Размер таблицы и строки в оптимизированных для памяти таблицах
Применимо к:![]() SQL Server
SQL Server![]() База данных SQL Azure Управляемый экземпляр SQL Azure
База данных SQL Azure Управляемый экземпляр SQL Azure![]()
До SQL Server 2016 (13.x) размер данных в строке оптимизированной для памяти таблицы не может превышать 8 060 байт. Однако начиная с SQL Server 2016 (13.x) и в База данных SQL Azure можно создать оптимизированную для памяти таблицу с несколькими большими столбцами (например, несколькими столбцами varbinary(8000) и бизнес-столбцами (то есть varbinary(max),varchar(max), а также nvarchar(max)) и выполнять операции с ними с помощью модулей Transact-SQL (T-SQL) и типов таблиц.
Столбцы, которые не соответствуют ограничению размера строки 8060 байт, помещаются вне строки в отдельной внутренней таблице. У каждого такого столбца имеется соответствующая внутренняя таблица, которая, в свою очередь, имеет один некластеризованный индекс. Дополнительные сведения об этих внутренних таблицах, используемых для столбцов вне строк, см. в sys.memory_optimized_tables_internal_attributes.
Существуют определенные сценарии, в которых полезно вычислить размер строки и таблицы:
Сколько памяти использует таблица.
Объем памяти, используемой таблицей, не может быть вычисляться точно. На объем используемой памяти влияет множество факторов. Это такие факторы, как постраничное выделение места в памяти, размещение, кэширование и заполнение. Кроме того, несколько версий строк, которые имеют активные связанные транзакции либо ожидают сборку мусора.
Минимальный размер, необходимый для данных и индексов в таблице, определяется вычислением для
<table size>, рассмотренным далее в этой статье.Вычисление использования памяти лучше всего приблизить, и вам рекомендуется включить планирование емкости в планы развертывания.
Размер данных строки и соответствует ли он ограничению размера строки в 8 060 байтов? Чтобы ответить на эти вопросы, используйте вычисления для
<row body size>, рассмотренные далее в этой статье.
Таблица, оптимизированная для памяти, представляет собой набор строк, а также индексов, которые содержат указатели на строки. На следующей схеме показана таблица с индексами и строками, которые в свою очередь содержат заголовки и текст:
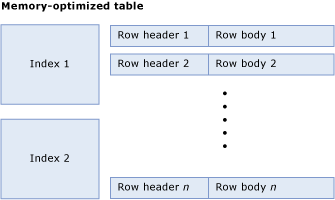
Размер таблицы вычислений
Размер, занимаемый таблицей в памяти (в байтах) вычисляется следующим образом.
<table size> = <size of index 1> + ... + <size of index n> + (<row size> * <row count>)
Размер хэш-индекса фиксируется на момент создания таблицы и зависит от фактического числа контейнеров. Значение bucket_count, указанное спецификацией индекса, округляется в сторону увеличения до ближайшей степени числа 2 для получения фактического числа контейнеров. Например, если указанное bucket_count значение равно 100000, фактическое число контейнеров для индекса 131072.
<hash index size> = 8 * <actual bucket count>
Размер некластеризованного индекса определяется в <row count> * <index key size>.
Размер строки вычисляется путем сложения значений для заголовка и текста:
<row size> = <row header size> + <actual row body size>
<row header size> = 24 + 8 * <number of indexes>
Размер текста вычисляемой строки
Строки в таблице, оптимизированной для памяти, включают следующие компоненты.
Заголовок строки содержит метку времени, необходимую для управления версиями строки. Заголовок строки также содержит указатель индекса для реализации цепочки строк в хэш-контейнерах (описанных ранее).
Текст строки содержит фактические данные столбцов, которые включают некоторые вспомогательные сведения, такие как массив значений NULL для столбцов, допускающих значение NULL, и массив смещений для типов данных с переменной длиной.
На следующем рисунке показана структура строк для таблицы с двумя индексами.

Метки времени начала и конца показывают период, в котором определенная версия строки является допустимой. Транзакции, запускаемые в данном интервале, могут видеть эту версию строки. Дополнительные сведения см. в разделе "Транзакции с оптимизированными для памяти таблицами".
Указатели индекса указывают на следующую строку в цепочке, принадлежащей хэш-контейнеру. На следующем рисунке показана структура таблицы с двумя столбцами (имя, город) и двумя индексами, один для столбца name и второй для столбца city.
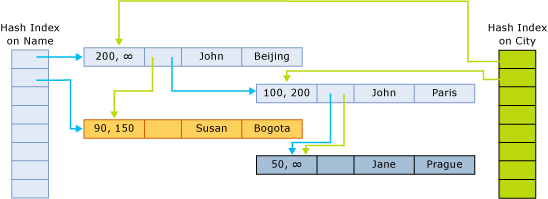
На этом рисунке имена John и Jane хэшируются в первый контейнер. Susan хэшируется во втором контейнере. Города Beijing и Bogota хэшируются в первый контейнер. Paris и Prague хэшируются во втором контейнере.
Таким образом, цепочки для хэш-индекса по именам выглядят следующим образом.
- Первый контейнер:
(John, Beijing); ;(John, Paris)(Jane, Prague) - Второй контейнер:
(Susan, Bogota)
Цепочки для индекса по городам выглядят следующим образом:
- Первый контейнер:
(John, Beijing),(Susan, Bogota) - Второй контейнер:
(John, Paris),(Jane, Prague)
Конечная метка времени ∞ (бесконечность) указывает, что это действительная на данный момент версия строки. Строка не была обновлена или удалена, так как эта версия строки была написана.
В течение большего времени 200таблица содержит следующие строки:
| Имя. | Город |
|---|---|
| Джон | Пекин |
| Джейн | Prague |
Однако любая активная транзакция с началом 100работы см. в следующей версии таблицы:
| Имя. | Город |
|---|---|
| Джон | Париж |
| Джейн | Prague |
| Сьюзан | Богота |
Вычисление <row body size> рассматривается в следующей таблице.
Размер текста строки вычисляется двумя способами: вычисляемый размер и фактический размер.
Вычисляемый размер (далее — вычисляемый размер строки) используется для того, чтобы определить, не превышает ли размер строки ограничение в 8060 байт.
Фактический размер (далее — фактический размер строки) представляет собой фактический размер строки в памяти и в файлах контрольных точек.
Оба показателя, вычисляемый размер строки и фактический размер строки, вычисляются схожим образом. Единственное различие заключается в вычислении размера столбцов (n)varchar(i) и varbinary(i), как отражено в нижней части следующей таблицы. Вычисляемый размер строки использует в качестве размера столбца декларируемый размер i , тогда как фактический размер строки использует фактический размер данных.
В следующей таблице описывается вычисление размера текста строки, заданного как <actual row body size> = SUM(<size of shallow types>) + 2 + 2 * <number of deep type columns>.
| Раздел | Размер | Комментарии |
|---|---|---|
| Столбцы неглубокого типа | SUM(<size of shallow types>). Размер отдельных типов в байтах:bit: 1tinyint: 1smallint: 2int: 4real: 4smalldatetime: 4smallmoney: 4bigint: 8datetime: 8datetime2: 8float: 8деньги: 8числовой (точность <= 18): 8time: 8числовой(точность > 18): 16uniqueidentifier: 16 |
|
| Заполнение неглубокого столбца | Возможны следующие значения:1 Если есть столбцы глубокого типа, а общий размер данных мелких столбцов имеет нечетное число.0 Иначе |
Глубокие типы — это типы (var)binary и (n)(var)char. |
| Массив смещения для столбцов глубокого типа | Возможны следующие значения:0 Если столбцы глубокого типа отсутствуют2 + 2 * <number of deep type columns> Иначе |
Глубокие типы — это типы (var)binary и (n)(var)char. |
| Массив NULL | <number of nullable columns> / 8 округляется до полных байтов. |
Массив имеет 1 бит на столбец, допускающий значение NULL. Эта величина округляется в сторону увеличения до целого числа байт. |
| Заполнение массива NULL | Возможны следующие значения:1 Если есть столбцы глубокого NULL типа, а размер массива — нечетное число байтов.0 Иначе |
Глубокие типы — это типы (var)binary и (n)(var)char. |
| Заполнение | Если столбцы глубокого типа отсутствуют: 0Если есть столбцы глубокого типа, добавляется 0 – 7 байт заполнений на основе наибольшего выравнивания, необходимого для мелкого столбца. Для каждого мелкого столбца требуется выравнивание, равное его размеру, как описано ранее, за исключением того, что столбцы GUID нуждаются в выравнивании 1 байта (не 16) и числовые столбцы всегда нуждаются в выравнивании 8 байт (никогда не 16). Используется наибольшее требование выравнивания среди всех мелких столбцов. 0 – 7 байт заполнений добавляется таким образом, что общий размер до сих пор (без столбцов глубокого типа) является нескольким из требуемого выравнивания. |
Глубокие типы — это типы (var)binary и (n)(var)char. |
| Столбцы глубокого типа фиксированной длины | SUM(<size of fixed length deep type columns>)Размер каждого столбца составляет: iдля char(i) и binary(i).2 * i для nchar(i) |
Столбцы глубокого типа фиксированной длины — это столбцы типа char(i), nchar(i) или binary(i). |
| Размер вычисляемых столбцов глубокого типа переменной длины | SUM(<computed size of variable length deep type columns>)вычисляемый размер каждого столбца составляет: iдля varchar(i) и varbinary(i)2 * i для nvarchar(i) |
Эта строка применяется только к вычисляемому размеру строки. Столбцы глубокого типа переменной длины — это столбцы типа varchar(i), nvarchar(i) или varbinary(i). Вычисляемый размер определяется максимальной длиной ( i) столбца. |
| Фактический размер столбцов глубокого типа переменной длины | SUM(<actual size of variable length deep type columns>)Фактический размер каждого столбца составляет: n, где n — это число символов, хранящихся в столбце, для varchar(i).2 * n, где n — это число символов, хранящихся в столбце, для nvarchar(i).n, где n — это число байтов, хранящихся в столбце, для varbinary(i). |
Эта строка применяется только к фактическому размеру строки. Фактический размер определяется данными, которые хранятся в столбцах в данной строке. |
Пример: вычисление размера таблицы и строки
Для хэш-индекса фактическое число контейнеров округляется в сторону увеличения до ближайшей степени числа 2. Например, если заданное число bucket_count равно 100 000, то фактическое число контейнеров для индекса составляет 131 072.
Рассмотрим таблицу Orders со следующим определением:
CREATE TABLE dbo.Orders (
OrderID INT NOT NULL PRIMARY KEY NONCLUSTERED,
CustomerID INT NOT NULL INDEX IX_CustomerID HASH WITH (BUCKET_COUNT = 10000),
OrderDate DATETIME NOT NULL,
OrderDescription NVARCHAR(1000)
)
WITH (MEMORY_OPTIMIZED = ON);
GO
Эта таблица содержит один хэш-индекс и некластеризованный индекс (первичный ключ). Он также имеет три столбца фиксированной длины и один столбец переменной длины, при этом один из столбцов NULLможет (OrderDescription). Предположим Orders , что таблица содержит 8379 строк, а средняя длина значений в OrderDescription столбце составляет 78 символов.
Чтобы определить размер таблицы, сначала необходимо определить размер индексов. Для bucket_count обоих индексов указывается значение 10000. Эта величина округляется в сторону увеличения до ближайшей степени числа 2: 16 384. Таким образом, общий размер индексов для Orders таблицы:
8 * 16384 = 131072 bytes
Что остается, это размер данных таблицы, то есть:
<row size> * <row count> = <row size> * 8379
(Пример таблицы содержит 8379 строк.) Теперь у нас есть:
<row size> = <row header size> + <actual row body size>
<row header size> = 24 + 8 * <number of indices> = 24 + 8 * 1 = 32 bytes
Далее давайте вычислим <actual row body size>:
Столбцы поверхностных типов:
SUM(<size of shallow types>) = 4 <int> + 4 <int> + 8 <datetime> = 16Заполнение для столбцов поверхностных типов равно 0, поскольку общий размер столбцов поверхностного типа является четным числом.
Массив смещений для столбцов глубоких типов:
2 + 2 * <number of deep type columns> = 2 + 2 * 1 = 4NULLмассив = 1NULLЗаполнение массива = 1, так какNULLразмер массива нечетный, и есть столбец глубокого типа.Заполнение
- 8 — это наибольшее требование выравнивания
- Размер до сих пор составляет 16 + 0 + 4 + 1 + 1 = 22
- Ближайшее число из 8 — 24
- Всего заполнение составляет 24 – 22 = 2 байта
В таблице нет столбцов глубоких типов переменной длины (столбцов глубоких типов фиксированной длины: 0).
Фактический размер столбца глубокого типа составляет 2 * 78 = 156. Единственный столбец глубокого типа
OrderDescriptionимеет типnvarchar.
<actual row body size> = 24 + 156 = 180 bytes
Для завершения вычисления:
<row size> = 32 + 180 = 212 bytes
<table size> = 8 * 16384 + 212 * 8379 = 131072 + 1776348 = 1907420
Таким образом, общий размер, занимаемый таблицей в памяти, составляет около 2 мегабайт. Это не учитывает потенциальные издержки, связанные с выделением памяти, и любые версии строк, необходимые для транзакций, обращаюющихся к этой таблице.
Фактический размер памяти, выделяемый для данной таблицы и используемый ею и ее индексами, можно получить при помощи следующего запроса:
SELECT * FROM sys.dm_db_xtp_table_memory_stats
WHERE object_id = object_id('dbo.Orders');
Ограничения столбцов вне строк
Некоторые ограничения и предостережения для использования столбцов вне строк в оптимизированной для памяти таблице перечислены следующим образом:
- Если в таблице, оптимизированной для памяти, есть индекс columnstore, все столбцы должны соответствовать строке.
- Но все ключевые столбцы индекса должны хранится "в строке". Если ключевой столбец индекса не помещается "в строке", добавление индекса завершается ошибкой.
- Пояснения по изменению таблицы, оптимизированной для памяти, со столбцами "вне строки".
- Для бизнес-объектов ограничение размера зеркало таблиц на основе дисков (ограничение на 2 ГБ для значений бизнес-объектов).
- Для оптимальной производительности рекомендуется, чтобы большинство столбцов соответствовали 8 060 байтам.
- Данные вне строки могут привести к чрезмерному использованию памяти и (или) диска.
Связанный контент
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по