Выборка линии высокой плотности в Power BI
Алгоритм выборки в Power BI улучшает визуальные элементы, которые используют данные высокой плотности. Например, вы можете создать график из результатов продаж розничных магазинов, каждый магазин с более чем 10000 квитанций о продажах каждый год. Линейчатая диаграмма таких сведений о продажах будет образец данных из данных для каждого хранилища и создание многосерийной линейной диаграммы, которая таким образом представляет базовые данные. Не забудьте выбрать понятное представление этих данных, чтобы иллюстрировать, как продажи изменяются с течением времени. Эта практика распространена при визуализации данных высокой плотности. Подробные сведения о выборке данных с высокой плотностью описаны в этой статье.
Примечание.
Алгоритм выборки высокой плотности, описанный в этой статье, доступен как в Power BI Desktop, так и в служба Power BI.
Как работает выборка линии высокой плотности
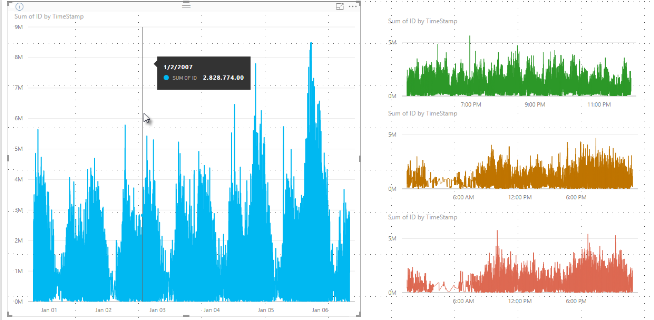
Ранее Power BI выбрала коллекцию примеров точек данных в полном диапазоне базовых данных в детерминированном виде. Например, при использовании данных с высокой плотностью визуального элемента, охватывающего один календарный год, в визуальном элементе может отображаться 350 точек данных, каждая из которых была выбрана для обеспечения полного диапазона данных в визуальном элементе. Чтобы понять, как это происходит, представьте себе график цен на акции за один год и выбор 365 точек данных для создания визуального элемента графики. Это одна точка данных для каждого дня.
В этой ситуации есть много значений для цен на акции в течение каждого дня. Конечно, есть ежедневный высокий и низкий, но они могут произойти в любое время в течение дня, когда фондовый рынок открыт. Для выборки линии высокой плотности, если базовый образец данных был взят в 10:30 и 12:00 каждый день, вы получите представительный снимок базовых данных, например цена за 10:30 и 12:00. Однако моментальный снимок может не захватить фактический высокий и низкий цену акций для этой репрезентативной точки данных в тот день. В этой ситуации и других, выборка является представителем базовых данных, но она не всегда захватывает важные моменты, которые в этом случае будут ежедневными ценами на акции и минимумами.
По определению данные с высокой плотностью выборки создаются достаточно быстро для создания визуализаций, которые реагируют на интерактивность. Слишком много точек данных на визуальном элементе может заболеть и может отвлечься от видимости тенденций. Выборка данных — это то, что приводит к созданию алгоритма выборки, чтобы обеспечить лучший интерфейс визуализации. В Power BI Desktop алгоритм обеспечивает лучшую комбинацию отклика, представления и четкого сохранения важных точек при каждом срезе.
Как работает новый алгоритм выборки строк
Алгоритм выборки линий высокой плотности доступен для визуальных элементов диаграммы и области с непрерывной осью x.
Для визуального элемента с высокой плотностью Power BI интеллектуально срезает данные в блоки с высоким разрешением, а затем выбирает важные моменты для представления каждого блока. Этот процесс обработки данных с высоким разрешением настраивается, чтобы гарантировать, что результирующая диаграмма визуально неотличима от отрисовки всех базовых точек данных, но более быстрая и интерактивная.
Минимальные и максимальные значения для визуальных элементов с высокой плотностью
Для любой визуализации применяются следующие ограничения:
3500 — максимальное количество точек данных, отображаемых на большинстве визуальных элементов, независимо от количества базовых точек данных или рядов, см. исключения в следующем списке. Например, если у вас есть 10 рядов с 350 точками данных каждый, визуальный элемент достиг максимального общего ограничения точек данных. Если у вас есть одна серия, это может иметь до 3500 точек данных, если алгоритм считает, что оптимальная выборка для базовых данных.
Существует не более 60 рядов для любого визуального элемента. Если у вас более 60 рядов, разбийте данные и создайте несколько визуальных элементов с 60 или меньшей серией. Рекомендуется использовать срез для отображения только сегментов данных, но только для определенных рядов. Например, если вы отображаете все подкатегории в условных обозначениях, можно использовать срез для фильтрации по общей категории на одной странице отчета.
Максимальное количество ограничений данных выше для следующих типов визуальных элементов, которые являются исключениями для ограничения в 3500 точек данных:
- Максимум 150 000 точек данных для визуальных элементов R.
- 30 000 точек данных для визуальных элементов Azure Map.
- 10 000 точек данных для некоторых конфигураций точечной диаграммы (точечная диаграмма по умолчанию — 3500).
- 3500 для всех остальных визуальных элементов с использованием выборки высокой плотности. Некоторые другие визуальные элементы могут визуализировать больше данных, но они не будут использовать выборку.
Эти параметры гарантируют, что визуальные элементы в Power BI Desktop быстро отображаются, реагируют на взаимодействие с пользователями и не приводят к чрезмерной вычислительной нагрузке на компьютер, отрисовывая визуальный элемент.
Оценка репрезентативных точек данных для визуальных элементов с высокой плотностью
Когда количество базовых точек данных превышает максимальное количество точек данных, которые могут быть представлены в визуальном элементе, начинается процесс, называемый binning . Binning блокирует базовые данные в группы, называемые ячейками , а затем итеративно уточняет эти ячейки.
Алгоритм создает максимальное количество ячеек, чтобы создать максимальную степень детализации для визуального элемента. В каждой ячейке алгоритм находит минимальное и максимальное значение данных, чтобы гарантировать, что важные и значимые значения, такие как выпадающие, фиксируются и отображаются в визуальном элементе. На основе результатов привязки и последующей оценки данных с помощью Power BI определяется минимальное разрешение оси x для визуального элемента, чтобы обеспечить максимальную степень детализации для визуального элемента.
Как упоминание ранее, минимальная степень детализации для каждой серии составляет 350 точек, а максимальное — 3500 для большинства визуальных элементов. Исключения перечислены в предыдущих абзацах.
Каждая ячейка представлена двумя точками данных, которые становятся репрезентативными точками данных в визуальном элементе. Точки данных являются высоким и низким значением для этой ячейки. Выбрав высокий и низкий, процесс бинирования гарантирует, что любое важное значение или значительное низкое значение фиксируется и отрисовывается в визуальном элементе.
Если это звучит как много анализа, чтобы убедиться, что случайные выбросы фиксируются и правильно отображаются в визуальном элементе, вы правильно. Именно поэтому алгоритм и процесс бинирования.
Подсказки и выборка линии высокой плотности
Важно отметить, что этот процесс бинирования, который приводит к минимальному и максимальному значению в заданном контейнере, который фиксируется и отображается, может повлиять на отображение подсказок данных при наведении указателя на точки данных. Чтобы объяснить, как и почему это происходит, давайте рассмотрим наш пример о ценах на акции.
Предположим, вы создаете визуальный элемент на основе цены на акции, и вы сравниваете две разные акции, оба из которых используют выборку с высокой плотностью. Базовые данные для каждой серии имеют множество точек данных. Например, может быть, вы захватываете цену акций каждую секунду дня. Алгоритм выборки линии высокой плотности выполняет объединение для каждой серии независимо от другой.
Теперь давайте скажем, что первые акции прыгают в цене на 12:02, а затем быстро вернется вниз 10 секунд спустя. Это важная точка данных. При возникновении бинирования для этого запаса высокий показатель в 12:02 является репрезентативной точкой данных для этого контейнера.
Тем не менее, для второй акции, 12:02 не было высоким или низким в корзине, которая включала это время. Может быть, высокий и низкий для корзины, которая включает 12:02 произошла три минуты спустя. В этой ситуации при создании линейной диаграммы и наведении указателя мыши на 12:02 вы увидите значение в подсказке для первой акции. Это связано с тем, что оно перескочило в 12:02, и это значение было выбрано в качестве высокой точки данных. Тем не менее, вы не увидите никакое значение в подсказке в 12:02 для второй акции. Это потому, что второй акции не имели высокой или низкой для корзины, которая включала 12:02. Таким образом, данные для второго запаса не отображаются в 12:02, поэтому всплывающие подсказки не отображаются.
Эта ситуация часто происходит с подсказками. Высокие и низкие значения для определенного ячейки, вероятно, не будут соответствовать идеально с равномерно масштабируемыми точками значений оси x, а подсказка не отображает значение.
Включение выборки линии высокой плотности
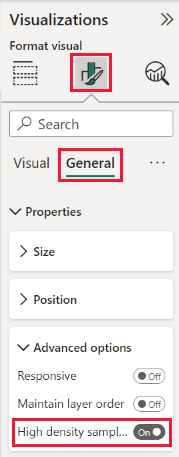
По умолчанию алгоритм включен. Чтобы изменить этот параметр, перейдите в область форматирования, в разделе "Общие карта" и в нижней части экрана вы увидите ползунок выборки с высокой плотностью. Выберите ползунок, чтобы включить или отключить.
Рекомендации и ограничения
Алгоритм выборки линии высокой плотности является важным улучшением Power BI, но при работе с значениями и данными с высокой плотностью необходимо знать несколько рекомендаций.
Из-за повышенной детализации и процесса бинирования подсказки могут отображаться только в том случае, если репрезентативные данные выровнены с курсором. Дополнительные сведения см. в разделе "Подсказки" и "Выборка линий с высокой плотностью" в этой статье.
Если размер общего источника данных слишком велик, алгоритм устраняет ряды (элементы условных обозначений), чтобы обеспечить максимальное ограничение импорта данных.
- В этой ситуации алгоритм упорядочивает ряд условных обозначений по алфавиту, начиная со списка элементов условных обозначений в алфавитном порядке до достижения максимального значения импорта данных и не импортирует больше рядов.
Если базовый набор данных имеет более 60 рядов, максимальное число рядов, алгоритм упорядочивает ряд в алфавитном порядке и устраняет ряды за пределами 60-й алфавитно упорядоченной серии.
Если значения в данных не являются числовыми или числовыми или датами и временем, Power BI не будет использовать алгоритм и будет отменить изменения к предыдущему алгоритму выборки с высокой плотностью.
Отображение элементов без параметра данных не поддерживается алгоритмом.
Алгоритм не поддерживается при использовании динамического подключения к модели, размещенной в СЛУЖБАх SQL Server Analysis Services версии 2016 или более ранней. Она поддерживается в моделях, размещенных в Power BI или Azure Analysis Services.