Общие сведения о вычислительных пулах в Кластерах больших данных SQL Server
Область применения: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Внимание
Поддержка надстройки "Кластеры больших данных" Microsoft SQL Server 2019 будет прекращена. Мы прекратим поддержку Кластеров больших данных SQL Server 2019 28 февраля 2025 г. Все существующие пользователи SQL Server 2019 с Software Assurance будут полностью поддерживаться на платформе, и программное обеспечение будет продолжать поддерживаться с помощью накопительных обновлений SQL Server до этого времени. Дополнительные сведения см. в записи блога объявлений и в статье о параметрах больших данных на платформе Microsoft SQL Server.
В этой статье описывается назначение пулов вычислений SQL Server в кластере больших данных SQL Server. Вычислительные пулы обеспечивают горизонтальное масштабирование вычислительных ресурсов для кластера больших данных SQL Server. Они используются для разгрузки главного экземпляра SQL Server, беря на себя вычислительные операции или промежуточные результирующие наборы. В следующих разделах содержатся сведения об архитектуре, функциональных возможностях и сценариях использования вычислительного пула.
Вы также можете просмотреть это пятиминутное видео для ознакомления с вычислительными пулами:
Архитектура вычислительного пула
Вычислительный пул состоит из одного или нескольких вычислительных объектов pod, работающих в Kubernetes. Автоматическое создание этих объектов и управление ими координируется главным экземпляром SQL Server. Каждый объект pod содержит набор базовых служб и экземпляр ядра СУБД SQL Server.
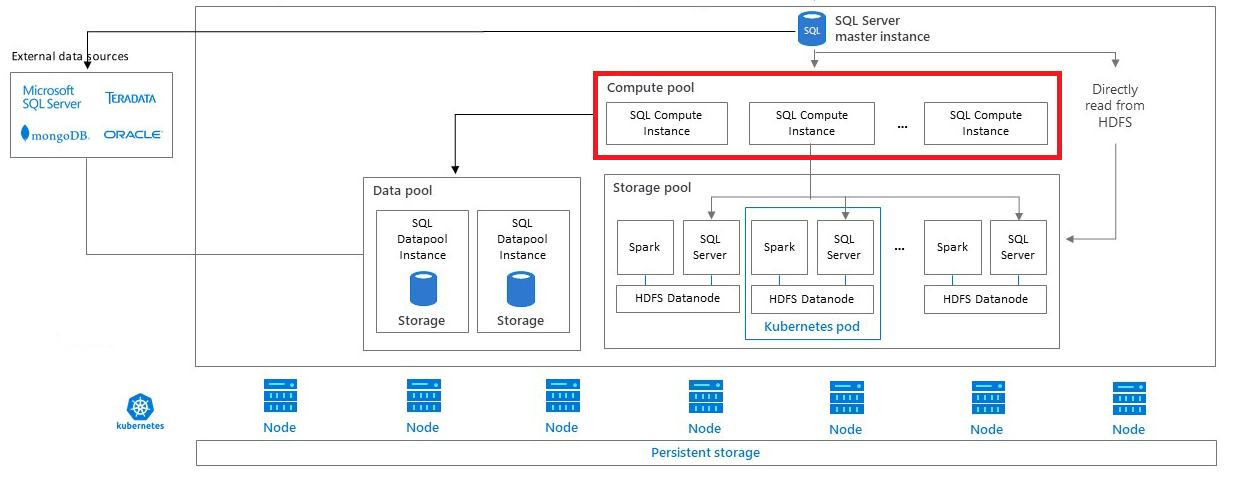
Масштабируемые группы
Вычислительный пул может выступать в роли группы горизонтального увеличения масштаба PolyBase для распределенных запросов к внешним источникам данных, таким как SQL Server, Oracle, MongoDB, Teradata или HDFS. Kubernetes позволяет автоматизировать создание и настройку вычислительных объектов pod в кластерах больших данных SQL Server для групп горизонтального увеличения масштаба PolyBase.
Сценарии использования вычислительных пулов
Ниже перечислены сценарии, в которых используется вычислительный пул:
Когда запросы, отправленные в главный экземпляр, используют одну или несколько таблиц, расположенных в пуле носителей.
Когда запросы, отправленные в главный экземпляр, используют одну или несколько таблиц с циклическим распределением, расположенных в пуле данных.
Когда запросы, отправленные в главный экземпляр, используют секционированные таблицы с внешними источниками данных (SQL Server, Oracle, MongoDB и Teradata). В этом сценарии должно быть включено указание запроса OPTION (FORCE SCALEOUTEXECUTION).
Когда запросы, отправленные в главный экземпляр, используют одну или несколько таблиц, расположенных в распределении по уровням HDFS.
Ниже перечислены сценарии, в которых не используется вычислительный пул:
Когда запросы, отправленные в главный экземпляр, используют одну или несколько таблиц во внешнем кластере Hadoop HDFS.
Когда запросы, отправленные в главный экземпляр, используют одну или несколько таблиц в Хранилище BLOB-объектов Azure.
Когда запросы, отправленные в главный экземпляр, используют несекционированные таблицы с внешними источниками данных (SQL Server, Oracle, MongoDB и Teradata).
Когда включено указание запроса OPTION (DISABLE SCALEOUTEXECUTION).
Когда запросы, отправленные в главный экземпляр, применяются к базам данных, расположенным в главном экземпляре.
Следующие шаги
Дополнительные сведения о Кластеры больших данных SQL Server см. в следующих ресурсах:
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по