Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Применимо к:![]() SQL Server 2017 (14.x) и более поздних версий
SQL Server 2017 (14.x) и более поздних версий
В этой статье описывается расширение Python для выполнения внешних скриптов Python с помощью Службы машинного обучения SQL Server. Расширение добавляет следующее.
- Среда выполнения Python
- Распространение Anaconda с помощью среды выполнения и интерпретатора Python 3.5
- Стандартные библиотеки и средства
- Пакеты Microsoft Python:
- revoscalepy для аналитики в большом масштабе.
- microsoftml для алгоритмов машинного обучения.
Установка среды выполнения и интерпретатора Python 3.5 гарантирует почти полную совместимость со стандартными решениями Python. Python и SQL Server выполняются в отдельных процессах, чтобы гарантировать, что операции с базой данных не будут скомпрометированы.
Компоненты Python
SQL Server содержит как пакеты с открытым исходным кодом, так и проприетарные пакеты. Среда выполнения Python, которая устанавливается программой установки — Anaconda 4.2 с Python 3.5. Среда выполнения Python устанавливается независимо от инструментов SQL и выполняется вне процессов основного движка в платформе расширяемости. При установке служб машинного обучения с Python вы должны принять условия открытой лицензии GNU.
SQL Server не изменяет базовые исполняемые файлы Python, однако необходимо использовать именно ту версию Python, которая была установлена программой установки, так как на базе этой версии устанавливаются и тестируются проприетарные пакеты. Список пакетов, поддерживаемых дистрибутивом Anaconda, см. на сайте аналитики Continuum: список пакетов Anaconda.
Дистрибутив Anaconda, связанный с конкретным экземпляром ядра СУБД, можно найти в папке, связанной с этим экземпляром. Например, если вы установили ядро СУБД SQL Server 2017 со службами машинного обучения и Python на экземпляре по умолчанию, обратитесь к папке C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\PYTHON_SERVICES.
Пакеты Python, добавленные корпорацией Майкрософт для параллельных и распределенных рабочих нагрузок, включают следующие библиотеки.
| Библиотека | Описание |
|---|---|
| revoscalepy | Поддерживает объекты источников данных и просмотр, обработку, преобразование и визуализацию данных. Поддерживает создание удаленных контекстов вычислений, а также различные масштабируемые модели машинного обучения, такие как rxLinMod. Дополнительные сведения см. в разделе Модуль revoscalepy в SQL Server. |
| microsoftml | Содержит алгоритмы машинного обучения, оптимизированные для достижения высокой скорости и точности, а также встроенные преобразования для работы с текстом и изображениями. Дополнительные сведения см. в разделе Модуль microsoftml в SQL Server. |
Модули microsoftml и revoscalepy тесно связаны. Источники данных, используемые в microsoftml, определяются как объекты revoscalepy. Ограничения контекста вычислений в revoscalepy распространяются на microsoftml. То есть для локальных операций доступны все функции, но для переключения на удаленный контекст вычислений требуется RxInSqlServer.
Использование Python в SQL Server
Вы импортируете модуль revoscalepy в код Python, а затем вызываете функции этого модуля в коде точно так же, как и любые другие функции Python.
К поддерживаемым источникам данных относятся базы данных ODBC, SQL Server и формат файлов XDF для обмена данными с другими источниками или с решениями R. Входные данные для Python должны иметь табличный формат. Все результаты Python должны возвращаться в виде pandas DataFrame.
Поддерживаемые контексты вычислений включают локальный и удаленный контексты вычислений SQL Server. Удаленный контекст вычислений относится к выполнению кода, которое начинается на одном компьютере, например на рабочей станции, но затем выполнение сценария переключается на удаленный компьютер. Для переключения контекста вычислений необходимо, чтобы в обеих системах использовалась одна и та же библиотека revoscalepy.
Локальный контекст вычислений, как и можно было бы ожидать, включает выполнение кода Python на том же сервере, на котором находится экземпляр ядра СУБД, причем код располагается в T-SQL или включается в хранимую процедуру. Также можно запустить код из локальной интегрированной среды разработки Python и сделать так, что сценарий будет выполнен на компьютере SQL Server, задав удаленный контекст вычислений.
Архитектура выполнения
На следующих схемах показано взаимодействие компонентов SQL Server со средой выполнения Python в каждом из поддерживаемых сценариев: выполнение сценария в базе данных и удаленное выполнение из терминала Python с использованием контекста вычислений SQL Server.
Сценарии Python, выполняемые в базе данных
При запуске Python "внутри" SQL Server необходимо инкапсулировать сценарий Python в специальную хранимую процедуру sp_execute_external_script.
После внедрения сценария в хранимую процедуру любое приложение, которое может вызвать хранимую процедуру, может инициировать выполнение кода Python. После этого SQL Server управляет выполнением кода, как показано на следующей схеме.
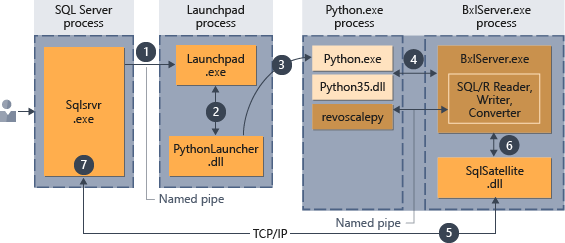
- Запрос к среде выполнения Python задается с помощью параметра
@language='Python', передаваемого хранимой процедуре. SQL Server отправляет этот запрос в службу панели запуска. В Linux SQL использует службу панели запуска для взаимодействия с отдельным процессом панели запуска для каждого пользователя. Дополнительные сведения см. на схеме архитектуры расширяемости. - Служба панели запуска запускает соответствующее средство запуска, в данном случае, PythonLauncher.
- PythonLauncher запускает внешний процесс Python35.
- BxlServer взаимодействует со средой выполнения Python для управления обменом данными и сохранения результатов работы.
- SQL Satellite управляет обменом сообщениями по связанным задачам и процессам с SQL Server.
- BxlServer использует SQL Satellite для сообщения о состоянии и результатах в SQL Server.
- SQL Server получает результаты и закрывает связанные задачи и процессы.
Скрипты Python, выполняемые из удаленного клиента
Скрипты Python можно запускать с удаленного компьютера, например ноутбука, и выполнять их в контексте компьютера SQL Server, если выполнены следующие условия:
- Вы проектируете сценарии соответствующим образом
- На удаленном компьютере установлены библиотеки расширяемости, используемые службами машинного обучения. Для использования удаленных контекстов вычислений необходим пакет revoscalepy.
На следующем рисунке показана общая схема рабочего процесса, в которой сценарии отправляются с удаленного компьютера.
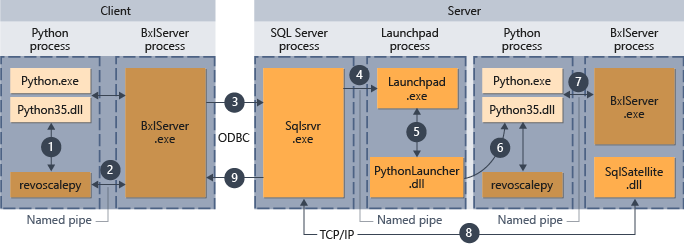
- Для функций, поддерживаемых в revoscalepy, среда выполнения Python вызывает связующую функцию, которая, в свою очередь, вызывает BxlServer.
- BxlServer входит в состав служб машинного обучения (в базе данных) и выполняется в отдельном процессе в среде выполнения Python.
- BxlServer определяет целевой объект подключения и инициирует подключение с использованием ODBC, передавая учетные данные в строке подключения в сценарии Python.
- BxlServer устанавливает подключение к экземпляру SQL Server.
- При вызове среды выполнения внешнего сценария вызывается служба панели запуска, которая, в свою очередь, запускает подходящее средство запуска, в данном случае PythonLauncher.dll. После этого код Python обрабатывается в рабочем процессе по аналогии с вызовом кода Python из хранимой процедуры в T-SQL.
- PythonLauncher вызывает экземпляр среды выполнения Python, установленной на компьютере SQL Server.
- Результаты возвращаются в BxlServer.
- SQL Satellite управляет взаимодействием с SQL Server и очисткой связанных объектов задания.
- SQL Server передает результаты клиенту.