Соединения (SQL Server)
Применимо: ![]() SQL Server
SQL Server ![]() База данных SQL Azure Управляемый экземпляр SQL Azure
База данных SQL Azure Управляемый экземпляр SQL Azure![]()
![]() azure Synapse Analytics Analytics
azure Synapse Analytics Analytics ![]() Platform System (PDW)
Platform System (PDW)
SQL Server выполняет операции сортировки, взаимодействия, объединения и разности с помощью технологии сортировки и хэш-соединения в памяти. С помощью этого типа плана запросов SQL Server поддерживает секционирование вертикальных таблиц.
SQL Server реализует операции логического соединения, как определено синтаксисом Transact-SQL:
- внутреннее соединение,
- левое внешнее соединение.
- Правое внешнее соединение
- Полное внешнее соединение
- Перекрестное соединение
Примечание.
Дополнительные сведения о синтаксисе соединения см. в разделе Предложение FROM и JOIN, APPLY, PIVOT (Transact-SQL).
SQL Server использует четыре типа операций физического соединения для выполнения операций логического соединения:
- Соединения вложенных циклов
- Соединения слиянием.
- Хэш-соединения.
- Адаптивные соединения (начиная с SQL Server 2017 (14.x))
Основные принципы присоединения
С помощью соединения можно получать данные из двух или нескольких таблиц на основе логических связей между ними. Соединения указывают, как SQL Server должен использовать данные из одной таблицы для выбора строк в другой таблице.
Соединение определяет способ связывания двух таблиц в запросе следующим образом:
- для каждой таблицы указываются столбцы, используемые в соединении. В типичном условии соединения указывается внешний ключ из одной таблицы и связанный с ним ключ из другой таблицы;
- Указывается логический оператор (например, = или <>), используемый для сравнения значений из столбцов.
Соединения выражаются логически с помощью следующего синтаксиса Transact-SQL:
- ВНУТРЕННЕЕ СОЕДИНЕНИЕ
- LEFT [ OUTER ] JOIN
- RIGHT [ OUTER ] JOIN
- FULL [ OUTER ] JOIN
- CROSS JOIN
Внутренние соединения можно задавать в предложениях FROM и WHERE. Внешние соединения и перекрестные соединения можно задавать только в предложении FROM. Условия соединения сочетаются с условиями поиска WHERE и HAVING для управления строками, выбранными из базовых таблиц, на которые ссылается предложение FROM.
Указание условий соединения в FROM предложении помогает отделять их от других условий поиска, которые могут быть указаны в WHERE предложении, и это рекомендуемый метод для указания соединений. Ниже приведен упрощенный синтаксис соединения с использованием предложения FROM стандарта ISO:
FROM first_table < join_type > second_table [ ON ( join_condition ) ]
- Join_type указывает, какой тип соединения выполняется: внутреннее, внешнее или перекрестное соединение. Описание различных типов соединений см . в предложении FROM.
- Join_condition определяет предикат для каждой пары присоединенных строк.
Следующий код является примером FROM спецификации соединения предложения:
FROM Purchasing.ProductVendor INNER JOIN Purchasing.Vendor
ON ( ProductVendor.BusinessEntityID = Vendor.BusinessEntityID )
Следующий код представляет собой простую SELECT инструкцию с помощью этого соединения:
SELECT ProductID, Purchasing.Vendor.BusinessEntityID, Name
FROM Purchasing.ProductVendor INNER JOIN Purchasing.Vendor
ON (Purchasing.ProductVendor.BusinessEntityID = Purchasing.Vendor.BusinessEntityID)
WHERE StandardPrice > $10
AND Name LIKE N'F%';
GO
Инструкция SELECT возвращает наименование продукта и сведения о поставщике для всех сочетаний запчастей, поставляемых компаниями с названиями на букву F и стоимостью продукта более 10 долларов.
Если один запрос содержит ссылки на несколько таблиц, то все ссылки столбцов должны быть однозначными. В предыдущем примере как таблица ProductVendor, так и таблица Vendor содержат столбец с именем BusinessEntityID. Имена столбцов, совпадающие в двух или более таблицах, на которые ссылается запрос, должны уточняться именем таблицы. Все ссылки на столбец Vendor в этом примере являются полными.
Если имя столбца не дублируется в двух или более таблицах, указанных в запросе, то ссылки на него уточнять именем таблицы не обязательно. Это показано в предыдущем примере. Подобное предложение SELECT иногда трудно понять, поскольку в нем нет ничего, что указывало бы на таблицы, из которых берутся столбцы. Запрос гораздо легче читать, если все столбцы указаны с именами соответствующих таблиц. Запрос будет читаться еще легче, если используются псевдонимы таблиц, особенно когда имена таблиц сами должны уточняться именами базы данных и владельца. Следующий код является тем же примером, за исключением того, что псевдонимы таблицы были назначены, а столбцы, квалифицированные с псевдонимами таблицы, чтобы повысить удобочитаемость:
SELECT pv.ProductID, v.BusinessEntityID, v.Name
FROM Purchasing.ProductVendor AS pv
INNER JOIN Purchasing.Vendor AS v
ON (pv.BusinessEntityID = v.BusinessEntityID)
WHERE StandardPrice > $10
AND Name LIKE N'F%';
В предыдущем примере условие соединения задается в предложении FROM, что является рекомендуемым способом. В следующем запросе это же условие соединения указывается в предложении WHERE:
SELECT pv.ProductID, v.BusinessEntityID, v.Name
FROM Purchasing.ProductVendor AS pv, Purchasing.Vendor AS v
WHERE pv.BusinessEntityID=v.BusinessEntityID
AND StandardPrice > $10
AND Name LIKE N'F%';
Список SELECT для соединения может ссылаться на все столбцы в соединяемых таблицах или на любое подмножество этих столбцов. Список SELECT не обязательно должен содержать столбцы из каждой таблицы в соединении. Например, в соединении из трех таблиц связующим звеном между одной из таблиц и третьей таблицей может быть только одна таблица, при этом список выборки не обязательно должен ссылаться на столбцы средней таблицы. Это так называемое антиполусоединение.
Хотя обычно в условиях соединения для сравнения используется оператор равенства (=), можно указать другие операторы сравнения или реляционные операторы, равно как другие предикаты. Дополнительные сведения см. в статьях "Операторы сравнения" (Transact-SQL) и WHERE (Transact-SQL).
При присоединении к SQL Server оптимизатор запросов выбирает наиболее эффективный метод (из нескольких возможностей) обработки соединения. Это включает выбор наиболее эффективного типа физического соединения, порядок объединения таблиц и даже использование типов операций логического соединения, которые нельзя выразить напрямую с помощью синтаксиса Transact-SQL, например полусоединения и анти-полусоединения. При физическом выполнении различных соединений можно использовать много разных оптимизаций, поэтому их нельзя надежно прогнозировать. Дополнительные сведения о полусоединениях и антиполусоединениях см. в справочнике по логическим и физическим операторам Showplan.
Столбцы, используемые в условии соединения, не обязательно должны иметь одинаковые имена или одинаковый тип данных. Однако если типы данных не совпадают, то они должны быть совместимыми или допускать в SQL Server неявное преобразование. Если типы данных не допускают неявное преобразование, то условия соединения должны явно преобразовывать эти типы данных с помощью функции CAST. Дополнительные сведения о неявных и явных преобразованиях см. в разделе "Преобразование типов данных" (ядро СУБД).
Большинство запросов, использующих соединение, можно переписать с помощью вложенных запросов и наоборот. Дополнительные сведения о вложенных запросах см. в разделе Вложенные запросы.
Примечание.
Таблицы невозможно соединять непосредственно по столбцам ntext, text или image. Однако соединить таблицы по столбцам ntext, text или image можно косвенно, с помощью SUBSTRING.
Например, SELECT * FROM t1 JOIN t2 ON SUBSTRING(t1.textcolumn, 1, 20) = SUBSTRING(t2.textcolumn, 1, 20) выполняет двух табличное внутреннее соединение на первых 20 символов каждого текстового столбца в таблицах t1 и t2.
