Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Оглавление
- Сводка
- Установка
- Запуск примера toy
- Обучение данных Pascal VOC
- Обучение CNTK Fast R-CNN на основе собственных данных
- Технические сведения
- Сведения об алгоритме
Сводка

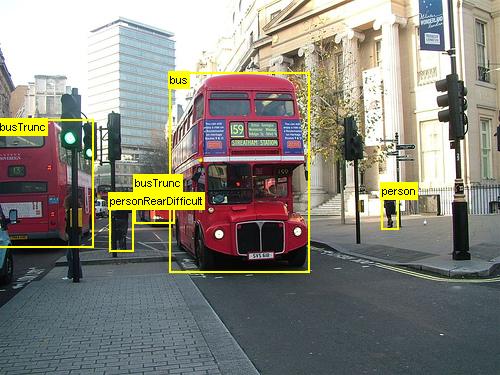
В этом руководстве описывается использование Fast R-CNN в API Python CNTK. Быстрый R-CNN с использованием BrainScript и cnkt.exe описаны здесь.
Приведенные выше примеры изображений и заметок объектов для продуктового набора данных (слева) и набора данных Pascal VOC (справа), используемого в этом руководстве.
Fast R-CNN — это алгоритм обнаружения объектов, предлагаемый Россом Гиршиком в 2015 году. Документ принят в ICCV 2015 и архивирован по адресу https://arxiv.org/abs/1504.08083. Fast R-CNN основывается на предыдущих работах, чтобы эффективно классифицировать предложения объектов с помощью глубоких сверточных сетей. По сравнению с предыдущей работой, Fast R-CNN использует область интересующей схемы объединения , которая позволяет повторно использовать вычисления из сверточных слоев.
Настройка
Чтобы запустить код в этом примере, требуется среда Python CNTK (см. здесь справку по настройке). Установите следующие дополнительные пакеты в среде cntk Python.
pip install opencv-python easydict pyyaml dlib
Предварительно скомпилированные двоичные файлы для регрессии ограничивающего прямоугольного поля и не максимального подавления
Examples\Image\Detection\utils\cython_modules Папка содержит предварительно скомпилированные двоичные файлы, необходимые для запуска Fast R-CNN. В настоящее время в репозитории содержатся версии Python 3.5 для Windows и Python 3.5, 3.6 для Linux, все 64-разрядные версии. Если вам нужна другая версия, ее можно скомпилировать, выполнив описанные ниже действия.
- Linux: https://github.com/rbgirshick/py-faster-rcnn
- Windows: https://github.com/MrGF/py-faster-rcnn-windows
Скопируйте созданные двоичные cython_bbox файлы и cpu_nms (или) gpu_nmsиз $FRCN_ROOT/lib/utils .$CNTK_ROOT/Examples/Image/Detection/utils/cython_modules
Пример модели данных и базовых показателей
Мы используем предварительно обученную модель AlexNet в качестве основы для обучения Fast-R-CNN (для VGG или других базовых моделей см. использование другой базовой модели. Пример набора данных и предварительно обученной модели AlexNet можно скачать, выполнив следующую команду Python из папки FastRCNN:
python install_data_and_model.py
- Узнайте, как использовать другую базовую модель
- Узнайте, как запустить Fast R-CNN на данных Pascal VOC
- Узнайте, как запустить Fast R-CNN на собственных данных
Запуск примера toy
Обучение и оценка быстрого запуска R-CNN
python run_fast_rcnn.py
Результаты обучения с 2000 ROIs в продуктовом магазине с помощью AlexNet в качестве базовой модели должны выглядеть примерно так:
AP for gerkin = 1.0000
AP for butter = 1.0000
AP for joghurt = 1.0000
AP for eggBox = 1.0000
AP for mustard = 1.0000
AP for champagne = 1.0000
AP for orange = 1.0000
AP for water = 0.5000
AP for avocado = 1.0000
AP for tomato = 1.0000
AP for pepper = 1.0000
AP for tabasco = 1.0000
AP for onion = 1.0000
AP for milk = 1.0000
AP for ketchup = 0.6667
AP for orangeJuice = 1.0000
Mean AP = 0.9479
Визуализация прогнозируемых ограничивающих прямоугольники и меток на изображениях, открытых FastRCNN_config.py из FastRCNN папки, и установка
__C.VISUALIZE_RESULTS = True
Образы будут сохранены в папке FastRCNN/Output/Grocery/ при запуске python run_fast_rcnn.py.
