Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Применимо к:![]() SQL Server
SQL Server![]() Azure SQL База данных
Azure SQL База данных![]() Azure SQL Управляемый экземпляр
Azure SQL Управляемый экземпляр![]() SQL База данных в Microsoft Fabric
SQL База данных в Microsoft Fabric
Ядро СУБД SQL Server обрабатывает запросы к различным архитектурам хранения данных, таким как локальные таблицы, секционированные таблицы и таблицы, распределенные по нескольким серверам. В следующих разделах описывается, как SQL Server обрабатывает запросы и оптимизирует повторное использование запросов с помощью кэширования плана выполнения.
Режимы выполнения
Компонент SQL Server Database Engine может обрабатывать инструкции Transact-SQL в двух разных режимах:
- выполнение в построчном режиме;
- выполнение в пакетном режиме.
выполнение в построчном режиме;
Построчный режим выполнения — это метод обработки запросов, применяемый с традиционными таблицами RDBMS, при котором данные сохраняются в строковом формате. При выполнении запроса к данным в таблицах, хранящих строки, операторы дерева выполнения и дочерние операторы считывают каждую требуемую строку по всем столбцам, указанным в схеме таблицы. Из каждой считанной строки SQL Server затем извлекает столбцы, необходимые для результирующего набора, как указано в инструкции SELECT, предикате JOIN или предикате фильтрации.
Примечание.
Построчный режим выполнения очень эффективен в сценариях OLTP, но может быть не так эффективен при обращении к большим объемам данных, например при работе с хранилищем данных.
выполнение в пакетном режиме.
Пакетный режим выполнения — это метод обработки запросов, при котором обрабатываются сразу несколько строк (поэтому он и называется пакетным). Каждый столбец из пакета сохраняется как вектор в отдельной области памяти. Таким образом, обработка в пакетном режиме основана на векторах. Кроме того, при обработке в пакетном режиме применяются алгоритмы, оптимизированные для многоядерных ЦП и увеличенной пропускной способности памяти, что характерно для современного оборудования.
При первом появлении выполнение в пакетом режиме было тесно интегрировано и оптимизировано для взаимодействия с форматом хранения columnstore. Однако начиная с SQL Server 2019 (15.x) и в базе данных Azure SQL выполнение пакетного режима больше не требует индексов columnstore. Для получения дополнительной информации см. раздел Пакетный режим для rowstore.
Обработка в пакетном режиме применяется к сжатым данным, когда это возможно, и исключает необходимость применения оператора обмена, используемого в построчном режиме выполнения. Это позволяет повысить уровень параллелизма и производительность.
Когда запрос выполняется в пакетном режиме и получает доступ к данным в индексах columnstore, операторы дерева выполнения и дочерние операторы считывают сразу несколько строк по сегментам столбцов. SQL Server считывает только столбцы, необходимые для результата, как указано в инструкции SELECT, предикате JOIN или предикате фильтра. Дополнительные сведения об индексах columnstore см. в статье Архитектура индексов columnstore.
Примечание.
Пакетный режим выполнения очень эффективен в сценариях хранилищ данных, в которых считываются и вычисляются большие объемы данных.
Обработка инструкций SQL
Обработка одиночной инструкции Transact-SQL — наиболее распространенный способ, с помощью которого SQL Server выполняет инструкции Transact-SQL. Шаги, используемые для обработки одиночной инструкции SELECT , которая обращается только к таблицам локальной базы (а не к представлениям и не к удаленным таблицам), иллюстрируют основной процесс.
Приоритет логического оператора
При использовании в инструкции нескольких логических операторов первым вычисляется NOT, затем AND и, наконец, OR. Арифметические и побитовые операции выполняются до логических. Дополнительные сведения см. в разделе Приоритет операторов.
В приведенном ниже примере условие цвета относится к модели продукта 21, но не к модели продукта 20, так как условие AND имеет приоритет над условием OR.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR ProductModelID = 21
AND Color = 'Red';
GO
Можно изменить смысл запроса, добавив скобки, чтобы принудить вычисление OR сначала. В следующий запрос найдёт только продукты под моделями 20 и 21, которые красного цвета.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE (ProductModelID = 20 OR ProductModelID = 21)
AND Color = 'Red';
GO
С помощью скобок, даже если они не требуются, можно улучшить читаемость запросов и уменьшить вероятность совершения незаметной ошибки из-за приоритета операторов. Использование скобок практически не влияет на производительность. Следующий пример более понятен, чем исходный, хотя синтаксически они равноправны.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR (ProductModelID = 21
AND Color = 'Red');
GO
Оптимизация инструкций SELECT
Оператор SELECT не является процедурным; он не указывает точные шаги, которые сервер базы данных должен использовать для получения запрошенных данных. Это означает, что сервер базы данных должен проанализировать инструкцию для определения самого эффективного способа извлечения запрошенных данных. Это упоминается как оптимизация инструкции SELECT . Компонент, который делает это, называется оптимизатором запросов. Входные данные оптимизатора запросов включают сам запрос, схему базы данных (определения таблиц и индексов) и статистику базы данных. Выходные данные оптимизатора запросов — это план выполнения запроса, который иногда называется планом запроса или выполнения. Содержимое плана выполнения подробно описано далее в этой статье.
Входные и выходные данные оптимизатора запросов при оптимизации одиночной инструкции SELECT показаны на следующей схеме.
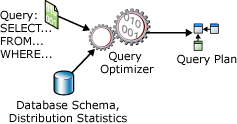
Инструкция SELECT определяет только следующее.
- Формат результирующего набора. Это указано главным образом в списке выбора. Однако другие предложения, например
ORDER BYиGROUP BY, также затрагивают конечную форму результирующего набора. - Таблицы, которые содержат исходные данные. Они указываются в предложении
FROM. - Как таблицы логически связаны для выполнения выражения
SELECT. Это определяется в спецификациях соединения, которые могут появляться в предложенииWHEREили в предложенииON, расположенном послеFROM. - Условия, которым строки в таблицах исходных данных должны соответствовать для квалификации по инструкции
SELECT. Они указываются в предложенияхWHEREиHAVING.
План выполнения запроса представляет собой определение следующего.
Последовательности, в которой происходит обращение к исходным таблицам.
Как правило, существует много последовательностей, в которых сервер базы данных может обращаться к базовым таблицам для построения результирующего набора. Например, если инструкцияSELECTссылается на три таблицы, сервер базы данных сначала может обратиться кTableA, использовать данные изTableAдля извлечения соответствующих строк изTableB, а затем использовать данные изTableBдля извлечения данных изTableC. Другие последовательности, в которых сервер базы данных может обращаться к таблицам:
TableC,TableB,TableAили
TableB,TableA,TableCили
TableB,TableC,TableAили
TableCTableATableBМетоды, используемые для извлечения данных из каждой таблицы.
Есть различные методы для обращения к данным в каждой таблице. Если необходимы только несколько строк с определенными ключевыми значениями, то сервер базы данных может использовать индекс. Если необходимы все строки в таблице, то сервер базы данных может пропустить индексы и выполнить просмотр таблицы. Если все строки таблицы необходимы, но есть индекс, ключевые столбцы которого находятся в объектеORDER BY, выполнение сканирования индекса вместо сканирования таблицы может сохранить отдельный тип результирующего набора. Если таблица очень мала, сканирование таблиц может быть наиболее эффективным методом почти для всех доступа к таблице.Методы, используемые для вычислений, а также фильтрации, статистической обработки и сортировки данных из каждой таблицы.
По мере доступа к данным из таблиц можно разными способами выполнять вычисления над данными (например, вычисления скалярных значений), а также статистическую обработку и сортировку данных, как определено в тексте запроса (например, при использовании предложенияGROUP BYилиORDER BY) и их фильтрацию (например, при использовании предложенияWHEREилиHAVING).
Процесс выбора одного плана выполнения из множества потенциально возможных планов называется оптимизацией. Оптимизатор запросов — один из важнейших компонентов ядра СУБД. Хотя для анализа запроса и выбора плана оптимизатору запросов требуются некоторые накладные расходы, эти накладные расходы обычно многократно окупаются, когда оптимизатор запроса выбирает эффективный план выполнения. Например, двум строительным компаниям могут быть предоставлены идентичные проекты дома. Если одна компания потратит сначала несколько дней на планирование того, как она будет строить дом, а другая компания начнет строить без планирования, то компания, которая потратит время на планирование проекта, вероятно, закончит первой.
Оптимизатор запросов SQL Server — это оптимизатор на основе затрат. Каждому возможному плану выполнения соответствует некоторая стоимость, определенная в терминах объема использованных вычислительных ресурсов. Оптимизатор запросов должен проанализировать возможные планы и выбрать тот, который имеет самую низкую предполагаемую стоимость. Для некоторых сложных инструкций SELECT есть тысячи возможных планов выполнения. В этих случаях оптимизатор запросов не анализирует все возможные сочетания. Вместо этого он использует сложные алгоритмы поиска плана выполнения, имеющего стоимость, близкую к минимальной возможной стоимости.
Оптимизатор запросов SQL Server не выбирает только план выполнения с наименьшей стоимостью ресурсов; Он выбирает план, который возвращает результаты пользователю с разумной стоимостью ресурсов и возвращает результаты быстрее. Например, параллельная обработка запроса обычно использует больше ресурсов, чем его последовательная обработка, но завершает выполнение запроса быстрее. Оптимизатор запросов SQL Server будет использовать параллельный план выполнения для возврата результатов, если нагрузка на сервер не будет негативно затронута.
Оптимизатор запросов SQL Server использует статистику распределения, когда оценивает затраты на ресурсы различных методов для извлечения информации из таблицы или индекса. Статистика распределения хранится для столбцов и индексов и содержит сведения о плотности 1 базовых данных. Она указывает избирательность значений в определенном индексе или столбце. Например, в таблице, представляющей автомобили, много автомобилей имеют одного производителя, но каждый автомобиль имеет уникальный идентификационный номер транспортного средства (VIN). Индекс по VIN более селективен, чем индекс по производителю, поскольку у VIN плотность меньше, чем у производителя. Если статистика индекса не является текущей, оптимизатор запросов может не сделать оптимальный выбор для текущего состояния таблицы. Дополнительные сведения о плотности см. в разделе Статистика.
1 Плотность определяет распределение уникальных значений в данных или среднее количество повторяющихся значений для данного столбца. По мере повышения плотности избирательность значения повышается.
Оптимизатор запросов SQL Server важен, так как он позволяет серверу базы данных динамически изменять условия в базе данных, не требуя ввода от программиста или администратора базы данных. Это дает возможность программистам сосредоточиться на описании конечного результата запроса. Они могут доверять тому, что оптимизатор запросов SQL Server создаст эффективный план выполнения для состояния базы данных при каждом запуске инструкции.
Примечание.
SQL Server Management Studio предоставляет три варианта отображения планов выполнения.
- *Предполагаемый план выполнения — это скомпилированный план, созданный оптимизатором запросов.
- Действительный план выполнения — это скомпилированный план с контекстом выполнения. Сюда входят сведения о среде выполнения, доступные после завершения выполнения, такие как предупреждения о выполнении, или в более новых версиях СУБД, затраченное и процессорное время, используемое при выполнении.
- Статистика активных запросов — это скомпилированный план с контекстом выполнения. Сюда входят сведения о времени выполнения, которые обновляются каждую секунду. Информация о времени выполнения включает, например, точное количество строк, проходящих через операторы.
Обработка запроса SELECT
Ниже представлены основные шаги, используемые SQL Server для обработки одиночной инструкции SELECT.
- Средство анализа просматривает инструкцию
SELECTи разбивает ее на логические единицы, такие как ключевые слова, выражения, операторы и идентификаторы. - Строится дерево запроса, иногда называемое деревом последовательности, с описанием логических шагов, необходимых для преобразования исходных данных в формат, требуемый результирующему набору.
- Оптимизатор запросов анализирует различные способы, с помощью которых можно обратиться к исходным таблицам. Затем он выбирает ряд шагов, которые возвращают результаты быстрее всего и используют меньше ресурсов. Дерево запроса обновляется для записи этого точного ряда шагов. Конечную, оптимизированную версию дерева запроса называют планом выполнения.
- Реляционный механизм начинает реализовывать план выполнения. В ходе обработки шагов, требующих данных из базовых таблиц, реляционный механизм запрашивает у подсистемы хранилища передачу данных из набора строк, указанных реляционным механизмом.
- Реляционный механизм преобразует данные, возвращенные подсистемой хранилища, в заданный для результирующего набора формат и возвращает результирующий набор клиенту.
Свертывание констант и оценка выражений
SQL Server оценивает некоторые константные выражения рано, чтобы повысить производительность запросов. Этот метод оптимизации, используемый оптимизатором запросов, направлен на упрощение выражений во время компиляции, а не во время выполнения. Он включает в себя оценку константных выражений во время компиляции запросов, чтобы итоговый план выполнения был более эффективным. Это называет сверткой констант. Константа — это литерал Transact-SQL, например3, 'ABC', '2005-12-31', 1.0e3 или 0x12345678. Например, выполните следующий запрос:
SELECT * FROM Orders WHERE OrderDate < DATEADD(day, 30 * 12, '2020-01-01');
Здесь 30 * 12 является константным выражением. SQL Server может оценить это во время компиляции и перезаписать запрос внутренне следующим образом:
SELECT * FROM Orders WHERE OrderDate < DATEADD(day, 360, '2020-01-01');
Свертываемые выражения
SQL Server использует константное свертывание со следующими типами выражений:
- Арифметические выражения, такие как
1 + 1и5 / 3 * 2, которые содержат только константы. - Логические выражения, такие как
1 = 1и1 > 2 AND 3 > 4, содержащие только константы. - Встроенные функции, которые считаются сворачиваемыми в SQL Server, включая
CASTиCONVERT. Обычно внутренняя функция является свертываемой, если это функция только своих входных данных, а не контекстуальных данных, таких как параметры SET, настройки языка, параметры базы данных, ключи шифрования. Недетерминированные функции не являются свертываемыми. Детерминированные встроенные функции являются свертываемыми за некоторыми исключениями. - Детерминированные методы определяемых пользователем типов CLR и детерминированные скалярные определяемые пользователем функции CLR (начиная с SQL Server 2012 (11.x)). Дополнительные сведения см. в разделе Свертка констант для определяемых пользователем функций и методов среды CLR.
Примечание.
Исключение делается для типов больших объектов. Если выходной тип процесса свертывания является большим типом объекта (text, ntext, image, nvarchar(max), varchar(max), varbinary(max) или XML), то SQL Server не сворачивает выражение.
Нескладываемые выражения
Все остальные типы выражения являются несвертываемыми. В частности, несвертываемыми являются следующие типы выражений:
- Неконстантные выражения, такие как выражение, результат которого зависит от значения столбца.
- Выражения, результат которых зависит от локальной переменной или параметра, такие как @x.
- Недетерминированные функции.
- Функции TransactSQL, определяемые пользователем1.
- Выражения, результат которых зависит от языковых настроек.
- Выражения, результат которых зависит от параметров SET.
- Выражения, результат которых зависит от параметров конфигурации сервера.
1 До SQL Server 2012 (11.x) детерминированные скалярные функции CLR, определяемые пользователем, и методы определяемых пользователем типов CLR не подлежали свёртыванию.
Примеры складываемых и нескладываемых константных выражений
Обратите внимание на следующий запрос:
SELECT *
FROM Sales.SalesOrderHeader AS s
INNER JOIN Sales.SalesOrderDetail AS d
ON s.SalesOrderID = d.SalesOrderID
WHERE TotalDue > 117.00 + 1000.00;
Если параметр базы данных PARAMETERIZATION для этого запроса не задан FORCED, то выражение 117.00 + 1000.00 вычисляется и заменяется его результатом 1117.00, до компиляции запроса. Такая свертка констант имеет следующие преимущества.
- Выражение не требуется многократно оценивать во время выполнения.
- Значение выражения после его вычисления используется оптимизатором запросов для оценки размера результирующего набора части запроса
TotalDue > 117.00 + 1000.00.
С другой стороны, если dbo.f - это пользовательская скалярная функция, выражение dbo.f(100) не свёрнуто, так как SQL Server не сворачивает выражения, включающие пользовательские функции, даже если они детерминированы. Дополнительные сведения о параметризации см. в разделе Принудительная параметризация далее в этой статье.
Вычисление выражения
Кроме того, некоторые выражения, которые не свертываются, но аргументы которых известны во время компиляции, где аргументы являются параметрами или постоянными, вычисляются механизмом оценки размера (количества элементов) набора результатов, который является частью оптимизатора во время оптимизации.
Во время компиляции вычисляются следующие встроенные функции и специальные операторы (если их входные данные известны): UPPER, LOWER, RTRIM, DATEPART( YY only ), GETDATE, CAST и CONVERT. Следующие операторы также вычисляются во время компиляции, если все входные данные известны:
- Арифметические операторы: +, -, *, /, unary -
- Логические операторы:
AND,ORиNOT - Операторы сравнения: <, >, <=, >=, <>,
LIKE,IS NULL,IS NOT NULL
Другие функции и операторы не оцениваются оптимизатором запросов при оценке кардинальности.
Примеры вычисления выражений во время компиляции
Рассмотрим следующую хранимую процедуру:
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc( @d datetime )
AS
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d+1;
Во время оптимизации инструкции SELECT в процедуре оптимизатор запросов пытается вычислить ожидаемую кратность результирующего набора для условия OrderDate > @d+1. Выражение @d+1 не является константным, так как @d является параметром. Однако во время оптимизации значение этого параметра известно. Это дает возможность оптимизатору запросов точно оценить размер результирующего набора, что поможет выбрать наилучший план запроса.
Теперь рассмотрим пример, похожий на предыдущий, за исключением того, что локальная переменная @d2 заменена в запросе выражением @d+1 и это выражение вычисляется в инструкции SET вместо вычисления в запросе.
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc2( @d datetime )
AS
BEGIN
DECLARE @d2 datetime
SET @d2 = @d+1
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d2
END;
SELECT Если инструкция оптимизирована в MyProc2 SQL Server, значение @d2 не известно. Поэтому в оптимизаторе запросов используется оценка по умолчанию для избирательности значений OrderDate > @d2 (в данном случае 30 %).
Обработка других инструкций
Основные шаги, описанные для обработки инструкции SELECT, применимы к другим инструкциям Transact-SQL, таким как INSERT, UPDATE и DELETE. Инструкции UPDATE и DELETE должны быть нацелены на набор строк, которые будут изменены или удалены. Идентификация этих строк выполняется так же, как и идентификация исходных строк, определяющих результирующий набор инструкции SELECT .
UPDATE и INSERT могут обе содержать внедренные SELECT инструкции, которые задают значения данных для обновления или вставки.
Даже инструкции языка описания данных (DDL), такие как CREATE PROCEDURE или ALTER TABLE, в конечном счете приводятся к ряду реляционных операций с таблицами системного каталога, а иногда (например, ALTER TABLE ADD COLUMN) с таблицами данных.
Рабочие таблицы
Реляционному движку может потребоваться создать рабочую таблицу для выполнения логической операции, указанной в инструкции Transact-SQL. Рабочие таблицы — это внутренние таблицы, предназначенные для хранения промежуточных результатов. Рабочие таблицы создаются для некоторых запросов GROUP BY, ORDER BY или UNION. Например, если ORDER BY предложение ссылается на столбцы, которые не охватываются никакими индексами, реляционному серверу может понадобиться создать рабочую таблицу для сортировки результирующего набора в порядке, запрошенном пользователем. Рабочие таблицы иногда также используются для временного хранения результатов выполнения части плана запроса. Рабочие таблицы создаются в базе данных tempdb , и когда они больше не нужны, автоматически удаляются.
Разрешение экрана
Обработчик запросов SQL Server обращается с индексированными и неиндексированными представлениями по-разному:
- Строки индексированного представления хранятся в базе данных в том же формате, что и таблица. Если оптимизатор запросов решает использовать индексированное представление в плане запроса, оно обрабатывается так же, как базовая таблица.
- В случае неиндексированного представления хранится только его определение, но не строки. Оптимизатор запросов интегрирует логику из определения представления в план выполнения, который создается для инструкции Transact-SQL, ссылающейся на неиндексированное представление.
Логика, используемая оптимизатором запросов SQL Server, позволяет решить, когда использовать индексированное представление, аналогично логике, используемой для выбора времени использования индекса в таблице. Если данные индексированного представления охватывают всю инструкцию Transact-SQL или ее часть, и оптимизатор запросов определит, что использовать индекс представления выгодно с точки зрения стоимости, он выберет индекс независимо от того, имеется ли в запросе ссылка на представление по имени.
Если инструкция Transact-SQL ссылается на неиндексированное представление, средство синтаксического анализа и оптимизатор запросов анализируют исходный код инструкции Transact-SQL и представления, разрешая их в один план выполнения. Для инструкции Transact-SQL нет одного плана и отдельного плана для представления.
Рассмотрим следующее представление:
USE AdventureWorks2022;
GO
CREATE VIEW EmployeeName AS
SELECT h.BusinessEntityID, p.LastName, p.FirstName
FROM HumanResources.Employee AS h
JOIN Person.Person AS p
ON h.BusinessEntityID = p.BusinessEntityID;
GO
Обе следующие инструкции Transact-SQL, основанные на данном представлении, выполняют одни и те же операции с базовой таблицей и дают одинаковый результат:
/* SELECT referencing the EmployeeName view. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.Sales.SalesOrderHeader AS soh
JOIN AdventureWorks2022.dbo.EmployeeName AS EmpN
ON (soh.SalesPersonID = EmpN.BusinessEntityID)
WHERE OrderDate > '20020531';
/* SELECT referencing the Person and Employee tables directly. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.HumanResources.Employee AS e
JOIN AdventureWorks2022.Sales.SalesOrderHeader AS soh
ON soh.SalesPersonID = e.BusinessEntityID
JOIN AdventureWorks2022.Person.Person AS p
ON e.BusinessEntityID =p.BusinessEntityID
WHERE OrderDate > '20020531';
В среде SQL Server Management Studio функция Showplan показывает, что реляционная машина создает один и тот же план выполнения для обеих SELECT инструкций.
Использование подсказок с представлениями
Подсказки, размещенные на представлениях в запросе, могут конфликтовать с другими указаниями, обнаруженными при развертывании представления для доступа к базовым таблицам. Когда это происходит, запрос возвращает ошибку. Взгляните, например, на следующее представление, в определение которого входит табличное указание:
USE AdventureWorks2022;
GO
CREATE VIEW Person.AddrState WITH SCHEMABINDING AS
SELECT a.AddressID, a.AddressLine1,
s.StateProvinceCode, s.CountryRegionCode
FROM Person.Address a WITH (NOLOCK), Person.StateProvince s
WHERE a.StateProvinceID = s.StateProvinceID;
Предположим, что вводится следующий запрос:
SELECT AddressID, AddressLine1, StateProvinceCode, CountryRegionCode
FROM Person.AddrState WITH (SERIALIZABLE)
WHERE StateProvinceCode = 'WA';
Запрос завершается ошибкой, поскольку подсказка SERIALIZABLE, примененная к представлению Person.AddrState в запросе, при расширении представления передается на таблицы Person.Address и Person.StateProvince. Однако при расширении представления будет также показана подсказка NOLOCK, находящаяся на Person.Address. Из-за конфликта подсказок SERIALIZABLE и NOLOCK результирующий запрос некорректен.
Табличные указания PAGLOCK, NOLOCK, ROWLOCK, TABLOCKи TABLOCKX , а также HOLDLOCK, NOLOCK, READCOMMITTED, REPEATABLEREADи SERIALIZABLE конфликтуют друг с другом.
Подсказки могут передаваться через уровни вложенных представлений. Например, предположим, что в запросе подсказка HOLDLOCK применяется к представлению v1. При расширении представления v1 выясняется, что представление v2 является частью его определения. Определение v2 включает в себя подсказку на одну из его базовых таблиц NOLOCK. Однако эта таблица также наследует указание HOLDLOCK из запроса на представление v1. Из-за конфликта подсказок NOLOCK и HOLDLOCK запрос терпит неудачу.
Если в запросе, включающем представление, используется указание FORCE ORDER , порядок соединения таблиц в представлении определяется по позиции представления в конструкции упорядочения. Например, приведенный ниже запрос выбирает данные из трех таблиц и представления:
SELECT * FROM Table1, Table2, View1, Table3
WHERE Table1.Col1 = Table2.Col1
AND Table2.Col1 = View1.Col1
AND View1.Col2 = Table3.Col2;
OPTION (FORCE ORDER);
И View1 определяется следующим образом:
CREATE VIEW View1 AS
SELECT Colx, Coly FROM TableA, TableB
WHERE TableA.ColZ = TableB.Colz;
В этом случае порядок соединения таблиц в плане запроса будет таким: Table1, Table2, TableA, TableB, Table3.
