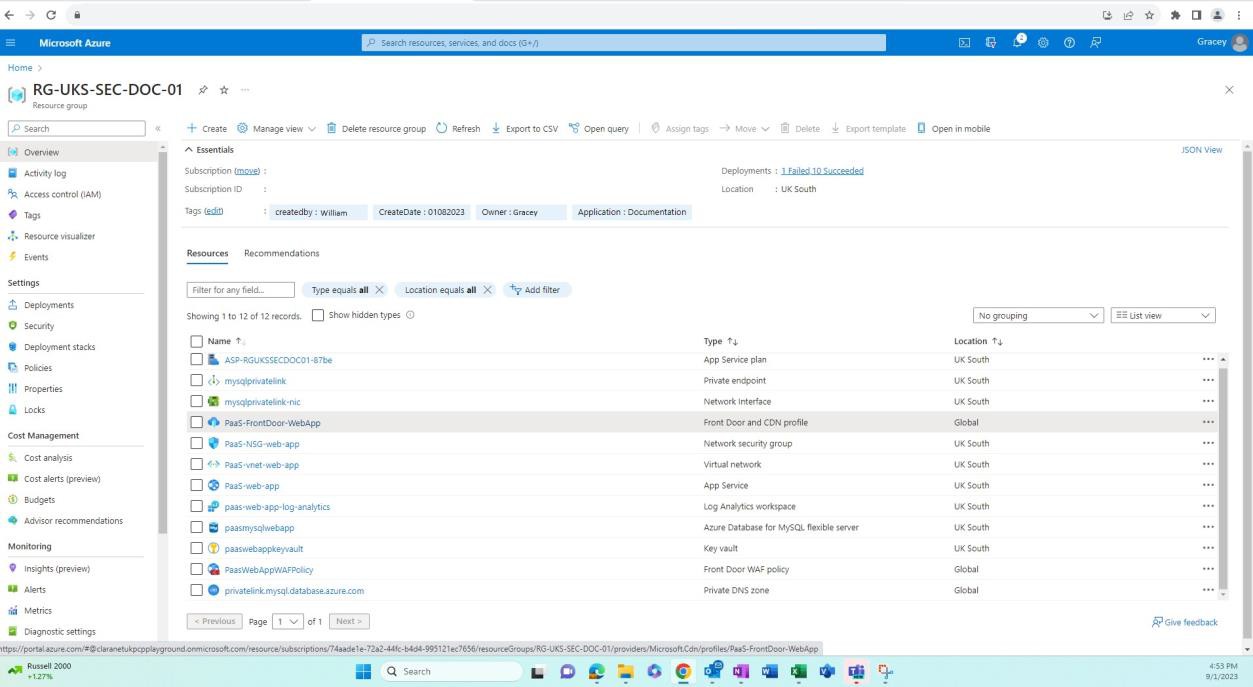
На следующих снимках экрана показано, что среды для разработки и тестирования отделены от рабочей среды. Это достигается с помощью групп ресурсов в Azure, что является способом логической группировки ресурсов в контейнер. Другими способами разделения могут быть разные подписки Azure, сети и подсети и т. д.
На следующем снимку экрана показана среда разработки и ресурсы в этой группе ресурсов.
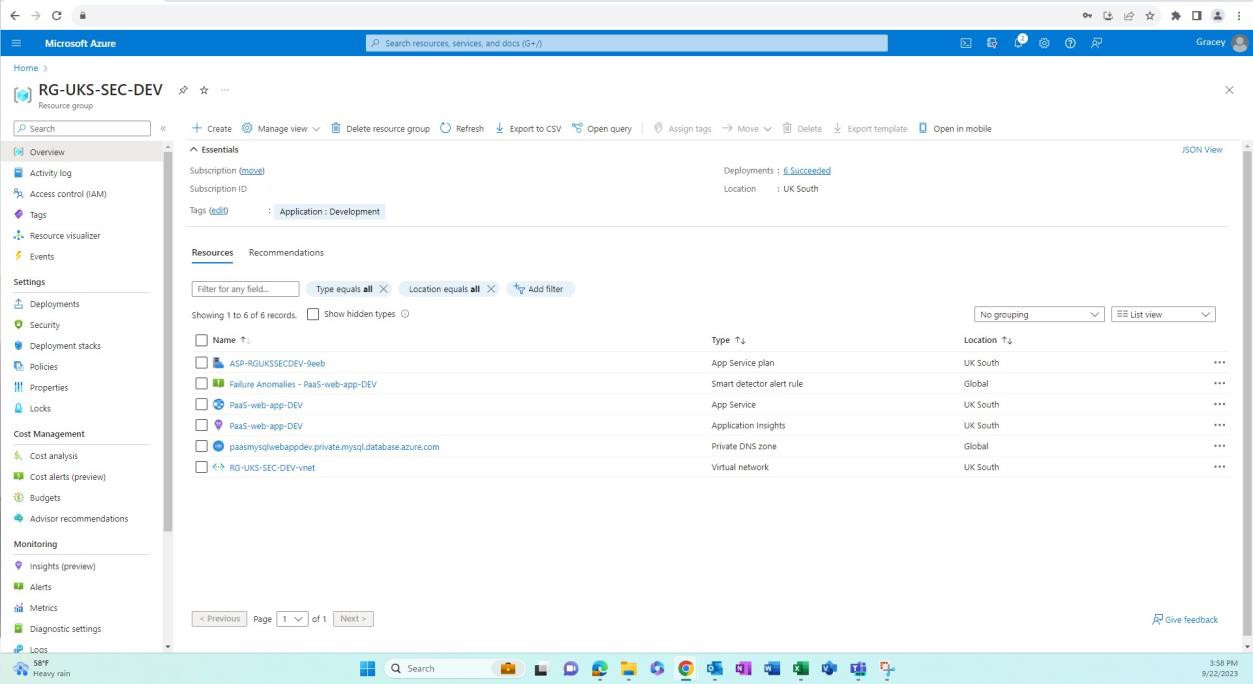
На следующем снимку экрана показана рабочая среда и ресурсы в этой группе ресурсов.
Пример доказательства:
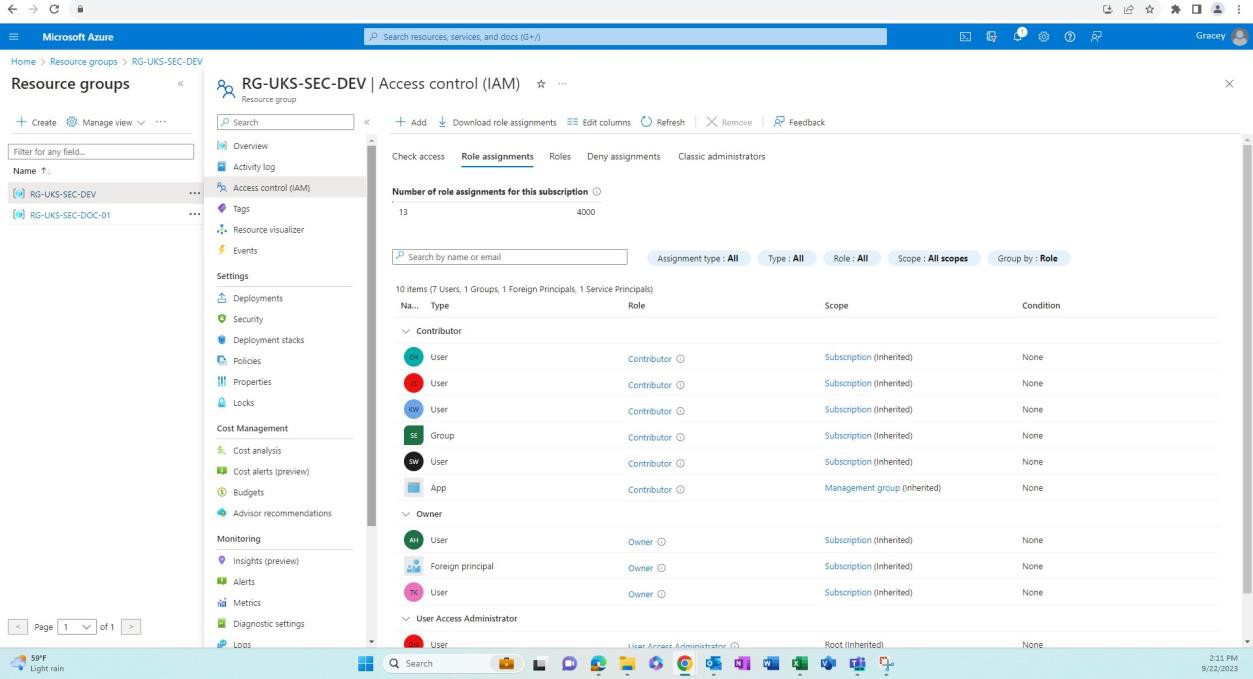
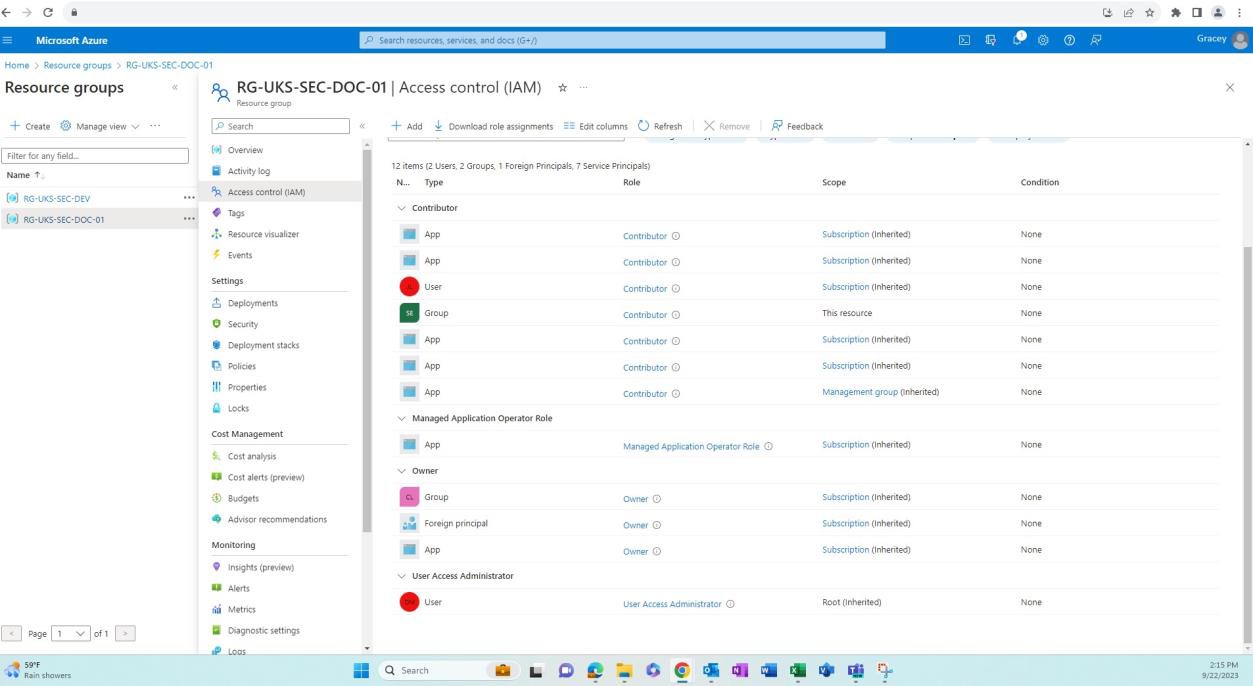
На следующих снимках экрана показано, что среды для разработки и тестирования отделены от рабочей среды. Адекватное разделение сред достигается с помощью разных пользователей или групп с разными разрешениями, связанными с каждой средой.
На следующем снимок экрана показана среда разработки и пользователи с доступом к этой группе ресурсов.
На следующем снимку экрана показана рабочая среда и пользователи (отличные от среды разработки), которые имеют доступ к этой группе ресурсов.
Рекомендации.
Доказательства можно предоставить путем предоставления общего доступа к снимкам экрана выходных данных одного и того же SQL-запроса в рабочей базе данных (отредактируйте любую конфиденциальную информацию) и базы данных разработки и тестирования. Выходные данные одних и того же команд должны создавать разные наборы данных. Там, где хранятся файлы, просмотр содержимого папок в обеих средах также должен демонстрировать различные наборы данных.
Пример доказательства
На снимке экрана показаны первые 3 записи (для отправки доказательств укажите первые 20) из рабочей базы данных.
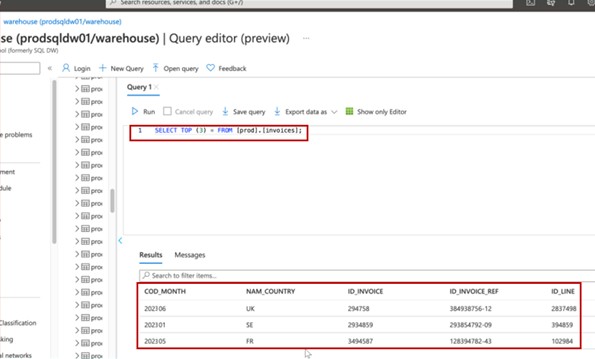
На следующем снимку экрана показан тот же запрос из базы данных разработки с разными записями.
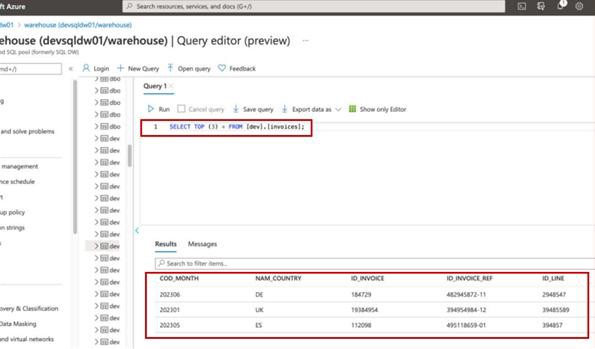
Примечание. В этом примере полный снимок экрана не использовался, однако все снимки экрана, отправленные isv, должны быть полными снимками экрана, показывающими URL-адрес, любое время и дату входа пользователя и системы.
Безопасная разработка и развертывание программного обеспечения
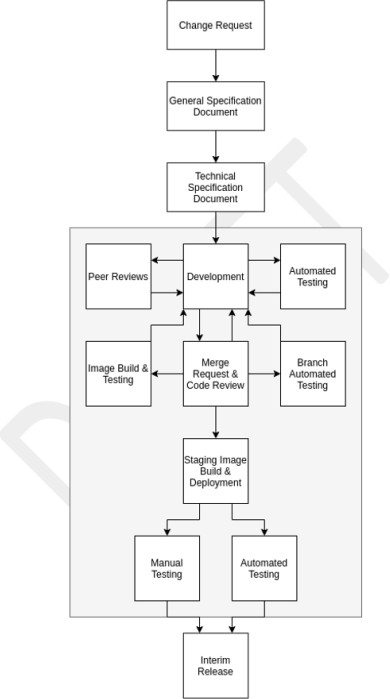
Организации, участвующие в разработке программного обеспечения, часто сталкиваются с конкурирующими приоритетами между безопасностью и давлением TTM (время на рынок), однако реализация действий, связанных с безопасностью на протяжении жизненного цикла разработки программного обеспечения (SDLC), может не только сэкономить деньги, но и сэкономить время. Если безопасность остается запоздалой мыслью, проблемы обычно выявляются только на этапе тестирования (DSLC), что часто может быть более трудоемким и дорогостоящим решением. Цель этого раздела безопасности — обеспечить соблюдение безопасных методов разработки программного обеспечения, чтобы снизить риск внедрения ошибок кода в разрабатываемое программное обеспечение. Кроме того, в этом разделе содержатся некоторые элементы управления, помогающие безопасному развертыванию программного обеспечения.
Элемент управления No 12
Предоставьте доказательства того, что документация существует и поддерживается, что:
поддерживает разработку безопасного программного обеспечения и включает отраслевые стандарты и(или) рекомендации по безопасному кодированию, такие как OWASP Top 10 или SANS Top 25 CWE.
разработчики ежегодно проходят соответствующее обучение по безопасному кодированию и безопасной разработке программного обеспечения.
Намерение: безопасная разработка
Организациям необходимо сделать все, что в их силах, чтобы обеспечить безопасную разработку программного обеспечения и защиту от уязвимостей. Для этого необходимо создать надежный жизненный цикл разработки программного обеспечения (SDLC) и рекомендации по безопасному кодированию, чтобы способствовать использованию безопасных методов программирования и безопасной разработки на протяжении всего процесса разработки программного обеспечения. Цель заключается в уменьшении количества и серьезности уязвимостей в программном обеспечении.
Для всех языков программирования существуют рекомендации и методы программирования, обеспечивающие безопасную разработку кода. Существуют внешние учебные курсы, предназначенные для обучения разработчиков различным типам классов уязвимостей программного обеспечения и методам программирования, которые можно использовать, чтобы остановить внедрение этих уязвимостей в программное обеспечение. Цель этого элемента управления также заключается в том, чтобы обучить эти методы всем разработчикам и обеспечить, чтобы эти методы не были забыты, или новые методы были изучены, выполняя их ежегодно.
Рекомендации: безопасная разработка
Предоставьте документированную документацию SDLC и (или) поддержку, в которой показано, что используется безопасный жизненный цикл разработки, и это руководство предоставляется всем разработчикам по продвижению рекомендаций по безопасному написанию кода. Ознакомьтесь с OWASP в SDLC и моделью зрелости программного обеспечения OWASP (SAMM).
Пример доказательства: безопасная разработка
Ниже приведен пример документа о политике безопасной разработки программного обеспечения. Ниже приведен отрывок из процедуры разработки безопасного программного обеспечения Компании Contoso, в которой демонстрируются безопасные методики разработки и программирования.

Примечание. В предыдущих примерах полные снимки экрана не использовались, однако все снимки данных, отправленные isV, должны быть полными снимками экрана с любым URL-адресом, вошедшего в систему пользователя, а также системным временем и датой.
Рекомендации: обучение безопасной разработке
Предоставьте свидетельство с помощью сертификатов, если обучение проводится внешней учебной компанией, или путем предоставления снимков экрана учебных дневников или других артефактов, демонстрирующих, что разработчики приняли участие в обучении. Если это обучение проводится с помощью внутренних ресурсов, предоставьте также доказательства учебных материалов.
Пример доказательства: обучение безопасной разработке
На следующем снимке экрана показано сообщение электронной почты с просьбой о том, чтобы сотрудники команды DevOps были зарегистрированы в OWASP Top Ten Training Annual Training.

На следующем снимку экрана показано, что обучение было запрошено с бизнес-обоснованием и утверждением. Затем следуют снимки экрана, сделанные из обучения, и запись о завершении, показывающая, что человек завершил ежегодное обучение.
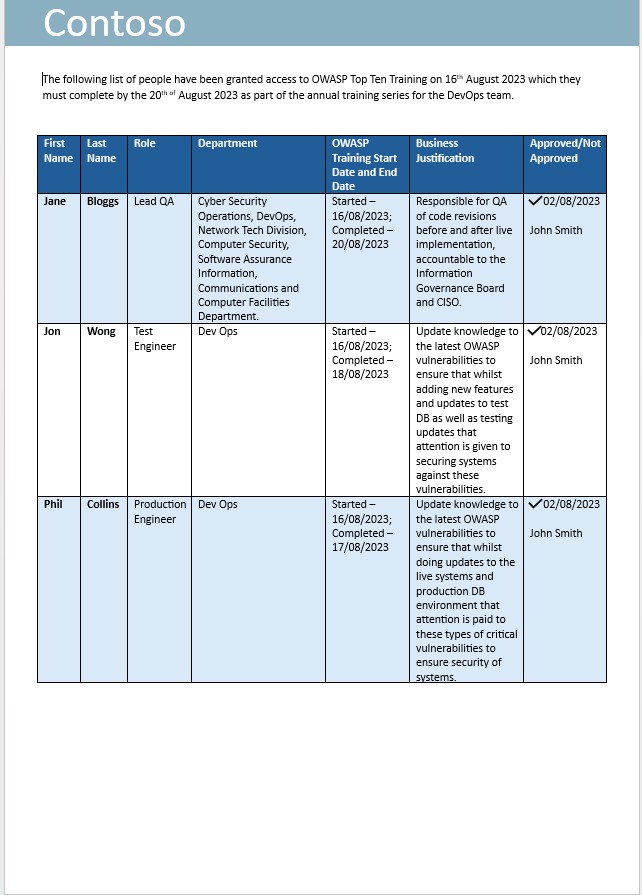
Примечание. В этом примере полный снимок экрана не использовался, однако все снимки экрана, отправленные isv, должны быть полными снимками экрана, показывающими URL-адрес, любое время и дату входа пользователя и системы.
Элемент управления No 13
Предоставьте подтверждение того, что репозитории кода защищены, чтобы:
перед слиянием с основной ветвью все изменения кода проходят проверку и утверждение вторым рецензентом.
имеются соответствующие элементы управления доступом.
весь доступ применяется с помощью многофакторной проверки подлинности (MFA).
все выпуски, внесенные в рабочую среду, проверяются и утверждаются перед развертыванием.
Намерение: проверка кода
Цель этой подпочты заключается в том, чтобы выполнить проверку кода другим разработчиком, чтобы помочь выявить любые ошибки кода, которые могут привести к уязвимости в программном обеспечении. Необходимо установить авторизацию, чтобы убедиться, что проверки кода выполняются, тестируются и т. д. перед развертыванием. Шаг авторизации проверяет, выполнены ли правильные процессы, что лежит в основе SDLC, определенного в элементе управления 12.
Цель заключается в том, чтобы убедиться, что все изменения кода проходят тщательную проверку и утверждение вторым рецензентом, прежде чем они будут объединены в главную ветвь. Этот процесс двойного утверждения служит в качестве меры контроля качества, направленной на перехват любых ошибок кодирования, уязвимостей системы безопасности или других проблем, которые могут поставить под угрозу целостность приложения.
Рекомендации: проверка кода
Предоставьте доказательства того, что код проходит рецензирование и должен быть авторизован, прежде чем его можно будет применить в рабочей среде. Это может быть через экспорт билетов на изменения, демонстрируя, что проверки кода были выполнены и изменения авторизованы, или это может быть через программное обеспечение для проверки кода, например Crucible
Пример доказательства: проверка кода
Ниже приведен билет, показывающий, что изменения кода проходят проверку и авторизацию кем-то, кроме исходного разработчика. Он показывает, что проверка кода была запрошена назначаемым и будет назначена другому пользователю для проверки кода.
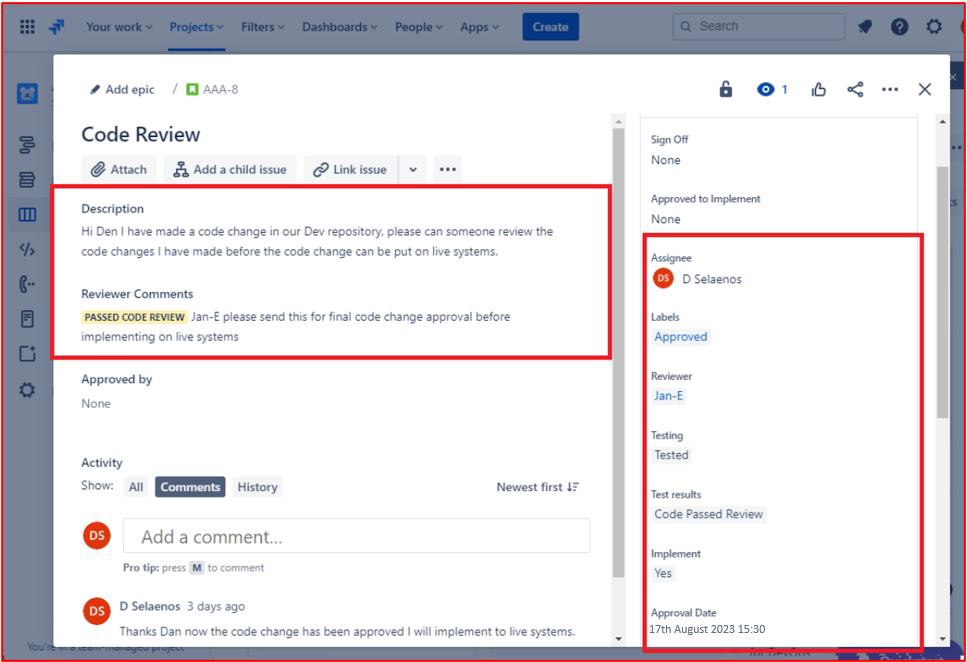
На следующем рисунке показано, что проверка кода была назначена другому разработчику, как показано в выделенном разделе в правой части изображения. На левой стороне код был проверен и получил состояние "ПЕРЕДАННАЯ ПРОВЕРКА КОДА" рецензентом кода. Теперь запрос должен получить одобрение руководителя, прежде чем изменения можно будет ввести в динамические производственные системы.
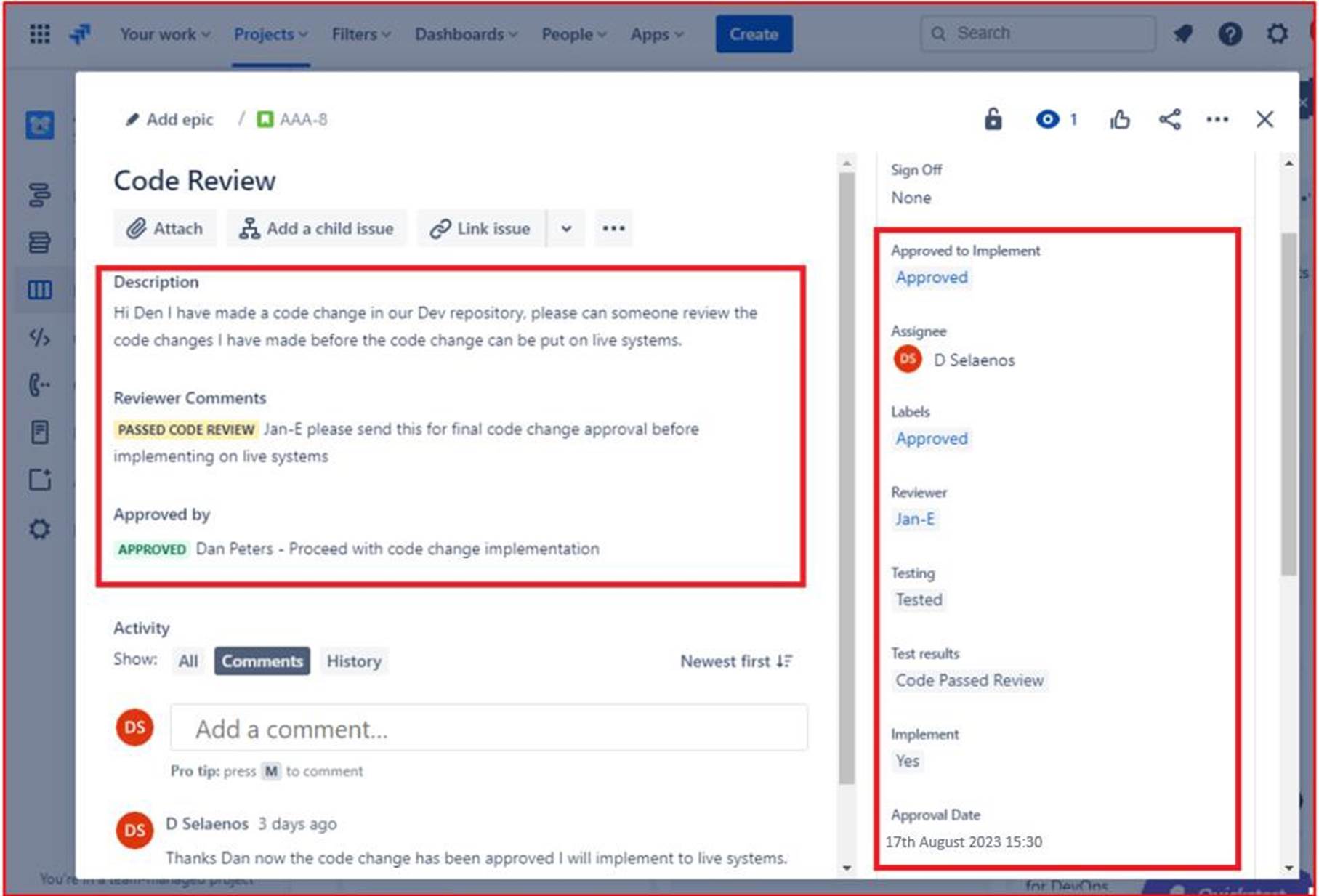
На следующем рисунке показано, что проверенный код утвержден для реализации в динамических производственных системах. После внесения изменений в код окончательное задание получает выход. Обратите внимание, что на протяжении всего процесса участвуют три человека: исходный разработчик кода, рецензент кода и руководитель, который дает утверждение и подписывается. Чтобы соответствовать критериям для этого элемента управления, следует ожидать, что ваши билеты будут следовать этому процессу.
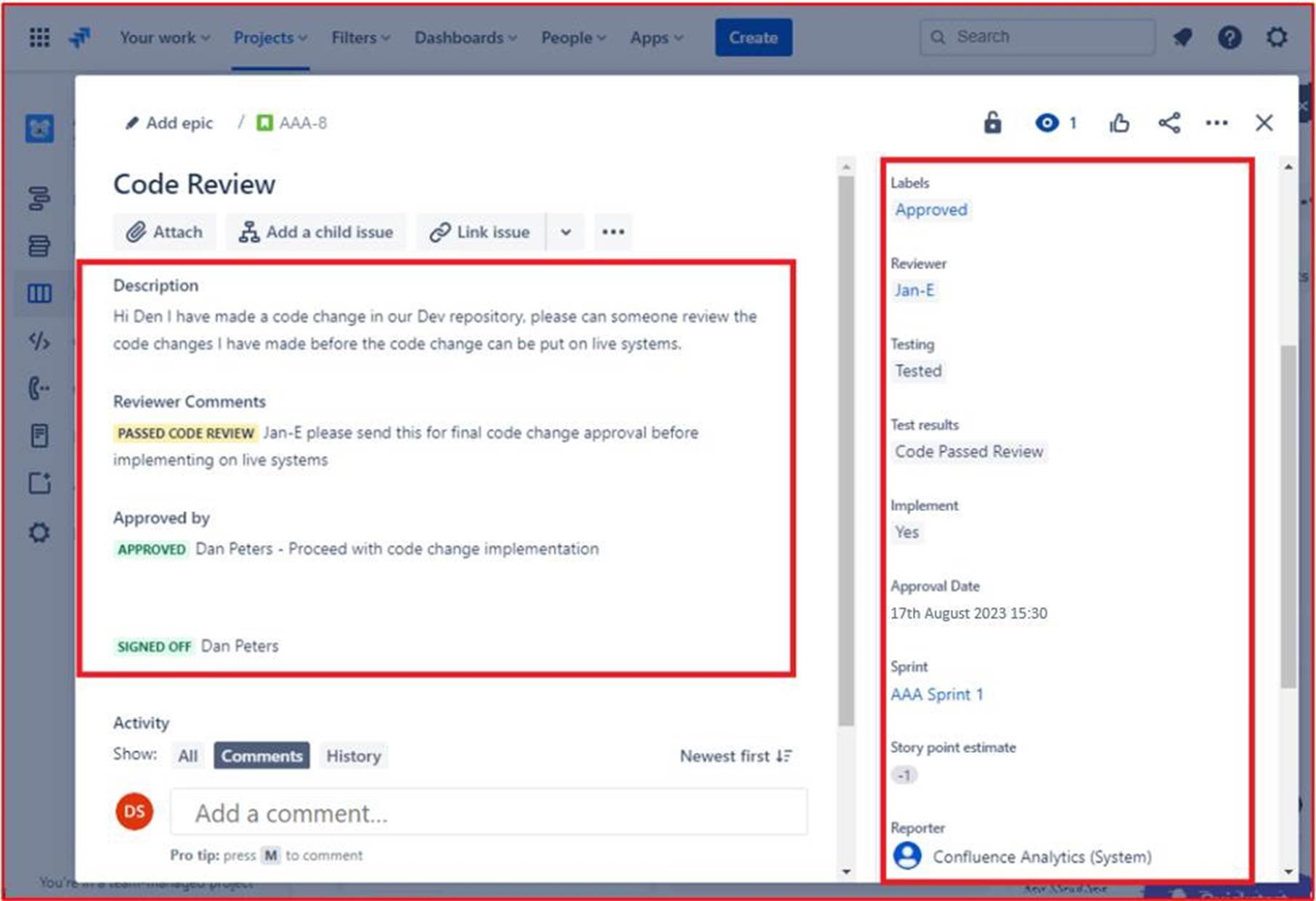
Примечание. В этом примере полный снимок экрана не использовался, однако все снимки экрана, отправленные isv, должны быть полными снимками экрана, показывающими URL-адрес, любое время и дату входа пользователя и системы.
Пример доказательства: проверка кода
Помимо административной части процесса, показанного выше, с современными репозиториями кода и платформами можно реализовать дополнительные элементы управления, такие как проверка политики ветвей, чтобы гарантировать, что слияние не может произойти до завершения такой проверки. В следующем примере показано, что это достигается в DevOps.
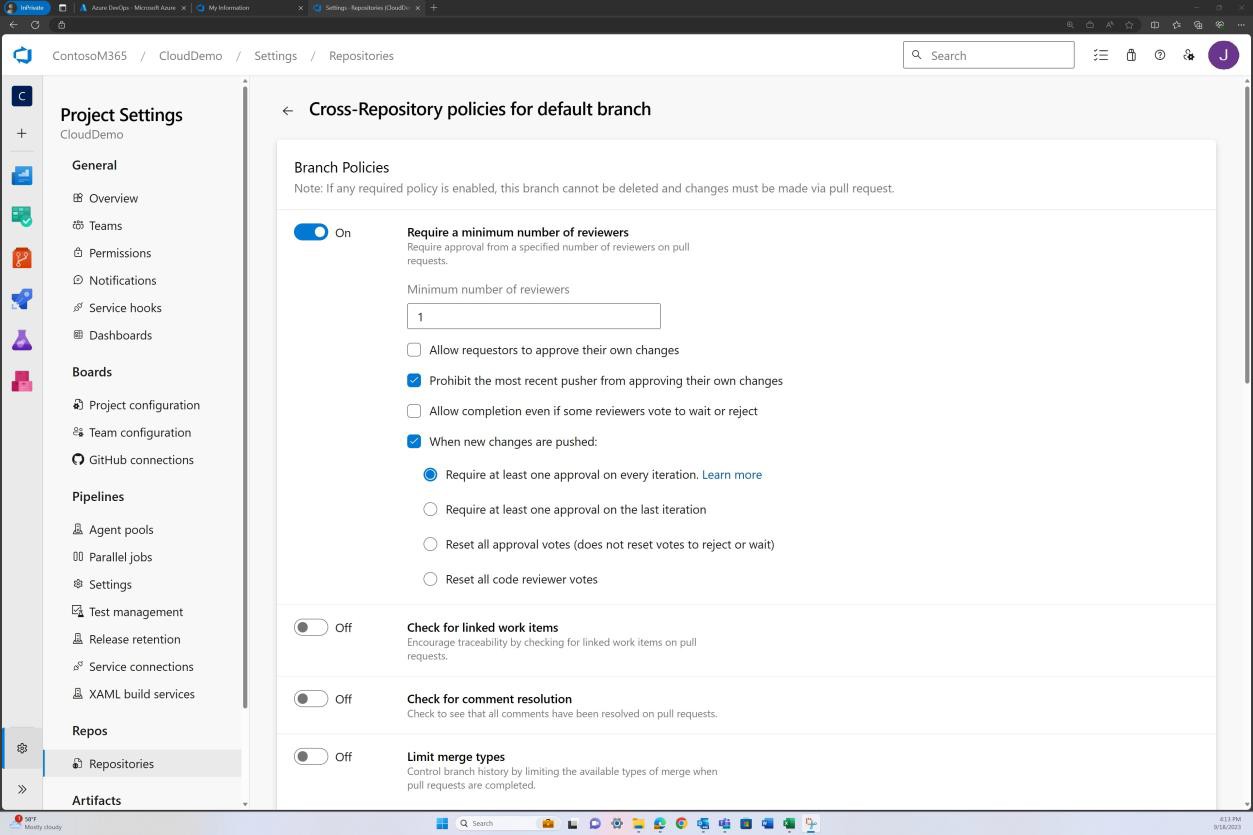
На следующем снимках экрана показано, что рецензенты по умолчанию назначаются, а проверка требуется автоматически.