Другая возможность сравнения столбцов ntext и text из двух таблиц заключается в сравнении длины столбцов с предложением WHERE, например: WHERE DATALENGTH(p1.pr_info) = DATALENGTH(p2.pr_info)
Общие сведения о соединениях вложенных циклов
Если один вход соединения имеет небольшой размер (менее десяти строк), а другой вход сравнительно большой и индексирован по соединяемым столбцам, индексное соединение вложенных циклов является самой быстрой операцией соединения, так как для нее потребуется наименьшее количество операций сравнения и ввода-вывода.
Соединение вложенных циклов, называемое также вложенной итерацией, использует один ввод соединения в качестве внешней входной таблицы (на графической схеме выполнения она является верхним входом), а второй в качестве внутренней (нижней) входной таблицы. Внешний цикл использует внешнюю входную таблицу построчно. Во внутреннем цикле для каждой внешней строки производится сканирование внутренней входной таблицы и вывод совпадающих строк.
В простейшем случае во время поиска целиком просматривается таблица или индекс; это называется упрощенным соединением вложенных циклов. Если при поиске используется индекс, то такой поиск называется индексным соединением вложенных циклов. Если индекс создается в качестве части плана запроса (и уничтожается после завершения запроса), то он называется временным индексным соединением вложенных циклов. Все эти варианты учитываются оптимизатором запросов.
Соединение вложенных циклов является особенно эффективным в случае, когда внешние входные данные сравнительно невелики, а внутренние входные данные велики и заранее индексированы. Во многих небольших транзакциях, работающих с небольшими наборами строк, индексное соединение вложенных циклов превосходит как соединения слиянием, так и хэш-соединения. Однако в больших запросах соединения вложенных циклов часто являются не лучшим вариантом.
Если для атрибута OPTIMIZED оператора соединения вложенными циклами задано значение True, это означает, что оптимизированные соединения вложенными циклами (или пакетная сортировка) используются для уменьшения количества операций ввода-вывода, когда внутренняя таблица имеет большой размер, независимо от того, выполняется ли ее параллельная обработка. Наличие этой оптимизации в данном плане может быть не очень очевидным при анализе плана выполнения, учитывая, что сама сортировка является скрытой операцией. Но при просмотре XML плана для атрибута OPTIMIZED это означает, что соединение вложенных циклов может попытаться изменить порядок входных строк для повышения производительности ввода-вывода.
Соединения слиянием.
Если два входа соединения достаточно велики, но отсортированы по соединяемым столбцам (например, если они были получены просмотром отсортированных индексов), то наиболее быстрой операцией соединения будет соединение слиянием. Если оба входа соединения велики и имеют сходные размеры, соединение слиянием с предварительной сортировкой и хэш-соединение имеют примерно одинаковую производительность. Однако операции хэш-соединения часто выполняются быстрее, если два входа значительно отличаются по размеру.
Соединение слиянием требует сортировки обоих наборов входных данных по столбцам слияния, которые определены предложениями равенства (ON) предиката объединения. Оптимизатор запросов обычно просматривает индекс, если для соответствующего набора столбцов такой существует, или устанавливает оператор сортировки под соединением слиянием. В редких случаях может быть несколько предложений равенства, но столбцы слияния взяты только из некоторых доступных предложений равенства.
Так как каждый набор входных данных сортируется, оператор Merge Join получает строку из каждого набора входных данных и сравнивает их. Например, для операций внутреннего соединения строки возвращаются в том случае, если они равны. Если они не равны, строка с меньшим значением не учитывается, и из этого набора входных данных берется другая строка. Этот процесс повторяется, пока не будет выполнена обработка всех строк.
Операция объединения слиянием — это обычная или многоуровневая операция. Соединение слиянием «многие ко многим» использует временную таблицу для хранения строк. При наличии повторяющихся значений из каждого входного элемента один из входных данных должен перемыкаться к началу дубликата по мере обработки каждого дубликата из другого ввода.
При наличии остаточного предиката все строки, удовлетворяющие предикату слияния, определяют остаточный предикат, и возвращаются только те строки, которые ему соответствуют.
Соединение слиянием — очень быстрая операция, но она может оказаться ресурсоемкой, если требуется выполнение операций сортировки. Однако если том данных имеет большой объем, и необходимые данные могут быть получены из существующих индексов сбалансированного дерева с выполненной предварительной сортировкой, соединение слиянием является самым быстрым из доступных алгоритмов соединения.
Хэш-соединения.
Хэш-соединения могут эффективно обрабатывать большие, несортированные и неиндексированные входы. Они полезны для получения промежуточных результатов в сложных запросах из-за следующего.
- Промежуточные результаты не индексированы (если только они явным образом не сохранены на диске, а затем проиндексированы) и часто отсортированы не так, как требуется для следующей операции в плане запроса.
- Оптимизаторы запросов оценивают только размеры промежуточных результатов. Так как для сложных запросов оценки могут быть очень неточны, алгоритмы обработки промежуточных результатов должны быть не только эффективными, но и правильно вырождаться, если объем промежуточных результатов оказался гораздо большим, чем ожидалось.
Хэш-соединение позволяет уменьшить денормализацию. Денормализация обычно используется для получения более высокой производительности при уменьшении количества операций соединения, несмотря на издержки, вызываемые избыточностью данных, например несогласованных обновлений. Хэш-соединения снижают потребность в денормализации и позволяют осуществлять вертикальное секционирование (представляющее группы столбцов, содержащиеся в одной таблице, в отдельных файлах или индексах) в качестве доступной возможности при реализации физической структуры базы данных.
Хэш-соединение имеет два входа: конструктивный и пробный. Оптимизатор запросов распределяет роли таким образом, при котором меньшему входу присваивается значение «конструктивный».
Хэш-соединения используются во многих операциях совпадающих множеств: внутреннее соединение; левое, правое и полное внешнее соединение; левое и правое полусоединение; пересечение; соединение; разность. Дополнительно модификация хэш-соединения применяется для двойного удаления и группирования, например SUM(salary) GROUP BY department. В указанной модификации используется общий вход как для конструктивной, так и для пробной ролей.
В представленных ниже разделах описываются различные типы хэш-соединений: хэш-соединения в памяти, поэтапные и рекурсивные хэш-соединения.
Хэш-соединение в памяти
Перед проведением хэш-соединения производится просмотр или вычисление входного конструктивного значения, а затем в памяти создается хэш-таблица. Каждая строка помещается в сегмент хэша согласно значению, вычисленному для хэш-ключа. В случае если конструктивное входное значение имеет размер, меньший объема доступной памяти, то все строки данных могут быть занесены в хэш-таблицу. После описанного конструктивного этапа предпринимается пробный этап. Производится построковое считывание или вычисление пробного входного значения, для каждой строки вычисляется значение хэш-ключа, затем происходит сканирование сегмента хэша и поиск совпадений.
Хэш-соединение грейс
Если размер конструктивного входного значения превышает максимально допустимый объем памяти, то хэш-соединение проводится в несколько шагов. Указанный процесс называется плавным хэш-соединением. Каждый шаг состоит из конструктивной и пробной частей. Исходные конструктивные и пробные входные данные разбиваются на несколько файлов (для этого используются хэш-функции ключей). При использовании хэш-функции для хэш-ключей обеспечивается гарантия нахождения соединяемых записей в общей паре файлов. Таким образом, задача соединения двух объемных входных значений разбивается на несколько более мелких задач. Затем хэш-соединение применяется к каждой паре разделенных файлов.
Рекурсивное хэш-соединение
Если объем информации, поступающей на конструктивный вход, настолько велик, что для использования обычного внешнего слияния требуется несколько уровней, то операцию разбиения необходимо проводить за несколько шагов на нескольких уровнях. Дополнительные шаги разбиения используются только для секций большого объема. Чтобы максимально ускорить проведение всех шагов разбиения, используются емкие асинхронные операции ввода-вывода, в результате чего один поток может занимать сразу несколько жестких дисков.
Примечание.
В случае незначительного превышения допустимого объема памяти конструктивными входными данными происходит совмещение элементов хэш-соединения в памяти и поэтапных хэш-соединений в общий этап. В результате получается гибридное хэш-соединение.
В процессе оптимизации не всегда удается определить тип используемого хэш-соединения. Поэтому в SQL Server в первую очередь используются хэш-соединения в памяти, а затем, в зависимости от объемов входной конструктивной информации, осуществляется переход на поэтапное или рекурсивное хэш-соединение.
В случае неверного определения конструктивного и пробного входов в оптимизаторе запросов их переключение осуществляется динамически. При использовании хэш-соединения осуществляется контроль использования меньшего файла в качестве конструктивного входа. Данная функция называется "переключением ролей". Переключение ролей происходит внутри хэш-соединения после сброса информации на диск.
Примечание.
Переключение ролей происходит независимо от указаний запроса или структуры запроса. Событие «переключение ролей» не отображается в плане запроса, и сообщение о нем выдается пользователю непосредственно после выполнения.
Хэш-спасение
Термин "аварийная остановка хэша" иногда используется для описания поэтапных и рекурсивных хэш-соединений.
Примечание.
Наличие рекурсивных хэш-соединений и аварийных остановок снижает производительность сервера. Если в трассировке содержится много "событий-предупреждений хэша", необходимо произвести обновление статистических данных соединяемых столбцов.
Дополнительные сведения об аварийных остановках хэша см. в разделе Класс событий Hash Warning.
Адаптивные соединения
Адаптивные соединения в пакетном режиме позволяют отложить выбор метода Хэш-соединение или Соединение вложенными цикламидо завершения сканирования первых входных данных. Оператор адаптивного соединения определяет пороговое значение, по которому принимается решение о переключении на план вложенного цикла. Таким образом, во время выполнения план запроса может динамически переключаться на более эффективную стратегию соединения без перекомпиляции.
Совет
Наиболее полезной эта функция будет для рабочих нагрузок с частыми переключениями между просмотрами входных данных мелких и крупных соединений.
Решение для среды выполнения зависит от следующего:
- Если число строк во входных данных соединения сборки настолько мало, что соединение вложенными циклами будет эффективнее хэш-соединения, план переключается на алгоритм вложенных циклов.
- Если число строк во входных данных соединения сборки превышает порог, переключение не выполняется и план продолжает использовать хэш-соединение.
Следующий запрос используется в качестве наглядного примера адаптивного соединения:
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity]
FROM [Fact].[Order] AS [fo]
INNER JOIN [Dimension].[Stock Item] AS [si]
ON [fo].[Stock Item Key] = [si].[Stock Item Key]
WHERE [fo].[Quantity] = 360;
Этот запрос возвращает 336 строк. Если включить функцию Статистика активных запросов, отобразится следующий план:

Обратите внимание на следующие моменты в плане:
- Просмотр индекса columnstore, используемый с целью предоставления строк для этапа сборки хэш-соединения.
- Новый оператор адаптивного соединения. Он определяет пороговое значение, по которому принимается решение о переключении на план вложенного цикла. В этом примере порог равен 78 строкам. Если число строк >= 78, будет использоваться хэш-соединение. Если значение меньше порога, будет использоваться соединение вложенными циклами.
- Так как запрос возвращает 336 строк, это превысило пороговое значение, поэтому вторая ветвь представляет этап проверки стандартной операции соединения хэша. Статистика динамических запросов показывает строки, поступающие через операторы, в этом случае —672 из 672.
- И последняя ветвь — поиск кластеризованного индекса, используемый соединением вложенными циклами, если порог не был превышен. Отображается 0 из 336 строк (ветвь неиспользуется).
Теперь контрастируйте план с тем же запросом, но если Quantity значение имеет только одну строку в таблице:
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity]
FROM [Fact].[Order] AS [fo]
INNER JOIN [Dimension].[Stock Item] AS [si]
ON [fo].[Stock Item Key] = [si].[Stock Item Key]
WHERE [fo].[Quantity] = 361;
Запрос возвращает одну строку. Если включить функцию "Статистика активных запросов", отобразится следующий план:
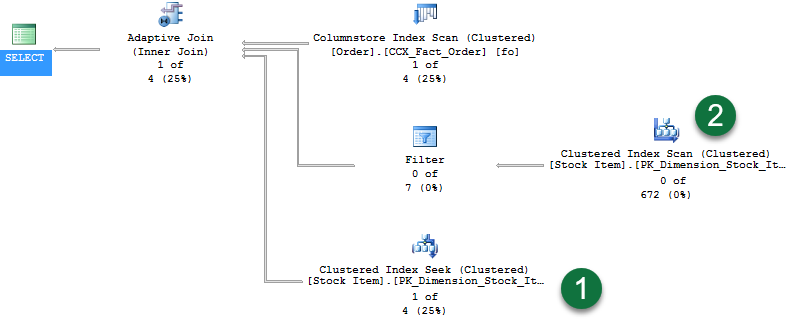
Обратите внимание на следующие моменты в плане:
- При возврате одной строки видно, что теперь через поиск кластеризованного индекса передаются строки.
- А так как этап сборки хэш-соединения не продолжается, никакие строки через вторую ветвь не передаются.
Примечания к адаптивным соединениям
Адаптивные соединения предъявляют более высокие требования к памяти, чем эквивалентный план соединения вложенными циклами индекса. Дополнительная память запрашивается так, как если бы вложенный цикл был хэш-соединением. Существуют также издержки на этапе сборки, такие как стартстопная операция и эквивалентное потоковое соединение вложенными циклами. При этом дополнительная стоимость обеспечивает гибкость в сценариях, когда количество строк изменяется в входных данных сборки.
Адаптивные соединения в пакетном режиме используются для первого выполнения инструкции. После компиляции последовательные выполнения остаются адаптивными с учетом порога скомпилированных адаптивных соединений и строк времени выполнения, передаваемых через этап сборки внешних входных данных.
Если адаптивное соединение переключается на режим вложенного цикла, оно использует строки, уже считанные сборкой хэш-соединения. Этот оператор не считывает повторно строки по внешней ссылке.
Отслеживание действия адаптивного соединения
Оператор адаптивного соединения имеет следующие атрибуты оператора плана:
| Атрибут плана | Description |
|---|---|
| AdaptiveThresholdRows | Показывает пороговое значение, используемое для переключения с хэш-соединения на соединение вложенными циклами. |
| EstimatedJoinType | К какому типу, вероятнее всего, относится соединение. |
| ActualJoinType | В фактическом плане показывает, какой итоговый алгоритм соединения был выбран на базе порогового значения. |
Предполагаемый план показывает форму плана адаптивного соединения, а также определенное пороговое значение адаптивного соединения и предполагаемый тип соединения.
Совет
Хранилище запросов захватывает и может принудительно применить план адаптивного соединения в пакетном режиме.
Допустимые инструкции адаптивного соединения
Чтобы логическое соединение стало допустимым для адаптивного соединения в пакетном режиме, должны выполняться следующие условия:
- Уровень совместимости базы данных имеет значение 140 или больше.
- Запрос является инструкцией
SELECT(инструкции для изменения данных сейчас недопустимы). - Соединение может выполняться посредством как индексированного соединения вложенными циклами, так и физического алгоритма хэш-соединения.
- Хэш-соединение использует пакетный режим, включенный через наличие индекса columnstore в запросе в целом, индексированную таблицу columnstore, на которую ссылается непосредственно соединение, или с помощью режима пакетной службы в rowstore.
- Созданные альтернативные решения соединения вложенными циклами и хэш-соединения должны иметь одинаковый первый дочерний элемент (внешняя ссылка).
