Заметка
Доступ к этой странице требует авторизации. Вы можете попробовать войти в систему или изменить каталог.
Доступ к этой странице требует авторизации. Вы можете попробовать сменить директорию.
ОБЛАСТЬ ПРИМЕНЕНИЯ К: Студия машинного обучения (классическая)
Студия машинного обучения (классическая)  Машинное обучение Azure
Машинное обучение Azure
Внимание
Поддержка Студии машинного обучения (классической) будет прекращена 31 августа 2024 г. До этой даты рекомендуется перейти на Машинное обучение Azure.
Начиная с 1 декабря 2021 года вы не сможете создавать новые ресурсы Студии машинного обучения (классической). Существующие ресурсы Студии машинного обучения (классической) можно будет использовать до 31 августа 2024 г.
- См. сведения о переносе проектов машинного обучения из Студии машинного обучения (классическая версия) в Машинное обучение Azure.
- См. дополнительные сведения о Машинном обучении Azure.
Прекращается поддержка документации по Студии машинного обучения (классической). В будущем документация может перестать обновляться.
В этой статье объясняется, как визуализировать и интерпретировать результаты прогнозирования в Студии машинного обучения (классическая). После того как вы обучите модель и сделаете на ее основе прогнозы (оцените модель), вам нужно понять и интерпретировать результат прогноза.
В Студии машинного обучения (классическая) существует четыре основных типа моделей машинного обучения:
- Классификация
- Кластеризация
- Регрессия
- системы рекомендаций.
Модули, используемые для прогнозирования на основе этих моделей:
- модуль Score Model (Оценка модели) для классификации и регрессии;
- модуль Assign to Clusters для кластеризации.
- модуль Score Matchbox Recommender (Рекомендатель Matchbox) для систем рекомендаций.
Узнайте, как выбирать параметры для оптимизации алгоритмов в Студии машинного обучения (классическая версия).
Сведения о том, как оценивать модели, см. в статье об оценке эффективности модели.
Если вы не знакомы с ML Studio (классическая версия), узнайте, как создать простой эксперимент.
Классификация
Существует две подкатегории задач классификации:
- задачи только с двумя классами (двухклассовая или двоичная классификация);
- задачи более чем с двумя классами (многоклассовая классификация).
Хотя Студия машинного обучения (классическая) содержит различные модули для работы с этими типами классификации, методы интерпретации прогнозных результатов для всех модулей похожи.
Двуклассовая классификация
Пример эксперимента
Пример проблемы с двухклассовой классификацией — классификация цветов ириса. Задача — классификация цветов ириса по их признакам. Набор данных Iris в Machine Learning Studio (классическая версия) — это подмножество популярного набора данных Iris, которое содержит экземпляры только двух видов цветов (классы 0 и 1). Для каждого цветка можно выделить четыре признака: длина наружной доли околоцветника, ширина наружной доли околоцветника, длина внутренней доли околоцветника и ширина внутренней доли околоцветника.
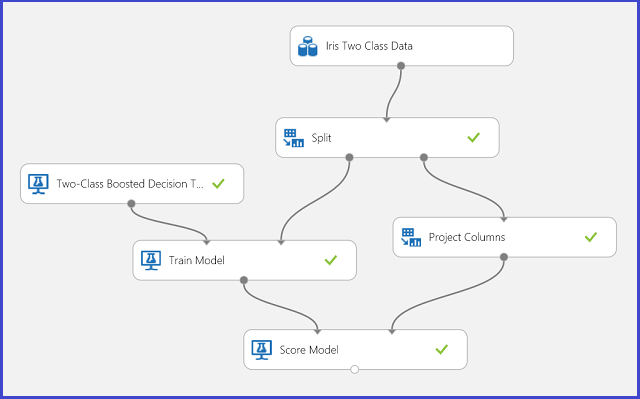
Рисунок 1. Эксперимент по задаче двухклассовой классификации ирисов
Эксперимент для решения этой задачи проведен, как показано на рис. 1. Модель усиленного дерева решений для двухклассовой классификации была обучена и оценена. Теперь результаты прогноза модуля Score Model (Оценка модели) можно визуализировать. Для этого щелкните порт вывода модуля Score Model (Оценка модели) и в раскрывшемся меню выберите команду Визуализировать.
Это действие приводит к отображению результатов подсчёта, как показано на рис. 2.
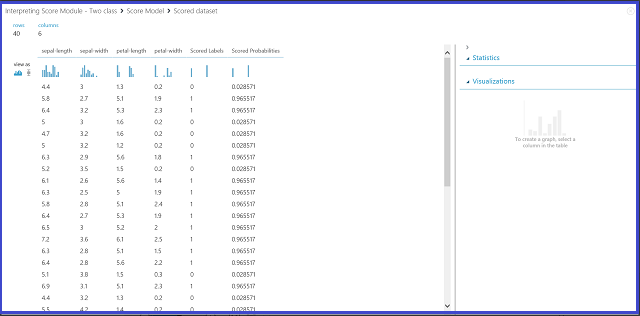
Рисунок 2. Визуализация результата модельной оценки для задачи двухклассовой классификации
Интерпретация результатов
В таблице результатов представлены шесть столбцов. Четыре столбца слева соответствуют четырем признакам. Два правых столбца — "Scored Labels" (Оцененные метки) и "Scored Probabilities" (Оцененные вероятности) — представляют результаты прогнозирования. Столбец "Scored Probabilities" (Оцененные вероятности) отражает вероятность того, что цветок принадлежит к положительному классу (класс 1). Например, первое число в этом столбце (0,028571) означает, что первый цветок принадлежит классу 1 с вероятностью 0,028571. Столбец «Оцененные метки» показывает прогнозируемый класс для каждого цветка. Этот прогноз основывается на столбце с балльными вероятностями. Если оцененная вероятность цветка больше 0,5, прогнозируется принадлежность к Классу 1. В противном случае прогнозируется принадлежность к классу 0.
Публикация в веб-службе
Если результаты прогнозирования выглядят понятными и убедительными, эксперимент можно опубликовать как веб-службу. Так вы сможете развертывать его в разных приложениях и прогнозировать принадлежность к классам новых цветков ириса. Сведения о том, как превратить обучающий эксперимент в оценивающий эксперимент и опубликовать его в виде веб-службы, см. в руководстве 3 по развертыванию модели кредитных рисков. Выполнив эту процедуру, вы получите оценивающий эксперимент, как показано на рис. 3.
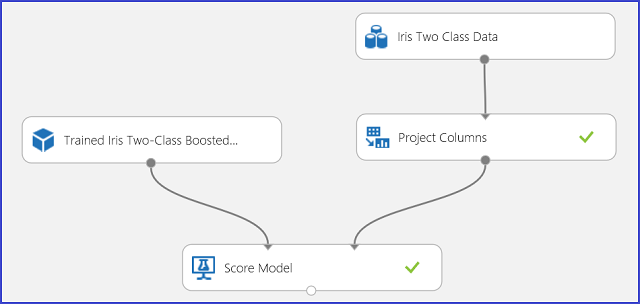
Рисунок 3. Оценка эксперимента с задачей двухклассовой классификации цветков ириса
Теперь вам нужно определить вход и выход для веб-службы. Входные данные — это правый входной порт Score Model, который является входом, входящим данные признаков цветка ириса. Выбор результата зависит от того, интересуетесь ли вы прогнозируемым классом (оцененной меткой), оцененной вероятностью или тем и другим. В этом примере предполагается, что вам интересны оба значения. Чтобы выбрать нужные выходные столбцы, используйте модуль Select Columns in Data set (Выбор столбцов в наборе данных). Щелкните на модуле Select Columns in Data set (Выбор столбцов в наборе данных), затем на Launch column selector (Запустить средство выбора столбцов) и выберите столбцы Scored Labels (Оцененные метки) и Scored Probabilities (Оцененные вероятности). Настроив порт вывода модуля Select Columns in Data set (Выбор столбцов в наборе данных) и запустив эксперимент еще раз, можно приступать к публикации оценивающего эксперимента в виде веб-службы. Для этого нажмите кнопку Опубликовать веб-службу. Окончательный эксперимент выглядит так, как на рис. 4.
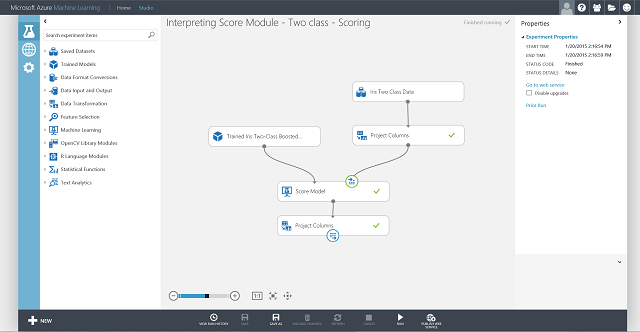
Рисунок 4. Финальный эксперимент оценки в задаче двухклассовой классификации цветков ириса
Запустив веб-службу, вы можете ввести некоторые значения признаков для тестового экземпляра и получить ответ в виде двух чисел. Первое число — это оцененная метка, а второе — оцененная вероятность. Прогноз относит этот цветок к классу 1 с вероятностью 0,9655.
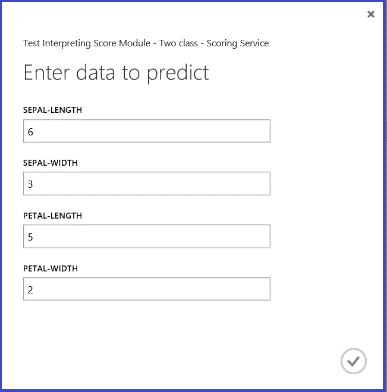

Рисунок 5. Результат, возвращаемый веб-сервисом для двухклассовой классификации ириса
Многоклассовая классификация
Пример эксперимента
В этом эксперименте в качестве примера многоклассовой классификации выполняется задача по распознаванию букв. Классификатор пытается предсказать определенную букву (класс) на основе некоторых значений атрибутов, извлеченных из изображений рукописного текста.
В обучающих данных предусмотрено 16 признаков, извлеченных из изображений рукописных букв. У нас есть 26 букв, которые образуют 26 классов. На рис. 6 представлен эксперимент, который обучает модель многоклассовой классификации распознавать буквы. Кроме того, он прогнозирует результаты по тому же набору признаков для тестового набора данных.
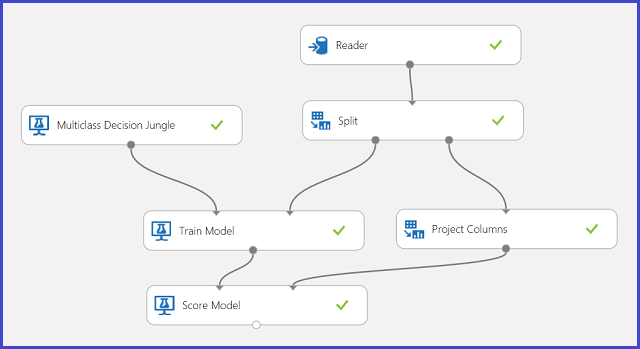
Рисунок 6. Эксперимент с многоклассовой задачей классификации для распознавания букв.
Отобразите результаты модуля Score Model (Оценка модели), щелкнув порт вывода модуля Score Model (Оценка модели) и выбрав команду Визуализировать. Вы увидите данные, представленные на рис. 7.
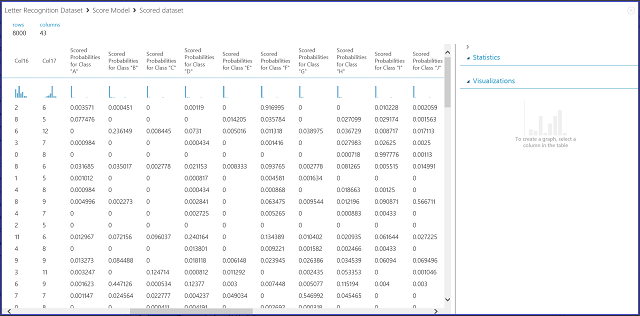
Рис. 7. Визуализировать результаты модели оценки для задачи многоклассовой классификации
Интерпретация результатов
16 столбцов слева представляют значения признаков тестового набора. Столбцы с названиями, подобными "Оцененные вероятности для класса «XX»", аналогичны столбцу "Оцененные вероятности" в двухклассовом случае. Они показывают вероятность того, что соответствующая запись будет принадлежать определенному классу. Например, для первой записи число 0,003571 представляет вероятность принадлежности к классу А, число 0,000451 — к классу В и т. д. Последний столбец (С оцененными метками) такой же, как и столбец "С оцененными метками" в случае с двумя классами. Класс с наибольшим показателем вероятности выбирается в качестве прогнозируемого класса соответствующей записи. Например, для первой записи оценка представлена меткой "F", так как у неё наибольшая вероятность быть "F" (0,916995).
Публикация в веб-службе
Здесь вы также можете получить значение оцененной метки для каждой записи и вероятность этой метки. Задача состоит в нахождении наибольшей вероятности среди всех оценок вероятностей. Для этого вам потребуется модуль Выполнить сценарий R. Код для скрипта R представлен на рис. 8, а на рис. 9 показан результат эксперимента.

Рис. 8. Код R для извлечения меток с оценками и связанных с ними вероятностей.
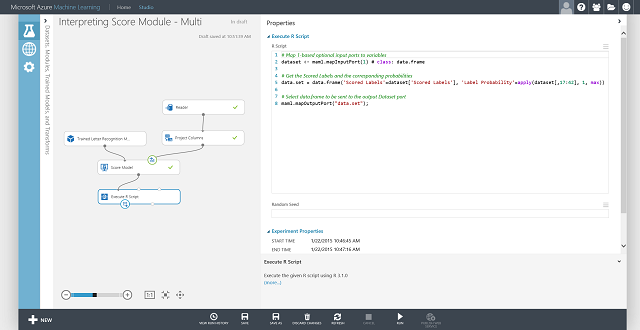
Рис. 9. Заключительный эксперимент по оценке задачи многоклассовой классификации распознавания букв
Когда вы опубликуете эту веб-службу и введете некоторые входные значения признаков, вы получите результат, который выглядит как на рис. 10. Эта рукописная буква согласно 16 извлеченным признакам будет буквой "T" с вероятностью 0,9715.

Рис. 10. Результат веб-службы многоклассовой классификации
Регрессия
Регрессионная задача отличается от задачи классификации. В задаче классификации мы пытаемся прогнозировать дискретные классы, определяя, например, к какому классу принадлежит цветок ириса. А в следующем примере представлена регрессионная задача, в которой мы пробуем спрогнозировать значение непрерывной переменной, например стоимости автомобиля.
Пример эксперимента
Используйте прогнозирование стоимости автомобиля в качестве примера регрессии. Вы будете прогнозировать цену автомобиля на основе таких его признаков, как производитель, тип топлива, тип кузова, типа привода и т. д. Этот эксперимент показан на рис. 11.
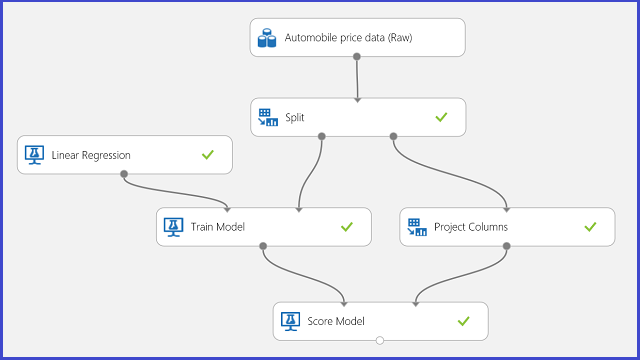
Рис. 11. Регрессионный эксперимент с задачей оценки стоимости автомобиля
При визуализации модуля Score Model результат выглядит как на рис. 12.
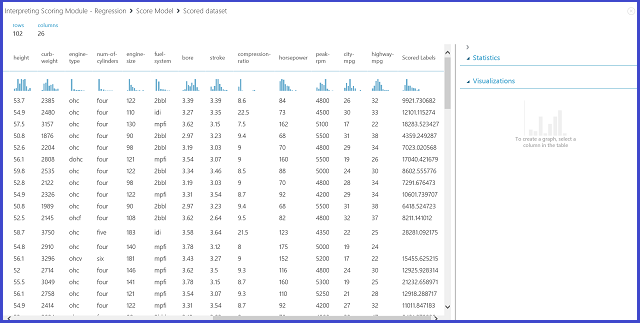
Рис. 12. Оценка результата для задачи прогноза стоимости автомобилей
Интерпретация результатов
В этом эксперименте результаты оценки представлены в столбце оцененных меток. Числа являются прогнозируемой стоимостью для каждого автомобиля.
Публикация в веб-службе
Вы можете опубликовать эксперимент регрессии в веб-сервисе и вызывать его для прогнозирования стоимости автомобиля так же, как в случае использования двухклассовой классификации.
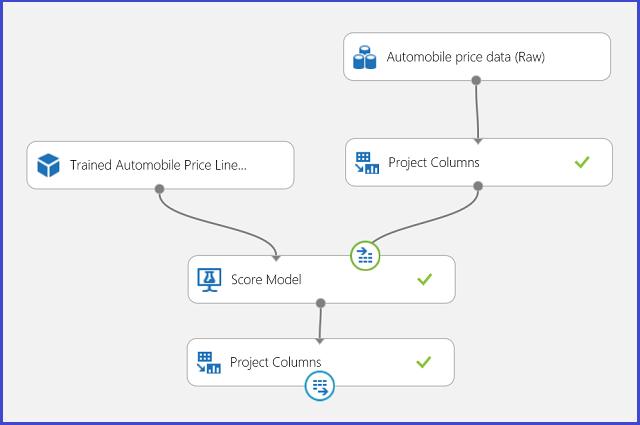
Рис. 13. Оценка эксперимента для задачи регрессии по оценке стоимости автомобилей
Запустив веб-службу, возвращаемый результат выглядит, как показано на рис. 14. Прогнозируемая стоимость этого автомобиля — 15 085,52 долларов США.
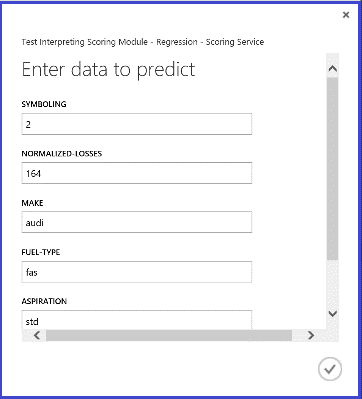

Рис. 14. Результат веб-сервиса для задачи регрессии цен автомобиля
Кластеризация
Пример эксперимента
Воспользуемся набором данных Iris еще раз, чтобы создать эксперимент кластеризации. Здесь вы можете отфильтровать метки классов в наборе данных, чтобы они включали только признаки и их можно было использовать для кластеризации. В этом сценарии использования набора данных Iris, во время процесса обучения необходимо указать два кластера, что означает, что цветки будут классифицированы на два класса. Этот эксперимент показан на рис. 15.
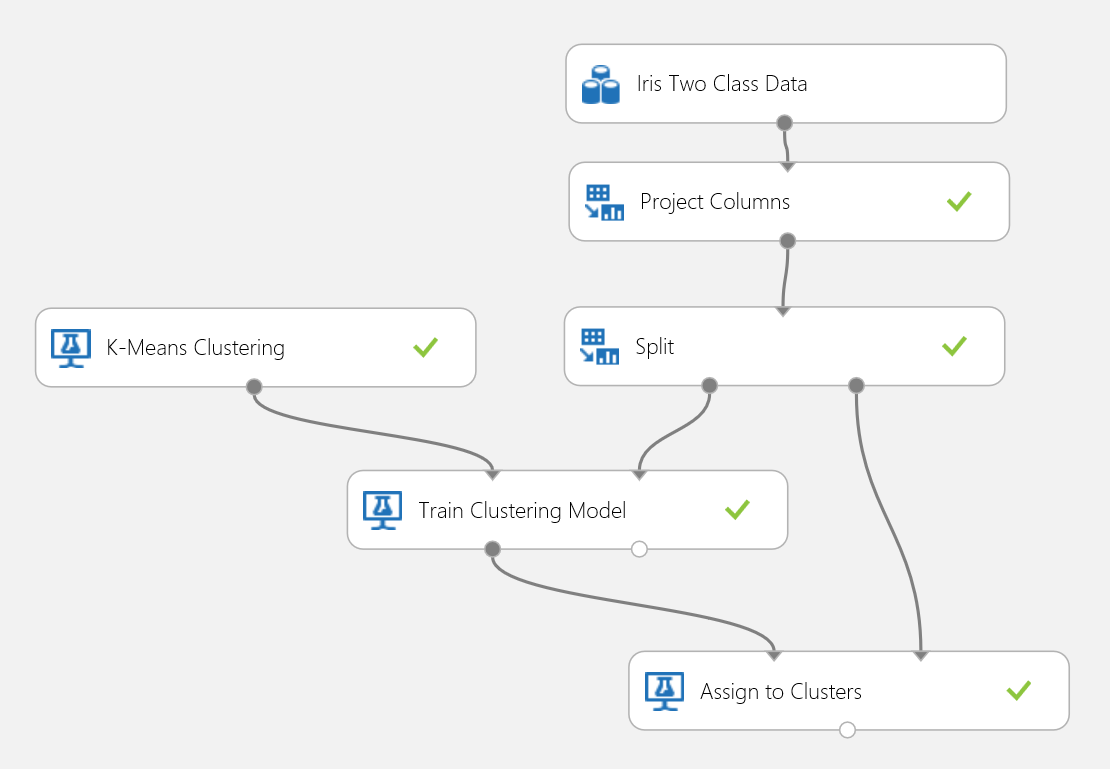
Рис. 15. Эксперимент с задачей кластеризации цветков ириса
Кластеризация отличается от классификации тем, что обучающий набор данных сам по себе не имеет изначальных меток. При кластеризации экземпляры обучающего набора данных группируются в несколько кластеров. В процессе обучения модель помечает записи по мере изучения различий между их признаками. После этого обученная модель может классифицировать новые записи. В задаче кластеризации нас интересуют результаты по двум направлениям. Сначала мы создадим метки для обучающего набора данных, а затем классифицируем новый набор данных с помощью обученной модели.
Первую часть результатов можно визуализировать, нажав на левый порт вывода Train Clustering Model и затем выбрав Визуализировать. Визуализация представлена на рис. 16.
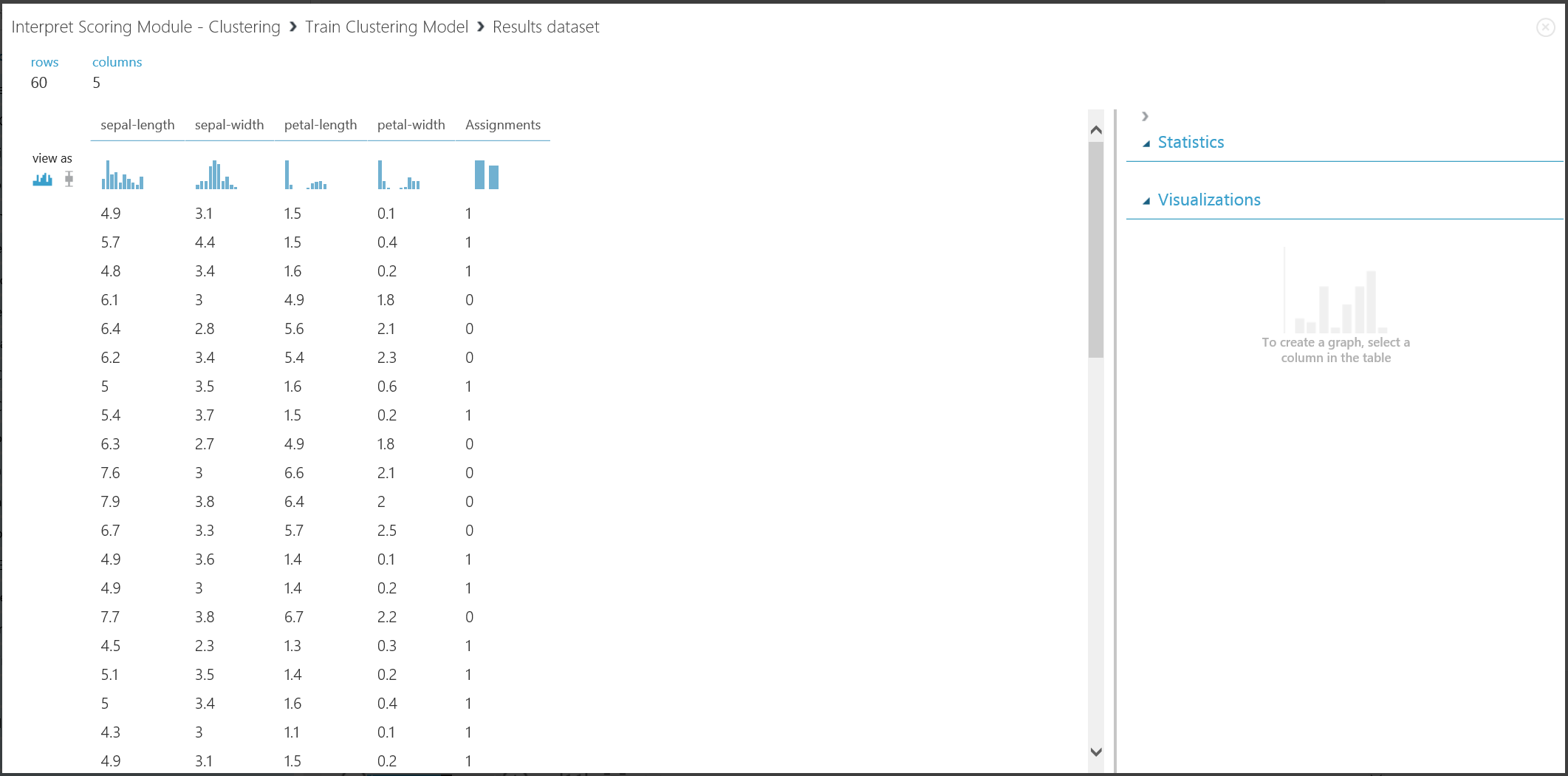
Рис. 16. Визуализация результата кластеризации для обучающего набора данных
Вторая часть результатов, кластеризация новых записей с помощью обученной модели кластеризации, показана на рис. 17.
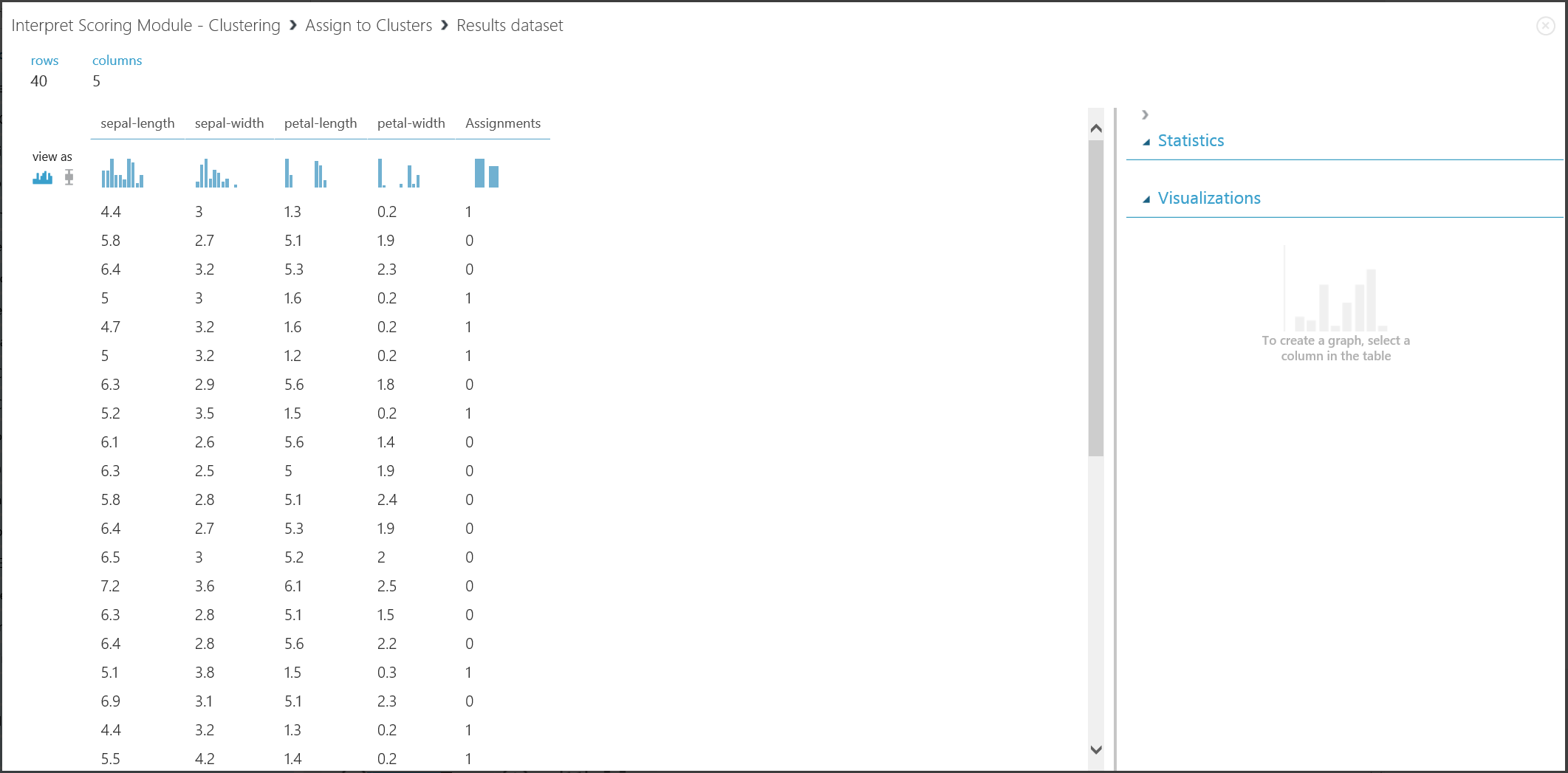
Рис. 17. Визуализация результата кластеризации для нового набора данных
Интерпретация результатов
Хотя результаты двух подмножеств получены на разных этапах эксперимента, они выглядят похожими и интерпретируются одинаково. Первые четыре столбца — это характеристики. Последний столбец "Assignments" (Назначения) представляет результат прогнозирования. Записи, которым назначены одинаковые числа, по прогнозу отнесены в один