Кучи (таблицы без кластеризованных индексов)
Применимо к:![]() SQL Server
SQL Server![]() База данных SQL Azure Управляемый экземпляр SQL Azure
База данных SQL Azure Управляемый экземпляр SQL Azure![]()
Кучей является таблица без кластеризованного индекса. Для таблиц, сохраненных как куча, может быть создан один или несколько некластеризованных индексов. Данные хранятся в куче без указания порядка. Обычно данные изначально хранятся в порядке вставки строк. Однако ядро СУБД может перемещать данные в куче, чтобы эффективно хранить строки. В результатах запроса невозможно предсказать порядок данных. Чтобы гарантировать порядок строк, возвращаемых из кучи, используйте ORDER BY предложение. Чтобы указать постоянный логический порядок хранения строк, создайте кластеризованный индекс для таблицы, чтобы таблица не была кучей.
Примечание.
Иногда бывают достаточные основания для того, чтобы оставить таблицу в виде кучи, не создавая кластеризованный индекс, однако эффективное использование куч требует высокой квалификации. Большинству таблиц следует создать кластеризованный индекс, если не существует веских оснований, чтобы оставить таблицу в виде кучи.
Когда следует использовать кучу
Куча идеально подходит для таблиц, которые часто усечены и перезагружаются. Ядро СУБД оптимизирует пространство в куче, заполняя самое раннее доступное пространство.
Рассмотрим следующий пример.
- Поиск свободного места в куче может быть дорогостоящим, особенно если было много удалений или обновлений.
- Кластеризованные индексы обеспечивают устойчивую производительность для таблиц, которые не часто усечены.
Для таблиц, которые регулярно усечены или повторно создаются, например временные или промежуточные таблицы, использование кучи часто более эффективно.
Выбор между использованием кучи и кластеризованным индексом может значительно повлиять на производительность и эффективность базы данных.
Если таблица сохранена как куча, отдельные строки идентифицируются по ссылке на 8-байтовый идентификатор строки (RID), состоящий из номера файла, номера страницы данных и слота на странице (FileID:PageID:SlotID). Идентификатор строки является небольшой и эффективной структурой.
Кучи можно использовать в качестве промежуточных таблиц для больших неупорядоченных операций вставки. Поскольку данные вставляются без применения строгого порядка, операция вставки обычно выполняется быстрее, чем эквивалентная вставка в кластеризованный индекс. Если данные кучи будут считываться и обрабатываться в окончательном назначении, может быть полезно создать узкий некластеризованный индекс, охватывающий предикат поиска, используемый запросом.
Примечание.
Данные извлекаются из кучи в порядке страниц данных, но не обязательно в порядке вставки данных.
Иногда специалисты данных используют кучи, если доступ к данным осуществляется только через некластеризованные индексы, а идентификатор RID меньше ключа кластеризованного индекса.
Если таблица является кучей и не имеет некластеризованных индексов, требуется прочитать всю таблицу (выполнить сканирование таблицы), чтобы найти любую строку. SQL Server не может искать RID непосредственно в куче. Это поведение может быть приемлемым, если таблица небольшая.
Если не использовать кучу
Не следует использовать кучу, если данные часто возвращаются в отсортированном порядке. Кластеризованный индекс для столбца сортировки поможет избежать операции сортировки.
Не используйте кучу для часто группируемых данных. Данные необходимо сортировать перед группировкой, и кластеризованный индекс для столбца сортировки поможет избежать операции сортировки.
Не следует использовать кучу, когда из таблицы часто запрашиваются диапазоны данных. Кластеризованный индекс в столбце диапазона не позволяет сортировать всю кучу.
Не используйте кучу, если некластеризованные индексы отсутствуют, а таблица большая. Единственное приложение для этого дизайна заключается в возврате всего содержимого таблицы без указанного порядка. В куче ядро СУБД считывает все строки, чтобы найти любую строку.
Не используйте кучу, если данные часто обновляются. Если вы изменяете запись и обновление занимает больше места на страницах данных, чем текущая версия, запись должна быть перемещена на страницу данных, имеющую достаточно свободного места. При этом создается перенаправленная запись, указывающая на новое расположение данных, и указатель перенаправления должен быть записан на странице, где раньше находились данные, чтобы указать новое физическое расположение. Это приводит к фрагментации в куче. Когда ядро СУБД сканирует кучу, она следует этим указателям. Это действие ограничивает производительность операций чтения и может повлечь за собой дополнительные операции ввода-вывода, что снижает производительность сканирования.
Управление кучами
Чтобы создать кучу, создайте таблицу без кластеризованного индекса. Если в таблице уже содержится кластеризованный индекс, удалите кластеризованный индекс, чтобы преобразовать таблицу в кучу.
Чтобы удалить кучу, создайте кластеризованный индекс в ней.
Перестроение кучи для освобождения неиспользуемого пространства:
- Создайте в куче кластеризованный индекс, а затем удалите его.
- Используйте команду
ALTER TABLE ... REBUILDдля перестроения кучи.
Предупреждение
Создание или удаление кластеризованных индексов требует перезаписи всей таблицы. Если у таблицы есть некластеризованные индексы, то все они должны быть созданы повторно при каждом изменении кластеризованного индекса. Таким образом, для перехода с кучи на кластеризованный индекс и обратно может потребоваться продолжительное время и дополнительное место на диске — для переупорядочения данных в базе данных tempdb.
Определение куч
Следующий запрос возвращает список куч из текущей базы данных. Этот список содержит следующие параметры:
- Имена таблиц
- Имена схем
- Число строк
- Размер таблицы в КБ
- Размер индекса в КБ
- Неиспользуемое пространство
- Столбец для идентификации кучы
SELECT t.name AS 'Your TableName',
s.name AS 'Your SchemaName',
p.rows AS 'Number of Rows in Your Table',
SUM(a.total_pages) * 8 AS 'Total Space of Your Table (KB)',
SUM(a.used_pages) * 8 AS 'Used Space of Your Table (KB)',
(SUM(a.total_pages) - SUM(a.used_pages)) * 8 AS 'Unused Space of Your Table (KB)',
CASE
WHEN i.index_id = 0
THEN 'Yes'
ELSE 'No'
END AS 'Is Your Table a Heap?'
FROM sys.tables t
INNER JOIN sys.indexes i
ON t.object_id = i.object_id
INNER JOIN sys.partitions p
ON i.object_id = p.object_id
AND i.index_id = p.index_id
INNER JOIN sys.allocation_units a
ON p.partition_id = a.container_id
LEFT JOIN sys.schemas s
ON t.schema_id = s.schema_id
WHERE i.index_id <= 1 -- 0 for Heap, 1 for Clustered Index
GROUP BY t.name,
s.name,
i.index_id,
p.rows
ORDER BY 'Your TableName';
Структуры кучи
Кучей является таблица без кластеризованного индекса. Для каждой кучи существует одна строка в представлении sys.partitionsс index_id = 0 для каждой секции, используемой кучей. По умолчанию у кучи есть одна секция. Если куча имеет несколько секций, каждая из них имеет структуру кучи, содержащую данные для этой определенной секции. Например, если у кучи четыре секции, имеются четыре структуры кучи, по одной на каждую секцию.
В зависимости от типов данных в куче, каждая структура кучи имеет одну или несколько единиц распределения для хранения и управления данными определенной секции. У каждой кучи есть не менее одной единицы распределения IN_ROW_DATA на каждую секцию. У кучи также будет одна единица распределения LOB_DATA на каждую секцию, если в этой секции есть столбцы больших объектов (LOB). Кроме того, для хранения строк переменной длины, превышающих ограничение на размер строки, равное 8060 байтам, для каждой секции требуется одна единица распределения ROW_OVERFLOW_DATA .
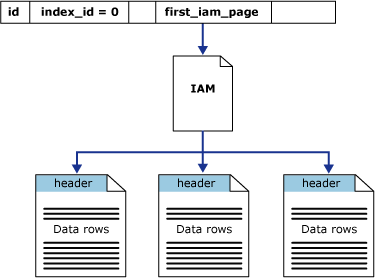
Столбец first_iam_page в системном представлении sys.system_internals_allocation_units указывает на первую IAM-страницу в цепочке IAM-страниц, которые управляют пространством, выделенным для кучи в определенной секции. SQL Server использует страницы IAM для перемещения по куче. Страницы данных и строки в этих страницах не расположены в каком-либо порядке и не связаны. Единственным логическим соединением страниц данных являются данные, записанные в IAM-страницы.
Внимание
Системное sys.system_internals_allocation_units представление зарезервировано только для внутреннего использования SQL Server. Совместимость с будущими версиями не гарантируется.
Просмотр таблиц или последовательное считывание в куче может выполняться просмотром IAM-страниц для нахождения экстентов, хранящих страницы кучи. Так как карта IAM представляет экстенты в том же порядке, в котором они существуют в файлах данных, это означает, что последовательный просмотр кучи выполняется последовательно в каждом файле. Использование IAM-страниц для определения последовательности просмотра означает также, что строки из кучи обычно возвращаются не в том порядке, в котором они вставлялись.
На следующей иллюстрации демонстрируется, как ядро СУБД SQL Server использует IAM-страницы для получения строк данных из кучи с одной секцией.
См. также
Инструкция CREATE INDEX (Transact-SQL)
DROP INDEX (Transact-SQL)
Описание кластеризованных и некластеризованных индексов
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по