Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Применимо к:![]() SQL Server 2016 (13.x) и более поздним версиям
SQL Server 2016 (13.x) и более поздним версиям ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
В третьей части этого цикла учебников, состоящего из четырех частей, вы обучите прогнозную модель на языке R. В следующей части цикла вы развернете эту модель в базе данных SQL Server с помощью Служб машинного обучения или в Кластерах больших данных.
В третьей части этого цикла учебников, состоящего из четырех частей, вы обучите прогнозную модель на языке R. В следующей части цикла вы развернете эту модель в базе данных SQL Server с помощью Служб машинного обучения.
В третьей части этого цикла учебников, состоящего из четырех частей, вы обучите прогнозную модель на языке R. В следующей части цикла вы развернете эту модель в базе данных с помощью служб SQL Server R Services.
В третьей части этого цикла учебников, состоящего из четырех частей, вы обучите прогнозную модель на языке R. В следующей части цикла вы развернете эту модель в базе данных Управляемого экземпляра SQL Azure с помощью Служб машинного обучения.
В этой статье вы узнаете, как выполнять следующие задачи.
- Обучение двух моделей машинного обучения.
- Создание прогнозов из обеих моделей.
- Сравнение результатов для выбора самой точной модели.
В одной части вы узнали, как восстановить образец базы данных.
В первой части вы узнали, как загрузить данные из базы данных в кадр данных Python и подготовить данные в R.
В четвертой части вы узнаете, как хранить модель в базе данных, а затем создавать хранимые процедуры из скриптов Python, разработанных в двух и трех частях. Хранимые процедуры будут запускаться на сервере, чтобы формировать прогнозы на основе новых данных.
Prerequisites
Часть 3 из этой серии учебников предполагает, что вы выполнили необходимые условия части 1 и выполнили действия, описанные в двух частях.
Обучение двух моделей
Чтобы найти лучшую модель для данных о прокате лыж, создайте две разные модели (линейная регрессия и дерево принятия решений) и посмотрите, какая из них делает более точные прогнозы. Вы используете кадр данных rentaldata, созданный в первой части этой серии.
#First, split the dataset into two different sets:
# one for training the model and the other for validating it
train_data = rentaldata[rentaldata$Year < 2015,];
test_data = rentaldata[rentaldata$Year == 2015,];
#Use the RentalCount column to check the quality of the prediction against actual values
actual_counts <- test_data$RentalCount;
#Model 1: Use lm to create a linear regression model, trained with the training data set
model_lm <- lm(RentalCount ~ Month + Day + WeekDay + Snow + Holiday, data = train_data);
#Model 2: Use rpart to create a decision tree model, trained with the training data set
library(rpart);
model_rpart <- rpart(RentalCount ~ Month + Day + WeekDay + Snow + Holiday, data = train_data);
Создание прогнозов из обеих моделей.
Используйте функцию прогнозирования, чтобы спрогнозировать количество случаев аренды, используя каждую обученную модель.
#Use both models to make predictions using the test data set.
predict_lm <- predict(model_lm, test_data)
predict_lm <- data.frame(RentalCount_Pred = predict_lm, RentalCount = test_data$RentalCount,
Year = test_data$Year, Month = test_data$Month,
Day = test_data$Day, Weekday = test_data$WeekDay,
Snow = test_data$Snow, Holiday = test_data$Holiday)
predict_rpart <- predict(model_rpart, test_data)
predict_rpart <- data.frame(RentalCount_Pred = predict_rpart, RentalCount = test_data$RentalCount,
Year = test_data$Year, Month = test_data$Month,
Day = test_data$Day, Weekday = test_data$WeekDay,
Snow = test_data$Snow, Holiday = test_data$Holiday)
#To verify it worked, look at the top rows of the two prediction data sets.
head(predict_lm);
head(predict_rpart);
Вот результат.
RentalCount_Pred RentalCount Month Day WeekDay Snow Holiday
1 27.45858 42 2 11 4 0 0
2 387.29344 360 3 29 1 0 0
3 16.37349 20 4 22 4 0 0
4 31.07058 42 3 6 6 0 0
5 463.97263 405 2 28 7 1 0
6 102.21695 38 1 12 2 1 0
RentalCount_Pred RentalCount Month Day WeekDay Snow Holiday
1 40.0000 42 2 11 4 0 0
2 332.5714 360 3 29 1 0 0
3 27.7500 20 4 22 4 0 0
4 34.2500 42 3 6 6 0 0
5 645.7059 405 2 28 7 1 0
6 40.0000 38 1 12 2 1 0
Сравнение результатов
Теперь необходимо посмотреть, какая модель делает более точные прогнозы. Быстрый и простой способ сделать это — использовать базовую функцию построения, чтобы увидеть разницу между фактическими значениями в данных для обучения и прогнозируемыми значениями.
#Use the plotting functionality in R to visualize the results from the predictions
par(mfrow = c(1, 1));
plot(predict_lm$RentalCount_Pred - predict_lm$RentalCount, main = "Difference between actual and predicted. lm")
plot(predict_rpart$RentalCount_Pred - predict_rpart$RentalCount, main = "Difference between actual and predicted. rpart")
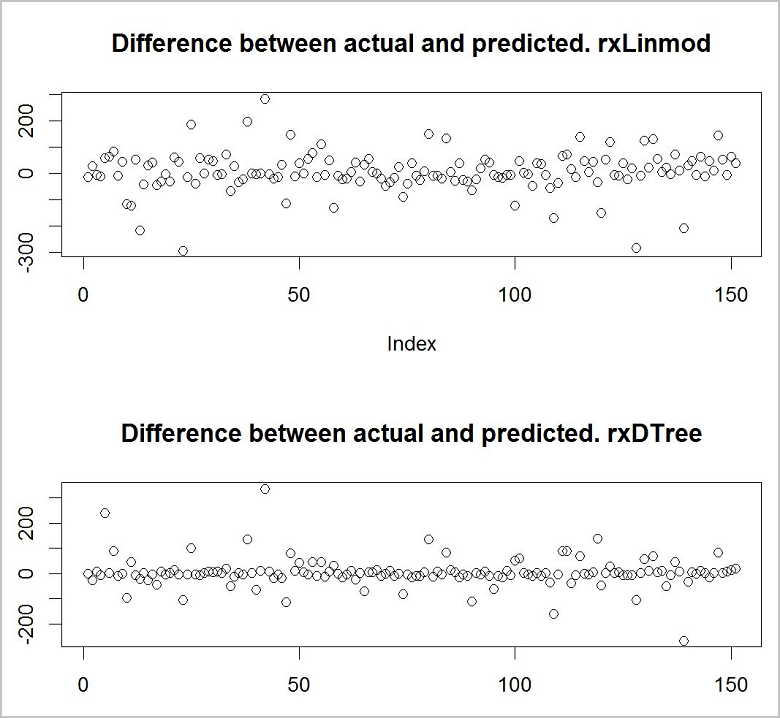
Похоже, что из двух моделей модель дерева принятия решений точнее.
Очистка ресурсов
Если вы не собираетесь продолжать работу с этим учебником, удалите базу данных TutorialDB.
Дальнейшие шаги
В третьей части этого цикла учебников вы узнали, как выполнять следующие задачи:
- Обучение двух моделей машинного обучения.
- Создание прогнозов из обеих моделей.
- Сравнение результатов для выбора самой точной модели.
Чтобы развернуть созданную модель машинного обучения, перейдите к четвертой части этого учебника: