Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Фон
В настоящее время модели искусственного интеллекта развиваются, чтобы стать более значительными, что требует увеличения спроса на расширенное оборудование и кластер компьютеров для эффективного обучения моделей. Пакет HPC может упростить эффективную работу по обучению модели.
PyTorch Distributed Data Parallel (aka DDP)
Для реализации обучения распределенной модели необходимо использовать распределенную платформу обучения. Выбор платформы зависит от используемой для сборки модели. В этой статье описано, как продолжить работу с PyTorch в пакете HPC.
PyTorch предлагает несколько методов для распределенного обучения. Среди них распределенная параллельная передача данных (DDP) широко предпочтительна из-за простоты и минимальных изменений кода, необходимых для текущей модели обучения с одним компьютером.
Настройка кластера пакета HPC для обучения модели ИИ
Кластер пакетов HPC можно настроить с помощью локальных компьютеров или виртуальных машин (виртуальных машин) в Azure. Просто убедитесь, что эти компьютеры оснащены графическими процессорами (в этой статье мы будем использовать GPU Nvidia).
Как правило, один GPU может иметь один процесс для распределенной работы обучения. Таким образом, если у вас есть два компьютера (ака узлов в кластере компьютеров), каждый из которых оснащен четырьмя GPU, можно достичь 2 * 4, что равно 8 параллельным процессам для обучения одной модели. Эта конфигурация может сократить время обучения примерно на 1/8 по сравнению с обучением по одному процессу, не указывая некоторые затраты на синхронизацию данных между процессами.
Создание кластера пакета HPC в шаблоне ARM
Для простоты можно запустить новый кластер пакетов HPC в Azure, в шаблонах ARM наGitHub.
Выберите шаблон "Кластер с одним головным узлом для рабочих нагрузок Linux" и нажмите кнопку "Развернуть в Azure"
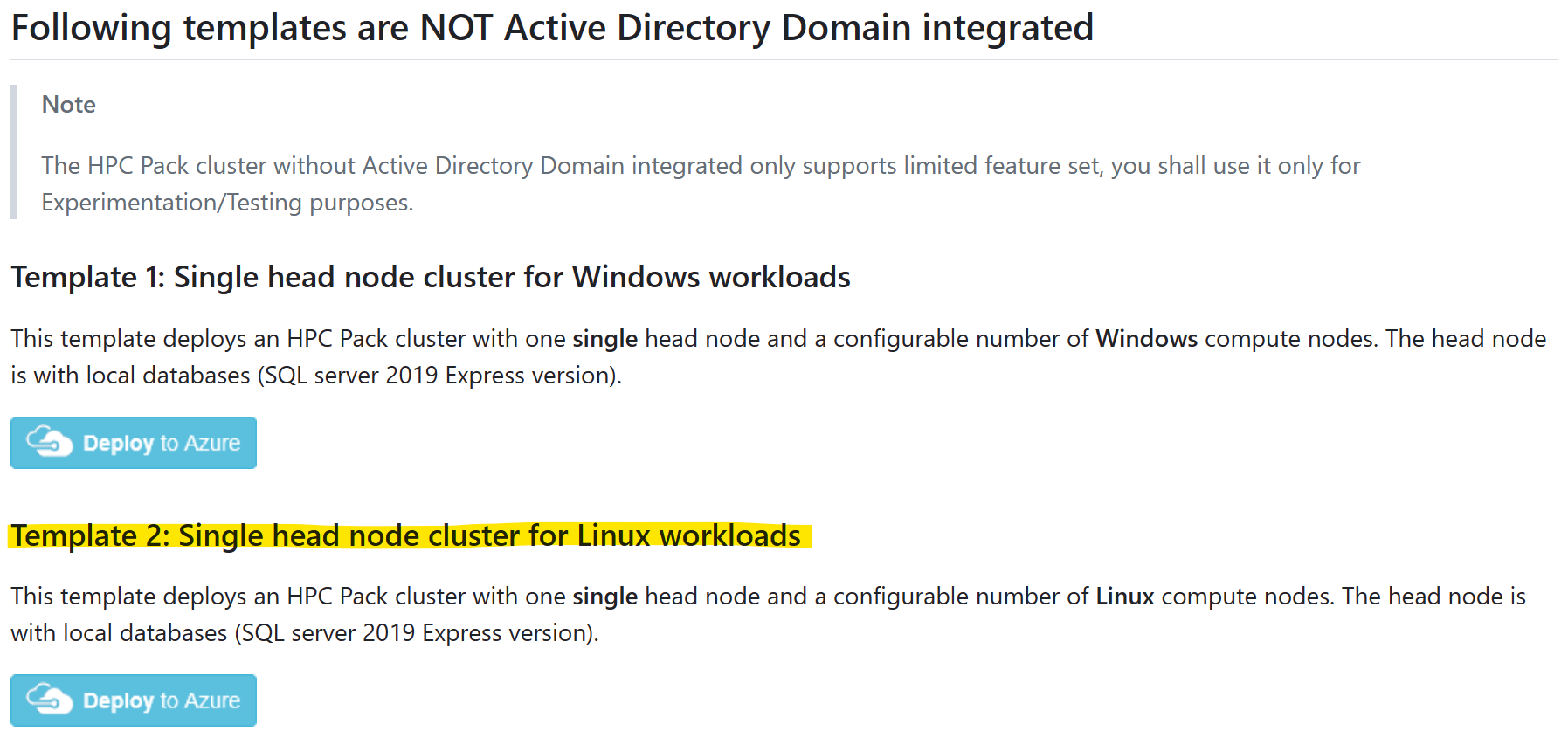
И обратитесь к предварительным требованиям о том, как сделать и отправить сертификат для использования пакета HPC.
Обратите внимание:
Вы должны выбрать образ вычислительного узла, помеченный как HPC. Это означает, что драйверы GPU предварительно установлены на образе. Не удалось это сделать, потребуется вручную установить драйвер GPU на вычислительном узле на более позднем этапе, что может оказаться сложной задачей из-за сложности установки драйвера GPU. Дополнительные сведения об изображениях HPC можно найти здесь.
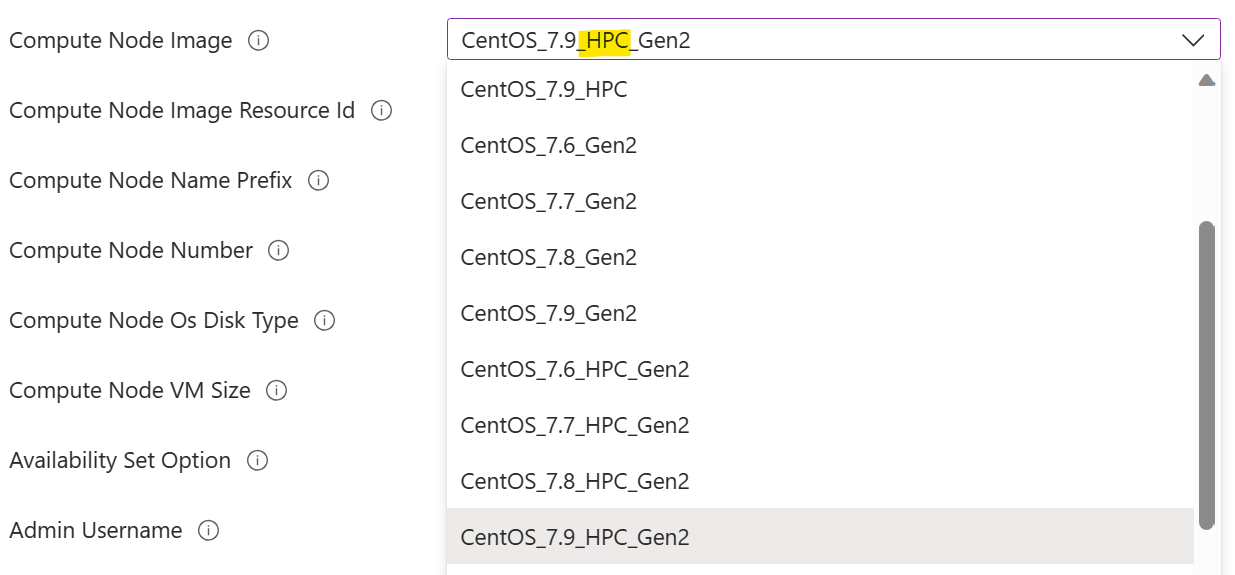
Необходимо выбрать размер виртуальной машины вычислительного узла с GPU. Это размер виртуальной машины серии N.
 GPU
GPU
Установка PyTorch на вычислительных узлах
На каждом вычислительном узле установите PyTorch с помощью команды
pip3 install torch torchvision torchaudio
Советы. Вы можете использовать пакет HPC "Выполнить команду" для параллельного выполнения команды между набором узлов кластера.
Настройка общего каталога
Прежде чем запустить обучающее задание, вам потребуется общий каталог, к которому можно получить доступ всеми вычислительными узлами. Каталог используется для обучения кода и данных (входного набора данных и обученной выходной модели).
Вы можете настроить каталог общего ресурса SMB на головном узле, а затем подключить его к каждому вычислительному узлу с cifs, как показано ниже.
На головном узле сделайте каталог
appв%CCP_DATA%\SpoolDir, который уже используется какCcpSpoolDirпакетом HPC по умолчанию.На вычислительном узле подключите каталог
app, напримерsudo mkdir /app sudo mount -t cifs //<your head node name>/CcpSpoolDir/app /app -o vers=2.1,domain=<hpc admin domain>,username=<hpc admin>,password=<your password>,dir_mode=0777,file_mode=0777ЗАМЕТКА:
- Параметр
passwordможет быть опущен в интерактивной оболочке. Вам будет предложено в этом случае. - Для
dir_modeиfile_modeзадано значение 0777, чтобы любой пользователь Linux смог прочитать и записать его. Разрешение с ограниченным доступом возможно, но более сложно настроить.
- Параметр
При необходимости сделайте подключение постоянно, добавив строку в
/etc/fstab, как//<your head node name>/CcpSpoolDir/app cifs vers=2.1,domain=<hpc admin domain>,username=<hpc admin>,password=<your password>,dir_mode=0777,file_mode=0777 0 2Здесь требуется
password.
Запуск задания обучения
Предположим, теперь у нас есть два вычислительных узла Linux, каждый из которых содержит четыре gpu NVidia версии 100. И мы установили PyTorch на каждом узле. Мы также настроили общий каталог app. Теперь мы можем начать нашу учебную работу.
Здесь я использую простую модель тома, построенную на DDP PyTorch. Вы можете получить код наGitHub.
