Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Область применения:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
Кластеры больших данных Microsoft SQL Server 2019 прекращены. Поддержка кластеров больших данных SQL Server 2019 закончилась с 28 февраля 2025 г. Дополнительные сведения см. в записи блога объявлений и параметрах больших данных на платформе Microsoft SQL Server.
В этом руководстве показано, как загрузить и запустить записную книжку в Azure Data Studio в кластере больших данных SQL Server 2019. Это позволяет специалистам по обработке и анализу данных запускать код Python, R или Scala в кластере.
Tip
Если вы предпочитаете, вы можете скачать и запустить скрипт для команд, приведенных в этом руководстве. Инструкции см. в примерах Spark на GitHub.
Prerequisites
-
Средства работы с большими данными
- kubectl
- Azure Data Studio
- Расширение SQL Server 2019
- Загрузка примеров данных в кластер больших данных
Скачивание примера файла записной книжки
Используйте следующие инструкции, чтобы загрузить пример файла записной книжки spark-sql.ipynb в Azure Data Studio.
Откройте командную строку bash (Linux) или Windows PowerShell.
Перейдите в каталог, в который нужно скачать пример файла записной книжки.
Выполните следующую команду curl , чтобы скачать файл записной книжки из GitHub:
curl https://raw.githubusercontent.com/Microsoft/sql-server-samples/master/samples/features/sql-big-data-cluster/spark/data-loading/transform-csv-files.ipynb -o transform-csv-files.ipynb
Открытие записной книжки
Ниже показано, как открыть файл записной книжки в Azure Data Studio:
В Azure Data Studio подключитесь к главному экземпляру кластера больших данных. Дополнительные сведения см. в разделе "Подключение к кластеру больших данных".
Дважды щелкните подключение шлюза HDFS/Spark в окне "Серверы". Затем выберите "Открыть записную книжку".
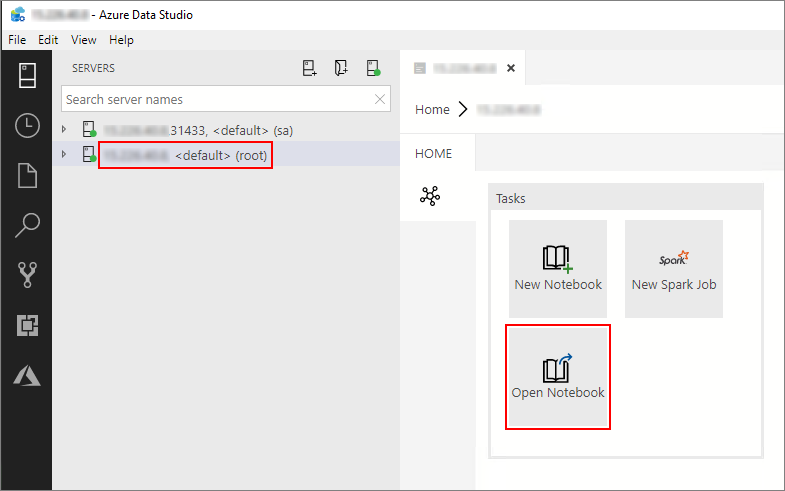
Дождитесь, пока будет заполнено поле Ядро и задан целевой контекст (Присоединить к). Установите для Kernel значение PySpark3 и задайте Attach to IP-адрес конечной точки вашего кластера больших данных.
Important
В Azure Data Studio все типы записных книжек Spark (Scala Spark, PySpark и SparkR) обычно определяют некоторые важные переменные сеанса Spark при первом выполнении ячеек. Эти переменные: spark, scи sqlContext. При копировании логики из записных книжек для пакетной отправки (например, в файл azdata bdc spark batch create Python), убедитесь, что вы определяете переменные соответствующим образом.
Запуск ячеек записной книжки
Каждую ячейку записной книжки можно запустить, нажав кнопку воспроизведения слева от ячейки. После того как выполнение ячейки будет завершено, в записной книжке будут показаны результаты.

Запустите каждую ячейку в образце блокнота последовательно. Дополнительные сведения об использовании записных книжек с кластерами больших данных SQL Server см. в следующих ресурсах:
Next steps
Дополнительные сведения о записных книжках: