Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Область применения:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Это важно
Надстройка "Кластеры больших данных Microsoft SQL Server 2019" будет прекращена. Поддержка кластеров больших данных SQL Server 2019 завершится 28 февраля 2025 г. Все существующие пользователи SQL Server 2019 с Software Assurance будут полностью поддерживаться на этой платформе, а программное обеспечение будет продолжать поддерживаться с помощью накопительных обновлений для SQL Server до этого времени. Для получения дополнительной информации см. запись блога об объявлении и параметры работы с большими данными на платформе Microsoft SQL Server.
В этой статье приведен пример использования kubeadm для настройки Kubernetes на нескольких компьютерах для развертываний кластеров больших данных SQL Server. В этом примере несколько компьютеров Ubuntu 16.04 или 18.04 LTS (физических или виртуальных) являются целевыми. При развертывании на другой платформе Linux необходимо изменить некоторые команды, чтобы соответствовать системе.
Подсказка
Примеры сценариев, которые настраивают Kubernetes, см. в разделе "Создание кластера Kubernetes с помощью Kubeadm" в Ubuntu 20.04 LTS.
Пример скрипта, который автоматизирует развертывание развертывания одного узла kubeadm на виртуальной машине, а затем развертывает конфигурацию кластера больших данных по умолчанию поверх него, см. в разделе развертывания кластера kubeadm с одним узлом.
Предпосылки
- Не менее трех физических машин или виртуальных машин Linux
- Рекомендуемая конфигурация для каждого компьютера:
- 8 ЦП
- 64 ГБ памяти
- 100 ГБ хранилища
Это важно
Перед началом развертывания кластера больших данных убедитесь, что часы синхронизируются во всех узлах Kubernetes, предназначенных для развертывания. В кластере больших данных имеются встроенные свойства диагностики состояния для различных служб, которые чувствительны к временным задержкам, и расхождения времени могут привести к неверному определению состояния.
Подготовка компьютеров
На каждом компьютере существует несколько необходимых компонентов. В терминале Bash выполните следующие команды на каждом компьютере:
Добавьте текущую машину в файл
/etc/hosts.echo $(hostname -i) $(hostname) | sudo tee -a /etc/hostsОтключите переключение на всех устройствах.
sudo sed -i "/ swap / s/^/#/" /etc/fstab sudo swapoff -aИмпортируйте ключи и зарегистрируйте репозиторий для Kubernetes.
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo sudo tee /etc/apt/trusted.gpg.d/apt-key.asc echo 'deb http://apt.kubernetes.io/ kubernetes-xenial main' | sudo tee -a /etc/apt/sources.list.d/kubernetes.listНастройте необходимые компоненты docker и Kubernetes на компьютере.
KUBE_DPKG_VERSION=1.15.0-00 #or your other target K8s version, which should be at least 1.13. sudo apt-get update && \ sudo apt-get install -y ebtables ethtool && \ sudo apt-get install -y docker.io && \ sudo apt-get install -y apt-transport-https && \ sudo apt-get install -y kubelet=$KUBE_DPKG_VERSION kubeadm=$KUBE_DPKG_VERSION kubectl=$KUBE_DPKG_VERSION && \ curl https://raw.githubusercontent.com/kubernetes/helm/master/scripts/get | bashЗадайте
net.bridge.bridge-nf-call-iptables=1. Сначала в Ubuntu 18.04 выполните следующие команды, чтобы включитьbr_netfilter.. /etc/os-release if [ "$VERSION_CODENAME" == "bionic" ]; then sudo modprobe br_netfilter; fi sudo sysctl net.bridge.bridge-nf-call-iptables=1
Настройка главного узла Kubernetes
После выполнения предыдущих команд на каждом компьютере выберите один из компьютеров, чтобы быть главным мастером Kubernetes. Затем выполните следующие команды на этом компьютере.
Сначала создайте файл rbac.yaml в текущем каталоге с помощью следующей команды.
cat <<EOF > rbac.yaml apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: default-rbac subjects: - kind: ServiceAccount name: default namespace: default roleRef: kind: ClusterRole name: cluster-admin apiGroup: rbac.authorization.k8s.io EOFИнициализировать мастер Kubernetes на этой машине. Приведенный ниже пример скрипта указывает версию
1.15.0Kubernetes. Используемая версия зависит от кластера Kubernetes.KUBE_VERSION=1.15.0 sudo kubeadm init --pod-network-cidr=10.244.0.0/16 --kubernetes-version=$KUBE_VERSIONВы должны увидеть сообщение о том, что главный узел Kubernetes успешно инициализирован.
Обратите внимание на
kubeadm joinкоманду, которую необходимо использовать на других серверах для присоединения к кластеру Kubernetes. Скопируйте его для последующего использования.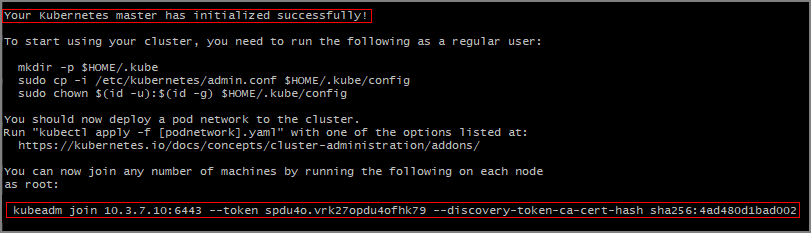
Настройте файл конфигурации Kubernetes для домашнего каталога.
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/configНастройте кластер и панель мониторинга Kubernetes.
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml helm init kubectl apply -f rbac.yaml kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/deploy/recommended/kubernetes-dashboard.yaml kubectl create clusterrolebinding kubernetes-dashboard --clusterrole=cluster-admin --serviceaccount=kube-system:kubernetes-dashboard
Настройка агентов Kubernetes
Другие компьютеры будут выступать в качестве агентов Kubernetes в кластере.
На каждом из других компьютеров выполните kubeadm join команду, скопированную в предыдущем разделе.

Просмотр состояния кластера
Чтобы проверить подключение к кластеру, используйте команду kubectl get для получения списка узлов кластера.
kubectl get nodes
Дальнейшие шаги
Действия, описанные в этой статье, настраивают кластер Kubernetes на нескольких компьютерах Ubuntu. Следующим шагом является развертывание кластера больших данных SQL Server 2019. Инструкции см. в следующей статье: