Автоматическая настройка
Область применения:![]() SQL Server 2017 (14.x) и более поздних версий
SQL Server 2017 (14.x) и более поздних версий ![]() Управляемого экземпляра Базы данных
Управляемого экземпляра Базы данных![]() SQL Azure SQL Azure
SQL Azure SQL Azure
Функция автоматической настройки базы данных предоставляет сведения о возможных проблемах с обработкой запросов и рекомендуемые решения. Она также может автоматически исправлять выявленные проблемы.
Функция автоматической настройки, представленная в SQL Server 2017 (14.x), отправляет вам уведомление каждый раз, когда обнаруживается потенциальная ошибка производительности, и позволяет применить корректирующие действия или дает возможность ядру СУБД автоматически устранять проблемы с производительностью. Автоматическая настройка SQL Server определяет и устраняет проблемы с производительностью, вызванные регрессией плана выполнения запросов. Функция автоматической настройки в Базе данных SQL Azure также создает необходимые индексы и удаляет неиспользуемые индексы. Дополнительные сведения о планах выполнения запросов см. в разделе Планы выполнения.
Ядро СУБД SQL Server отслеживает запросы, выполняемые в базе данных, и автоматически повышает производительность рабочей нагрузки. Ядро СУБД имеет встроенный интеллектуальный механизм, способный автоматически настраивать и повышать производительность запросов путем динамической адаптации базы данных к рабочей нагрузке. Доступны две функции автоматической настройки:
Автоматическое исправление плана. Определяет проблемные планы выполнения запросов, такие как проблемы учета или сканирования параметров, а также устраняет проблемы производительности, связанные с планом выполнения запросов, принудительно применяя последний известный эффективный план до возникновения регрессии. Область применения: SQL Server (начиная с SQL Server 2017 (14.x)) и Базы данных SQL Azure и Управляемого экземпляра SQL Azure]
Автоматическое управление индексами. Определяет индексы, которые необходимо добавить в базу данных или удалить. Область применения: База данных SQL Azure
Почему автоматическая настройка
Три из основных задач в классическом администрировании базы данных — мониторинг рабочей нагрузки, определение критически важных запросов Transact-SQL и определение индексов, которые следует добавить для повышения производительности, или индексы, которые редко используются и могут быть удалены для повышения производительности. База данных SQL Azure обеспечивает точное представление о запросах и индексах, которые необходимо отслеживать. Однако постоянный мониторинг базы данных — это сложная и трудоемкая задача, особенно при работе с несколькими базами данных. Эффективное управление огромным количеством баз данных может оказаться невозможным. Вместо того чтобы отслеживать и настраивать базу данных вручную, вы можете делегировать некоторые действия по мониторингу и настройке ядру СУБД при помощи функции автоматической настройки.
Как работает автоматическая настройка
Автоматическая настройка — это непрерывный процесс мониторинга и анализа, который постоянно изучает характеристики вашей рабочей нагрузки, а также определяет потенциальные проблемы и улучшения.
Этот процесс позволяет базе данных динамически адаптироваться к рабочей нагрузке, определяя, какие индексы и планы могут повысить производительность рабочих нагрузок и какие индексы оказывают влияние на рабочие нагрузки. На основании этих результатов автоматическая настройка применяет действия по настройке, повышающие производительность рабочей нагрузки. Кроме того, автоматическая настройка постоянно отслеживает производительность базы данных после внесения любых изменений, чтобы гарантировать повышение производительности рабочей нагрузки. Любое действие, которое не улучшило производительность, автоматически отменяется. Этот процесс проверки является ключевой функцией, гарантирующей, что любые изменения, внесенные автоматической настройкой, не снижают общую производительность рабочей нагрузки.
Автоматическое исправление плана
Автоматическое исправление плана — это функция автоматической настройки, которая определяет регрессию в выборе плана выполнения и автоматически устраняет проблему, принудительно применяя последний известный эффективный план. Дополнительные сведения об обработке запросов и планах выполнения запросов см. в статье Руководство по архитектуре обработки запросов.
Внимание
Автоматическая коррекция плана зависит от того, включено ли хранилище запросов в базе данных для отслеживания рабочей нагрузки.
