Отправка заданий Spark в SQL Server Кластеры больших данных в Azure Data Studio
Область применения: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Внимание
Поддержка надстройки "Кластеры больших данных" Microsoft SQL Server 2019 будет прекращена. Мы прекратим поддержку Кластеров больших данных SQL Server 2019 28 февраля 2025 г. Все существующие пользователи SQL Server 2019 с Software Assurance будут полностью поддерживаться на платформе, и программное обеспечение будет продолжать поддерживаться с помощью накопительных обновлений SQL Server до этого времени. Дополнительные сведения см. в записи блога объявлений и в статье о параметрах больших данных на платформе Microsoft SQL Server.
Одним из основных сценариев для кластеров больших данных является возможность отправки заданий Spark для SQL Server. Функция отправки заданий Spark позволяет отправлять локальные файлы JAR или PY со ссылками на кластер больших данных SQL Server 2019. Она также позволяет выполнять файлы JAR или PY, которые уже находятся в файловой системе HDFS.
Необходимые компоненты
Средства для работы с большими данными SQL Server 2019
- Azure Data Studio
- Расширение SQL Server 2019
- kubectl
Подключите Azure Data Studio к шлюзу HDFS/Spark кластера больших данных.
Открытие диалогового окна отправки заданий Spark
Диалоговое окно отправки заданий Spark можно открыть несколькими способами. К ним относятся панель мониторинга, контекстное меню в обозревателе объектов и палитра команд.
Чтобы открыть диалоговое окно отправки заданий Spark, щелкните Создать задание Spark на панели мониторинга.

Либо щелкните правой кнопкой мыши кластер в обозревателе объектов и выберите пункт Отправить задание Spark в контекстном меню.
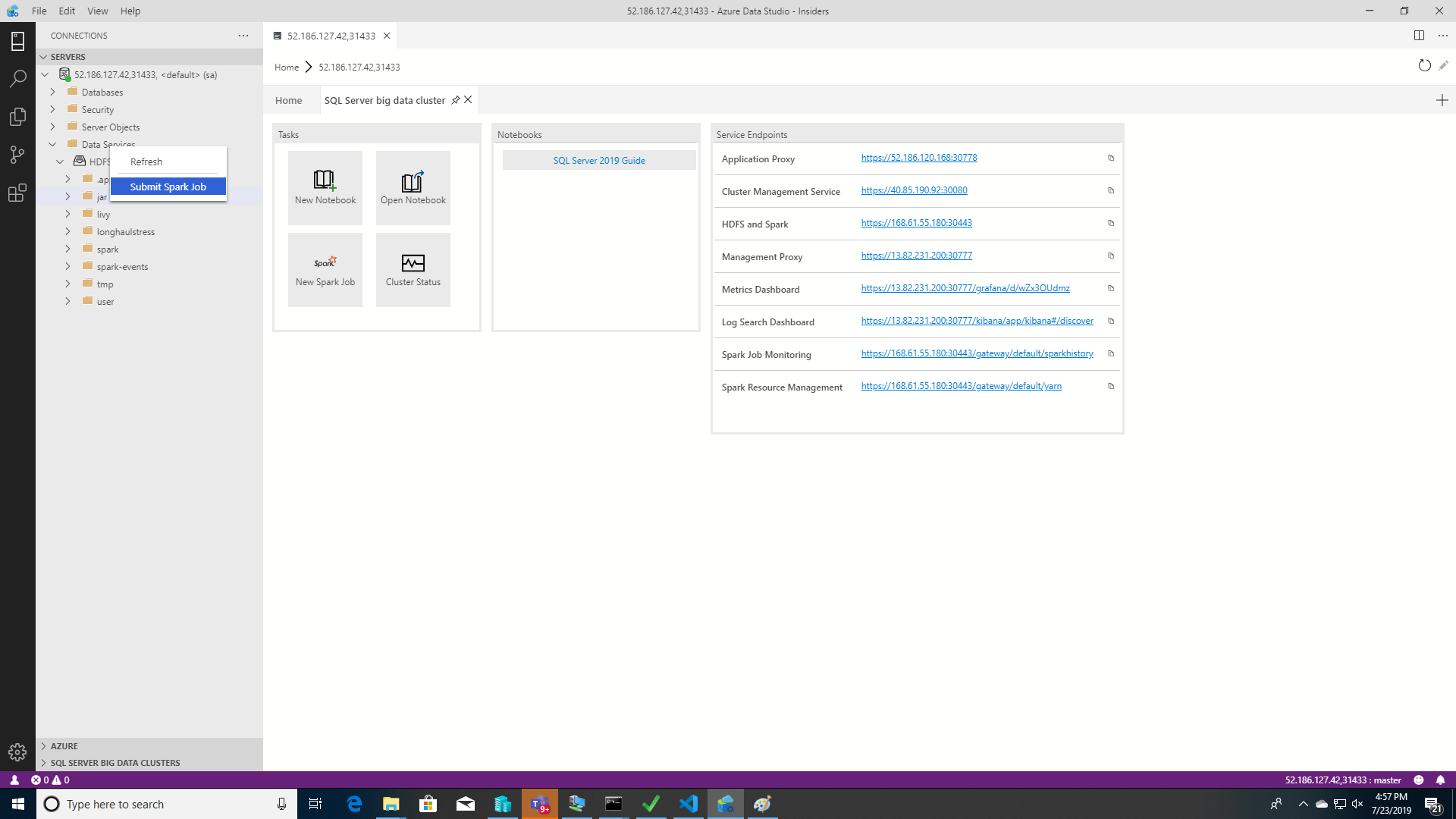
Чтобы открыть диалоговое окно отправки заданий Spark с предварительно заполненными полями JAR/PY, щелкните правой кнопкой мыши файл JAR/PY в обозревателе объектов и выберите пункт Отправить задание Spark в контекстном меню.