Обучение на Pascal VOC
Чтобы скачать данные Pascal и создать файлы заметок для Pascal в формате CNTK, выполните следующие скрипты:
python Examples/Image/DataSets/Pascal/install_pascalvoc.py
python Examples/Image/DataSets/Pascal/mappings/create_mappings.py
dataset_cfg Изменение метода get_configuration()run_fast_rcnn.py на
from utils.configs.Pascal_config import cfg as dataset_cfg
Теперь вы можете обучить данные Pascal VOC 2007 с помощью python run_fast_rcnn.py. Будьте осторожны, что обучение может занять некоторое время.
Обучение на основе собственных данных
Подготовка пользовательского набора данных
Вариант 1. Инструмент добавления тегов визуальных объектов (рекомендуется)
Средство маркировки визуальных объектов (VOTT) — это кроссплатформенное средство заметок для добавления тегов видео и ресурсов изображений.

VOTT предоставляет следующие возможности:
- Компьютерное добавление тегов и отслеживание объектов в видео с помощью алгоритма отслеживания Camshift.
- Экспорт тегов и ресурсов в формат CNTK Fast-RCNN для обучения модели обнаружения объектов.
- Запуск и проверка обученной модели обнаружения объектов CNTK на новых видео для создания более сильных моделей.
Как добавить заметки с помощью VOTT:
- Скачивание последнего выпуска
- Следуйте инструкциям readme , чтобы запустить задание добавления тегов
- После добавления тегов экспорта в каталог набора данных
Вариант 2. Использование скриптов заметок
Чтобы обучить модель CNTK Fast R-CNN в собственном наборе данных, мы предоставляем два сценария для добавления заметок в прямоугольные области на изображения и назначения меток этим регионам.
Скрипты будут хранить заметки в правильном формате, как это необходимо для первого шага запуска Fast R-CNN (A1_GenerateInputROIs.py).
Сначала сохраните изображения в следующей структуре папок.
<your_image_folder>/negative— изображения, используемые для обучения, которые не содержат объектов.<your_image_folder>/positive— изображения, используемые для обучения, содержащие объекты.<your_image_folder>/testImages— образы, используемые для тестирования, содержащие объекты.
Для отрицательных изображений не нужно создавать заметки. Для двух других папок используйте предоставленные скрипты:
- Запустите,
C1_DrawBboxesOnImages.pyчтобы нарисовать ограничивающие прямоугольники на изображениях.- Перед выполнением в наборе
imgDir = <your_image_folder>скриптов (/positiveили/testImages) - Добавьте заметки с помощью курсора мыши. Когда все объекты на изображении помечены, нажатие клавиши "n" записывает файл .bboxes.txt, а затем переходит к следующему изображению, "u" отменяет (т. е. удаляет) последний прямоугольник, а q завершает работу средства заметки.
- Перед выполнением в наборе
- Выполните команду
C2_AssignLabelsToBboxes.py, чтобы назначить метки ограничивающим прямоугольникам.- В наборе
imgDir = <your_image_folder>скриптов (/positiveили/testImages) перед запуском... - ... и адаптируйте классы в скрипте, чтобы отразить категории объектов, например
classes = ("dog", "cat", "octopus"). - Скрипт загружает эти прямоугольники вручную, аннотированные для каждого изображения, отображает их по одному и просит пользователя предоставить класс объекта, нажав соответствующую кнопку слева от окна. Примечания к действительности, помеченные как "неопределенные" или "исключаемые", полностью исключаются из дальнейшей обработки.
- В наборе
Обучение настраиваемого набора данных
После хранения образов в описанной структуре папок и аннотирования их выполните
python Examples/Image/Detection/utils/annotations/annotations_helper.py
после изменения папки в этом скрипте на папку данных. Наконец, создайте MyDataSet_config.py в папке utils\configs следующие примеры:
__C.CNTK.DATASET == "YourDataSet":
__C.CNTK.MAP_FILE_PATH = "../../DataSets/YourDataSet"
__C.CNTK.CLASS_MAP_FILE = "class_map.txt"
__C.CNTK.TRAIN_MAP_FILE = "train_img_file.txt"
__C.CNTK.TEST_MAP_FILE = "test_img_file.txt"
__C.CNTK.TRAIN_ROI_FILE = "train_roi_file.txt"
__C.CNTK.TEST_ROI_FILE = "test_roi_file.txt"
__C.CNTK.NUM_TRAIN_IMAGES = 500
__C.CNTK.NUM_TEST_IMAGES = 200
__C.CNTK.PROPOSAL_LAYER_SCALES = [8, 16, 32]
Обратите внимание, что __C.CNTK.PROPOSAL_LAYER_SCALES не используется для Fast R-CNN, только для более быстрого R-CNN.
Чтобы обучить и оценить Fast R-CNN на данные, измените dataset_cfg метод run_fast_rcnn.py на get_configuration()
from utils.configs.MyDataSet_config import cfg as dataset_cfg
и запустите python run_fast_rcnn.py.
Технические сведения
Алгоритм Fast R-CNN описан в разделе сведений об алгоритме вместе с общими сведениями о том, как он реализуется в API Python CNTK. В этом разделе основное внимание уделяется настройке Fast R-CNN и использованию различных базовых моделей.
Параметры
Параметры группируются в три части:
- Параметры детектора (см. )
FastRCNN/FastRCNN_config.py - Параметры набора данных (см. пример
utils/configs/Grocery_config.py) - Параметры базовой модели (см. пример
utils/configs/AlexNet_config.py)
Три части загружаются и объединяются в get_configuration() метод в run_fast_rcnn.py. В этом разделе мы рассмотрим параметры детектора. Здесь описаны параметры набора данных , параметры базовой модели. В следующем примере мы рассмотрим наиболее важные параметры в FastRCNN_config.py. Все параметры также закомментированы в файле. В конфигурации EasyDict используется пакет, позволяющий легко получить доступ к вложенным словарям.
# Number of regions of interest [ROIs] proposals
__C.NUM_ROI_PROPOSALS = 200 # use 2000 or more for good results
# the minimum IoU (overlap) of a proposal to qualify for training regression targets
__C.BBOX_THRESH = 0.5
# Maximum number of ground truth annotations per image
__C.INPUT_ROIS_PER_IMAGE = 50
__C.IMAGE_WIDTH = 850
__C.IMAGE_HEIGHT = 850
# Use horizontally-flipped images during training?
__C.TRAIN.USE_FLIPPED = True
# If set to 'True' conv layers weights from the base model will be trained, too
__C.TRAIN_CONV_LAYERS = True
Предложения ROI вычисляются на лету в первой эпохе с использованием реализации выборочного поиска из dlib пакета. Количество создаваемых предложений управляется параметром __C.NUM_ROI_PROPOSALS . Мы рекомендуем использовать около 2000 предложений. Голова регрессии обучается только на тех ROIs, которые имеют перекрытие (IoU) с наземным полем истины по крайней мере __C.BBOX_THRESH.
__C.INPUT_ROIS_PER_IMAGE указывает максимальное количество заметок истины на изображение. В настоящее время для CNTK требуется задать максимальное число. Если есть меньше заметок, они будут заполнены внутри. __C.IMAGE_WIDTH и __C.IMAGE_HEIGHT являются измерениями, которые используются для изменения размера и заполнения входных изображений.
__C.TRAIN.USE_FLIPPED = True дополнит обучающие данные, перевернув все изображения каждой другой эпохи, т. е. первая эпоха содержит все регулярные изображения, вторая — все изображения перевернуты и т. д. __C.TRAIN_CONV_LAYERS определяет, будут ли сверточных слоев от входных данных к карте сверточных признаков обучены или исправлены. Исправление весов уровня конвов означает, что весы из базовой модели принимаются и не изменяются во время обучения. (Вы также можете указать, сколько слоев conv требуется обучить, см. раздел "Использование другой базовой модели".
# NMS threshold used to discard overlapping predicted bounding boxes
__C.RESULTS_NMS_THRESHOLD = 0.5
# If set to True the following two parameters need to point to the corresponding files that contain the proposals:
# __C.DATA.TRAIN_PRECOMPUTED_PROPOSALS_FILE
# __C.DATA.TEST_PRECOMPUTED_PROPOSALS_FILE
__C.USE_PRECOMPUTED_PROPOSALS = False
__C.RESULTS_NMS_THRESHOLD — это порог NMS, используемый для отмены перекрывающихся прогнозируемых ограничивающих прямоугольника в вычислении. Более низкий порог дает меньше удалений и, следовательно, более прогнозируемые ограничивающие прямоугольники в окончательных выходных данных. Если вы задали __C.USE_PRECOMPUTED_PROPOSALS = True средство чтения, будет считывать предварительно вычисляемые roIS из текстовых файлов. Это например, используется для обучения данным Pascal VOC. Имена __C.DATA.TRAIN_PRECOMPUTED_PROPOSALS_FILE файлов и __C.DATA.TEST_PRECOMPUTED_PROPOSALS_FILE указаны в .Examples/Image/Detection/utils/configs/Pascal_config.py
# The basic segmentation is performed kvals.size() times. The k parameter is set (from, to, step_size)
__C.roi_ss_kvals = (10, 500, 5)
# When doing the basic segmentations prior to any box merging, all
# rectangles that have an area < min_size are discarded. Therefore, all outputs and
# subsequent merged rectangles are built out of rectangles that contain at
# least min_size pixels. Note that setting min_size to a smaller value than
# you might otherwise be interested in using can be useful since it allows a
# larger number of possible merged boxes to be created
__C.roi_ss_min_size = 9
# There are max_merging_iterations rounds of neighboring blob merging.
# Therefore, this parameter has some effect on the number of output rectangles
# you get, with larger values of the parameter giving more output rectangles.
# Hint: set __C.CNTK.DEBUG_OUTPUT=True to see the number of ROIs from selective search
__C.roi_ss_mm_iterations = 30
# image size used for ROI generation
__C.roi_ss_img_size = 200
Приведенные выше параметры настраивают выборочный поиск dlib. Дополнительные сведения см. на домашней странице dlib. Следующие дополнительные параметры используются для фильтрации созданных ROIs w.r.t. минимальной и максимальной длины, области и пропорций.
# minimum relative width/height of an ROI
__C.roi_min_side_rel = 0.01
# maximum relative width/height of an ROI
__C.roi_max_side_rel = 1.0
# minimum relative area of an ROI
__C.roi_min_area_rel = 0.0001
# maximum relative area of an ROI
__C.roi_max_area_rel = 0.9
# maximum aspect ratio of an ROI vertically and horizontally
__C.roi_max_aspect_ratio = 4.0
# aspect ratios of ROIs for uniform grid ROIs
__C.roi_grid_aspect_ratios = [1.0, 2.0, 0.5]
Если выборочный поиск возвращает больше URI, чем запрошено, они выборки случайным образом. Если в обычной сетке создаются дополнительные ROIs с помощью указанного __C.roi_grid_aspect_ratiosзначения.
Использование другой базовой модели
Чтобы использовать другую базовую модель, необходимо выбрать другую конфигурацию модели в методе get_configuration()run_fast_rcnn.py. Две модели поддерживаются сразу:
# for VGG16 base model use: from utils.configs.VGG16_config import cfg as network_cfg
# for AlexNet base model use: from utils.configs.AlexNet_config import cfg as network_cfg
Чтобы скачать модель VGG16, используйте скрипт скачивания в <cntkroot>/PretrainedModels:
python download_model.py VGG16_ImageNet_Caffe
Если вы хотите использовать другую базовую модель, необходимо скопировать файл конфигурации utils/configs/VGG16_config.py и изменить его в соответствии с базовой моделью:
# model config
__C.MODEL.BASE_MODEL = "VGG16"
__C.MODEL.BASE_MODEL_FILE = "VGG16_ImageNet_Caffe.model"
__C.MODEL.IMG_PAD_COLOR = [103, 116, 123]
__C.MODEL.FEATURE_NODE_NAME = "data"
__C.MODEL.LAST_CONV_NODE_NAME = "relu5_3"
__C.MODEL.START_TRAIN_CONV_NODE_NAME = "pool2" # __C.MODEL.FEATURE_NODE_NAME
__C.MODEL.POOL_NODE_NAME = "pool5"
__C.MODEL.LAST_HIDDEN_NODE_NAME = "drop7"
__C.MODEL.FEATURE_STRIDE = 16
__C.MODEL.RPN_NUM_CHANNELS = 512
__C.MODEL.ROI_DIM = 7
Для изучения имен узлов базовой модели можно использовать plot() метод из cntk.logging.graph. Обратите внимание, что модели ResNet в настоящее время не поддерживаются, так как объединение roi в CNTK пока не поддерживает среднее пулирование roi.