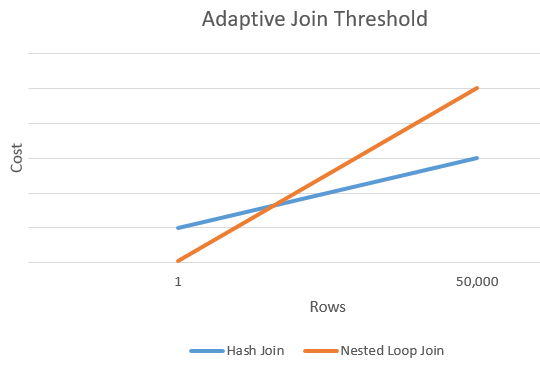
Строки адаптивного порогового значения
На приведенной ниже диаграмме показан пример пересечения между показателем затрат хэш-соединения и таким показателем альтернативного ему соединения вложенными циклами. В этой точке пересечения определяется пороговое значение, что, в свою очередь, определяет фактический алгоритм, используемый для операции соединения.
Отключение адаптивных соединений без изменения уровня совместимости
Адаптивные соединения можно отключить в области базы данных или инструкций, сохраняя уровень совместимости базы данных 140 и более поздних версий.
Чтобы отключить адаптивные соединения для всех запросов, поступающих из базы данных, выполните следующую команду в контексте соответствующей базы данных:
-- SQL Server 2017
ALTER DATABASE SCOPED CONFIGURATION SET DISABLE_BATCH_MODE_ADAPTIVE_JOINS = ON;
-- Azure SQL Database, SQL Server 2019 and later versions
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ADAPTIVE_JOINS = OFF;
Если этот параметр включен , этот параметр отображается в sys.database_scoped_configurations.
Чтобы снова включить адаптивные соединения для всех запросов, выполняемых из базы данных, выполните следующую команду в контексте соответствующей базы данных:
-- SQL Server 2017
ALTER DATABASE SCOPED CONFIGURATION SET DISABLE_BATCH_MODE_ADAPTIVE_JOINS = OFF;
-- Azure SQL Database, SQL Server 2019 and later versions
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ADAPTIVE_JOINS = ON;
Вы также можете отключить адаптивные соединения для определенного запроса, назначив DISABLE_BATCH_MODE_ADAPTIVE_JOINS в качестве указания запроса USE HINT. Рассмотрим пример.
SELECT s.CustomerID,
s.CustomerName,
sc.CustomerCategoryName
FROM Sales.Customers AS s
LEFT OUTER JOIN Sales.CustomerCategories AS sc
ON s.CustomerCategoryID = sc.CustomerCategoryID
OPTION (USE HINT('DISABLE_BATCH_MODE_ADAPTIVE_JOINS'));
Примечание.
Указание запроса USE HINT имеет приоритет над конфигурацией, областью действия которой является база данных, или флагом трассировки.
Значения NULL и соединения
Если в столбцах, по которым производится соединение таблиц, есть значение NULL, значения NULL друг с другом совпадать не будут. Наличие таких значений в столбце одной из соединяемых таблиц возможно только при использовании внешнего соединения (если только предложение WHERE не исключает значение NULL).
Ниже приведены две таблицы, которые содержатся NULL в столбце, который будет участвовать в соединении:
table1 table2
a b c d
------- ------ ------- ------
1 one NULL two
NULL three 4 four
4 join4
Соединение, которое сравнивает значения в столбце a с столбцами c , не получает совпадения по столбцам со значениями NULL:
SELECT *
FROM table1 t1 JOIN table2 t2
ON t1.a = t2.c
ORDER BY t1.a;
GO
Возвращается только одна строка со значением 4 в столбцахa:c
a b c d
----------- ------ ----------- ------
4 join4 4 four
(1 row(s) affected)
Значения NULL, возвращаемые из базовой таблицы, также сложно отличить от значений NULL, возвращаемых при внешнем соединении. Например, следующая инструкция SELECT выполняет левое внешнее соединение этих двух таблиц.
SELECT *
FROM table1 t1 LEFT OUTER JOIN table2 t2
ON t1.a = t2.c
ORDER BY t1.a;
GO
Результирующий набор:
a b c d
----------- ------ ----------- ------
NULL three NULL NULL
1 one NULL NULL
4 join4 4 four
(3 row(s) affected)
Результаты не позволяют легко различать NULL данные из NULL данных, которые представляют собой ошибку соединения. Если значения NULL присутствуют в присоединении к данным, обычно предпочтительнее опустить их из результатов с помощью регулярного соединения.