Индексирование данных JSON
Область применения:![]() SQL Server 2016 (13.x) и более поздних
SQL Server 2016 (13.x) и более поздних ![]() версий База данных SQL Azure Управляемый экземпляр SQL Azure
версий База данных SQL Azure Управляемый экземпляр SQL Azure ![]()
Вы можете оптимизировать запросы по документам JSON с помощью стандартных индексов. В SQL Server нет пользовательских индексов JSON.
- В настоящее время в JSON SQL Server не является встроенным типом данных.
- В настоящее время тип данных JSON доступен в База данных SQL Azure.
Индексы работают так же, как данные JSON в varchar nvarchar/ или собственный тип данных JSON.
Индексы баз данных делают операции фильтрации и сортировки более эффективными. Без индексов SQL Server пришлось бы сканировать всю таблицу при каждом запросе данных.
Индексация свойств JSON с помощью вычисляемых столбцов
При хранении данных JSON в SQL Server результаты запросов обычно нужно фильтровать или сортировать по одному или нескольким свойствам документов JSON.
Пример
В этом примере предположим, что AdventureWorks.SalesOrderHeader в таблице есть Info столбец, содержащий различные сведения в формате JSON о заказах на продажу. Например, он содержит неструктурированные данные о клиенте и менеджере по продажам, адреса доставки и выставления счетов и т. д. Значения из столбца Info можно использовать для фильтрования заказов на продажу по клиентам.
По умолчанию используемый столбец Info не существует, его можно создать в базе данных AdventureWorks, используя следующий код. В следующих примерах не применяется AdventureWorksLT ряд примеров баз данных.
IF NOT EXISTS(SELECT * FROM sys.columns WHERE object_id = OBJECT_ID('[Sales].[SalesOrderHeader]') AND name = 'Info')
ALTER TABLE [Sales].[SalesOrderHeader] ADD [Info] NVARCHAR(MAX) NULL
GO
UPDATE h
SET [Info] =
(
SELECT [Customer.Name] = concat(p.FirstName, N' ', p.LastName),
[Customer.ID] = p.BusinessEntityID,
[Customer.Type] = p.[PersonType],
[Order.ID] = soh.SalesOrderID,
[Order.Number] = soh.SalesOrderNumber,
[Order.CreationData] = soh.OrderDate,
[Order.TotalDue] = soh.TotalDue
FROM [Sales].SalesOrderHeader AS soh
INNER JOIN [Sales].[Customer] AS c ON c.CustomerID = soh.CustomerID
INNER JOIN [Person].[Person] AS p ON p.BusinessEntityID = c.CustomerID
WHERE soh.SalesOrderID = h.SalesOrderID FOR JSON PATH, WITHOUT_ARRAY_WRAPPER
)
FROM [Sales].SalesOrderHeader AS h;
Запрос оптимизации
С помощью индекса можно оптимизировать запросы, например, указанного ниже типа.
SELECT SalesOrderNumber,
OrderDate,
JSON_VALUE(Info, '$.Customer.Name') AS CustomerName
FROM Sales.SalesOrderHeader
WHERE JSON_VALUE(Info, '$.Customer.Name') = N'Aaron Campbell'
Пример индекса
Чтобы ускорить применение фильтров или предложений ORDER BY к свойству в документе JSON, можно применить те же индексы, которые уже используются в других столбцах. При этом напрямую на свойства в документах JSON ссылаться нельзя.
- Сначала создайте "виртуальный столбец", который возвращает значения, которые необходимо использовать для фильтрации.
- Затем создайте индекс в этом виртуальном столбце.
В следующем примере создается вычисляемый столбец, который можно использовать для индексирования. Затем в новом вычисляемом столбце создается индекс. В этом примере создается столбец, содержащий имя клиента, которое хранится в документах JSON по пути $.Customer.Name.
ALTER TABLE Sales.SalesOrderHeader
ADD vCustomerName AS JSON_VALUE(Info,'$.Customer.Name')
CREATE INDEX idx_soh_json_CustomerName
ON Sales.SalesOrderHeader(vCustomerName)
Этот оператор возвращает следующее предупреждение:
Warning! The maximum key length for a nonclustered index is 1700 bytes.
The index 'vCustomerName' has maximum length of 8000 bytes.
For some combination of large values, the insert/update operation will fail.
Функция JSON_VALUE может возвращать текстовые значения до 8000 байт (например, как тип nvarchar(4000). При этом проиндексировать значения, превышающие 1700 байт, нельзя. Если вы пытаетесь ввести значение в индексированном вычисляемом столбце, превышающем 1700 байт, операция языка обработки данных (DML) завершится ошибкой.
Для повышения производительности попробуйте привести значение, которое вы предоставляете с помощью вычисляемого столбца в наименьший применимый тип данных. Используйте типы int и datetime2 вместо строковых типов.
Дополнительные сведения о вычисляемых столбцах
Вычисляемый столбец не сохраняется. Столбец компьютера, вычисляемый только при перестроении индекса. и не занимает дополнительное место в таблице.
Вычисляемый столбец необходимо создавать с тем же выражением, которое вы планируете использовать в запросах — в данном случае выражение JSON_VALUE(Info, '$.Customer.Name').
Запросы переписывать не нужно. Если выражения используются с функцией JSON_VALUE, как показано в предыдущем примере запроса, SQL Server определяет наличие эквивалентного вычисляемого столбца с тем же выражением и по возможности применяет индекс.
План выполнения для этого примера
Вот план выполнения запроса в этом примере:
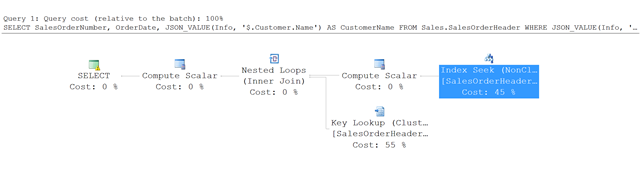
Вместо полного табличного сканирования SQL Server применяет оператор Index Seek к некластеризованному индексу и выявляет строки, отвечающие указанным условиям. Затем он выполняет поиск ключей по таблице SalesOrderHeader, чтобы получить другие указанные в запросе столбцы — в этом примере это столбцы SalesOrderNumber и OrderDate.
Дополнительная оптимизация индекса с включенными столбцами
При добавлении требуемых столбцов в индекс такого дополнительного поиска по таблице можно избежать. Эти столбцы можно добавить как стандартные включенные столбцы, как показано в следующем примере, дополняющем предыдущий пример CREATE INDEX.
CREATE INDEX idx_soh_json_CustomerName
ON Sales.SalesOrderHeader(vCustomerName)
INCLUDE(SalesOrderNumber,OrderDate)
В этом случае SQL Server не должен считывать дополнительные данные из SalesOrderHeader таблицы, так как все необходимые данные включены в некластеризованный индекс JSON. Этот тип индекса является хорошим способом объединения данных JSON и столбцов в запросах и создания оптимальных индексов для вашей рабочей нагрузки.
Индексы JSON — это индексы с учетом сортировки
Важной особенностью индексов на основе JSON является то, что эти индексы учитывают параметры сортировки. Результатом выполнения функции JSON_VALUE, которая применяется при создании вычисляемого столбца, является текстовое значение, которое наследует параметры сортировки из входного выражения. Таким образом, значения в индексе упорядочиваются согласно правилам сортировки, определенным в исходных столбцах.
Чтобы продемонстрировать, что индексы учитывают параметры сортировки, в следующем примере создается простая таблица коллекций с первичным ключом и данными в формате JSON.
CREATE TABLE JsonCollection
(
id INT IDENTITY CONSTRAINT PK_JSON_ID PRIMARY KEY,
[json] NVARCHAR(MAX) COLLATE SERBIAN_CYRILLIC_100_CI_AI
CONSTRAINT [Content should be formatted as JSON]
CHECK(ISJSON(json)>0)
)
Предыдущая команда указывает сербский кириллический параметры сортировки для столбца json . В следующем примере таблица заполняется и создается индекс по свойству name.
INSERT INTO JsonCollection
VALUES
(N'{"name":"Иво","surname":"Андрић"}'),
(N'{"name":"Андрија","surname":"Герић"}'),
(N'{"name":"Владе","surname":"Дивац"}'),
(N'{"name":"Новак","surname":"Ђоковић"}'),
(N'{"name":"Предраг","surname":"Стојаковић"}'),
(N'{"name":"Михајло","surname":"Пупин"}'),
(N'{"name":"Борислав","surname":"Станковић"}'),
(N'{"name":"Владимир","surname":"Грбић"}'),
(N'{"name":"Жарко","surname":"Паспаљ"}'),
(N'{"name":"Дејан","surname":"Бодирога"}'),
(N'{"name":"Ђорђе","surname":"Вајферт"}'),
(N'{"name":"Горан","surname":"Бреговић"}'),
(N'{"name":"Милутин","surname":"Миланковић"}'),
(N'{"name":"Никола","surname":"Тесла"}')
GO
ALTER TABLE JsonCollection
ADD vName AS JSON_VALUE(json,'$.name')
CREATE INDEX idx_name
ON JsonCollection(vName)
Указанные выше команды создают стандартный индекс по значению vName вычисляемого столбца, которое соответствует свойству $.name. На сербской кириллической кодовой странице порядок букв : А, ВБ, , ГД, Ђ, Еи т. д. Порядок элементов в индексе соответствует сербским правилам кириллицы, так как результат JSON_VALUE функции наследует его параметры сортировки от исходного столбца. Следующий пример запрашивает эту коллекцию и сортирует результаты по имени.
SELECT JSON_VALUE(json,'$.name'),*
FROM JsonCollection
ORDER BY JSON_VALUE(json,'$.name')
Если посмотреть на фактический план выполнения, можно увидеть, что в нем используются отсортированные значения из некластеризованного индекса.

Несмотря на то что запрос содержит предложение ORDER BY, в плане выполнения не используется оператор Sort. Индекс JSON уже упорядочен по правилам сербской кириллицы. В связи с этим SQL Server может использовать некластеризованный индекс, в котором результаты уже отсортированы.
Но если порядок сортировки по выражению ORDER BY изменить, например добавить COLLATE French_100_CI_AS_SC после функции JSON_VALUE, план выполнения запроса станет совершенно иным.

Поскольку порядок значений в индексе не соответствует правилам сортировки для французского языка, SQL Server не может использовать этот индекс для упорядочивания результатов. В связи с этим он добавляет оператор Sort, который сортирует результаты по правилам сортировки для французского языка.
Видео Майкрософт
Примечание.
Некоторые ссылки на видео в этом разделе могут не работать в настоящее время. Корпорация Майкрософт переносит содержимое, которое ранее транслировалось канале Channel 9, на новую платформу. Мы будем обновлять ссылки по мере переноса видео на новую платформу.
Наглядные инструкции по встроенной поддержке JSON в SQL Server и базе данных SQL Azure см. в следующих видео.
- JSON as a bridge between NoSQL and relational worlds (JSON как мост между NoSQL и реляционными решениями)
Связанный контент
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по