Сведения об алгоритме
Быстрый R-CNN
R-CNN для обнаружения объектов были впервые представлены в 2014 году Росс Girshick et al., и были показаны, чтобы превзойти предыдущие подходы к состоянию искусства на одном из основных задач распознавания объектов в области: Pascal VOC. С тех пор были опубликованы два последующих документа, которые содержат значительные улучшения скорости: Fast R-CNN и Fast R-CNN.
Основная идея R-CNN заключается в том, чтобы взять глубокую нейронную сеть, которая была первоначально обучена для классификации изображений с помощью миллионов аннотированных изображений и изменить ее для обнаружения объектов. Основная идея из первой бумаги R-CNN показана на рисунке ниже (взятом из статьи): (1) С учетом входного изображения (2) на первом шаге создаются предложения большого числа регионов. (3) Эти предложения региона или регионы интересов (ROIS) затем отправляются через сеть, которая выводит вектор, например 4096 значений с плавающей запятой для каждого roI. Наконец, (4) классификатор получает представление 4096 float ROI в качестве входных и выходных данных метки и достоверности для каждого roI.

Хотя этот подход хорошо работает с точки зрения точности, это очень затратно для вычислений, так как нейронная сеть должна быть оценена для каждого roI. Быстрый R-CNN устраняет этот недостаток, оценивая только большую часть сети (чтобы быть конкретными: слои свертки) один раз на изображение. По словам авторов, это приводит к 213-кратной скорости во время тестирования и 9-кратной скорости во время обучения без потери точности. Это достигается с помощью уровня пула ROI, который проецирует roI на карту сверточных компонентов и выполняет максимальное количество пулов для создания требуемого размера выходных данных, который ожидается на следующем уровне.
В примере AlexNet, используемом в этом руководстве, уровень пула roI помещается между последним сверточных слоев и первым полностью подключенным слоем. В приведенном ниже коде API Python CNTK это реализуется путем клонирования двух частей сети, а также conv_layersfc_layers. Затем входное изображение сначала нормализуется, передается через conv_layersслой иfc_layers, наконец, roipooling добавляются головки прогнозирования и регрессии, которые прогнозируют метку класса и коэффициенты регрессии для каждого кандидата ROI соответственно.
def create_fast_rcnn_model(features, roi_proposals, label_targets, bbox_targets, bbox_inside_weights, cfg):
# Load the pre-trained classification net and clone layers
base_model = load_model(cfg['BASE_MODEL_PATH'])
conv_layers = clone_conv_layers(base_model, cfg)
fc_layers = clone_model(base_model, [cfg["MODEL"].POOL_NODE_NAME], [cfg["MODEL"].LAST_HIDDEN_NODE_NAME], clone_method=CloneMethod.clone)
# Normalization and conv layers
feat_norm = features - Constant([[[v]] for v in cfg["MODEL"].IMG_PAD_COLOR])
conv_out = conv_layers(feat_norm)
# Fast RCNN and losses
cls_score, bbox_pred = create_fast_rcnn_predictor(conv_out, roi_proposals, fc_layers, cfg)
detection_losses = create_detection_losses(...)
pred_error = classification_error(cls_score, label_targets, axis=1)
return detection_losses, pred_error
def create_fast_rcnn_predictor(conv_out, rois, fc_layers, cfg):
# RCNN
roi_out = roipooling(conv_out, rois, cntk.MAX_POOLING, (6, 6), spatial_scale=1/16.0)
fc_out = fc_layers(roi_out)
# prediction head
cls_score = plus(times(fc_out, W_pred), b_pred, name='cls_score')
# regression head
bbox_pred = plus(times(fc_out, W_regr), b_regr, name='bbox_regr')
return cls_score, bbox_pred
Оригинальная реализация Caffe, используемая в документах R-CNN, можно найти на сайте GitHub: RCNN, Fast R-CNN и Fast R-CNN.
Обучение SVM и NN
Патрик Buehler предоставляет инструкции по обучению SVM на CNTK Fast R-CNN выходных данных (используя 4096 особенности из последнего полностью подключенного слоя), а также обсуждение плюсов и минусов здесь.
Выборочный поиск
Выборочный поиск — это метод для поиска большого набора возможных расположений объектов на изображении, независимо от класса фактического объекта. Он работает путем кластеризации пикселей изображения в сегменты, а затем выполняет иерархическую кластеризацию для объединения сегментов из одного объекта в предложения объектов.



Чтобы дополнить обнаруженные ROIs из выборочного поиска, мы добавим rois, которые равномерно охватывают изображение в различных масштабах и пропорциях. На изображении слева показан пример выходных данных выборочного поиска, где каждое возможное расположение объекта визуализируется зеленым прямоугольником. Rois, которые слишком малы, слишком большие и т. д. удаляются (средний) и, наконец, rois, которые равномерно охватывают изображение, добавляются (справа). Эти прямоугольники затем используются в качестве регионов интересов (ROIS) в конвейере R-CNN.
Цель создания ROI — найти небольшой набор ROI, который, однако, плотно охватывает как можно больше объектов на изображении. Эти вычисления должны быть достаточно быстрыми, одновременно находить расположения объектов в разных масштабах и пропорциях. Выборочный поиск был показан для выполнения этой задачи с хорошей точностью, чтобы ускорить компромиссы.
NMS (не максимальное подавление)
Методы обнаружения объектов часто выводить несколько обнаружений, которые полностью или частично охватывают один и тот же объект на изображении.
Эти rois должны быть объединены, чтобы иметь возможность подсчитать объекты и получить их точные расположения на изображении.
Обычно это делается с помощью метода, называемого не максимальным подавлением (NMS). Используемая версия NMS (и которая также использовалась в публикациях R-CNN), не объединяет ROIs, а пытается определить, какие ROIs лучше всего охватывают реальные расположения объекта и отбрасывают все остальные ROIs. Это реализуется путем итеративного выбора roI с наивысшей степенью достоверности и удаления всех остальных rois, которые значительно перекрывают этот roI и классифицируются как один и тот же класс. Пороговое значение перекрытия можно задать в PARAMETERS.py (сведениях).
Результаты обнаружения до (слева) и после (справа) не максимальное подавление:


mAP (средняя средняя точность)
После обучения качество модели можно измерить с помощью различных критериев, таких как точность, полнота, точность, точность, область под кривой и т. д. Общая метрика, используемая для вызова распознавания объектов VOC Pascal, заключается в измерении средней точности (AP) для каждого класса. Следующее описание средней точности берется из Everingham et. al. Среднее среднее значение точности (mAP) вычисляется путем принятия среднего значения по APS всех классов.
Для заданной задачи и класса кривая точности и отзыва вычисляется на основе ранжированных выходных данных метода. Отзыв определяется как доля всех положительных примеров, ранжированных выше заданного ранга. Точность — это доля всех примеров выше того ранга, которые относятся к положительному классу. AP суммирует форму кривой точности и отзыва и определяется как средняя точность на наборе из одиннадцати одинаково разных уровней полноты [0,0,1, . . . ,1]:
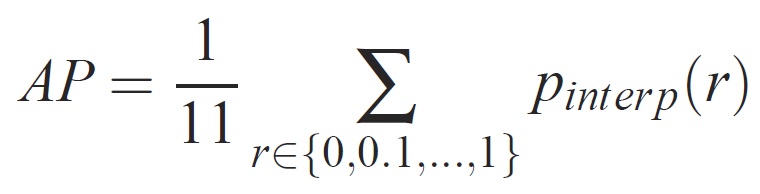
Точность на каждом уровне отзыва r интерполируется путем получения максимальной точности для метода, для которого соответствующий отзыв превышает r:
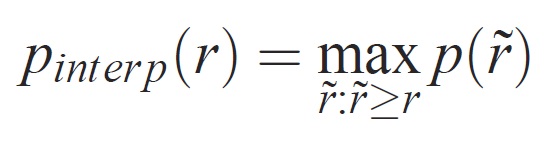
где p( ̃r) — измеряемая точность при отзыве ̃r. Цель интерполяции кривой точности и полноты таким образом заключается в уменьшении влияния "вилок" в кривой точности и отзыва, вызванной небольшими вариациями в рейтинге примеров. Следует отметить, что для получения высокой оценки метод должен иметь точность на всех уровнях отзыва — это штрафует методы, которые извлекают только подмножество примеров с высокой точностью (например, боковые представления автомобилей).