Устранение неполадок с записной книжкой pyspark
Важно!
Поддержка надстройки "Кластеры больших данных" Microsoft SQL Server 2019 будет прекращена. Мы прекратим поддержку Кластеров больших данных SQL Server 2019 28 февраля 2025 г. Все существующие пользователи SQL Server 2019 с Software Assurance будут полностью поддерживаться на платформе, а программное обеспечение будет по-прежнему поддерживаться с помощью SQL Server накопительных обновлений до этого времени. Дополнительные сведения см. в записи блога объявлений и в статье о параметрах больших данных на платформе Microsoft SQL Server.
В этой статье показано, как устранить неполадки с записной книжкой pyspark.
Архитектура задания PySpark в Azure Data Studio
Azure Data Studio взаимодействует с конечной точкой livy в Кластерах больших данных SQL Server.
Конечная точка livy выдает команды spark-submit в кластере больших данных. Каждая команда spark-submit имеет параметр, указывающий YARN в качестве диспетчера кластерных ресурсов.
Чтобы эффективно устранять неполадки в сеансе PySpark, вы будете собирать и просматривать журналы в каждом слое: Livy, YARN и Spark.
Для выполнения действий по устранению неполадок необходимо следующее.
- Установленная программа командной строки Azure Data CLI (
azdata) с конфигурацией для вашего кластера. - Знакомство с выполнением команд Linux и навыки устранения неполадок с помощью журналов.
Действия по устранению неполадок
Проверьте стек и сообщения об ошибках в
pyspark.Извлеките идентификатор приложения из первой ячейки записной книжки. Используйте этот идентификатор приложения, чтобы изучить журналы
livy, YARN и Spark.SparkContextиспользует этот идентификатор приложения YARN.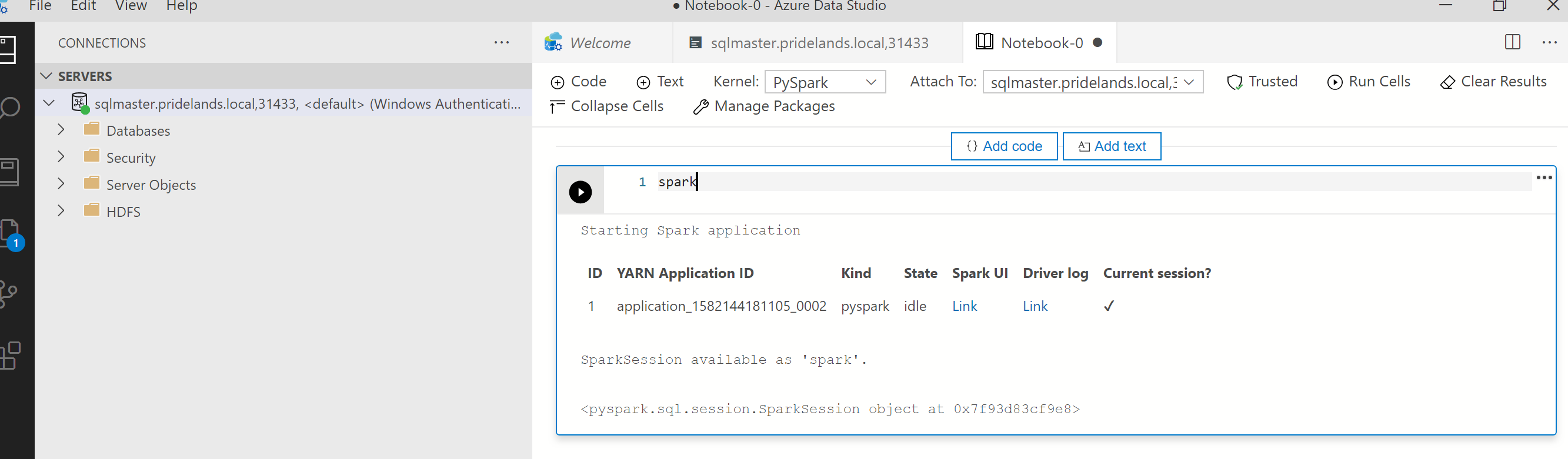
Получите журналы.
Изучите их с помощью команды
azdata bdc debug copy-logs.В следующем примере выполняется подключение конечной точки кластера больших данных для копирования журналов. Перед выполнением обновите следующие значения в примере.
-
<ip_address>: конечная точка кластера больших данных. -
<username>: имя пользователя кластера больших данных. -
<namespace>: пространство имен Kubernetes для кластера. -
<folder_to_copy_logs>: путь к локальной папке, в которую нужно скопировать журналы.
azdata login --auth basic --username <username> --endpoint https://<ip_address>:30080 azdata bdc debug copy-logs -n <namespace> -d <folder_to_copy_logs>Пример выходных данных
<user>@<server>:~$ azdata bdc debug copy-logs -n <namespace> -d copy_logs Collecting the logs for cluster '<namespace>'. Collecting logs for containers... Creating an archive from logs-tmp/<namespace>. Log files are archived in /home/<user>/copy_logs/debuglogs-<namespace>-YYYYMMDD-HHMMSS.tar.gz. Creating an archive from logs-tmp/dumps. Log files are archived in /home/<user>/copy_logs/debuglogs-<namespace>-YYYYMMDD-HHMMSS-dumps.tar.gz. Collecting the logs for cluster 'kube-system'. Collecting logs for containers... Creating an archive from logs-tmp/kube-system. Log files are archived in /home/<user>/copy_logs/debuglogs-kube-system-YYYYMMDD-HHMMSS.tar.gz. Creating an archive from logs-tmp/dumps. Log files are archived in /home/<user>/copy_logs/debuglogs-kube-system-YYYYMMDD-HHMMSS-dumps.tar.gz.-
Просмотрите журналы Livy. Журналы Livy находятся в папке
<namespace>\sparkhead-0\hadoop-livy-sparkhistory\supervisor\log.- Найдите идентификатор приложения YARN из первой ячейки записной книжки pyspark.
- Найдите состояние
ERR.
Пример журнала Livy с состоянием
YARN ACCEPTEDLivy отправляет приложение Yarn.HH:MM:SS INFO utils.LineBufferedStream: YYY-MM-DD HH:MM:SS INFO impl.YarnClientImpl: Submitted application application_<application_id> YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: YYY-MM-DD HH:MM:SS INFO yarn.Client: Application report for application_<application_id> (state: ACCEPTED) YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: YYY-MM-DD HH:MM:SS INFO yarn.Client: YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: client token: N/A YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: diagnostics: N/A YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: ApplicationMaster host: N/A YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: ApplicationMaster RPC port: -1 YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: queue: default YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: start time: ############ YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: final status: UNDEFINED YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: tracking URL: https://sparkhead-1.fnbm.corp:8090/proxy/application_<application_id>/ YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: user: <account>Изучите пользовательский интерфейс YARN
Получите URL-адрес конечной точки YARN из панели мониторинга кластера больших данных Azure Data Studio или запустите
azdata bdc endpoint list –o table.Пример:
azdata bdc endpoint list -o tableРезультаты
Description Endpoint Name Protocol ------------------------------------------------------ ---------------------------------------------------------------- -------------------------- ---------- Gateway to access HDFS files, Spark https://knox.<namespace-value>.local:30443 gateway https Spark Jobs Management and Monitoring Dashboard https://knox.<namespace-value>.local:30443/gateway/default/sparkhistory spark-history https Spark Diagnostics and Monitoring Dashboard https://knox.<namespace-value>.local:30443/gateway/default/yarn yarn-ui https Application Proxy https://proxy.<namespace-value>.local:30778 app-proxy https Management Proxy https://bdcmon.<namespace-value>.local:30777 mgmtproxy https Log Search Dashboard https://bdcmon.<namespace-value>.local:30777/kibana logsui https Metrics Dashboard https://bdcmon.<namespace-value>.local:30777/grafana metricsui https Cluster Management Service https://bdcctl.<namespace-value>.local:30080 controller https SQL Server Master Instance Front-End sqlmaster.<namespace-value>.local,31433 sql-server-master tds SQL Server Master Readable Secondary Replicas sqlsecondary.<namespace-value>.local,31436 sql-server-master-readonly tds HDFS File System Proxy https://knox.<namespace-value>.local:30443/gateway/default/webhdfs/v1 webhdfs https Proxy for running Spark statements, jobs, applications https://knox.<namespace-value>.local:30443/gateway/default/livy/v1 livy httpsПроверьте идентификатор приложения и отдельные журналы application_master и журналы контейнеров.
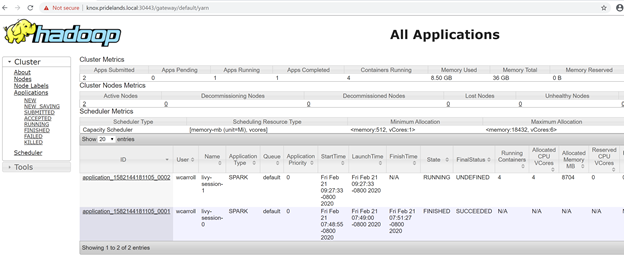
Просмотрите журналы приложения YARN.
Получите журнал приложения. Используйте
kubectlдля подключения к модулю podsparkhead-0, например:kubectl exec -it sparkhead-0 -- /bin/bashЗатем выполните следующую команду в этой оболочке, указав правильное значение
application_id.yarn logs -applicationId application_<application_id>Поищите ошибки или стеки.
Пример ошибки разрешений для HDFS. В стеке Java найдите элемент
Caused by:.YYYY-MM-DD HH:MM:SS,MMM ERROR spark.SparkContext: Error initializing SparkContext. org.apache.hadoop.security.AccessControlException: Permission denied: user=<account>, access=WRITE, inode="/system/spark-events":sph:<bdc-admin>:drwxr-xr-x at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:399) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:255) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:193) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1852) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1836) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkAncestorAccess(FSDirectory.java:1795) at org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp.resolvePathForStartFile(FSDirWriteFileOp.java:324) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileInt(FSNamesystem.java:2504) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileChecked(FSNamesystem.java:2448) Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=<account>, access=WRITE, inode="/system/spark-events":sph:<bdc-admin>:drwxr-xr-xИзучите пользовательский интерфейс SPARK.
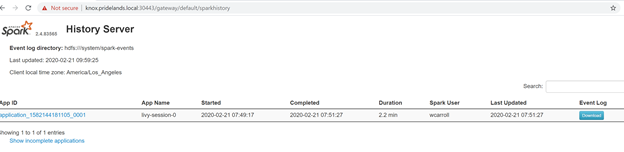
Детализируйте задачи этапов в поисках ошибок.
Дальнейшие действия
Устранение неполадок при интеграции Кластеров больших данных SQL Server с Active Directory