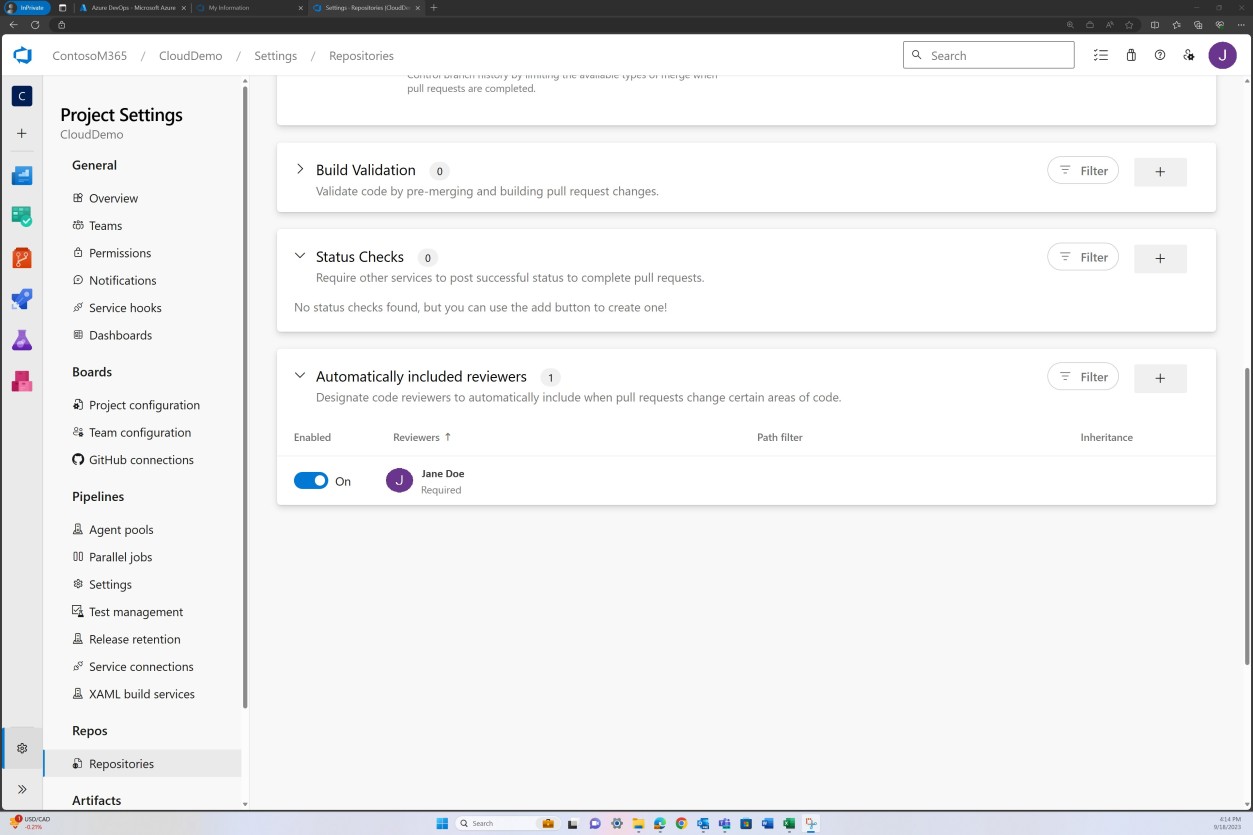
Пример доказательства: проверка кода
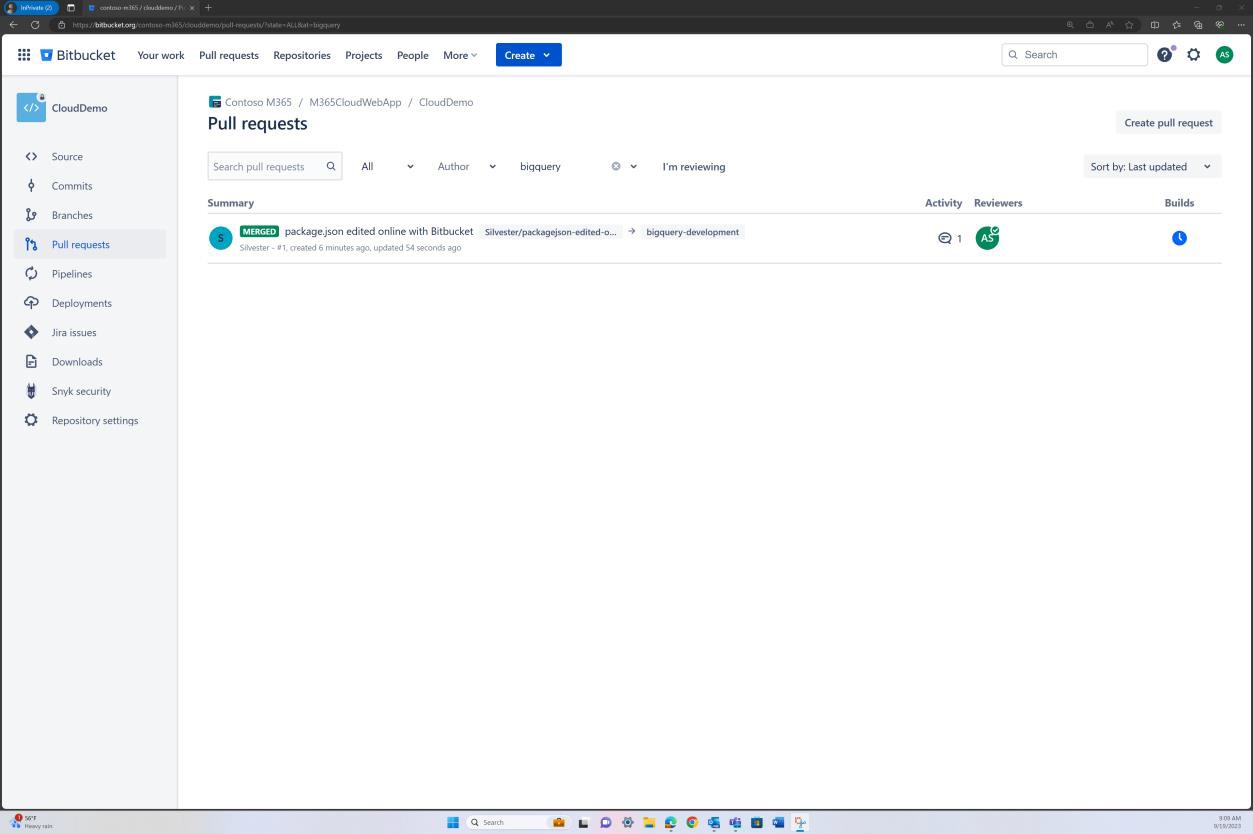
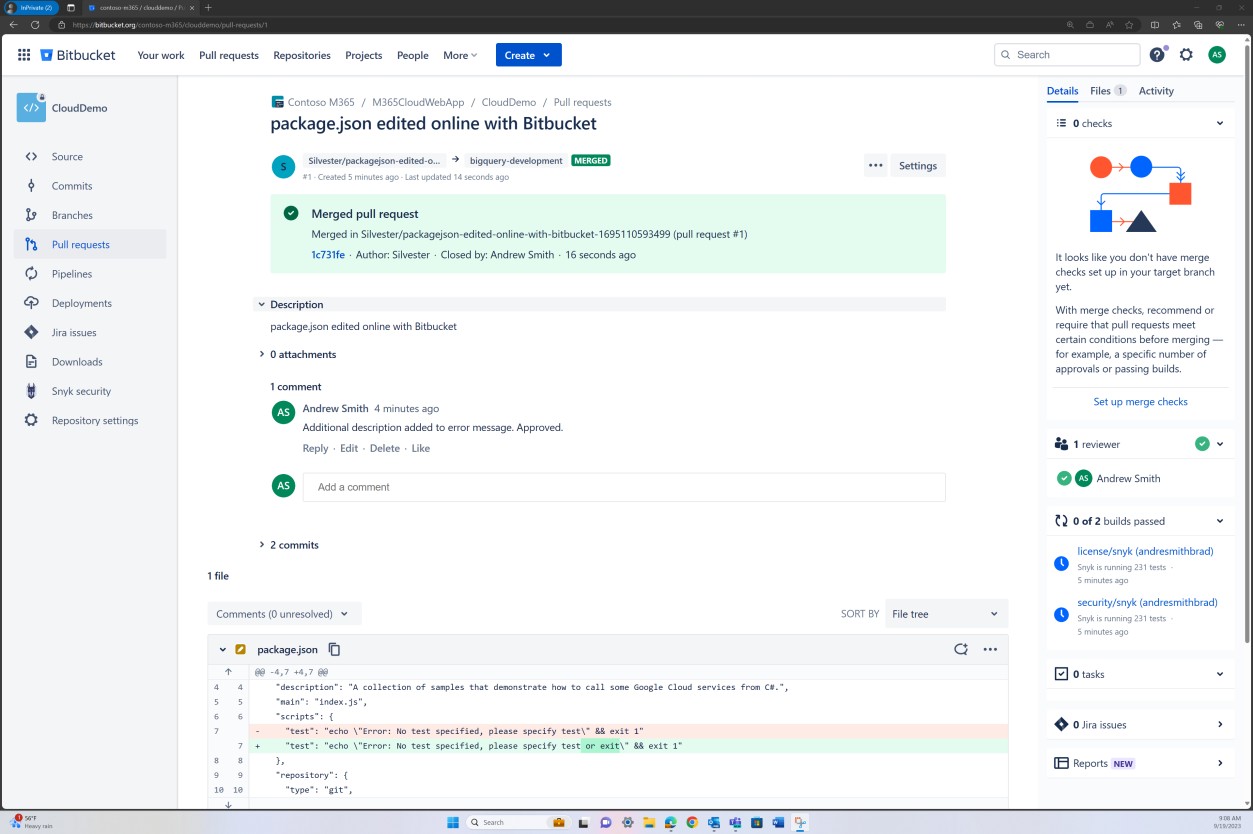
Проверка политики ветви также может быть выполнена в Bitbucket.
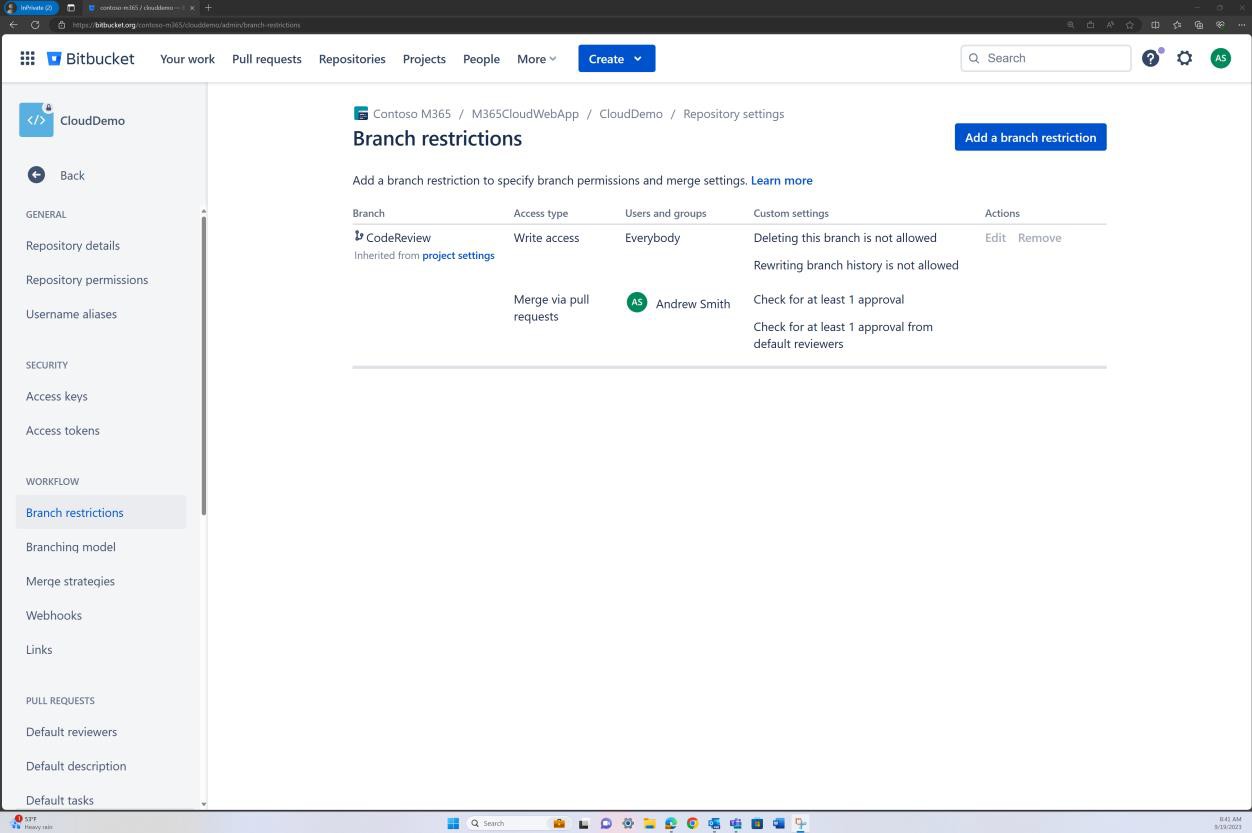
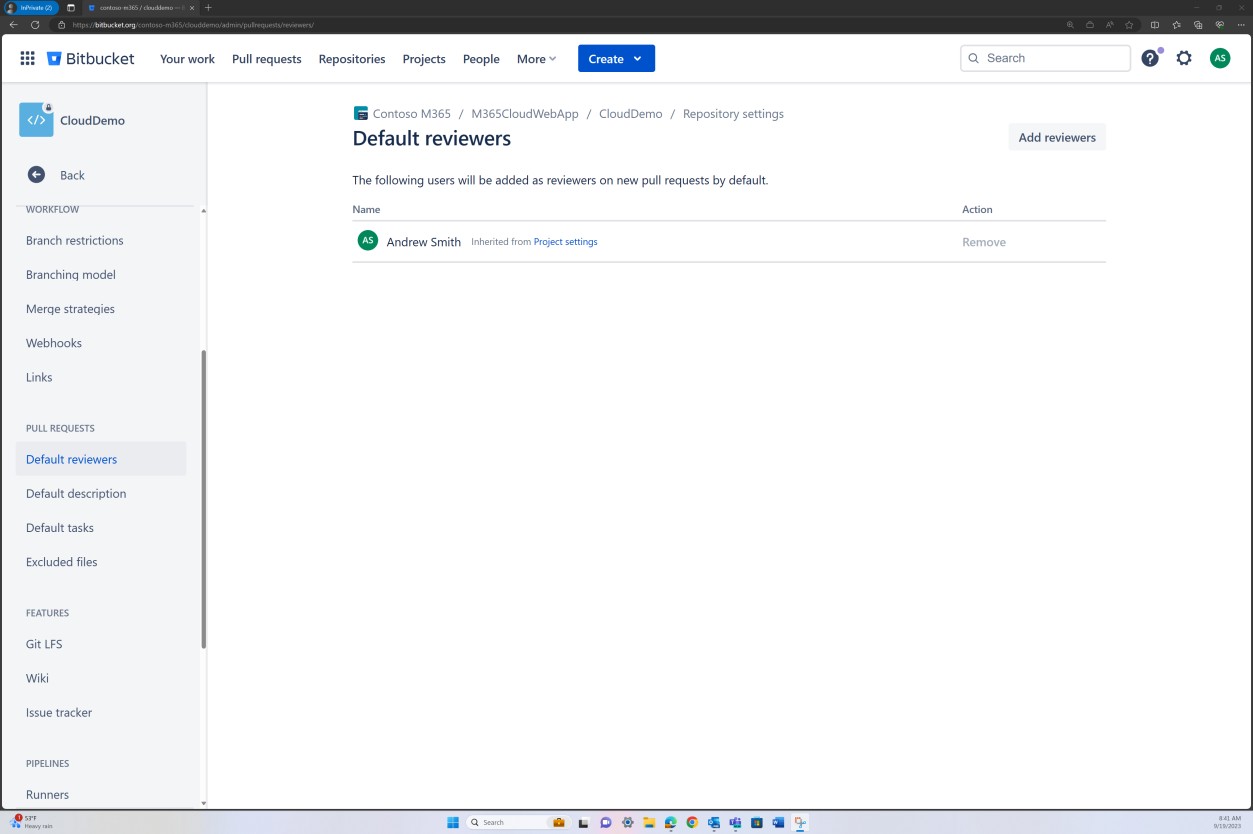
На следующем снимке экрана задан рецензент по умолчанию. Это гарантирует, что для всех слияний потребуется проверка от назначенного человека перед распространением изменений в главную ветвь.
На следующих двух снимках экрана показан пример применяемых параметров конфигурации. А также завершенный запрос на вытягивание, который был инициирован пользователем Silvester и требовал утверждения от рецензента по умолчанию Эндрю перед слиянием с главной ветвью.
Обратите внимание, что при получении доказательств ожидается, что комплексный процесс будет демонстрироваться. Примечание. Должны быть предоставлены снимки экрана, показывающие параметры конфигурации, если политика ветви имеется (или какой-либо другой программный метод или элемент управления), а также билеты/записи о предоставлении утверждения.
Намерение: ограниченный доступ
Начиная с предыдущего элемента управления, необходимо реализовать элементы управления доступом, чтобы ограничить доступ только отдельными пользователями, работающими над конкретными проектами. Ограничивая доступ, вы можете снизить риск несанкционированных изменений и тем самым ввести небезопасные изменения кода. Для защиты репозитория кода следует использовать наименее привилегированный подход.
Рекомендации: ограниченный доступ
Предоставьте доказательства с помощью снимков экрана из репозитория кода, что доступ ограничен пользователями, которые требуются, включая различные привилегии.
Пример доказательства: ограниченный доступ
На следующих снимках экрана показаны элементы управления доступом, реализованные в Azure DevOps. Команда CloudDemo имеет два участника, каждый из которых имеет разные разрешения.
Примечание. На следующих снимках экрана показан пример типа доказательства и формата, которые должны соответствовать этому элементу управления. Это ни в коем случае не является обширным, и реальные случаи могут отличаться от того, как реализованы средства управления доступом.
Если разрешения заданы на уровне группы, необходимо указать свидетельство для каждой группы и пользователей этой группы, как показано во втором примере для Bitbucket.
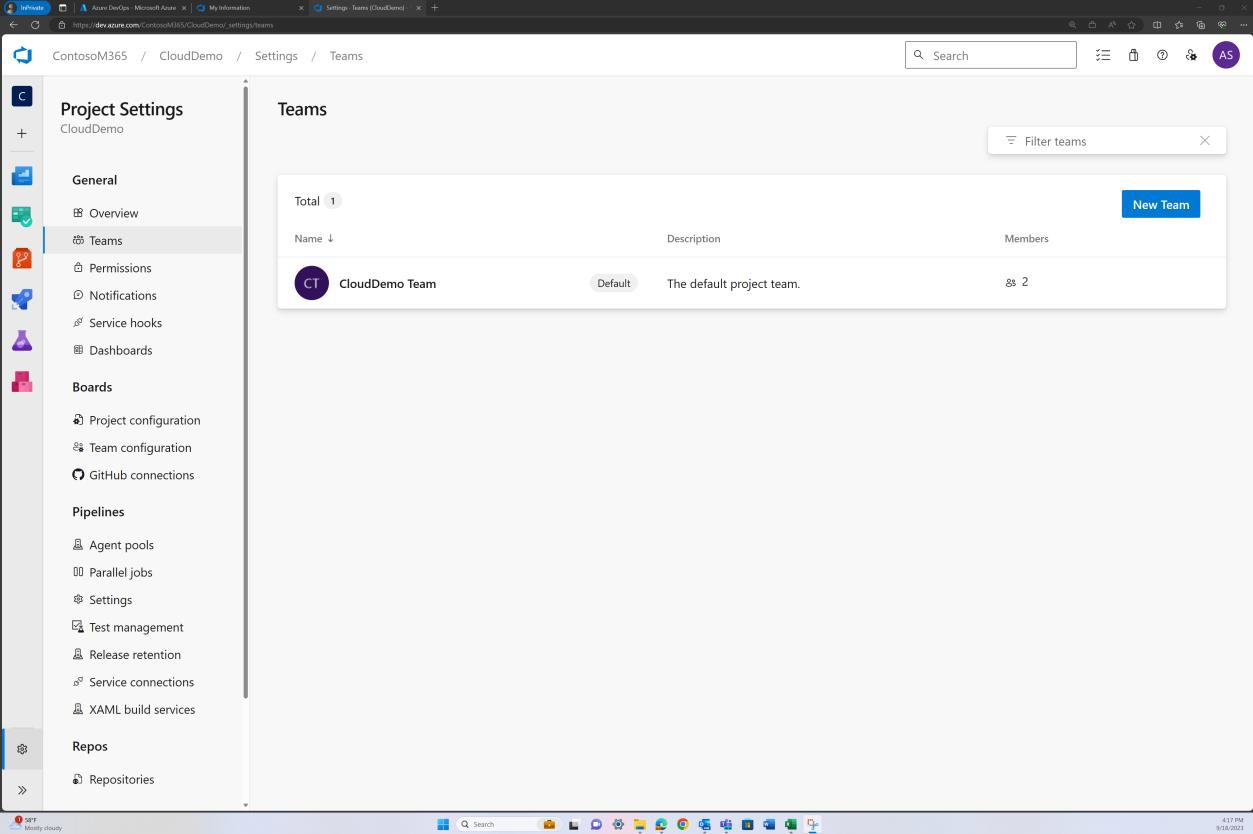
Снимок экрана ниже: участники команды CloudDemo.
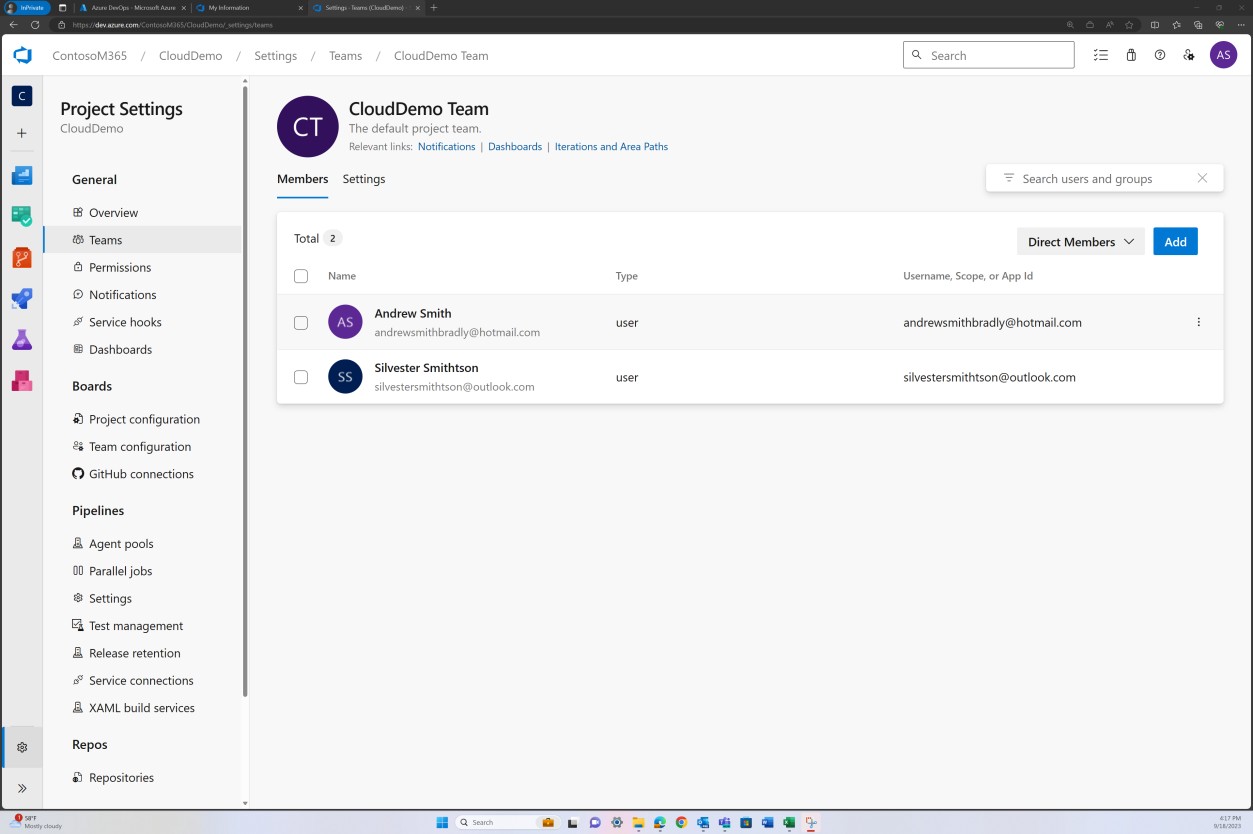
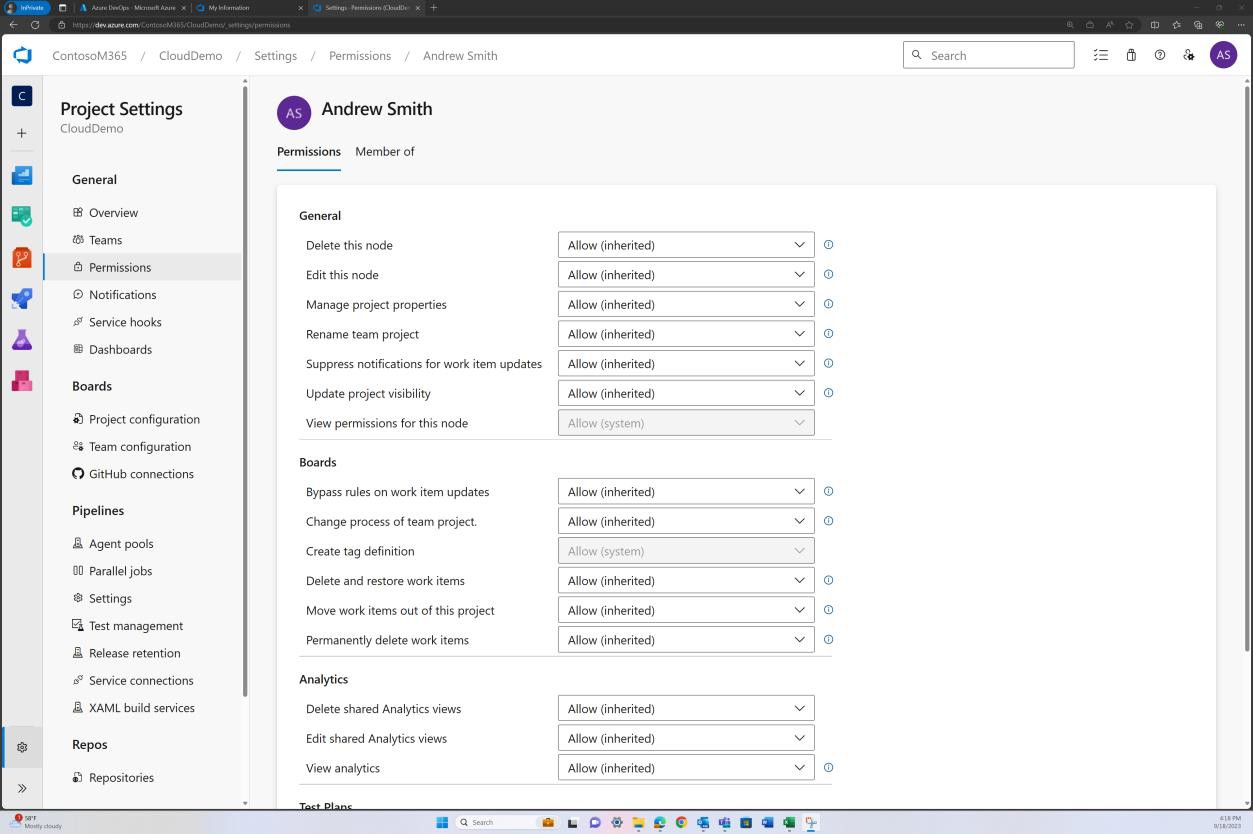
На предыдущем изображении показано, что Эндрю Смит имеет значительно более высокие привилегии в качестве владельца проекта, чем Silvester ниже.
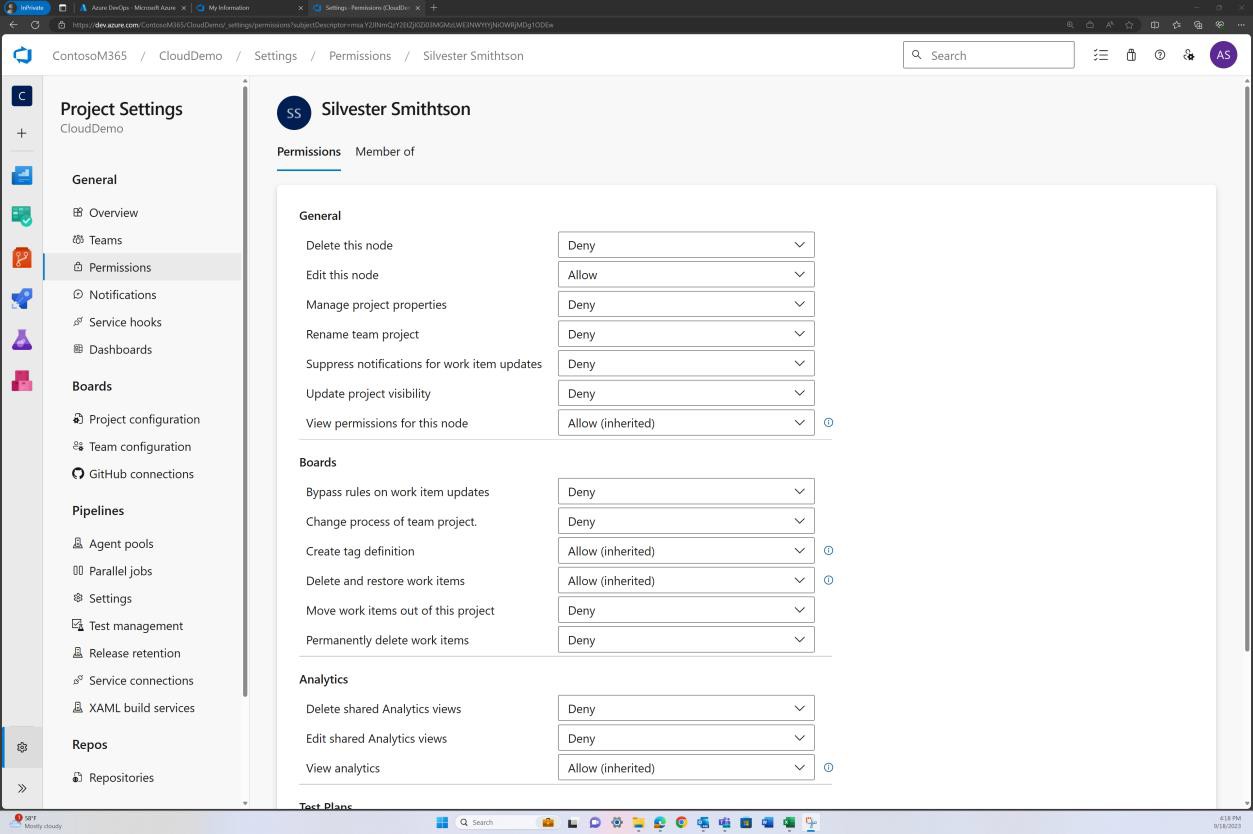
Пример доказательства
На следующем снимке экрана управление доступом, реализованное в Bitbucket, достигается с помощью разрешений, заданных на уровне группы. Для уровня доступа к репозиторию существует группа "Администратор" с одним пользователем и группа "Разработчик" с другим пользователем.
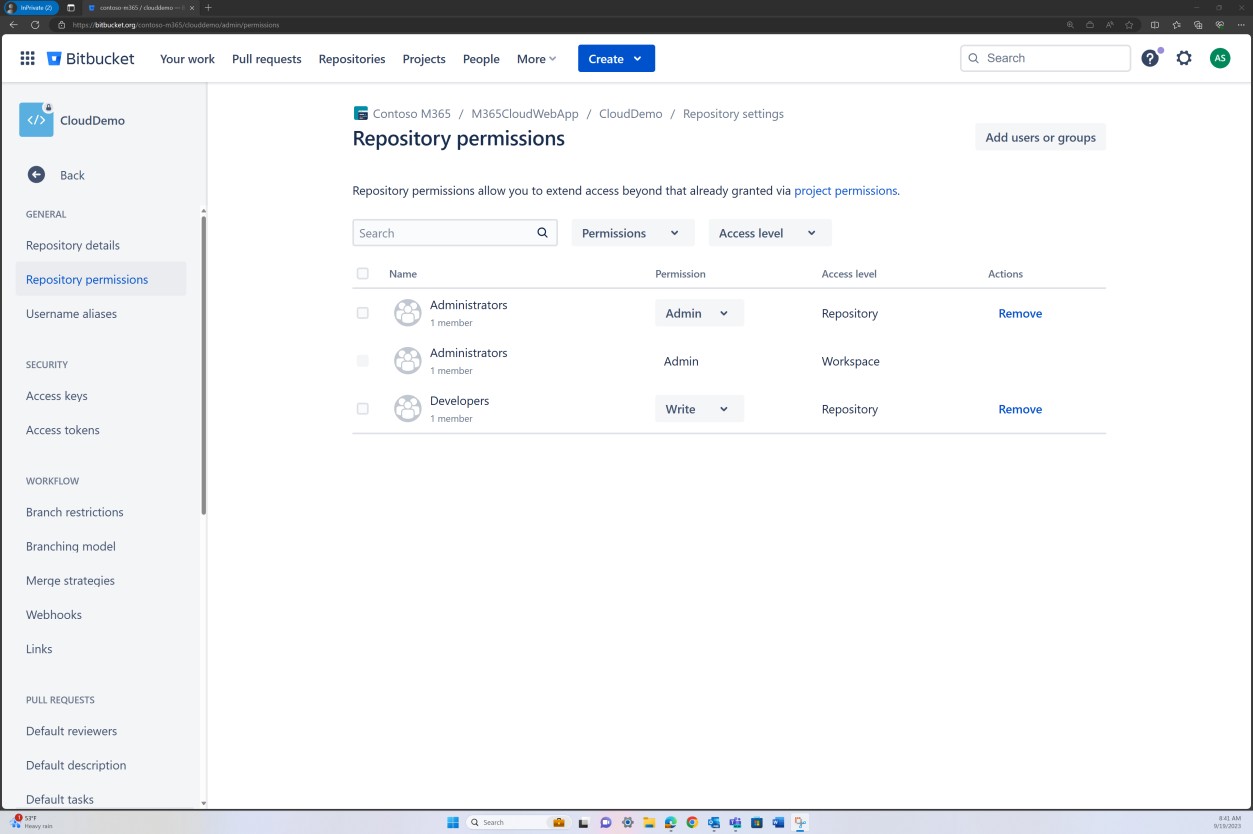
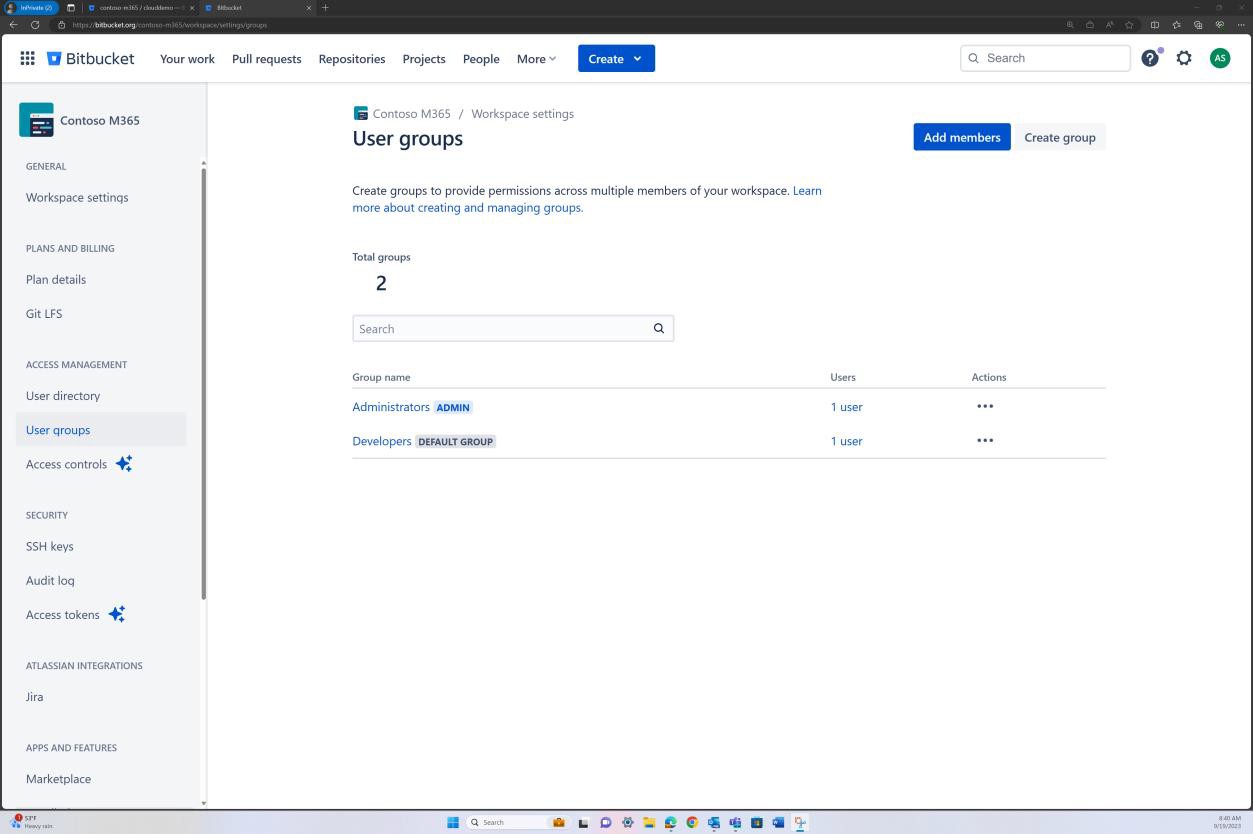
На следующих снимках экрана показано, что каждый из пользователей принадлежит к другой группе и по своей сути имеет разный уровень разрешений. Эндрю Смит является администратором, а Сильвестр входит в группу разработчиков, которая предоставляет ему только привилегии разработчика.
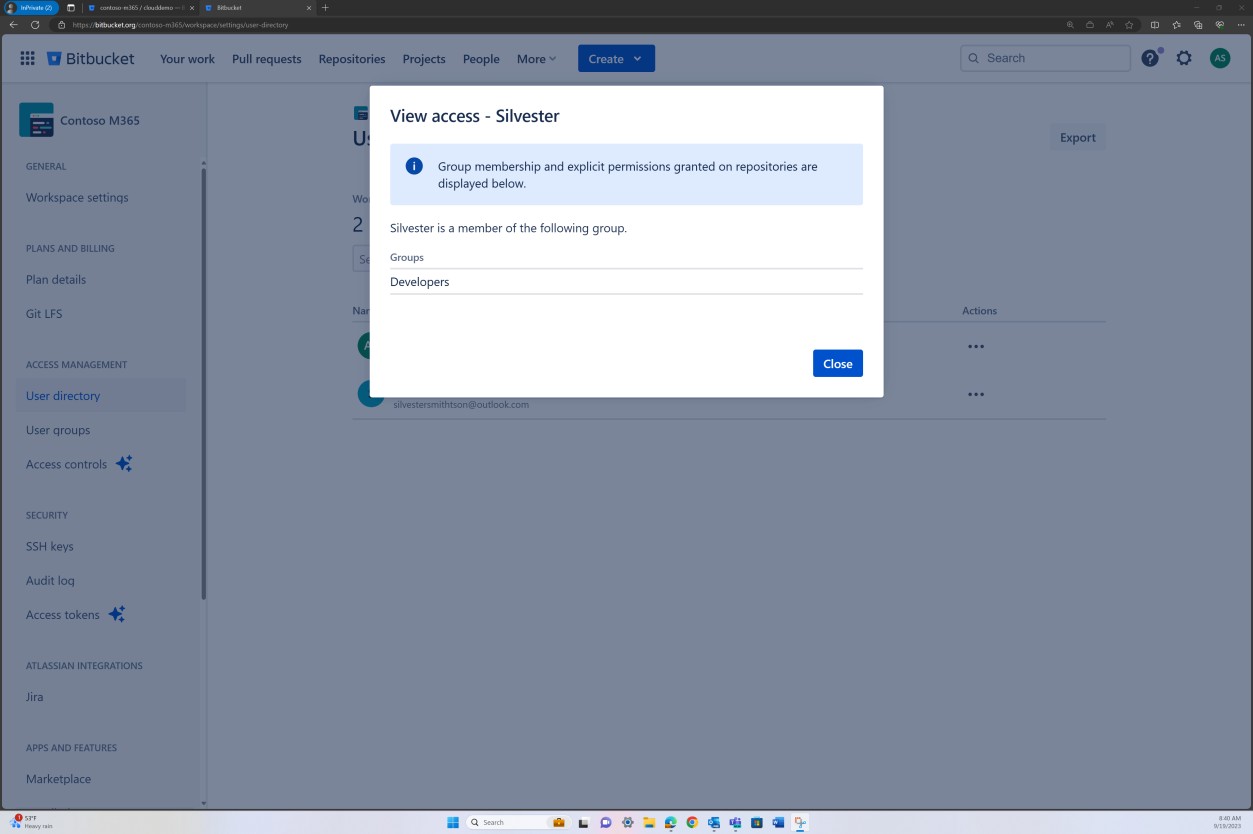
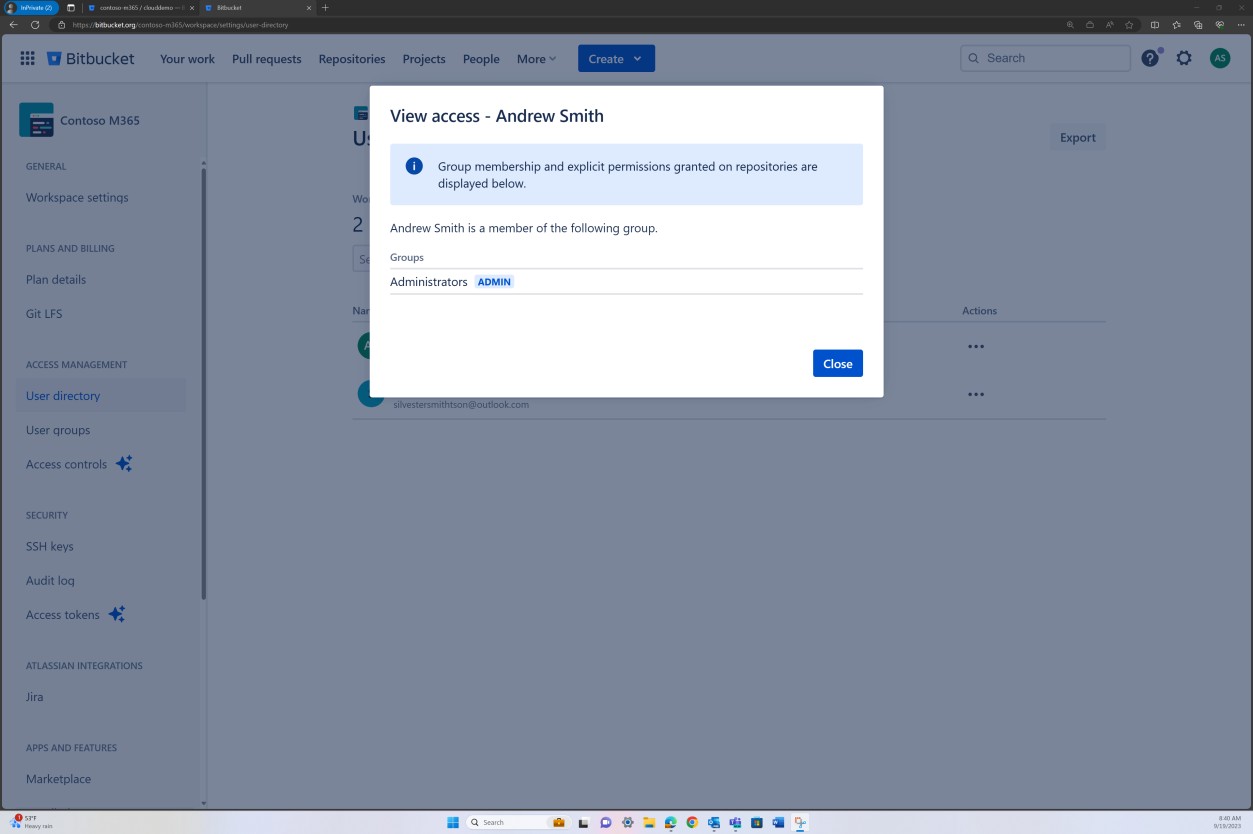
Намерение: MFA
Если субъект угрозы может получить доступ к базе кода программного обеспечения и изменить его, он может внести уязвимости, backdoor или вредоносный код в базу кода и, следовательно, в приложение. Было несколько случаев этого уже, с, вероятно, наиболее широко разглавленной является атака SolarWinds 2020 года, когда злоумышленники ввели вредоносный код в файл, который позже был включен в обновления программного обеспечения SolarWinds Orion. Более 18 000 клиентов SolarWinds установили вредоносные обновления, при этом вредоносные программы распространяются незамеченными.
Цель этой подточии — убедиться, что весь доступ к репозиториям кода обеспечивается с помощью многофакторной проверки подлинности (MFA).
Рекомендации: MFA
Предоставляйте с помощью снимков экрана из репозитория кода свидетельство того, что для всех пользователей включена MFA.
Пример доказательства: MFA
Если репозитории кода хранятся и поддерживаются в Azure DevOps, то в зависимости от того, как была настроена MFA на уровне клиента, из AAD можно предоставить свидетельство, например "MFA на пользователя". На следующем снимке экрана показано, что MFA применяется для всех пользователей в AAD, и это также относится к Azure DevOps.
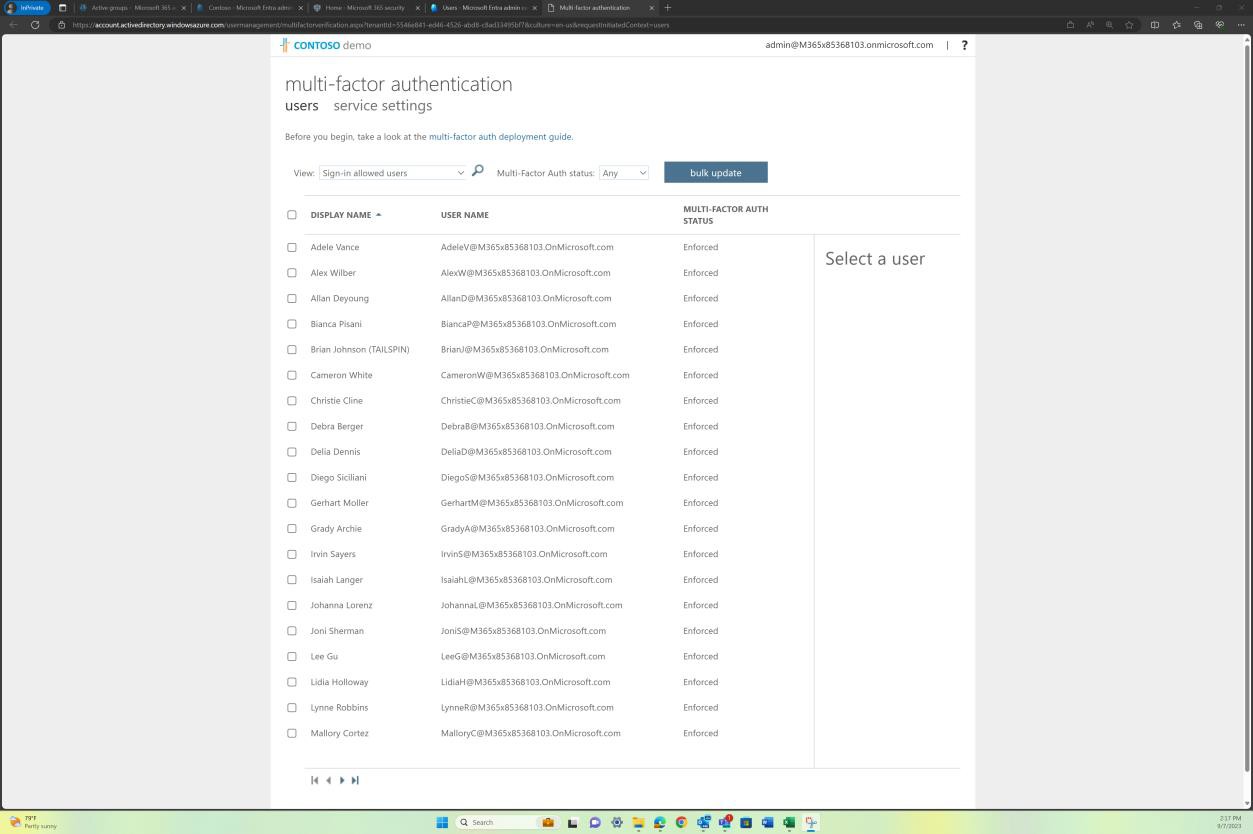
Пример доказательства: MFA
Если организация использует такую платформу, как GitHub, вы можете продемонстрировать, что 2FA включена, предоставив свидетельство из учетной записи "Организация", как показано на следующих снимках экрана.
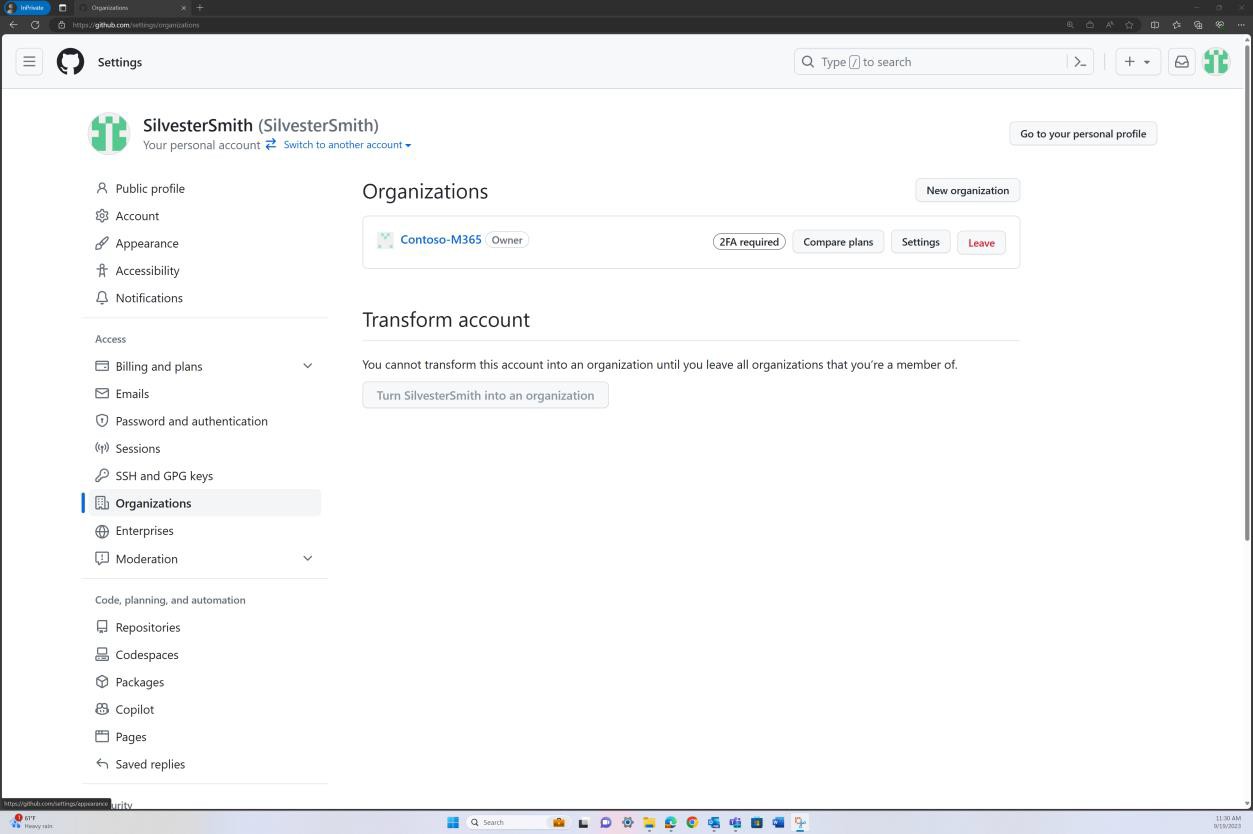
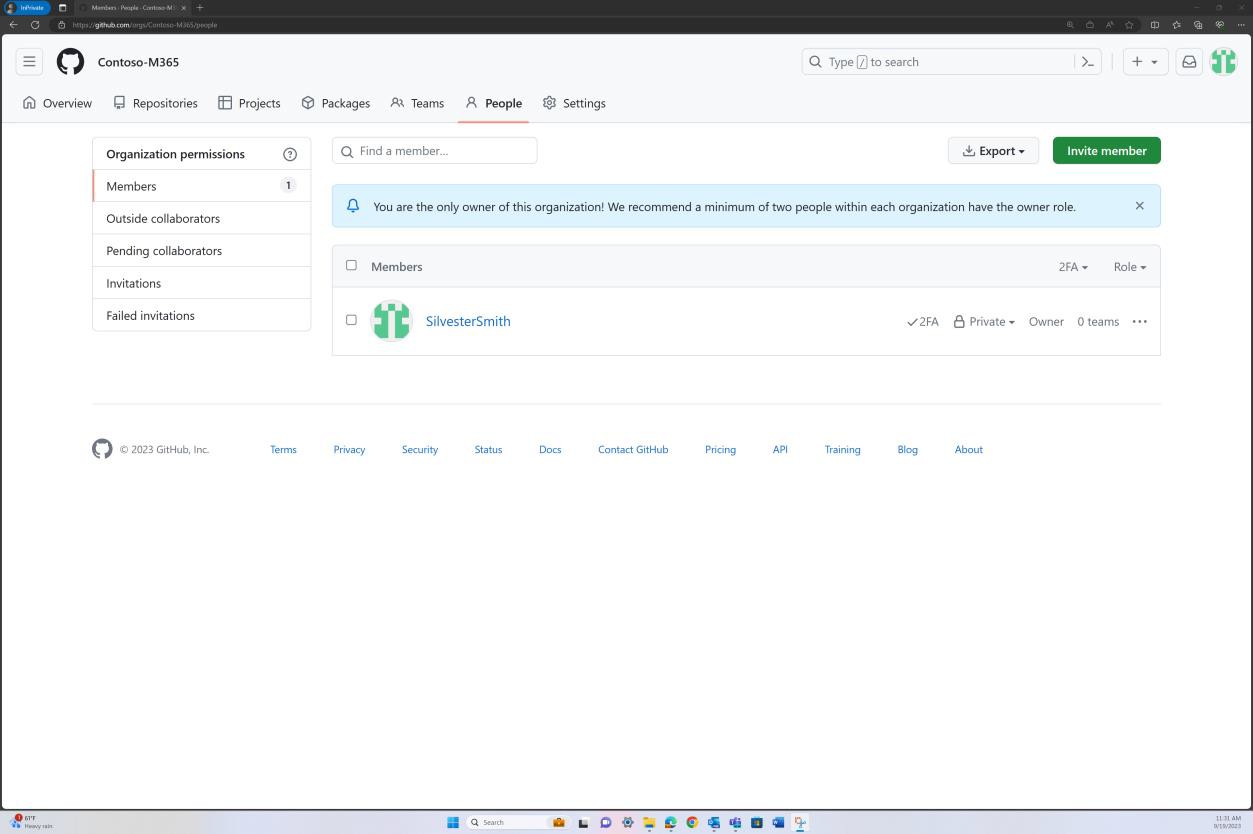
Чтобы узнать, применяется ли 2FA для всех участников вашей организации, на сайте GitHub перейдите на вкладку параметров организации, как показано на следующем снимке экрана.
Перейдя на вкладку "Люди" в GitHub, можно установить, что "2FA" включена для всех пользователей в организации, как показано на следующем снимке экрана.
Намерение: проверки
Этот элемент управления предназначен для проверки выпуска в среде разработки другим разработчиком, чтобы выявить ошибки в коде, а также неправильные настройки, которые могут привести к уязвимости. Необходимо установить авторизацию для проверки выпуска, тестирования и т. д. перед развертыванием в рабочей среде. Авторизация. шаг может проверить, выполнены ли правильные процессы, что лежит в основе принципов SDLC.
Рекомендации
Предоставьте доказательства того, что все выпуски из среды тестирования или разработки в рабочей среде проверяются другим пользователем или разработчиком, чем инициатор. Если это достигается с помощью конвейера непрерывной интеграции и непрерывного развертывания, то предоставленные доказательства должны показывать (как и в случае с проверкой кода), что проверки применяются.
Пример доказательства
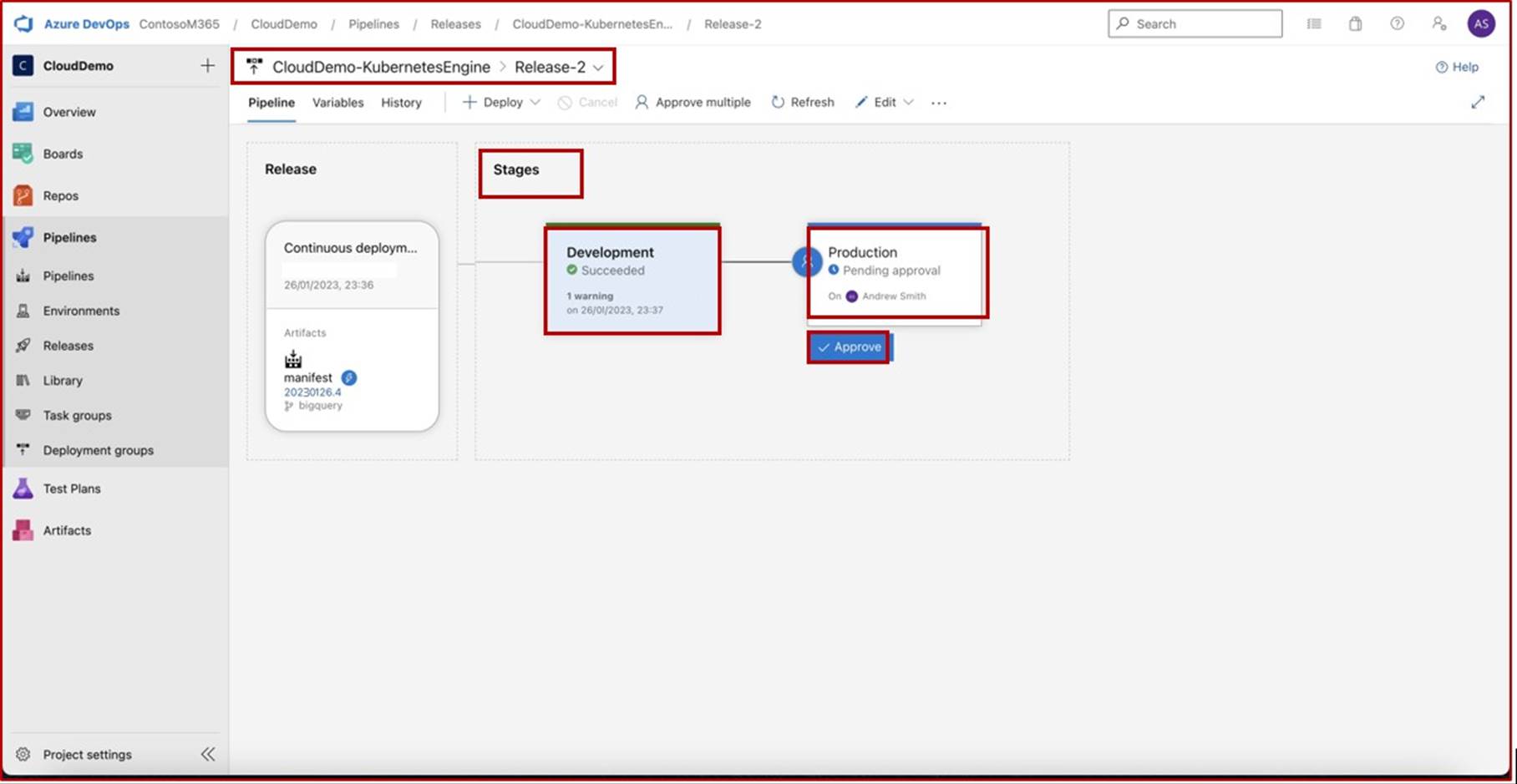
На следующем снимке экрана видно, что конвейер CI/CD используется в Azure DevOps. Конвейер содержит два этапа: разработка и рабочая среда. Выпуск был активирован и успешно развернут в среде разработки, но еще не распространился на втором этапе (рабочая среда) и ожидает утверждения от Эндрю Смита.
Ожидается, что после развертывания в разработке соответствующая команда выполняет тестирование безопасности и только в том случае, если назначенный сотрудник с соответствующими полномочиями для проверки развертывания выполнил вторичную проверку и будет удовлетворен выполнением всех условий, а затем предоставит утверждение, которое позволит выпускать выпуск в рабочую среду.
Оповещение по электронной почте, которое обычно будет получать назначенный рецензент, информирующий о том, что условие перед развертыванием сработало и что проверка и утверждение ожидается.
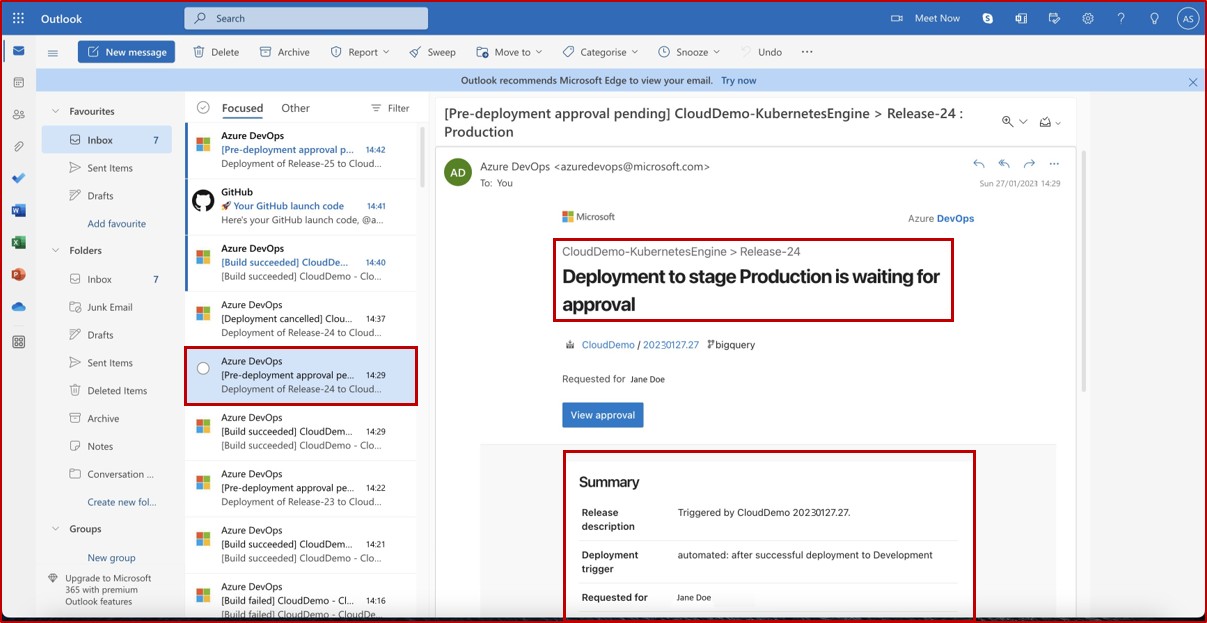
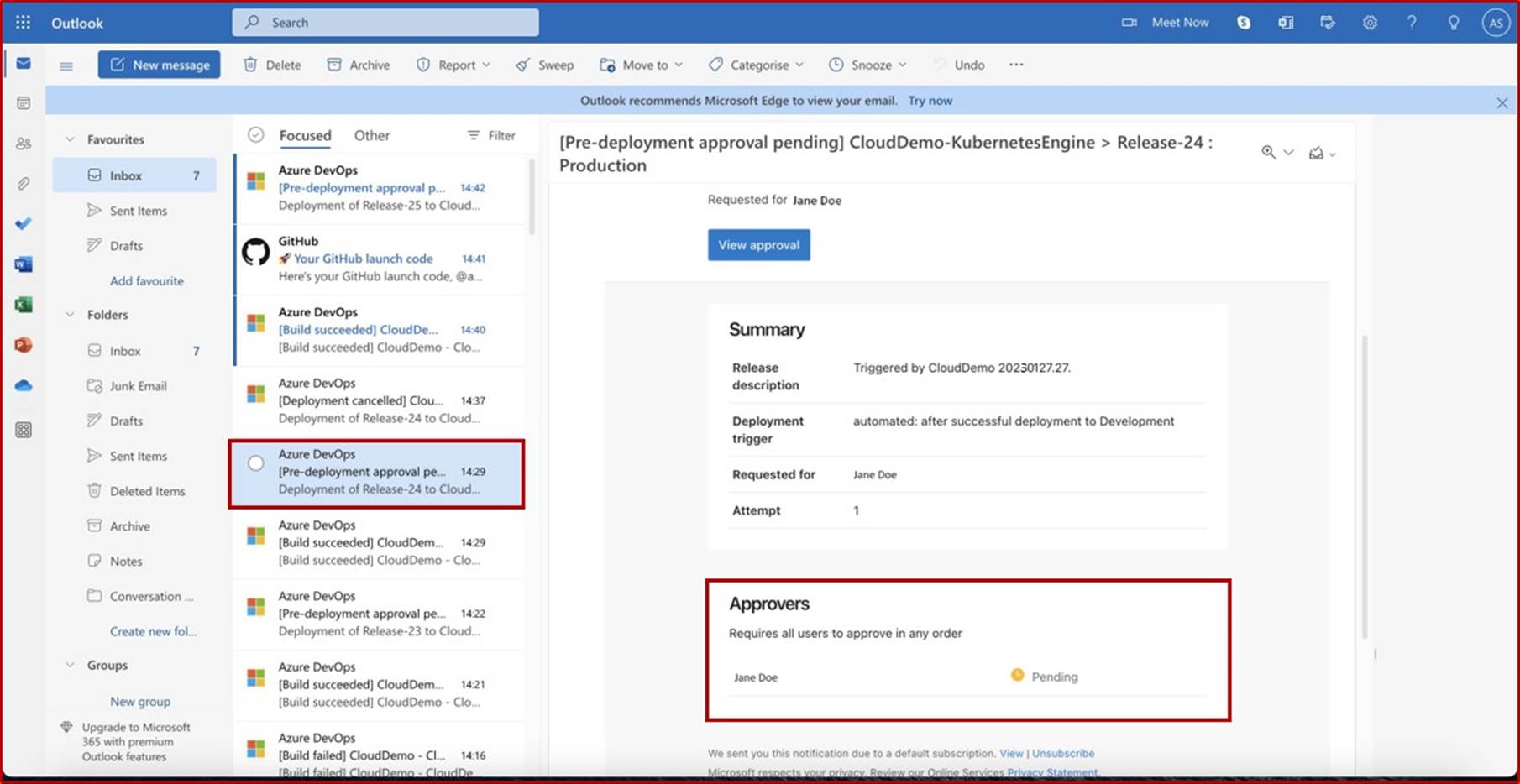
Используя уведомление по электронной почте, рецензент может перейти к конвейеру выпуска в DevOps и предоставить утверждение. Мы видим, что добавлены комментарии, оправдывающие утверждение.
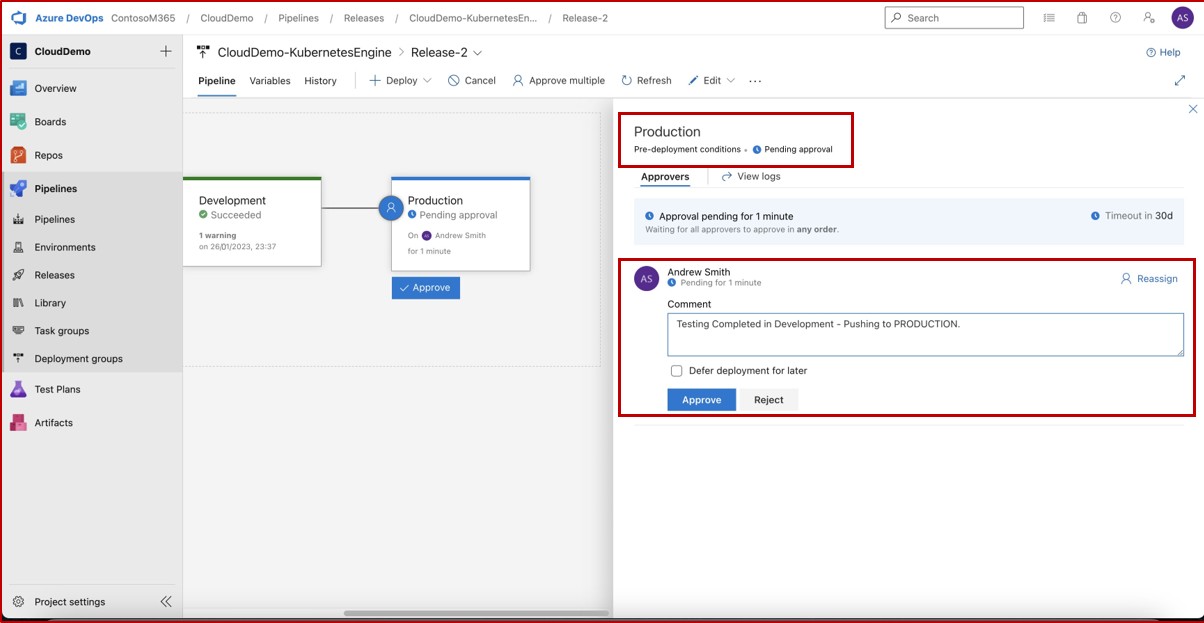
На втором снимке экрана показано, что утверждение было предоставлено и выпуск в рабочую среду успешно завершен.
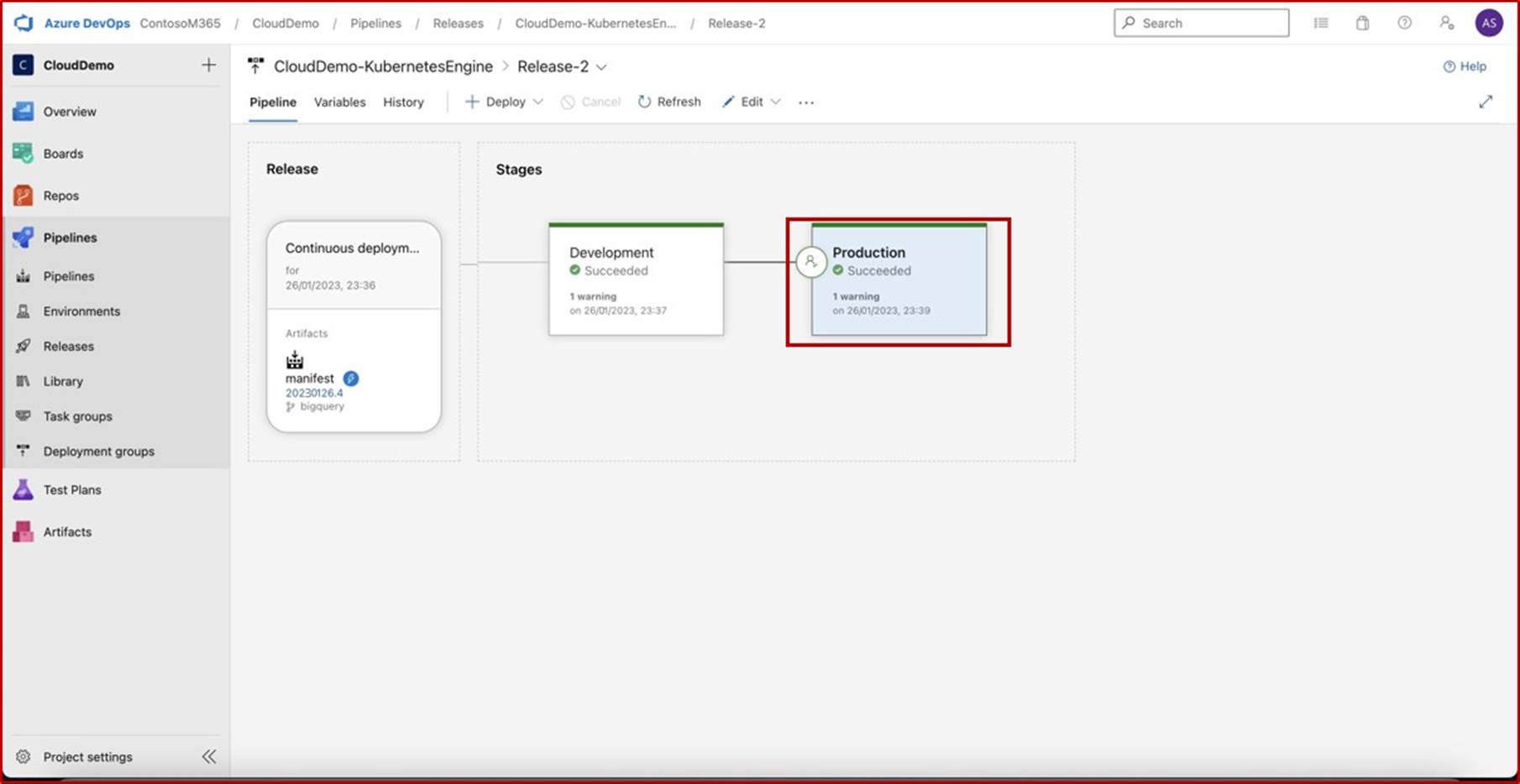
На следующих двух снимках экрана показана выборка ожидаемых доказательств.
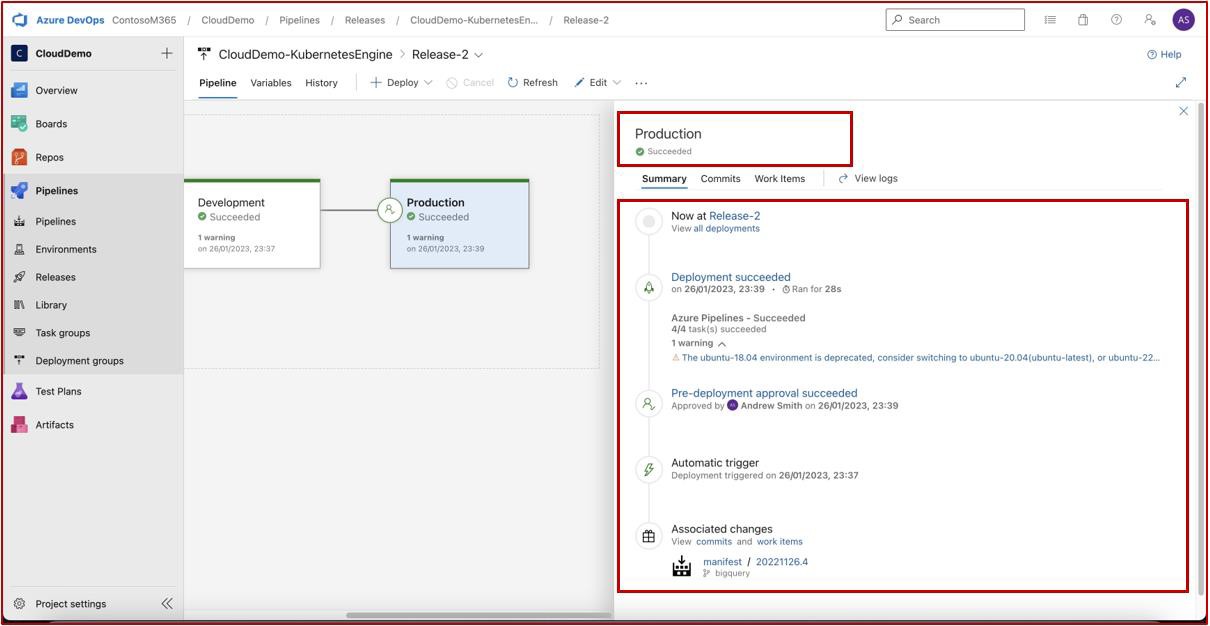
Свидетельство показывает, что существуют исторические выпуски и что применяются условия перед развертыванием, а перед развертыванием в рабочей среде требуется проверка и утверждение.
На следующем снимок экрана показан журнал выпусков, включая последний выпуск, который, как мы видим, был успешно развернут как в разработке, так и в рабочей среде.
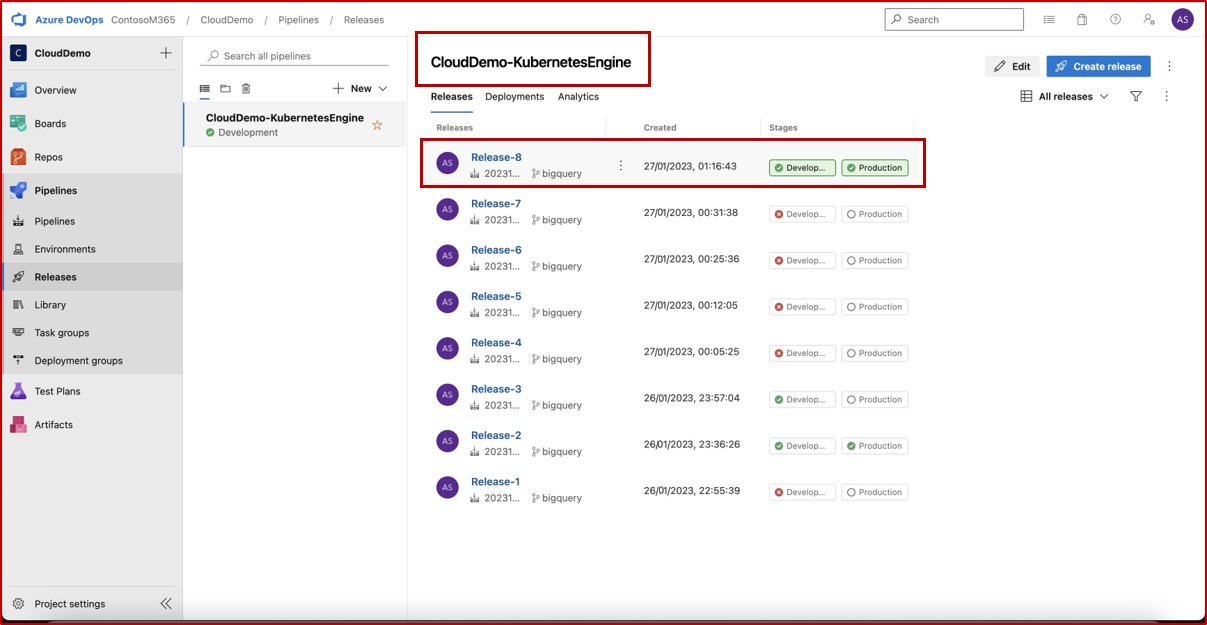
Примечание. В предыдущих примерах полный снимок экрана не использовался, однако все снимки экрана, отправленные isV, должны быть полными снимками экрана, показывающими URL-адрес, любое время и дату входа пользователя, системы.
Управление учетными записями
Безопасные методы управления учетными записями важны, так как учетные записи пользователей формируют основу для предоставления доступа к информационным системам, системным средам и данным. Учетные записи пользователей должны быть должным образом защищены, так как компрометация учетных данных пользователя может обеспечить не только плацдарм в среде и доступ к конфиденциальным данным, но также может обеспечить административный контроль над всей средой или ключевыми системами, если учетные данные пользователя имеют права администратора.
Элемент управления No 14
Предоставьте доказательства того, что:
Учетные данные по умолчанию отключаются, удаляются или изменяются в выборочных системных компонентах.
Выполняется процесс защиты (усиления защиты) учетных записей служб и выполнения этого процесса.
Намерение: учетные данные по умолчанию
Хотя это становится все менее популярным, по-прежнему существуют случаи, когда субъекты угроз могут использовать учетные данные пользователя по умолчанию и хорошо задокументированные учетные данные пользователя для компрометации компонентов рабочей системы. Популярным примером этого является dell iDRAC (интегрированный контроллер удаленного доступа Dell). Эту систему можно использовать для удаленного управления сервером Dell, который может использоваться субъектом угроз для получения контроля над операционной системой сервера. Учетные данные по умолчанию root::calvin задокументированы и часто могут использоваться субъектами угроз для получения доступа к системам, используемым организациями. Цель этого элемента управления — убедиться, что учетные данные по умолчанию отключены или удалены для повышения безопасности.
Рекомендации: учетные данные по умолчанию
Существуют различные способы сбора доказательств для поддержки этого элемента управления. Снимок экрана настроенных пользователей во всех системных компонентах может помочь, т. е. снимки экрана учетных записей Windows по умолчанию с помощью командной строки (CMD) и файлов Linux /etc/shadow и /etc/passwd помогут продемонстрировать, отключены ли учетные записи.
Пример доказательства: учетные данные по умолчанию
На следующем снимку экрана показан файл /etc/shadow, демонстрирующий, что учетные записи по умолчанию имеют заблокированный пароль, а новые созданные и активные учетные записи имеют доступный для использования пароль.
Обратите внимание, что файл /etc/shadow потребуется для демонстрации того, что учетные записи действительно отключены, замечая, что хэш паролей начинается с недопустимого символа, например "!", указывающего, что пароль непригоден для использования. На следующих снимках экрана значение "L" означает блокировку пароля именованной учетной записи. Этот параметр отключает пароль, изменяя его на значение, которое не соответствует возможному зашифрованном значению (добавляется! в начале пароля). "P" означает, что это пригодный для использования пароль.
На втором снимках экрана показано, что на сервере Windows все учетные записи по умолчанию отключены. С помощью команды "net user" в терминале (CMD) можно перечислить сведения о каждой из существующих учетных записей, замечая, что все эти учетные записи не активны.