Устранение индексов в представлениях
Как и в любом индексе, SQL Server выбирает использование индексированного представления в плане запроса только в том случае, если оптимизатор запросов определяет, что это полезно.
Индексированные представления можно создавать в любом выпуске SQL Server. В некоторых выпусках некоторых старых версий SQL Server оптимизатор запросов автоматически рассматривает индексированное представление. В некоторых выпусках старых версий SQL Server для использования индексированного представления необходимо использовать подсказку таблицы NOEXPAND. Автоматическое использование индексированного представления оптимизатором запросов поддерживается только в определенных выпусках SQL Server. База данных Azure SQL и Управляемый экземпляр Azure SQL также поддерживают автоматическое применение индексированных представлений без указания NOEXPAND подсказки.
Оптимизатор запросов SQL Server использует индексированное представление при выполнении следующих условий:
- Для следующих параметров сеанса задано
ONзначение :ANSI_NULLSANSI_PADDINGANSI_WARNINGSARITHABORTCONCAT_NULL_YIELDS_NULLQUOTED_IDENTIFIER
- Для параметра сеанса
NUMERIC_ROUNDABORTустановлено значение OFF. - Оптимизатор запросов находит совпадение между столбцами индекса представления и элементами в запросе, например следующим образом:
- предикаты условий поиска в предложении WHERE
- Операции объединения
- Агрегатные функции
- Условия
GROUP BY - Ссылки на таблицы
- Предполагаемые затраты на использование индекса имеют меньшую стоимость по сравнению с любыми механизмами доступа, имеющимися в распоряжении оптимизатора запросов.
- Каждая таблица, на которую ссылается запрос (либо прямо, либо при расширении представления для доступа к его базовым таблицам), соответствующая табличной ссылке в индексированном представлении, должна иметь в запросе точно такой же набор указаний.
Примечание.
Указания READCOMMITTED и READCOMMITTEDLOCK в данном контексте всегда рассматриваются как разные, независимо от уровня изоляции текущей транзакции.
За исключением требований к параметрам SET и табличным указаниям, это те же самые правила, по которым оптимизатор запросов выясняет, подходит ли индекс таблицы для выполнения запроса. Для использования индексированного представления в запросе больше ничего указывать не нужно.
Запрос не должен явно ссылаться на индексированное представление в FROM предложении для оптимизатора запросов для использования индексированного представления. Если запрос ссылается на столбцы в базовой таблице, которые также присутствуют в индексированном представлении, и оптимизатор запросов определяет, что индексированное представление будет иметь самую низкую стоимость механизма доступа, он применит индексированное представление точно так же, как он применяет индекс базовой таблицы, если на него отсутствуют прямые ссылки в запросе. Оптимизатор запросов может выбрать представление, если он содержит столбцы, на которые не ссылается запрос, если представление предлагает самый низкий вариант затрат для покрытия одного или нескольких столбцов, указанных в запросе.
Индексированное представление, указанное в предложении FROM , оптимизатор запросов рассматривает как стандартное представление. Оптимизатор запросов расширяет определение представления внутри запроса в начале процесса оптимизации. Затем выполняется сопоставление с индексированным представлением. Индексированное представление можно использовать в окончательном плане выполнения, выбранном оптимизатором запросов, или вместо этого план может материализовать необходимые данные из представления путем доступа к базовым таблицам, на которые ссылается представление. Оптимизатор запросов выбирает вариант с наименьшей стоимостью.
Использование хинтов в индексированных представлениях
Чтобы индексы представления не использовались для запроса, можно использовать указание запроса EXPAND VIEWS, или табличное указание NOEXPAND, чтобы принудительно использовать индекс для индексированного представления, указанного в предложении FROM. Однако оптимизатору запросов следует разрешить динамически определять лучший метод доступа для каждого из запросов. Ограничьте применение указаний EXPAND и NOEXPAND только теми случаями, когда очевидно, что они значительно повысят производительность.
Параметр
EXPAND VIEWSуказывает, что оптимизатор запросов не будет использовать индексы представления для всего запроса.Если для представления задано указание
NOEXPAND, оптимизатор запросов предполагает использование всех индексов, определенных в представлении.NOEXPANDс указанием необязательного предложенияINDEX()заставляет оптимизатор запросов использовать указанные индексы.NOEXPANDможно указать только для индексированного представления и не может быть указан для представления, не индексированного. Автоматическое использование индексированного представления оптимизатором запросов поддерживается только в определенных выпусках SQL Server. База данных SQL Azure и Управляемый экземпляр SQL Azure также поддерживают автоматическое использование индексированных представлений без указанияNOEXPANDуказания.
Если в запросе, содержащем представление, не заданы ни NOEXPAND , ни EXPAND VIEWS , это представление расширяется для доступа к базовым таблицам. Если запрос представления содержит какие-либо табличные указания, они распространяются на базовые таблицы. (Этот процесс подробно описан в разделе "Разрешение представлений".) Пока указания, имеющиеся в базовых таблицах представления, идентичны, для запроса может устанавливаться соответствие с индексированным представлением. Чаще всего эти указания соответствуют друг другу, поскольку они наследуются непосредственно из представления. Однако, если запрос ссылается на таблицы вместо представлений, и подсказки, применяемые непосредственно к этим таблицам, не идентичны, то такой запрос не подходит для сопоставления с индексированными представлениями. Если подсказки INDEX, PAGLOCK, ROWLOCK, TABLOCKX, UPDLOCK или XLOCK применимы к таблицам, на которые ссылается запрос после расширения представления, то запрос не подходит для сопоставления с индексированным представлением.
Если подсказка в виде INDEX (index_val[ ,...n] ) ссылается на представление в запросе и вы также не указываете подсказку NOEXPAND, то подсказка индекса игнорируется. Для указания конкретного индекса используйте NOEXPAND.
Обычно, если оптимизатор запросов устанавливает соответствие индексированного представления запросу, все заданные в таблицах или представлениях запроса указания применяются непосредственно к индексированному представлению. Если оптимизатор запросов решил не использовать индексированное представление, все указания распространяются непосредственно на таблицы, на которые ссылается это представление. Дополнительные сведения см. в разделе "Разрешение экрана". Это распространение не применяется к указаниям на присоединение. Они применяются только в той исходной позиции запроса, где они указаны. Подсказки соединения не рассматриваются оптимизатором запросов при сопоставлении запросов с индексированными представлениями. Если план запроса использует индексированное представление, совпадающее с частью запроса, содержащего подсказку соединения, то подсказка соединения не используется в плане.
В определениях индексированных представлений указания не допускаются. В режимах совместимости 80 и выше SQL Server пропускает указания при работе с определениями индексированных представлений и при выполнении содержащих их запросов. Хотя использование подсказок в определениях индексированного представления не приведет к возникновению синтаксической ошибки в режиме совместимости 80, они игнорируются.
Дополнительные сведения см. в статье Указания по таблицам (Transact-SQL).
Разрешение распределенных секционированных представлений
Обработчик запросов SQL Server оптимизирует производительность распределенных секционированных представлений. Наиболее важным аспектом производительности распределённого секционированного представления является минимизация объёма данных, передаваемых между серверами-членами.
SQL Server создает интеллектуальные динамические планы, которые позволяют эффективно использовать распределенные запросы для доступа к данным в удаленных таблицах-элементах.
- Обработчик запросов сначала использует OLE DB для получения определений ограничений CHECK для каждой таблицы-элемента. Это позволяет процессору запросов определить распределение ключевых значений между таблицами участников.
- Обработчик запросов сравнивает диапазоны ключей, заданные в инструкции Transact-SQL
WHERE, со схемой распределения строк между таблицами-элементами. Затем обработчик запросов строит план выполнения, который использует распределенные запросы для получения только тех удаленных строк, которые требуются для завершения инструкции Transact-SQL. План выполнения также строится таким образом, что любое обращение к удаленным таблицам участников, будь то для данных или метаданных, задерживается до момента, когда эта информация требуется.
Например, рассмотрим систему, в Customers которой таблица секционируется по серверу1 (от 1 до 3299999), Server2 (CustomerIDот 3300000 до 6599999) и Server3 (CustomerIDCustomerIDот 6600000 до 9999999).
Допустим, план выполнения, созданный для этого запроса, выполняется на сервере Server1:
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID BETWEEN 3200000 AND 3400000;
План выполнения этого запроса извлекает строки со значениями ключей CustomerID от 3200000 до 3299999 из локальной таблицы-элемента и вызывает распределенный запрос для получения строк со значениями ключей от 3300000 до 3400000 с сервера Server2.
Обработчик запросов SQL Server также может встраивать динамическую логику в планы выполнения запросов для инструкций Transact-SQL в тех случаях, когда значения ключей во время создания плана неизвестны. Рассмотрим следующую хранимую процедуру:
CREATE PROCEDURE GetCustomer @CustomerIDParameter INT
AS
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID = @CustomerIDParameter;
SQL Server не может предсказать, какое значение ключа будет предоставляться параметром @CustomerIDParameter при каждом выполнении процедуры. Так как значение ключа невозможно спрогнозировать, обработчик запросов также не может предсказать, к какой таблице-члену придется получить доступ. В этом случае SQL Server создает план выполнения с условной логикой, называемой динамическими фильтрами, для управления доступом к таблицам-элементам на основе значения входного параметра. Если предположить, что хранимая процедура GetCustomer выполнена на сервере Server1, логику плана выполнения можно представить следующим образом:
IF @CustomerIDParameter BETWEEN 1 and 3299999
Retrieve row from local table CustomerData.dbo.Customer_33
ELSE IF @CustomerIDParameter BETWEEN 3300000 and 6599999
Retrieve row from linked table Server2.CustomerData.dbo.Customer_66
ELSE IF @CustomerIDParameter BETWEEN 6600000 and 9999999
Retrieve row from linked table Server3.CustomerData.dbo.Customer_99
Иногда SQL Server создает динамические планы выполнения даже для непараметризованных запросов. Оптимизатор запросов может параметризировать запрос, чтобы план выполнения можно было повторно использовать. Если оптимизатор запросов параметризует запрос, ссылающийся на секционированное представление, он не будет знать, находятся ли нужные строки в заданной базовой таблице. В дальнейшем ему придется использовать динамические фильтры в планах выполнения.
Хранимая процедура и выполнение триггера
SQL Server хранит только исходный код хранимых процедур и триггеров. При выполнении хранимой процедуры или триггера в первый раз исходный код компилируется в план выполнения. Если очередной вызов хранимой процедуры или триггера будет инициирован до устаревания плана выполнения, реляционный механизм обнаружит существующий план и использует его повторно. Если план устарел и был удален из памяти, будет создан новый план. Этот процесс похож на то, как SQL Server обрабатывает все инструкции Transact-SQL. Основное преимущество хранимых процедур и триггеров SQL Server над пакетами динамического кода Transact-SQL в плане быстродействия заключается в том, что их инструкции Transact-SQL всегда остаются постоянными. Благодаря этому реляционный механизм может с легкостью сопоставлять их с любыми существующими планами выполнения. Это облегчает повторное использование планов хранимых процедур и триггеров.
Планы выполнения хранимых процедур и триггеров обрабатываются отдельно от плана выполнения пакета, вызвавшего хранимую процедуру или приведшего к срабатыванию триггера. Это способствует повторному использованию планов выполнения хранимых процедур и триггеров.
Кэширование и повторное использование плана выполнения
В SQL Server есть пул памяти, предназначенный для хранения планов выполнения и буферов данных. Процентное соотношение размера пула, выделенного для планов выполнения и буферов данных, динамически изменяется в зависимости от состояния системы. Часть пула памяти, используемого для хранения планов выполнения, называется кэшем планов.
В кэше планов есть два хранилища для всех скомпилированных планов:
- хранилище кэша Object Plans (OBJCP), которое используется для планов, связанных с сохраняемыми объектами (хранимыми процедурами, функциями и триггерами);
- хранилище кэша SQL Plans (SQLCP), которое используется для планов, связанных с автоматически параметризуемыми, динамическими или подготовленными запросами.
Следующий запрос предоставляет сведения об использовании памяти для этих двух хранилищ:
SELECT * FROM sys.dm_os_memory_clerks
WHERE name LIKE '%plans%';
Примечание.
В кэше планов есть еще два хранилища, которые не используются для хранения планов.
- Хранилище кэша Bound Trees (PHDR) предназначено для структур данных, используемых во время компиляции плана для представлений, ограничений и значений по умолчанию. Эти структуры называются связанными деревьями или деревьями алгебризатора.
