Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Эндрю Маршалл, Джугал Парих, Эмре Кичиман и Рам Шанкар Сива Кумар
Особое спасибо Раул Роджас и AETHER Security Engineering Workstream
Ноябрь 2019 г.
Этот документ представляет собой результат работы группы по проектированию AETHER для рабочей группы ИИ и дополняет существующие методики моделирования угроз SDL, предоставляя новые рекомендации по перечислению угроз и устранению рисков, характерных для области искусственного интеллекта и машинного обучения. Он предназначен для использования в качестве ссылки во время проверок проектирования безопасности следующих элементов:
Продукты и услуги, взаимодействующие с службами на основе искусственного интеллекта и машинного обучения или зависящие от них.
Продукты и услуги, построенные на основе ИИ/ML
Традиционное устранение угроз безопасности является более важным, чем когда-либо. Требования, установленные жизненным циклом разработки безопасности, необходимы для создания основы безопасности продукта, на которой основано данное руководство. Неспособность справиться с традиционными угрозами безопасности способствует атакам, связанным с ИИ/ML, которые описаны в этом документе, как в программном обеспечении, так и в физических областях, а также облегчает компрометацию на более низких уровнях стека программного обеспечения. Общие сведения о новых угрозах безопасности в этом пространстве см. в статье "Защита будущего искусственного интеллекта и машинного обучения в Майкрософт".
Наборы навыков инженеров безопасности и специалистов по обработке и анализу данных обычно не перекрываются. Это руководство позволяет обеим дисциплинам упорядоченные обсуждения этих совершенно новых угроз и мер по их устранению, не требуя от инженеров безопасности становиться специалистами по данным или наоборот.
Этот документ разделен на два раздела:
- "Ключевые новые соображения в моделировании угроз" сосредоточены на новых подходах к мышлению и новых вопросах, которые следует задавать при моделировании угроз для систем ИИ/ML. Как специалисты по обработке и анализу данных, так и инженеры по безопасности должны ознакомиться с этим, так как это будет их сборник схем для обсуждений по моделированию угроз и приоритетов по устранению рисков.
- "Угрозы ИИ/МАШИНного обучения и их устранение рисков" содержат сведения о конкретных атаках, а также конкретных шагах по устранению рисков, используемых сегодня для защиты продуктов и служб Майкрософт от этих угроз. Этот раздел предназначен в основном для специалистов по обработке и анализу данных, которые, возможно, потребуется реализовать конкретные способы устранения угроз в качестве выходных данных процесса моделирования угроз или проверки безопасности.
Это руководство организовано вокруг враждебной таксономии угроз машинного обучения, созданной Рамом Шанкаром Кумаром, Дэвидом О'Брайеном, Кендрой Альберт, Саломе Вильджоэн и Джеффри Сновером под названием "Failure Modes in Machine Learning" ("Режимы сбоя в машинном обучении"). Рекомендации по управлению инцидентами по оценке угроз безопасности, описанных в этом документе, см. Баг-бар SDL для угроз ИИ/ML. Все они — живые документы, которые будут развиваться вместе с изменениями в ландшафте угроз.
Основные новые рекомендации в моделировании угроз: изменение способа просмотра границ доверия
Предположим компрометацию и отравление данных, на которых вы обучаетесь, и поставщика данных. Узнайте, как обнаруживать аномальные и вредоносные записи данных, а также различать и восстанавливать их
Сводка
Учебные хранилища данных и системы, в которых они размещаются, являются частью области моделирования угроз. Самая большая угроза безопасности в машинном обучении сегодня — это отравление данными из-за отсутствия стандартных обнаружений и устранения рисков в этом пространстве, в сочетании с зависимостью от ненадежных или неизвестных общедоступных наборов данных в качестве источников обучающих данных. Отслеживание источника и линии происхождения ваших данных является важным для обеспечения их достоверности и предотвращения цикла обучения по принципу "мусор на входе - мусор на выходе".
Вопросы, задаваемые в обзоре безопасности
Если ваши данные отравлены или изменены, как вы знаете?
-Какую телеметрию вы используете для обнаружения перекоса в качестве ваших обучающих данных?
Вы обучаетесь на данных, предоставленных пользователем?
-Какая проверка и очистка входных данных выполняется для этого содержимого?
- Структура этих данных похожа на таблицы для наборов данных?
Если вы обучаете модель, используя данные из онлайн-хранилищ, какие действия необходимо предпринять для обеспечения безопасности подключения между моделью и источником данных?
-Есть ли у них способ сообщать потребителям своих каналов о компромиссах?
- Они даже способны к тому?
Насколько конфиденциальны данные, из которые вы обучаете?
-Вы каталогизируете это или управляете добавлением, обновлением и удалением записей данных?
Может ли модель выводить конфиденциальные данные?
-Были ли эти данные получены с разрешением от источника?
Выводит ли модель только те результаты, которые необходимы для достижения своей цели?
Возвращает ли модель необработанные оценки достоверности или любые другие прямые выходные данные, которые могут быть записаны и дублированы?
Каковы последствия восстановления обучающих данных путем атаки или инвертирования модели?