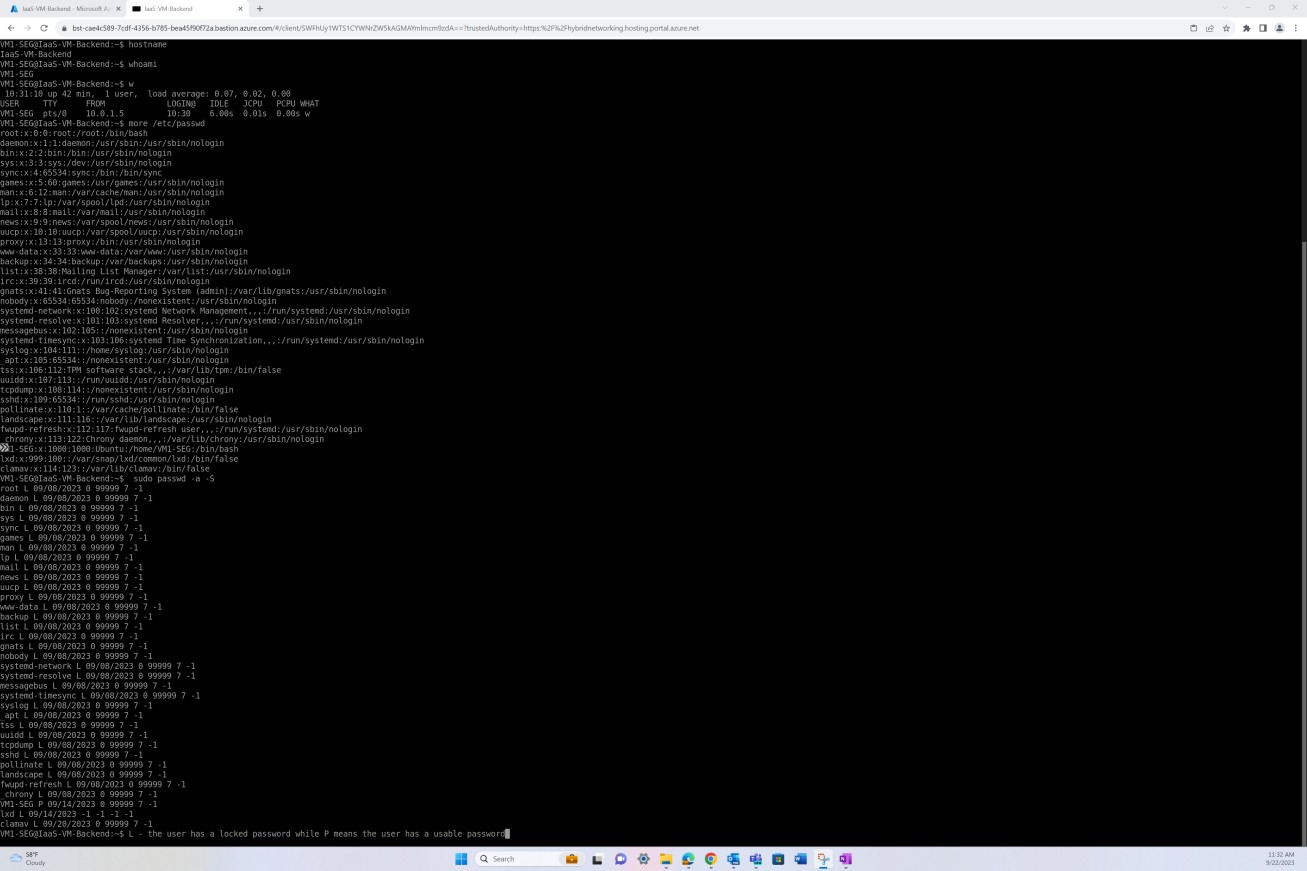
С помощью команды net user в CMD можно отобразить все учетные записи и заметить, что все учетные записи по умолчанию не активны.
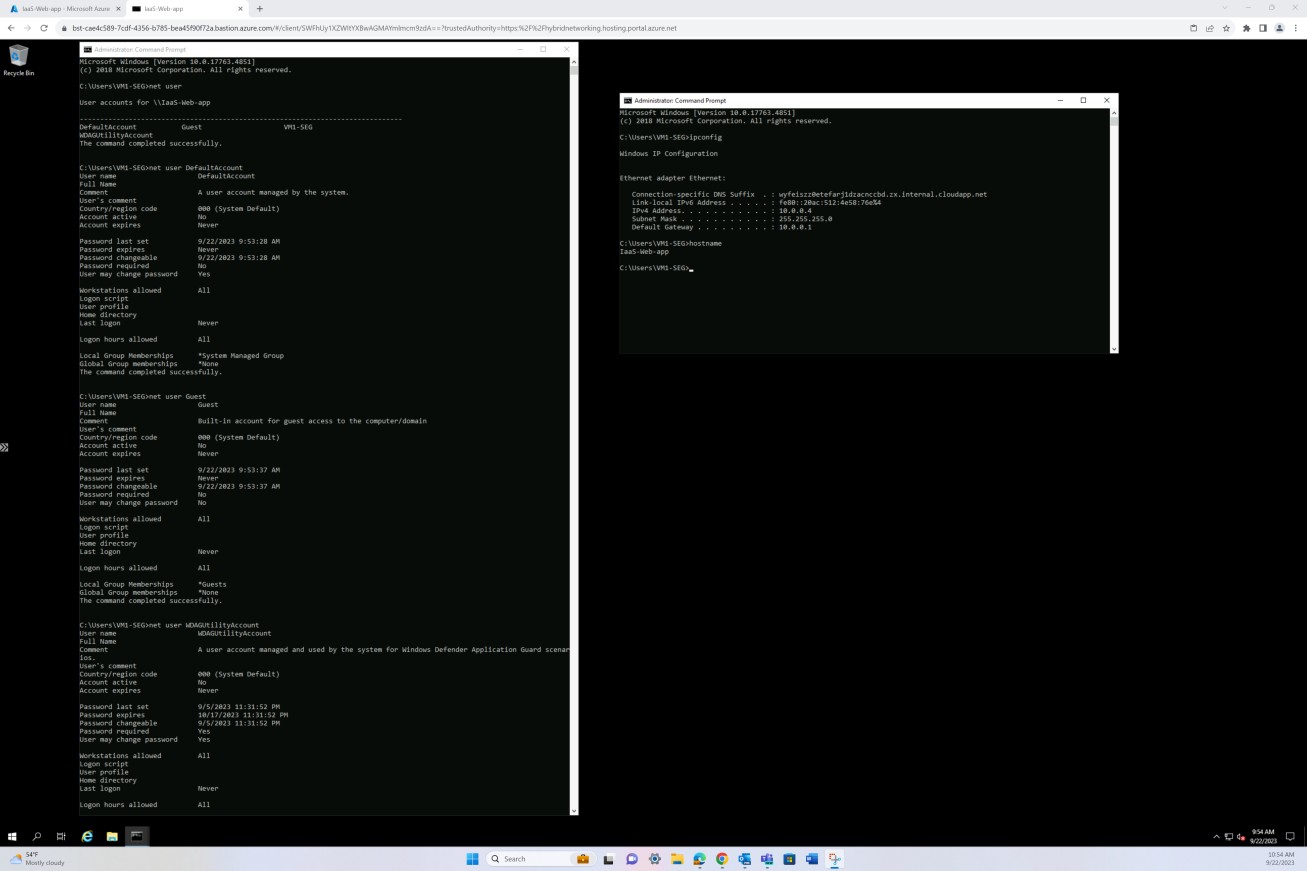
Намерение: учетные данные по умолчанию
Учетные записи служб часто становятся целевыми для субъектов угроз, так как они часто настроены с повышенными привилегиями. Эти учетные записи могут не следовать стандартным политикам паролей, так как срок действия паролей учетных записей службы часто нарушает функциональные возможности. Таким образом, они могут быть настроены с использованием слабых паролей или паролей, которые повторно используются в организации. Другой потенциальной проблемой, особенно в среде Windows, может быть то, что операционная система кэширует хэш паролей. Это может быть большой проблемой, если:
учетная запись службы настраивается в службе каталогов, так как эта учетная запись может использоваться для доступа в нескольких системах с настроенным уровнем привилегий;
учетная запись службы является локальной, вероятность того, что одна и та же учетная запись или пароль будут использоваться в нескольких системах в среде.
Предыдущие проблемы могут привести к тому, что субъект угроз получает доступ к большему набору систем в среде и может привести к дальнейшему повышению привилегий и/или боковому смещению. Таким образом, цель заключается в том, чтобы обеспечить правильную защиту учетных записей служб, чтобы защитить их от переключения на субъект угрозы, или путем ограничения риска в случае компрометации одной из этих учетных записей службы. Элемент управления требует наличия формального процесса усиления защиты этих учетных записей, который может включать ограничение разрешений, использование сложных паролей и регулярную смену учетных данных.
Рекомендации
В Интернете существует множество руководств, которые помогут защитить учетные записи служб. Доказательства могут быть в виде снимков экрана, демонстрирующих, как организация реализовала безопасное усиление защиты учетной записи. Ниже приведены несколько примеров (ожидается, что будет использоваться несколько методов).
Ограничение учетных записей набором компьютеров в Active Directory,
Настройка учетной записи для интерактивного входа запрещена.
Установка чрезвычайно сложного пароля,
Для Active Directory включите флаг "Учетная запись является конфиденциальной и не может быть делегирована".
Пример доказательства
Существует несколько способов усиления защиты учетной записи службы, которые будут зависеть от каждой отдельной среды. Ниже приведены некоторые из механизмов, которые могут быть использованы:
На следующем снимку экрана показан параметр "Учетная запись является конфиденциальной и подключение должно быть делегировано" в учетной записи службы "_Prod учетной записи службы SQL".
На этом втором снимке экрана показано, что учетная запись службы "_Prod учетная запись службы SQL" заблокирована для SQL Server и может выполнять вход только на этом сервере.
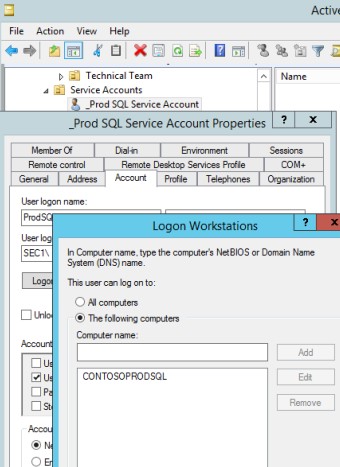
На следующем снимке экрана показано, что учетная запись службы "_Prod учетная запись службы SQL" разрешена только для входа в качестве службы.
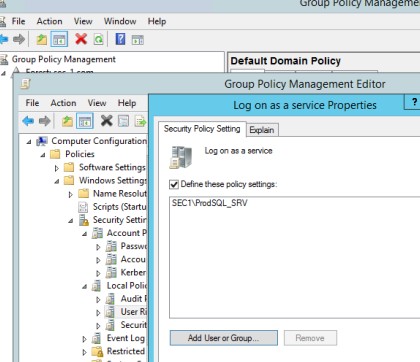
Примечание. В предыдущих примерах полный снимок экрана не использовался, однако все снимки экрана, отправленные isV, должны быть полными снимками экрана, показывающими URL-адрес, любое время и дату входа пользователя, системы.
Элемент управления No 15
Предоставьте доказательства того, что:
Уникальные учетные записи пользователей выдаются всем пользователям.
В среде соблюдаются принципы минимальных привилегий пользователей.
Существует политика надежных паролей или парольных фраз или другие подходящие способы устранения рисков.
Выполняется процесс, который выполняется по крайней мере каждые три месяца для отключения или удаления учетных записей, не используемых в течение 3 месяцев.
Намерение: безопасные учетные записи служб
Цель этого элемента управления — подотчетность. Выпустив пользователей с собственными уникальными учетными записями пользователей, пользователи будут отвечать за свои действия, так как действия пользователя могут отслеживаться отдельным пользователем.
Рекомендации. Защита учетных записей служб
Свидетельством могут быть снимки экрана, показывающие настроенные учетные записи пользователей в системных компонентах в области, которые могут включать серверы, репозитории кода, облачные платформы управления, Active Directory, брандмауэры и т. д.
Пример доказательства: безопасные учетные записи служб
На следующем снимке экрана показаны учетные записи пользователей, настроенные для среды Azure в области, и все учетные записи уникальны.
Намерение: привилегии
Пользователям должны быть предоставлены только привилегии, необходимые для выполнения их рабочих функций. Это позволяет ограничить риск того, что пользователь намеренно или непреднамеренно обращается к данным, которые он не должен или выполняет
вредоносный акт. Следуя этому принципу, он также уменьшает потенциальную область атаки (т. е. привилегированные учетные записи), на которые может быть направлен злоумышленник.
Рекомендации: привилегии
Большинство организаций будут использовать группы для назначения привилегий на основе команд в организации. Свидетельством могут быть снимки экрана, показывающие различные привилегированные группы и только учетные записи пользователей из команд, которым требуются эти привилегии. Как правило, резервная копия выполняется с помощью вспомогательных политик и процессов, определяющих каждую определенную группу с необходимыми привилегиями и бизнес-обоснованием, а иерархия участников группы для проверки членства в группах настроена правильно.
Например: в Azure группа "Владельцы" должна быть очень ограниченной, поэтому она должна быть задокументирована и в ней должно быть назначено ограниченное число людей. Другим примером может быть ограниченное число сотрудников с возможностью внесения изменений в код. Группа может быть настроена с этой привилегией с сотрудниками, которые считаются нуждающимися в этом разрешении. Это должно быть задокументировано, чтобы аналитик сертификации смог перекрестно ссылаться на документ с настроенными группами и т. д.
Пример доказательства: привилегии
На следующих снимках экрана показан принцип минимальных привилегий в среде Azure.
На следующем снимке экрана показано использование различных групп в Azure Active Directory (AAD)/Microsoft Entra. Обратите внимание, что существует три группы безопасности: "Разработчики", "Ведущие инженеры", "Операции безопасности".
При переходе к группе "Разработчики" на уровне группы назначаются только роли "Разработчик приложений" и "Читатели каталогов".
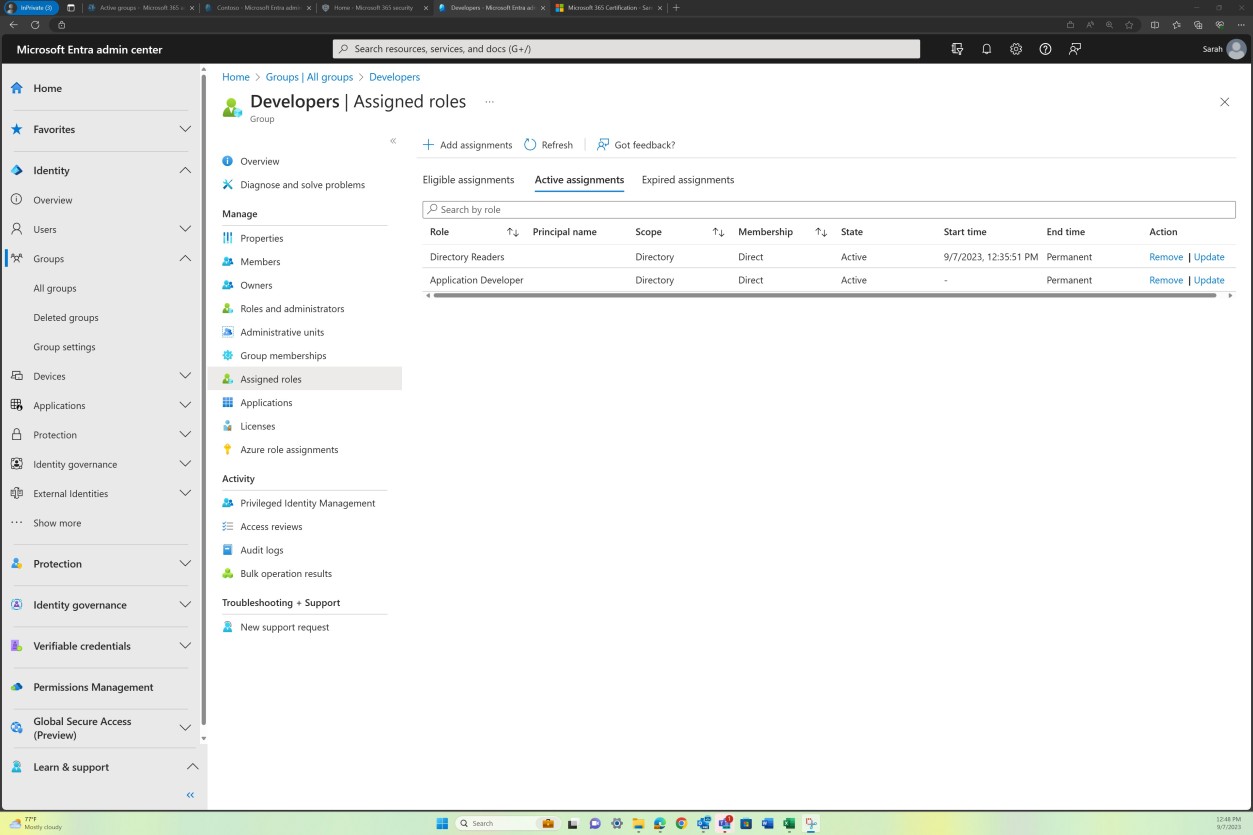
На следующем снимку экрана показаны члены группы "Разработчики".
Наконец, на следующем снимок экрана показан владелец группы.
В отличие от группы "Разработчики", "Операции безопасности" назначены разные роли, например "Оператор безопасности", который соответствует требованию задания.
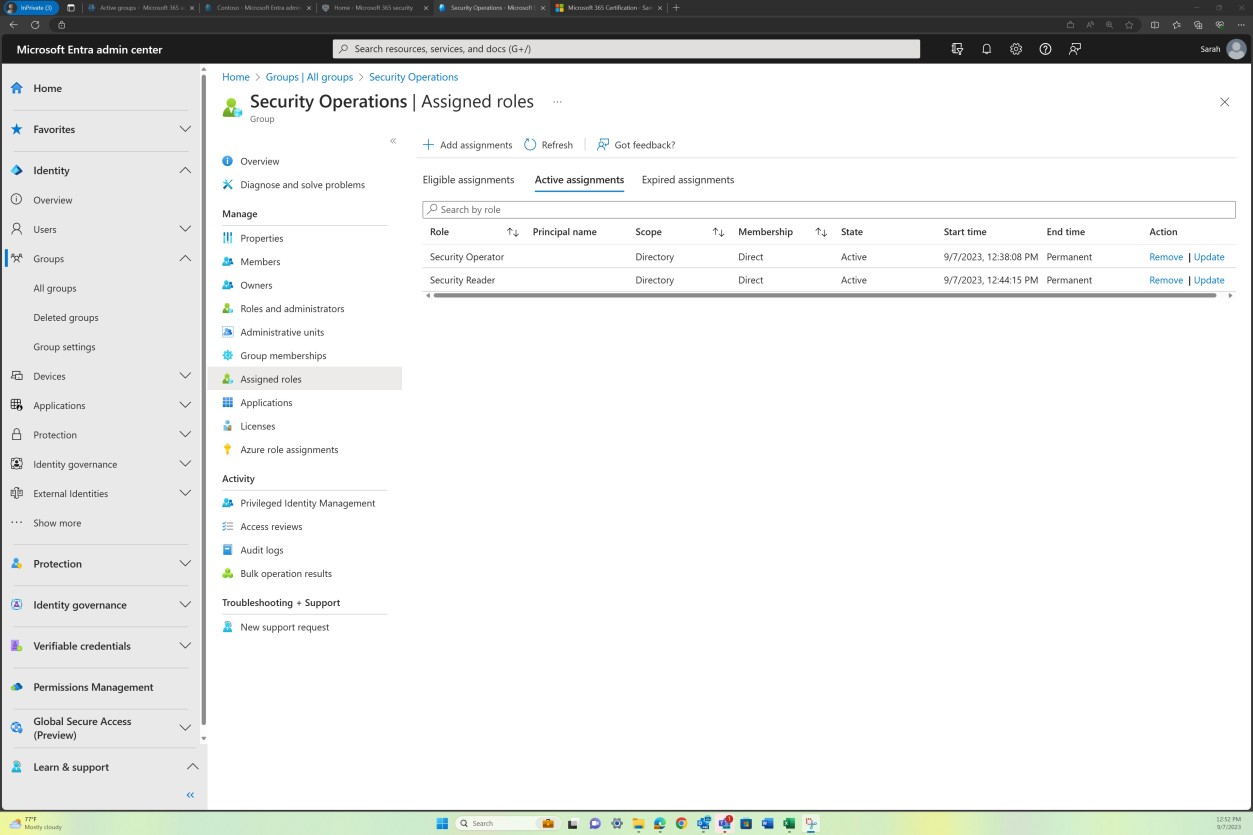
На следующем снимку экрана показано, что в группе "Операции безопасности" есть разные участники.
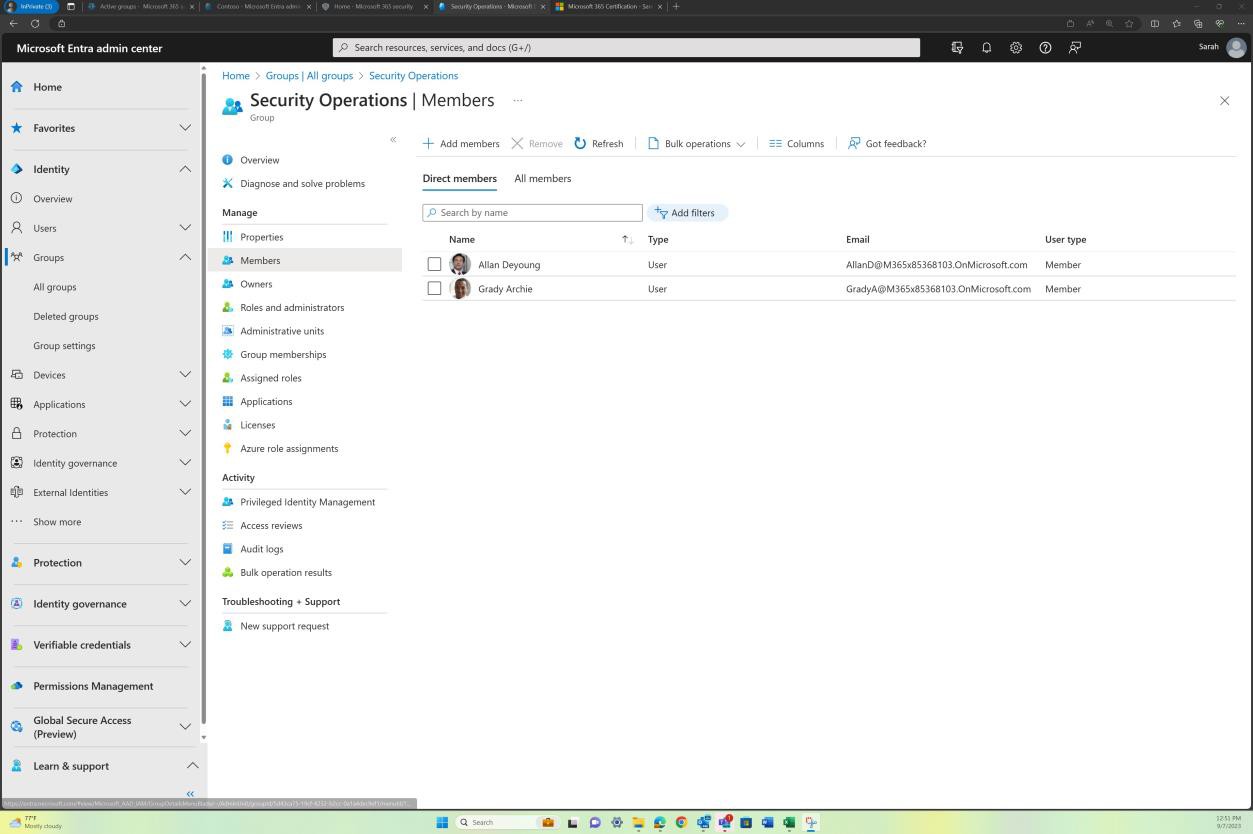
Наконец, группа имеет другого владельца.
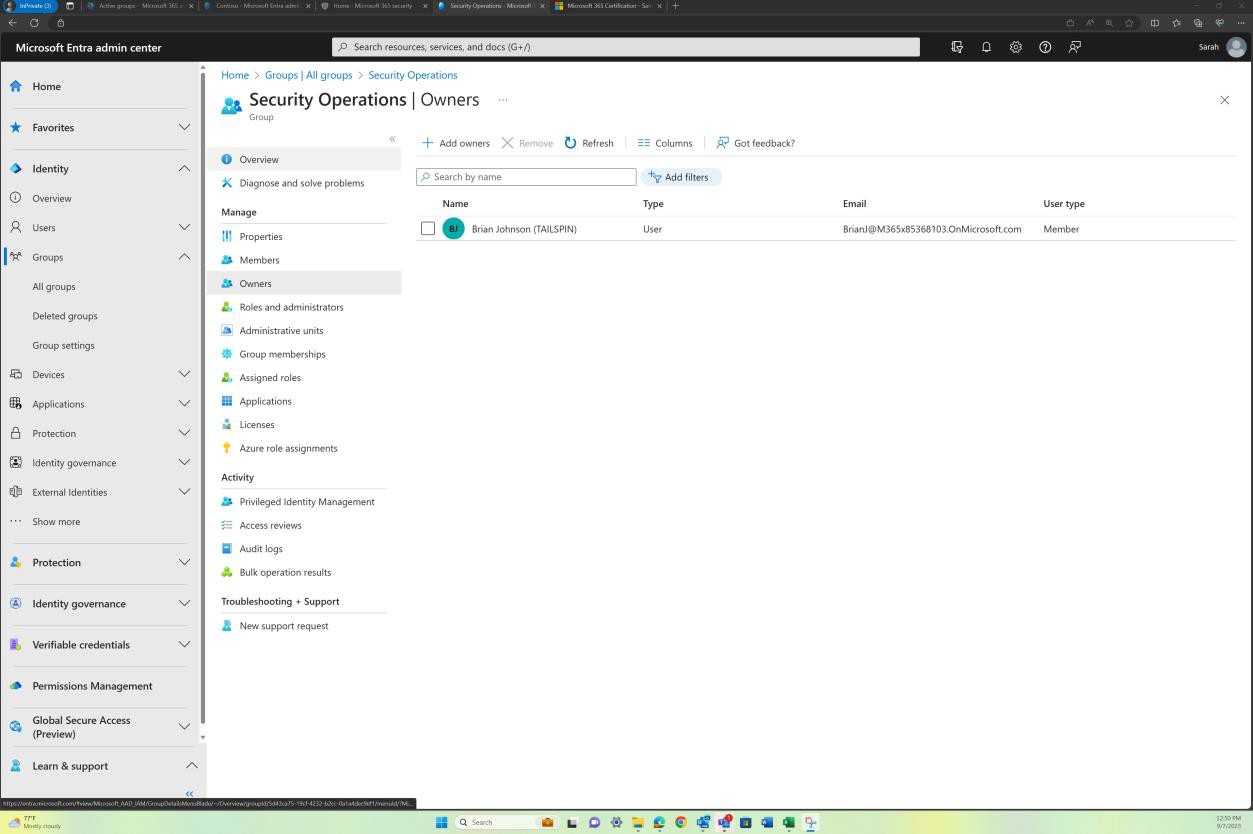
Глобальные администраторы — это очень привилегированная роль, и организации должны определить уровень риска, который они хотят принять при предоставлении такого типа доступа. В приведенном примере есть только два пользователя с этой ролью. Это необходимо для того, чтобы уменьшить область атаки и влияние.
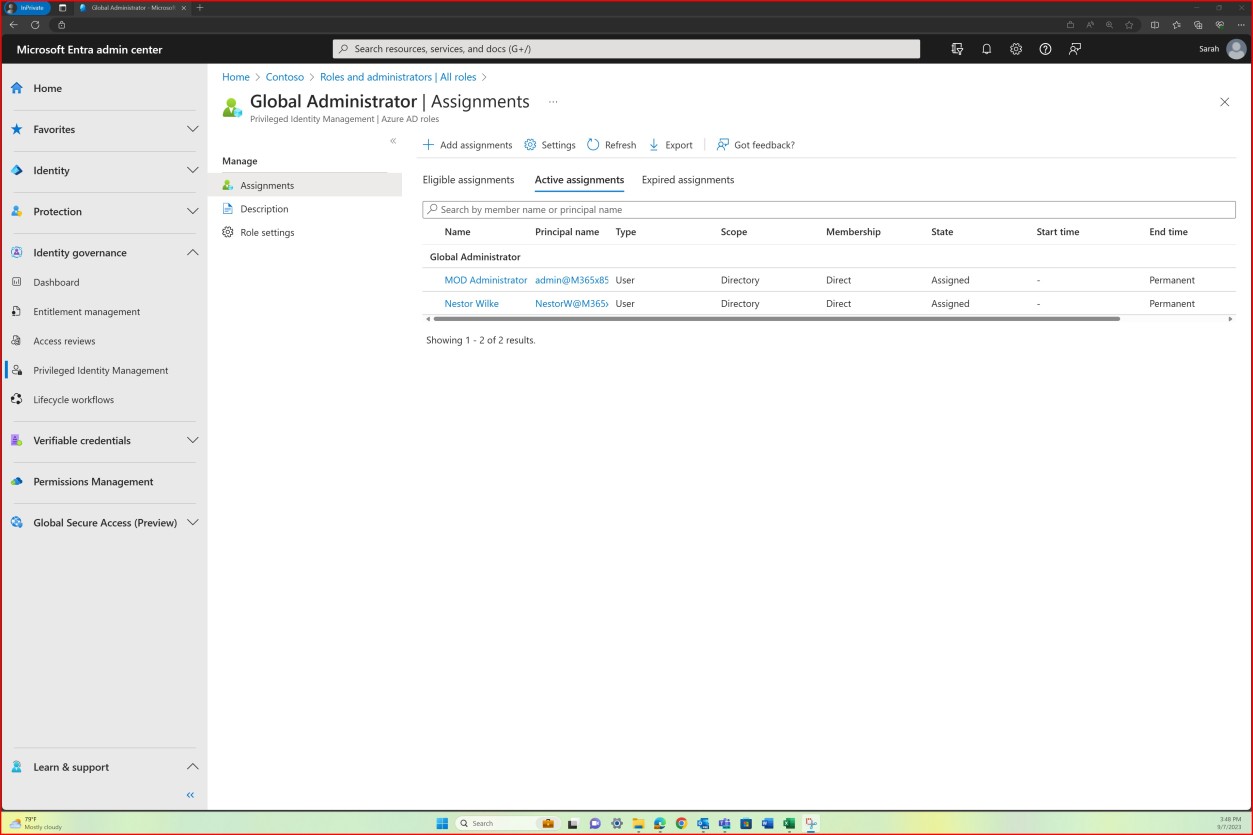
Намерение: политика паролей
Учетные данные пользователя часто являются целью атаки злоумышленников, пытающихся получить доступ к среде организации. Политика надежных паролей предназначена для того, чтобы попытаться заставить пользователей выбирать надежные пароли, чтобы снизить вероятность того, что субъекты угроз смогут принудить их к подбору. Цель добавления "или других подходящих мер по устранению рисков" заключается в том, чтобы признать, что организации могут реализовать другие меры безопасности для защиты учетных данных пользователей на основе отраслевых событий, таких как специальная публикация NIST800-63B.
Рекомендации: политика паролей
Свидетельством для демонстрации надежной политики паролей может быть снимок экрана объекта групповой политики организации или локальной политики безопасности "Политики учетных записей → политика паролей" и "Политики учетных записей → политика блокировки учетных записей". Свидетельство зависит от используемых технологий, т. е. для Linux это может быть файл конфигурации /etc/pam.d/common-password, для Bitbucket раздел "Политики проверки подлинности" на портале администрирования [Управление политикой паролей | AtlassianSupport и т. д.
Пример подтверждения: политика паролей
В следующих свидетельствах показана политика паролей, настроенная в локальной политике безопасности системного компонента CONTOSO-SRV1 в области.
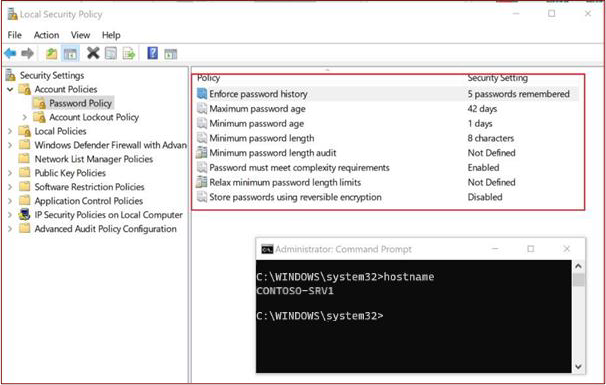
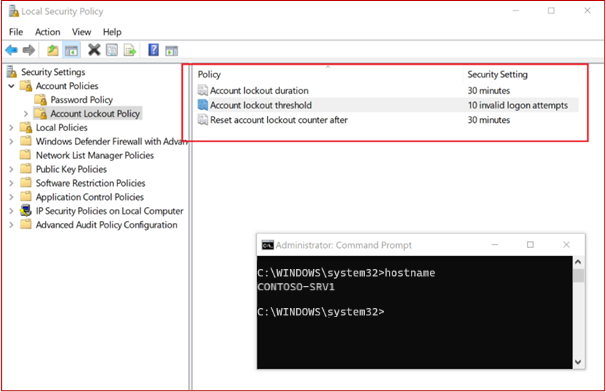
На следующем снимке экрана показаны параметры блокировки учетной записи для брандмауэра WatchGuard.
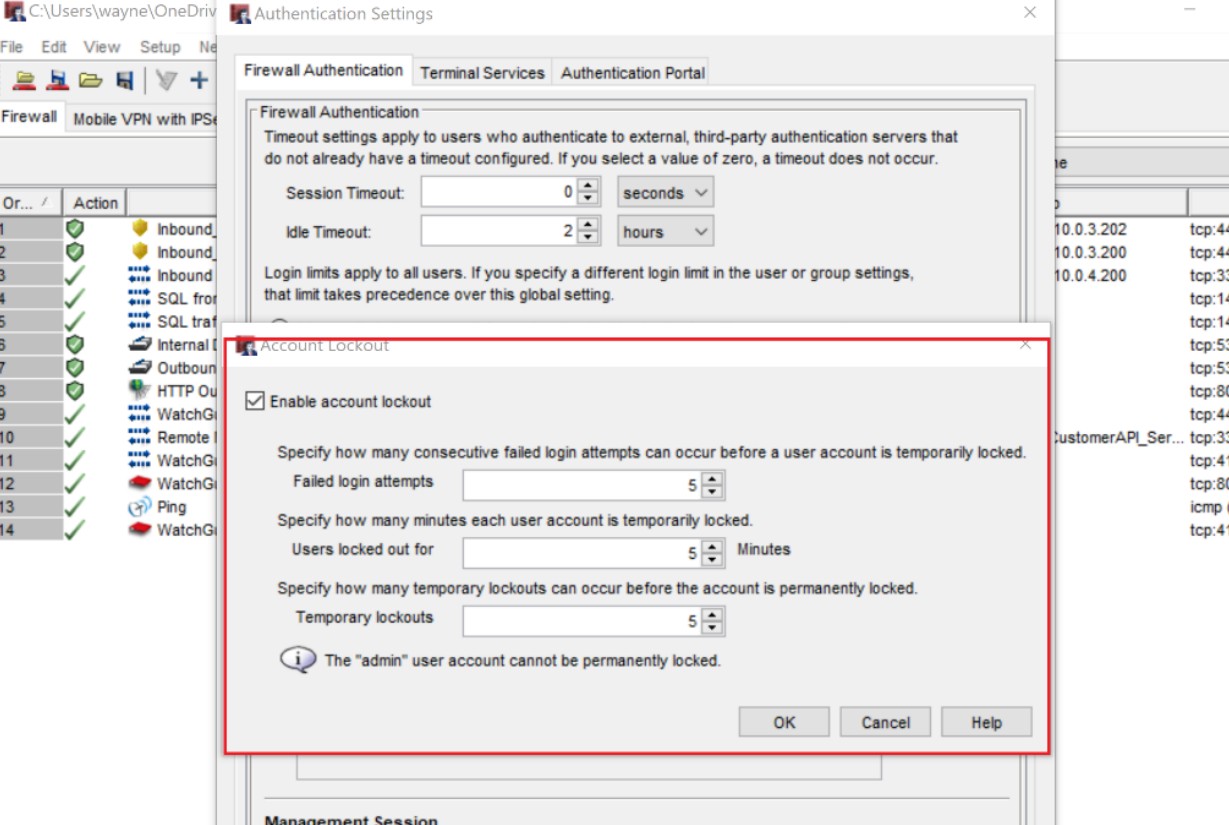
Ниже приведен пример минимальной длины парольной фразы для брандмауэра WatchGuard.
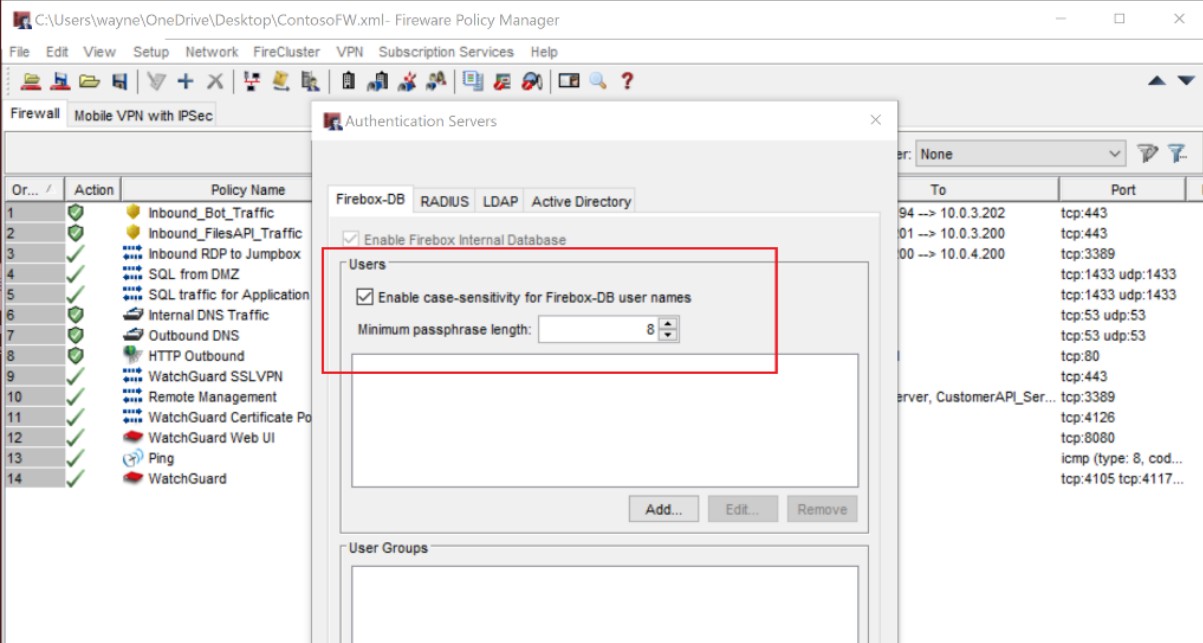
Обратите внимание: в предыдущих примерах полный снимок экрана не использовался, однако все снимки экрана, отправленные isV, должны быть полными снимками экрана, показывающими URL-адрес, все вошедшие в систему время и дату входа пользователя.
Намерение: неактивные учетные записи
Неактивные учетные записи иногда могут быть скомпрометированы либо из-за того, что они предназначены для атак методом подбора, которые не могут быть помечены как пользователь не будет пытаться войти в учетные записи, либо путем взлома базы данных паролей, когда пароль пользователя был использован повторно и доступен в дампе имени пользователя или пароля в Интернете. Неиспользуемые учетные записи должны быть отключены или удалены, чтобы уменьшить область атаки, которую субъект угроз должен выполнять действия по компрометации учетной записи. Эти счета могут быть вызваны тем, что процесс ухода не осуществляется должным образом, сотрудник, продолжающий долгосрочную болезнь, или сотрудник, уезжающий в отпуск по беременности и родам/уходу за ребенком. Реализуя ежеквартальный процесс идентификации этих учетных записей, организации могут свести к минимуму область атаки.
Этот контроль требует, чтобы процесс был на месте и следовать по крайней мере каждые три месяца для отключения или удаления учетных записей, которые не использовались в течение последних трех месяцев, с целью снижения риска путем обеспечения регулярных проверок учетных записей и своевременной деактивации неиспользуемых учетных записей.
Рекомендации: неактивные учетные записи
Доказательства должны быть двоякими:
Сначала снимок экрана или экспорт файла, показывающий "последний вход" всех учетных записей пользователей в среде в области. Это могут быть локальные учетные записи, а также учетные записи в централизованной службе каталогов, например AAD (Azure Active Directory). Это покажет, что учетные записи старше 3 месяцев не включены.
Во-вторых, свидетельство о процессе ежеквартальной проверки, которое может быть документальным свидетельством выполнения задачи в рамках ADO (Azure DevOps) или JIRA-билетов, или с помощью бумажных записей, которые должны быть подписаны.
Пример доказательства: неактивные учетные записи
На следующем снимку экрана показано, что для проверки доступа используется облачная платформа. Для этого используется функция управления удостоверениями в Azure.
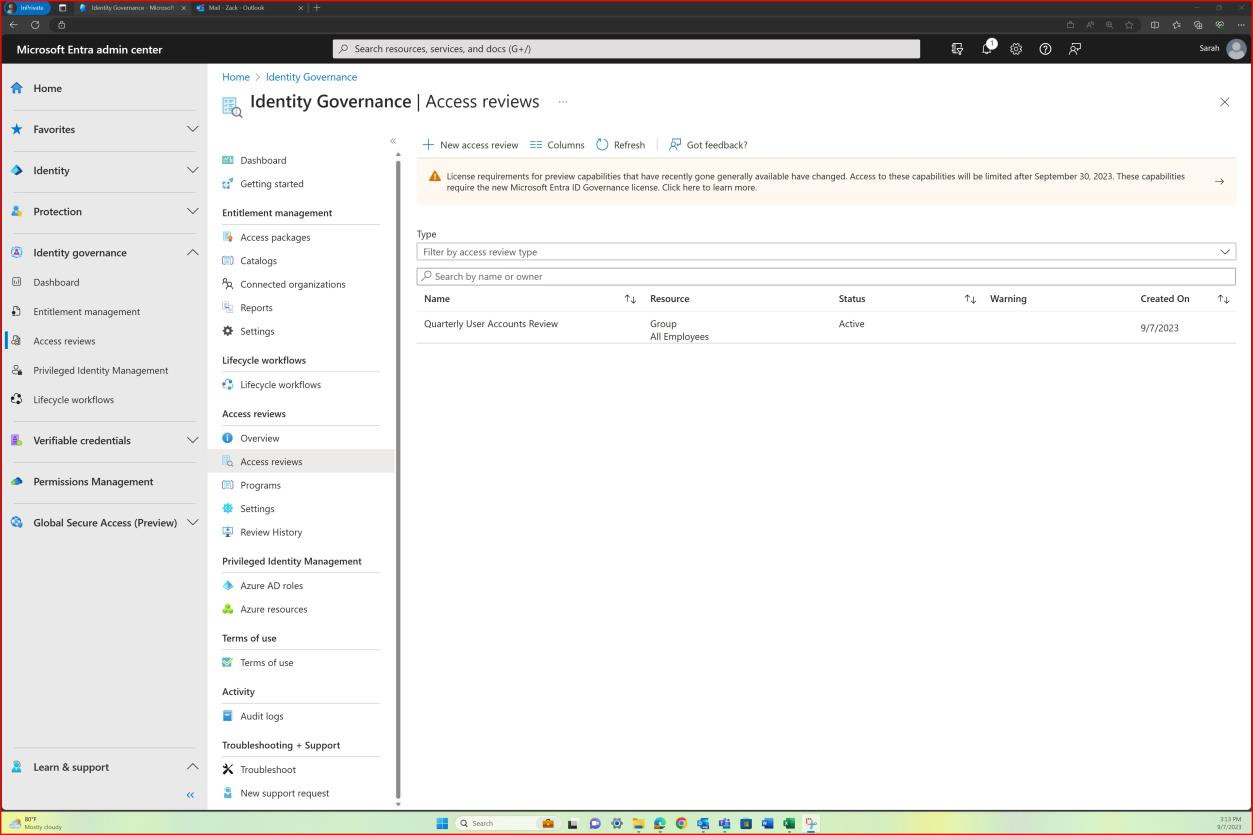
На следующем снимок экрана показан журнал отзывов, период проверки и состояние.
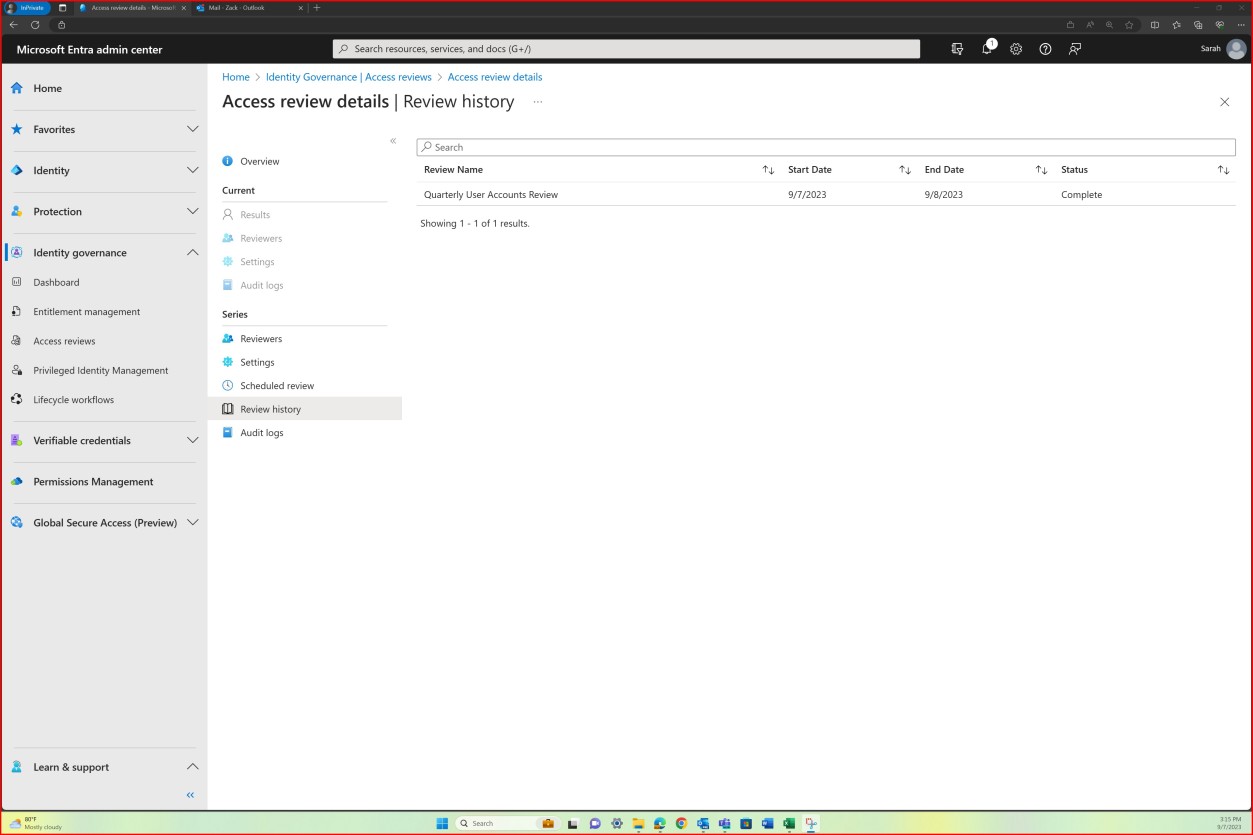
Панель мониторинга и метрики, образующие проверку, предоставляют дополнительные сведения, такие как область, которая является всеми пользователями организации, и результаты проверки, а также периодичность, которая является ежеквартально.
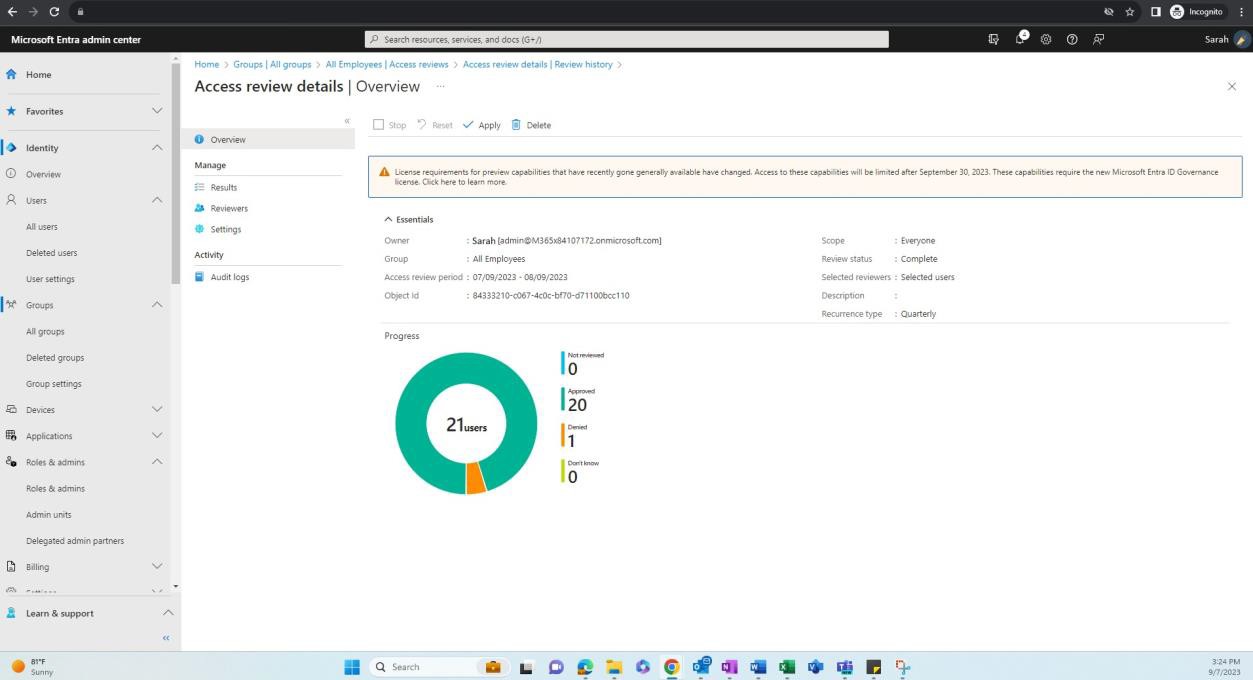
При оценке результатов проверки изображение указывает, что было предоставлено рекомендуемое действие, основанное на предварительно настроенных условиях. Кроме того, требуется, чтобы назначенный сотрудник вручную применял решения по проверке.
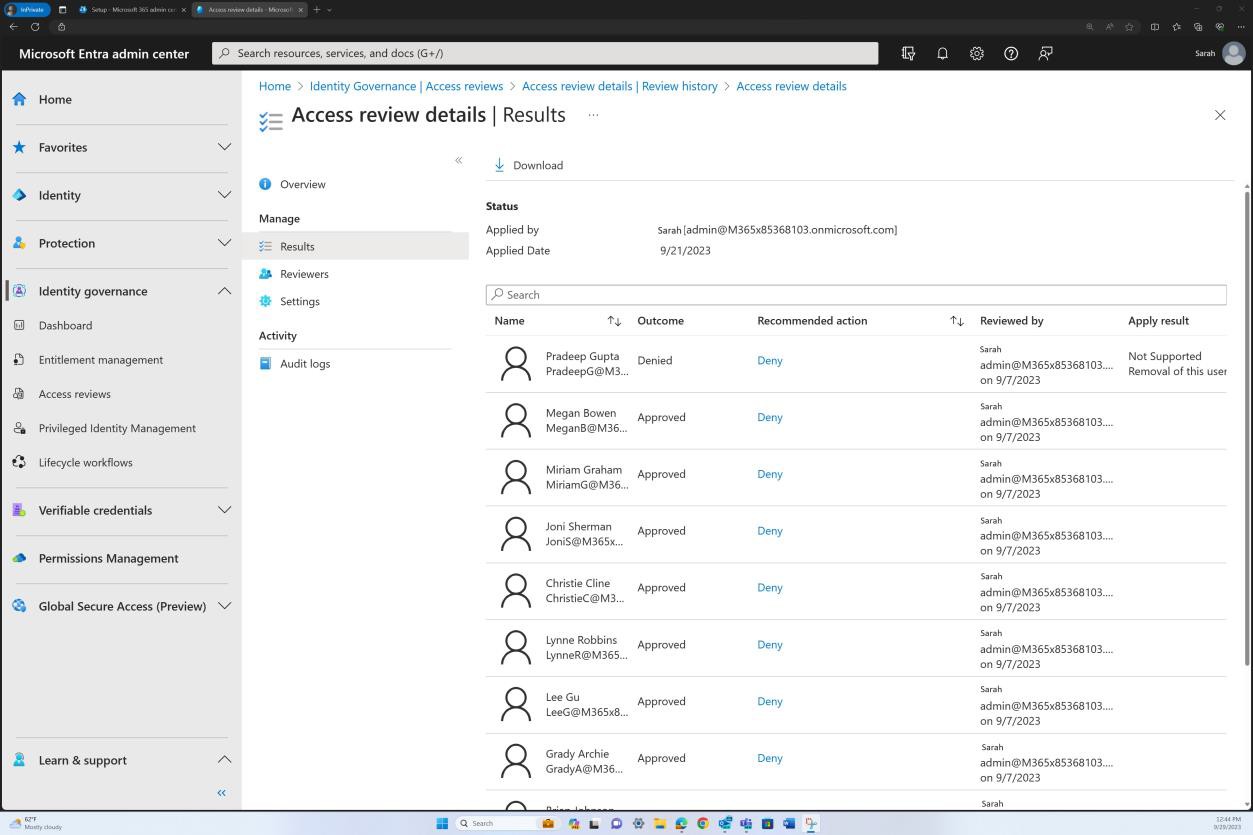
Ниже вы можете заметить, что для каждого сотрудника есть рекомендация и обоснование. Как упоминалось, решение принять рекомендацию или игнорировать ее перед применением проверки требуется назначенным лицом. Если окончательное решение противоречит рекомендации, то ожидается, что доказательства будут предоставлены для объяснения причин.
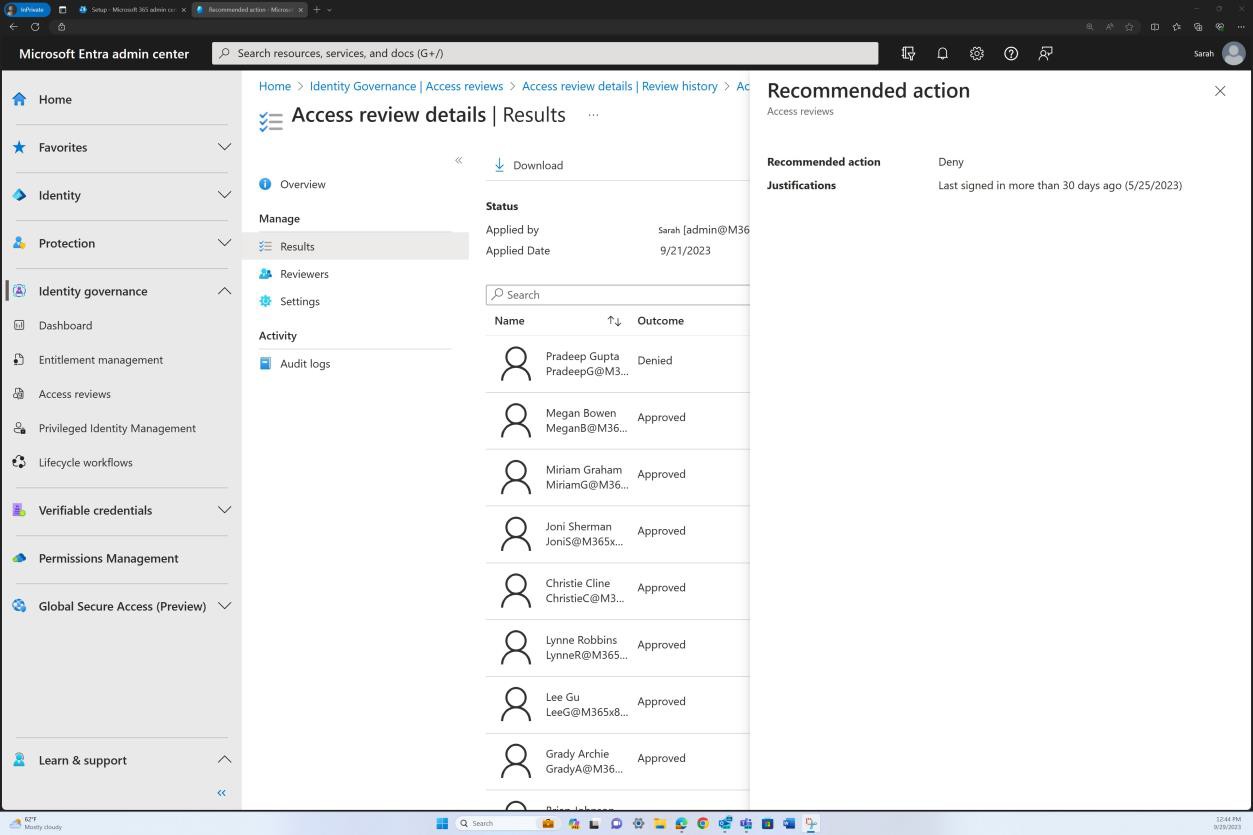
Элемент управления No 16
Убедитесь, что многофакторная проверка подлинности (MFA) настроена для всех подключений удаленного доступа и всех неконсолевых административных интерфейсов, включая доступ к любым репозиториям кода и интерфейсам управления облаком.
Значение этих терминов
Удаленный доступ . Это относится к технологиям, используемым для доступа к вспомогательной среде. Например, УДАЛЕННЫй доступ IPSec VPN, SSL VPN или Jumpbox/Bastian Host.
Неконсольные административные интерфейсы . Это относится к сетевым административным подключениям к компонентам системы. Это может быть удаленный рабочий стол, SSH или веб-интерфейс.
Репозитории кода . Кодовая база приложения должна быть защищена от вредоносных изменений, которые могут привести к вредоносным программам в приложение. MFA необходимо настроить в репозиториях кода.
Интерфейсы управления облачными клиентами— где часть или вся среда размещается в поставщике облачных служб (CSP). Сюда входит административный интерфейс для управления облаком.
Намерение: MFA
Цель этого элемента управления — обеспечить защиту от атак методом подбора на привилегированные учетные записи с безопасным доступом к среде путем реализации многофакторной проверки подлинности (MFA). Даже если пароль скомпрометирован, механизм MFA по-прежнему должен быть защищен, гарантируя, что все действия по доступу и администрирование выполняются только авторизованными и доверенными сотрудниками.
Для повышения безопасности важно добавить дополнительный уровень безопасности как для подключений удаленного доступа, так и для неконсолевых административных интерфейсов с помощью MFA. Подключения удаленного доступа особенно уязвимы для несанкционированного входа, а административные интерфейсы управляют функциями с высоким уровнем привилегий, что делает обе критически важные области, требующие повышенных мер безопасности. Кроме того, репозитории кода содержат конфиденциальные функции разработки, а интерфейсы управления облаком обеспечивают широкий доступ к облачным ресурсам организации, что делает их дополнительными критически важными точками, которые должны быть защищены с помощью MFA.
Рекомендации: MFA
Доказательства должны показать, что MFA включена во всех технологиях, которые соответствуют предыдущим категориям. Это может быть снимок экрана, показывающий, что MFA включена на уровне системы. На уровне системы нам нужны доказательства того, что она включена для всех пользователей, а не только для примера учетной записи с включенной MFA. Если технология откатывается к решению MFA, нам нужны доказательства, чтобы продемонстрировать, что она включена и используется. Что подразумевается под этим: Если технология настроена для проверки подлинности Radius, которая указывает на поставщика MFA, необходимо также доказать, что сервер Radius Server, на который он указывает, является решением MFA и что учетные записи настроены для его использования.
Пример доказательства: MFA
На следующих снимках экрана показано, как можно реализовать в AAD/Entra условную политику MFA для применения требования двухфакторной проверки подлинности в организации. Ниже мы видим, что политика включена.
На следующем снимку экрана показано, что политика MFA должна применяться ко всем пользователям в организации и что она включена.
На следующем снимку экрана показано, что доступ предоставляется при выполнении условия MFA. В правой части экрана видно, что доступ будет предоставлен пользователю только после реализации MFA.
Пример доказательства: MFA
Можно реализовать дополнительные элементы управления, например требование регистрации MFA, которое гарантирует, что после регистрации пользователям потребуется настроить MFA перед предоставлением доступа к новой учетной записи. Ниже приведена конфигурация политики регистрации MFA, которая применяется ко всем пользователям.
В продолжение предыдущего снимка экрана, на котором показана политика, применяемая без исключений, на следующем снимке экрана показано, что все пользователи включены в политику.
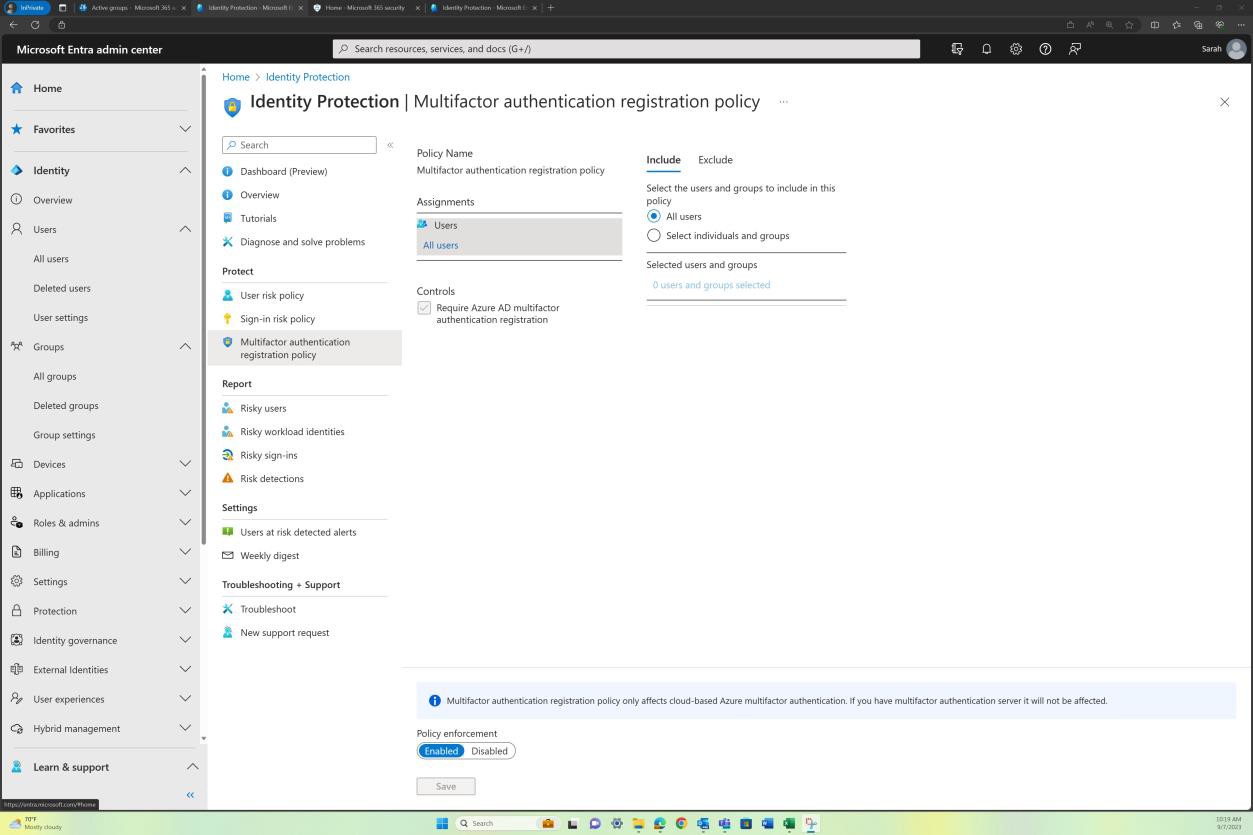
Пример доказательства: MFA
На следующем снимку экрана показано, что страница MFA для каждого пользователя демонстрирует, что MFA применяется для всех пользователей.
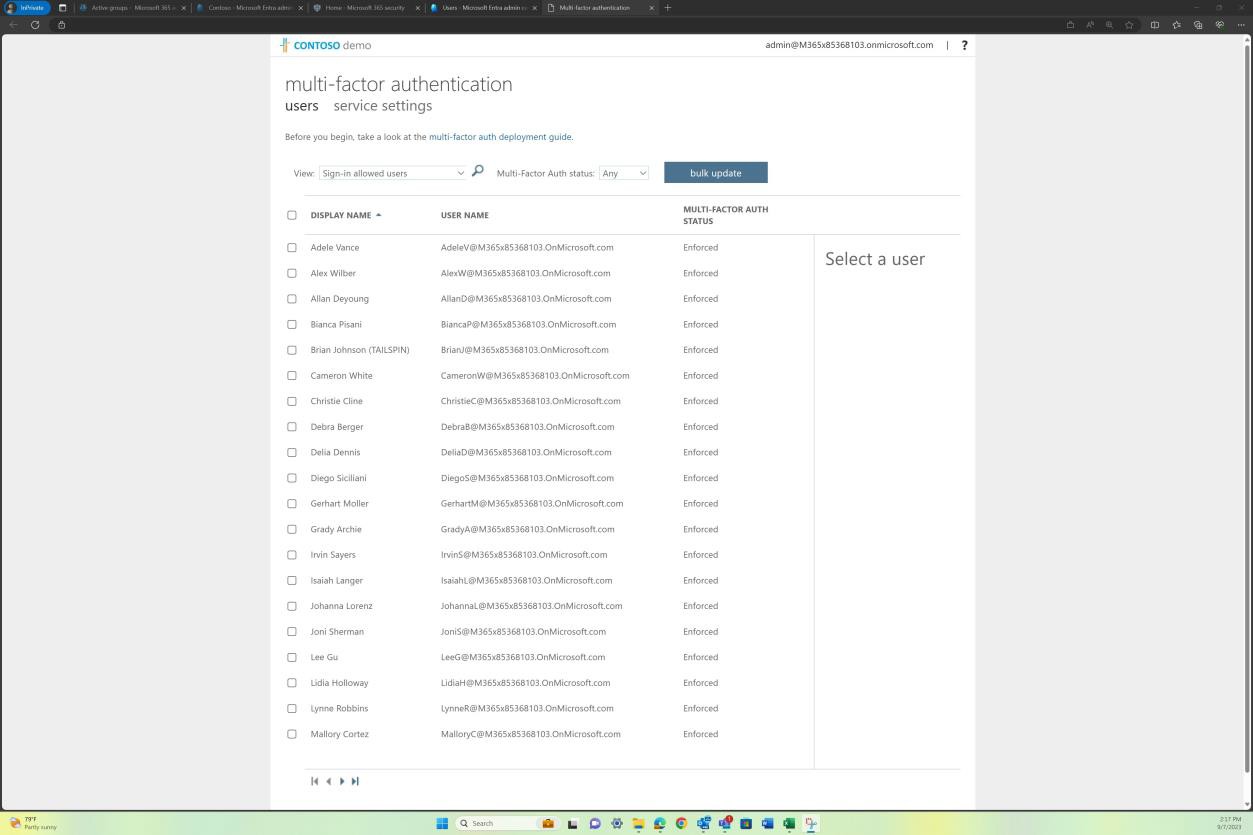
Пример доказательства: MFA
На следующих снимках экрана показаны области проверки подлинности, настроенные в Pulse Secure, которая используется для удаленного доступа к среде. Проверка подлинности отключается службой SaaS Duo для поддержки MFA.
На этом снимке экрана показано, что включен дополнительный сервер проверки подлинности, указывающий на "Duo-LDAP" для области проверки подлинности "Duo — маршрут по умолчанию".
На этом заключительном снимке экрана показана конфигурация для сервера проверки подлинности Duo-LDAP, которая показывает, что это указывает на службу SaaS Duo для MFA.
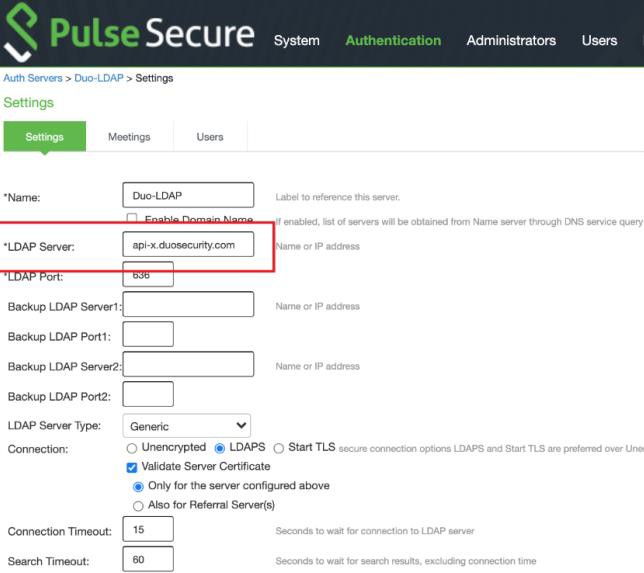
Примечание. В предыдущих примерах полный снимок экрана не использовался, однако все снимки экрана, отправленные isV, должны быть полными снимками экрана, показывающими URL-адрес, любое время и дату входа пользователя, системы.
Ведение журнала событий безопасности, просмотр и оповещение
Ведение журнала событий безопасности является неотъемлемой частью программы безопасности организации. Надлежащее ведение журнала событий безопасности в сочетании с настроенными процессами оповещений и проверки помогает организациям выявлять нарушения или попытки нарушений, которые могут быть использованы организацией для повышения безопасности и защитных стратегий безопасности. Кроме того, надлежащее ведение журнала будет способствовать реагированию на инциденты в организации, которая может использоваться в других действиях, таких как возможность точно определить, какие и кто данные были скомпрометированы, период компрометации, предоставление подробных аналитических отчетов государственным учреждениям и т. д.
Проверка журналов безопасности — это важная функция, помогающая организациям выявлять события безопасности, которые могут свидетельствовать о нарушениях безопасности или разведывательных действиях, которые могут свидетельствовать о будущем. Это можно сделать с помощью ежедневного процесса вручную или с помощью решения SIEM (управление информационной безопасностью и событиями), которое помогает анализировать журналы аудита, искать корреляции и аномалии, которые можно пометить для проверки вручную.
Критические события безопасности необходимо немедленно исследовать, чтобы свести к минимуму влияние на данные и рабочую среду. Оповещение помогает сразу же выявить потенциальные нарушения безопасности для сотрудников, чтобы обеспечить своевременный ответ, чтобы организация могла как можно быстрее сдержать событие безопасности. Обеспечивая эффективную работу оповещений, организации могут свести к минимуму последствия нарушения безопасности, тем самым уменьшая вероятность серьезного нарушения, которое может нанести ущерб торговой марке организации и нанести финансовые потери за счет штрафов и репутационного ущерба.
Элемент управления No 17
Укажите подтверждение того, что ведение журнала событий безопасности настроено в среде в области для регистрации событий, где это применимо, например:
Доступ пользователей к системным компонентам и приложению.
Все действия, выполняемые пользователем с высоким уровнем привилегий.
Недопустимые попытки логического доступа.
Создание или изменение привилегированной учетной записи.
Изменение журнала событий.
Отключение средств безопасности; например, ведение журнала событий.
Ведение журнала защиты от вредоносных программ; например, обновления, обнаружение вредоносных программ, сбои сканирования.
Намерение: ведение журнала событий
Для выявления попыток и фактических нарушений важно, чтобы все системы, составляющие среду, собирали соответствующие журналы событий безопасности. Цель этого элемента управления заключается в том, чтобы обеспечить фиксацию правильных типов событий безопасности, которые затем могут передаваться в процессы проверки и оповещения, чтобы помочь идентифицировать эти события и реагировать на них.
Эта вложенная точка требует, чтобы isV настроили ведение журнала событий безопасности для записи всех экземпляров доступа пользователей к системным компонентам и приложениям. Это крайне важно для отслеживания доступа к системным компонентам и приложениям в организации и имеет важное значение для обеспечения безопасности и аудита.
Для этого необходимо, чтобы все действия, выполняемые пользователями с привилегированными правами, регистрировались. Пользователи с высоким уровнем привилегий могут внести значительные изменения, которые могут повлиять на состояние безопасности организации. Поэтому крайне важно вести учет их действий.
Эта подзапункта требует ведения журнала любых недопустимых попыток получить логический доступ к системным компонентам или приложениям. Такое ведение журнала является основным способом обнаружения попыток несанкционированного доступа и потенциальных угроз безопасности.
Эта подзапункта требует ведения журнала любого создания или изменения учетных записей с привилегированным доступом. Этот тип ведения журнала имеет решающее значение для отслеживания изменений в учетных записях, которые имеют высокий уровень доступа к системе и могут быть атакованы злоумышленниками.
Эта подзапункта требует ведения журнала любых попыток незаконного изменения журналов событий. Незаконное изменение журналов может быть способом скрыть несанкционированные действия, поэтому крайне важно, чтобы такие действия регистрировались и действовали.
Эта подзапункт требует ведения журнала всех действий, которые отключают средства безопасности, включая ведение журнала событий. Отключение средств безопасности может быть красным флагом, указывающим на атаку или внутреннюю угрозу.
Эта подзапункт требует ведения журнала действий, связанных с средствами защиты от вредоносных программ, включая обновления, обнаружение вредоносных программ и сбои сканирования. Правильная работа и обновление средств защиты от вредоносных программ необходимы для обеспечения безопасности организации, а журналы, связанные с этими действиями, помогают в мониторинге.
Рекомендации: ведение журнала событий
Доказательства с помощью снимков экрана или параметров конфигурации должны предоставляться на всех устройствах и любых важных системных компонентах, чтобы продемонстрировать, как настроено ведение журнала для обеспечения гарантии того, что эти типы событий безопасности фиксируются.
Пример доказательства
На следующих снимках экрана показаны конфигурации журналов и метрик, созданных различными ресурсами в Azure, которые затем передаются в централизованную рабочую область Log Analytic.
На первом снимке экрана видно, что хранилище журналов — PaaS-web-app-log-analytics.
В Azure параметры диагностики можно включить в ресурсах Azure для доступа к журналам аудита, безопасности и диагностики, как показано ниже. Журналы действий, которые доступны автоматически, включают источник событий, дату, пользователя, метку времени, исходные адреса, адреса назначения и другие полезные элементы.
Обратите внимание: в следующих примерах показан тип доказательств, которые можно предоставить для выполнения этого элемента управления. Это зависит от того, как ваша организация настроила ведение журнала событий безопасности в среде в области. Другие примеры могут включать Azure Sentinel, Datadog и т. д.
С помощью параметра "Параметры диагностики" для веб-приложения, размещенного в Службах приложений Azure, можно настроить, какие журналы создаются и куда отправляются для хранения и анализа.
На следующем снимке экрана для журналов аудита access и IPSecurity Audit Logs настроены для создания и записи в рабочую область Log Analytic.
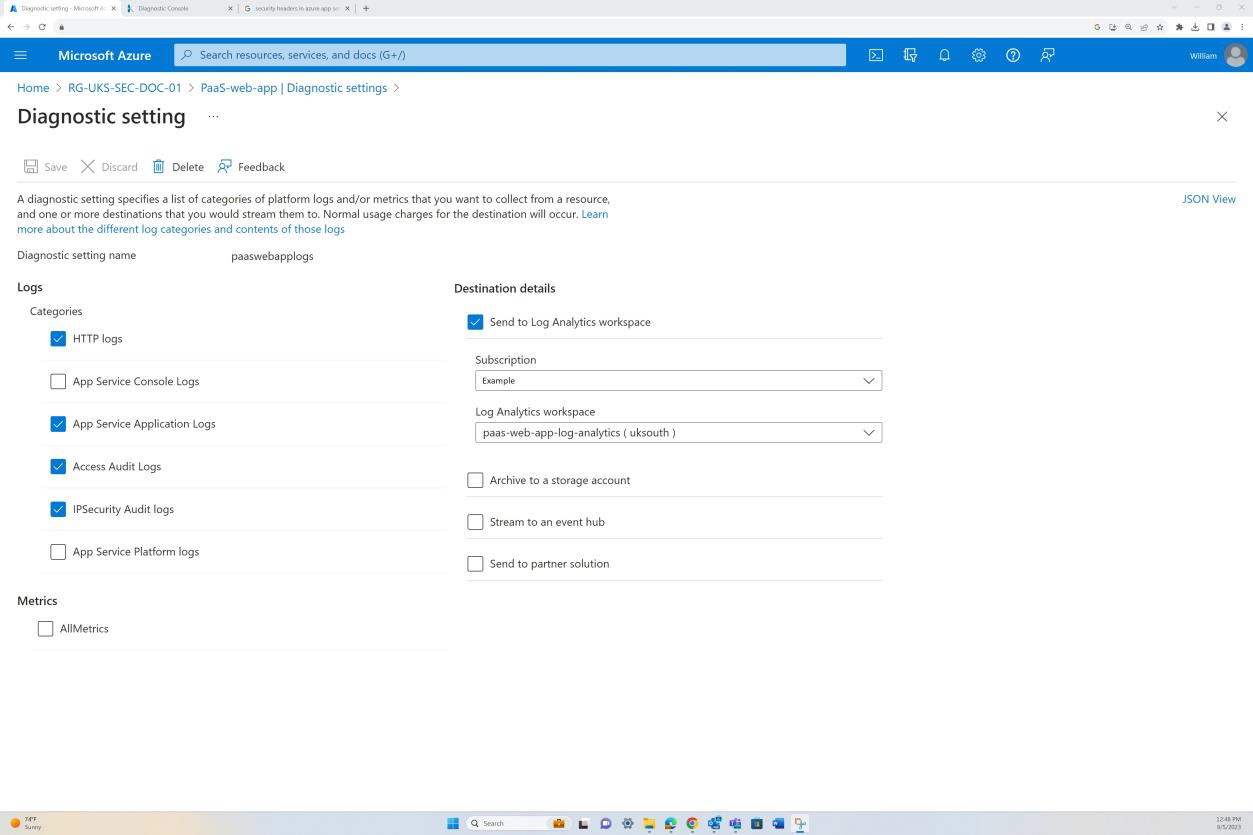
Другой пример — Azure Front Door, который настроен для отправки журналов, созданных в ту же централизованную рабочую область Log Analytic.
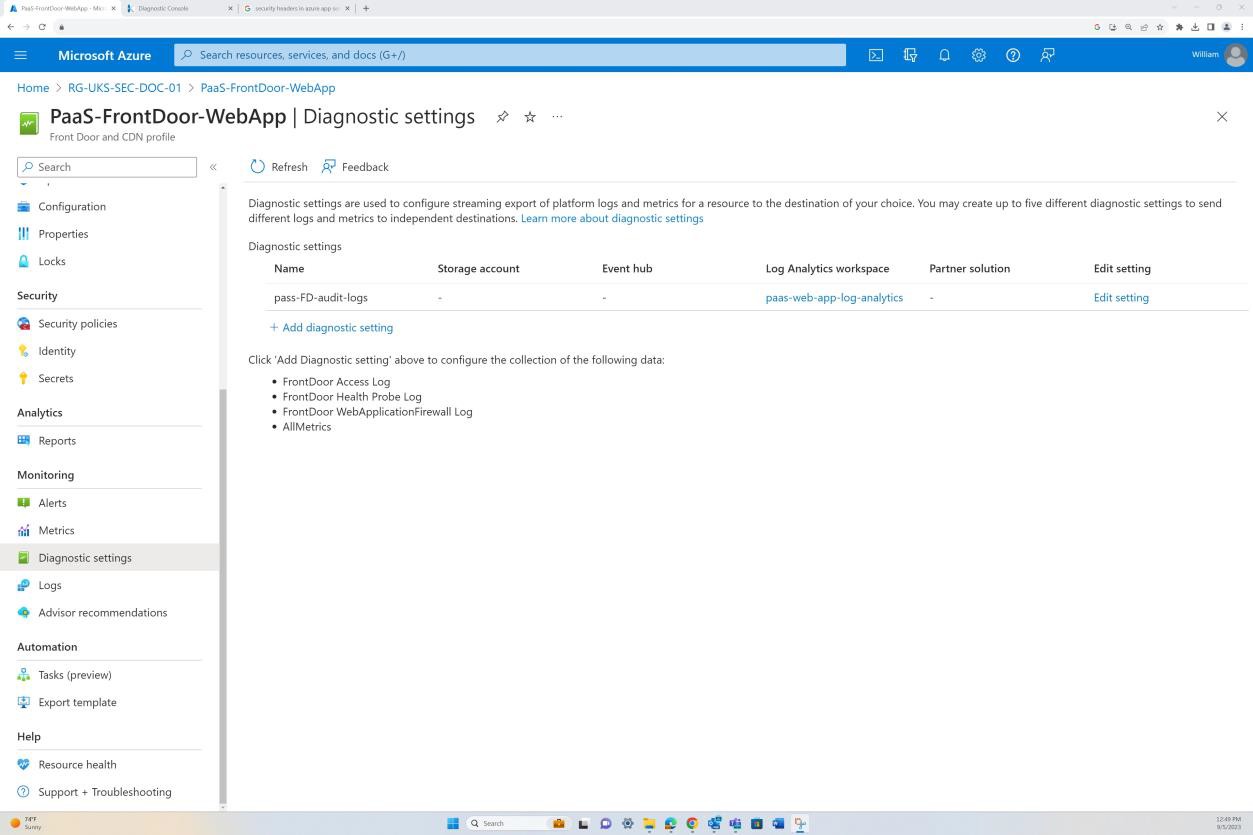
Как и перед использованием параметра "Параметры диагностики", настройте, какие журналы создаются и куда отправляются для хранения и анализа. На следующем снимку экрана показано, что журналы доступа и журналы WAF настроены.
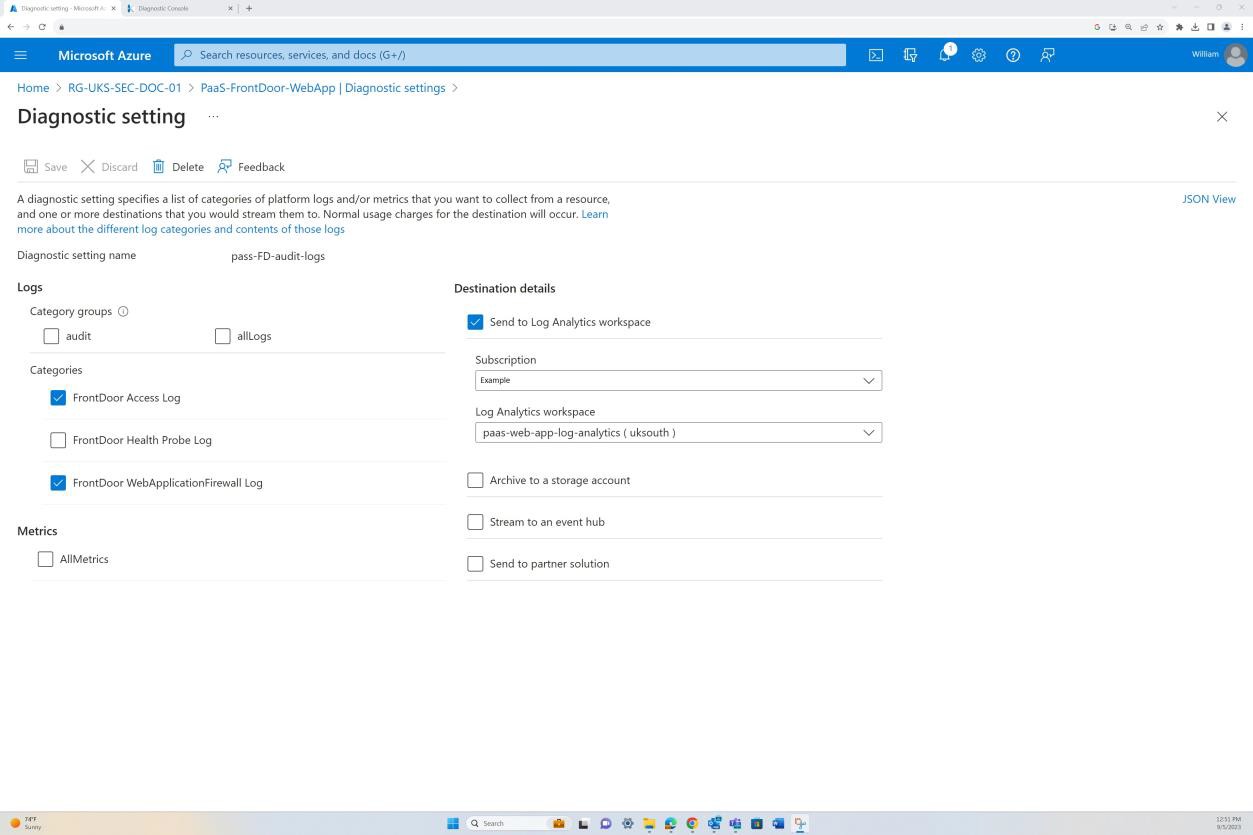
Аналогичным образом, для AZURE SQL Server "Параметры диагностики" могут настроить, какие журналы создаются и куда отправляются для хранения и анализа.
На следующем снимках экрана показано, что журналы аудита для сервера SQL Server создаются и отправляются в рабочую область Log Analytics.
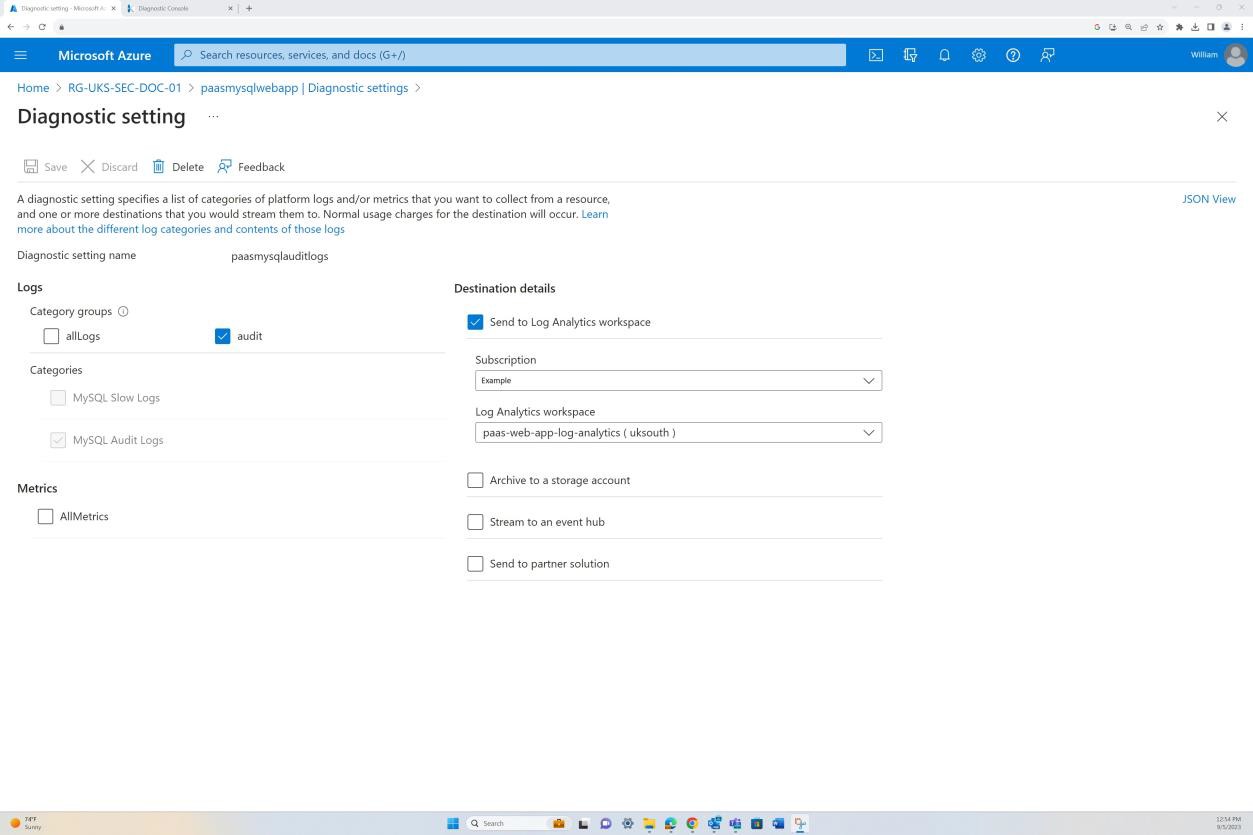
Пример доказательства
На следующем снимку экрана из AAD/Entra показано, что журналы аудита создаются для привилегированных ролей и администраторов. Эти сведения включают состояние, действие, службу, целевой объект и инициатор.
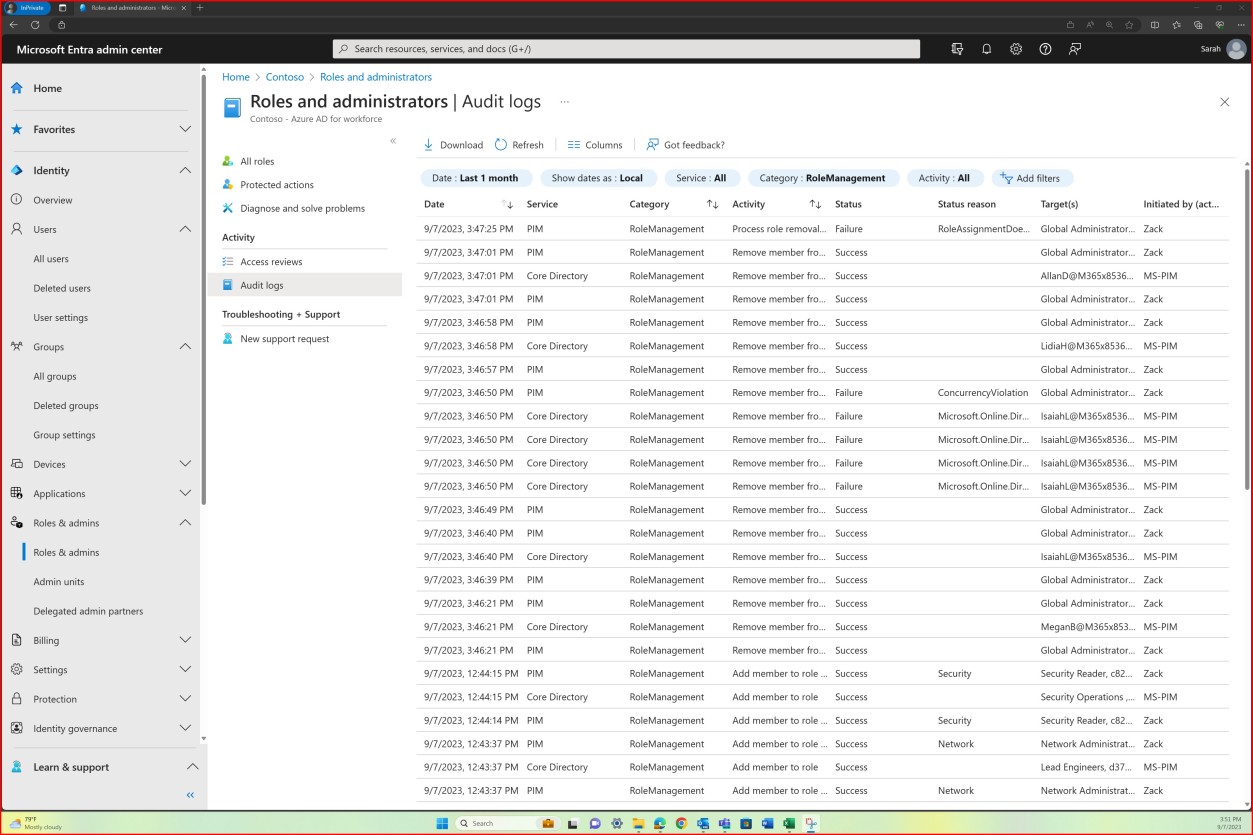
На следующем снимке экрана показаны журналы входа. Сведения журнала включают IP-адрес, состояние, расположение и дату.
Пример доказательства
В следующем примере основное внимание уделяется журналам, созданным для вычислительных экземпляров, таких как виртуальные машины. Реализовано правило сбора данных, и регистрируются журналы событий Windows, включая журналы аудита безопасности.
На следующем снимке экрана показан еще один пример параметров конфигурации из примера устройства с именем Galaxy-Compliance. Параметры демонстрируют различные параметры аудита, включенные в "Локальную политику безопасности".
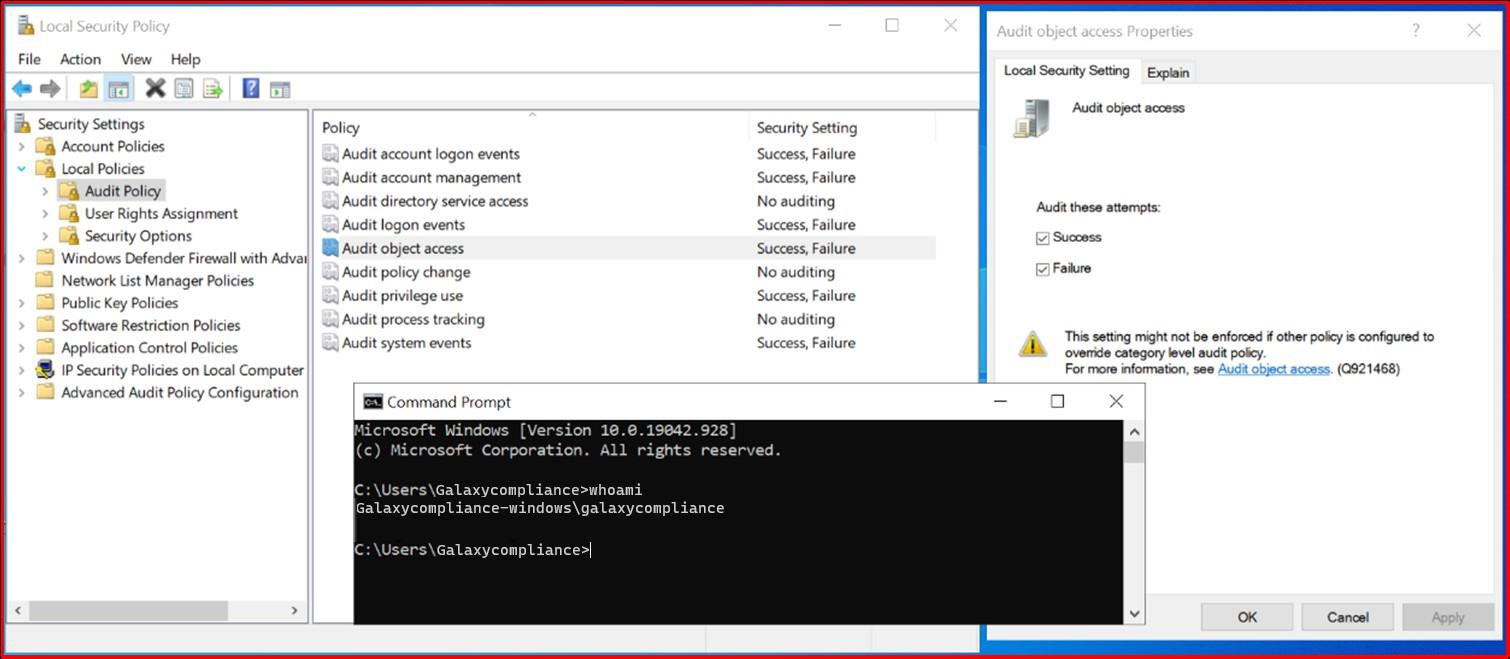
На следующем снимке экрана показано событие, в котором пользователь очистил журнал событий с образца устройства "Galaxy-Compliance".
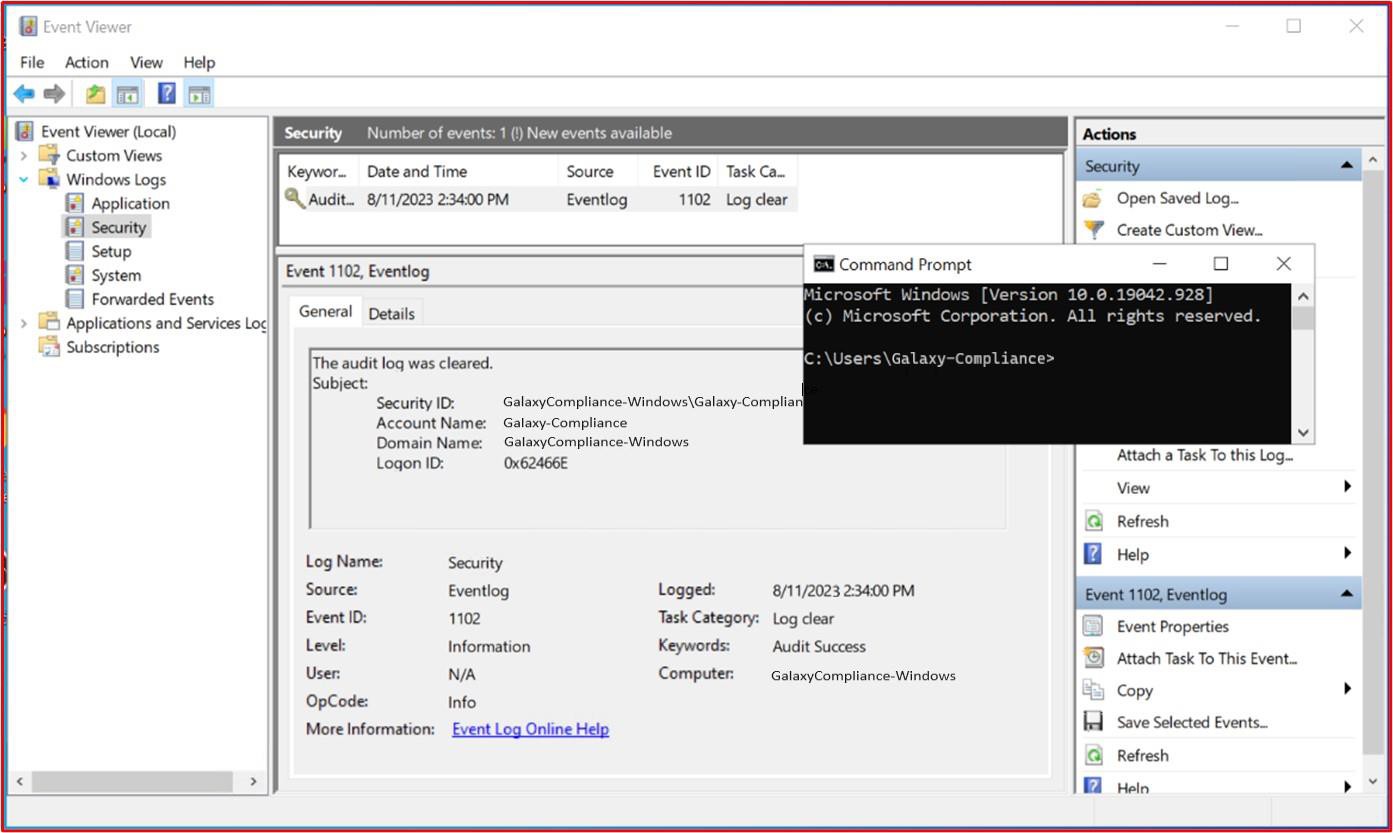
Обратите внимание: предыдущие примеры не являются полноэкранными снимками экрана, вам потребуется отправить полноэкранные снимки экрана с любым URL-адресом, вошедшего в систему пользователя и меткой времени и даты для проверки доказательств. Если вы являетесь пользователем Linux, это можно сделать с помощью командной строки.
Элемент управления No 18
Предоставьте подтверждение того, что данные журнала событий безопасности сразу же доступны как минимум за 30 дней, при этом журналы событий безопасности хранятся в течение 90 дней.
Намерение: ведение журнала событий
Иногда между компрометацией или событием безопасности и организацией, идентифицируемой его организацией, существует разрыв во времени. Цель этого контроля заключается в том, чтобы организация получила доступ к историческим данным о событиях, чтобы помочь с реагированием на инциденты и любой работой судебно-медицинской экспертизы, которая может потребоваться. Обеспечение того, чтобы организация хранила не менее 30 дней данных журнала событий безопасности, которые немедленно доступны для анализа, чтобы упростить быстрое расследование и реагирование на инциденты безопасности. Кроме того, журналы событий безопасности хранятся в общей сложности за 90 дней, чтобы обеспечить глубокий анализ.
Рекомендации: ведение журнала событий
Как правило, подтверждением является отображение параметров конфигурации решения для централизованного ведения журнала, показывающее, как долго хранятся данные. Данные журнала событий безопасности за 30 дней должны быть немедленно доступны в решении. Тем не менее, если данные архивируются, необходимо продемонстрировать доступность 90 дней. Это может быть путем отображения архивных папок с датами экспортированных данных.
Пример свидетельства: ведение журнала событий
В соответствии с предыдущим примером в элементе управления 17, где централизованная рабочая область Log Analytic используется для хранения всех журналов, созданных облачными ресурсами, ниже можно увидеть, что журналы хранятся в отдельных таблицах для каждой категории журналов. Кроме того, интерактивное хранение для всех таблиц составляет 90 дней.
На следующем снимку экрана приведены дополнительные сведения о параметрах конфигурации для периода хранения рабочей области Log Analytic.
Пример доказательства
На следующих снимках экрана показано, что в AlienVault доступны журналы за 30 дней.
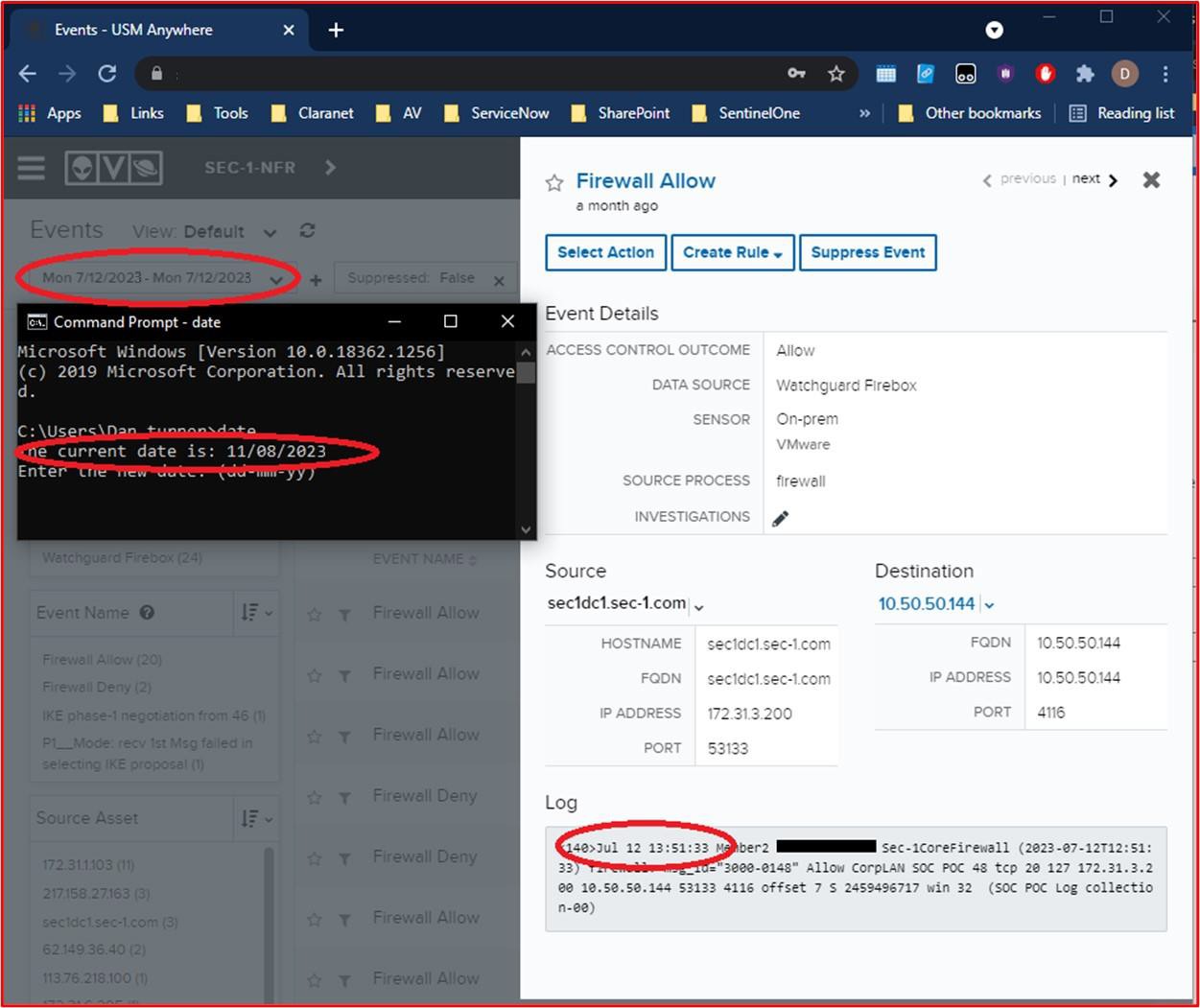
Примечание. Так как это общедоступный документ, серийный номер брандмауэра был отредактирован, однако поставщики программного обеспечения будут обязаны отправить эту информацию без исправлений, если она не содержит личные данные (PII), которые должны быть раскрыты аналитику.
На следующем снимку экрана показано, что журналы доступны, показано, как извлечь журнал за пять месяцев.
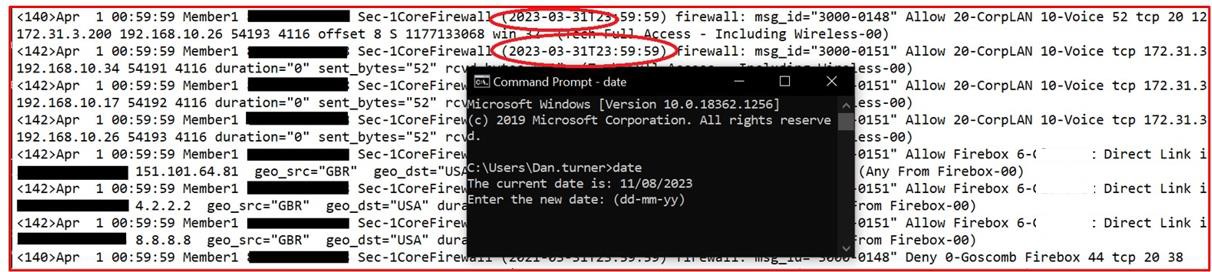
Примечание. Так как это общедоступный документ, общедоступные IP-адреса были отредактированы, однако поставщики программного обеспечения будут обязаны отправить эту информацию без каких-либо исправлений, если она не содержит личные данные (PII), которые они должны сначала обсудить со своим аналитиком.
Примечание. Предыдущие примеры не являются полноэкранными снимками экрана. Вам потребуется отправить полноэкранные снимки экрана с любым URL-адресом, вошедшего в систему пользователя, а также меткой времени и даты для проверки доказательств. Если вы являетесь пользователем Linux, это можно сделать с помощью командной строки.
Пример доказательства
На следующем снимке экрана показано, что события журнала хранятся в течение 30 дней в реальном времени и 90 дней в холодном хранилище в Azure.
Обратите внимание: ожидается, что помимо параметров конфигурации, демонстрирующих настроенное хранение, будет предоставлен пример журналов за 90-дневный период, чтобы проверить, хранятся ли журналы в течение 90 дней.
Обратите внимание: эти примеры не являются полноэкранными снимками экрана. Вам потребуется отправить полноэкранные снимки экрана с любым URL-адресом, вошедшего в систему пользователя, а также меткой времени и даты для проверки доказательств. Если вы являетесь пользователем Linux, это можно сделать с помощью командной строки.
Элемент управления No 19
Предоставьте доказательства того, что:
Журналы периодически проверяются, а все потенциальные события и аномалии безопасности, выявленные в процессе проверки, исследуются и устраняются.
Намерение: ведение журнала событий
Цель этого элемента управления — обеспечить проведение периодических проверок журналов. Это важно для выявления аномалий, которые не могут быть приняты скриптами или запросами оповещений, настроенными для предоставления оповещений о событиях безопасности. Кроме того, исследуются все аномалии, выявленные в ходе проверок журналов, и выполняется соответствующее исправление или действие. Обычно это включает в себя процесс рассмотрения, чтобы определить, требуются ли аномалии действия, а затем может потребоваться вызвать процесс реагирования на инциденты.
Рекомендации: ведение журнала событий
Доказательства будут предоставляться на снимках экрана, демонстрирующих, что проверки журналов проводятся. Это может быть формами, которые заполняются каждый день, или путем билета JIRA или DevOps с помощью
соответствующие комментарии, публикуемые, чтобы показать, что это выполняется. Если какие-либо аномалии помечены, это можно задокументировать в этом же запросе, чтобы продемонстрировать, что аномалии, выявленные в рамках проверки журнала, отслеживаются, а затем подробно, какие действия были выполнены после этого. Это может потребовать создания определенного билета JIRA для отслеживания всех выполняемых действий, или это может быть просто задокументировано в билете проверки журнала. Если требуется действие реагирования на инцидент, это должно быть задокументировано как часть процесса реагирования на инциденты, и должны быть предоставлены доказательства, чтобы продемонстрировать это.
Пример свидетельства: ведение журнала событий
На этом первом снимку экрана показано, где пользователь был добавлен в группу "Администраторы домена".

На следующем снимках экрана показано, где после нескольких неудачных попыток входа следует успешное имя входа, которое может подчеркнуть успешную атаку методом подбора.

На этом заключительном снимку экрана показано, где произошло изменение политики паролей, поэтому срок действия паролей учетных записей не истек.

На следующем снимку экрана показано, что запрос автоматически создается в средстве ServiceNow SOC, активируя предыдущее правило выше.
Обратите внимание: эти примеры не являются полноэкранными снимками экрана. Вам потребуется отправить полноэкранные снимки экрана с любым URL-адресом, вошедшего в систему пользователя, а также меткой времени и даты для проверки доказательств. Если вы являетесь пользователем Linux, это можно сделать с помощью командной строки.
Элемент управления No 20
Предоставьте доказательства того, что:
Правила генерации оповещений настраиваются таким образом, что оповещения активируются для исследования следующих событий безопасности, если применимо:
Создание и изменение привилегированных учетных записей.
Действия или операции с привилегированным или высоким риском.
События вредоносных программ.
Изменение журнала событий.
События IDPS/WAF (если настроено).
Намерение: оповещения
Это некоторые типы событий безопасности, которые могут подчеркнуть, что произошло событие безопасности, которое может указывать на нарушение среды и (или) утечку данных.
Эта подсеть заключается в том, чтобы убедиться, что правила генерации оповещений специально настроены для запуска исследований при создании или изменении привилегированных учетных записей. В случае создания или изменения привилегированной учетной записи должны создаваться журналы, а оповещения должны активироваться при создании новой привилегированной учетной записи или изменении существующих разрешений привилегированной учетной записи. Это помогает отслеживать любые несанкционированные или подозрительные действия.
Эта подмножная точка предназначена для установки правил генерации оповещений для уведомления соответствующего персонала о выполнении привилегированных действий или операций с высоким риском. Для действий или операций с привилегированным или высоким риском необходимо настроить оповещения, чтобы уведомлять соответствующего персонала о начале таких действий. Это может включать изменения в правилах брандмауэра, передачу данных или доступ к конфиденциальным файлам.
Цель этой подмыщения заключается в том, чтобы наказать конфигурацию правил генерации оповещений, которые активируются событиями, связанными с вредоносными программами. События вредоносных программ должны не только регистрироваться в журнале, но и запускать немедленное оповещение для исследования. Эти оповещения должны быть разработаны для включения таких сведений, как источник, характер вредоносных программ и затронутые системные компоненты, чтобы ускорить время реагирования.
Эта вложенная точка предназначена для обеспечения того, чтобы любое незаконное изменение журналов событий вызывало немедленное оповещение для исследования. Что касается изменения журналов событий, система должна быть настроена для активации оповещений при обнаружении несанкционированного доступа к журналам или изменения журналов. Это обеспечивает целостность журналов событий, которые имеют решающее значение для судебно-медицинского анализа и аудита соответствия требованиям.
Эта подмножка предназначена для обеспечения того, чтобы при настройке систем обнаружения и предотвращения вторжений (IDPS) или брандмауэров веб-приложений (WAF) они были настроены для активации оповещений для исследования. Если настроены системы обнаружения и предотвращения вторжений (IDPS) или брандмауэры веб-приложений (WAF), они также должны быть настроены для активации оповещений о подозрительных действиях, таких как повторяющиеся сбои входа, попытки внедрения кода SQL или шаблоны, предполагающие атаку типа "отказ в обслуживании".
Рекомендации: оповещения
Доказательства должны быть предоставлены с помощью снимков экрана конфигурации оповещений И подтверждения полученных оповещений. На снимках экрана конфигурации должна отображаться логика, которая активирует оповещения, и способ их отправки. Оповещения можно отправлять через SMS, электронную почту, каналы Teams, каналы Slack и т. д....
Пример доказательства: оповещения
На следующем снимке экрана показан пример настройки оповещений в Azure. На первом снимку экрана можно увидеть, что при остановке и освобождении виртуальной машины сработало оповещение. Обратите внимание, что это пример оповещений, настроенных в Azure, и ожидается, что будут предоставлены доказательства того, что оповещения создаются для всех событий, указанных в описании элемента управления.
На следующем снимку экрана показаны оповещения, настроенные для любых административных действий, выполняемых на уровне Службы приложений Azure, а также на уровне группы ресурсов Azure.
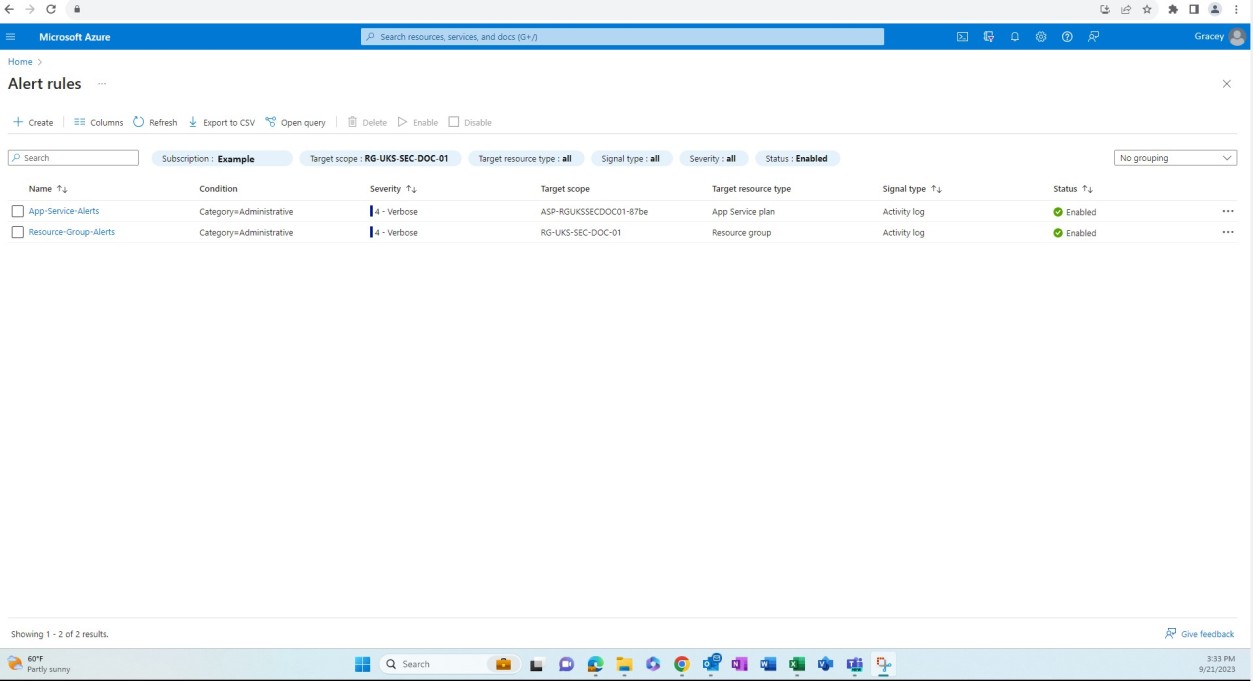
Пример доказательства
Компания Contoso использует сторонний центр управления безопасностью (SOC), предоставляемый Contoso Security. В примере показано, что оповещение в AlienVault, используемое SOC, настроено для отправки оповещений участнику команды SOC Салли Голд в Contoso Security.
На следующем снимку экрана показано, как Салли получает оповещение.
Обратите внимание: эти примеры не являются полноэкранными снимками экрана. Вам потребуется отправить полноэкранные снимки экрана с любым URL-адресом, вошедшего в систему пользователя, а также меткой времени и даты для проверки доказательств. Если вы являетесь пользователем Linux, это можно сделать с помощью командной строки.
Управление рисками информационной безопасности
Управление рисками информационной безопасности — это важная деятельность, которую все организации должны выполнять по крайней мере ежегодно. Организации должны понимать свои риски, чтобы эффективно устранять угрозы. Без эффективного управления рисками организации могут внедрять ресурсы безопасности в областях, которые они считают важными, когда другие угрозы могут быть более вероятными. Эффективное управление рисками поможет организациям сосредоточиться на рисках, представляющих наибольшую угрозу для бизнеса. Это должно осуществляться ежегодно по мере того, как ландшафт безопасности постоянно меняется, и поэтому угрозы и риски могут изменяться сверхурочными. Например, во время недавней блокировки COVID-19 произошел большой рост фишинговых атак с переходом на удаленную работу.
Элемент управления No 21
Предоставьте доказательства того, что утвержденная официальная политика или процесс управления рисками информационной безопасности задокументированы и установлены.