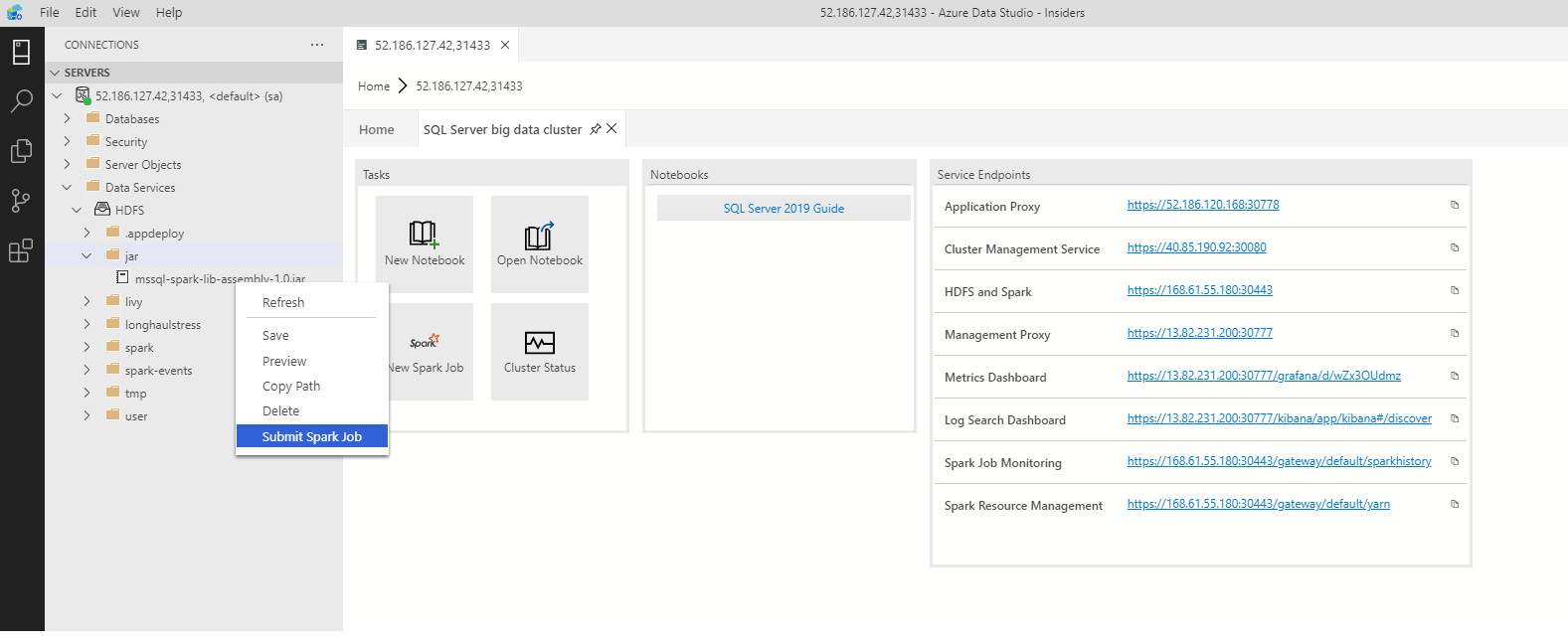
Используйте элемент Отправить задание Spark из палитры команд, нажав клавиши CTRL+SHIFT+P (в Windows) и CMD+SHIFT+P (в Mac).

