Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Простота и простота использования, которая позволяет пользователям Power BI быстро собирать данные и создавать интересные и мощные отчеты, чтобы принимать интеллектуальные бизнес-решения, также позволяет пользователям легко создавать плохо выполняемые запросы. Это часто происходит, когда есть две таблицы, которые связаны между собой, как это бывает с внешними ключами в таблицах SQL или списках SharePoint. (Для записи эта проблема не относится к SQL или SharePoint и возникает во многих сценариях извлечения внутренних данных, особенно в тех случаях, когда схема является гибкой и настраиваемой.) Кроме того, нет ничего неправильного в хранении данных в отдельных таблицах, которые совместно используют общий ключ. На самом деле это фундаментальный принцип проектирования и нормализации базы данных. Но это означает лучший способ расширения отношений.
Рассмотрим следующий пример списка клиентов SharePoint.
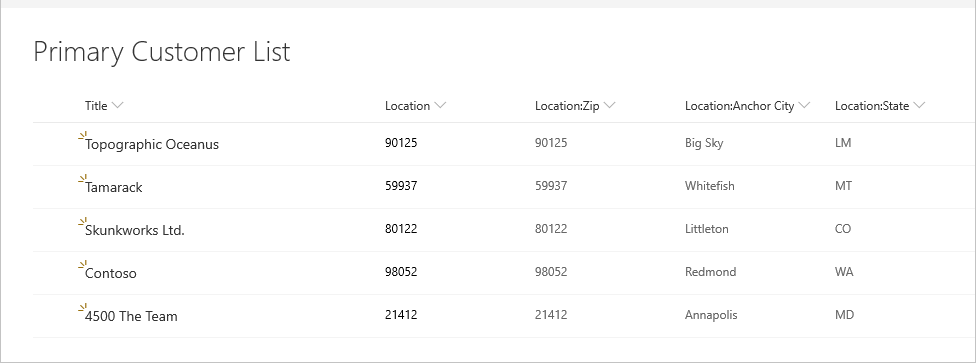
В следующем списке мест, на который он ссылается.
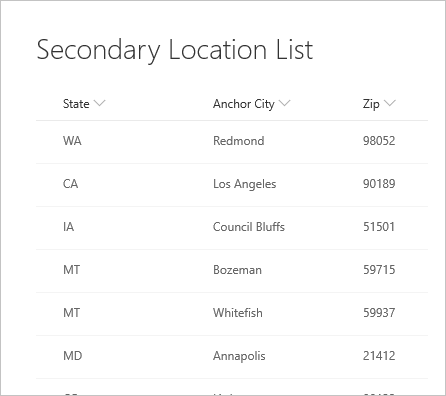
При первом подключении к списку местоположение отображается в виде записи.
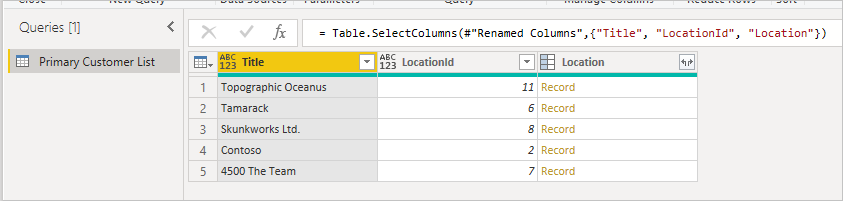
Эти данные верхнего уровня собираются через один http-вызов API SharePoint (игнорируя вызов метаданных), который можно увидеть в любом веб-отладчике.

При развертывании записи вы увидите поля, присоединенные из вторичной таблицы.
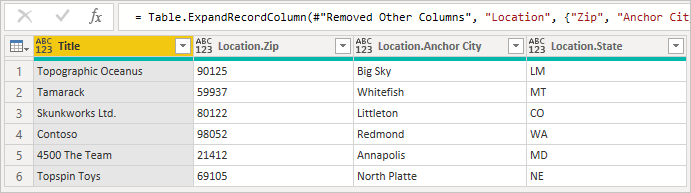
При расширении связанных строк из одной таблицы в другую поведение по умолчанию Power BI заключается в создании вызова Table.ExpandTableColumn. Это можно увидеть в поле созданной формулы. К сожалению, этот метод создает отдельный вызов второй таблицы для каждой строки в первой таблице.
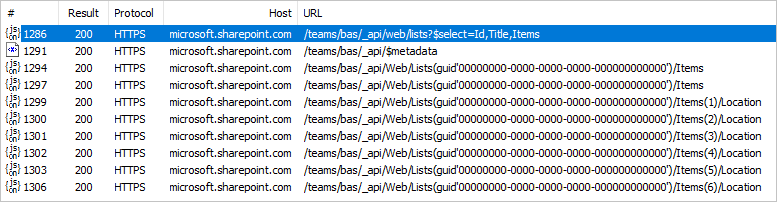
Это увеличивает количество http-вызовов по одному для каждой строки в основном списке. Это может показаться не так много в приведенном выше примере из пяти или шести строк, но в рабочих системах, где списки SharePoint достигают сотен тысяч строк, это может привести к значительному снижению производительности.
Когда запросы достигают этого узкого места, лучше всего избежать вызова для каждой строки с помощью классического соединения таблицы. Это гарантирует, что вызов для получения второй таблицы будет только один, а остальная часть расширения может происходить в памяти с использованием общего ключа между двумя таблицами. Разница в производительности может быть массивной в некоторых случаях.
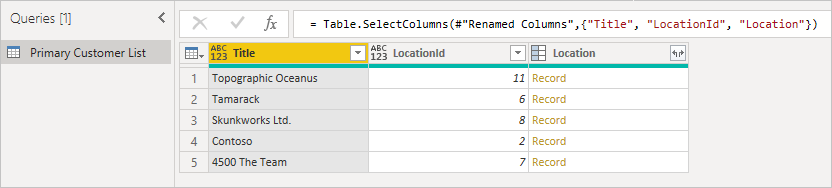
Сначала начните с исходной таблицы, отметив столбец, который вы хотите развернуть, и убедитесь, что у вас есть идентификатор элемента, чтобы его можно было сопоставить. Обычно внешний ключ называется похожим на отображаемое имя столбца с добавленным Id. В этом примере это LocationId.
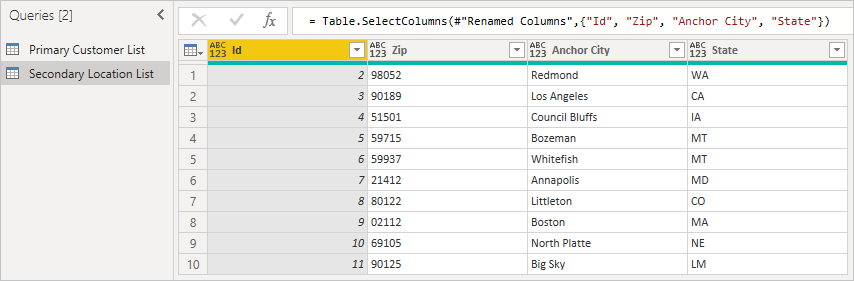
Во-вторых, загрузите вторичную таблицу, включив идентификатор, который является внешним ключом. Щелкните правой кнопкой мыши панель "Запросы", чтобы создать новый запрос.
Наконец, объедините две таблицы, используя совпадающие имена столбцов. Обычно это поле можно найти, сначала развернув столбец, а затем ища соответствующие столбцы в предварительном просмотре.

В этом примере можно увидеть, что LocationId в первичном списке соответствует идентификатору в дополнительном списке. Пользовательский интерфейс переименовывает это в Location.Id , чтобы сделать имя столбца уникальным. Теперь давайте будем использовать эти сведения для слияния таблиц.
Щелкнув правой кнопкой мыши на панели запросов и выбрав Создать запрос>Объединить>Объединить запросы как новый, вы увидите удобный пользовательский интерфейс, который поможет объединить эти два запроса.
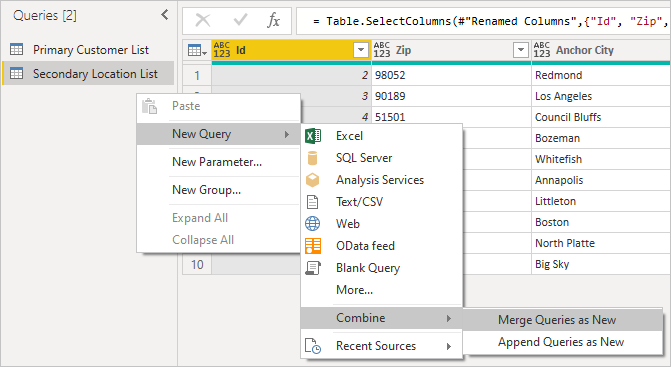
Выберите каждую таблицу из раскрывающегося списка, чтобы просмотреть предварительный просмотр запроса.
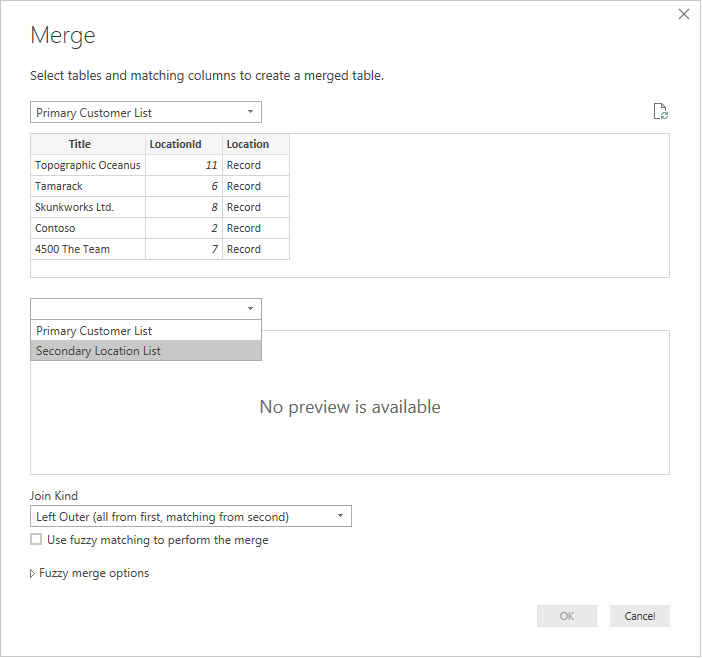
Выбрав обе таблицы, выберите столбец, который объединяет таблицы логически (в этом примере — LocationId из первичной таблицы и идентификатора из вторичной таблицы). Диалоговое окно покажет вам, сколько строк совпадает, используя этот внешний ключ. Скорее всего, вы захотите использовать тип соединения по умолчанию (левый внешний) для таких данных.
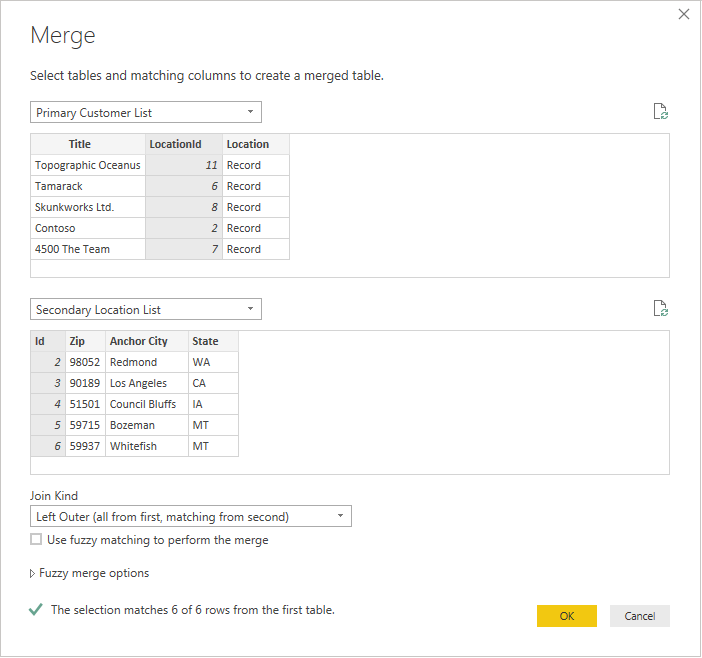
Нажмите кнопку "ОК ", и вы увидите новый запрос, который является результатом соединения. Расширение записи теперь не подразумевает дополнительные вызовы серверной части.

Обновление этих данных приведет только к двум вызовам SharePoint — одному для основного списка и одному для дополнительного списка. Соединение будет выполнено в памяти, значительно уменьшая количество вызовов в SharePoint.
Этот подход можно использовать для любых двух таблиц в PowerQuery, имеющих соответствующий внешний ключ.
Замечание
Списки пользователей SharePoint и таксономия также доступны в виде таблиц и могут быть присоединены точно так же, как описано выше, если у пользователя есть достаточные привилегии для доступа к этим спискам.