Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Замечание
Уровни конфиденциальности в настоящее время недоступны в потоках данных Power Platform, но команда продуктов работает над включением этой функции.
Если вы использовали Power Query какое-то время, то, скорее всего, уже сталкивались с этим. Вот вы, проводите запросы, когда внезапно возникает ошибка, которую никакие поисковые запросы в Интернете, изменения в запросах или энергичное нажатие клавиш не могут исправить. Ошибка, например:
Formula.Firewall: Query 'Query1' (step 'Source') references other queries or steps, so it may not directly access a data source. Please rebuild this data combination.
Или может быть:
Formula.Firewall: Query 'Query1' (step 'Source') is accessing data sources that have privacy levels which cannot be used together. Please rebuild this data combination.
Эти Formula.Firewall ошибки являются результатом брандмауэра конфиденциальности данных Power Query (также известного как брандмауэр), который иногда может показаться, что он существует исключительно для разочарования аналитиков данных во всем мире. Поверите или нет, но брандмауэр выполняет важную функцию. В этой статье мы углубимся под капотом, чтобы лучше понять, как это работает. Вооружившись более большим пониманием, вы, надеюсь, сможете лучше диагностировать и устранять ошибки брандмауэра в будущем.
Что это такое?
Цель брандмауэра конфиденциальности данных проста: она существует, чтобы предотвратить непреднамеренно утечку данных между источниками Power Query.
Почему? Я имею в виду, вы, безусловно, можете написать код на M, который будет передавать значение SQL в канал OData. Но это было бы преднамеренной утечкой данных. Автор mashup (или, по крайней мере, должен) знать, что он это делает. Почему тогда необходимость защиты от непреднамеренной утечки данных?
Ответ? Складной.
Складной?
Свертывание — это термин, который относится к преобразованию выражений в M (например, фильтры, переименования, соединения и т. д.) в операции для применения к необработанному источнику данных (например, SQL, OData и т. д.). Огромная часть возможностей Power Query исходит от того, что Power Query может преобразовать операции, выполняемые пользователем через его пользовательский интерфейс в сложные языки SQL или других внутренних языков источника данных, без необходимости знать указанные языки. Пользователи получают преимущество производительности собственных операций источника данных с легкостью использования пользовательского интерфейса, где все источники данных можно преобразовать с помощью общего набора команд.
В рамках преобразования Power Query иногда может определить, что наиболее эффективный способ выполнения данного mashup заключается в передаче данных из одного источника другому. Например, если вы присоединяете небольшой CSV-файл к огромной таблице SQL, вы, вероятно, не хотите, чтобы Power Query считывал CSV-файл, считывал всю таблицу SQL, а затем объединять их вместе на локальном компьютере. Вероятно, вы хотите, чтобы Power Query встроит данные CSV в инструкцию SQL и попросите базу данных SQL выполнить присоединение.
Это то, как может произойти непреднамеренное утечка данных.
Представьте, что вы объединяли данные SQL, которые включали Социальные номера сотрудников, с результатами внешнего канала OData, и вдруг обнаружили, что Социальные номера из SQL отправляются в сервис OData. Плохие новости, да?
Это тип сценария, который брандмауэр предназначен для предотвращения.
Как это работает?
Брандмауэр существует, чтобы предотвратить непреднамеренные отправки данных из одного источника в другой источник. Достаточно просто.
Так как он выполняет эту миссию?
Это делается путем разделения запросов M на нечто называемое секциями, а затем применив следующее правило:
- Раздел может получить доступ к совместимым источникам данных или ссылаться на другие разделы, но не одновременно.
Простой... тем не менее, запутанный. Что такое раздел? Что делает два источника данных совместимыми? И почему брандмауэру должно быть важно, если раздел хочет получить доступ к источнику данных и ссылаться на другой раздел?
Давайте разберем это и рассмотрим предыдущее правило за раз.
Что такое раздел?
На самом базовом уровне раздел — это просто совокупность одного или нескольких этапов запроса. Наиболее детализированное деление (по крайней мере в текущей реализации) состоит из одной операции. Крупнейшие разделы иногда включают несколько запросов. (Подробнее об этом позже.)
Если вы не знакомы с действиями, их можно просмотреть справа от окна редактора Power Query после выбора запроса на панели "Примененные шаги ". Этапы отслеживают все, что вы делаете для преобразования данных в их окончательную форму.
Разделы, ссылающиеся на другие секции
При оценке запроса с помощью брандмауэра брандмауэр разделяет запрос и все его зависимости на секции (то есть группы шагов). В любой момент, когда одна секция ссылается на что-то в другой секции, брандмауэр заменяет ссылку вызовом специальной функции Value.Firewall. Другими словами, брандмауэр не позволяет секциям напрямую обращаться друг к другу. Все ссылки изменяются для прохождения через брандмауэр. Подумайте о брандмауэре как о привратнике. Раздел, ссылающийся на другую секцию, должен получить разрешение брандмауэра для этого, и брандмауэр определяет, разрешены ли ссылки на эти данные в секцию.
Все это может показаться довольно абстрактным, поэтому рассмотрим пример.
Предположим, что у вас есть запрос с именем Employees, который извлекает некоторые данные из базы данных SQL. Предположим, что у вас также есть другой запрос (EmployeesReference), который просто ссылается на сотрудников.
shared Employees = let
Source = Sql.Database(…),
EmployeesTable = …
in
EmployeesTable;
shared EmployeesReference = let
Source = Employees
in
Source;
Эти запросы в конечном итоге разделены на два раздела: один для запроса Employees и один для запроса EmployeesReference (который ссылается на раздел Employees). При оценке брандмауэра эти запросы перезаписываются следующим образом:
shared Employees = let
Source = Sql.Database(…),
EmployeesTable = …
in
EmployeesTable;
shared EmployeesReference = let
Source = Value.Firewall("Section1/Employees")
in
Source;
Обратите внимание, что простая ссылка на запрос Employees заменяется вызовом Value.Firewall, в который передаётся полное имя запроса Employees.
При оценке EmployeesReference брандмауэр перехватывает вызов Value.Firewall("Section1/Employees"), который теперь может контролировать, будет ли (и как) запрашиваемая информация поступать в раздел EmployeesReference. Это может выполнить множество действий: запретить запрос, буферизовать запрошенные данные (что предотвращает дальнейшее объединение с исходным источником) и т. д.
Это то, как брандмауэр поддерживает контроль над потоком данных между секциями.
Секции, которые напрямую обращаются к источникам данных
Предположим, что вы определите запрос Query1 с одним шагом (обратите внимание, что этот одношаговый запрос соответствует одному разделу брандмауэра), и что этот один шаг обращается к двум источникам данных: таблице базы данных SQL и CSV-файлу. Как брандмауэр справляется с этим, если нет ссылки на раздел и, следовательно, вызова к Value.Firewall для его перехвата? Давайте рассмотрим правило, указанное ранее:
- Секция может получить доступ к совместимым источникам данных или ссылаться на другие секции, но не оба.
Чтобы разрешить выполнение запроса с одним разделом, но двумя источниками данных, два источника данных должны быть совместимыми. Другими словами, между ними должно быть обеспечено двунаправленное обмен данными. Это означает, что уровни конфиденциальности обоих источников должны быть общедоступными или организационными, так как это единственные два сочетания, которые позволяют обмениваться данными в обоих направлениях. Если оба источника помечены как частные, либо один помечен как общедоступный, и один помечен как организационный, либо они помечены с помощью другого сочетания уровней конфиденциальности, то двунаправленный общий доступ не допускается. Им небезопасно проходить оценку вместе в одном разделе. Это означает, что утечка небезопасных данных может произойти (из-за свертывания), и брандмауэр не сможет предотвратить его.
Что произойдет, если вы пытаетесь получить доступ к несовместимным источникам данных в той же секции?
Formula.Firewall: Query 'Query1' (step 'Source') is accessing data sources that have privacy levels which cannot be used together. Please rebuild this data combination.
Надеюсь, теперь вы лучше понимаете одно из сообщений об ошибках, перечисленных в начале этой статьи.
Это требование совместимости применяется только в заданной секции . Если секция ссылается на другие секции, источники данных из ссылочных секций не должны быть совместимы друг с другом. Это связано с тем, что брандмауэр может буферизовать данные, что предотвращает дальнейшее агрегирование данных от исходного источника данных. Данные загружаются в память и обрабатываются так, как если бы они не были нигде.
Почему бы не сделать и то, и другое?
Предположим, что вы определите запрос с одним шагом (который снова соответствует одному разделу), который обращается к двум другим запросам (т. е. двум другим секциям). Что если вы хотите на том же этапе также напрямую получить доступ к базе данных SQL? Почему не удается ссылаться на другие секции и напрямую обращаться к совместимым источникам данных?
Как вы видели ранее, когда один раздел ссылается на другой раздел, брандмауэр выступает в качестве контролера для всех данных, поступающих в раздел. Чтобы сделать это, он должен иметь возможность контролировать, какие данные допускаются. Если в разделе осуществляется доступ к источникам данных, а данные поступают из других разделов, он теряет свою способность быть привратником, поскольку входящие данные могут утекать в один из внутренних источников данных без уведомления. Таким образом, брандмауэр предотвращает возможность раздела, который обращается к другим разделам, непосредственно получать доступ к любым источникам данных.
Так что происходит, если секция пытается ссылаться на другие секции, а также напрямую обращаться к источникам данных?
Formula.Firewall: Query 'Query1' (step 'Source') references other queries or steps, so it may not directly access a data source. Please rebuild this data combination.
Теперь вы надеемся лучше понять другое сообщение об ошибке, указанное в начале этой статьи.
Подробные сведения о разделах
Как вы, вероятно, можете предположить из предыдущей информации, то, как происходит разделение запросов, оказывается невероятно важным. Если у вас есть шаги, ссылающиеся на другие запросы, и шаги, которые обращаются к источникам данных, вы можете осознать, что определение границ раздела в определенных местах приводит к ошибкам брандмауэра, в то время как их определение в других местах позволяет выполнять запрос без проблем.
Так как именно запросы будут секционированы?
Этот раздел, вероятно, является наиболее важным для понимания причин возникновения ошибок брандмауэра и понимания их разрешения (где это возможно).
Общая сводка логики разделения.
- Начальное секционирование
- Создает раздел для каждого шага в каждом запросе
- Статический этап
- Этот этап не зависит от результатов оценки. Вместо этого он зависит от структуры запросов.
- Обрезка параметров
- Обрезает разделы, похожие на параметры, т. е. любой из них:
- Не ссылается на другие разделы
- Не содержит вызовов функций
- Не циклический (т. е. он не относится к себе)
- Обратите внимание, что "удаление" раздела эффективно означает, что он включается в любые другие разделы, ссылающиеся на него.
- Разделение параметров позволяет ссылкам на параметры, используемые в вызовах функций источника данных (например,
Web.Contents(myUrl)), работать, а не вызывать ошибки "секции не могут ссылаться на источники данных и другие шаги".
- Обрезает разделы, похожие на параметры, т. е. любой из них:
- Группирование (статический)
- Разделы объединяются в порядке возрастания зависимости. В объединённых разделах, следующие остаются отдельными:
- Разделы в разных запросах
- Секции, которые не ссылаются на другие секции (и которым таким образом разрешён доступ к источнику данных)
- Разделы, ссылающиеся на другие разделы (и поэтому имеют запрещённый доступ к источнику данных)
- Разделы объединяются в порядке возрастания зависимости. В объединённых разделах, следующие остаются отдельными:
- Обрезка параметров
- Этот этап не зависит от результатов оценки. Вместо этого он зависит от структуры запросов.
- Динамический этап
- Этот этап зависит от результатов оценки, включая сведения о источниках данных, к которым обращается различные секции.
- Обрезка
- Тримминг разделов, которые соответствуют всем следующим требованиям:
- Не обращается к источникам данных
- Не ссылается на разделы, которые обращаются к источникам данных
- Не циклический
- Тримминг разделов, которые соответствуют всем следующим требованиям:
- Группирование (динамическое)
- Теперь, когда ненужные секции обрезаются, попробуйте создать исходные секции, которые максимально большие. Это создание выполняется путем объединения секций с использованием одинаковых правил, описанных на предыдущем этапе статической группировки.
Что означает все это?
Давайте рассмотрим один пример, чтобы показать, как работает сложная логика, описанная ранее.
Ниже приведен пример сценария. Это довольно простое слияние текстового файла (контакты) с базой данных SQL (сотрудники), где СЕРВЕР SQL является параметром (DbServer).
Три запроса
Ниже приведен код M для трех запросов, используемых в этом примере.
shared DbServer = "MySqlServer" meta [IsParameterQuery=true, Type="Text", IsParameterQueryRequired=true];
shared Contacts = let
Source = Csv.Document(File.Contents(
"C:\contacts.txt"),[Delimiter=" ", Columns=15, Encoding=1252, QuoteStyle=QuoteStyle.None]
),
#"Promoted Headers" = Table.PromoteHeaders(Source, [PromoteAllScalars=true]),
#"Changed Type" = Table.TransformColumnTypes(
#"Promoted Headers",
{
{"ContactID", Int64.Type},
{"NameStyle", type logical},
{"Title", type text},
{"FirstName", type text},
{"MiddleName", type text},
{"LastName", type text},
{"Suffix", type text},
{"EmailAddress", type text},
{"EmailPromotion", Int64.Type},
{"Phone", type text},
{"PasswordHash", type text},
{"PasswordSalt", type text},
{"AdditionalContactInfo", type text},
{"rowguid", type text},
{"ModifiedDate", type datetime}
}
)
in
#"Changed Type";
shared Employees = let
Source = Sql.Databases(DbServer),
AdventureWorks = Source{[Name="AdventureWorks"]}[Data],
HumanResources_Employee = AdventureWorks{[Schema="HumanResources",Item="Employee"]}[Data],
#"Removed Columns" = Table.RemoveColumns(
HumanResources_Employee,
{
"HumanResources.Employee(EmployeeID)",
"HumanResources.Employee(ManagerID)",
"HumanResources.EmployeeAddress",
"HumanResources.EmployeeDepartmentHistory",
"HumanResources.EmployeePayHistory",
"HumanResources.JobCandidate",
"Person.Contact",
"Purchasing.PurchaseOrderHeader",
"Sales.SalesPerson"
}
),
#"Merged Queries" = Table.NestedJoin(
#"Removed Columns",
{"ContactID"},
Contacts,
{"ContactID"},
"Contacts",
JoinKind.LeftOuter
),
#"Expanded Contacts" = Table.ExpandTableColumn(
#"Merged Queries",
"Contacts",
{"EmailAddress"},
{"EmailAddress"}
)
in
#"Expanded Contacts";
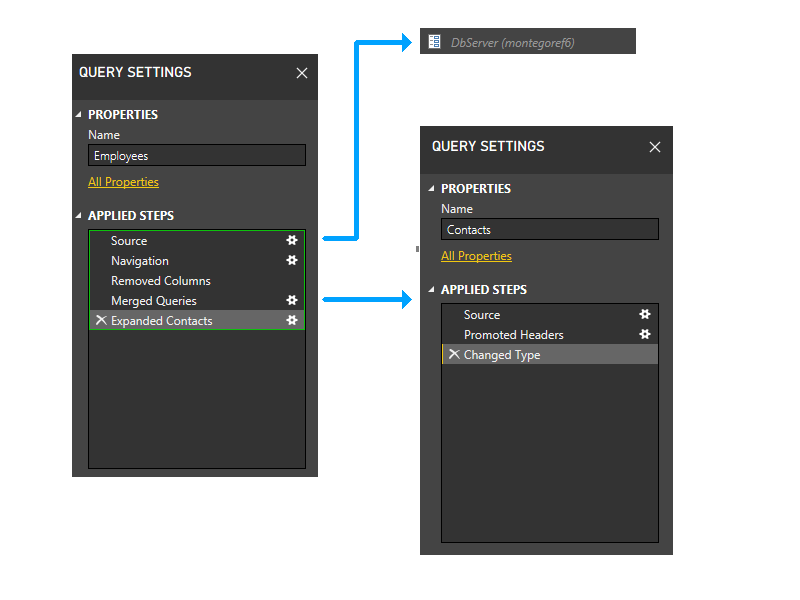
Ниже приведено представление более высокого уровня, показывающее зависимости.