Отправка задания Spark
Диалоговое окно отправки заданий Spark отображается в указанном ниже виде. Заполните имя задания, путь к файлу JAR/PY, основной класс и другие поля. Источником файла JAR/PY может быть локальная файловая система или HDFS. Если задание Spark содержит ссылки на файлы JAR, PY или другие, перейдите на вкладку Дополнительно и введите соответствующие пути к файлам. Нажмите кнопку Отправить, чтобы отправить задание Spark.
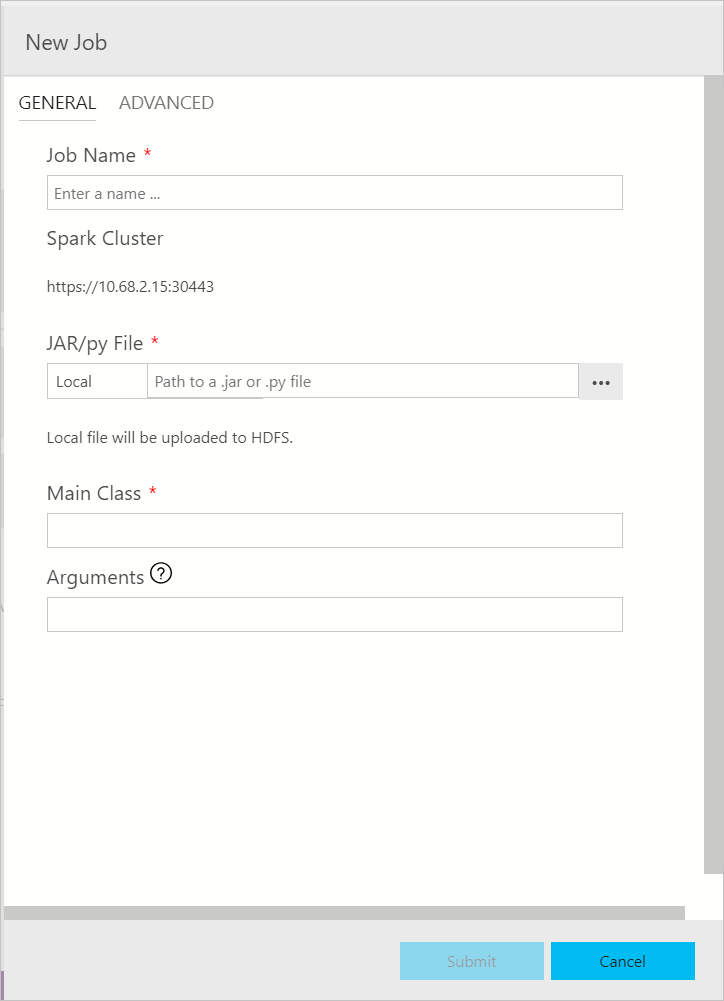
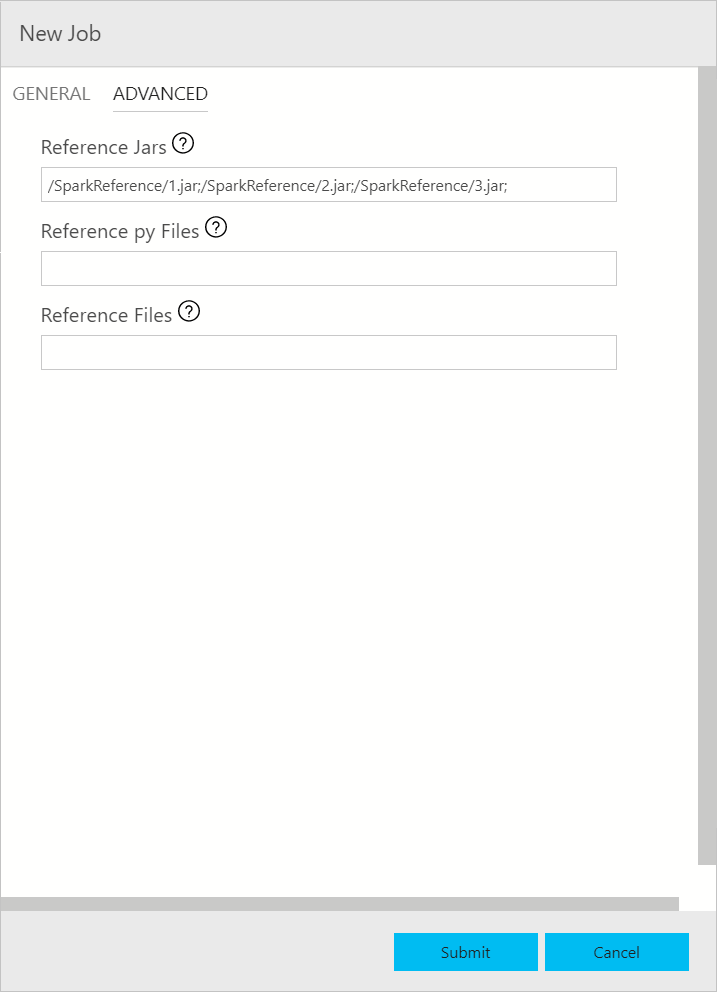
Мониторинг отправки задания Spark
После отправки задания Spark сведения о состоянии его отправки и выполнения отображаются в журнале задач слева. Сведения о ходе выполнения и журналах также отображаются в окне Вывод внизу.