Если уровень достоверности выходных данных модели внезапно упадет, вы можете узнать, как или почему, а также данные, вызвавшие его?
Вы определили хорошо сформированные входные данные для модели? Что вы делаете, чтобы убедиться, что входные данные соответствуют этому формату и что делать, если они не?
Если ваши выходные данные неверны, но не приводят к возникновению ошибок, как вы узнаете?
Знаете ли вы, устойчивы ли алгоритмы обучения к враждебному вводу на математическом уровне?
Как вы восстанавливаетесь после враждебного загрязнения данных обучения?
-Можно ли изолировать и поместить на карантин вредоносное содержимое и переобучить затронутые модели?
-Можно ли откатить или восстановить модель предыдущей версии для повторного обучения?
Вы используете обучение с подкреплением для несортированного общедоступного содержимого?
Начните думать о происхождении ваших данных – если вы обнаружите проблему, сможете ли вы отследить момент её включения в набор данных? Если нет, это проблема?
Узнайте, откуда приходят данные обучения, и определите статистические нормы, чтобы начать понимание аномалий
-Какие элементы данных обучения уязвимы для внешнего влияния?
-Кто может внести вклад в наборы данных, на которых вы обучаетесь?
-Как вы нападаете на источники обучающих данных, чтобы повредить конкуренту?
Связанные угрозы и устранение рисков в этом документе
Состязательное пертурбация (все варианты)
Отравление данными (все варианты)
Примеры атак
Принуждение безвредных писем к классификации в спам или невидимость злонамеренного сообщения.
Созданные злоумышленником входные данные, которые снижают уровень достоверности правильной классификации, особенно в сценариях с высоким уровнем последствий.
Злоумышленник вводит шум случайным образом в исходные данные, классифицируемые, чтобы снизить вероятность правильной классификации, используемой в будущем, эффективно глупая модель
Загрязнение обучающих данных для принудительной неправильной классификации определенных точек данных, что приводит к конкретным действиям, выполняемым или опущенным системой
Определите действия, которые могут предпринять ваши модели или продукты или услуги, которые могут причинить вред клиенту в Сети или в физическом домене
Сводка
Оставшиеся неуправляемыми, атаки на системы ИИ/ML могут найти свой путь к физическому миру. Любой сценарий, который может быть закручен к психологически или физическому вреду пользователям, является катастрофическим риском для вашего продукта или службы. Это касается любых конфиденциальных данных о клиентах, используемых для обучения и принятия проектных решений, которые могут привести к утечкам этих личных данных.
Вопросы, задаваемые в обзоре безопасности
Вы обучаетесь на примерах атак? Какое влияние они влияют на выходные данные модели в физическом домене?
Как выглядит троллинг для вашего продукта или службы? Как обнаружить и ответить на него?
Что потребуется, чтобы получить модель, чтобы вернуть результат, который обманывает вашу службу в отказе доступа к законным пользователям?
Какое влияние оказывает копирование или кража вашей модели?
Можно ли использовать модель для вывода членства отдельного человека в определенной группе или просто в обучающих данных?
Может ли злоумышленник вызвать репутационный ущерб или обратную реакцию pr на ваш продукт, заставив его выполнить определенные действия?
Как справляться с отформатированными, но чрезмерно предвзятыми данными, например, от троллей?
Для каждого способа, которым можно взаимодействовать с моделью или обращаться к ней, можно выяснить, раскрывает ли он обучающие данные или функциональные возможности модели?
Связанные угрозы и устранение рисков в этом документе
Инференция принадлежности к множеству
Инверсия модели
Кража моделей
Примеры атак
Восстановление и извлечение обучающих данных путем многократного запроса модели для получения максимальной достоверности результатов
Дублирование модели путем исчерпывающего сопоставления запросов и ответа
Запрос модели таким образом, чтобы показать определенный элемент частных данных был включен в обучающий набор.
Самоуправляемый автомобиль обманывается, чтобы игнорировать знаки остановки или дорожно-транспортный свет
Диалоговые боты, используемые для того, чтобы троллить безобидных пользователей
Определите все источники зависимостей ИИ/ML, а также уровни внешнего представления в цепочке поставок данных и моделей
Сводка
Многие атаки в области искусственного интеллекта и машинного обучения начинаются с законного доступа к API, которые предоставляются для выполнения запросов к модели. Из-за богатых источников данных и богатого пользовательского опыта, аутентифицированный, но «неуместный» (здесь серая зона) доступ сторонних организаций к вашим моделям представляет собой риск из-за возможности служить уровнем представления над службой, предоставленной корпорацией Майкрософт.
Вопросы, задаваемые в обзоре безопасности
Какие клиенты и партнеры проходят проверку подлинности для доступа к вашим API-интерфейсам модели или службы?
-Могут ли они выступать в качестве слоя презентации поверх вашего сервиса?
-Можете ли вы немедленно отозвать доступ в случае компрометации?
-Какова ваша стратегия восстановления в случае злонамеренного использования вашего сервиса или его зависимостей?
Может ли 3-я сторона построить фасад вокруг вашей модели, чтобы перенацеленная модель навредила корпорации Майкрософт или ее клиентам?
Предоставляют ли клиенты данные для обучения напрямую?
-Как защитить эти данные?
-Как поступить, если это злонамеренная атака, и ваш сервис является целью?
Как выглядит ложноположительный результат здесь? Каково влияние ложно-отрицательного результата?
Можно ли отслеживать и измерять отклонение истинных положительных и ложных положительных показателей в нескольких моделях?
Какой вид телеметрии вам нужен, чтобы доказать надежность выходных данных вашей модели клиентам?
Определитевсе 3-сторонние зависимости в цепочке поставок данных машинного обучения и обучения — не только программное обеспечение с открытым исходным кодом, но и поставщики данных.
-Почему вы используете их и как вы проверяете их надежность?
Вы используете предварительно созданные модели от третьих сторон или отправляете обучающие данные сторонним поставщикам MLaaS?
Инвентаризация новостей о атаках на аналогичные продукты и услуги. Учитывая, что многие угрозы в области ИИ и машинного обучения переходят между различными типами моделей, как эти атаки могут повлиять на ваши собственные продукты?
Связанные угрозы и устранение рисков в этом документе
Перепрограммирование нейронной сети
Примеры противодействия в физической области
Вредоносные поставщики машинного обучения восстанавливают обучающие данные
Атака на цепочку поставок для машинного обучения
Модель с закладкой
Скомпрометированные зависимости для машинного обучения
Примеры атак
Вредоносный поставщик MLaaS внедряет троян в вашу модель с помощью специального обхода.
Враждебный клиент находит уязвимость в распространенных зависимостях OSS, которые вы используете, и загружает специально созданный формат данных для обучения, чтобы скомпрометировать ваш сервис.
Недобросовестный партнер использует API распознавания лиц и создает слой представления поверх вашего сервиса для создания дипфейков.
Угрозы, связанные с искусственным интеллектом и машинным обучением, и их устранение
#1: Враждебное возмущение
Описание
При атаках в стиле пертурбации злоумышленник тайно изменяет вопрос, чтобы получить желаемый ответ от модели, используемой в рабочей среде[1]. Это нарушение целостности входных данных модели, что приводит к атакам типа fuzzing, когда конечный результат не обязательно является нарушением доступа или повышением привилегий (EOP), а вместо этого снижает производительность классификации модели. Это также может проявляться в действиях троллей, использующих определенные целевые слова так, что ИИ заблокирует их, фактически отказывая в обслуживании законным пользователям, если их имя совпадает с запрещенным словом.
 [24]
[24]
Вариант #1a: целевая неправильная классификация
В этом случае злоумышленники создают образец, который не входит в входной класс целевого классификатора, но классифицируется моделью как определенный входной класс. Враждебный пример может показаться случайным шумом для человеческих глаз, но злоумышленники обладают определенными знаниями о целевой системе машинного обучения, чтобы создать белый шум, который не является случайным, а использует конкретные аспекты целевой модели. Злоумышленник предоставляет исходный образец, который не является достоверным, но целевая система классифицирует его как достоверный класс.
Примеры
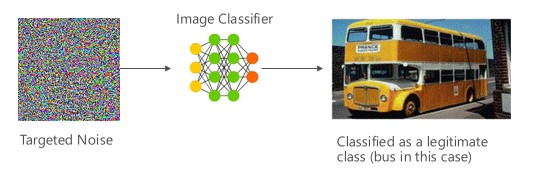 [6]
[6]
Устранение проблем
Укрепление состязательной устойчивости с помощью доверия модели, вызванного состязательным обучением [19]: авторы предлагают Высоко уверенное близкое соседство (HCNN), структуру, которая объединяет информацию о доверии и поиск ближайших соседей, чтобы укрепить состязательную устойчивость базовой модели. Это может помочь отличить правильные и неправильные прогнозы модели в окрестности точки, выбранной из базового обучающего распределения.
Анализ причин, основанный на атрибуции [20]: авторы изучают связь между устойчивостью к враждебным возмущениям и объяснениями, основанными на атрибуции, индивидуальных решений, созданных моделями машинного обучения. Они сообщают, что состязательные входные данные ненадежны в пространстве атрибуции, то есть маскирование нескольких признаков с высокой атрибуцией приводит к изменению ненадежности модели машинного обучения на состязательных примерах. В отличие от этого, естественные входные данные являются надежными в пространстве атрибуции.
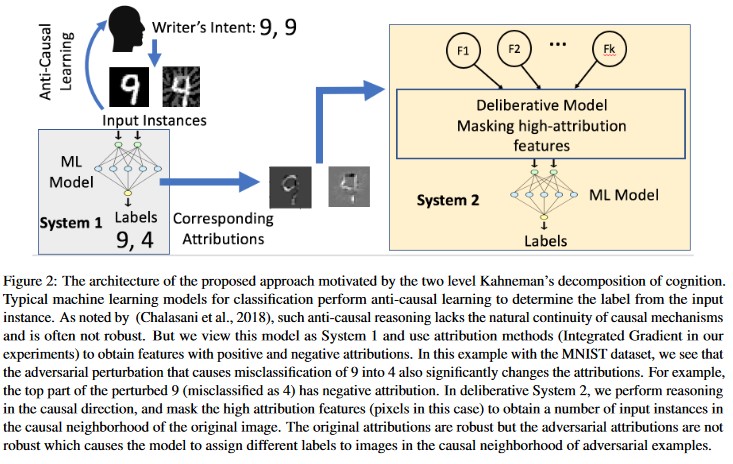 [20]
[20]
Эти подходы могут сделать модели машинного обучения более устойчивыми к состязательным атакам, так как для обмана этой двухуровневой системы распознавания требуется не только атаковать исходную модель, но и гарантировать, что атрибуция, созданная для состязательного примера, похожа на исходные примеры. Обе системы должны быть одновременно скомпрометированы для успешной состязательной атаки.
Традиционные параллели
Удаленное повышение привилегий, так как злоумышленник теперь управляет вашей моделью
Степень серьезности
Критически важно
Вариант #1b: неправильное классификация исходного или целевого объекта
Это характеризуется как попытка злоумышленника привести к тому, чтобы модель возвратила желаемую метку для заданного ввода. Обычно это заставляет модель возвращать ложноположительное или ложное отрицательное значение. Конечный результат — это тонкий захват модели, который позволяет злоумышленнику целенаправленно обойти точность классификации.
Хотя эта атака оказывает значительное негативное влияние на точность классификации, она также может быть более интенсивной для выполнения, учитывая, что злоумышленник должен не только управлять исходными данными, чтобы они больше не помечены правильно, но и помечены специально с требуемой мошеннической меткой. Эти атаки часто включают несколько шагов или попыток, чтобы вызвать ошибочную классификацию [3]. Если модель уязвима для передачи атак обучения, которые принудительно нацелены на неправильное классифицирование, возможно, нет четкого трафика злоумышленников, так как атаки на пробу могут быть выполнены в автономном режиме.
Примеры
Принуждение к классификации безопасных электронных писем как спам или пропуск вредоносных сообщений, чтобы они остались незамеченными. Они также известны как атаки на обход моделей или имитации.
Устранение проблем
Действия реактивного и оборонительного обнаружения
- Установите минимальный временной интервал между вызовами API, предоставляющего результаты классификации. Это замедляет многоэтапное тестирование атак, увеличивая общее время, необходимое для выявления успешного возмущения.
Упреждающие и защитные действия
Повышение устойчивости к атаке путем понижения шума признаков [22]: авторы разрабатывают новую сетевую архитектуру, которая повышает устойчивость к атаке, проводя понижение шума признаков. В частности, сети содержат блоки, которые уменьшают шум признаков с помощью нелокальных методов или других фильтров; все сети обучены от начала до конца. В сочетании с обучением с противодействием сети денойсинга признаков существенно повышают актуальный уровень надежности противодействия как в условиях атаки с открытым доступом, так и с закрытым доступом ('черный ящик').
Обучение с использованием известных состязательных примеров и регуляризация: обучение с целью повышения устойчивости и надежности системы перед вредоносными входными данными. Это также можно рассматривать как форма нормализации, которая наказывает норму входных градиентов и делает функцию прогнозирования классификатора более гладкой (увеличивая поле ввода). Это включает правильные классификации с более низким уровнем достоверности.
Инвестируйте в разработку монотонной классификации с выделением монотонных признаков. Это гарантирует, что злоумышленник не сможет обойти классификатор, просто заполняя признаки из отрицательного класса [13].
Сжатие признаков [18] можно использовать для защиты моделей DNN, обнаруживая состязательные примеры. Он уменьшает пространство поиска, доступное злоумышленнику, путем объединения выборок, которые соответствуют множеству различных векторов признаков в исходном пространстве в одном образце. Сравнивая прогноз модели DNN на исходных входных данных с прогнозом на сжатых данных, сжатие признаков может помочь обнаружить адверсариальные примеры. Если исходные и сжатые примеры существенно отличаются по результатам модели, входные данные, вероятно, являются враждебными. Измеряя разногласия между прогнозами и выбирая пороговое значение, система может выводить правильный прогноз для законных примеров и отклонять состязательные входные данные.

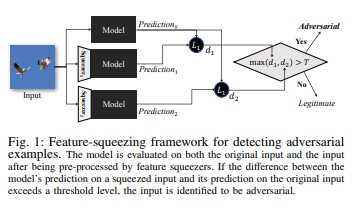 [18]
[18]Сертифицированные защиты от примеров атак [22]: авторы предлагают метод, основанный на полуопределенном расслаблении, который выводит сертификат, подтверждающий невозможность того, что для заданной сети и тестового входа атака приведет к увеличению ошибки выше заданного значения. Во-вторых, так как этот сертификат дифференцируемый, авторы совместно оптимизируют его с сетевыми параметрами, предоставляя адаптивный регуляризатор, который поощряет устойчивость ко всем атакам.
Действия ответа
- Выпуск оповещений о результатах классификации с высоким различием между классификаторами, особенно если они от одного пользователя или небольшой группы пользователей.
Традиционные параллели
Удаленное повышение привилегий
Степень серьезности
Критически важно
Вариант #1c: случайная неправильная классификация
Это особый вариант, в котором целевая классификация злоумышленника может быть отличной от законной классификации источников. Атака обычно включает внедрение шума случайным образом в исходные данные, классифицируемые, чтобы снизить вероятность правильной классификации, используемой в будущем [3].
Примеры
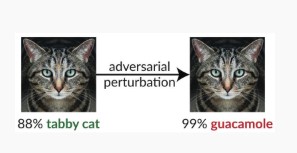
Устранение проблем
Совпадает с вариантом 1a.
Традиционные параллели
Непрекращающийся отказ в обслуживании
Степень серьезности
Это важно
Вариант #1d: уменьшение достоверности
Злоумышленник может создавать входные данные, чтобы снизить уровень достоверности правильной классификации, особенно в сценариях с высоким уровнем последствий. Это также может иметь форму большого количества лжесигналов, предназначенных для перегрузки администраторов или систем мониторинга с мошенническими предупреждениями, неотличимыми от законных оповещений [3].
Примеры

Устранение проблем
- Помимо действий, описанных в variant #1a, можно использовать регулирование событий для уменьшения объема оповещений из одного источника.
Традиционные параллели
Непрекращающийся отказ в обслуживании
Степень серьезности
Это важно
#2a целевое отравление данных
Описание
Цель злоумышленника заключается в том, чтобы загрязнить модель компьютера, созданную на этапе обучения, чтобы прогнозы на новых данных были изменены на этапе тестирования[1]. В целевых атаках с использованием отравления злоумышленник хочет ошибочно классифицировать конкретные примеры, чтобы вызвать выполнение или игнорирование определённых действий.
Примеры
Представление антивирусного программного обеспечения как вредоносного с целью его неправильной классификации и устранения использования целевого антивируса в системах клиентов.
Устранение проблем
Определите датчики аномалий для анализа распределения данных на ежедневной основе и оповещения о изменениях
-Измерять изменчивость обучающих данных ежедневно, телеметрия для перекоса и дрейфа.
Проверка входных данных, как очистка, так и проверка целостности
Отравление внедряет излишающие образцы обучения. Две основные стратегии борьбы с этой угрозой:
-Санация/валидация данных: удалите коррумпированные образцы из обучающих данных -Bagging для борьбы с атаками с использованием отравления [14]
-Функция отклоненияNegative-Impact (RONI) защиты [15]
-Надежное обучение: выберите алгоритмы обучения, которые являются надежными в присутствии образцов отравлений.
-Один такой подход описан в [21], где авторы решают проблему отравлений данных двумя шагами: 1) вводя новый надежный метод факторизации матрицы для восстановления истинного подпространства, и 2) новый надежный метод регрессии на основе главных компонент для обрезания враждебных экземпляров на основе, восстановленной на шаге 1. Они характеризуют необходимые и достаточные условия для успешного восстановления истинного подпространства и представляют границу ожидаемой потери прогноза по сравнению с истинными данными.
Традиционные параллели
Компьютер, зараженный трояном, где злоумышленник находится в сети. Данные для обучения или конфигурации скомпрометированы и используются для создания модели.
Степень серьезности
Критически важно
#2b неизбирательное отравление данных
Описание
Цель заключается в том, чтобы разрушить качество и целостность набора данных, на который нападает атака. Многие наборы данных являются общедоступными или ненадежными или неизвестными, поэтому это создает дополнительные проблемы по поводу возможности обнаружения таких нарушений целостности данных в первую очередь. Обучение на неосознанно скомпрометированных данных приводит к ошибочным результатам. После обнаружения необходимо определить объем данных, подвергшихся утечке, и провести их изоляцию/переобучение.
Примеры
Компания собирает данные с известного и надежного веб-сайта о фьючерсах на нефть для обучения своих моделей. Веб-сайт поставщика данных затем скомпрометирован посредством атаки типа SQL-инъекция. Злоумышленник может отравить набор данных, а обученная модель не имеет понятия о том, что данные запятнаются.
Устранение проблем
Совпадает с вариантом 2a.
Традиционные параллели
Аутентифицированный отказ в обслуживании ценного ресурса
Степень серьезности
Это важно
#3 Атаки инверсии модели
Описание
Частные функции, используемые в моделях машинного обучения, можно восстановить [1]. Это включает в себя восстановление частных обучающих данных, к которым злоумышленник не имеет доступа. Также известные как атаки подъёма в биометрических сообществах [16, 17]. Это достигается путем поиска таких входных данных, которые максимизируют возвращаемый уровень достоверности при условии, что классификация совпадает с целевой [4].
Примеры
 [4]
[4]
Устранение проблем
Интерфейсы для моделей, обученных из конфиденциальных данных, требуют строгого контроля доступа.
Запросы с ограничением скорости, разрешенные моделью
Реализуйте шлюзы между пользователями/абонентами и фактической моделью, выполняя проверку корректности входных данных во всех предлагаемых запросах, отклоняя все, что не удовлетворяет определению модели правильности ввода и возвращая только минимальный объем информации, нужной для практического использования.
Традиционные параллели
Целевое, скрытое раскрытие информации
Степень серьезности
Это по умолчанию считается важным согласно стандартной панели ошибок SDL, но извлечение конфиденциальных или личных данных повышает его до критически важного уровня.
Атака на вывод об участии №4
Описание
Злоумышленник может определить, является ли данная запись данных частью обучающего набора данных модели или нет[1]. Исследователи смогли предсказать основную процедуру пациента (например, пациент перенес операцию) исходя из таких атрибутов, как возраст, пол пациента, больница [1].
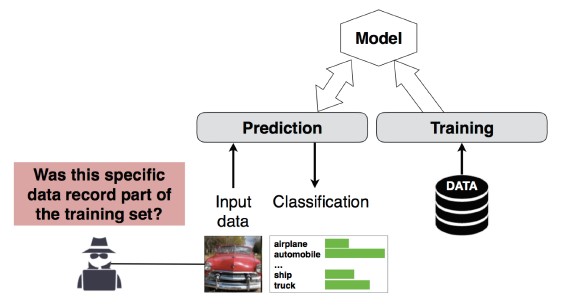 [12]
[12]
Устранение проблем
Исследовательские работы, демонстрирующие жизнеспособность этой атаки, указывают на то, что дифференциальная конфиденциальность [4, 9] может быть эффективным средством смягчения. Это всё ещё находящаяся в зачаточном состоянии область в Microsoft и AETHER Security Engineering рекомендует развивать экспертизу посредством исследовательских инвестиций в этой области. Это исследование должно было бы перечислить возможности дифференциальной конфиденциальности и оценить их эффективность практических мер по снижению рисков, а затем разработать способы прозрачного наследования этих защит на платформах онлайн-сервисов, аналогично тому, как компиляция кода в Visual Studio предоставляет on-by-default защиты безопасности, которые являются прозрачными для разработчика и пользователей.
Использование выпадения нейронов и модельного стека может быть эффективным средством смягчения в значительной степени. Использование удаления нейронов не только повышает устойчивость нейронной сети к этой атаке, но и повышает производительность модели [4].
Традиционные параллели
Конфиденциальность данных. Вывод делается о включении точки данных в набор обучения, но сами данные обучения не раскрываются.
Степень серьезности
Это проблема конфиденциальности, а не проблема безопасности. Он рассматривается в руководстве по моделированию угроз, поскольку домены перекрываются, но здесь решения основываются на конфиденциальности, а не на безопасности.
№5 Кража моделей
Описание
Злоумышленники воссоздают основную модель, делая законные запросы к модели. Функциональные возможности новой модели совпадают с функциональностью базовой модели[1]. После повторного создания модели её можно инвертировать, чтобы восстановить информацию о признаках или сделать выводы на основе обучающих данных.
Решение уравнений. Для модели, которая возвращает вероятности класса через выходные данные API, злоумышленник может создавать запросы для определения неизвестных переменных в модели.
Поиск пути — атака, которая использует особенности API для извлечения "решений", принятых деревом при классификации входных данных [7].
Атака на передачу — злоумышленник может обучить локальную модель , возможно, выдав прогнозные запросы в целевую модель и использовать ее для создания состязательные примеры, которые передаются в целевую модель [8]. Если вашу модель извлекли и обнаружили уязвимой для атакующего типа ввода, злоумышленник, который извлек копию вашей модели, может полностью в автономном режиме разработать новые атаки против модели, внедренной в рабочую среду.
Примеры
В условиях, где модель машинного обучения используется для обнаружения враждебного поведения, например идентификации нежелательной почты, классификации вредоносных программ и обнаружения сетевых аномалий, извлечение модели может способствовать атакам уклонения [7].
Устранение проблем
Упреждающие и защитные действия
Свести к минимуму или скрыть сведения, возвращаемые в API прогнозирования, сохраняя их полезность для "честных" приложений [7].
Сформулируйте хорошо сформированный запрос для входных данных вашей модели и возвращайте только результаты в ответ на завершенные, хорошо сформированные входные данные, соответствующие этому формату.
Возвращает округленные значения достоверности. Большинство звонящих не нуждаются в высокой точности, выраженной несколькими десятичными знаками.
Традиционные параллели
Неуверенное, доступное только для чтения изменение системных данных, целевое раскрытие информации с высоким уровнем ценности?
Степень серьезности
Важно в моделях с учетом безопасности, умеренно в противном случае
Перепрограммирование нейронной сети #6
Описание
С помощью специально созданного запроса от злоумышленника системы машинного обучения можно перепрограммировать в задачу, которая отклоняется от первоначального намерения создателя [1].
Примеры
Слабое управление доступом для API распознавания лиц позволяет третьим сторонам интегрировать в приложения, предназначенные для нанесения вреда клиентам Майкрософт, такие как генератор дипфейков.
Устранение проблем
Надежная взаимная клиент-серверная аутентификация и управление доступом к интерфейсам модели
Удаление учетных записей, нарушающих правила.
Определите и примените соглашение об уровне обслуживания для API. Определите допустимое время устранения проблемы после сообщения и убедитесь, что проблема больше не повторяется после истечения срока действия соглашения об уровне обслуживания.
Традиционные параллели
Это сценарий злоупотреблений. Вероятнее всего, вы просто отключите учетную запись нарушителя, чем откроете инцидент безопасности по этому поводу.
Степень серьезности
От важного до критического
#7 Состязательный пример в физическом домене (бит-атомы>)
Описание
Пример состязательности — это ввод или запрос от вредоносной сущности, отправленной с единственной целью ввести в заблуждение систему машинного обучения [1]
Примеры
Эти примеры могут проявляться в физической области, например, когда самоуправляемый автомобиль обманут и нарушает знак остановки из-за определенного цвета света (враждебный сигнал), который направляется на знак остановки, заставляя систему распознавания изображений перестать распознавать его как знак остановки.
Традиционные параллели
Повышение привилегий, удаленное выполнение кода
Устранение проблем
Эти атаки проявляются, так как проблемы на уровне машинного обучения (уровень данных и алгоритмов ниже принятия решений на основе ИИ) не были устранены. Как и в любой другой физической системе программного обеспечения *или*, уровень ниже целевого объекта всегда может быть атакован с помощью традиционных векторов. Из-за этого традиционные методики безопасности более важны, чем когда-либо, особенно с уровнем неуправляемых уязвимостей (уровень данных или алго), используемых между ИИ и традиционным программным обеспечением.
Степень серьезности
Критически важно
#8 Вредоносные поставщики машинного обучения, которые могут восстановить обучающие данные
Описание
Вредоносный поставщик представляет алгоритм с бэкдоров, в котором восстанавливаются конфиденциальные данные обучения. Они смогли восстановить лица и тексты, лишь с помощью модели.
Традиционные параллели
Раскрытие целевой информации
Устранение проблем
Исследовательские документы, демонстрирующие жизнеспособность этой атаки, свидетельствуют о том, что гомоморфное шифрование будет эффективным решением. Это область, в которую Microsoft пока мало инвестирует, и AETHER Security Engineering рекомендует развивать экспертизу через инвестиции в исследования в этой области. Это исследование должно перечислить принципы гомоморфного шифрования и оценить их практическую эффективность в качестве мер по смягчению угроз со стороны вредоносных поставщиков услуг по модели ML-as-a-Service.
Степень серьезности
Важно, если данные содержат ПДИ (персонально идентифицируемую информацию), умеренно важно в противном случае
#9 Атака на цепь поставок в области машинного обучения
Описание
Из-за больших ресурсов (данных и вычислений), необходимых для обучения алгоритмов, текущая практика заключается в повторном использованию моделей, обученных крупными корпорациями, и немного изменять их для задач (например, ResNet является популярной моделью распознавания изображений от Майкрософт). Эти модели курируются в зоопарке моделей (Caffe размещает популярные модели распознавания изображений). В этой атаке злоумышленник направляет действия на модели, размещенные в Caffe, тем самым делая их бесполезными для всех остальных. [1]
Традиционные параллели
Компрометация сторонних зависимостей, не относящихся к безопасности
Неосознанно размещая вредоносные программы в магазине приложений
Устранение проблем
Свести к минимуму сторонние зависимости для моделей и данных, где это возможно.
Включите эти зависимости в процесс моделирования угроз.
Используйте надежную проверку подлинности, управление доступом и шифрование между 1st/3 сторонними системами.
Степень серьезности
Критически важно
#10 Backdoor Machine Learning
Описание
Учебный процесс передается третьей стороне злоумышленника, который вмешивается в данные обучения и предоставляет троянскую модель, которая вынуждает целенаправленные ошибочные классификации, например, классифицировать определенный вирус как безвредный[1]. Это риск в сценариях создания моделей машинного обучения как службы.
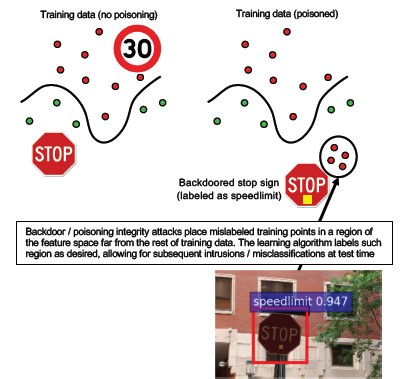 [12]
[12]
Традиционные параллели
Компрометация компонентов безопасности сторонних производителей
Скомпрометированный механизм обновления программного обеспечения
Компрометация центра сертификации
Устранение проблем
Действия реактивного и оборонительного обнаружения
- Ущерб уже был нанесен после обнаружения этой угрозы, поэтому модель и все обучающие данные, предоставляемые вредоносным поставщиком, не могут быть доверенными.
Упреждающие и защитные действия
Обучение всех конфиденциальных моделей внутри компании.
Каталогизируйте обучающие данные или убедитесь, что они поступают от доверенной стороны с соблюдением строгих норм безопасности.
Модель угроз для взаимодействия между поставщиком MLaaS и собственными системами
Действия ответа
- То же, что и для компрометации внешней зависимости
Степень серьезности
Критически важно
#11 Использование программных зависимостей системы машинного обучения
Описание
В этой атаке злоумышленник не управляет алгоритмами. Вместо этого использует уязвимости программного обеспечения, такие как переполнение буфера или межсайтовое скриптирование[1]. По-прежнему проще компрометировать уровни программного обеспечения под ИИ/ML, чем атаковать уровень обучения напрямую, поэтому традиционные методики устранения угроз безопасности, описанные в жизненном цикле разработки безопасности, являются важными.
Традиционные параллели
Скомпрометированная зависимость программного обеспечения с открытым исходным кодом
Уязвимость веб-сервера (XSS, CSRF, сбой проверки входных данных API)
Устранение проблем
Работайте с вашей командой безопасности, чтобы следовать применимым рекомендациям по жизненному циклу разработки системы безопасности и операционной безопасности.
Степень серьезности
Переменная; До критического значения в зависимости от типа традиционной уязвимости программного обеспечения.
Список литературы
[1] Режимы сбоя в машинном обучении, Рам Шанкар Сива Кумар, Дэвид О'Брайен, Кендра Альберт, Салом Вильджоэн и Джеффри Snover, https://learn.microsoft.com/security/failure-modes-in-machine-learning
[2] Направление инженерии безопасности AETHER, происхождение данных, v-team
[3] Примеры состязательности в глубоком обучении: характеризация и расхождение, Wei, et al, https://arxiv.org/pdf/1807.00051.pdf
[4] Утечки данных в моделях машинного обучения: независимые от модели и данных атаки и защита, Салем и др. https://arxiv.org/pdf/1806.01246v2.pdf
[5] М. Фредриксон, С. Джха и Т. Ристенпарт, "Атаки обратного моделирования, которые эксплуатируют информацию о доверии, и основные контрмеры", в трудах конференции ACM SIGSAC по безопасности компьютерных и коммуникационных систем (CCS).
[6] Николас Papernot и Патрик Макданиэль - состязательные примеры в машинном обучении AIWTB 2017
[7] Кража моделей машинного обучения с помощью API прогнозирования, Флориан Трамэр, École Polytechnique Fédérale de Lausanne (EPFL); Фан Чжан, Университет Корнелла; Ари Джуелс, Корнелл Тех; Майкл К. Рейтер, Университет Северной Каролины в Чапел Хилл; Томас Ристенпарт, Корнелл Тех
[8] Пространство переносимых противодействующих примеров, Флориан Трамер, Николас Папернот, Ян Гудфеллоу, Дэн Боне, и Патрик МакДэниэл
[9] Понимание выводов членства в Well-Generalized модели обучения Yunhui Long1, Винсент Bindschaedler1, Лей Wang2, Diyue Bu2, Xiaofeng Wang2, Haixu Tang2, Карл A. Gunter1 и Kai Chen3,4
[10] Simon-Gabriel и соавторы, уязвимость нейронных сетей к атаке увеличивается с увеличением входной размерности, ArXiv 2018;
[11] Lyu et al., унифицированное семейство градиентной регуляризации для состязательных примеров, ICDM 2015
[12] Дикие шаблоны: десять лет после подъема состязательного машинного обучения - NeCS 2019 Battista Biggioa, Fabio Roli
[13] Проверенно устойчивое обнаружение вредоносных программ с применением монотонной классификации Иниго Инсера и др.
[14] Battista Biggio, Igino Corona, Джорджио Фумера, Джорджио Джиачинто и Фабио Роли. Классификаторы бэггинга для борьбы с атаками отравления в задачах классификации в условиях противодействия
[15] Улучшенная защита от негативного воздействия Хонгцзян Ли и Патрик П.К. Чан
[16] Адлер. Уязвимости в биометрических системах шифрования. 5-я Международная конференция AVBPA, 2005
[17] Галбалли, МакКул, Фиеррес, Марсель, Ортега-Гарсия. Уязвимость систем верификации лиц к атакам восхождения. Пэтт. Rec., 2010
[18] Вейлин Су, Дэвид Эванс, Янжун Ци. Сжатие признаков: обнаружение враждебных примеров в глубоких нейронных сетях. 2018 г. Сетевой и распределенный семинар по безопасности системы. 18-21 февраля.
[19] Усиление устойчивости к атаке с помощью уверенности модели, обеспеченной состязательным обучением - Xi Wu, Uyeong Jang, Jiefeng Chen, Lingjiao Chen, Somesh Jha
[20] Причинно-ориентированный анализ, основанный на атрибуции, для обнаружения состязательных примеров, Susmit Jha, Sunny Raj, Стивен Фернандес, Sumit Kumar Jha, Somesh Jha, Gunjan Verma, Брайан Джалаян, Ananthram Swami
[21] Устойчивость линейной регрессии к подделке обучающих данных — Chang Liu et al.
[22] Шумоподавление признаков для улучшения адверсариальной устойчивости, Cihang Xie, Yuxin Wu, Лоренс ван дер Маатен, Алан Юилль, Kaiming He
[23] Сертифицированные защиты от враждебных примеров - Aditi Raghunathan, Джейкоб Штайнхардт, Перси Лианг