Отладка и диагностика приложений Spark на sql Server Кластеры больших данных в сервере журнала Spark
Область применения: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Внимание
Поддержка надстройки "Кластеры больших данных" Microsoft SQL Server 2019 будет прекращена. Мы прекратим поддержку Кластеров больших данных SQL Server 2019 28 февраля 2025 г. Все существующие пользователи SQL Server 2019 с Software Assurance будут полностью поддерживаться на платформе, и программное обеспечение будет продолжать поддерживаться с помощью накопительных обновлений SQL Server до этого времени. Дополнительные сведения см. в записи блога объявлений и в статье о параметрах больших данных на платформе Microsoft SQL Server.
В этой статье содержатся указания по использованию расширенного сервера журнала Spark для отладки и диагностики приложений Spark в кластере больших данных SQL Server. Эти возможности отладки и диагностики встроены в сервер журнала Spark и обеспечиваются технологиями корпорации Майкрософт. Расширение включает вкладку данных и вкладку графа и вкладку диагностики. На вкладке данных пользователи могут проверять входные и выходные данные задания Spark. На вкладке графа пользователи могут проверять поток данных и воспроизводить граф задания. На вкладке диагностики пользователь может просматривать результаты анализа неравномерного распределения данных, неравномерного распределения времени и использования исполнителя.
Получение доступа к серверу журнала Spark
Интерфейс сервера журнала Spark в рамках проекта с открытым кодом дополняется такой информацией, как данные по заданиям и интерактивная визуализация графа заданий и потоков данных для кластера больших данных.
Открытие пользовательского веб-интерфейса сервера журнала Spark по URL-адресу
Чтобы открыть сервер журнала Spark, перейдите по приведенному ниже URL-адресу, заменив <Ipaddress> и <Port> на значения для кластера больших данных. В кластерах, развернутых до выпуска накопительного пакета обновления 5 (CU5) для SQL Server 2019, с конфигурацией кластера больших данных с обычной проверкой подлинности (имя пользователя и пароль) для входа в конечные точки шлюза (Knox) необходимо предоставить учетные данные привилегированного пользователя. См. раздел Развертывание кластера больших данных SQL Server. Начиная с SQL Server 2019 (15.x) CU 5 при развертывании нового кластера с базовой проверкой подлинности всех конечных точек, включая использование AZDATA_USERNAME шлюза и AZDATA_PASSWORD. Конечные точки в кластерах, которые обновлены до накопительного пакета обновления 5, продолжают использовать root в качестве имени пользователя для подключения к конечной точке шлюза. Это изменение не применяется к развертываниям, в которых используется проверка подлинности с помощью Active Directory. Подробные сведения см. в заметках о выпуске в разделе Учетные данные для доступа к службам через конечную точку шлюза.
https://<Ipaddress>:<Port>/gateway/default/sparkhistory
Пользовательский веб-интерфейс сервера журнала Spark выглядит следующим образом:
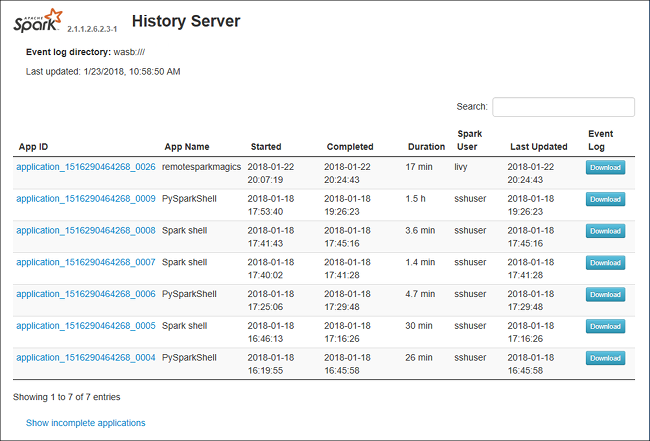
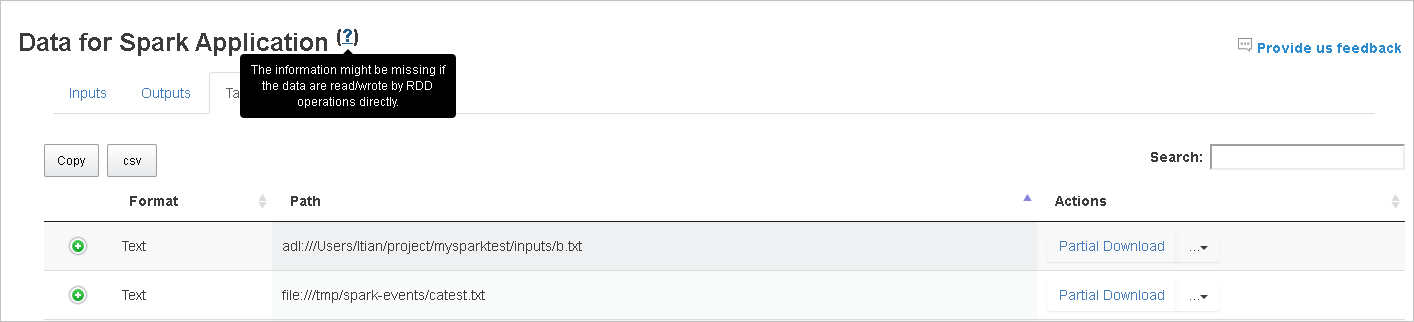
Вкладка данных на сервере журнала Spark
Выберите идентификатор задания, а затем в меню инструментов выберите пункт Данные, чтобы открыть представление данных.
Выберите вкладку Входы, Выходы или Операции с таблицей, чтобы просмотреть соответствующие сведения.
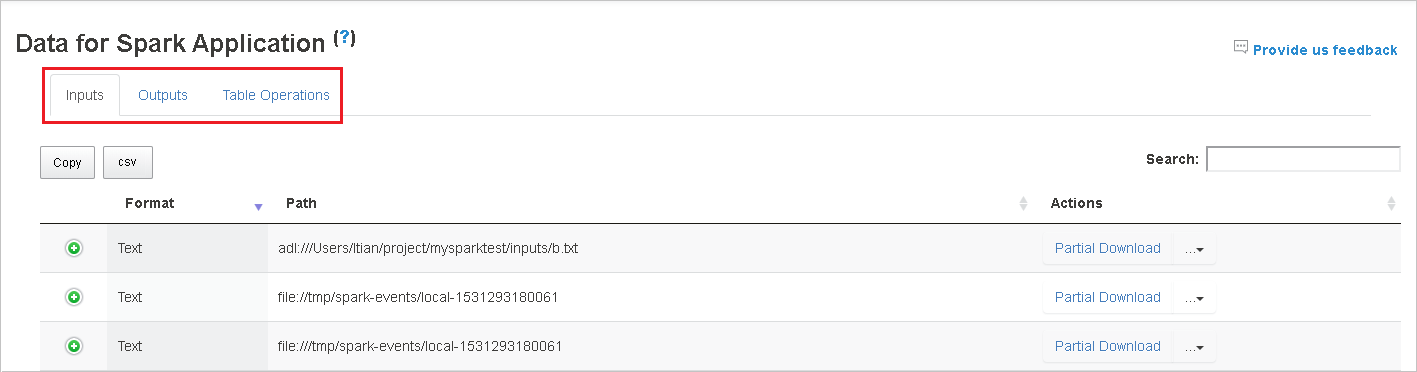
Чтобы скопировать все строки, нажмите кнопку Копировать.
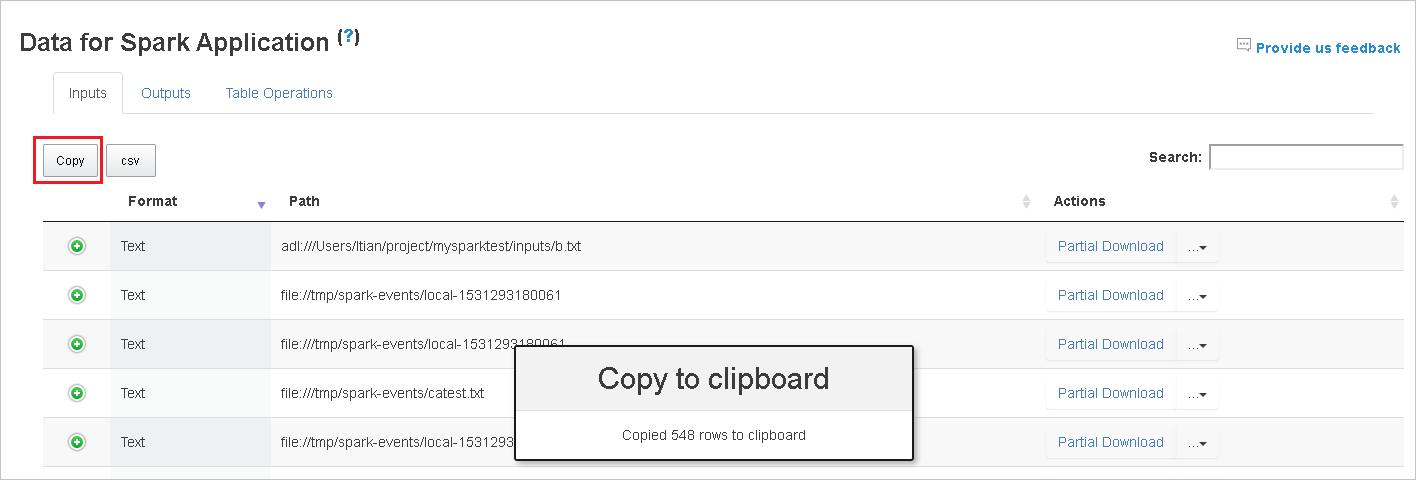
Чтобы сохранить все данные в CSV-файле, нажмите кнопку CSV.
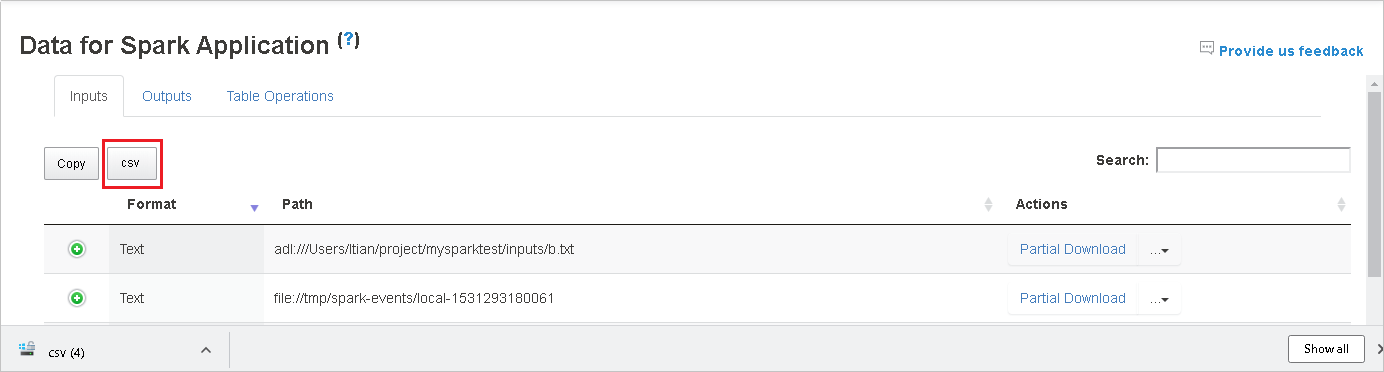
Чтобы выполнить поиск, введите ключевые слова в поле поиска. Результаты отображаются немедленно.
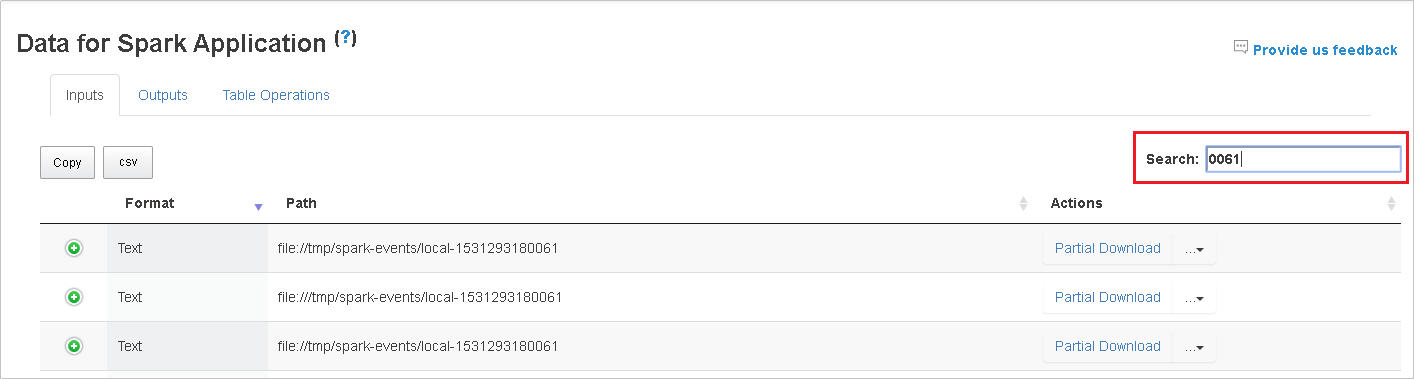
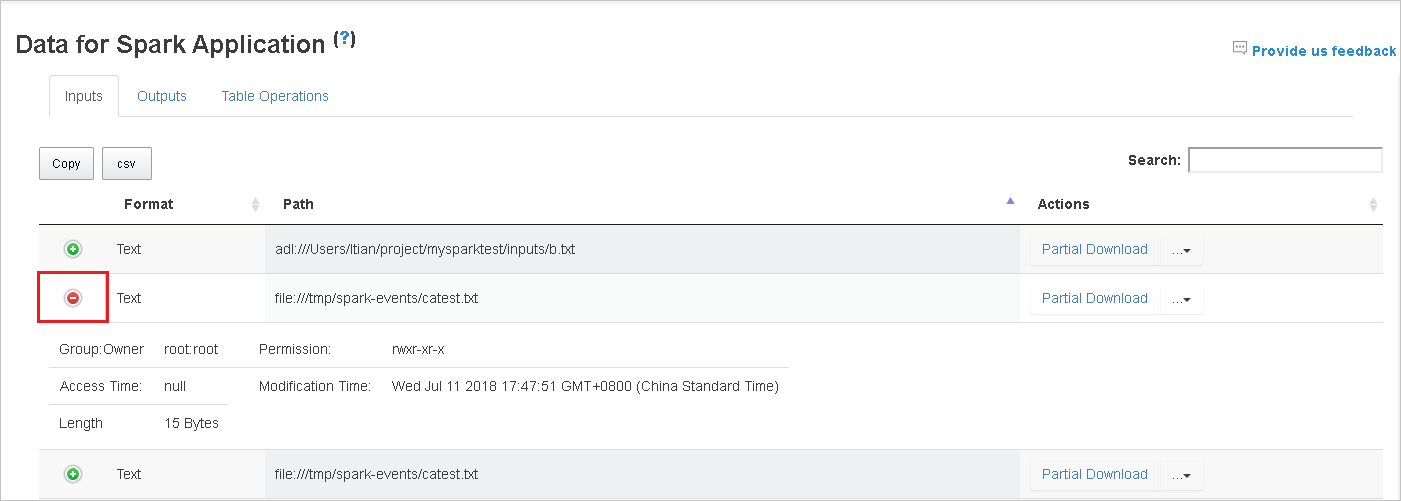
Щелкните заголовок столбца для сортировки таблицы, знак "плюс", чтобы развернуть строку и просмотреть дополнительные сведения, или знак "минус", чтобы свернуть строку.
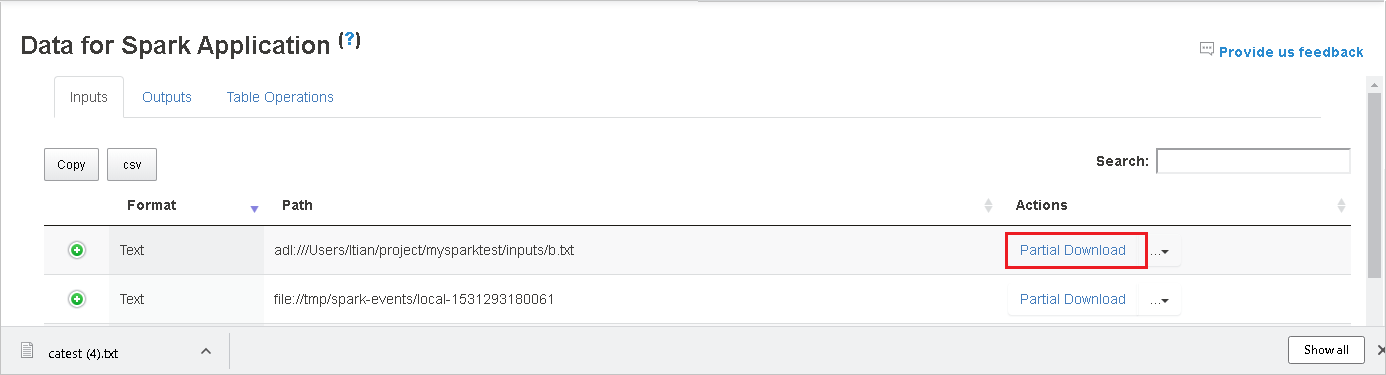
Чтобы скачать один файл, нажмите кнопку Частичное скачивание справа. Выбранный файл скачается в локальное расположение. Если файл больше не существует, откроется новая вкладка с сообщениями об ошибках.
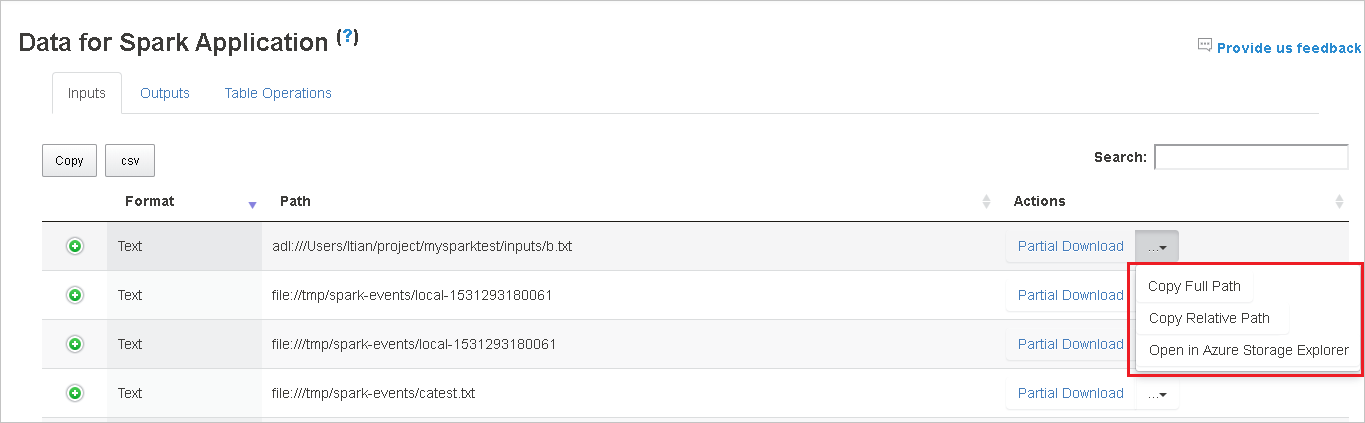
Чтобы скопировать полный или относительный путь, выберите пункт Копировать полный путь или Копировать относительный путь в меню скачивания. Для файлов Azure Data Lake Storage выбор пункта Открыть в Обозревателе службы хранилища Azure приводит к запуску Обозревателя службы хранилища Azure. После входа открывается указанная папка.
Если все строки не помещаются на одной странице, щелкайте номера под таблицей для перехода по страницам.

Наведите указатель на вопросительный знак рядом с заголовком "Данные", чтобы увидеть подсказку, или щелкните вопросительный знак, чтобы получить дополнительные сведения.
Чтобы отправить отзыв о проблемах, щелкните Отправить нам отзыв.
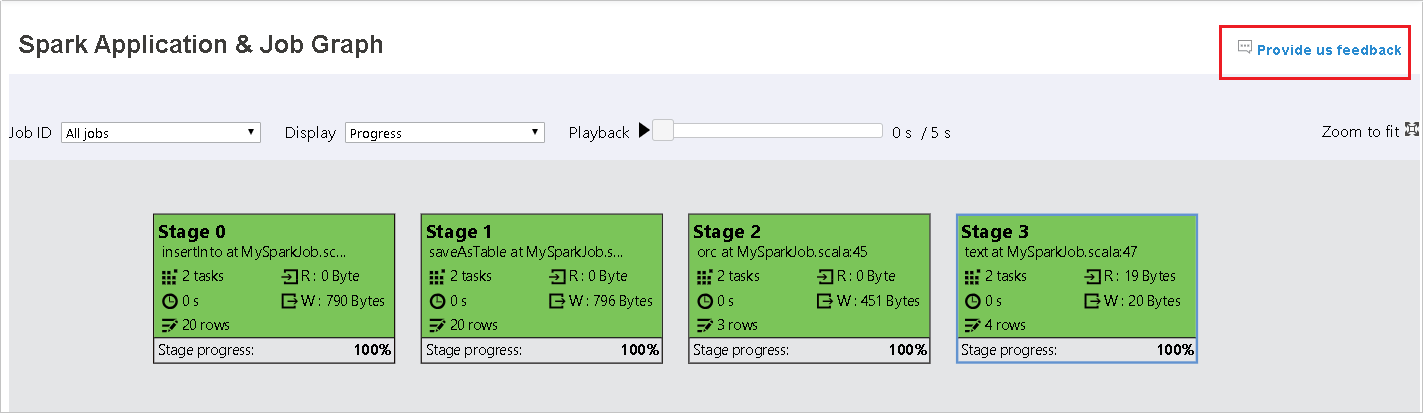
Вкладка графа на сервере журнала Spark
Выберите идентификатор задания, а затем в меню инструментов выберите пункт Граф, чтобы открыть представление графа задания.
Созданный граф задания позволяет получить общее представление о задании.
По умолчанию отображаются все задания. Представление можно отфильтровать по идентификатору задания.
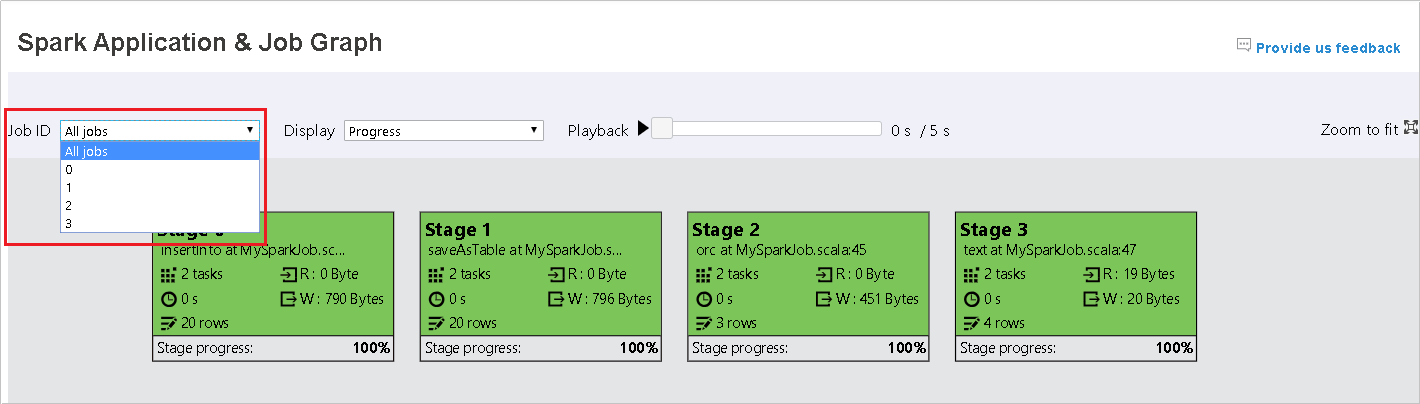
Значение по умолчанию — Ход выполнения. Пользователь может проверить поток данных, выбрав в раскрывающемся списке Отображение пункт Чтение или Запись.
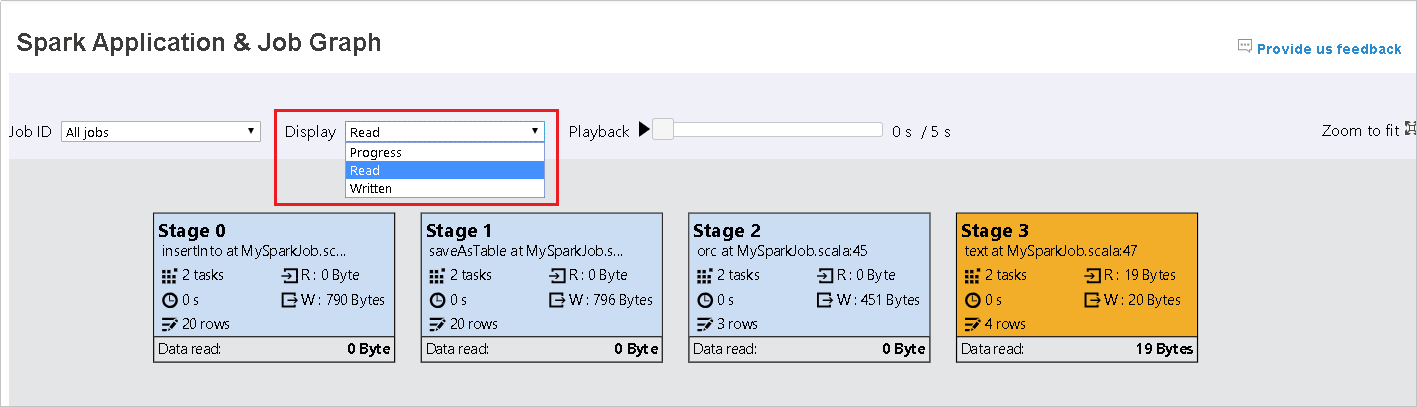
Узел графа отображается в цветах тепловой карты.

Чтобы воспроизвести задание, нажмите кнопку Воспроизведение. Воспроизведение можно остановить в любой момент, нажав кнопку "Стоп". Во время воспроизведения задача отображается в цвете, соответствующем состоянию.
- Зеленый при успешном выполнении: задание выполнено успешно.
- Оранжевый при повторе: экземпляры задач, которые не удалось выполнить, но они не влияют на результат задания. Эти задачи имеют дублирующиеся или повторные экземпляры, которые могут быть успешно выполнены позже.
- Синий при выполнении: задача выполняется.
- Белый при ожидании или пропуске: задача ожидает выполнения или пропущен этап.
- Красный при сбое: не удалось выполнить задачу.

Пропущенный этап отображается белым цветом.


Примечание.
Допускается воспроизведение каждого задания. Воспроизведение незавершенных заданий не поддерживается.
Используйте колесико мыши для увеличения или уменьшения графа задания или щелкните Вписать, чтобы масштабировать его по размеру экрана.
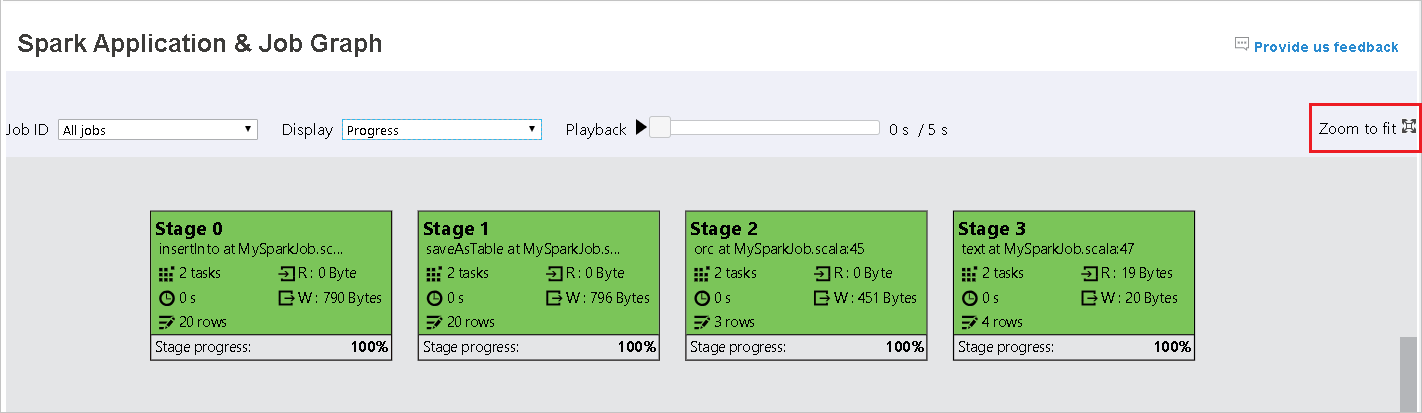
Наведите указатель мыши на узел графа, чтобы увидеть подсказку при наличии невыполненных задач, и щелкните этап, чтобы открыть страницу этапа.
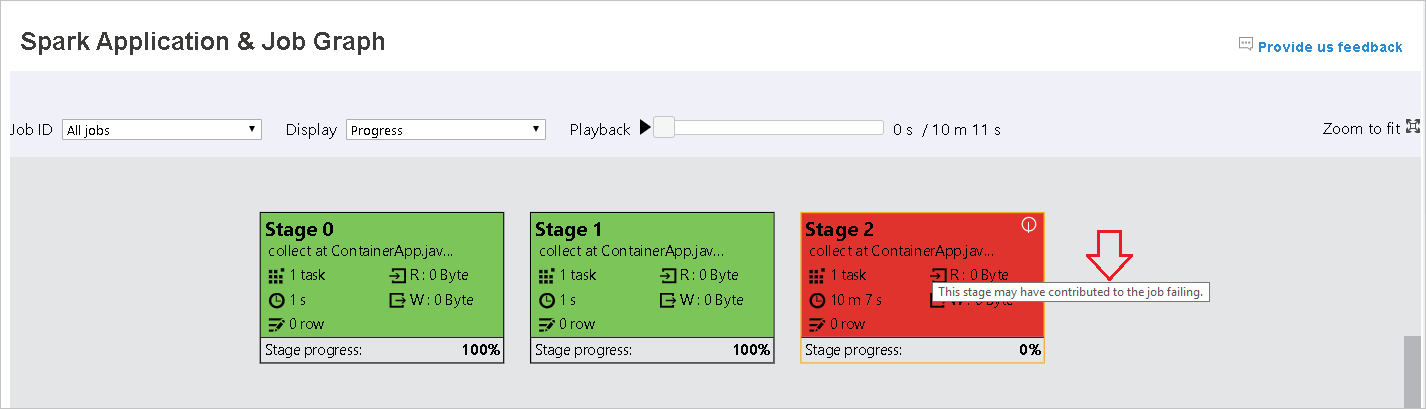
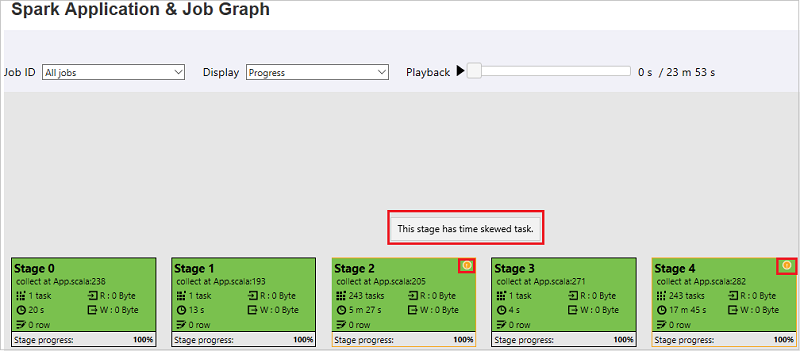
На вкладке графа задания этапы будут иметь подсказки и небольшие значки при наличии задач, которые соответствуют указанным ниже условиям.
- Неравномерное распределение данных: размер считанных данных > удвоенного среднего размера считанных данных для всех задач на этом этапе и размер считанных данных > 10 МБ.
- Неравномерное распределение времени: время выполнения > удвоенного среднего времени выполнения всех задач на этом этапе и время выполнения > 2 мин.
В узле графа задания отображаются следующие сведения о каждом этапе:
- Идентификатор.
- имя или описание;
- общее количество задач;
- чтение данных: сумма размеров входных данных и смешанного чтения;
- запись данных: сумма размеров выходных данных и смешанной записи;
- время выполнения: время от начала первой попытки до завершения последней попытки;
- число строк: сумма входных записей, выходных записей, записей смешанного чтения и записей смешанной записи;
- ход выполнения.
Примечание.
По умолчанию в узле графа задания отображаются сведения о последней попытке на каждом этапе (за исключением времени выполнения этапа), но во время воспроизведения отображаются сведения о каждой попытке.
Примечание.
Для размера считанных и записанных данных используются соотношения 1 МБ = 1000 КБ = 1000 * 1000 байтов.
Чтобы отправить отзыв о проблемах, щелкните Отправить нам отзыв.
Вкладка диагностики на сервере журнала Spark
Выберите идентификатор задания, а затем в меню инструментов выберите пункт Диагностика, чтобы открыть представление диагностики задания. На вкладке диагностики доступны вкладки Неравномерное распределение данных, Неравномерное распределение времени и Анализ использования исполнителя.
Выберите вкладку Неравномерное распределение данных, Неравномерное распределение времени или Анализ использования исполнителя, чтобы просмотреть соответствующие сведения.
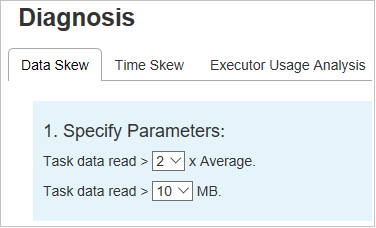
Неравномерное распределение данных
Выберите вкладку Неравномерное распределение данных. Отобразятся соответствующие задачи с неравномерным распределением на основе указанных параметров.
Укажите параметры — в первом разделе отображаются параметры, которые служат для обнаружения неравномерного распределения данных. Встроенное правило: чтение данных задачи превышает три раза среднего числа данных задачи, а данные задачи считываются более 10 МБ. Если вы хотите определить собственное правило для задач с неравномерным распределением, то можете выбрать собственные параметры. Разделы Этап с неравномерным распределением и Диаграмма неравномерного распределения обновятся соответствующим образом.
Этап с неравномерным распределением — во втором разделе отображаются этапы, имеющие задачи с неравномерным распределением, которые отвечают указанным выше условиям. Если на этапе более одной задачи с неравномерным распределением, в таблице этапа с неравномерным распределением отображается только одна задача с наибольшим неравномерным распределением (например, наибольшим размером неравномерно распределенных данных).
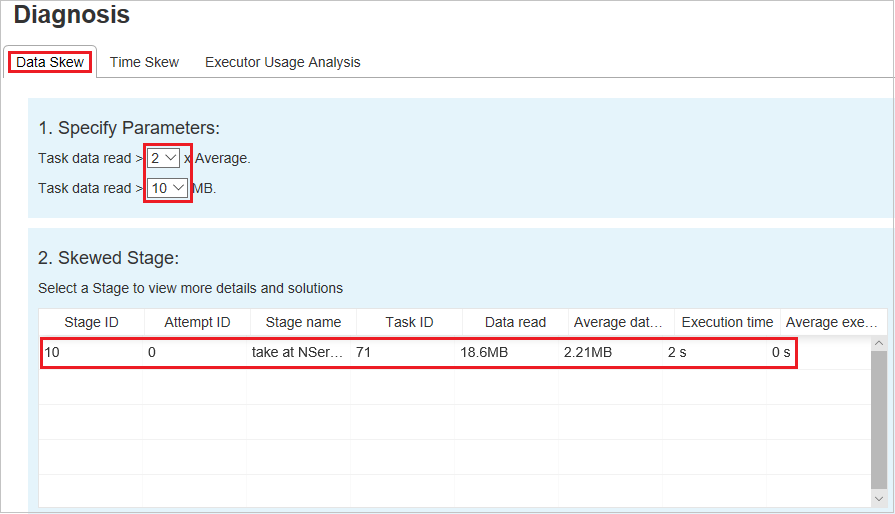
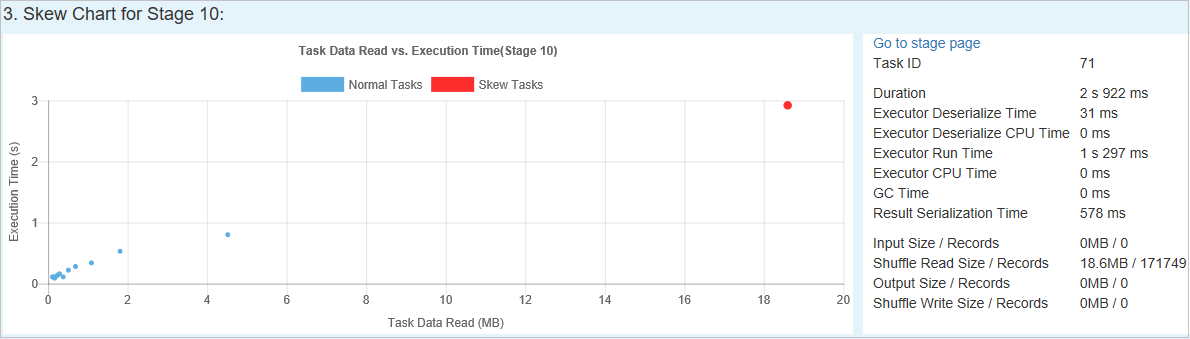
Диаграмма неравномерного распределения — когда в таблице этапа с неравномерным распределением выбрана строка, на диаграмме неравномерного распределения отображаются дополнительные сведения о распределении задач на основе размера считанных данных и времени выполнения. Задачи с неравномерным распределением отмечены красным цветом, а нормальные задачи — синим. Для повышения производительности на диаграмме отображаются не более 100 образцов задач. Подробные сведения о задаче отображаются на правой нижней панели.