Скачайте следующие файлы в общий каталог %CCP_DATA%\SpoolDir\app на головном узле
- neural_network.py
- operations.py
- run_ddp.py
Затем создайте задание с node в качестве единицы ресурсов и два узла для задания, например
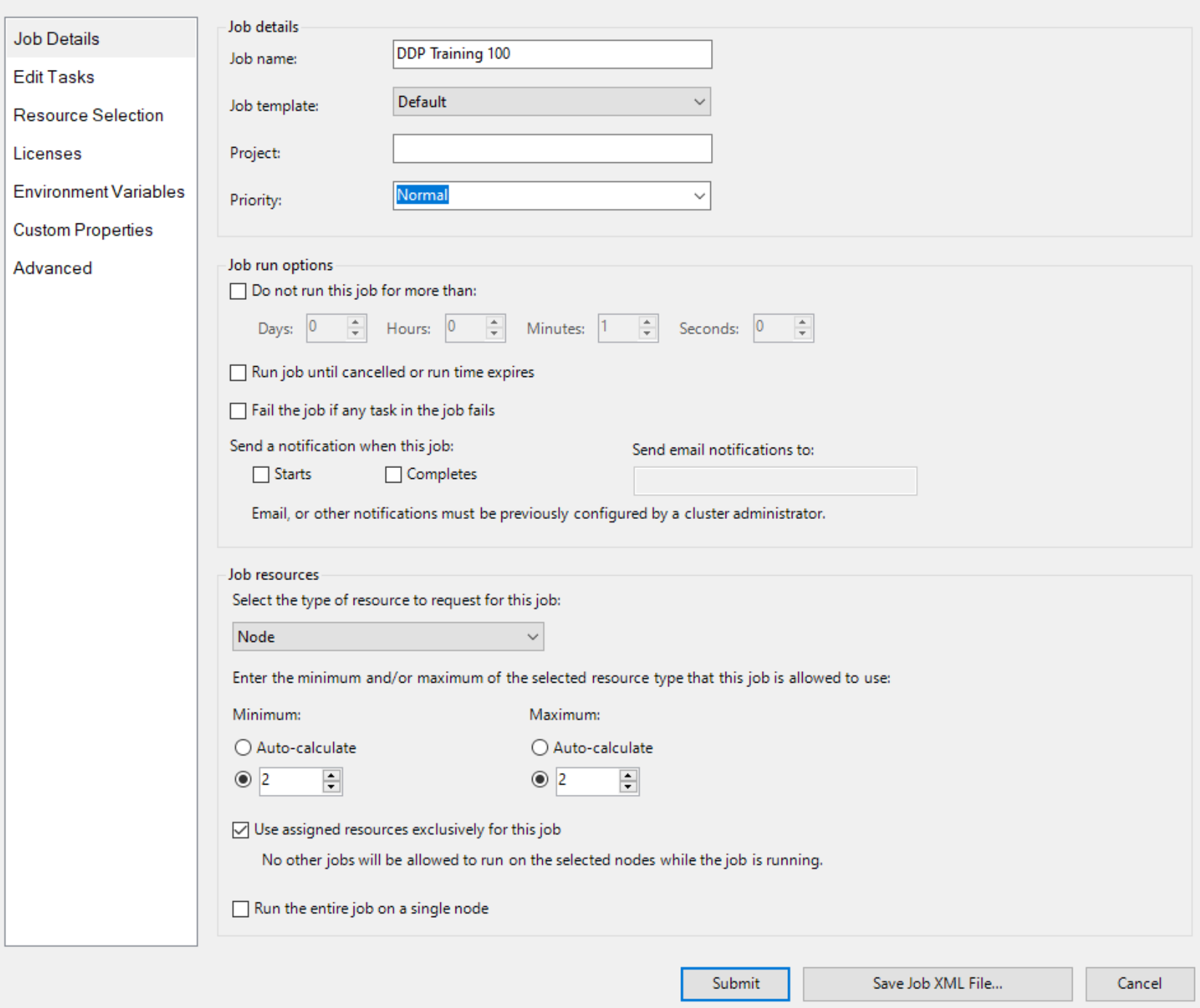
И укажите два узла с GPU явным образом, например
выбора ресурса задания
Затем добавьте задачи задания, например
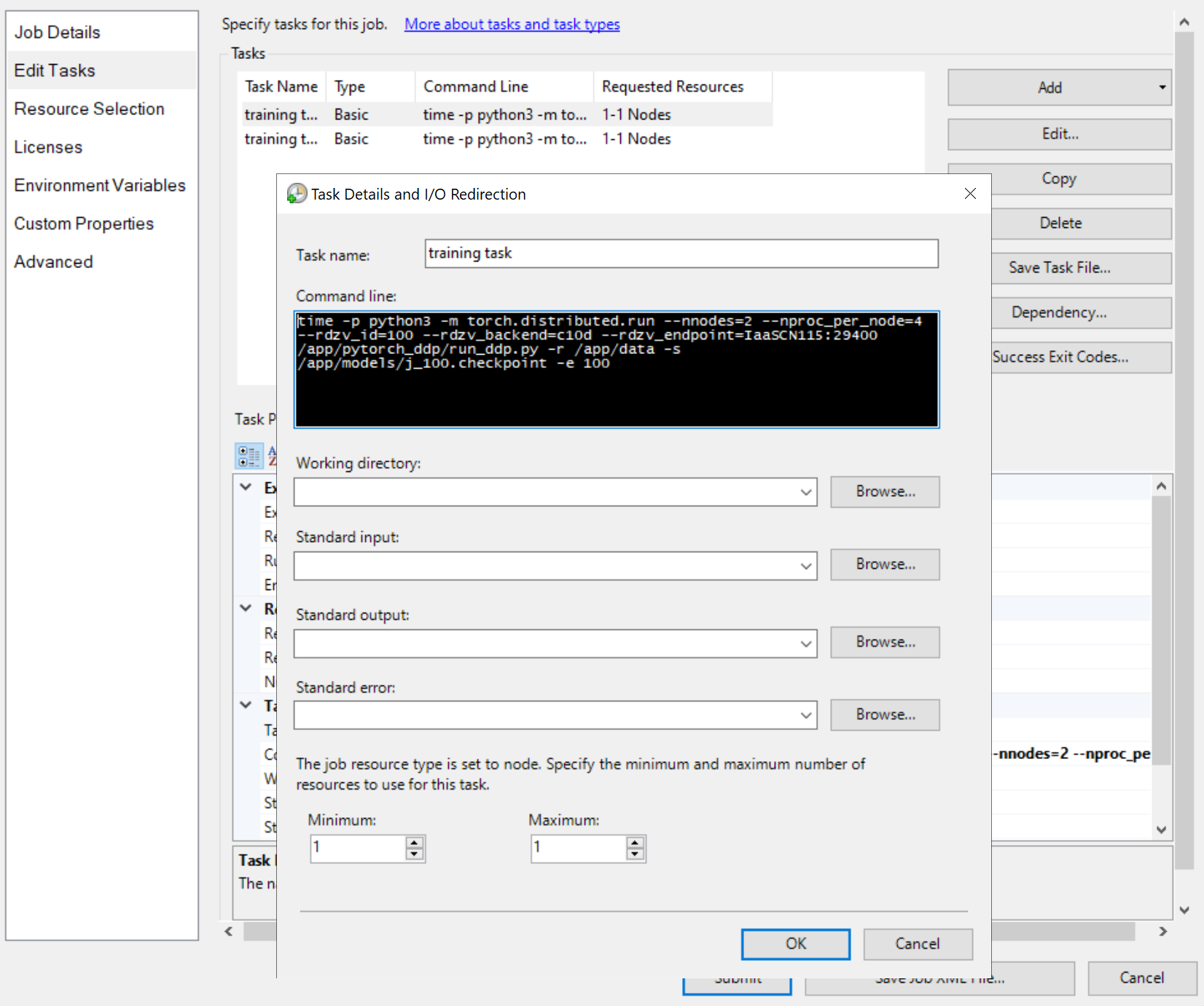
Командные строки задач одинаковы, как и
python3 -m torch.distributed.run --nnodes=<the number of compute nodes> --nproc_per_node=<the processes on each node> --rdzv_id=100 --rdzv_backend=c10d --rdzv_endpoint=<a node name>:29400 /app/run_ddp.py
-
nnodesуказывает количество вычислительных узлов для задания обучения. -
nproc_per_nodeуказывает количество процессов на каждом вычислительном узле. Он не может превышать количество GPU на узле. То есть один GPU может иметь в большинстве случаев один процесс. -
rdzv_endpointуказывает имя и порт узла, который выступает в качестве rendezvous. Любой узел в задании обучения может работать. - "/app/run_ddp.py" — это путь к файлу кода обучения. Помните, что
/app— это общий каталог на головном узле.
Отправьте задание и подождите результат. Вы можете просмотреть выполняемые задачи, например
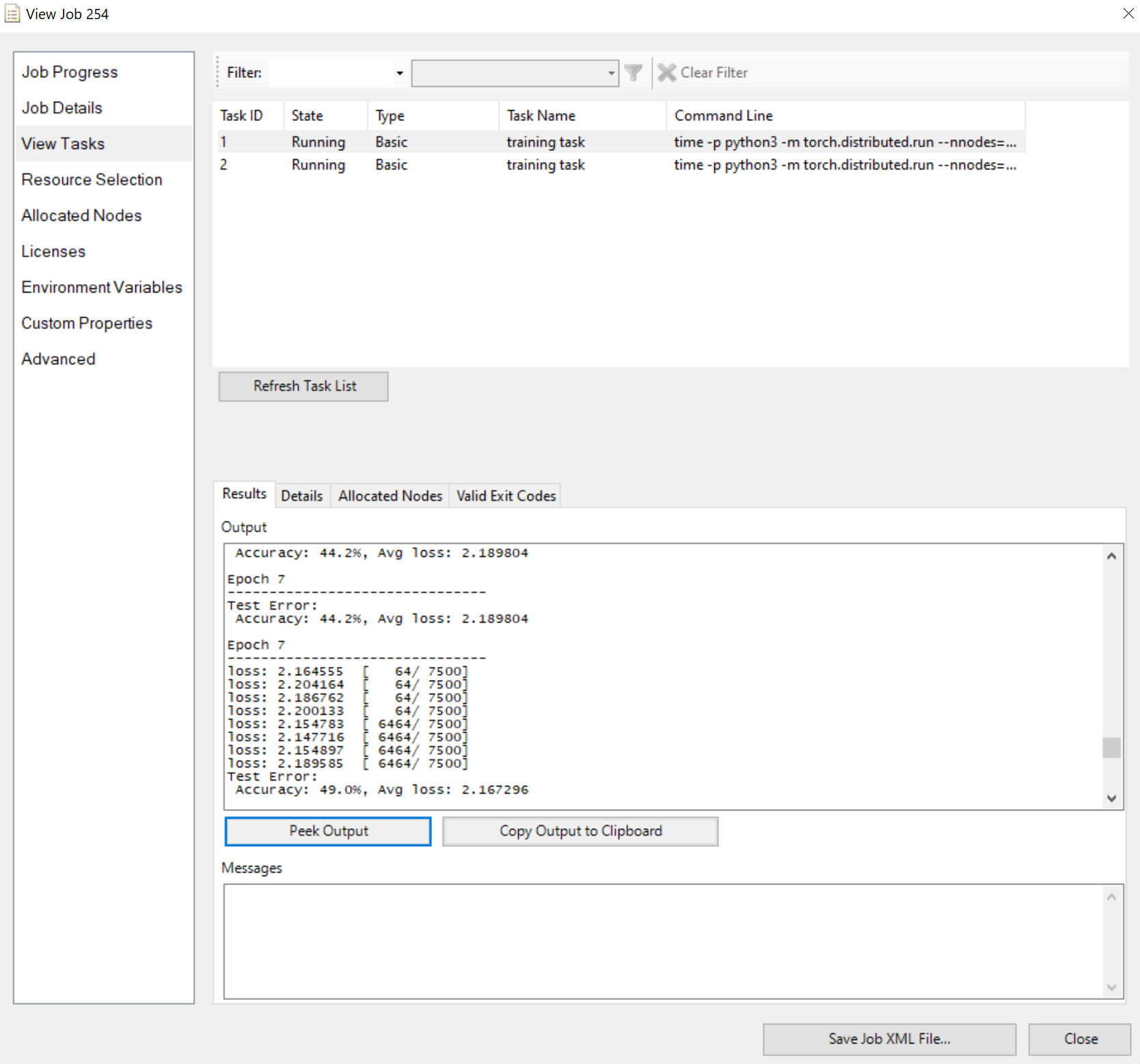
Обратите внимание, что в области результатов отображаются усеченные выходные данные, если это слишком долго.
Это все для этого. Я надеюсь, что вы получаете баллы и пакет HPC может ускорить вашу учебную работу.