По мере выполнения задания Spark панель Журнал задач и окно Вывод обновляются.
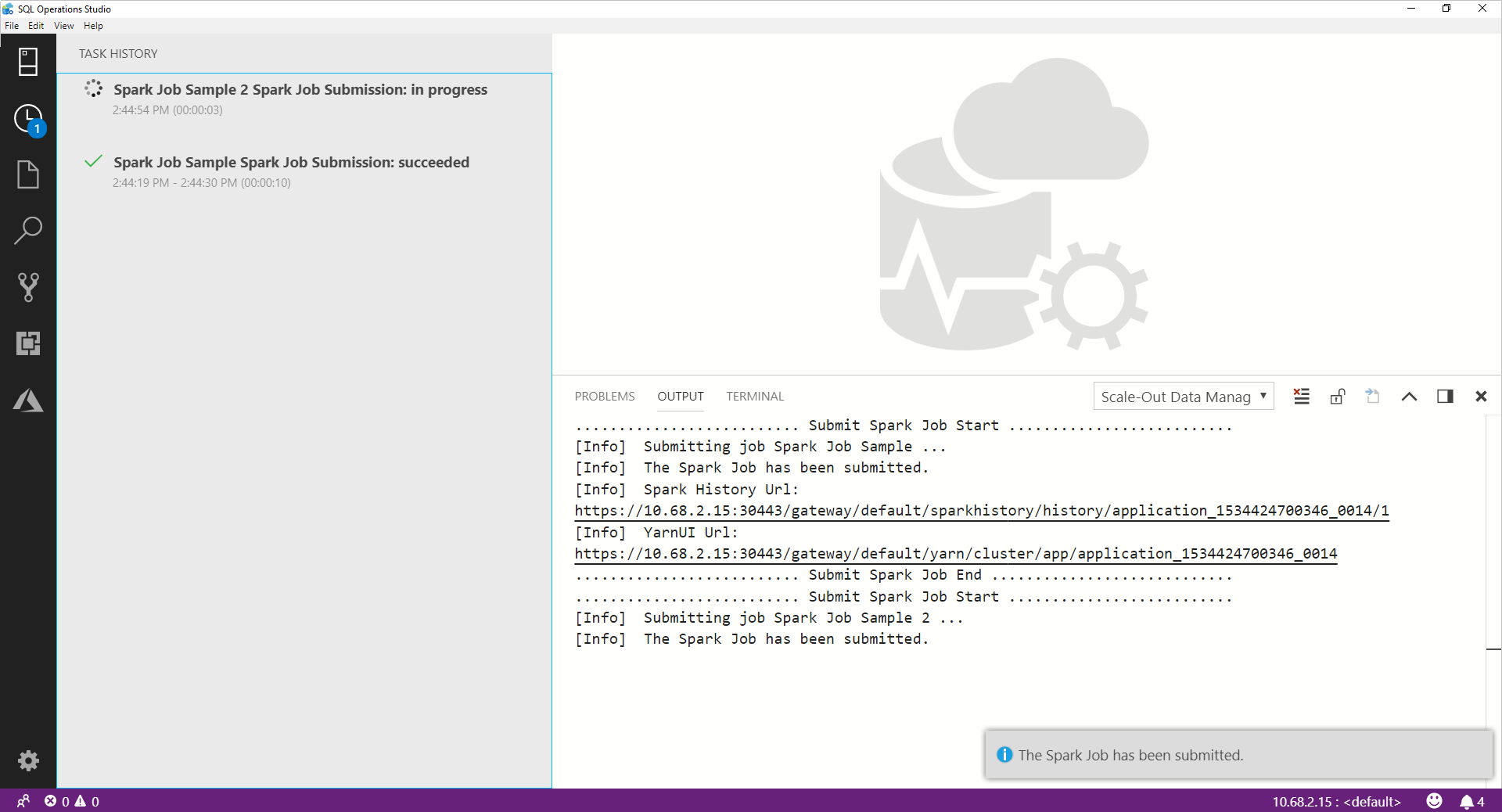
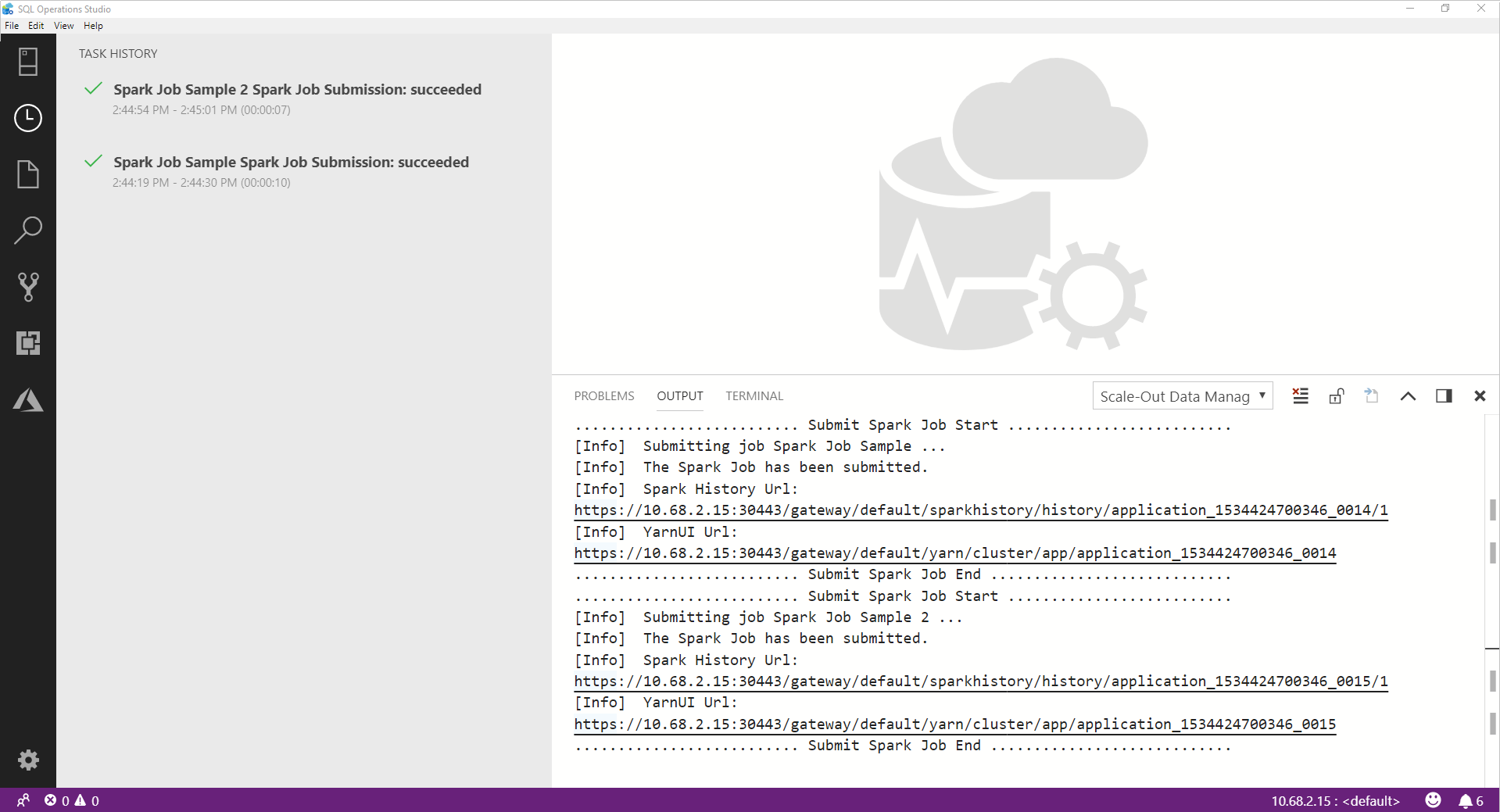
После успешного завершения задания Spark в окне Вывод отображаются ссылки пользовательского интерфейса Spark и Yarn. Перейдите по ссылкам для получения дополнительных сведений.
Следующие шаги
Дополнительные сведения о кластере больших данных SQL Server и связанных сценариях см. в статье "Знакомство с SQL Server Кластеры больших данных".