Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Сводные таблицы упрощают большие наборы данных. Они позволяют быстро манипулировать сгруппированных данных. API JavaScript для Excel позволяет надстройке создавать сводные таблицы и взаимодействовать с их компонентами. В этой статье описывается представление сводных таблиц API JavaScript для Office, а также приведены примеры кода для ключевых сценариев.
Если вы не знакомы с функциональностью сводных таблиц, рассмотрите возможность их изучения в качестве конечного пользователя. См . статью Создание сводной таблицы, чтобы проанализировать данные листа , чтобы получить хорошее руководство по этим средствам.
Важно!
Сводные таблицы, созданные с помощью OLAP, в настоящее время не поддерживаются. Power Pivot также не поддерживается.
Объектная модель
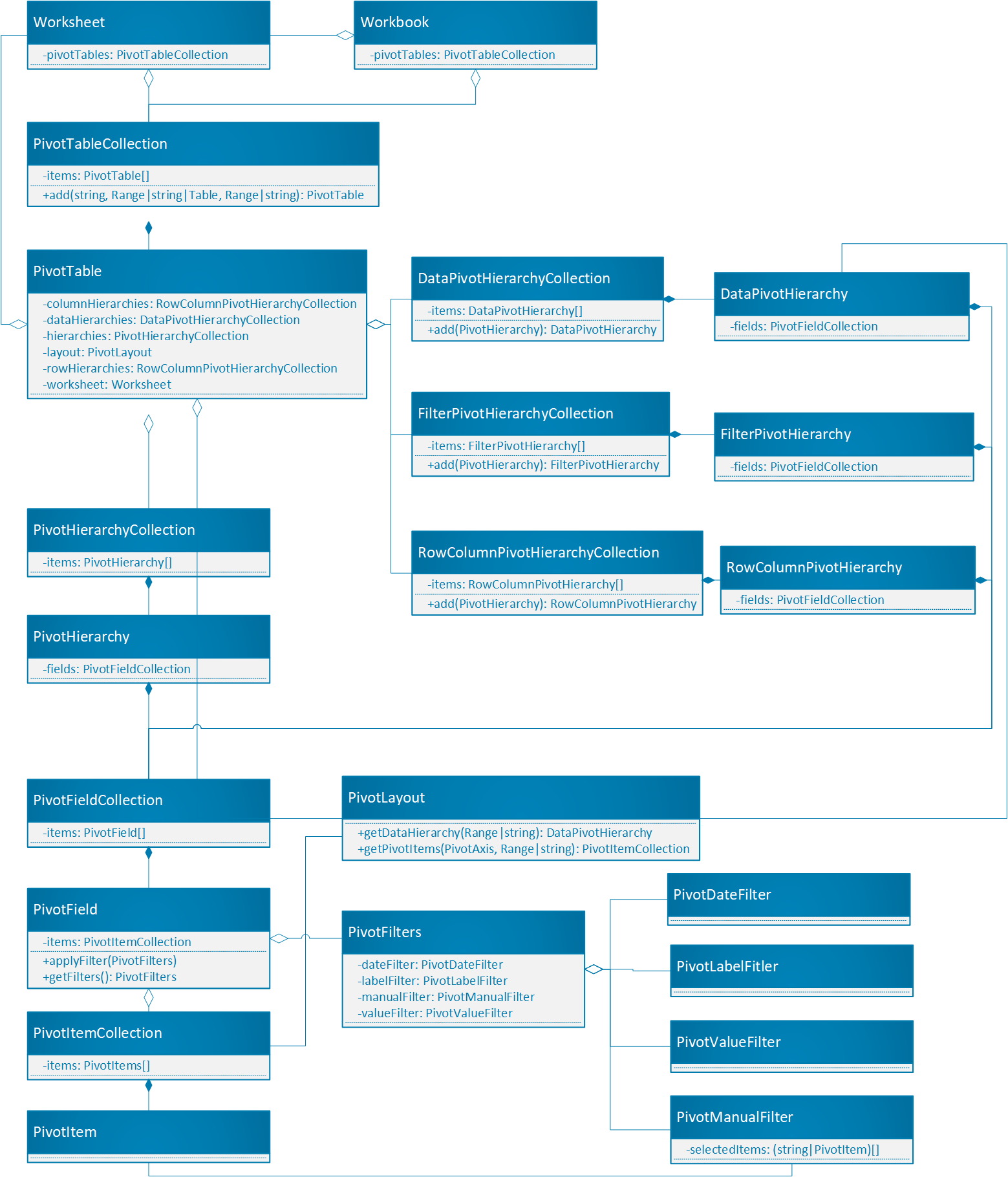
Сводная таблица является центральным объектом для сводных таблиц в API JavaScript для Office.
-
Workbook.pivotTablesиWorksheet.pivotTables— это PivotTableCollections , содержащие сводные таблицы в книге и листе соответственно. - Сводная таблица содержит сводную таблицу PivotHierarchyCollection с несколькими PivotHierarchies.
- Эти сводные иерархии можно добавить в определенные коллекции иерархий, чтобы определить способ сводных данных сводной таблицы (как описано в следующем разделе).
- Сводная иерархия содержит коллекцию PivotFieldCollection, которая содержит ровно одно поле PivotField. Если конструктор расширяется и включает сводные таблицы OLAP, это может измениться.
- К PivotField может применяться один или несколько PivotFilters , если сводная иерархия поля назначена категории иерархии.
- PivotField содержит PivotItemCollection с несколькими PivotItem.
- Сводная таблица содержит сводную таблицу, которая определяет, где на листе отображаются сводные поля и сводные элементы. Макет также управляет некоторыми параметрами отображения для сводной таблицы.
Давайте посмотрим, как эти связи применяются к некоторым примерам данных. Следующие данные описывают продажи фруктов из различных ферм. Это будет пример в этой статье.
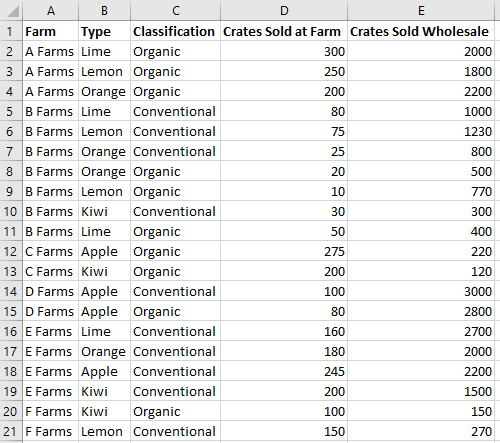
Эти данные о продажах фруктовой фермы будут использоваться для создания сводной таблицы. Каждый столбец, например Типы, является .PivotHierarchy Иерархия Типов содержит поле Типы . Поле Типы содержит элементы Apple, Kiwi, Lemon, Лайм и Orange.
Hierarchies
Сводные таблицы упорядочены по четырем категориям иерархии: строка, столбец, данные и фильтр.
Приведенные ранее данные фермы имеют пять иерархий: Фермы, Тип, Классификация, Ящики, Проданные на ферме, и Ящики, Проданные оптовые продажи. Каждая иерархия может существовать только в одной из четырех категорий. Если тип добавляется в иерархии столбцов, он также не может находиться в иерархиях строк, данных или фильтров. Если тип впоследствии добавляется в иерархии строк, он удаляется из иерархий столбцов. Такое поведение выполняется независимо от того, выполняется ли назначение иерархии с помощью пользовательского интерфейса Excel или API JavaScript для Excel.
Иерархии строк и столбцов определяют, как будут группироваться данные. Например, иерархия строк ферм будет группировать все наборы данных из одной фермы. Выбор между иерархией строк и столбцов определяет ориентацию сводной таблицы.
Иерархии данных — это значения, которые необходимо агрегировать на основе иерархий строк и столбцов. Сводная таблица с иерархией строк Фермы и иерархией данных crates Sold Оптовая продажа отображает суммарную сумму (по умолчанию) всех различных фруктов для каждой фермы.
Иерархии фильтров включают или исключают данные из сводной таблицы на основе значений в этом отфильтрованном типе. В иерархии фильтров классификации с выбранным типом Organic отображаются только данные для органических фруктов.
Ниже приведены данные фермы, а также сводная таблица. Сводная таблица использует ферму и тип в качестве иерархий строк, ящики, проданные на ферме , и crates sold в качестве иерархий данных (с агрегатной функцией суммы по умолчанию) и классификацию как иерархию фильтров (с выбранным параметром Organic ).
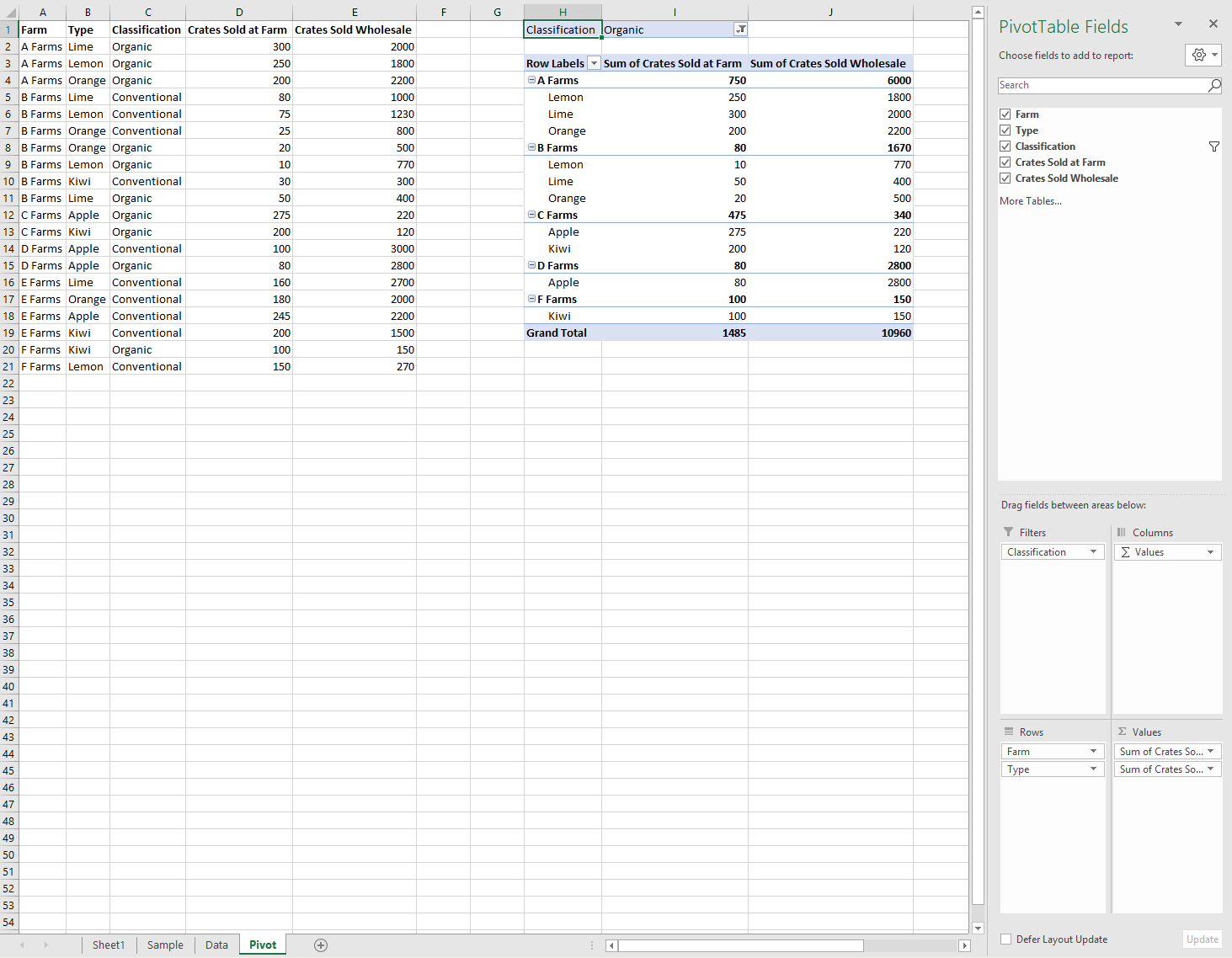
Эту сводную таблицу можно создать с помощью API JavaScript или пользовательского интерфейса Excel. Оба варианта позволяют выполнять дополнительные операции с помощью надстроек.
Создание сводной таблицы
Для сводных таблиц требуются имя, источник и назначение. Источником может быть адрес диапазона или имя таблицы (передается как Rangeтип , stringили Table ). Назначение — это адрес диапазона (предоставляется как или Rangestring).
В следующих примерах показаны различные методы создания сводной таблицы.
Создание сводной таблицы с адресами диапазона
await Excel.run(async (context) => {
// Create a PivotTable named "Farm Sales" on the current worksheet at cell
// A22 with data from the range A1:E21.
context.workbook.worksheets.getActiveWorksheet().pivotTables.add(
"Farm Sales", "A1:E21", "A22");
await context.sync();
});
Создание сводной таблицы с объектами Range
await Excel.run(async (context) => {
// Create a PivotTable named "Farm Sales" on a worksheet called "PivotWorksheet" at cell A2
// the data comes from the worksheet "DataWorksheet" across the range A1:E21.
let rangeToAnalyze = context.workbook.worksheets.getItem("DataWorksheet").getRange("A1:E21");
let rangeToPlacePivot = context.workbook.worksheets.getItem("PivotWorksheet").getRange("A2");
context.workbook.worksheets.getItem("PivotWorksheet").pivotTables.add(
"Farm Sales", rangeToAnalyze, rangeToPlacePivot);
await context.sync();
});
Создание сводной таблицы на уровне книги
await Excel.run(async (context) => {
// Create a PivotTable named "Farm Sales" on a worksheet called "PivotWorksheet" at cell A2
// the data is from the worksheet "DataWorksheet" across the range A1:E21.
context.workbook.pivotTables.add(
"Farm Sales", "DataWorksheet!A1:E21", "PivotWorksheet!A2");
await context.sync();
});
Использование существующей сводной таблицы
Созданные вручную сводные таблицы также доступны через коллекцию сводных таблиц книги или отдельных листов. Следующий код получает сводную таблицу с именем My Pivot из книги.
await Excel.run(async (context) => {
let pivotTable = context.workbook.pivotTables.getItem("My Pivot");
await context.sync();
});
Добавление строк и столбцов в сводную таблицу
Строки и столбцы сводить данные вокруг значений этих полей.
При добавлении столбца Ферма все продажи разворачиваются вокруг каждой фермы. При добавлении строк Тип и Классификация данные разбиваются в зависимости от того, какие фрукты были проданы и были ли они органическими.
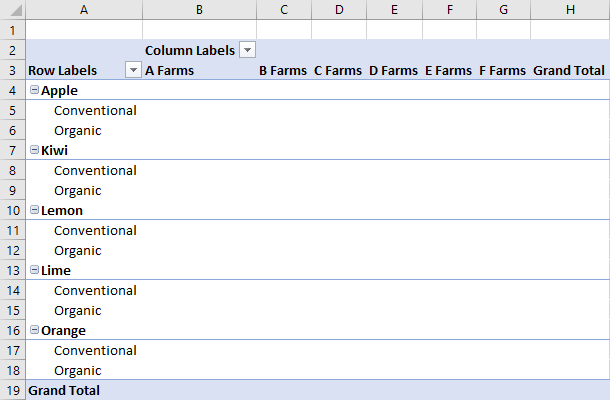
await Excel.run(async (context) => {
let pivotTable = context.workbook.worksheets.getActiveWorksheet().pivotTables.getItem("Farm Sales");
pivotTable.rowHierarchies.add(pivotTable.hierarchies.getItem("Type"));
pivotTable.rowHierarchies.add(pivotTable.hierarchies.getItem("Classification"));
pivotTable.columnHierarchies.add(pivotTable.hierarchies.getItem("Farm"));
await context.sync();
});
Также можно создать сводную таблицу, включаемую только в строки или столбцы.
await Excel.run(async (context) => {
let pivotTable = context.workbook.worksheets.getActiveWorksheet().pivotTables.getItem("Farm Sales");
pivotTable.rowHierarchies.add(pivotTable.hierarchies.getItem("Farm"));
pivotTable.rowHierarchies.add(pivotTable.hierarchies.getItem("Type"));
pivotTable.rowHierarchies.add(pivotTable.hierarchies.getItem("Classification"));
await context.sync();
});
Добавление иерархий данных в сводную таблицу
Иерархии данных заполняют сводную таблицу сведениями для объединения на основе строк и столбцов. Добавление иерархий данных контейнеров, проданных на ферме и crates sold, дает суммы этих цифр для каждой строки и столбца.