Что такое регрессия в выборе плана выполнения?
В ядре СУБД SQL Server могут использоваться различные планы выполнения для выполнения запросов Transact-SQL. Планы запросов зависят от статистики, индексов и других факторов. Оптимальный план, который следует использовать для выполнения запроса Transact-SQL, может меняться со временем в зависимости от изменений в этих факторах. В некоторых случаях новый план может быть не лучше предыдущего и может привести к регрессии производительности, например к проблеме, связанной с учетом параметров или сканированием параметров.
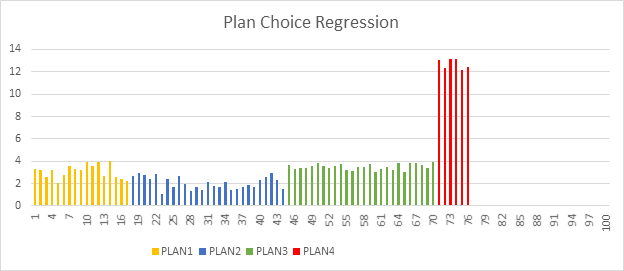
Всякий раз, когда вы замечаете регрессию в выборе плана, вам нужно найти предыдущий эффективный план и принудительно использовать его вместо текущего. Это можно сделать с помощью процедуры sp_query_store_force_plan. В ядре СУБД в SQL Server 2017 (14.x) содержатся сведения о планах с потерей производительности, а также рекомендуемых действиях по их исправлению. Кроме того, ядро СУБД позволяет полностью автоматизировать этот процесс, а также устранить любую обнаруженную проблему, связанную с изменением плана.
Внимание
Автоматическую коррекцию плана следует использовать в рамках обновления уровня совместимости базы данных после захвата базового уровня для автоматического снижения рисков обновления рабочей нагрузки. Дополнительные сведения об этом варианте использования см. в разделе Поддержание стабильной производительности во время обновления до более новой версии SQL Server.
Автоматическое исправление выбранного плана
Ядро СУБД может автоматически переключаться на последний известный эффективный план всякий раз, когда обнаруживается регрессия в выборе плана.
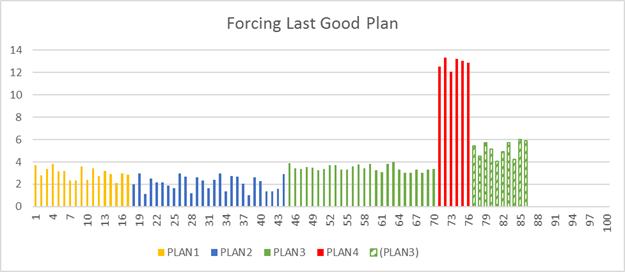
Ядро СУБД автоматически обнаруживает любую потенциальную регрессию в выборе плана, включая план, который следует использовать вместо неправильного. Итоговый план выполнения, принудительно вызванный автоматической коррекцией плана, будет таким же или похожим на последний известный эффективный план. Так как итоговый план может не совпадать с последним известным планом, производительность принудительного плана может быть другой. В редких случаях разница в производительности может быть значительной и отрицательной; в этом случае автоматическая коррекция плана автоматически прекратит попытки форсировать замену плана.
Когда в ядре СУБД применяется последний известный эффективный план до регрессии, он автоматически отслеживает производительность принудительного плана. Если принудительный план не лучше регрессивного, новый план не будет применяться принудительно и с помощью ядра СУБД будет скомпилирован новый план. Если ядро СУБД проверит, что принудительный план лучше регрессивного, принудительный план будет сохранен. Он будет храниться до тех пор, пока не произойдет повторная компиляция (например, при следующем обновлении статистики или изменении схемы). Дополнительные сведения о принудительном использовании планов и типах планов, которые могут быть принудительными, см. в разделе Ограничения принудительного применения плана.
Заметка
Если экземпляр SQL Server перезапускается перед проверкой принудительного действия плана, этот план будет автоматически отключен. В противном случае принудительное выполнение плана сохраняется при перезапуске SQL Server.
Включение автоматического исправления выбора плана
Вы можете включить автоматическую настройку для каждой базы данных и указать, что последний эффективный план должен быть принудительно применен всякий раз, когда обнаруживается некоторая регрессия изменения плана. Автоматическая настройка включается с помощью следующей команды.
ALTER DATABASE <yourDatabase>
SET AUTOMATIC_TUNING ( FORCE_LAST_GOOD_PLAN = ON );
После включения этого параметра для ядра СУБД будет автоматически применяться любая рекомендация, в которой предполагаемое увеличение ЦП превышает 10 секунд или количество ошибок в новом плане превышает количество ошибок в рекомендуемом и проверяет, будет ли принудительный план лучше текущего.
Чтобы включить автоматическую настройку в Базе данных SQL Azure и Управляемом экземпляре SQL Azure, см . статью "Включить автоматическую настройку в Базе данных SQL Azure" с помощью портала Azure.
Альтернатива — исправление выбранного плана вручную
Без автоматической настройки пользователи должны периодически проверять состояние системы и искать запросы, в которых были потери производительности. Если в каком-либо плане обнаружена потеря производительности, пользователю нужно найти предыдущий эффективный план и принудительно применить его вместо текущего, используя процедуру sp_query_store_force_plan. Лучшей методикой будет принудительное применение последнего известного эффективного плана, потому что предыдущие планы могут оказаться недействительными из-за изменений статистики или индекса. Пользователь, принудительно применяющий последний известный эффективный план, должен отслеживать производительность запроса, выполняемого с использованием принудительного плана, и проверять, работает ли принудительный план должным образом. В зависимости от результатов мониторинга и анализа план должен быть применен принудительно или пользователь должен найти другой способ оптимизации запроса, например перезапись. Принудительно примененные вручную планы не следует применять на неограниченное количество времени, так как в ядре СУБД должна быть возможность применения оптимальных планов. В конечном итоге пользователь или администратор баз данных должен отменить принудительное применение плана с помощью процедуры sp_query_store_unforce_plan и позволить ядру СУБД найти оптимальный план.
Совет
В качестве альтернативы можно использовать представление хранилища запросов Запросы с принудительными планами, чтобы найти и отменить принудительно примененные планы.
SQL Server предоставляет все необходимые представления и процедуры, необходимые для мониторинга производительности и устранения проблем в хранилище запросов.
В SQL Server 2016 (13.x) регрессии выбора плана можно найти с помощью системных представлений хранилища запросов. Начиная с SQL Server 2017 (14.x) в ядре СУБД обнаруживаются и отображаются потенциальные регрессии при выборе плана, а также рекомендуемые действия, которые следует применять в динамическом административном представлении sys.dm_db_tuning_recommendations (Transact-SQL). В динамическом административном представлении показана информация о проблеме, ее важности и такие сведения, как идентифицированный запрос, идентификатор регрессивного плана, идентификатор плана, который использовался в качестве базового для сравнения, а также инструкция Transact-SQL, которую можно выполнить для устранения проблемы.
| тип | description | datetime | score | details | ... |
|---|---|---|---|---|---|
FORCE_LAST_GOOD_PLAN |
Время ЦП изменено с 4 мс на 14 мс | 17.03.2017 | 83 | queryId recommendedPlanId regressedPlanId T-SQL |
|
FORCE_LAST_GOOD_PLAN |
Время ЦП изменено с 37 мс на 84 мс | 16.03.2017 | 26 | queryId recommendedPlanId regressedPlanId T-SQL |
Некоторые столбцы из этого представления описаны в следующем списке:
- Тип рекомендуемого действия
FORCE_LAST_GOOD_PLAN. - Описание, содержащее сведения о том, почему ядро СУБД считает, что это изменение плана может привести к снижению производительности.
- Дата и время обнаружения потенциальной регрессии.
- Оценка этой рекомендации.
- Сведения о таких проблемах, как идентификатор обнаруженного плана, идентификатор регрессивного плана, идентификатор плана, с помощью которого проблема должна была быть принудительно устранена, скрипт Transact-SQL, который можно применить для устранения проблемы и т. д. Сведения хранятся в формате JSON.
Используйте следующий запрос, чтобы получить скрипт, устраняющий проблему, и дополнительные сведения о предполагаемом увеличении:
SELECT reason, score,
script = JSON_VALUE(details, '$.implementationDetails.script'),
planForceDetails.*,
estimated_gain = (regressedPlanExecutionCount + recommendedPlanExecutionCount)
* (regressedPlanCpuTimeAverage - recommendedPlanCpuTimeAverage)/1000000,
error_prone = IIF(regressedPlanErrorCount > recommendedPlanErrorCount, 'YES','NO')
FROM sys.dm_db_tuning_recommendations
CROSS APPLY OPENJSON (Details, '$.planForceDetails')
WITH ( [query_id] int '$.queryId',
regressedPlanId int '$.regressedPlanId',
recommendedPlanId int '$.recommendedPlanId',
regressedPlanErrorCount int,
recommendedPlanErrorCount int,
regressedPlanExecutionCount int,
regressedPlanCpuTimeAverage float,
recommendedPlanExecutionCount int,
recommendedPlanCpuTimeAverage float
) AS planForceDetails;
Результирующий набор:
| reason | score | Скрипт | query_id | текущий plan_id | рекомендуемый plan_id | estimated_gain | error_prone |
|---|---|---|---|---|---|---|---|
| Время ЦП изменено с 3 мс на 46 мс | 36 | EXEC sp_query_store_force_plan 12, 17; | 12 | 28 | 17 | 11,59 | 0 |
Столбец estimated_gain представляет предполагаемое количество секунд, которое будет сохранено, если рекомендуемый план будет использоваться для выполнения запроса вместо текущего. Рекомендуемый план следует принудительно использовать вместо текущего, если увеличение составляет 10 секунд. Если в текущем плане больше ошибок (например, время ожидания или прерванные выполнения), чем в рекомендуемом плане, столбец error_prone будет иметь значение YES. Подверженный ошибкам план является еще одной причиной, по которой рекомендуемый план следует принудительно использовать вместо текущего.
Хотя в ядре СУБД предоставляется вся информация, необходимая для выявления регрессии выбора плана, непрерывный мониторинг и устранение проблем с производительностью может стать утомительным процессом. Автоматическая настройка намного упрощает этот процесс.
Заметка
Данные в динамическом административном представлении sys.dm_db_tuning_recommendations не сохраняются после перезапуска ядра СУБД. Узнать время последнего запуска ядра СУБД можно в столбце sqlserver_start_time из sys.dm_os_sys_info.
Автоматическое управление индексами
В базе данных SQL Azure управлять индексами легко, так как база данных SQL Azure отслеживает рабочую нагрузку и всегда обеспечивает оптимальную индексацию данных. Правильное проектирование индекса имеет решающее значение для обеспечения оптимальной производительности при рабочей нагрузке. Автоматическое управление индексами поможет оптимизировать их. Автоматическое управление индексами может как устранять проблемы с производительностью в неправильно индексированных базах данных, так и поддерживать и оптимизировать индексы в существующей схеме базы данных. Автоматическая настройка в Базе данных SQL Azure выполняет следующие действия:
- определение индексов, которые могут повысить производительность запросов Transact-SQL, считывающих данные из таблиц;
- определение избыточных индексов или индексов, которые не использовались в течение длительного периода времени, которые можно удалить. Удаление ненужных индексов повышает производительность запросов, обновляющих данные в таблицах.
Для чего необходимо управление индексами
Индексы ускоряют некоторые из ваших запросов, которые считывают данные из таблиц, однако они могут замедлять запросы, которые обновляют данные. Необходимо тщательно проанализировать необходимость создания индекса и какие столбцы нужно включать в него. Некоторые индексы могут оказаться ненужными через некоторое время. Таким образом, необходимо периодически определять индексы, которые не приносят никаких преимуществ, и удалять их. Если проигнорировать неиспользуемые индексы, производительность запросов, которые обновляют данные, снизится без какой-либо пользы для запросов, которые считывают данные. Неиспользуемые индексы также влияют на общую производительность системы, так как дополнительные обновления требуют ненужного ведения журнала.
Поиск оптимального набора индексов, повышающего производительность запросов, которые считывают данные из таблиц и оказывают минимальное влияние на обновления, может потребовать непрерывного и сложного анализа.
