Решение "Монитор производительности сети": мониторинг производительности
Важно!
Начиная с 1-го июля 2021 г. вы не сможете добавлять новые тесты в существующую рабочую область или включать новую рабочую область в службе "Монитор производительности сети". Вы сможете продолжить использование тестов, созданных до 1 июля 2021 г. Чтобы минимизировать прерывание ваших текущих рабочих нагрузок, необходимо выполнить переход с "Монитора производительности сети" на новый "Монитор подключений" в Наблюдателе за сетями Azure до 29 февраля 2024 г.
Функции системного монитора в службе Монитор производительности сети помогают отслеживать сетевые подключения в разных точках сети. Можно отслеживать подключения в облачных развертываниях и локальных расположениях, нескольких центрах обработки данных и филиалах, критически важных многоуровневых приложениях или микрослужбах. С помощью мониторинга производительности можно выявить проблемы в сети перед тем, как пользователи начнут на них жаловаться. Основные преимущества перечислены ниже:
- отслеживание потерь и задержек в различных подсетях и настройка оповещений;
- отслеживание всех путей (включая избыточные) в сети;
- устранение временных неполадок в сети и неполадок в сети до точки во времени, которые усложняют репликацию;
- определение конкретного сегмента в сети, с которым связана низкая производительность;
- отслеживание работоспособности сети без необходимости использования SNMP.
Конфигурация
Чтобы открыть конфигурацию Монитора производительности сети, откройте решение Монитор производительности сети и нажмите кнопку Настройка.
Создание сетей
Сеть в мониторе производительности сети — это логический контейнер для подсетей. Он позволяет организовать мониторинг инфраструктуры сети с учетом ваших потребностей в мониторинге. Можно создать сеть с понятным именем и добавить в нее подсети в соответствии с бизнес-логикой. Например, можно создать сеть Vladivostok и добавить в нее все подсети из центра обработки данных во Владивостоке. Или можно создать сеть ContosoFrontEnd и добавить в нее все подсети с именем Contoso, используемые в интерфейсной части приложения. Решение автоматически создает сеть по умолчанию, в которой содержатся все подсети, обнаруженные в вашей среде.
Каждый раз при создании сети в нее добавляется подсеть. Затем эта подсеть удаляется из сети по умолчанию. Если удалить сеть, все подсети автоматически возвратятся в сеть по умолчанию. Сеть по умолчанию является контейнером для всех подсетей, которые не содержатся в какой-либо сети, определяемой пользователем. Сеть по умолчанию нельзя изменить или удалить. Она всегда остается в системе. Вы можете создать любое количество настраиваемых сетей. В большинстве случаев подсети в вашей организации образуют несколько сетей. Создайте одну или несколько сетей, чтобы объединить подсети согласно вашей бизнес-логике.
Чтобы создать сеть, сделайте следующее:
- Щелкните вкладку Сети.
- Щелкните Добавить сеть и введите имя и описание сети.
- Выберите одну или несколько подсетей и щелкните Добавить.
- Нажмите кнопку Сохранить, чтобы сохранить конфигурацию.
Создание правил мониторинга
Функция монитора производительности формирует события работоспособности при нарушении порога производительности сетевых подключений между двумя подсетями или сетями. Система может автоматически определить эти пороговые значения. Можно также указать их самостоятельно. Система автоматически создает правило по умолчанию, которое формирует событие работоспособности каждый раз, когда значения потери или задержки между любой парой подключенных сетей или подсетей превышают определенный системой порог. Этот процесс помогает решению отслеживать сетевую инфраструктуру, пока правила мониторинга не созданы явным образом. Если правило по умолчанию включено, то все узлы отправляют искусственные транзакции на все узлы, для которых включен мониторинг. Правило по умолчанию удобно применять в случае небольших сетей. Например, если имеется небольшое количество серверов, на которых выполняется микрослужба, и вы хотите обеспечить подключение между всеми серверами.
Примечание
Рекомендуется отключить правило по умолчанию и создать настраиваемые правила мониторинга, особенно для крупных сетей, в которых используется большое количество узлов, требующих наблюдения. Это позволит уменьшить трафик, создаваемый решением, и упростит организацию мониторинга сети.
Создайте правила мониторинга в соответствии с бизнес-логикой. Например, если вы хотите отслеживать производительность сетевых подключений между двумя офисными сайтами и центральным офисом. Сгруппируйте все подсети офисного сайта 1 в сеть O1. Затем сгруппируйте все подсети офисного сайта 2 в сеть O2. Наконец, сгруппируйте все подсети центрального офиса в сеть H. Создайте два правила мониторинга — одно между сетями O1 или H, а другое — между сетями O2 и H.
Чтобы создать настраиваемые правила мониторинга, сделайте следующее:
- На вкладке Монитор щелкните Добавить правило и введите имя и описание правила.
- Выберите из списков пару сетевых соединений или соединений подсети для мониторинга.
- Из раскрывающегося списка сетей выберите сеть, содержащую требуемые подсети. Затем выберите подсети из соответствующего раскрывающегося списка подсетей. Выберите Все подсети, если необходимо отслеживать все подсети в сетевом соединении. Аналогичным образом выберите другие необходимые подсети. Щелкните Добавить исключение, чтобы исключить мониторинг для определенных соединений подсетей из списка выбранных.
- Для выполнения искусственных транзакций выберите один из протоколов: ICMP или TCP.
- Если не нужно создавать события работоспособности для выбранных элементов, снимите флажок Enable Health Monitoring on the links covered by this rule (Включить наблюдение за работоспособностью ссылок, охваченных этим правилом).
- Выберите условия мониторинга. Чтобы задать настраиваемые пороговые значения для создания событий работоспособности, введите эти пороговые значения. Каждый раз, когда значение условия превышает выбранное пороговое значение для выбранной пары сетей или подсетей, создается событие работоспособности.
- Нажмите кнопку Сохранить, чтобы сохранить конфигурацию.
Сохранив правило мониторинга, вы можете интегрировать это правило с управлением оповещениями. Для этого щелкните Создать оповещение. Будет автоматически создано правило генерации оповещений с поисковым запросом. Другие обязательные параметры заполняются автоматически. Используя правило оповещения, вы можете получать оповещения по электронной почте в дополнение к существующим оповещениям в Мониторе производительности сети. Оповещения также могут запускать корректирующие действия для модулей Runbook, или их можно интегрировать с существующими решениями по управлению службами, использующими веб-перехватчики. Щелкните Управлять оповещениями, чтобы изменить параметры оповещений.
Теперь можно создать дополнительные правила мониторинга производительности или перейти к панели мониторинга решения, чтобы использовать эту функцию.
Выбор протокола
Монитор производительности сети использует искусственные транзакции для вычисления показателей производительности сети, таких как потеря пакетов и задержка связи. Чтобы лучше в этом разобраться, рассмотрим агент Монитора производительности сети, подключенный к одному концу сетевого соединения. Этот агент Монитора производительности сети отправляет пакеты пробы второму агенту Монитора производительности сети, подключенному к другому концу сети. Второй агент отвечает отправкой ответных пакетов. Этот процесс повторяется несколько раз. Измеряя количество ответов и время, затраченное на получение каждого ответа, первый агент Монитора производительности сети оценивает задержку связи и потерю пакетов.
Формат, размер и последовательность этих пакетов определяется протоколом, который выбирается при создании правил мониторинга. В зависимости от протокола пакетов промежуточные сетевые устройства (маршрутизаторы, коммутаторы и др.) могут по-разному обрабатывать эти пакеты. Поэтому от выбора протокола зависит точность результатов. От выбора протокола также зависит, потребуется ли после развертывания решения "Монитор производительности сети" выполнять какие-то действия вручную.
Для выполнения искусственных транзакций в Мониторе производительности сети доступны два протокола — ICMP и TCP. Если при создании правила искусственных транзакций выбрать протокол ICMP, то для расчета задержки в сети и потери пакетов агенты Монитора производительности сети будут использовать эхо-сообщения ICMP. В эхо-сообщениях ICMP используется такой же тип сообщений, как и в традиционной служебной программе проверки связи. Если выбрать протокол TCP, то агенты Монитора производительности сети будут отправлять по сети пакеты TCP SYN. После этого выполняется подтверждение TCP, а затем подключение удаляется с помощью пакетов RST.
Прежде чем выбрать протокол, ознакомьтесь с приведенными ниже сведениями.
Обнаружение нескольких сетевых маршрутов. При обнаружении нескольких маршрутов протокол TCP обеспечивает более точные результаты. А также ему требуется меньше агентов в каждой подсети. Например, один или два агента, использующие протокол TCP, могут обнаруживать все избыточные пути между подсетями. При этом для достижения подобных результатов с помощью протокола ICMP необходимо несколько агентов. Если при использовании протокола ICMP у вас несколько маршрутов между двумя подсетями, то вам необходимо не менее 5N агентов в исходной или целевой подсети.
Точность результатов. Как правило, маршрутизаторы и коммутаторы назначают эхо-пакетам ICMP более низкий приоритет по сравнению с пакетами TCP. В определенных ситуациях при высокой загрузке сетевых устройств данные, полученные по протоколу TCP, более точно отражают фактические показатели потери и задержки в приложениях. Это связано с тем, что большая часть трафика приложений проходит по протоколу TCP. В таких случаях ICMP обеспечивает менее точные результаты, чем TCP.
Конфигурация брандмауэра. Для протокола TCP требуется, чтобы пакеты TCP отправлялись на конечный порт. По умолчанию агентами Монитора производительности сети используется порт 8084. Его можно изменить при настройке агентов. Необходимо убедиться, что сетевые брандмауэры или правила групп безопасности сети (в Azure) разрешают передачу трафика через этот порт. Также необходимо убедиться, что в настройках локального брандмауэра на компьютерах, где установлены агенты, разрешен трафик через этот порт. Правила брандмауэра на компьютерах под управлением Windows можно настроить с помощью сценариев PowerShell, однако сетевой брандмауэр настраивается вручную. Напротив, протокол ICMP не использует порт. В большинстве корпоративных сценариев ICMP-трафик через брандмауэры разрешается, чтобы была возможность использовать диагностические инструменты, такие как служебная программа проверки связи. Если вам удалось выполнить проверку связи между двумя компьютерами, то вы можете использовать протокол ICMP, не настраивая брандмауэры вручную.
Примечание
Некоторые брандмауэры могут блокировать протокол ICMP, что может привести к повторной передаче, порождающей большое количество событий в сведениях системы безопасности и системе управления событиями. Убедитесь, что выбранный протокол не блокируется сетевым брандмауэром или NSG. В противном случае Монитор производительности сети не сможет отслеживать сегмент сети. Рекомендуется использовать протокол TCP для мониторинга. Протокол ICMP следует применять в сценариях, в которых невозможно использовать протокол TCP, например:
- если вы используете узлы на основе клиента Windows, так как незащищенные сокеты TCP не допускаются в клиентах Windows;
- если ваш сетевой брандмауэр или NSG блокирует протокол TCP;
- если вам не известно, как сменить протокол.
Если во время развертывания вы выбрали протокол ICMP, то для его смены на TCP можно в любое время изменить правило мониторинга по умолчанию.
- Последовательно выберите Производительность сети>Монитор>Настройка>Монитор. Выберите Правило по умолчанию.
- Прокрутите страницу до раздела Протокол и выберите протокол, который хотите использовать.
- Чтобы применить настройку, нажмите кнопку Сохранить.
Даже если в правиле по умолчанию используется определенный протокол, вы можете создавать другие правила с другим протоколом. Можно даже создать набор правил, в котором одна часть правил использует протокол ICMP, и другая часть — TCP.
Пошаговое руководство
Теперь рассмотрим простое изучение первопричины события работоспособности.
На панели мониторинга решения отображается событие работоспособности: сетевое соединение находится в неработоспособном состоянии. Чтобы изучить проблему, щелкните элемент Network links being monitored (Отслеживаемые сетевые соединения).
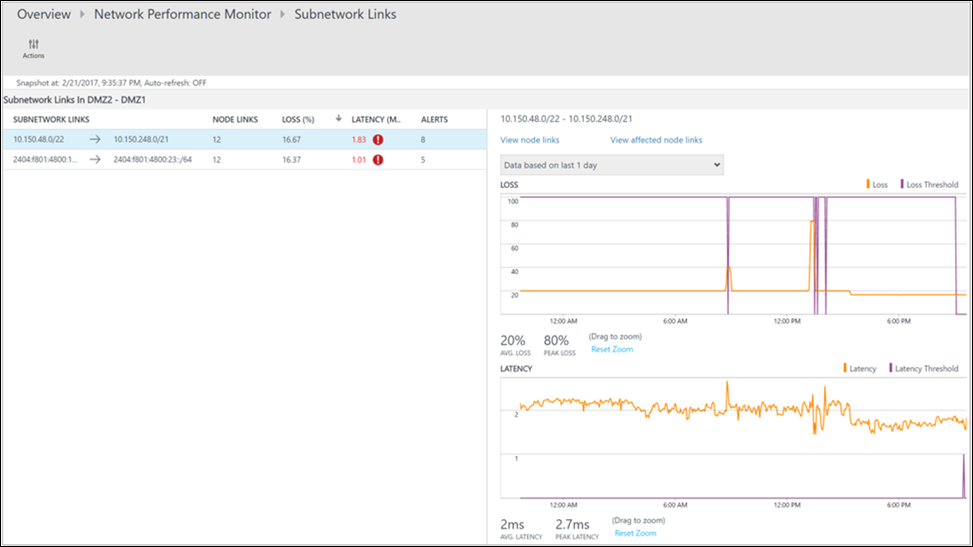
На странице подробных сведений вы увидите, что в неработоспособном состоянии находится сетевое соединение DMZ2-DMZ1. Щелкните View subnet links (Просмотреть соединения подсетей) для этого сетевого соединения.