В примере ферма и тип являются строками, в которых в качестве данных отображаются продажи в ящике.
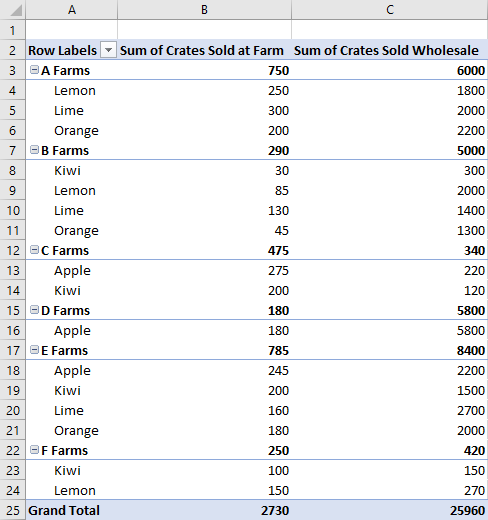
await Excel.run(async (context) => {
let pivotTable = context.workbook.worksheets.getActiveWorksheet().pivotTables.getItem("Farm Sales");
// "Farm" and "Type" are the hierarchies on which the aggregation is based.
pivotTable.rowHierarchies.add(pivotTable.hierarchies.getItem("Farm"));
pivotTable.rowHierarchies.add(pivotTable.hierarchies.getItem("Type"));
// "Crates Sold at Farm" and "Crates Sold Wholesale" are the hierarchies
// that will have their data aggregated (summed in this case).
pivotTable.dataHierarchies.add(pivotTable.hierarchies.getItem("Crates Sold at Farm"));
pivotTable.dataHierarchies.add(pivotTable.hierarchies.getItem("Crates Sold Wholesale"));
await context.sync();
});
Макеты сводной таблицы и получение сводных данных
PivotLayout определяет размещение иерархий и их данных. Вы можете получить доступ к макету, чтобы определить диапазоны, в которых хранятся данные.
На следующей схеме показано, какие вызовы функций макета соответствуют диапазонам сводной таблицы.
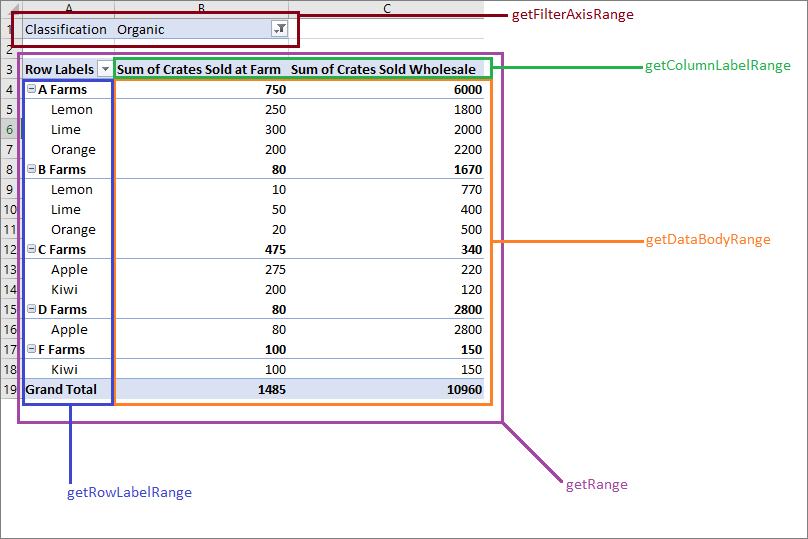
Получение данных из сводной таблицы
Макет определяет отображение сводной таблицы на листе. Это означает, PivotLayout что объект управляет диапазонами, используемыми для элементов сводной таблицы. Используйте диапазоны, предоставляемые макетом, для получения данных, собираемых и агрегированных сводной таблицей. В частности, используйте для PivotLayout.getDataBodyRange доступа к данным, созданным сводной таблицей.
В следующем коде показано, как получить последнюю строку данных сводной таблицы путем просмотра макета ( общий итог столбцов Sum of Crates Sold at Farm и Sum of Crates Sold Wholesale в предыдущем примере). Затем эти значения суммируются для итогового итога, который отображается в ячейке E30 (за пределами сводной таблицы).
await Excel.run(async (context) => {
let pivotTable = context.workbook.worksheets.getActiveWorksheet().pivotTables.getItem("Farm Sales");
// Get the totals for each data hierarchy from the layout.
let range = pivotTable.layout.getDataBodyRange();
let grandTotalRange = range.getLastRow();
grandTotalRange.load("address");
await context.sync();
// Sum the totals from the PivotTable data hierarchies and place them in a new range, outside of the PivotTable.
let masterTotalRange = context.workbook.worksheets.getActiveWorksheet().getRange("E30");
masterTotalRange.formulas = [["=SUM(" + grandTotalRange.address + ")"]];
await context.sync();
});
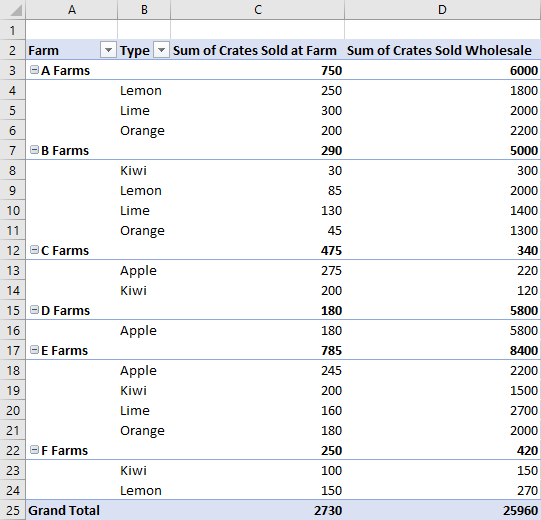
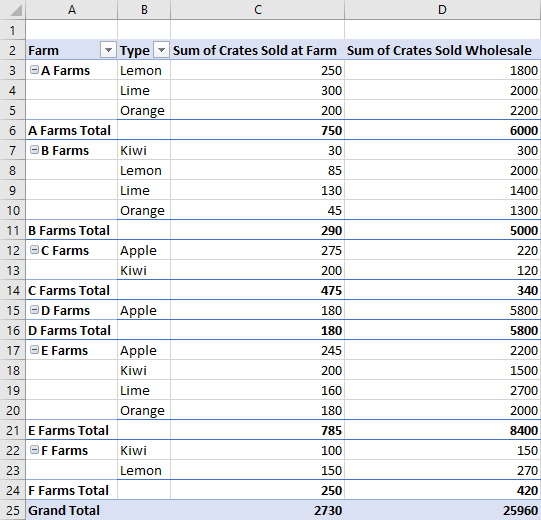
Типы макетов
Сводные таблицы имеют три стиля макета: компактный, контурный и табличный. Компактный стиль мы видели в предыдущих примерах.
В следующих примерах используются стили контура и таблицы соответственно. В примере кода показано, как переключаться между различными макетами.
Макет структуры
Табличный макет
Пример кода переключения типа PivotLayout
await Excel.run(async (context) => {
// Change the PivotLayout.type to a new type.
let pivotTable = context.workbook.worksheets.getActiveWorksheet().pivotTables.getItem("Farm Sales");
pivotTable.layout.load("layoutType");
await context.sync();
// Cycle between the three layout types.
if (pivotTable.layout.layoutType === "Compact") {
pivotTable.layout.layoutType = "Outline";
} else if (pivotTable.layout.layoutType === "Outline") {
pivotTable.layout.layoutType = "Tabular";
} else {
pivotTable.layout.layoutType = "Compact";
}
await context.sync();
});
Другие функции PivotLayout
По умолчанию сводные таблицы настраивают размеры строк и столбцов по мере необходимости. Это делается при обновлении сводной таблицы.
PivotLayout.autoFormat указывает это поведение. Любые изменения размера строк или столбцов, внесенные надстройкой, сохраняются, если autoFormat имеет значение false. Кроме того, параметры сводной таблицы по умолчанию сохраняют любое настраиваемое форматирование в сводной таблице (например, заливку и изменение шрифта). Задайте значение PivotLayout.preserveFormatting , false чтобы применить формат по умолчанию при обновлении.
Также PivotLayout управляет параметрами заголовка и общей строки, способом отображения пустых ячеек данных и параметрами замещающего текста . В справочнике по PivotLayout представлен полный список этих функций.
В следующем примере кода пустые ячейки данных отображают строку "--", форматируют диапазон текста до согласованного горизонтального выравнивания и гарантируют, что изменения форматирования сохраняются даже после обновления сводной таблицы.
await Excel.run(async (context) => {
let pivotTable = context.workbook.pivotTables.getItem("Farm Sales");
let pivotLayout = pivotTable.layout;
// Set a default value for an empty cell in the PivotTable. This doesn't include cells left blank by the layout.
pivotLayout.emptyCellText = "--";
// Set the text alignment to match the rest of the PivotTable.
pivotLayout.getDataBodyRange().format.horizontalAlignment = Excel.HorizontalAlignment.right;
// Ensure empty cells are filled with a default value.
pivotLayout.fillEmptyCells = true;
// Ensure that the format settings persist, even after the PivotTable is refreshed and recalculated.
pivotLayout.preserveFormatting = true;
await context.sync();
});
Удаление сводной таблицы
Сводные таблицы удаляются с использованием их имени.
await Excel.run(async (context) => {
context.workbook.worksheets.getItem("Pivot").pivotTables.getItem("Farm Sales").delete();
await context.sync();
});
Фильтрация сводной таблицы
Основной метод фильтрации данных сводной таблицы — с помощью PivotFilters. Срезы предлагают альтернативный, менее гибкий метод фильтрации.
PivotFilters фильтруют данные на основе четырех категорий иерархии сводной таблицы (фильтры, столбцы, строки и значения). Существует четыре типа сводных фильтров, которые позволяют фильтровать на основе дат календаря, анализировать строки, сравнивать числа и фильтровать на основе пользовательских входных данных.
Срезы можно применять как к сводных таблицам, так и к обычным таблицам Excel. При применении к сводной таблице срезы функционируют как PivotManualFilter и разрешают фильтрацию на основе пользовательских входных данных. В отличие от сводных фильтрах, срезы имеют компонент пользовательского интерфейса Excel. С помощью класса вы создаете Slicer этот компонент пользовательского интерфейса, управляете фильтрацией и управляете его внешним видом.
Фильтрация с помощью PivotFilters
PivotFilters позволяют фильтровать данные сводной таблицы на основе четырех категорий иерархии (фильтры, столбцы, строки и значения). В объектной модели PivotFilters сводной таблицы применяются к сводным полям, и каждому из них PivotField может быть назначено PivotFiltersодно или несколько . Чтобы применить PivotFilters к PivotField, соответствующая PivotHierarchy поля должна быть назначена категории иерархии.
Типы сводных фильтрах
| Тип фильтра | Назначение фильтра | Справочные материалы по API JavaScript для Excel |
|---|---|---|
| Фильтр даты | Фильтрация на основе дат календаря. | PivotDateFilter |
| LabelFilter | Фильтрация сравнения текста. | PivotLabelFilter |
| ManualFilter | Настраиваемая фильтрация входных данных. | PivotManualFilter |
| ValueFilter | Фильтрация сравнения чисел. | PivotValueFilter |
Создание сводного фильтра
Чтобы отфильтровать данные сводной таблицы с помощью Pivot*Filter (например PivotDateFilter, ), примените фильтр к PivotField. В следующих четырех примерах кода показано, как использовать каждый из четырех типов PivotFilters.
PivotDateFilter
Первый пример кода применяет PivotDateFilter к сводных полям Даты обновления , скрывая все данные до 2020-08-01.
Важно!
Не Pivot*Filter может применяться к PivotField, если сводная иерархия этого поля не назначена категории иерархии. В следующем примере кода необходимо добавить в категорию сводной таблицыrowHierarchies, dateHierarchy прежде чем его можно будет использовать для фильтрации.
await Excel.run(async (context) => {
// Get the PivotTable and the date hierarchy.
let pivotTable = context.workbook.worksheets.getActiveWorksheet().pivotTables.getItem("Farm Sales");
let dateHierarchy = pivotTable.rowHierarchies.getItemOrNullObject("Date Updated");
await context.sync();
// PivotFilters can only be applied to PivotHierarchies that are being used for pivoting.
// If it's not already there, add "Date Updated" to the hierarchies.
if (dateHierarchy.isNullObject) {
dateHierarchy = pivotTable.rowHierarchies.add(pivotTable.hierarchies.getItem("Date Updated"));
}
// Apply a date filter to filter out anything logged before August.
let filterField = dateHierarchy.fields.getItem("Date Updated");
let dateFilter = {
condition: Excel.DateFilterCondition.afterOrEqualTo,
comparator: {
date: "2020-08-01",
specificity: Excel.FilterDatetimeSpecificity.month
}
};
filterField.applyFilter({ dateFilter: dateFilter });
await context.sync();
});
Примечание.
В следующих трех фрагментах кода вместо полных Excel.run вызовов отображаются только фрагменты, относящиеся к фильтру.
PivotLabelFilter
Во втором фрагменте кода показано, как применить PivotLabelFilter к типу PivotField, используя LabelFilterCondition.beginsWith свойство для исключения меток, которые начинаются с буквы L.
// Get the "Type" field.
let filterField = pivotTable.hierarchies.getItem("Type").fields.getItem("Type");
// Filter out any types that start with "L" ("Lemons" and "Limes" in this case).
let filter: Excel.PivotLabelFilter = {
condition: Excel.LabelFilterCondition.beginsWith,
substring: "L",
exclusive: true
};
// Apply the label filter to the field.
filterField.applyFilter({ labelFilter: filter });
PivotManualFilter
Третий фрагмент кода применяет ручной фильтр с PivotManualFilter к полю Классификация , отфильтровав данные, которые не включают классификацию Organic.
// Apply a manual filter to include only a specific PivotItem (the string "Organic").
let filterField = classHierarchy.fields.getItem("Classification");
let manualFilter = { selectedItems: ["Organic"] };
filterField.applyFilter({ manualFilter: manualFilter });
PivotValueFilter
Чтобы сравнить числа, используйте фильтр значений с PivotValueFilter, как показано в последнем фрагменте кода. Сравнивает PivotValueFilter данные в сводном поле фермы с данными в поле PivotField проданных контейнеров, включая только фермы, сумма проданных ящиков которых превышает значение 500.
// Get the "Farm" field.
let filterField = pivotTable.hierarchies.getItem("Farm").fields.getItem("Farm");
// Filter to only include rows with more than 500 wholesale crates sold.
let filter: Excel.PivotValueFilter = {
condition: Excel.ValueFilterCondition.greaterThan,
comparator: 500,
value: "Sum of Crates Sold Wholesale"
};
// Apply the value filter to the field.
filterField.applyFilter({ valueFilter: filter });
Удаление сводных фильтрах
Чтобы удалить все PivotFilters, примените clearAllFilters метод к каждому PivotField, как показано в следующем примере кода.
await Excel.run(async (context) => {
// Get the PivotTable.
let pivotTable = context.workbook.worksheets.getActiveWorksheet().pivotTables.getItem("Farm Sales");
pivotTable.hierarchies.load("name");
await context.sync();
// Clear the filters on each PivotField.
pivotTable.hierarchies.items.forEach(function (hierarchy) {
hierarchy.fields.getItem(hierarchy.name).clearAllFilters();
});
await context.sync();
});
Фильтрация с помощью срезов
Срезы позволяют фильтровать данные из сводной таблицы или таблицы Excel. Срез использует значения из указанного столбца или сводного поля для фильтрации соответствующих строк. Эти значения хранятся как объекты SlicerItem в Slicer. Надстройка может настраивать эти фильтры, как и пользователи (с помощью пользовательского интерфейса Excel). Срез находится поверх листа на слое документа, как показано на следующем снимке экрана.
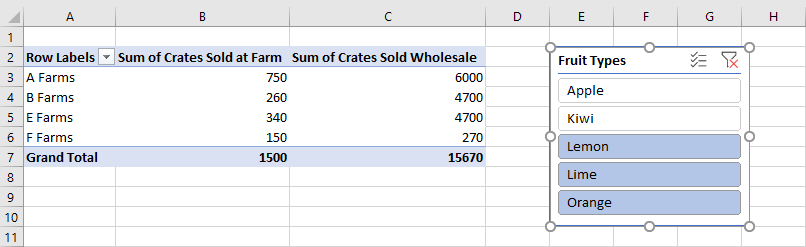
Примечание.
Методы, описанные в этом разделе, посвящены использованию срезов, подключенных к сводных таблицам. Те же методы также применяются к использованию срезов, подключенных к таблицам.
Создание среза
Срез можно создать в книге или листе Workbook.slicers.add с помощью метода или Worksheet.slicers.add . При этом добавляется срез в коллекцию SlicerCollection указанного Workbook объекта или Worksheet . Метод SlicerCollection.add имеет три параметра:
-
slicerSource: источник данных, на котором основан новый срез. Это может бытьPivotTableстрока ,Tableили , представляющая имя или идентификаторPivotTableобъекта илиTable. -
sourceField: поле в источнике данных, по которому выполняется фильтрация. Это может бытьPivotFieldстрока ,TableColumnили , представляющая имя или идентификаторPivotFieldобъекта илиTableColumn. -
slicerDestination: лист, на котором будет создан новый срез. Это может бытьWorksheetобъект или имя или идентификатор объектаWorksheet. Этот параметр не нужен, если доступ к объектуSlicerCollectionосуществляется черезWorksheet.slicers. В этом случае в качестве назначения используется лист коллекции.
Следующий пример кода добавляет новый срез на лист Pivot . Источником среза является сводная таблица "Продажи фермы " и выполняется фильтрация по данным типа . Срез также называется Fruit Slicer для дальнейшего использования.
await Excel.run(async (context) => {
let sheet = context.workbook.worksheets.getItem("Pivot");
let slicer = sheet.slicers.add(
"Farm Sales" /* The slicer data source. For PivotTables, this can be the PivotTable object reference or name. */,
"Type" /* The field in the data to filter by. For PivotTables, this can be a PivotField object reference or ID. */
);
slicer.name = "Fruit Slicer";
await context.sync();
});
Фильтрация элементов с помощью среза
Срез фильтрует сводную таблицу по элементам из sourceField. Метод Slicer.selectItems задает элементы, которые остаются в срезе. Эти элементы передаются в метод в виде string[], представляющего ключи элементов. Все строки, содержащие эти элементы, остаются в агрегате сводной таблицы. Последующие вызовы для selectItems задания списка ключей, указанных в этих вызовах.
Примечание.
Если Slicer.selectItems передается элемент, который отсутствует в источнике данных, InvalidArgument возникает ошибка. Содержимое можно проверить с помощью Slicer.slicerItems свойства SlicerItemCollection.
В следующем примере кода показаны три элемента, выбираемые для среза: Лимон, Лайм и Оранжевый.
await Excel.run(async (context) => {
let slicer = context.workbook.slicers.getItem("Fruit Slicer");
// Anything other than the following three values will be filtered out of the PivotTable for display and aggregation.
slicer.selectItems(["Lemon", "Lime", "Orange"]);
await context.sync();
});
Чтобы удалить все фильтры из среза, используйте Slicer.clearFilters метод , как показано в следующем примере.
await Excel.run(async (context) => {
let slicer = context.workbook.slicers.getItem("Fruit Slicer");
slicer.clearFilters();
await context.sync();
});
Стиль и форматирование среза
Надстройка может настраивать параметры отображения среза с помощью Slicer свойств. В следующем примере кода задается стиль SlicerStyleLight6, тексту в верхней части среза присваивается значение Fruit Types, срез помещает его в положение (395, 15) на слое рисования, а размер среза — 135 x 150 пикселей.
await Excel.run(async (context) => {
let slicer = context.workbook.slicers.getItem("Fruit Slicer");
slicer.caption = "Fruit Types";
slicer.left = 395;
slicer.top = 15;
slicer.height = 135;
slicer.width = 150;
slicer.style = "SlicerStyleLight6";
await context.sync();
});
Удаление среза
Чтобы удалить срез, вызовите Slicer.delete метод . В следующем примере кода первый срез удаляется с текущего листа.
await Excel.run(async (context) => {
let sheet = context.workbook.worksheets.getActiveWorksheet();
sheet.slicers.getItemAt(0).delete();
await context.sync();
});
Функция агрегирования изменений
Иерархии данных имеют свои значения, агрегированные. Для наборов данных чисел это сумма по умолчанию. Свойство summarizeBy определяет это поведение на основе типа AggregationFunction .
В настоящее время поддерживаются Sumтипы агрегатных функций , , AverageCount, Max, Min, Product, , StandardDeviationStandardDeviationPVarianceCountNumbersVariancePи Automatic (по умолчанию).