База данных SQL Azure использует встроенную аналитику и расширенные правила, которые анализируют запросы, определяют индексы, оптимальные для текущих рабочих нагрузок, а также индексы, которые, возможно, потребуется удалить. База данных SQL Azure гарантирует, что у вас есть минимально необходимый набор индексов, оптимизирующих запросы, которые считывают данные, с минимальным влиянием на другие запросы.
Автоматическое управление индексами
Помимо обнаружения База данных SQL Azure может автоматически применять определенные рекомендации. Если обнаружится, что встроенные правила повышают производительность базы данных, можно разрешить Базе данных SQL Azure автоматически управлять индексами.
Когда База данных SQL Azure применяет рекомендацию CREATE INDEX или DROP INDEX, она автоматически отслеживает производительность запросов, на которые влияет индекс. Новый индекс будет сохранен только в том случае, если производительность затронутых запросов улучшается. Удаленный индекс будет автоматически создан повторно, если есть запросы, которые выполняются медленнее из-за отсутствия индекса.
Рекомендации по автоматическому управлению индексами
Действия, которые требуются для создания необходимых индексов в Базе данных SQL Azure, могут потреблять ресурсы и временно влиять на производительность рабочей нагрузки. Чтобы свести к минимуму влияние создания индекса на производительность рабочей нагрузки, База данных SQL Azure находит подходящее временное окно для любой операции управления индексом. Действия по настройке будут отложены, если базе данных требуются ресурсы для выполнения рабочей нагрузки, и будут перезапущены, когда в базе данных будет достаточно неиспользуемых ресурсов, которые можно использовать для задачи обслуживания. Одна из важных функций автоматического управления индексами — это проверка действий. Когда База данных SQL Azure создает или удаляет индекс, процесс мониторинга анализирует производительность рабочей нагрузки, чтобы убедиться, что это действие улучшило общую производительность. Если действие не привело к значительным улучшениям, оно будет немедленно отменено. Таким образом, База данных SQL Azure гарантирует, что действия автоматической настройки не повлияют негативно на производительность рабочей нагрузки. Индексы, созданные автоматической настройкой, прозрачны для операции обслуживания в базовой схеме. Изменения схемы, например удаление или переименование столбцов, не блокируются при наличии автоматически созданных индексов. Индексы, которые были автоматически созданы Базой данных SQL Azure, немедленно удаляются при удалении связанных таблиц или столбцов.
Альтернатива — ручное управление индексами
Без автоматического управления индексами пользователю или администратору баз данных пришлось бы вручную запрашивать представление sys.dm_db_missing_index_details (Transact-SQL) или использовать отчет панели мониторинга производительности в Management Studio для поиска индексов, которые могли бы повысить производительность, создать индексы с помощью сведений, предоставленных в этом представлении, и вручную отслеживать производительность запроса. Чтобы найти индексы, которые необходимо удалить, пользователи должны отслеживать статистику использования индексов, чтобы найти редко используемые индексы.
База данных SQL Azure упрощает этот процесс. База данных SQL Azure анализирует рабочую нагрузку, определяет запросы, которые могут быть выполнены быстрее с новым индексом, а также выявляет неиспользуемые или дублированные индексы. Дополнительные сведения об идентификации индексов, которые необходимо изменить, см. в статье Использование помощника по базам данных SQL на портале Azure.
Далее
- Автоматическая настройка в Базе данных SQL Azure и Управляемом экземпляре SQL Azure
- ALTER DATABASE SET AUTOMATIC_TUNING (Transact-SQL)
- sys.database_automatic_tuning_options (Transact-SQL)
- sys.dm_db_tuning_recommendations (Transact-SQL)
- sys.dm_db_missing_index_details (Transact-SQL)
- sp_query_store_force_plan (Transact-SQL)
- sys.query_store_plan_forcing_locations (Transact-SQL)
- sp_query_store_unforce_plan (Transact-SQL)
- sys.database_query_store_options (Transact-SQL)
- sys.dm_os_sys_info (Transact-SQL)
- Функций JSON
- Планы выполнения
- Наблюдение и настройка производительности
- Средства контроля и настройки производительности
- Мониторинг производительности с использованием хранилища запросов
- Помощник по настройке запросов
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по