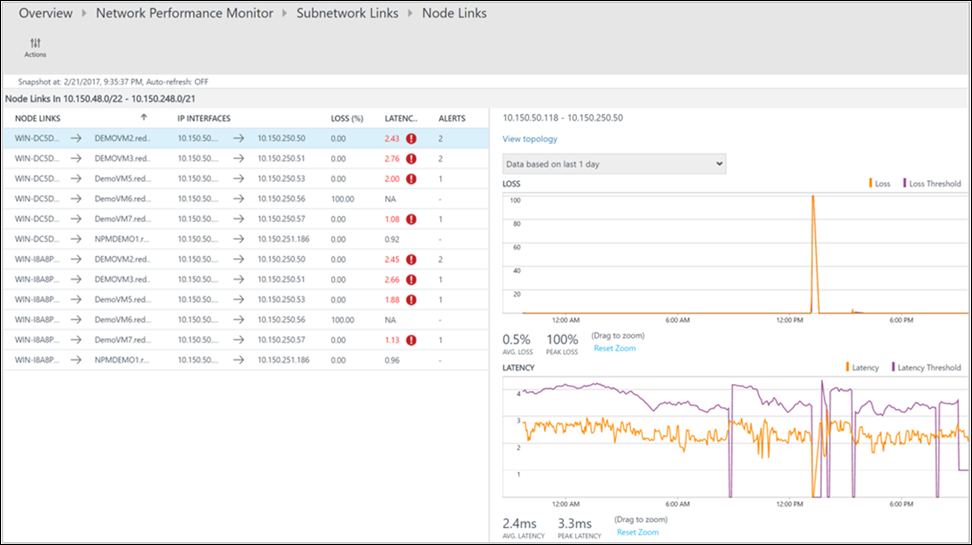
На странице детализации отображаются все соединения подсетей в сетевом соединении DMZ2-DMZ1. Для обоих соединений подсетей значение задержки превысило пороговое значение. Это и является причиной неработоспособности сетевого соединения. Кроме того, можно увидеть тенденции задержки обоих соединений подсетей. На диаграмме можно использовать элемент управления для выбора времени, чтобы сосредоточиться на необходимом диапазоне времени. Можно узнать период времени, когда значение задержки достигло пика. Позже можно найти сведения для этого периода времени в журналах, чтобы определить причину проблемы. Щелкните Просмотреть ссылки на узлы для дополнительной детализации.
Как и на предыдущей странице, на странице детализации для определенного соединения подсети представлены связанные с ней соединения узлов. Здесь можно выполнить те же действия, которые описаны на предыдущем шаге. Чтобы просмотреть топологию между двумя узлами, щелкните Просмотреть топологию.
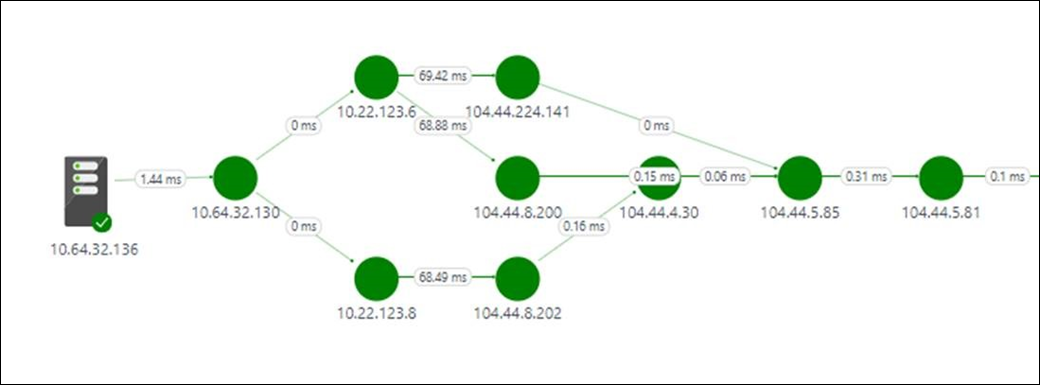
Все пути между двумя выбранными узлами отображаются на карте топологии. Топологию маршрутов можно визуализировать по прыжкам между двумя узлами на карте топологии. Это обеспечивает четкое представление о количестве маршрутов между двумя узлами и путях, по которым передаются пакеты данных. Узкие места производительности сети помечаются красным цветом. Чтобы найти неисправное сетевое подключение или неисправное сетевое устройство, нужно просмотреть элементы, помеченные красным цветом на карте топологии.
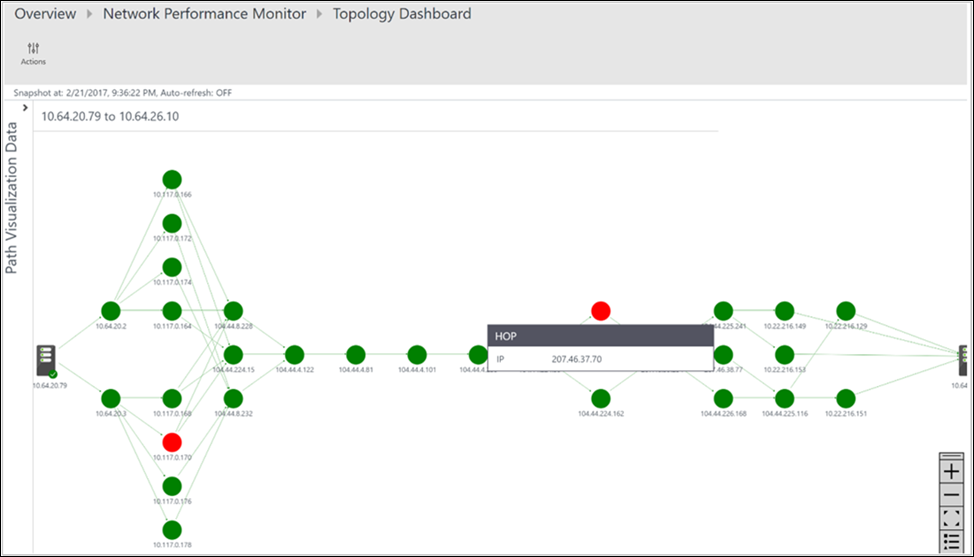
Значения потери, задержки и количество прыжков в каждом пути можно просмотреть в области Действие. Используйте полосу прокрутки, чтобы просмотреть сведения об этих неработоспособных путях. Используйте фильтры для выбора путей с неработоспособными прыжками, чтобы отобразить топологию только выбранных путей. С помощью колесика мыши можно увеличить или уменьшить масштаб карты топологии.
На следующем рисунке красным цветом выделены пути и прыжки, определяющие первопричину проблемных областей в конкретном сегменте сети. Щелкнув узел на карте топологии, можно увидеть его свойства, включая полное доменное имя и IP-адрес. Если щелкнуть прыжок, отобразится IP-адрес прыжка.
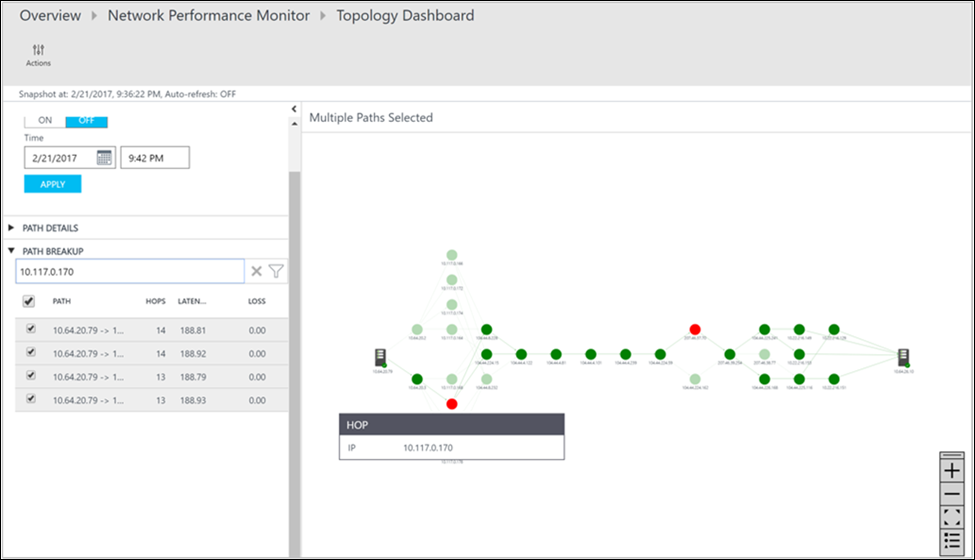
Дальнейшие действия
Выполните поиск по журналам, чтобы просмотреть подробные записи данных о производительности сети.