Намерение: управление рисками
Надежный процесс управления рисками информационной безопасности имеет важное значение, чтобы помочь организациям эффективно управлять рисками. Это поможет организациям спланировать эффективные меры по устранению угроз для среды. Цель этого контроля заключается в том, чтобы подтвердить, что организация имеет официально утвержденную политику или процесс управления рисками информационной безопасности, который полностью задокументирован. В политике должно быть указано, как организация определяет, оценивает и управляет рисками информационной безопасности. Она должна включать роли и обязанности, методологии оценки рисков, критерии принятия рисков и процедуры для устранения рисков.
Примечание. Оценка рисков должна быть сосредоточена на рисках информационной безопасности, а не только на общих бизнес-рисках.
Рекомендации: управление рисками
Необходимо предоставить официально задокументированную процедуру управления оценкой рисков.
Пример доказательства: управление рисками
Ниже приведен снимок экрана, на котором показана часть процесса оценки рисков компании Contoso.
Примечание. Ожидается, что поставщики программного обеспечения будут совместно использовать фактическую документацию по политике или процедуре поддержки, а не просто предоставить снимок экрана.
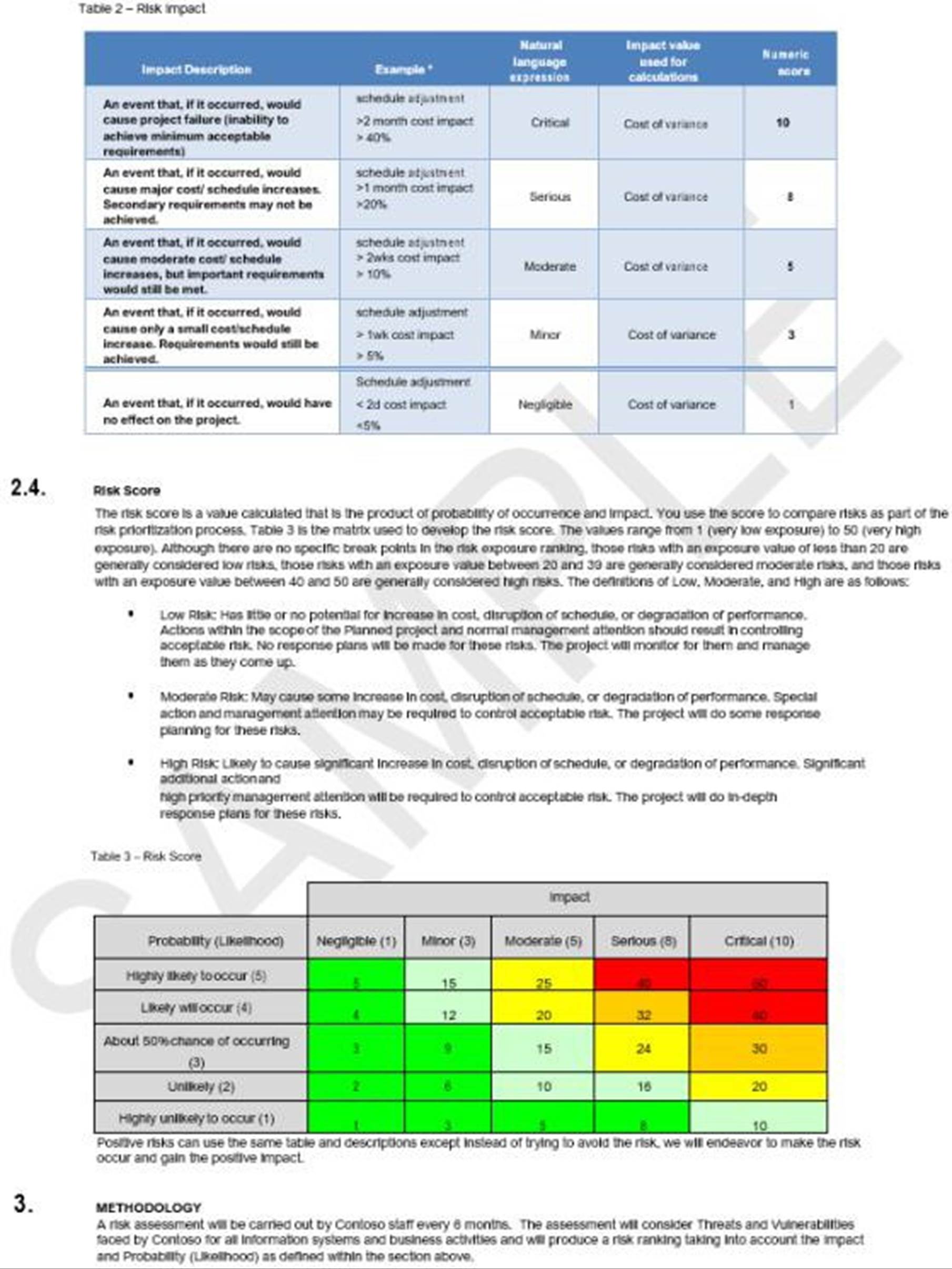
Примечание. Ожидается, что поставщики программного обеспечения будут совместно использовать фактическую документацию по политике или процедуре поддержки, а не просто предоставить снимок экрана.
Элемент управления No 22
Предоставьте доказательства того, что:
- Официальная оценка рисков информационной безопасности в масштабах всей компании проводится не реже одного раза в год.
ИЛИ для целевого анализа рисков:
Задокументирован и выполняется целевой анализ рисков:
Как минимум каждые 12 месяцев для каждого случая, когда нет традиционного контроля или лучшей практики в отрасли.
Если конструктор или технологическое ограничение создает риск внедрения уязвимости в среде или ставит пользователей и данные под угрозу.
При подозрении или подтверждении компромисса.
Намерение: ежегодная оценка
Угрозы безопасности постоянно меняются в зависимости от изменений в среде, изменений в предлагаемых службах, внешних влияний, эволюции ландшафта угроз безопасности и т. д. Организации должны проходить процесс оценки рисков по крайней мере раз в год. Рекомендуется также проводить этот процесс при значительных изменениях, так как угрозы могут измениться.
Цель этого контроля заключается в том, чтобы убедиться, что организация проводит официальную оценку рисков информационной безопасности компании не реже одного раза в год и (или) целевой анализ рисков во время изменений системы или инцидентов, обнаружения уязвимостей, изменения инфраструктуры и т. д. Эта оценка должна охватывать все организационные ресурсы, процессы и данные, направленные на выявление и оценку потенциальных уязвимостей и угроз.
Для целевого анализа рисков этот элемент управления подчеркивает необходимость выполнения анализа рисков в конкретных сценариях. Он ориентирован на более узкую область, например ресурс, угрозу, систему или элемент управления. Цель этого заключается в обеспечении непрерывной оценки и выявления организациями рисков, связанных с отклонениями от рекомендаций по обеспечению безопасности или ограничениями проектирования системы. Выполняя целевые анализы рисков по крайней мере ежегодно, когда отсутствуют элементы управления, когда технологические ограничения создают уязвимости, а также в ответ на предполагаемые или подтвержденные инциденты безопасности, организация может выявить слабые места и риски. Это позволяет принимать обоснованные решения, основанные на риске, о том, чтобы приоритезировать усилия по исправлению и реализовать компенсирующие средства контроля, чтобы свести к минимуму вероятность и последствия эксплуатации. Цель состоит в том, чтобы обеспечить постоянную должную осмотрительность, рекомендации и доказательства того, что известные пробелы устраняются с учетом рисков, а не игнорируются на неопределенный срок. Выполнение этих целевых оценок рисков свидетельствует о приверженности организации активному повышению уровня безопасности с течением времени.
Рекомендации: ежегодная оценка
Доказательства могут быть в виде отслеживания версий или датированные доказательства. Необходимо предоставить свидетельство, показывающее выходные данные оценки рисков информационной безопасности и даты NOT в самом процессе оценки рисков информационной безопасности.
Пример доказательства: ежегодная оценка
На следующем снимок экрана показано, как планируется собрание по оценке рисков каждые шесть месяцев.
На следующих двух снимках экрана показан пример минут собрания из двух оценок риска. Ожидается, что будет предоставлен отчет/протокол собрания или отчет об оценке риска.

Примечание. На этом снимку экрана показан документ политики или процесса. Ожидается, что поставщики программного обеспечения будут совместно использовать фактическую документацию по политике или процедуре, а не просто предоставить снимок экрана.
Примечание. На этом снимку экрана показан документ политики или процесса. Ожидается, что поставщики программного обеспечения будут делиться фактической вспомогательной документацией по политике или процедуре, а не просто предоставить снимок экрана.
Элемент управления No 23
Убедитесь, что оценка рисков информационной безопасности включает в себя:
Затронутый системный компонент или ресурс.
Угрозы и уязвимости, или эквивалент.
Матрицы влияния и вероятности или эквивалентные.
Создание регистра рисков или плана лечения рисков.
Намерение: оценка рисков
Цель заключается в том, что оценка рисков включает в себя системные компоненты и ресурсы, так как она помогает определить наиболее важные ИТ-ресурсы и их ценность. Выявляя и анализируя потенциальные угрозы для бизнеса, организация может в первую очередь сосредоточиться на рисках, которые имеют наибольшее потенциальное влияние и наибольшую вероятность. Понимание потенциального влияния на ИТ-инфраструктуру и связанных с ней затрат может помочь руководству принимать обоснованные решения о бюджете, политиках, процедурах и т. д. Список системных компонентов или ресурсов, которые могут быть включены в оценку рисков безопасности:
Серверы
Databases
Приложения
Сети
Устройства хранения данных
Люди
Для эффективного управления рисками информационной безопасности организации должны проводить оценку рисков, связанных с угрозами для среды и данных, а также с возможными уязвимостями, которые могут присутствовать. Это поможет организациям выявить множество угроз и уязвимостей, которые могут представлять значительный риск. Оценки рисков должны документировать оценки влияния и вероятности, которые можно использовать для определения значения риска. Это можно использовать для определения приоритетов лечения рисков и снижения общей стоимости риска. Оценки рисков должны быть надлежащим образом отслеживаться, чтобы обеспечить запись одного из четырех применяемых методов лечения риска. Эти методы лечения риска:
Избегайте и завершайте работу. Компания может определить, что стоимость работы с риском больше, чем доход, полученный от службы. Таким образом, компания может прекратить выполнение службы.
Передача и совместное использование. Компания может передать риск третьей стороне, переместив обработку в стороннюю сторону.
Принять, разрешить и сохранить. Компания может решить, что риск является приемлемым. Это во многом зависит от аппетита бизнеса к риску и может отличаться в зависимости от организации.
Обрабатывать, устранять и изменять. Компания решает реализовать средства управления устранением рисков, чтобы снизить риск до приемлемого уровня.
Рекомендации: оценка рисков
Доказательства должны предоставляться не только посредством уже предоставленного процесса оценки рисков информационной безопасности, но и выходных данных оценки рисков (посредством регистра рисков или плана обработки рисков), чтобы продемонстрировать, что процесс оценки рисков выполняется должным образом. Регистр рисков должен включать риски, уязвимости, влияние и оценки вероятности.
Пример доказательства: оценка рисков
На следующем снимку экрана показан регистр рисков, в котором показаны угрозы и уязвимости. В нем также показано, что влияние и вероятность включены.
Примечание. Вместо снимка экрана необходимо предоставить полную документацию по оценке рисков. На следующем снимку экрана показан план лечения рисков.
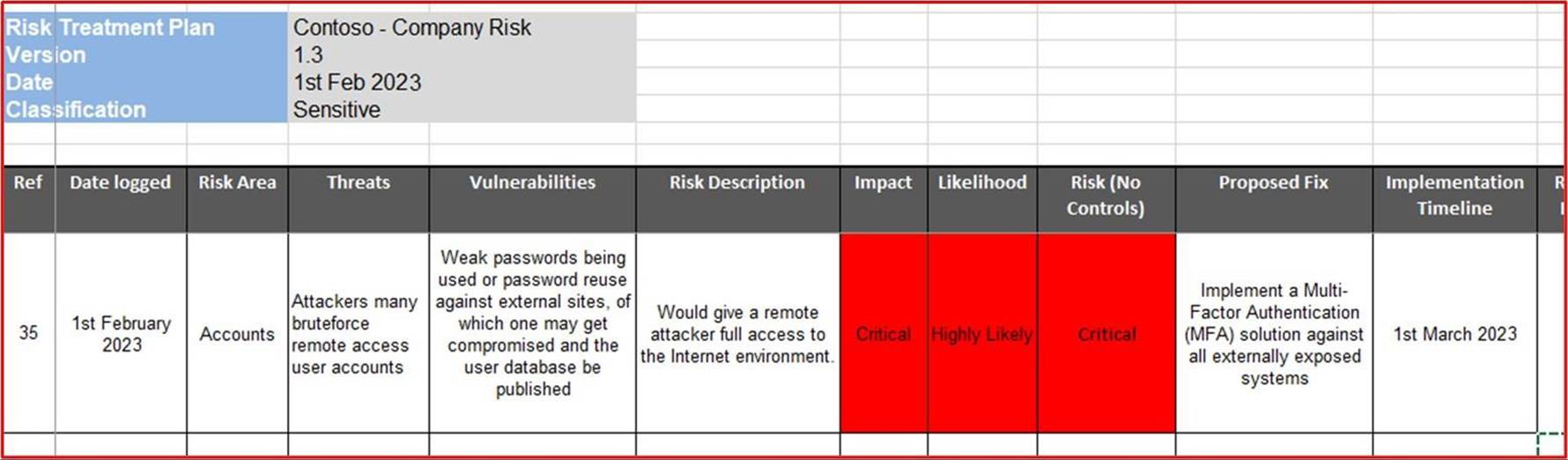
Элемент управления No 24
Укажите доказательства того, что:
У вас (ISV) есть процессы управления рисками, которые оценивают и управляют рисками, связанными с поставщиками и бизнес-партнерами.
Вы (ISV) можете выявлять и оценивать изменения и риски, которые могут повлиять на систему внутренних средств контроля.
Намерение: поставщики и партнеры
Управление рисками поставщиков — это практика оценки рисков бизнес-партнеров, поставщиков или сторонних поставщиков как до установления деловых отношений, так и на протяжении всего периода их существования. Управляя рисками поставщиков, организации могут избежать нарушений непрерывности бизнес-процессов, предотвратить финансовые последствия, защитить свою репутацию, соблюдать правила, а также выявлять и минимизировать риски, связанные с сотрудничеством с поставщиком. Для эффективного управления рисками поставщиков важно иметь процессы, которые включают оценку надлежащей осмотрительности, договорные обязательства, связанные с безопасностью, и постоянный мониторинг соответствия поставщиков.
Рекомендации: поставщики и партнеры
Для демонстрации процесса оценки рисков поставщика можно предоставить доказательства, например документацию по закупкам и проверке, контрольные списки и анкеты для адаптации новых поставщиков и подрядчиков, выполненные оценки, проверки соответствия требованиям и т. д.
Пример доказательства: поставщики и партнеры
На следующем снимке экрана показано, что процесс подключения и проверки поставщика поддерживается в Confluence как задача JIRA. Для каждого нового поставщика выполняется первоначальная оценка риска для проверки состояния соответствия требованиям. В процессе закупок заполняется анкета оценки рисков, а общий риск определяется на основе уровня доступа к системам и данным, предоставляемым поставщику.
На следующем снимках экрана показаны результаты оценки и общий риск, который был определен на основе первоначальной проверки.
Намерение: внутренние элементы управления
Основное внимание в этой подразделе уделяется распознаванию и оценке изменений и рисков, которые могут повлиять на системы внутреннего контроля организации, чтобы гарантировать, что внутренние средства контроля остаются эффективными с течением времени. По мере изменения бизнес-операций внутренние средства контроля могут перестать действовать. Риски со временем развиваются, и могут возникать новые риски, которые ранее не рассматривались. Выявляя и оценивая эти риски, вы можете убедиться, что внутренние средства контроля предназначены для их устранения. Это помогает предотвратить мошенничество и ошибки, обеспечить непрерывность бизнес-процессов и обеспечить соответствие нормативным требованиям.
Рекомендации: внутренние средства контроля
Можно предоставить доказательства, такие как просмотр протоколов собрания и отчетов, которые могут продемонстрировать, что процесс оценки рисков поставщика обновляется в определенный период, чтобы гарантировать, что потенциальные изменения поставщика учитываются и оцениваются.
Пример доказательства: внутренние элементы управления
На следующих снимках экрана показано, что выполняется трехмесячная проверка утвержденного поставщика и списка подрядчиков, чтобы убедиться, что их стандарты соответствия и уровень соответствия соответствуют первоначальной оценке во время адаптации.
На первом снимке экрана показаны установленные рекомендации по выполнению оценки и анкета о рисках.
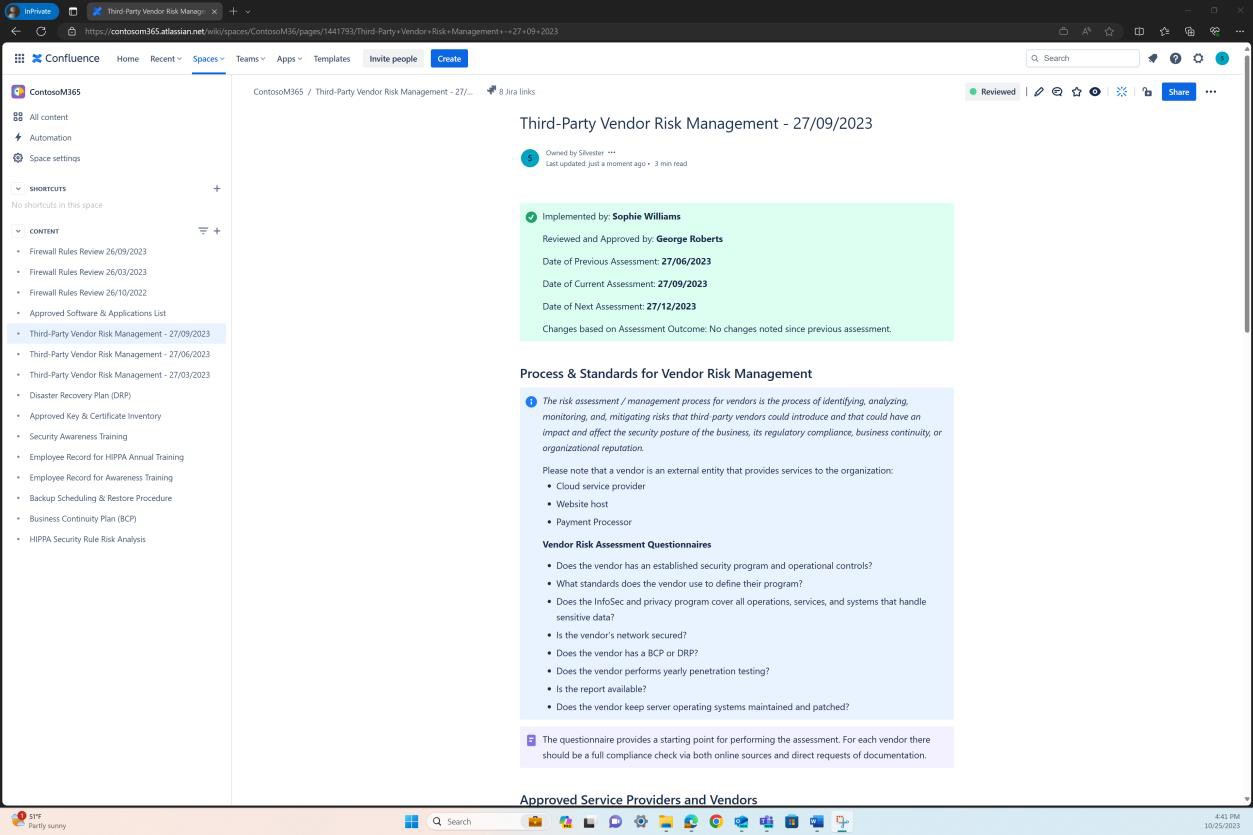
На следующих снимках экрана показан фактический список, утвержденный поставщиком, уровень соответствия требованиям, выполненная оценка, оценщик, утверждающий и т. д. Обратите внимание, что это просто пример рудиментной оценки рисков поставщика, предназначенной для предоставления базового сценария для понимания требования к контролю и отображения формата ожидаемых доказательств. В качестве независимого поставщика программного обеспечения вы должны предоставить собственную оценку рисков поставщика в соответствии с вашей организацией.
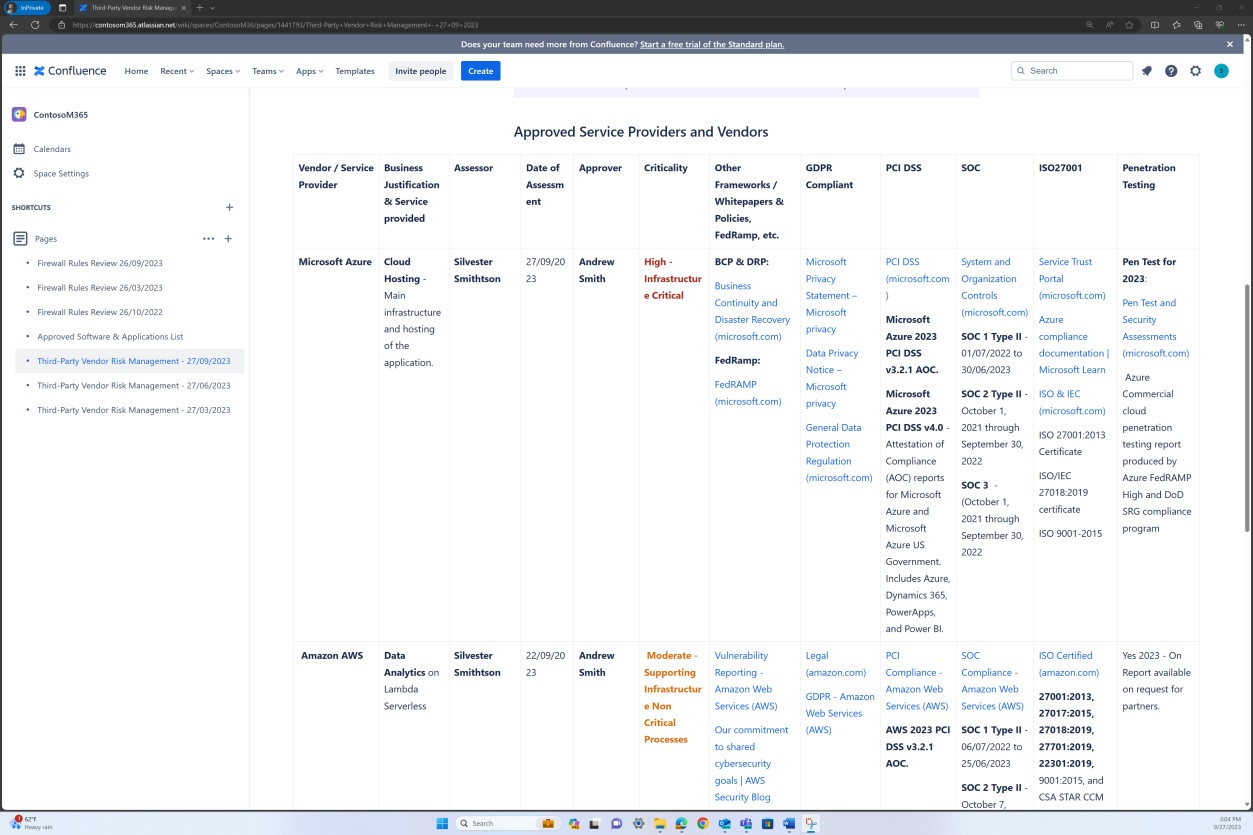
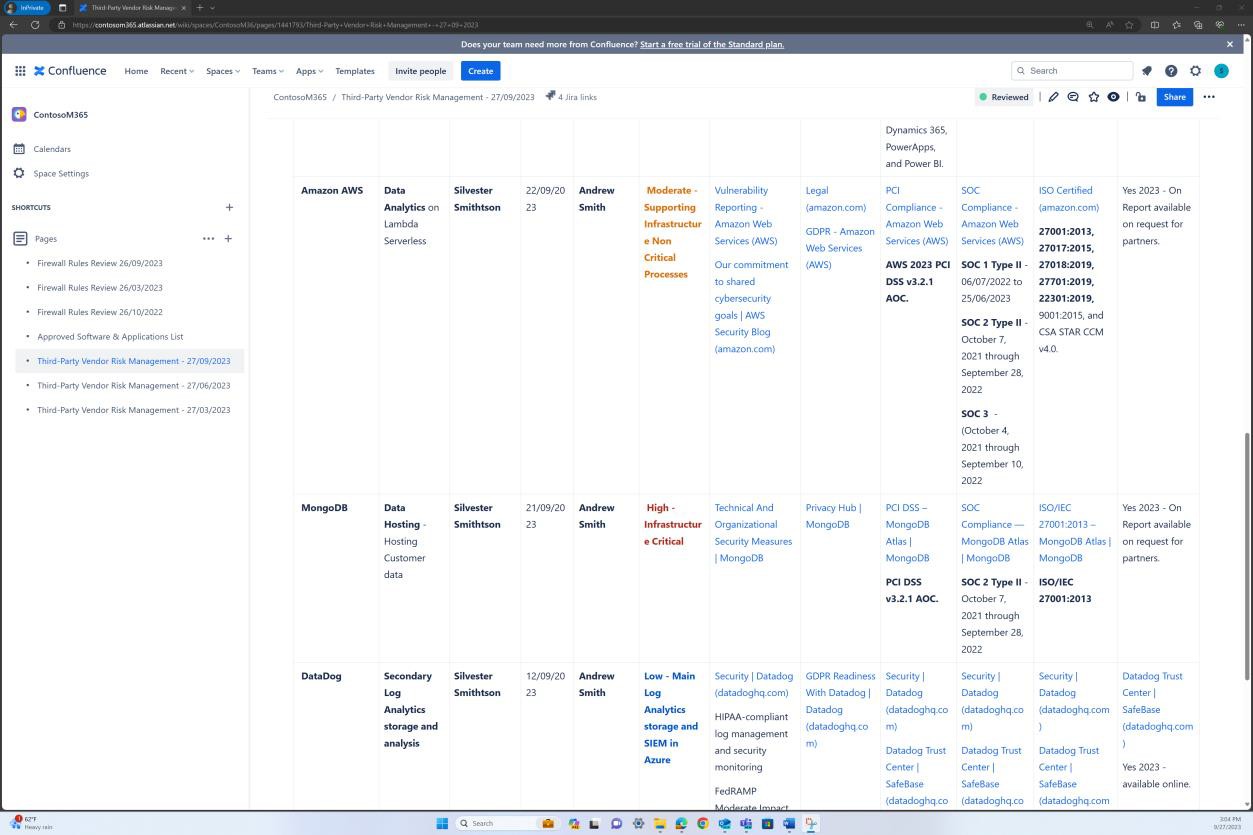
Реагирование на инциденты безопасности
Реагирование на инциденты безопасности важно для всех организаций, так как это может сократить время, затрачиваемое организацией на инцидент безопасности, и ограничить уровень подверженности организации краже данных. Разработав комплексный и подробный план реагирования на инциденты безопасности, это воздействие можно сократить с момента идентификации до времени сдерживания.
В докладе IBM, озаглавленном "Стоимость отчета о нарушении данных за 2020 год", подчеркивается, что в среднем время, затраченное на сдерживание нарушения, составило 73 дня. Кроме того, в том же докладе определяется самая большая экономия затрат для организации, которая пострадала от нарушения, была готовность к реагированию на инциденты, обеспечивая в среднем
Экономия затрат на 2 000 000 долл. США. Организации должны следовать рекомендациям по обеспечению соответствия безопасности с помощью отраслевых стандартных платформ, таких как ISO 27001, NIST, SOC 2, PCI DSS и т. д.
Элемент управления No 25
Укажите утвержденный план или процедуру реагирования на инциденты безопасности (IRP), в которой описывается, как ваша организация реагирует на инциденты, показывается, как она поддерживается, и что она включает в себя:
сведения о группе реагирования на инциденты, включая контактные данные,
внутренний план коммуникации во время инцидента и внешней связи с соответствующими сторонами, такими как ключевые заинтересованные лица, платежные бренды и покупатели, регулирующие органы (например, 72 часа для GDPR), надзорные органы, директора, клиенты;
шаги для таких действий, как классификация инцидентов, сдерживание, устранение рисков, восстановление и возвращение к обычным бизнес-операциям в зависимости от типа инцидента.
Намерение: План реагирования Incedent (IRP)
Цель этого элемента управления — обеспечить наличие официально задокументированного плана реагирования на инциденты (IRP), который включает в себя назначенную группу реагирования на инциденты с четко задокументированные роли, обязанности и контактные данные. IRP должен обеспечить структурированный подход к управлению инцидентами безопасности от обнаружения до разрешения, включая классификацию характера инцидента, сдерживание непосредственного воздействия, устранение рисков, восстановление после инцидента и восстановление обычных бизнес-операций. Каждый шаг должен быть четко определен, с четкими протоколами, чтобы обеспечить соответствие предпринятых действий стратегиям управления рисками организации и обязательствам по соответствию.
Подробная спецификация группы реагирования на инциденты в IRP гарантирует, что каждый член команды понимает свою роль в управлении инцидентом, обеспечивая скоординированное и эффективное реагирование. Имея IRP, организация может более эффективно управлять реагированием на инциденты безопасности, что в конечном итоге может ограничить уязвимость организации к потере данных и снизить затраты на компрометацию.
У организаций могут быть обязательства по уведомлению о нарушениях, основанные на стране или странах, в которых они работают (например, Общий регламент по защите данных GDPR) или на основе предлагаемых функциональных возможностей (например, PCI DSS, если платежные данные обрабатываются). Сбой своевременного уведомления может иметь серьезные последствия; таким образом, чтобы обеспечить выполнение обязательств по уведомлению, планы реагирования на инциденты должны включать процесс коммуникации, включая общение со всеми заинтересованными лицами, процессы коммуникации со средствами массовой информации и тех, кто может и не может говорить со средствами массовой информации.
Рекомендации: внутренние средства контроля
Укажите полную версию плана или процедуры реагирования на инциденты. План реагирования на инциденты должен включать раздел, охватывающий процесс обработки инцидентов от идентификации до разрешения, а также документированные процессы коммуникации.
Пример доказательства: внутренние элементы управления
На следующем снимку экрана показано начало плана реагирования на инциденты Компании Contoso.
Примечание. В рамках отправки доказательств необходимо предоставить весь план реагирования на инциденты.

Пример доказательства: внутренние элементы управления
На следующем снимку экрана показана выписка из плана реагирования на инциденты, показывающая процесс взаимодействия.
Элемент управления No 26
Предоставьте доказательства, которые свидетельствуют о том, что:
Все члены группы реагирования на инциденты прошли ежегодное обучение, позволяющее им реагировать на инциденты.
Намерение: обучение
Чем больше времени требуется организации, чтобы обеспечить компрометацию, тем выше риск кражи данных, что может привести к большему объему эксфильтрованных данных и тем выше общая стоимость компрометации. Важно, чтобы группы реагирования на инциденты организации были подготовлены для своевременного реагирования на инциденты безопасности. Выполняя регулярные учебные курсы и проводя настольные учения, команда готова быстро и эффективно обрабатывать инциденты безопасности. Этот учебный курс должен охватывать различные аспекты, такие как выявление потенциальных угроз, первоначальные действия по реагированию, процедуры эскалации и долгосрочные стратегии их устранения.
Рекомендация заключается в проведении как внутреннего обучения реагирования на инциденты для группы реагирования на инциденты, так и для проведения регулярных настольных упражнений, которые должны быть связаны с риском информационной безопасности.
оценка для выявления наиболее вероятных инцидентов безопасности. Упражнение на столе должно имитировать реальные сценарии, чтобы проверить и отточить способности команды реагировать под давлением. Таким образом, организация может убедиться, что ее сотрудники знают, как правильно справляться с нарушением безопасности или кибератакой. И команда будет знать, какие меры следует предпринять для сдерживания и расследования наиболее вероятных инцидентов безопасности, быстро.
Рекомендации: обучение
Должны быть предоставлены доказательства, которые свидетельствуют о том, что обучение было проведено путем обмена учебным материалом и записей, показывающих, кто присутствовал (которые должны включать в себя все группы реагирования на инциденты). Кроме того, или также, записи, показывающие, что упражнение на столе было выполнено. Все это должно быть завершено в течение 12 месяцев с момента представления доказательств.
Пример доказательства: обучение
Компания Contoso провела табличное упражнение по реагированию на инциденты с помощью внешней компании по обеспечению безопасности. Ниже приведен пример отчета, созданного в рамках консультационной службы.

Примечание. Необходимо предоставить общий доступ к полному отчету. Это упражнение также может выполняться внутри организации, так как не существует требований к Microsoft 365, которые должны выполняться сторонней компанией.
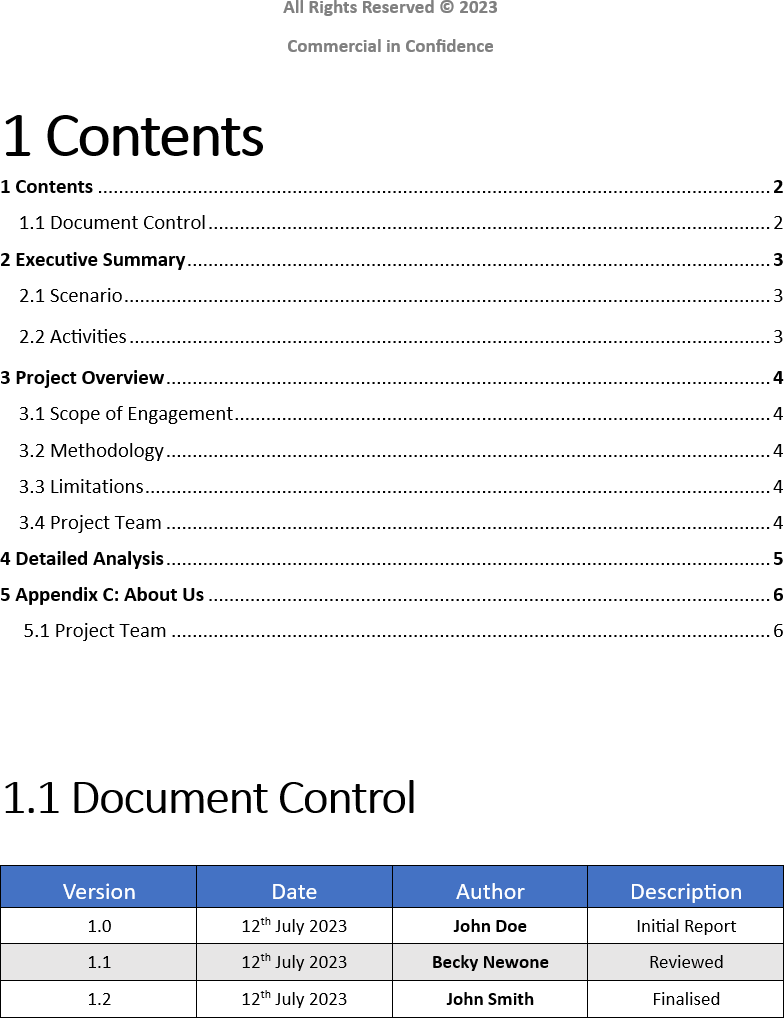
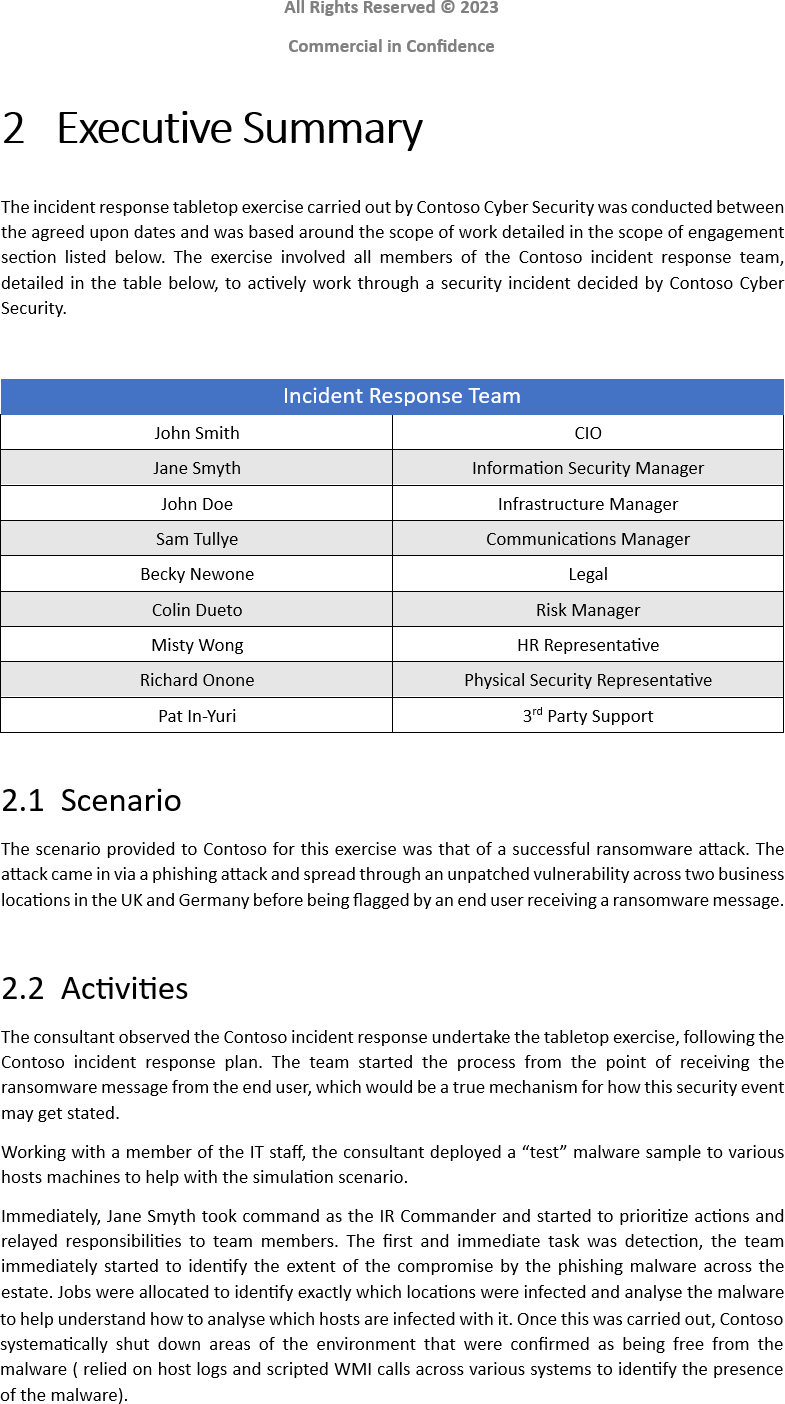
Примечание. Необходимо предоставить общий доступ к полному отчету. Это упражнение также может выполняться внутри организации, так как не существует требований Microsoft 365 для выполнения этой инструкции сторонней компанией.
Элемент управления No 27
Укажите доказательства того, что:
Стратегия реагирования на инциденты и вспомогательная документация проверяются и обновляются на основе следующих:
уроки, извлеченные из упражнения на столе
уроки, извлеченные из реагирования на инцидент
Организационные изменения
Намерение: проверки планов
Со временем план реагирования на инциденты должен развиваться на основе организационных изменений или на основе уроков, извлеченных при принятии плана. Изменения в операционной среде могут потребовать внесения изменений в план реагирования на инциденты, так как угрозы могут измениться или могут измениться нормативные требования. Кроме того, по мере того как выполняются настольные упражнения и фактические реагирования на инциденты безопасности, это часто позволяет определить области плана, которые можно улучшить. Это необходимо встроить в план, и цель этого элемента управления заключается в том, чтобы обеспечить включение этого процесса. Цель этого контроля заключается в том, чтобы поручить обзор и обновление стратегии реагирования на инциденты организации и вспомогательной документации на основе трех отдельных триггеров:
После выполнения имитации упражнений для проверки эффективности стратегии реагирования на инциденты все выявленные пробелы или области для улучшения должны быть немедленно включены в существующий план реагирования на инциденты.
Фактический инцидент предоставляет бесценное представление о сильных и слабых сторонах текущей стратегии реагирования. В случае возникновения инцидента следует провести проверку после инцидента, чтобы извлечь эти уроки, которые затем следует использовать для обновления стратегии и процедур реагирования.
Любые существенные изменения в организации, такие как слияния, приобретения или изменения в ключевых сотрудниках, должны инициировать пересмотр стратегии реагирования на инциденты. Эти организационные изменения могут привести к новым рискам или изменить существующие, и план реагирования на инциденты должен быть обновлен соответствующим образом, чтобы оставаться в силе.
Рекомендации: проверки планов
Это часто подтверждается проверкой результатов инцидентов безопасности или настольными упражнениями, в которых были выявлены извлеченные уроки и были обновлены план реагирования на инциденты. План должен поддерживать журнал изменений, который также должен ссылаться на изменения, которые были реализованы на основе извлеченных уроков или организационных изменений.
Пример доказательства: проверки планов
Следующие снимки экрана приведены из предоставленного плана реагирования на инциденты, который включает раздел об обновлении на основе извлеченных уроков и (или) изменений в организации.



Примечание. Эти примеры не являются полноэкранными снимками экрана. Вам потребуется отправить полноэкранные снимки экрана с любым URL-адресом, вошедшего в систему пользователя, а также меткой времени и даты для проверки доказательств. Если вы являетесь пользователем Linux, это можно сделать с помощью командной строки.
План непрерывности бизнес-процессов и план аварийного восстановления
Планирование непрерывности бизнес-процессов и планирование аварийного восстановления — это два важных компонента стратегии управления рисками организации. Планирование непрерывности бизнес-процессов — это процесс создания плана для обеспечения того, чтобы основные бизнес-функции могли продолжать работать во время и после аварии, в то время как планирование аварийного восстановления — это процесс создания плана восстановления после аварии и восстановления нормальных бизнес-операций как можно быстрее. Оба плана дополняют друг друга. Вы должны иметь оба варианта, чтобы противостоять операционным проблемам, вызванным авариями или непредвиденными перебоями. Эти планы важны, так как они помогают гарантировать, что организация может продолжать работу во время аварии, защищать свою репутацию, соблюдать юридические требования, поддерживать доверие клиентов, эффективно управлять рисками и обеспечивать безопасность сотрудников.
Элемент управления No 28
Предоставьте доказательства того, что:
Документация существует и поддерживается, которая описывает план непрерывности бизнес-процессов и включает в себя:
сведения о соответствующем персонале, включая его роли и обязанности
бизнес-функции с соответствующими требованиями и целями на случай непредвиденных обстоятельств
процедуры системного и резервного копирования данных, конфигурации, планирования и хранения
целевые показатели приоритета и временных интервалов восстановления
план на случай непредвиденных обстоятельств с подробными сведениями о действиях, шагах и процедурах, которые необходимо выполнить для возврата критически важных информационных систем, бизнес-функций и служб в работу в случае непредвиденных и незапланированных прерываний
установленный процесс, охватывающий итоговое полное восстановление системы и возвращение в исходное состояние
Намерение: план непрерывности бизнес-процессов
Цель этого элемента управления заключается в том, чтобы четко определенный список сотрудников с назначенными ролями и обязанностями включался в план непрерывности бизнес-процессов. Эти роли имеют решающее значение для эффективной активации и выполнения плана во время инцидента.
Рекомендации: план непрерывности бизнес-процессов
Укажите полную версию плана или процедуры аварийного восстановления, которая должна включать разделы, охватывающие обработанный контур в описании элемента управления. Предоставьте фактический документ PDF/WORD, если в цифровой версии, или если процесс поддерживается через онлайн-платформу, предоставьте экспорт или снимки экрана процессов.
Пример доказательства: план непрерывности бизнес-процессов
На следующих снимках экрана показан фрагмент плана непрерывности бизнес-процессов, который существует и поддерживается.
Примечание. На этом снимке экрана показаны моментальные снимки документа политики или процесса. Ожидается, что поставщики программного обеспечения будут делиться фактической вспомогательной документацией по политике или процедуре, а не просто предоставить снимок экрана.
На следующих снимках экрана показан фрагмент политики, в котором описан раздел "Ключевые сотрудники", включая соответствующую команду, контактные данные и действия, которые необходимо выполнить.
Намерение: определение приоритетов
Цель этого элемента управления — документировать и определять приоритеты бизнес-функций в соответствии с их важностью. Это должно сопровождаться описанием соответствующих требований на случай непредвиденных обстоятельств, необходимых для поддержания или быстрого восстановления каждой функции во время незапланированного прерывания.
Рекомендации: определение приоритетов
Укажите полную версию плана или процедуры аварийного восстановления, которая должна включать разделы, охватывающие обработанный контур в описании элемента управления. Предоставьте фактический документ PDF/WORD, если в цифровой версии, или если процесс поддерживается через онлайн-платформу, предоставьте экспорт или снимки экрана процессов.
Пример доказательства: определение приоритетов
На следующих снимках экрана показана выдержка плана непрерывности бизнес-процессов, схема бизнес-функций и уровня их важности, а также наличие планов на случай непредвиденных обстоятельств.
Примечание. На этом снимка экранах показан документ политики или процесса. Ожидается, что поставщики программного обеспечения будут делиться фактической вспомогательной документацией по политике или процедуре, а не просто предоставить снимок экрана.

Намерение: резервные копии
Цель этой подзапункты — поддерживать задокументированные процедуры резервного копирования основных систем и данных. В документации также должны быть указаны параметры конфигурации, а также политики планирования резервного копирования и хранения, чтобы гарантировать, что данные являются актуальными и извлекаемыми.
Рекомендации: резервные копии
Укажите полную версию плана или процедуры аварийного восстановления, которая должна включать разделы, охватывающие обработанный контур в описании элемента управления. Предоставьте фактический документ PDF/WORD, если в цифровой версии, или если процесс поддерживается через онлайн-платформу, предоставьте экспорт или снимки экрана процессов.
Пример доказательства: резервные копии
На следующих снимках экрана показано извлечение плана аварийного восстановления Компании Contoso и наличие задокументированных конфигураций резервного копирования для каждой системы. Обратите внимание, что на следующем снимке экрана также описано расписание резервного копирования, обратите внимание, что в этом примере конфигурация резервного копирования описывается как часть плана аварийного восстановления, так как планы непрерывности бизнес-процессов и аварийного восстановления работают вместе.
Примечание. На этом снимке экрана показан моментальный снимок документа политики или процедуры. Ожидается, что поставщики программного обеспечения поделиться фактической документацией по политике или процедуре, а не просто предоставить снимок экрана.
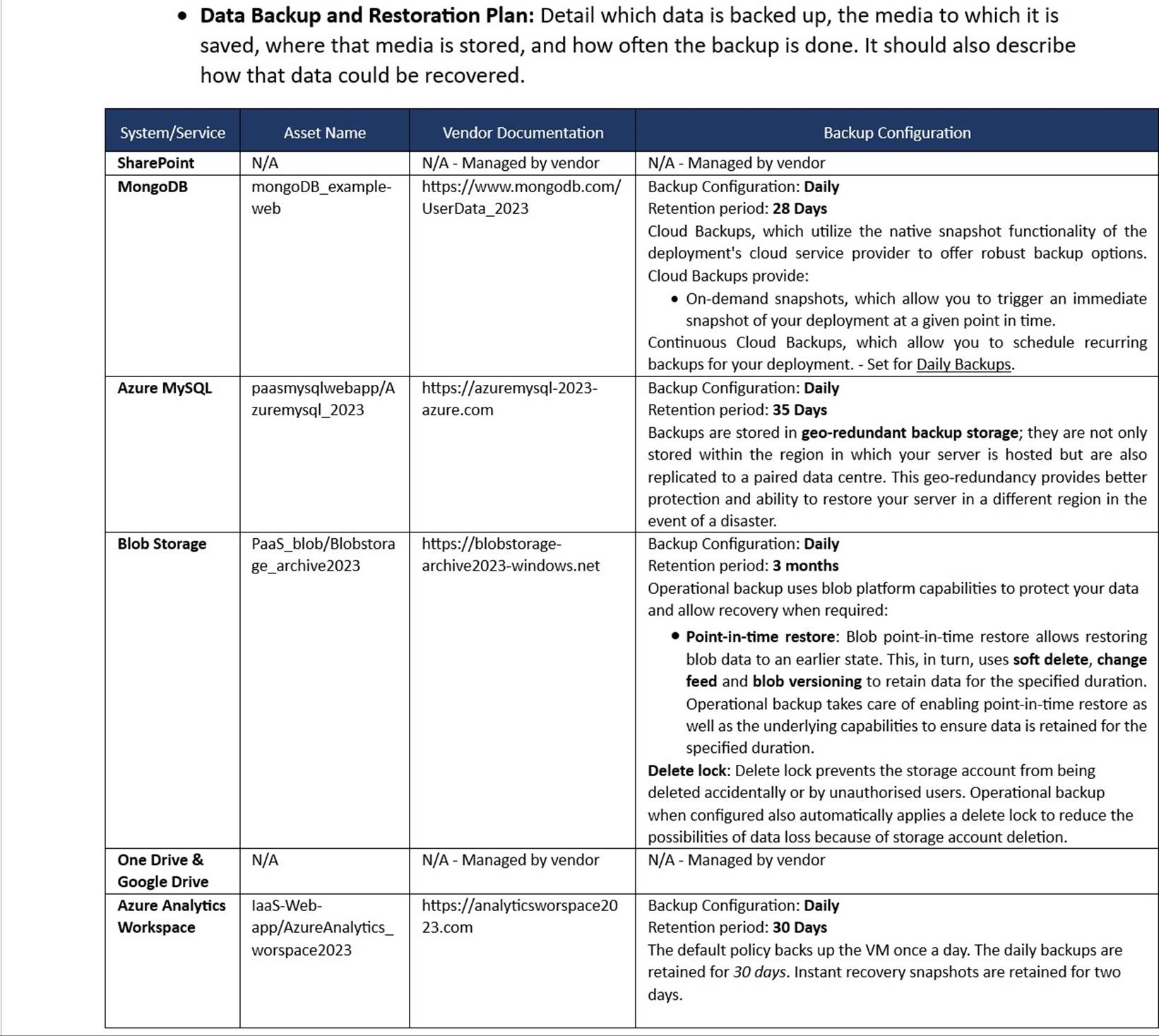
Намерение: временные шкалы
Этот элемент управления предназначен для определения приоритетных временных шкал для действий восстановления. Эти цели времени восстановления (ОРВ) должны быть согласованы с анализом влияния на бизнес и должны быть четко определены, чтобы персонал понимал, какие системы и функции необходимо восстановить в первую очередь.
Рекомендации: временные шкалы
Укажите полную версию плана или процедуры аварийного восстановления, которая должна включать разделы, охватывающие обработанный контур в описании элемента управления. Предоставьте фактический документ PDF/WORD, если в цифровой версии, или если процесс поддерживается через онлайн-платформу, предоставьте экспорт или снимки экрана процессов.
Пример доказательства: временные шкалы
Следующий снимок экрана: продолжение бизнес-функций и классификация важности, а также установленная цель времени восстановления (RTO).
Примечание. На этом снимка экранах показан документ политики или процесса. Ожидается, что поставщики программного обеспечения будут делиться фактической вспомогательной документацией по политике или процедуре, а не просто предоставить снимок экрана.


Намерение: восстановление
Этот элемент управления предоставляет пошаговую процедуру, которая должна выполняться для возврата критически важных информационных систем, бизнес-функций и служб в рабочее состояние. Это должно быть достаточно подробно для того, чтобы направлять процесс принятия решений в ситуациях с высоким давлением, где необходимы быстрые и эффективные действия.
Рекомендации: восстановление
Укажите полную версию плана или процедуры аварийного восстановления, которая должна включать разделы, охватывающие обработанный контур в описании элемента управления. Предоставьте фактический документ PDF/WORD, если в цифровой версии, или если процесс поддерживается через онлайн-платформу, предоставьте экспорт или снимки экрана процессов.
Пример доказательства: восстановление
На следующих снимках экрана показан фрагмент нашего плана аварийного восстановления и что для каждой системы и бизнес-функции существует документированные планы восстановления. Обратите внимание, что в этом примере процедура восстановления системы является частью плана аварийного восстановления, так как планы непрерывности бизнес-процессов и аварийного восстановления работают вместе для достижения полного восстановления или восстановления.
Примечание. На этом снимка экранах показан документ политики или процесса. Ожидается, что поставщики программного обеспечения будут делиться фактической вспомогательной документацией по политике или процедуре, а не просто предоставить снимок экрана.
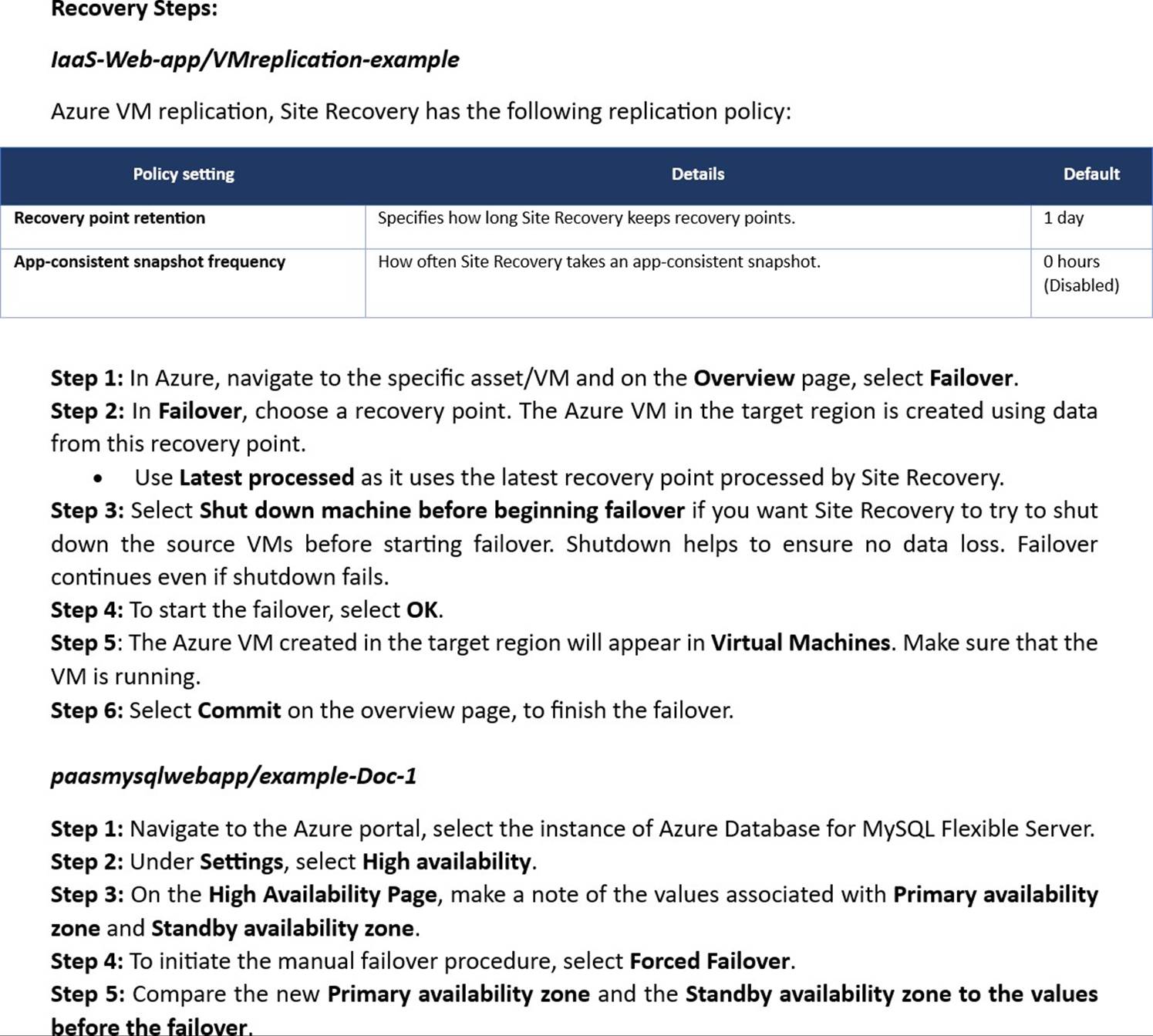
Намерение: проверка
Эта контрольная точка направлена на обеспечение того, чтобы план непрерывности бизнес-процессов включает структурированный процесс, который поможет организации восстановить системы до исходного состояния после кризиса. Это включает в себя шаги проверки, чтобы убедиться, что системы полностью работают и сохраняют свою целостность.
Рекомендации: проверка
Укажите полную версию плана или процедуры аварийного восстановления, которая должна включать разделы, охватывающие обработанный контур в описании элемента управления. Предоставьте фактический документ PDF/WORD, если в цифровой версии, или если процесс поддерживается через онлайн-платформу, предоставьте экспорт или снимки экрана процессов.
Пример доказательства: проверка
На следующем снимке экрана показан процесс восстановления, описанный в политике плана непрерывности бизнес-процессов, а также шаги и действия, которые необходимо выполнить.
Примечание. На этом снимке экрана показан моментальный снимок документа политики или процедуры. Ожидается, что поставщики программного обеспечения поделиться фактической документацией по политике или процедуре, а не просто предоставить снимок экрана.

Элемент управления No 29
Предоставьте доказательства того, что:
Документация существует и поддерживается, которая описывает план аварийного восстановления и включает в себя как минимум:
сведения о соответствующем персонале, включая его роли и обязанности
бизнес-функции с соответствующими требованиями и целями на случай непредвиденных обстоятельств
процедуры системного и резервного копирования данных, конфигурации, планирования и хранения
целевые показатели приоритета и временных интервалов восстановления
план на случай непредвиденных обстоятельств с подробными сведениями о действиях, шагах и процедурах, которые необходимо выполнить для возврата критически важных информационных систем, бизнес-функций и служб в работу в случае непредвиденных и незапланированных прерываний
установленный процесс, охватывающий итоговое полное восстановление системы и возвращение в исходное состояние
Намерение: DRP
Цель этого элемента управления — иметь хорошо документированные роли и обязанности для каждого члена команды аварийного восстановления. Следует также наметить процесс эскалации, чтобы обеспечить быстрое повышение уровня проблем и их решение соответствующим персоналом во время сценария аварии.
Рекомендации: DRP
Укажите полную версию плана или процедуры аварийного восстановления, которая должна включать разделы, охватывающие обработанный контур в описании элемента управления. Предоставьте фактический документ PDF/WORD, если в цифровой версии, или если процесс поддерживается через онлайн-платформу, предоставьте экспорт или снимки экрана процессов.
Пример доказательства: DRP
На следующих снимках экрана показано, как извлечь план аварийного восстановления и что он существует и поддерживается.
Примечание. На этом снимка экранах показан документ политики или процесса. Ожидается, что поставщики программного обеспечения будут делиться фактической вспомогательной документацией по политике или процедуре, а не просто предоставить снимок экрана.
На следующем снимку экрана показана выдержка из политики, в которой описывается "План на случай непредвиденных обстоятельств", включая соответствующую команду, контактные данные и шаги эскалации.
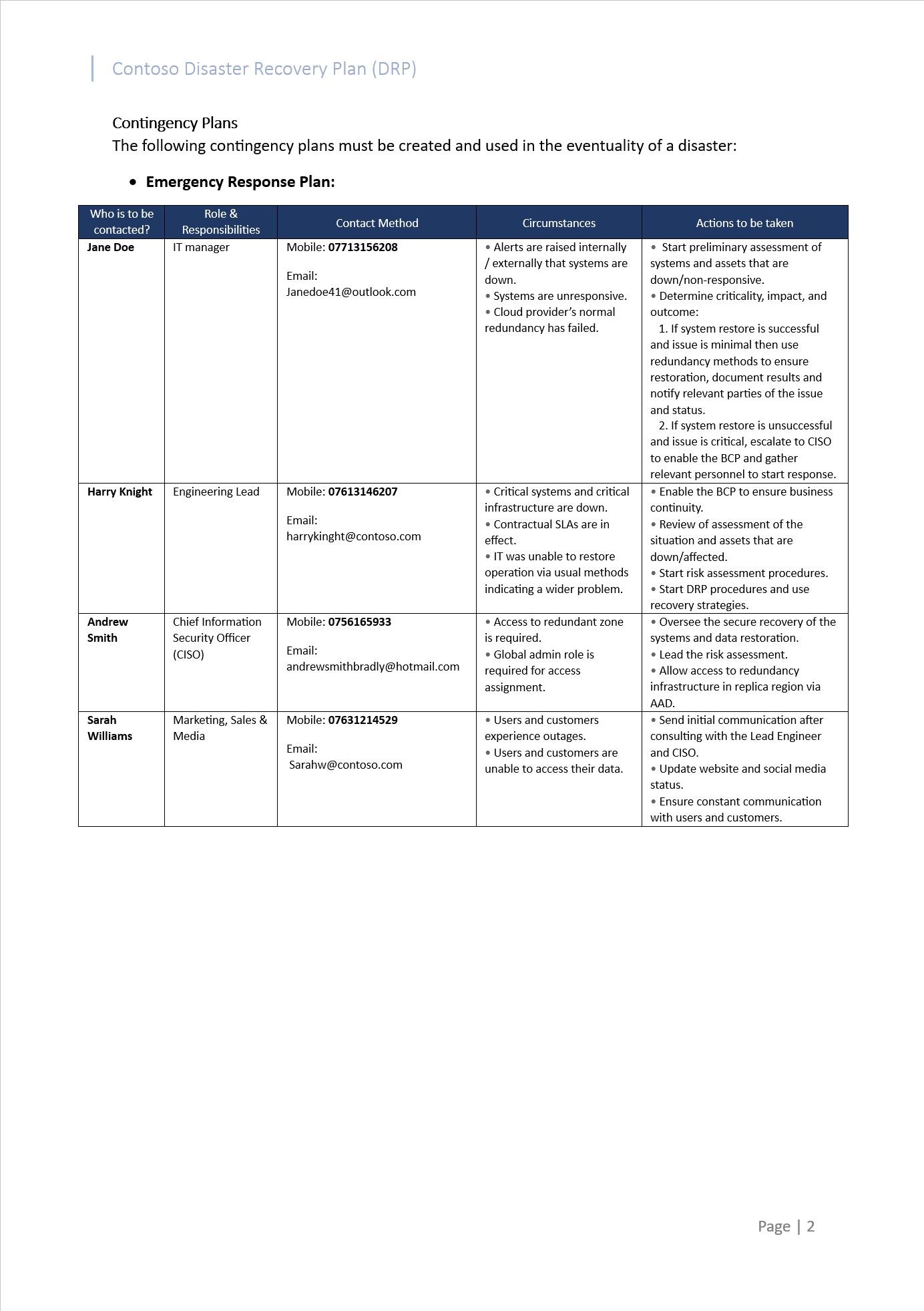
Намерение: инвентаризация
Цель этого контроля заключается в поддержании актуального списка запасов всех информационных систем, которые имеют решающее значение для поддержки бизнес-операций. Этот список имеет основополагающее значение для понимания того, какие системы должны быть приоритетными во время аварийного восстановления.
Рекомендации: инвентаризация
Укажите полную версию плана или процедуры аварийного восстановления, которая должна включать разделы, охватывающие обработанный контур в описании элемента управления. Предоставьте фактический документ PDF/WORD, если в цифровой версии, или если процесс поддерживается через онлайн-платформу, предоставьте экспорт или снимки экрана процессов.
Пример доказательства: инвентаризация
На следующих снимках экрана показано извлечение DRP и наличие инвентаризации критически важных систем и уровня их важности, а также системных функций.
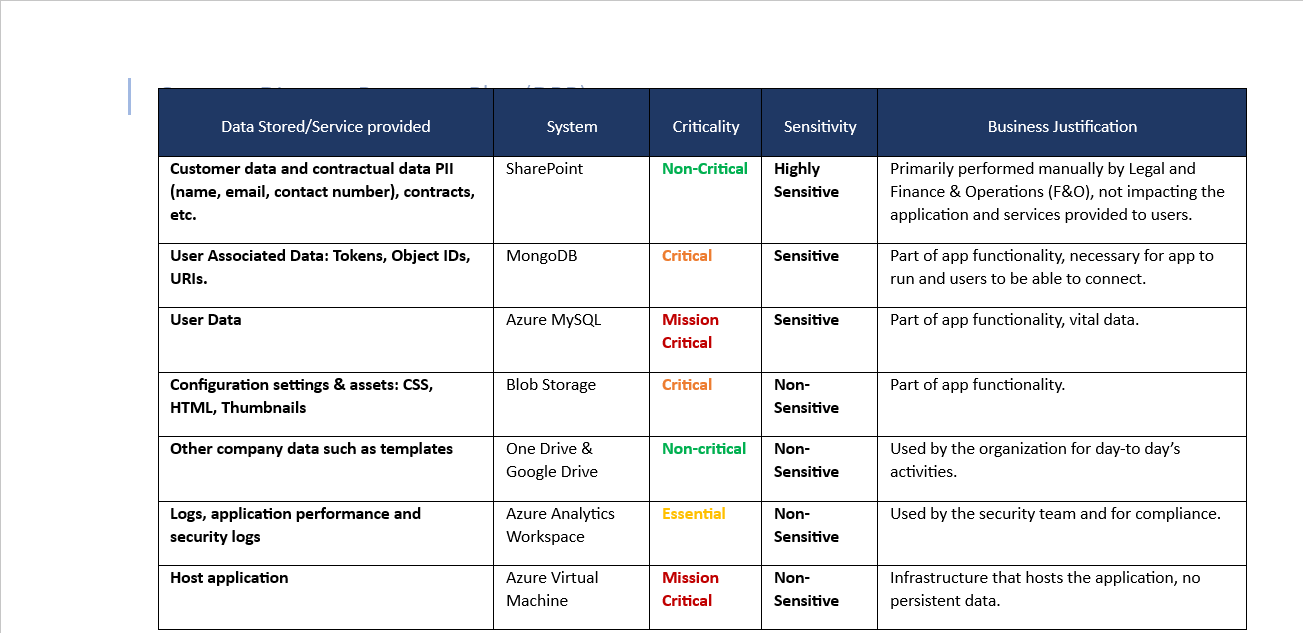
Примечание. На этом снимка экранах показан документ политики или процесса. Ожидается, что поставщики программного обеспечения будут делиться фактической вспомогательной документацией по политике или процедуре, а не просто предоставить снимок экрана.
На следующем снимку экрана показано определение классификации и важности службы.
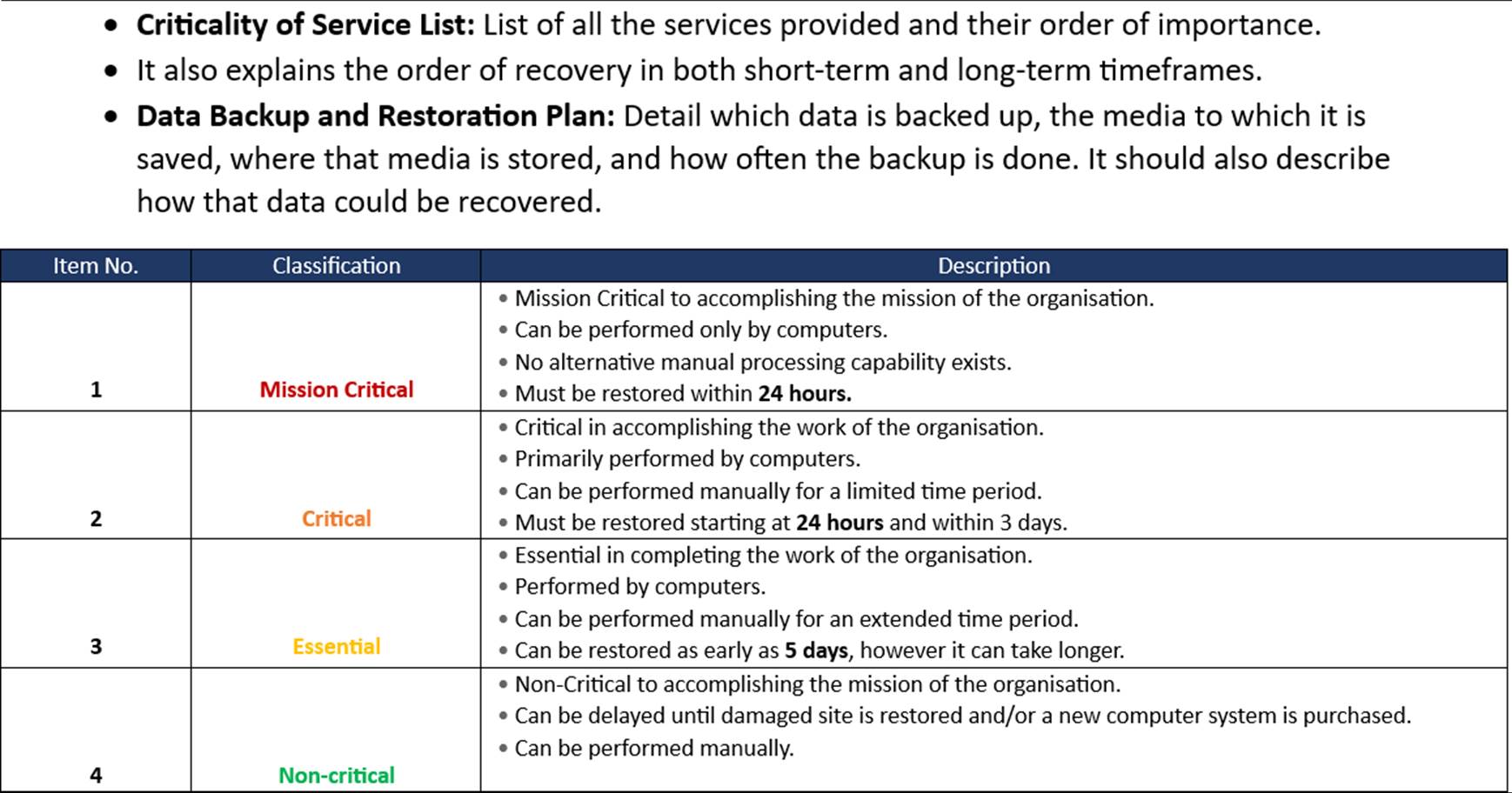
Примечание. На этом снимка экранах показан документ политики или процесса. Ожидается, что поставщики программного обеспечения будут делиться фактической вспомогательной документацией по политике или процедуре, а не просто предоставить снимок экрана.
Намерение: резервные копии
Этот элемент управления требует наличия четко определенных процедур для резервного копирования системы и данных. Эти процедуры должны описывать частоту, конфигурацию и расположение резервных копий, чтобы обеспечить восстановление всех критически важных данных в случае сбоя или аварии.
Рекомендации: резервные копии
Укажите полную версию плана или процедуры аварийного восстановления, которая должна включать разделы, охватывающие обработанный контур в описании элемента управления. Предоставьте фактический документ PDF/WORD, если в цифровой версии, или если процесс поддерживается через онлайн-платформу, предоставьте экспорт или снимки экрана процессов.
Пример доказательства: резервные копии
На следующих снимках экрана показано, как извлечь план аварийного восстановления и что для каждой системы существует задокументированная конфигурация резервного копирования. Обратите внимание, что расписание резервного копирования также описано ниже.
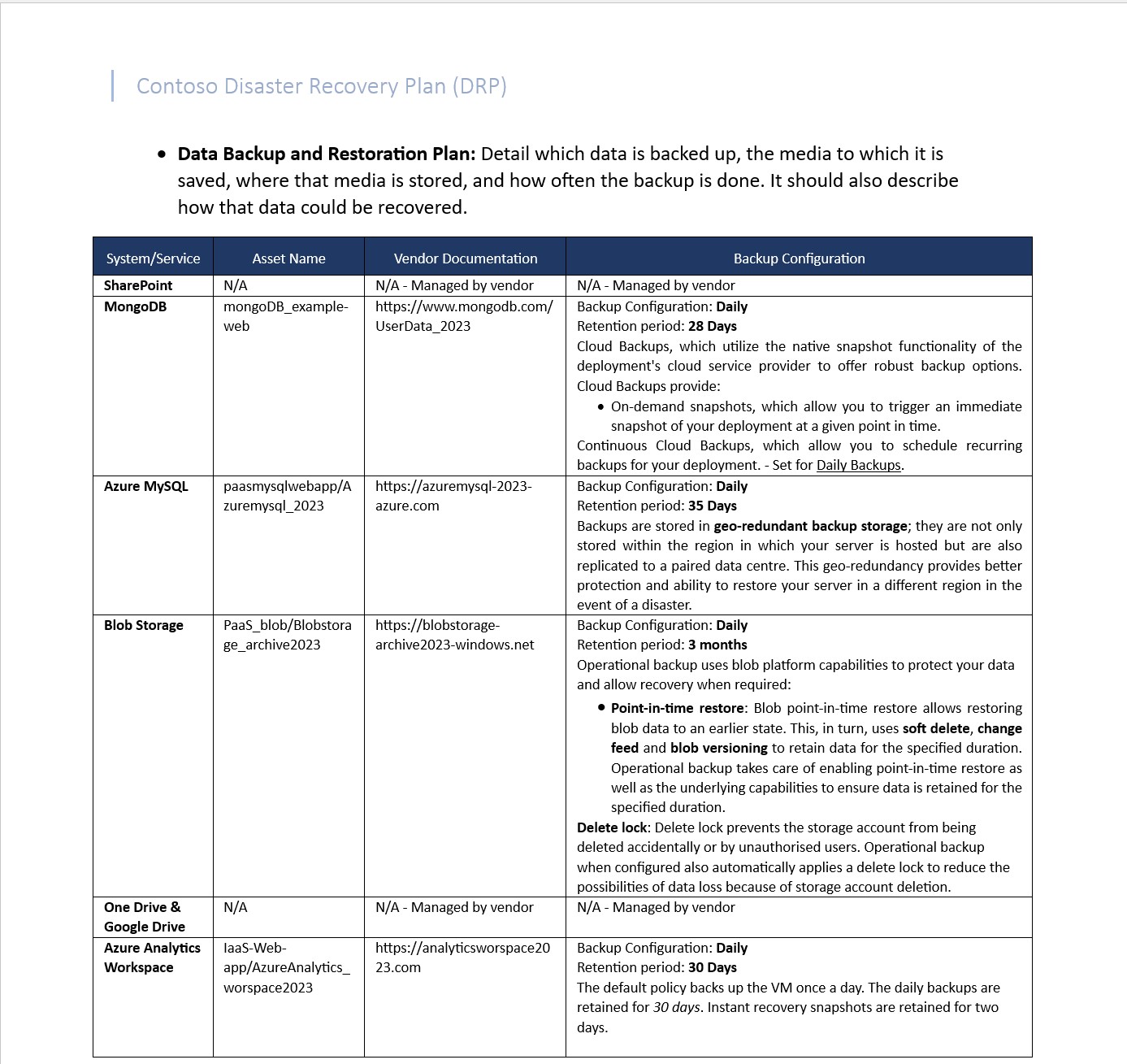
Примечание. На снимках экрана показан моментальный снимок документа политики или процесса. Ожидается, что поставщики программного обеспечения будут совместно использовать фактическую документацию по политике или процедуре, а не просто предоставить снимок экрана.
Намерение: восстановление
Этот элемент управления требует комплексного плана восстановления, в котором описываются пошаговые процедуры восстановления жизненно важных систем и данных. Это служит дорожной картой для команды аварийного восстановления и гарантирует, что все действия по восстановлению будут предумышленными и эффективными при восстановлении бизнес-операций.
Рекомендации: восстановление
Укажите полную версию плана или процедуры аварийного восстановления, которая должна включать разделы, охватывающие обработанный контур в описании элемента управления. Предоставьте фактический документ PDF/WORD, если в цифровой версии, или если процесс поддерживается через онлайн-платформу, предоставьте экспорт или снимки экрана процессов.
Пример доказательства: восстановление
На следующих снимках экрана показано, как извлечь план аварийного восстановления и что существуют шаги и инструкции по замене оборудования, а также инструкции по восстановлению системы, а также процедура восстановления, которая включает временные интервалы восстановления, действия, которые необходимо выполнить для восстановления облачной инфраструктуры и т. д.

Примечание. На снимках экрана показан моментальный снимок документа политики или процесса. Ожидается, что поставщики программного обеспечения будут совместно использовать фактическую документацию по политике или процедуре, а не просто предоставить снимок экрана.
Элемент управления No 30
Предоставьте доказательства того, что:
План непрерывности бизнес-процессов и план аварийного восстановления пересматриваются по крайней мере каждые 12 месяцев, чтобы убедиться, что он остается действительным и эффективным в неблагоприятных ситуациях и обновляется на основе:
Ежегодный обзор плана.
Весь соответствующий персонал обучается своим ролям и обязанностям, назначенным в планах на непредвиденные случаи.
План и ы тестируются с помощью упражнений по обеспечению непрерывности бизнес-процессов или аварийному восстановлению.
Результаты тестов документируются, включая уроки, извлеченные из упражнений или организационных изменений.
Намерение: ежегодный обзор
Цель этого элемента управления — убедиться, что планы непрерывности бизнес-процессов и аварийного восстановления проверяются ежегодно. Этот обзор должен подтвердить, что планы по-прежнему эффективны, точны и согласованы с текущими бизнес-целями и технологическими архитектурами.
Цель: ежегодное обучение
Этот контроль требует, чтобы все лица с назначенными ролями в планах непрерывности бизнес-процессов и аварийного восстановления ежегодно получали соответствующее обучение. Цель состоит в том, чтобы убедиться, что они знают о своих обязанностях и способны эффективно выполнять их в случае аварии или прерывания работы.
Намерение: упражнения
Цель здесь — проверить эффективность планов непрерывности бизнес-процессов и аварийного восстановления с помощью реальных упражнений. Эти упражнения должны быть разработаны для имитации различных неблагоприятных условий, чтобы проверить, насколько хорошо организация может поддерживать или восстанавливать бизнес-операции.
Намерение: анализ
Окончательная контрольная точка предназначена для тщательной документации по всем результатам испытаний, включая анализ того, что работало хорошо, а что нет. Извлеченные уроки должны быть включены в планы, и любые недостатки должны быть немедленно устранены для повышения устойчивости организации.
Рекомендации: проверки
Для проверки следует предоставить такие данные, как отчеты, заметки о собраниях и выходные данные ежегодных мероприятий по обеспечению непрерывности бизнес-процессов и планов аварийного восстановления.
Пример доказательства: отзывы
На следующих снимках экрана показаны выходные данные отчета о детализации (упражнении) непрерывности бизнес-процессов и аварийного восстановления, в котором был создан сценарий, позволяющий команде выполнить план непрерывности бизнес-процессов и аварийного восстановления, а также пошаговое руководство по ситуации до успешного восстановления бизнес-функций и работы системы.
Примечание. На этих снимках экрана показаны моментальные снимки документа политики или процесса. Ожидается, что поставщики программного обеспечения будут делиться фактической вспомогательной документацией по политике или процедуре, а не просто предоставлять снимок экрана.





Примечание. На этих снимках экрана показаны моментальные снимки документа политики или процесса. Ожидается, что поставщики программного обеспечения будут делиться фактической вспомогательной документацией по политике или процедуре, а не просто предоставлять снимок экрана.