В следующих примерах кода агрегация изменяется на средние значения данных.
await Excel.run(async (context) => {
let pivotTable = context.workbook.worksheets.getActiveWorksheet().pivotTables.getItem("Farm Sales");
pivotTable.dataHierarchies.load("no-properties-needed");
await context.sync();
// Change the aggregation from the default sum to an average of all the values in the hierarchy.
pivotTable.dataHierarchies.items[0].summarizeBy = Excel.AggregationFunction.average;
pivotTable.dataHierarchies.items[1].summarizeBy = Excel.AggregationFunction.average;
await context.sync();
});
Изменение вычислений с помощью ShowAsRule
Сводные таблицы по умолчанию объединяют данные иерархий строк и столбцов независимо друг от друга. ShowAsRule изменяет иерархию данных на выходные значения на основе других элементов в сводной таблице.
Объект ShowAsRule имеет три свойства:
-
calculation: тип относительного вычисления, применяемого к иерархии данных (по умолчанию —none). -
baseField: сводное поле в иерархии, содержащей базовые данные перед применением вычисления. Так как в сводных таблицах Excel есть одно к одному сопоставление иерархии с полем, вы будете использовать одно и то же имя для доступа как к иерархии, так и к полю. -
baseItem: отдельный элемент PivotItem сравнивается со значениями базовых полей на основе типа вычисления. Это поле требуется не для всех вычислений.
В следующем примере вычисление для иерархии данных Sum of Crates Sold at Farm задается в процентах от общего числа столбцов. Мы по-прежнему хотим, чтобы детализация расширяла уровень типа фруктов, поэтому мы будем использовать иерархию строк Type и ее базовое поле. В примере в качестве первой строки также указана иерархия фермы , поэтому в общих записях фермы отображается процент, за который отвечает каждая ферма.
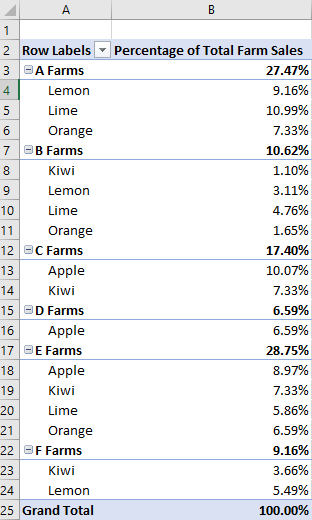
await Excel.run(async (context) => {
let pivotTable = context.workbook.worksheets.getActiveWorksheet().pivotTables.getItem("Farm Sales");
let farmDataHierarchy = pivotTable.dataHierarchies.getItem("Sum of Crates Sold at Farm");
farmDataHierarchy.load("showAs");
await context.sync();
// Show the crates of each fruit type sold at the farm as a percentage of the column's total.
let farmShowAs = farmDataHierarchy.showAs;
farmShowAs.calculation = Excel.ShowAsCalculation.percentOfColumnTotal;
farmShowAs.baseField = pivotTable.rowHierarchies.getItem("Type").fields.getItem("Type");
farmDataHierarchy.showAs = farmShowAs;
farmDataHierarchy.name = "Percentage of Total Farm Sales";
});
В предыдущем примере для вычисления задается столбец относительно поля отдельной иерархии строк. Если вычисление связано с отдельным элементом, используйте baseItem свойство .
В следующем примере показано вычисление differenceFrom . В нем отображается разница в записях иерархии данных продаж фермы по сравнению с записями ферм A.
Объект baseField is Farm, поэтому мы видим различия между другими фермами, а также разбивки для каждого типа, например fruit (Тип также является иерархией строк в этом примере).
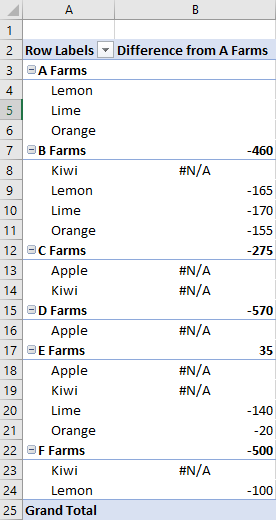
await Excel.run(async (context) => {
let pivotTable = context.workbook.worksheets.getActiveWorksheet().pivotTables.getItem("Farm Sales");
let farmDataHierarchy = pivotTable.dataHierarchies.getItem("Sum of Crates Sold at Farm");
farmDataHierarchy.load("showAs");
await context.sync();
// Show the difference between crate sales of the "A Farms" and the other farms.
// This difference is both aggregated and shown for individual fruit types (where applicable).
let farmShowAs = farmDataHierarchy.showAs;
farmShowAs.calculation = Excel.ShowAsCalculation.differenceFrom;
farmShowAs.baseField = pivotTable.rowHierarchies.getItem("Farm").fields.getItem("Farm");
farmShowAs.baseItem = pivotTable.rowHierarchies.getItem("Farm").fields.getItem("Farm").items.getItem("A Farms");
farmDataHierarchy.showAs = farmShowAs;
farmDataHierarchy.name = "Difference from A Farms";
});
Изменение имен иерархии
Поля иерархии доступны для редактирования. В следующем коде показано, как изменить отображаемые имена двух иерархий данных.
await Excel.run(async (context) => {
let dataHierarchies = context.workbook.worksheets.getActiveWorksheet()
.pivotTables.getItem("Farm Sales").dataHierarchies;
dataHierarchies.load("no-properties-needed");
await context.sync();
// Changing the displayed names of these entries.
dataHierarchies.items[0].name = "Farm Sales";
dataHierarchies.items[1].name = "Wholesale";
});
См. также
Совместная работа с нами на GitHub
Источник этого содержимого можно найти на GitHub, где также можно создавать и просматривать проблемы и запросы на вытягивание. Дополнительные сведения см. в нашем руководстве для участников.
Office Add-ins