Заметка
Доступ к этой странице требует авторизации. Вы можете попробовать войти в систему или изменить каталог.
Доступ к этой странице требует авторизации. Вы можете попробовать сменить директорию.
Применимо:![]() SQL Server
SQL Server ![]() База данных SQL Azure Управляемый экземпляр SQL Azure
База данных SQL Azure Управляемый экземпляр SQL Azure![]()
![]() azure Synapse Analytics Analytics
azure Synapse Analytics Analytics![]() Platform System (PDW)
Platform System (PDW)
В этой статье описывается, как использовать файл форматирования для пропуска импорта столбца таблицы, когда данные для пропущенного столбца не существуют в исходном файле данных. Количество полей в файле данных может быть меньше количества столбцов в целевой таблице. То есть столбец пропускается, если верно хотя бы одно из следующих двух условий для целевой таблицы:
- пропускаемый столбец допускает значение NULL;
- пропускаемый столбец имеет значение по умолчанию.
Примечание.
Этот синтаксис, включая массовую вставку, не поддерживается в Azure Synapse Analytics. В Azure Synapse Analytics и других облачных платформах баз данных выполните перемещение данных с помощью инструкции COPY в Фабрика данных Azure или с помощью инструкций T-SQL, таких как COPY INTO и PolyBase.
Пример таблицы и файла данных
Примеры, приведенные в этой статье, ожидают таблицу с именем myTestSkipCol в схеме dbo . Эту таблицу можно создать в примере базы данных, например WideWorldImporters или AdventureWorks в любой другой базе данных. Создайте таблицу следующим образом:
USE WideWorldImporters;
GO
CREATE TABLE myTestSkipCol
(
Col1 SMALLINT,
Col2 NVARCHAR (50) NULL,
Col3 NVARCHAR (50) NOT NULL
);
GO
В примерах в этой статье также используется образец файла данных myTestSkipCol2.dat. Этот файл содержит только два поля, хотя целевая таблица содержит три столбца.
1,DataForColumn3
1,DataForColumn3
1,DataForColumn3
Основные этапы
Чтобы пропустить столбец таблицы, вы можете использовать файл форматирования как в формате XML, так и в формате, отличном от XML. В обоих случаях есть два этапа:
- Используйте служебную программу командной строки bcp, чтобы создать файл форматирования по умолчанию.
- Измените формат файла форматирования по умолчанию в текстовом редакторе.
Измененный файл форматирования должен сопоставлять каждое существующее поле с соответствующим ему столбцом в целевой таблице. Он также должен указывать, какие столбцы таблицы следует пропускать.
Например, чтобы выполнить массовый импорт данных из myTestSkipCol2.dat в таблицу myTestSkipCol, в файле форматирования первое поле данных сопоставляется с Col1, пропускается Col2, и второе поле сопоставляется с Col3.
Вариант 1. Использование файла форматирования не в формате XML
Шаг 1. Создание файла форматирования по умолчанию в формате, отличном от XML
Создайте файл форматирования по умолчанию в формате, отличном от XML, для примера таблицы myTestSkipCol. Для этого выполните следующую команду bcp в командной строке:
bcp WideWorldImporters..myTestSkipCol format nul -f myTestSkipCol_Default.fmt -c -T
Внимание
Возможно, вам придется указать имя экземпляра сервера, к которому вы подключаетесь с аргументом -S . Кроме того, может потребоваться указать имя пользователя и пароль с помощью аргументов -U и -P. Дополнительные сведения см. в разделе bcp Utility.
Предыдущая команда создает файл форматирования в формате, отличном от XML, myTestSkipCol_Default.fmt. Этот файл форматирования называется файлом форматирования по умолчанию , так как это форма, созданная bcp. Файл форматирования по умолчанию задает однозначное соответствие между полями файла данных и столбцами таблицы.
На следующем снимке экрана показаны значения в этом примере файла форматирования по умолчанию.
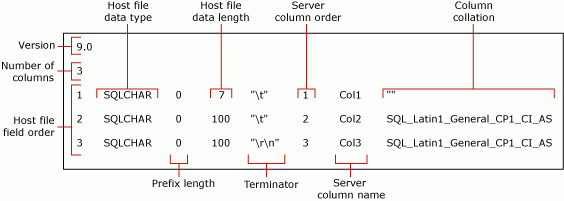
Примечание.
Дополнительные сведения о полях форматирования файлов см. в файлах форматирования, отличных от XML (SQL Server).
Шаг 2. Изменение файла форматирования в формате, отличном от XML
Есть два способа изменить файл форматирования по умолчанию в формате, отличном от XML. Либо альтернатива указывает, что поле данных не существует в файле данных и что данные не должны быть вставлены в соответствующий столбец таблицы.