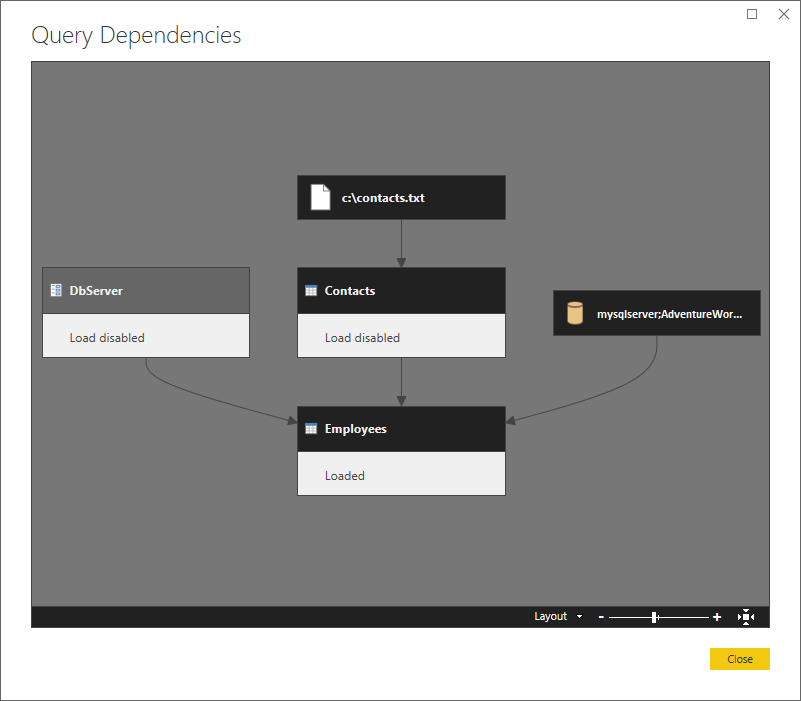
Давайте секционируем
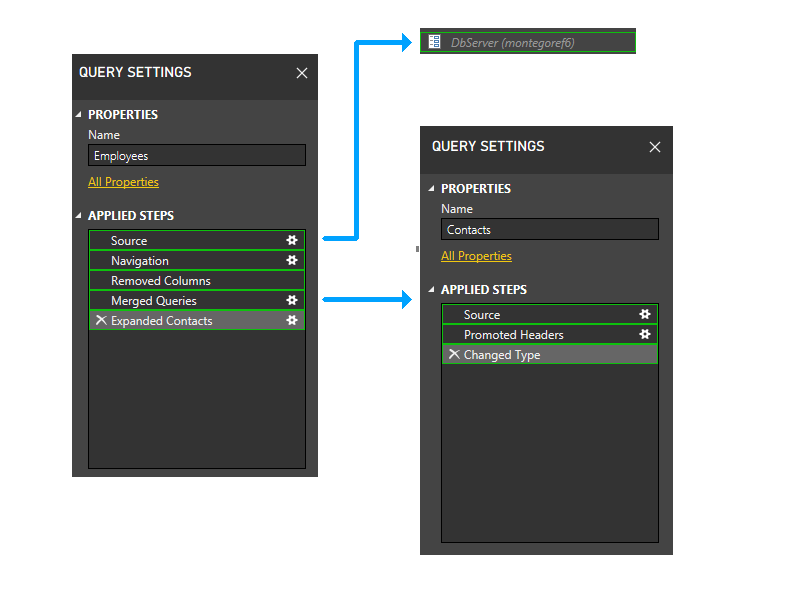
Давайте немного масштабируем и добавим шаги в рисунок и начнем с логики секционирования. Ниже приведена схема трех запросов, показывающая начальные секции брандмауэра зеленым цветом. Обратите внимание, что каждый шаг начинается в отдельном разделе.
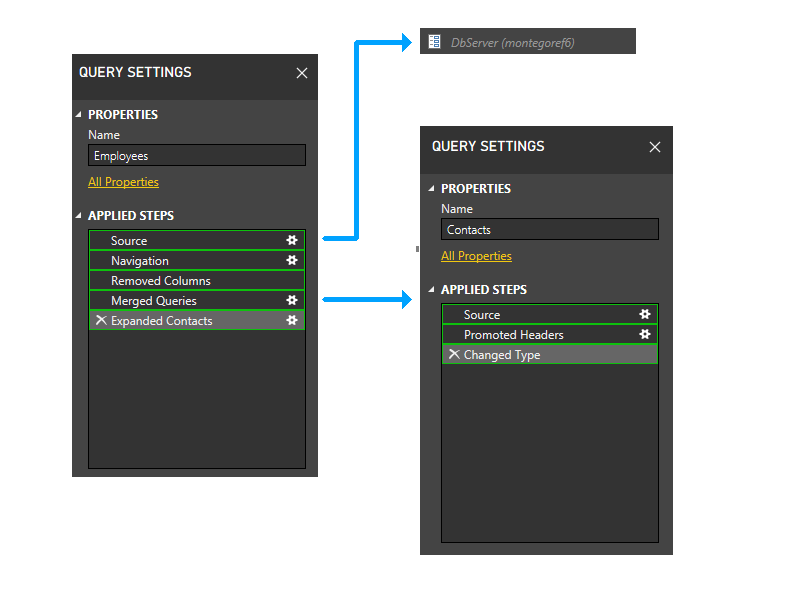
Затем мы обрезаем секции параметров. Таким образом, DbServer неявно включается в раздел Source.
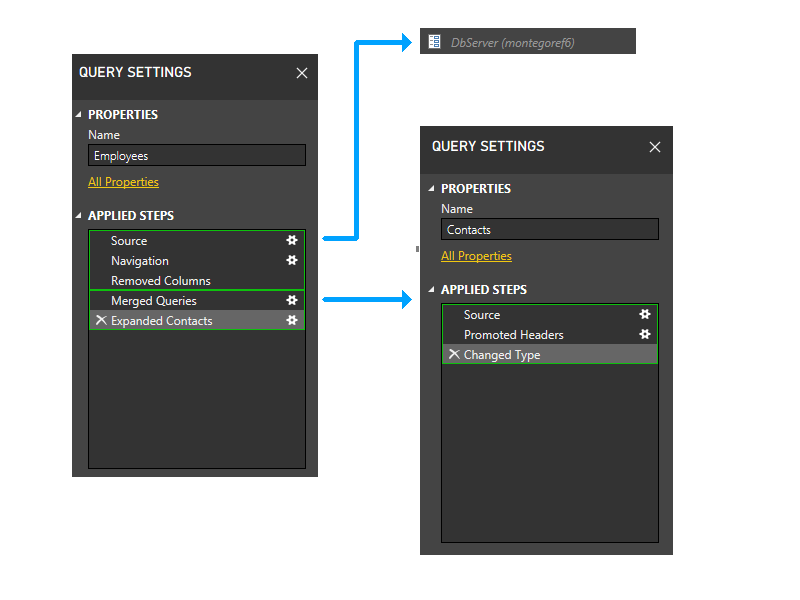
Теперь мы выполняем статическую группировку. Эта группировка поддерживает разделение между разделами в отдельных запросах (обратите внимание, например, что последние два этапа сотрудников не объединяются с этапами контактов), а также между разделами, которые ссылаются на другие разделы (например, последние два этапа сотрудников), и теми, которые не ссылаются (например, первые три этапа сотрудников).
Теперь мы входим в динамический этап. На этом этапе оцениваются вышеупомянутые статические секции. Секции, не имеющие доступа к источникам данных, обрезаются. Затем разделы группируются для создания исходных разделов максимально возможного размера. Однако в этом примере все оставшиеся разделы получают доступ к источникам данных, и невозможно выполнить дополнительную группировку. Секции в нашем примере, таким образом, не изменяются на этом этапе.
Давайте притворимся
Для иллюстрации, однако, давайте рассмотрим, что произойдет, если запрос "Контакты", а не из текстового файла, был жестко закодирован в M (возможно, через диалоговое окно ввод данных ).
В этом случае запрос "Контакты" не будет получать доступ к источникам данных. Таким образом, она будет сокращена во время первой стадии динамичного этапа.
