Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Регулярное выражение, обычно называемое регулярным выражением, — это последовательность символов, которая определяет шаблон поиска. Регулярные выражения в основном используются для сопоставления шаблонов со строками и при сопоставлении строк; например, в операциях поиска и замены. Регулярное выражение в Защита от потери данных Microsoft Purview (DLP) можно использовать для определения шаблонов, которые помогают выявлять и классифицировать конфиденциальные данные, или для обнаружения шаблонов в содержимом. Наиболее распространенные использования регулярных выражений в Microsoft Purview DLP:
- Определение пользовательских типов конфиденциальной информации.
- Использование условия в правиле
SubjectOrBodyMatchesPatternsзащиты от потери данных (дополнительные сведения см. здесь.)
В этой статье описаны распространенные проблемы, возникающие при работе с регулярными выражениями, и способы их устранения.
Потенциальная проблема с проверкой при использовании регулярного выражения с защитой от потери данных
- Базовые единицы шаблона, такие как литеральные символы, цифры, пробелы и знаки препинания, могут быть представлены сами по себе или специальными символами, называемыми метачарами, например
\dдля любой цифры,\sдля любого пробела или\.для литеральной точки. - Базовые единицы в сочетании с квантификаторами указывают, сколько раз они могут или должны встречаться в совпадении. Например,
*означает ноль или несколько,+означает один или несколько,?означает ноль или единицу, а{n,m}означает междуnиmвремя. Например,\d+означает одну или несколько цифр,\s?означает необязательный пробел иa{3,5}означает от трех до пяти экземпляров литерала a. - Регулярное выражение использует положительный или отрицательный взгляд за спиной. Просмотр используется для проверка, есть ли совпадение перед определенной позицией во входной строке без учета фактических символов в совпадении. Положительный взгляд за спиной используется для сопоставления при наличии шаблона lookbehind, в то время как отрицательный взгляд используется для сопоставления, когда шаблон lookbehind отсутствует .
- Рассмотрим следующий пример:
(?<=^|\s|_). В этом примере показан обзор, включающий три возможности:-
^утверждает позицию. В этом случае требуется, чтобы сопоставление шаблонов начиналось в начале строки. -
\sобнаруживает все пробелы в виде совпадения. -
_соответствует символу символа подчеркивания литерала ( _ ).
-
- В предыдущем примере варианты 2 и 3 будут соответствовать одному символу. Однако возможность 1 указывает только, где должно начинаться сопоставление. Он не даст результатов в отношении каких-либо совпадений символов.
- Возьмем второй пример,
^\d+$. Этот регулярный выражение будет обнаруживать только строку, состоящую полностью из цифр, от начала до конца. - Регулярные проверки шаблонов в условиях по умолчанию не учитывают регистр. Чтобы учитывать чувствительность регистра, добавьте (?-i) в шаблон
Получение извлеченного текста
Регулярное выражение сопоставляется с извлеченным текстом содержимого, а не с самим содержимым. Таким образом, даже если шаблон отображается в содержимом, он может не совпадать при оценке политики защиты от потери данных.
Чтобы обеспечить запись соответствующих совпадений, выполните следующие действия.
- Используйте командлет Test-TextExtraction , чтобы получить извлеченный текст, который будет состоять из потока строк.
- Затем используйте извлеченный текст для сопоставления регулярного выражения.
Например:
$data = ([System.IO.File]::ReadAllBytes('<FilePath>'))
$tr = Test-TextExtraction -FileData $data
$tr.ExtractedResults.ExtractedStreamText | Format-List
Проверка обнаружения типов конфиденциальной информации
Чтобы проверить обнаружение типа конфиденциальной информации (SIT), необходимо взять только что извлеченный текст, а затем выполнить командлет Test-DataClassification для проверки обнаружения. Результаты выполнения командлета будут указывать, есть ли совпадения SIT для регулярного выражения.
Например:
$textStream = $tr.ExtractedResults.ExtractedStreamText | Out-String
$result = Test-DataClassification -TextToClassify $textStream
$result.ClassificationResults | Format-List
Пример использования регулярного выражения в правиле политики защиты от потери данных
В этом примере мы заблокируем сообщение электронной почты, содержащее строки, начиная с ABC , за которым следует число.
Используется регулярное выражение:^ABC\d
Пример правила защиты от потери данных:New-DlpComplianceRule -Name "Rule_00" -Policy "Policy_00" -SubjectOrBodyMatchesPatterns "^ABC\d" - BlockAccess $True
Пример сообщения электронной почты
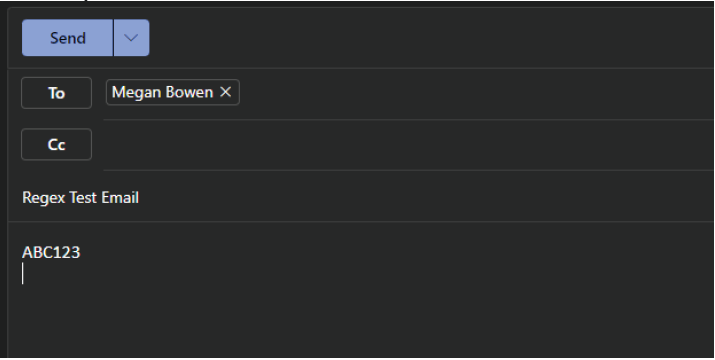
Хотя кажется, что регулярное выражение обнаружит совпадение с этим элементом почты, извлеченный текст выглядит следующим образом:
Regex Test Email ABC123
Как видите, извлеченный текст начинается с содержимого в строке темы сообщения, а не с содержимого в тексте сообщения. Однако для включения символа утверждения в начале регулярного выражения требуется, ^чтобы строка ABC... была в начале извлеченного текста, чтобы было обнаружено совпадение.
Чтобы устранить эту проблему, можно изменить регулярное выражение на ABC\d.