Индексы columnstore. Руководство по загрузке данных
Применимо: ![]() SQL Server
SQL Server ![]() База данных SQL Azure Управляемый экземпляр SQL Azure
База данных SQL Azure Управляемый экземпляр SQL Azure![]()
![]() azure Synapse Analytics Analytics
azure Synapse Analytics Analytics ![]() Platform System (PDW)
Platform System (PDW)
Рекомендации и параметры для загрузки данных в индексы columnstore с помощью стандартных методов массовой загрузки и тонкой вставки SQL. Загрузка данных в индекс columnstore является неотъемлемой частью любого процесса хранения данных, так как данные перемещаются в индекс при подготовке к анализу.
Незнакомы с индексами columnstore? См. статьи, посвященные обзору индексов columnstore и их архитектуре.
Что такое массовая загрузка?
Массовая загрузка — это тип добавления большого числа строк в хранилище данных. Это самый простой способ перемещения данных в индекс columnstore, так как он работает над пакетами строк. При массовой загрузке группы строк максимально заполняются, а затем сжимаются непосредственно в columnstore. В deltastore отправляются только те строки, которые по завершении загрузки не собирают даже минимальное число строк (102 400) на группу строк.
Чтобы выполнить массовую загрузку, вы можете использовать программу bcp, службы Integration Services или выбрать строки из промежуточной таблицы.
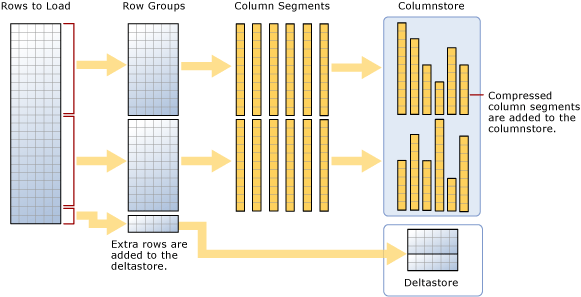
Как видно на диаграмме, массовая загрузка:
- Не предупретирует данные. Данные вставляются в группы строк в том порядке, в который он получен.
- Если размер пакета равен >102400, строки загружаются непосредственно в сжатые группы строк. Для эффективного массового импорта следует выбрать размер >пакета =102400, так как можно избежать перемещения строк данных в разностные группы строк, прежде чем строки в конечном итоге перемещены в сжатые группы строк фоновым потоком, перемещение кортежей (TM).
- Если размер < пакета 102 400 или остальные строки равны < 102 400, строки загружаются в разностные группы строк.
Примечание.
В таблице rowstore с некластеризованными данными индекса columnstore SQL Server всегда вставляет данные в базовую таблицу. Данные никогда не вставляются непосредственно в индекс columnstore.
Ниже приведены встроенные механизмы оптимизации производительности в операции массовой загрузки.
Параллельные нагрузки: можно использовать несколько параллельных массовых нагрузок (bcp или bulk insert), которые загружаются в отдельный файл данных. В отличие от массового загрузки rowstore в SQL Server, вам не нужно указывать
TABLOCK, так как каждый поток массового импорта загружает данные исключительно в отдельные группы строк (сжатые или разностные группы строк) с монопольной блокировкой.Сокращенное ведение журнала: данные, которые загружаются непосредственно в сжатые группы строк, приводят к значительному сокращению размера журнала. Например, если данные были сжаты 10x, соответствующий журнал транзакций примерно 10x меньше, не требуя ТАБЛОК или модели массового ведения журнала или простого восстановления. Все данные, которые попадают в разностную группу строк, подвергаются полному протоколированию. Сюда входят все пакеты с размером менее 102 400 строк. Рекомендуется использовать пакетную обработку >= 102400. Так как не требуется TABLOCK, данные можно загружать параллельно.
Минимальное ведение журнала: вы можете получить дальнейшее сокращение ведения журнала, если следовать предварительным требованиям для минимального ведения журнала. Однако, в отличие от загрузки данных в хранилище строк, TABLOCK приводит к блокировке X таблицы, а не блокировке bu (bulk Update) и поэтому параллельная загрузка данных не может быть выполнена. Дополнительные сведения о блокировке см. в разделе Блокировки и управление версиями строк.
Оптимизация блокировки: блокировка X группы строк автоматически приобретается при загрузке данных в сжатую группу строк. Однако при массовой загрузке в разностную группу строк блокировка X приобретается в группе строк, но SQL Server по-прежнему блокирует страницу или экстент, так как блокировка X группы строк не является частью иерархии блокировки.
Если у вас есть некластеризованный индекс B-дерева в индексе columnstore, то нет оптимизации блокировки или ведения журнала для самого индекса, но оптимизации кластеризованного индекса columnstore, как описано ранее, применимы.
Изменение данных (вставка, удаление, обновление) не является операцией в пакетном режиме, так как она не параллельна.
Планирование размеров массовых загрузок для уменьшения числа разностных групп строк
Индексы columnstore наиболее эффективны, когда большинство строк не находятся в разностных группах строк, а сжаты в columnstore. Лучше всего изменить размер загрузок, чтобы строки сразу отправлялись в columnstore, обходя deltastore.
В следующих сценариях описано, когда загруженные строки перейдут непосредственно в columnstore, а когда — в deltastore. В примере каждая rowgroup может иметь 102 400-1 048 576 строк на rowgroup. На практике максимальный размер группы строк может быть меньше 1048 576 строк при нехватке памяти.
| Строки для массовой загрузки | Строки, добавленные в сжатую группу строк | Строки, добавленные в разностную группу строк |
|---|---|---|
| 102 000 | 0 | 102 000 |
| 145,000 | 145,000 Размер группы строк: 145 000. |
0 |
| 1,048,577 | 1 048 576 Размер группы строк: 1 048 576. |
1 |
| 2,252,152 | 2,252,152 Размер группы строк: 1 048 576, 1 048 576, 155 000. |
0 |
В следующем примере показаны результаты загрузки 1 048 577 строк в таблицу. Результаты показывают наличие одной СЖАТОЙ rowgroup в columnstore (в виде сжатых сегментов столбцов) и 1 строки в deltastore.
SELECT object_id, index_id, partition_number, row_group_id, delta_store_hobt_id,
state, state_desc, total_rows, deleted_rows, size_in_bytes
FROM sys.dm_db_column_store_row_group_physical_stats;

Использование промежуточной таблицы для улучшения производительности
Если данные загружаются только на стадию перед выполнением дополнительных преобразований, загрузка таблицы в таблицу кучи гораздо быстрее, чем загрузка данных в кластеризованную таблицу columnstore. Кроме того, загрузка данных во [временную таблицу] также будет происходить значительно быстрее, чем загрузка таблицы в постоянное хранилище.
Типичным шаблоном загрузки данных является загрузка данных в промежуточную таблицу, выполнение некоторого преобразования и его загрузка в целевую таблицу с помощью следующей команды:
INSERT INTO [<columnstore index>]
SELECT col1 /* include actual list of columns in place of col1*/
FROM [<Staging Table>]
Эта команда загружает данные в индекс columnstore аналогично bcp или массовой вставке, но в одном пакете. Если число строк в промежуточной таблице < 102400, строки загружаются в разностную группу строк, в противном случае строки загружаются непосредственно в сжатые группы строк. Одно из основных ограничений заключалось в том, что эта операция INSERT была однопотоковой. Чтобы загрузить данные в параллельном режиме, можно создать несколько промежуточных таблиц или выполнить инструкцию INSERT/SELECT с неперекрывающимися диапазонами строк из промежуточной таблицы. Это ограничение исчезает с SQL Server 2016 (13.x). Следующая команда загружает данные из промежуточной таблицы параллельно, но необходимо указать TABLOCK. Вам может показаться, что это противоречит тому, что говорилось ранее о массовой загрузке. Однако ключевое различие заключается в том, что параллельная загрузка данных из промежуточной таблицы осуществляется в рамках одной транзакции.
INSERT INTO [<columnstore index>] WITH (TABLOCK)
SELECT col1 /* include actual list of columns in place of col1*/
FROM [<Staging Table>]
При загрузке в кластеризованный индекс columnstore из промежуточной таблицы доступны следующие оптимизации:
- Оптимизация журнала: уменьшение ведения журнала при загрузке данных в сжатые группы строк.
- Оптимизация блокировки. При загрузке данных в сжатые группы строк приобретается блокировка X в строковой группе. Однако при использовании разностной группы строк блокировка X приобретается в группе строк, но SQL Server по-прежнему блокирует блокировку PAGE/EXTENT, так как блокировка X rowgroup не является частью иерархии блокировки.
Если у вас есть один или несколько некластеризованных индексов, нет блокировки или оптимизации ведения журнала для самого индекса, но оптимизации для кластеризованного индекса columnstore, как описано ранее, все еще существуют.
Что такое тонкая вставка?
Тонкая вставка — это способ перемещения отдельных строк в индекс columnstore. Для тонких вставок используется инструкция INSERT INTO. При их использовании все строки попадают в deltastore. Это эффективно для небольшого числа строк и совсем непрактично для больших загрузок.
INSERT INTO [<table-name>] VALUES ('some value' /*replace with actual set of values*/)
Примечание.
Следует отметить, что параллельные потоки, выполняемые с помощью инструкции INSERT INTO для вставки значений в кластеризованный индекс columnstore, могут вставлять строки в одну и ту же группу строк deltastore.
После того как группа строк содержит 1048 576 строк, разностная группа строк, помеченная как закрытая, но она по-прежнему доступна для запросов и операций обновления и удаления, но вновь вставленные строки попадают в существующую или только что созданную группу строк deltastore. Существует фоновый поток Кортежа Mover (TM), который сжимает закрытые разностные группы строк периодически каждые 5 минут. Вы можете явно вызвать следующую команду, чтобы сжать закрытую разностную группу строк.
ALTER INDEX [<index-name>] on [<table-name>] REORGANIZE
Если вы хотите принудительно закрыть и сжать разностную группу строк, можно выполнить следующую команду. Вы можете выполнить эту команду, если вы закончите загрузку строк и не ожидаете новых строк. Благодаря явному закрытию и сжатию разностной группы строк можно экономить место в хранилище и повышать производительность аналитических запросов. Эту команду рекомендуется использовать, если вставка новых строк не нужна.
ALTER INDEX [<index-name>] on [<table-name>] REORGANIZE with (COMPRESS_ALL_ROW_GROUPS = ON)
Как работает загрузка в секционированную таблицу
Для секционированных данных SQL Server сначала назначает каждую строку секции, а затем выполняет операции columnstore с данными в разделе. Каждая секция содержит собственные группы строк, а также как минимум одну разностную группу строк.
Следующие шаги
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по