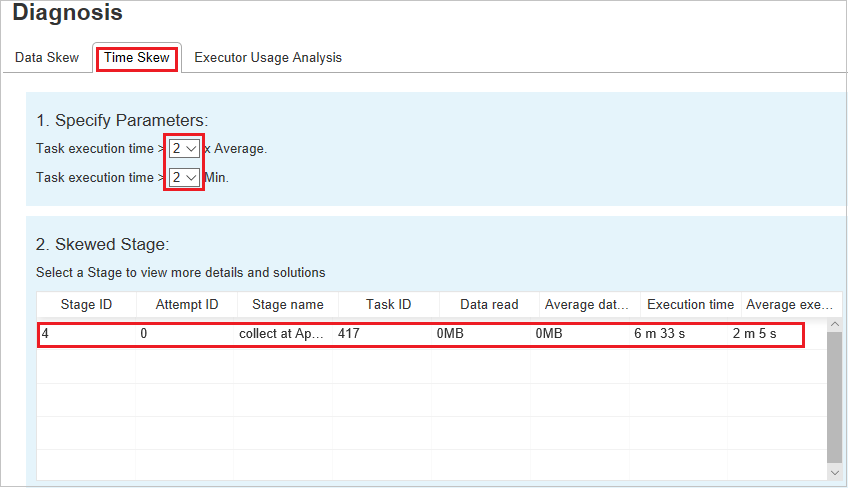
Неравномерное распределение времени
На вкладке Неравномерное распределение времени отображаются задачи с неравномерным распределением времени выполнения.
Укажите параметры — в первом разделе отображаются параметры, которые служат для обнаружения неравномерного распределения времени. По умолчанию для обнаружения неравномерного распределения времени используется следующий критерий: время выполнения задачи больше среднего времени выполнения, умноженного на три, и превышает 30 секунд. Параметры можно изменить в соответствии с вашими потребностями. В разделах Этап с неравномерным распределением и Диаграмма неравномерного распределения отображаются соответствующие сведения об этапах и задачах, так же как на вкладке Неравномерное распределение данных, описанной выше.
Щелкните Неравномерное распределение времени. В разделе Этап с неравномерным распределением отобразятся отфильтрованные результаты в соответствии с параметрами, заданными в разделе Укажите параметры. Щелкните один элемент в разделе Этап с неравномерным распределением. Соответствующая диаграмма будет построена в разделе 3, а сведения о задаче отобразятся на правой нижней панели.
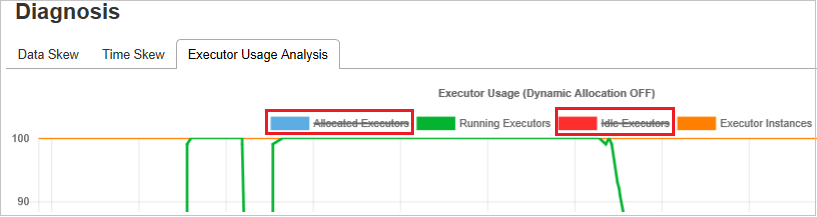
Анализ использования исполнителя
На графе использования исполнителя визуализируются фактическое выделение и состояние выполнения задания Spark.
Щелкните Анализ использования исполнителя. Будут построены четыре кривые, связанные с использованием исполнителя. К ним относятся Выделенные исполнители, Выполняющиеся исполнители, Неактивные исполнители и Максимальное число экземпляров исполнителя. Каждое событие "Исполнитель добавлен" или "Исполнитель удален" приводит к увеличению или уменьшению количества выделенных исполнителей. Дополнительные возможности сравнения доступны на временной шкале событий на вкладке "Задания".
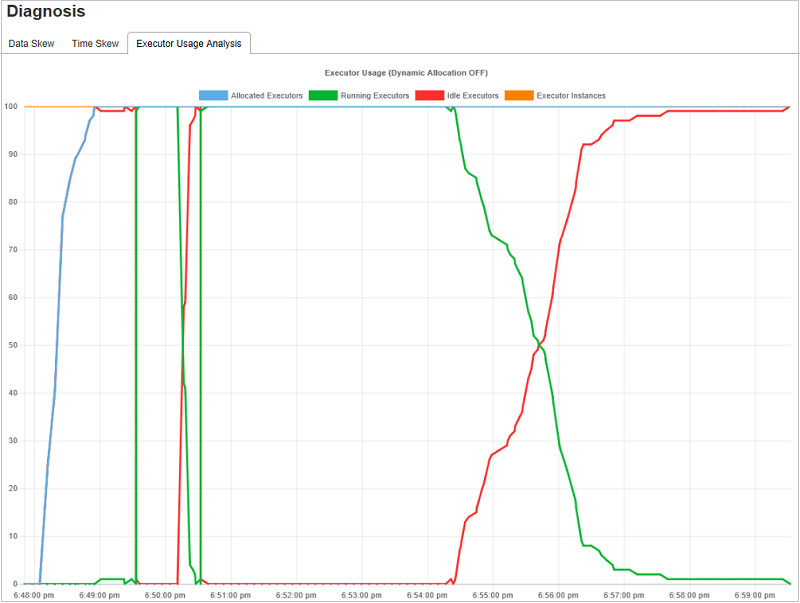
Щелкните значок цвета, чтобы выбрать соответствующее содержимое на всех графиках или отменить его выбор.
Журналы Spark и Yarn
Помимо сервера журнала Spark, журналы для Spark и Yarn соответственно можно найти в следующих местах.
- Журналы событий Spark: hdfs:///system/spark-events
- Журналы Yarn: hdfs:///tmp/logs/root/logs-tfile
Примечание. Оба этих журнала имеют срок хранения по умолчанию 7 дней. Если вы хотите изменить период хранения, см. страницу Настройка Apache Spark и Apache Hadoop. Расположение изменить нельзя.
Известные проблемы
Сервер журнала Spark имеет указанные ниже известные проблемы.
В настоящее время он работает только с кластером Spark 3.1 (с CU13 и более поздних версий) и Spark 2.4 (с CU12 и более ранних версий).
Входные и выходные данные RDD не отображаются на вкладке данных.
Следующие шаги
- Начало работы с кластерами больших данных SQL Server
- Настройка параметров Spark
- Настройка параметров Spark