кластер. Это означает, что у них есть определенные сходства (в этом эксперименте использовалась стандартная формула Евклидовой метрики для оценки расстояния). Так как вы указали, что кластеров должно быть 2, записям в разделе "Назначения" присвоены значения либо 0, либо 1.
Публикация в веб-службе
Вы можете опубликовать эксперимент кластеризации в веб-службе и вызывать его для прогнозирования кластеризации так же, как и эксперимент двухклассовой классификации.
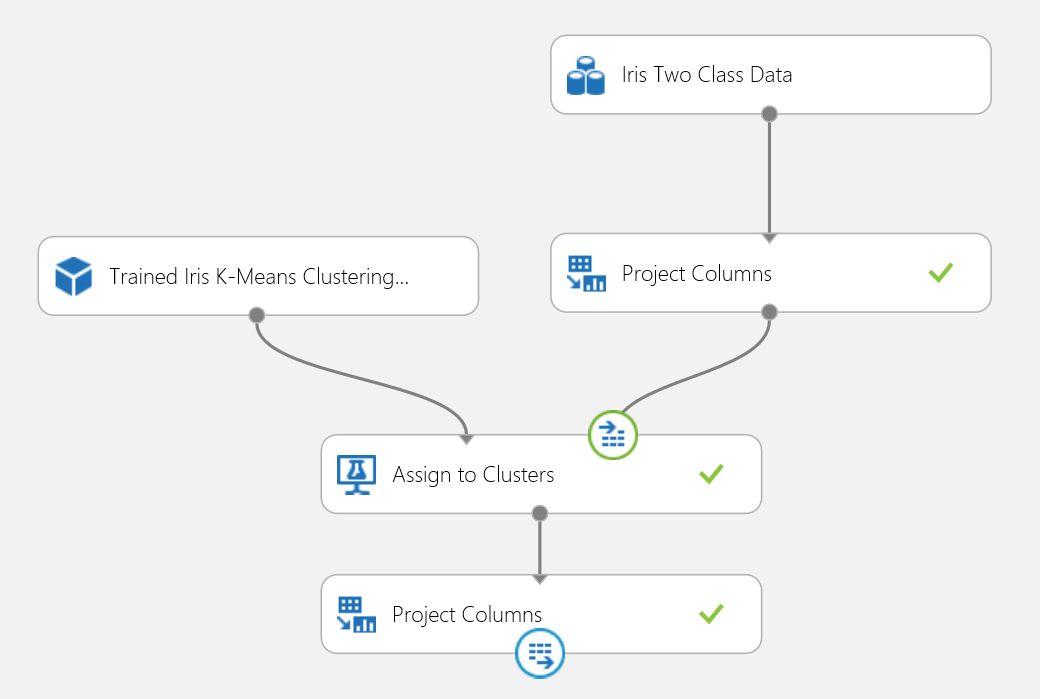
Рис. 18. Эксперимент по оценке задачи кластеризации набора данных Iris
Запустив веб-службу, вы получите результат, представленный на рис. 19. Согласно прогнозу этот цветок относится к кластеру 0.
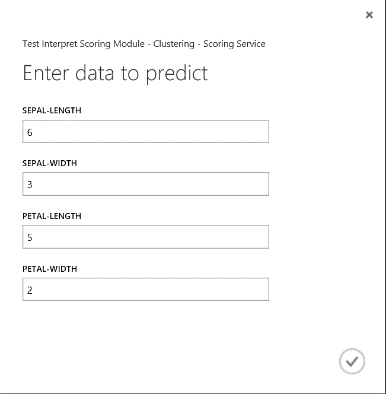

Рис. 19. Результат, возвращаемый веб-сервисом для двухклассовой классификации ириса
Система рекомендаций
Пример эксперимента
Чтобы ознакомиться с системой рекомендаций, в качестве примера рассмотрим задачу рекомендации ресторана: вы будете рекомендовать клиентам рестораны на основе их оценок. Входные данные делятся на три части:
- клиентские оценки ресторанов;
- данные о характеристиках клиентов;
- Данные об услугах ресторанов
С помощью модуля Train Matchbox Recommender в Студии машинного обучения (классическая) можно выполнять несколько задач:
- Прогноз оценки для указанных пользователя и объекта
- рекомендовать объект данному пользователю;
- Поиск пользователей, связанных с указанным пользователем
- Поиск объектов, связанных с данным объектом
Вы можете выбрать нужную задачу в меню Recommender prediction kind (Тип прогноза системы рекомендаций), где есть четыре варианта. Здесь мы рассмотрим все четыре сценария.
Типичный эксперимент Студии машинного обучения (классическая) для системы рекомендаций представлен на рис. 20. Дополнительную информацию о том, как использовать эти модули системы рекомендаций, см. в разделе Train matchbox recommender и Score matchbox recommender.
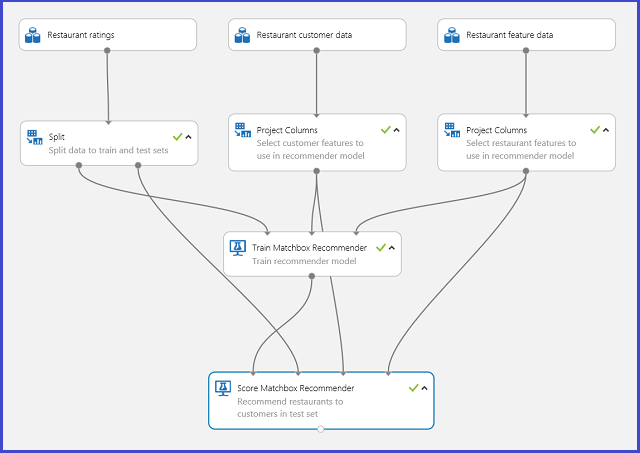
Рис. 20. Эксперимент с системой рекомендаций
Интерпретация результатов
Прогноз оценки для указанных пользователя и объекта
Выбрав пункт Rating Prediction (Прогноз оценки) в меню Recommender prediction kind (Тип прогноза системы рекомендаций), мы запросим у системы рекомендаций создать прогнозную оценку для указанных пользователя и объекта. Визуализация результатов Score Matchbox Recommender выглядит как на рис. 21.
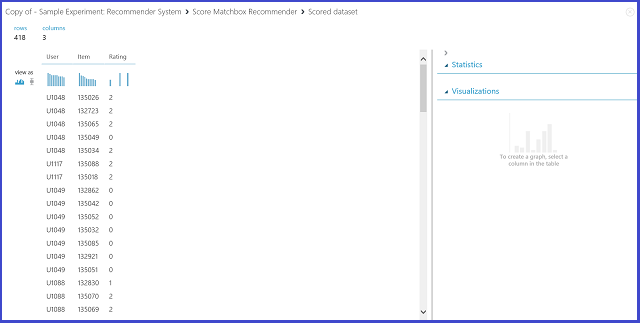
Рис. 21. Визуализация результата оценки системы рекомендаций — прогнозная оценка
Первые два столбца — это пары пользователь-объект, представленные во входных данных. Третий столбец является прогнозируемой оценкой пользователя для определенного объекта. Например в первой строке клиент U1048 вероятно даст ресторану 135026 оценку 2.
Рекомендация объекта указанному пользователю
Выбрав пункт Item Recommendation (Рекомендация объекта) в меню Recommender prediction kind (Тип прогноза системы рекомендаций), мы запросим систему рекомендаций найти рекомендуемые объекты для указанного пользователя. В этом сценарии нужно указать значение еще одного параметра: Recommended item selection (Выбор рекомендуемого объекта). Параметр From Rated Items (for model evaluation) используется преимущественно для оценки модели в процессе обучения. На этом этапе прогнозирования мы выбираем Из всех объектов. Визуализация результатов Score Matchbox Recommender показана на рис. 22.
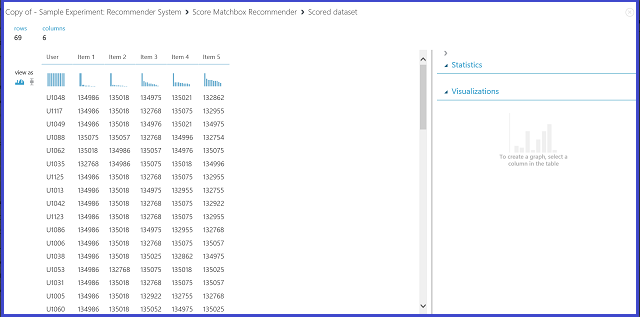
Рис. 22. Визуализация результата оценки системы рекомендаций — рекомендуемый объект
Первый из шести столбцов содержит идентификаторы пользователей, которым будут рекомендованы объекты. Они получены из входных данных. Остальные пять столбцов содержат объекты, рекомендуемые каждому пользователю. Они перечислены в порядке убывания релевантности. Например, в первой строке для клиента U1048 первый рекомендуемый ресторан представлен значением 134986; за ним следуют 135018, 134975, 135021 и 132862.
Поиск пользователей, связанных с указанным пользователем
Выбрав пункт Related Users (Связанные пользователи) в меню Recommender prediction kind (Тип прогноза системы рекомендаций), мы запросим систему рекомендаций найти пользователей, связанных с указанным пользователем. Связанными пользователями являются пользователи с аналогичными параметрами. В этом сценарии нужно выбрать значение еще одного параметра: Related user selection (Выбор связанных пользователей). Параметр Из пользователей, которые оценили объекты используется преимущественно для оценки модели при обучении. Выберите Из всех пользователей для этого этапа прогнозирования. Визуализация результатов Score Matchbox Recommender показана на рис. 23.
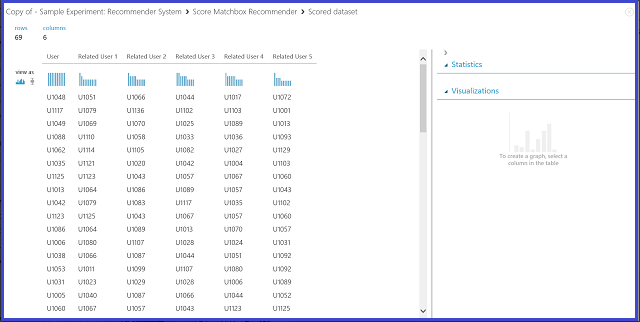
Рис. 23. Визуализация результатов оценок системы рекомендаций для связанных пользователей
Первый из шести столбцов показывает необходимые идентификаторы пользователей, которые требуются для поиска связанных пользователей, как указано во входных данных. Остальные пять столбцов содержат предсказанные данные о связанных пользователях, перечисленных в порядке убывания релевантности. Например, в первой строке для клиента U1048 наиболее соответствующий клиент представлен значением U1051; за ним следуют U1066, U1044, U1017 и U1072.
Поиск объектов, связанных с данным объектом
Выбрав пункт Related Items (Связанные объекты) в меню Recommender prediction kind (Тип прогноза системы рекомендаций), мы запросим систему рекомендаций найти объекты, связанные с указанным объектом. Связанные объекты — это те объекты, которые скорее всего понравятся тем же пользователям. В этом сценарии нужно выбрать значение еще одного параметра: Related item selection (Выбор связанных объектов). Параметр From Rated Items (for model evaluation) используется преимущественно для оценки модели в процессе обучения. На этом этапе прогнозирования мы выбираем вариант From All Items (Из всех объектов). Визуализация вывода Score Matchbox Recommender выглядит как на рис. 24.
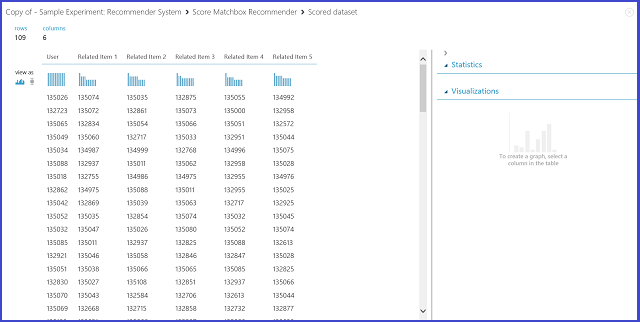
Рис. 24. Визуализация результатов оценки системы рекомендаций — связанные объекты
Первый из шести столбцов представляет собой идентификаторы объектов, которые необходимы для поиска связанных элементов и предоставлены во входных данных. Остальные пять столбцов содержат прогнозы по связанным объектам. Они перечислены в порядке убывания релевантности. Например, в первой строке для объекта 135026 наиболее соответствующий объект представлен значением 135074; за ним следуют 135035, 132875, 135055 и 134992.
Публикация в веб-службе
Процесс публикации этих экспериментов как веб-служб для получения прогнозов аналогичен для каждого из четырех сценариев. В качестве примера мы возьмем второй сценарий, в котором объекты рекомендуются указанному пользователю. Ту же процедуру необходимо повторить и для трех остальных сценариев.
Сохранив обученную систему рекомендаций в виде обученной модели и отфильтровав входные данные до одного столбца идентификаторов пользователей по запросу, можно подключить эксперимент, как показано на рис. 25, и опубликовать его как веб-службу.
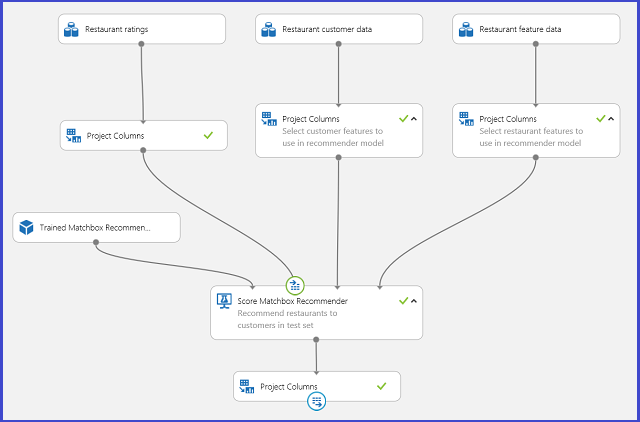
Рис. 25. Эксперимент по оценке проблемы рекомендации ресторанов
Запустив эту веб-службу, мы получим результат, представленный на рис. 26. Пользователю U1048 рекомендуются пять ресторанов: 134986, 135018, 134975, 135021 и 132862.
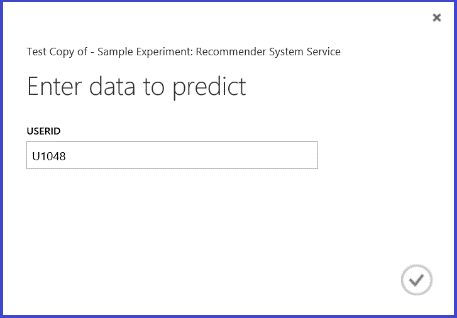

Рис. 26. Результаты веб-службы для задачи рекомендации ресторана