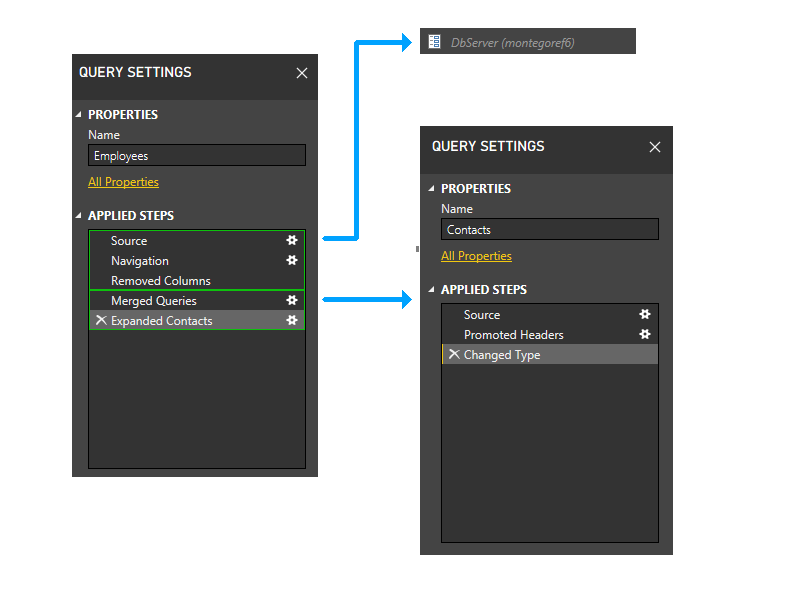
После удаления раздела "Контакты" последние два шага "Employees" больше не будут ссылаться на разделы, кроме раздела, содержащего первые три шага "Employees". Таким образом, два раздела будут сгруппированы.
Результирующий раздел будет выглядеть следующим образом.
Пример. Передача данных из одного источника данных в другой
Хорошо, достаточно абстрактного объяснения. Давайте рассмотрим распространенный сценарий, в котором, скорее всего, возникает ошибка брандмауэра и действия по ее устранению.
Представьте, что вы хотите найти имя компании из службы Northwind OData, а затем использовать имя компании для поиска Bing.
Сначала вы создадите запрос компании для получения имени компании.
let
Source = OData.Feed(
"https://services.odata.org/V4/Northwind/Northwind.svc/",
null,
[Implementation="2.0"]
),
Customers_table = Source{[Name="Customers",Signature="table"]}[Data],
CHOPS = Customers_table{[CustomerID="CHOPS"]}[CompanyName]
in
CHOPS
Затем вы создадите запрос поиска , который ссылается на компанию и передает его в Bing.
let
Source = Text.FromBinary(Web.Contents("https://www.bing.com/search?q=" & Company))
in
Source
На этом этапе возникают проблемы. При оценке поиска возникает ошибка брандмауэра.
Formula.Firewall: Query 'Search' (step 'Source') references other queries or steps, so it may not directly access a data source. Please rebuild this data combination.
Эта ошибка возникает, так как исходный шаг поиска ссылается на источник данных (bing.com), а также ссылается на другой запрос или секцию (компания). Это нарушает ранее указанное правило ("раздел может получить доступ к совместимым источникам данных или ссылаться на другие разделы, но не оба одновременно").
Что делать? Одним из вариантов является отключение брандмауэра (с помощью параметра "Конфиденциальность" с меткой "Игнорировать уровни конфиденциальности" и потенциально повысить производительность). Но что делать, если вы хотите оставить брандмауэр включено?
Чтобы устранить ошибку без отключения брандмауэра, можно объединить компанию и поиск в один запрос, как показано ниже.
let
Source = OData.Feed(
"https://services.odata.org/V4/Northwind/Northwind.svc/",
null,
[Implementation="2.0"]
),
Customers_table = Source{[Name="Customers",Signature="table"]}[Data],
CHOPS = Customers_table{[CustomerID="CHOPS"]}[CompanyName],
Search = Text.FromBinary(Web.Contents("https://www.bing.com/search?q=" & CHOPS))
in
Search
Все происходит внутри одной секции. Предположим, что уровни конфиденциальности для двух источников данных совместимы, межсетевой экран теперь должен функционировать корректно, и вы больше не будете сталкиваться с ошибками.
Это завершение
Хотя есть гораздо больше, что можно сказать по этой теме, эта вводная статья уже достаточно длинна. Надеюсь, это дает вам лучшее понимание брандмауэра и помогает понять и исправить ошибки брандмауэра при их возникновении в будущем.