Чтобы пропустить столбец таблицы, отредактируйте файл форматирования в формате, отличном от XML, и измените файл с помощью одного из следующих вариантов.
Вариант 1. Удаление строки
Рекомендуемый метод для пропуска столбца включает три следующих этапа:
- Сначала удалите из файла форматирования все строки, которые описывают поля, отсутствующие в исходном файле данных.
- Затем уменьшите значение «порядкового номера поля в файле данных» каждой строки файла форматирования, которая следует за удаленной строкой. Целью являются последовательные значения "порядкового номера поля в файле данных", от 1 до n, которые отражают действительную позицию каждого поля данных в файле данных.
- Наконец, уменьшите значение в поле «Число столбцов» до действительного числа полей в файле данных.
Приведенный ниже пример основан на файле форматирования по умолчанию для таблицы myTestSkipCol. Этот измененный файл форматирования сопоставляет первое поле данных полю Col1, пропускает поле Col2и сопоставляет второе поле данных Col3. Строка для поля Col2 была удалена. Разделитель после первого поля также изменен с \t на ,.
14.0
2
1 SQLCHAR 0 7 "," 1 Col1 ""
2 SQLCHAR 0 100 "\r\n" 3 Col3 SQL_Latin1_General_CP1_CI_AS
Вариант 2. Изменение определения строки
В качестве альтернативы, чтобы пропустить столбец таблицы, можно изменить определение строки файла форматирования, которая соответствует этому столбцу таблицы. В этой строке файла форматирования значения «длина префикса», «длина данных файла узла» и «порядковый номер столбца на сервере» должны быть равны 0. Кроме того, поля "терминатор" и "параметры сортировки столбцов" должны иметь значение "" (т. е. пустое или NULL значение). Для значения столбца сервера требуется непустая строка, хотя фактическое имя столбца не требуется. Для оставшихся полей форматирования требуются значения по умолчанию.
Следующий пример основан на файле форматирования по умолчанию для таблицы myTestSkipCol .
14.0
3
1 SQLCHAR 0 7 "," 1 Col1 ""
2 SQLCHAR 0 0 "" 0 Col2 ""
3 SQLCHAR 0 100 "\r\n" 3 Col3 SQL_Latin1_General_CP1_CI_AS
Примеры с файлом форматирования не в формате XML
Приведенные ниже примеры основаны на образце таблицы myTestSkipCol и образце файла данных myTestSkipCol2.dat, описанных ранее в этой статье.
Использование BULK INSERT
Этот пример может использовать любой из измененных файлов форматирования не в формате XML, создание которых описано в предыдущем разделе. В этом примере измененный файл форматирования называется myTestSkipCol2.fmt.
BULK INSERT Для массового импорта myTestSkipCol2.dat файла данных в SQL Server Management Studio (SSMS) выполните следующий код. Обновите пути файловой системы к файлам образцов на вашем компьютере.
USE WideWorldImporters;
GO
BULK INSERT myTestSkipCol FROM 'C:\myTestSkipCol2.dat'
WITH (FORMATFILE = 'C:\myTestSkipCol2.fmt');
GO
SELECT *
FROM myTestSkipCol;
GO
Вариант 2. Использование файла форматирования в формате XML
Шаг 1. Создание XML-файла форматирования по умолчанию
Создайте XML-файл форматирования по умолчанию для примера таблицы myTestSkipCol. Для этого выполните следующую команду bcp в командной строке:
bcp WideWorldImporters..myTestSkipCol format nul -f myTestSkipCol_Default.xml -c -x -T
Внимание
Возможно, вам придется указать имя экземпляра сервера, к которому вы подключаетесь с аргументом -S . Кроме того, может потребоваться указать имя пользователя и пароль с помощью аргументов -U и -P. Дополнительные сведения см. в разделе bcp Utility.
При помощи предыдущей команды создается XML-файл форматирования myTestSkipCol_Default.xml. Этот файл форматирования называется файлом форматирования по умолчанию , так как это форма, созданная bcp. Файл форматирования по умолчанию задает однозначное соответствие между полями файла данных и столбцами таблицы.
<?xml version="1.0"?>
<BCPFORMAT xmlns="http://schemas.microsoft.com/sqlserver/2004/bulkload/format" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<RECORD>
<FIELD ID="1" xsi:type="CharTerm" TERMINATOR="\t" MAX_LENGTH="7" />
<FIELD ID="2" xsi:type="CharTerm" TERMINATOR="\t" MAX_LENGTH="100" COLLATION="SQL_Latin1_General_CP1_CI_AS" />
<FIELD ID="3" xsi:type="CharTerm" TERMINATOR="\r\n" MAX_LENGTH="100" COLLATION="SQL_Latin1_General_CP1_CI_AS" />
</RECORD>
<ROW>
<COLUMN SOURCE="1" NAME="Col1" xsi:type="SQLSMALLINT" />
<COLUMN SOURCE="2" NAME="Col2" xsi:type="SQLNVARCHAR" />
<COLUMN SOURCE="3" NAME="Col3" xsi:type="SQLNVARCHAR" />
</ROW>
</BCPFORMAT>
Примечание.
Сведения о структуре XML-файлов форматирования см. в разделе XML-файлы форматирования (SQL Server).
Шаг 2. Изменение XML-файла форматирования
Ниже приведен измененный XML-файл форматирования myTestSkipCol2.xml, который пропускает Col2. Записи FIELD и ROW для Col2 были удалены, и записи были перенумерованы. Разделитель после первого поля также изменен с \t на ,.
<?xml version="1.0"?>
<BCPFORMAT xmlns="http://schemas.microsoft.com/sqlserver/2004/bulkload/format" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<RECORD>
<FIELD ID="1" xsi:type="CharTerm" TERMINATOR="," MAX_LENGTH="7" />
<FIELD ID="2" xsi:type="CharTerm" TERMINATOR="\r\n" MAX_LENGTH="100" COLLATION="SQL_Latin1_General_CP1_CI_AS" />
</RECORD>
<ROW>
<COLUMN SOURCE="1" NAME="Col1" xsi:type="SQLSMALLINT" />
<COLUMN SOURCE="2" NAME="Col3" xsi:type="SQLNVARCHAR" />
</ROW>
</BCPFORMAT>
Примеры с XML-файлом форматирования
Приведенные ниже примеры основаны на образце таблицы myTestSkipCol и образце файла данных myTestSkipCol2.dat, описанных ранее в этой статье.
Для импорта данных из файла myTestSkipCol2.dat в таблицу myTestSkipCol в примерах используется измененный XML-файл форматирования myTestSkipCol2.xml.
Использование BULK INSERT с представлением
В XML-файле форматирования невозможно пропустить столбец при импорте непосредственно в таблицу с помощью команды bcp или инструкции BULK INSERT . Однако можно выполнить импорт всех столбцов таблицы, кроме последнего. Если нужно пропустить любой столбец, кроме последнего, создайте представление целевой таблицы, которое содержит только столбцы из файла данных. После этого можно выполнить массовый импорт данных из этого файла в представление.
Следующий пример создает представление v_myTestSkipCol для таблицы myTestSkipCol. В этом представлении пропущен второй столбец таблицы Col2. Затем применяется инструкция BULK INSERT для импорта файла данных myTestSkipCol2.dat в это представление.
Выполните в SSMS следующий код. Обновите пути файловой системы к файлам образцов на вашем компьютере.
USE WideWorldImporters;
GO
CREATE VIEW v_myTestSkipCol AS
SELECT Col1,
Col3
FROM myTestSkipCol;
GO
BULK INSERT v_myTestSkipCol FROM 'C:\myTestSkipCol2.dat'
WITH (FORMATFILE = 'C:\myTestSkipCol2.xml');
GO
Использование OPENROWSET(BULK...)
Чтобы использовать XML-файл форматирования для пропуска столбца таблицы с помощью OPENROWSET(BULK...), предоставьте в явном виде следующий список столбцов в списке выбора и в целевой таблице, как показано ниже:
INSERT ...<column_list> SELECT <column_list> FROM OPENROWSET(BULK...)
В следующем примере используется поставщик массового набора строк OPENROWSET и файл форматирования myTestSkipCol2.xml . В примере выполняется массовый импорт файла данных myTestSkipCol2.dat в таблицу myTestSkipCol . Инструкция, в соответствии с требованиями, содержит явный список столбцов в списке выбора, а также в целевой таблице.
Выполните в SSMS следующий код. Обновите пути файловой системы к файлам образцов на вашем компьютере.
USE WideWorldImporters;
GO
INSERT INTO myTestSkipCol (Col1, Col3)
SELECT Col1,
Col3
FROM OPENROWSET (
BULK 'C:\myTestSkipCol2.Dat',
FORMATFILE = 'C:\myTestSkipCol2.Xml'
) AS t1;
GO
Связанный контент
- Программа bcp
- BULK INSERT (Transact-SQL)
- OPENROWSET (Transact-SQL)
- Использование файла форматирования для пропуска поля данных (SQL Server)
- Использование файла форматирования для сопоставления столбцов таблиц с полями файлов данных (SQL Server)
- Использование файла форматирования для массового импорта данных (SQL Server)