- Хранилище кэша Extended Stored Procedures (XPROC) предназначено для предварительно определенных системных процедур, таких как
sp_executeSqlилиxp_cmdshell, которые определены с помощью библиотеки DLL, а не инструкций Transact-SQL. Кэшированная структура содержит только имя функции и имя библиотеки DLL, в которой реализована процедура.
В SQL Server планы выполнения состоят из следующих основных компонентов.
Скомпилированный план (или план запроса)
План запроса, создаваемый в результате компиляции, является, как правило, реентерабельной структурой данных только для чтения, которую могут использовать любое число пользователей. В нем хранятся следующие сведения:Физические операторы, реализующие операцию, описанную логическими операторами.
порядок этих операторов, определяющий очередность доступа к данным, их фильтрации и агрегирования;
предполагаемое количество строк, передаваемых через операторы.
Примечание.
В более новых версиях движка базы данных также хранятся сведения об объектах статистики, которые использовались для оценки кардинальности.
Какие объекты поддержки необходимо создать, например рабочие таблицы или рабочие файлы.
tempdbКонтекст пользователя или сведения времени выполнения в плане запроса не хранятся. В памяти содержится одна или две копии плана запроса (но не более): одна — для всех последовательных выполнений, а другая — для всех параллельных выполнений. Одна параллельная копия обслуживает все параллельные выполнения независимо от степени параллелизма.
Контекст выполнения
Для каждого пользователя, который в настоящий момент выполняет запрос, имеется структура данных, которая содержит данные, относящиеся к данному выполнению, например значения параметров. Эта структура данных называется контекстом выполнения. Структуры данных контекста выполнения используются повторно, но их содержимое не используется повторно. Если другой пользователь выполняет тот же запрос, структуры данных инициализируются повторно контекстом нового пользователя.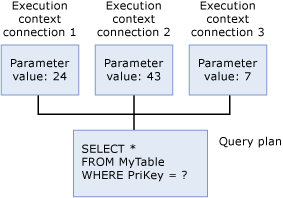
При выполнении любой инструкции Transact-SQL в SQL Server ядро СУБД сначала просматривает кэш планов, проверяя, нет ли в нем плана выполнения для такой же инструкции Transact-SQL. Инструкция Transact-SQL считается существующей, если она точно соответствует выполнявшейся ранее инструкции Transact-SQL с кэшированным планом, символ за символом. SQL Server повторно использует все найденные планы, что позволяет избежать перекомпиляции инструкций Transact-SQL. Если план выполнения не существует, SQL Server создает новый план выполнения для запроса.
Примечание.
Планы выполнения для некоторых инструкций Transact-SQL не сохраняются в кэше планов. К ним относятся инструкции массовых операций, работающие в rowstore, а также инструкции, содержащие строковые литералы размером более 8 КБ. Такие планы существуют только во время выполнения запроса.
SQL Server реализует эффективный алгоритм поиска существующих планов выполнения для любой инструкции Transact-SQL. В большинстве систем минимальные ресурсы, используемые этим сканированием, меньше ресурсов, которые сохраняются благодаря возможности повторного использования существующих планов вместо компиляции каждой инструкции Transact-SQL.
Алгоритмы сопоставления новых инструкций Transact-SQL с существующими неиспользуемыми планами выполнения в кэше планов требуют, чтобы все ссылки на объекты были полностью квалифицированными. Например, предположим, что Person является схемой по умолчанию для пользователя, выполняющего инструкции SELECT ниже. Хотя в этом примере не требуется, чтобы таблица Person была полностью квалифицирована для выполнения, это означает, что второй оператор не сопоставляется с существующим планом, но третий сопоставляется.
USE AdventureWorks2022;
GO
SELECT * FROM Person;
GO
SELECT * FROM Person.Person;
GO
SELECT * FROM Person.Person;
GO
Изменение любого из следующих SET-параметров для заданного выполнения повлияет на возможность повторного использования планов, так как ядро СУБД выполняет константное свертывание, и эти параметры влияют на результаты таких выражений.
ANSI_NULL_DFLT_OFF
ПЛАН ПРИНУЖДЕНИЯ
ARITHABORT
DATEFIRST
ANSI_PADDING
Прерывание округления числовых данных
ANSI_NULL_DFLT_ON (включение режима ANSI_NULL)
ЯЗЫК
CONCAT_NULL_YIELDS_NULL (объединение NULL возвращает NULL)
формат даты
ANSI_WARNINGS (предупреждения ANSI)
Кавычечный идентификатор
ANSI_NULLS (параметр SQL)
НЕТ_ТАБЛИЦЫ_ДЛЯ_ОБЗОРА
Значения по умолчанию ANSI
Кэширование нескольких планов для одного запроса
Запросы и планы выполнения однозначно идентифицируются в базе данных, аналогично отпечаткам пальцев.
- Хэш-значение плана запроса — это двоичное хэш-значение, вычисленное для плана выполнения данного запроса и используемое для уникальной идентификации планов выполнения со сходной логикой.
- Хэш-значение для запроса — это двоичное хэш-значение, вычисленное для текста Transact-SQL запроса и используемое для уникальной идентификации запросов.
Скомпилированный план можно получить из кэша планов с помощью дескриптора плана, который представляет собой временный идентификатор, сохраняющий свое значение, только пока план остается в кэше. Дескриптор плана — это хэш-значение, которое выводится из скомпилированного плана целого пакета. Дескриптор плана для скомпилированного плана остается неизменным, даже если одна или несколько инструкций в пакете перекомпилируются.
Примечание.
Если план был скомпилирован для пакета инструкций, а не для одной инструкции, то планы для отдельных инструкций в этом пакете можно получить с помощью дескриптора плана и смещений инструкций.
Динамическое административное представление sys.dm_exec_requests содержит для каждой записи столбцы statement_start_offset и statement_end_offset, которые ссылаются на выполняемую в настоящее время инструкцию выполняющегося пакета или сохраняемого объекта. Для получения дополнительной информации см. sys.dm_exec_requests (Transact-SQL).
Динамическое административное представление sys.dm_exec_query_stats также содержит для каждой записи столбцы, ссылающиеся на положение инструкции внутри пакета или сохраняемого объекта. Дополнительные сведения см. в статье sys.dm_exec_query_stats (Transact-SQL).
Фактический текст Transact-SQL пакета хранится в отдельной области памяти, которая не связана с кэшем планов и называется кэшем SQL Manager (SQLMGR). Текст Transact-SQL для скомпилированного плана можно получить из кэша SQL Manager с помощью дескриптора SQL, который представляет собой временный идентификатор, сохраняющий свое значение, только пока в кэше планов остается по крайней мере один ссылающийся на него план. Дескриптор SQL — это хэш-значение, которое выводится из всего текста пакета и гарантированно является уникальным для каждого пакета.
Примечание.
Как и скомпилированный план, текст Transact-SQL хранится для каждого пакета, включая комментарии. Дескриптор SQL содержит хэш-код MD5 всего текста пакета и гарантированно является уникальным для каждого пакета.
Следующий запрос предоставляет сведения об использовании памяти для кэша SQL Manager:
SELECT * FROM sys.dm_os_memory_objects
WHERE type = 'MEMOBJ_SQLMGR';
Между идентификатором SQL и идентификаторами планов существует отношение "один ко многим". Такая ситуация возникает, когда ключ кэша для скомпилированных планов отличается. Это может произойти из-за изменения параметров SET между двумя выполнениями одного пакета.
Рассмотрим следующую хранимую процедуру:
USE WideWorldImporters;
GO
CREATE PROCEDURE usp_SalesByCustomer @CID int
AS
SELECT * FROM Sales.Customers
WHERE CustomerID = @CID
GO
SET ANSI_DEFAULTS ON
GO
EXEC usp_SalesByCustomer 10
GO
Проверьте содержимое кэша планов, используя следующий запрос:
SELECT cp.memory_object_address, cp.objtype, refcounts, usecounts,
qs.query_plan_hash, qs.query_hash,
qs.plan_handle, qs.sql_handle
FROM sys.dm_exec_cached_plans AS cp
CROSS APPLY sys.dm_exec_sql_text (cp.plan_handle)
CROSS APPLY sys.dm_exec_query_plan (cp.plan_handle)
INNER JOIN sys.dm_exec_query_stats AS qs ON qs.plan_handle = cp.plan_handle
WHERE text LIKE '%usp_SalesByCustomer%'
GO
Вот результаты.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Теперь выполните хранимую процедуру с другим параметром, не внося иных изменений в контекст выполнения:
EXEC usp_SalesByCustomer 8
GO
Еще раз проверьте содержимое кэша планов. Вот результаты.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Обратите внимание, что usecounts увеличилось до 2, что означает, что тот же кэшированный план был повторно использован без изменений, поскольку структуры данных контекста выполнения были повторно использованы. Теперь измените параметр SET ANSI_DEFAULTS и выполните хранимую процедуру с использованием того же параметра.
SET ANSI_DEFAULTS OFF
GO
EXEC usp_SalesByCustomer 8
GO
Еще раз проверьте содержимое кэша планов. Вот полученный набор данных.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CD01DEC060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02B031F111CD01000001000000000000000000000000000000000000000000000000000000
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Обратите внимание, что в выходных данных динамического административного представления sys.dm_exec_cached_plans теперь есть две записи.
- В
usecountsстолбце отображается значение1в первой записи, которая является планом, выполненным один раз сSET ANSI_DEFAULTS OFF. - В
usecountsстолбце отображается значение2во второй записи, где планSET ANSI_DEFAULTS ONвыполнен, так как он был выполнен дважды. - Разные значения
memory_object_addressуказывают на разные записи планов выполнения в кэше планов. Однако значениеsql_handleодинаково для обеих записей, так как они ссылаются на один и тот же пакет.- Выполнение с параметром
ANSI_DEFAULTSсо значением OFF имеет новый дескрипторplan_handleи может быть повторно использовано для вызовов, имеющих такой же набор параметров SET. Новый дескриптор плана необходим по той причине, что контекст выполнения был инициализирован повторно из-за измененных параметров SET. Но это не вызывает перекомпиляцию: обе записи ссылаются на одни и те же план и запрос, о чем свидетельствуют одинаковые значенияquery_plan_hashиquery_hash.
- Выполнение с параметром
Таким образом, в кэше есть две записи планов, соответствующие одному пакету. Это подчеркивает важность того, что параметры SET, влияющие на кэш планов, должны быть одинаковы, когда одни и те же запросы выполняются повторно. Это позволяет оптимизировать повторное использование плана и свести необходимый размер кэша планов к минимуму.
Совет
Распространенная ошибка заключается в том, что разные клиенты могут иметь разные значения по умолчанию для параметров SET. Например, подключение, выполненное через SQL Server Management Studio, автоматически устанавливает QUOTED_IDENTIFIER значение ON, а SQLCMD устанавливает QUOTED_IDENTIFIER значение OFF. Выполнение одних и тех же запросов из этих двух клиентов приведет к созданию нескольких планов (как описано в примере выше).
Удаление планов выполнения из кэша планов
Планы выполнения остаются в кэше планов до тех пор, пока для их хранения остается достаточно памяти. Если имеется недостаток памяти, ядро базы данных SQL Server использует подход, основанный на стоимости, чтобы определить, какие планы выполнения следует удалить из кеша планов. Чтобы принять решение на основе затрат, SQL Server ядро СУБД увеличивает и уменьшает текущую переменную затрат для каждого плана выполнения в соответствии со следующими факторами.
Когда процесс пользователя вставляет план выполнения в кэш, процесс пользователя задает текущую стоимость, равную исходной стоимости компиляции запроса; для планов нерегламентированного выполнения процесс пользователя задает текущую стоимость нулю. После этого каждый раз, когда пользовательский процесс обращается к плану выполнения, он сбрасывает текущую стоимость до исходной стоимости компиляции; для планов выполнения ad hoc пользовательский процесс увеличивает текущую стоимость. Для всех планов максимальное значение текущей стоимости равно исходной стоимости компиляции.
При возникновении давления на память модуль базы данных SQL Server реагирует, удаляя планы выполнения из кэша планов. Чтобы определить, какие планы следует удалить, SQL Server ядро СУБД неоднократно проверяет состояние каждого плана выполнения и удаляет планы, когда их текущая стоимость равна нулю. План выполнения с нулевой текущей стоимостью не удаляется автоматически при наличии давления памяти; Он удаляется только в том случае, если SQL Server ядро СУБД проверяет план, а текущая стоимость равна нулю. При проверке плана выполнения ядро базы данных SQL Server снижает стоимость до нуля, если запрос в настоящее время не использует план.
СУБД SQL Server неоднократно проверяет планы выполнения до тех пор, пока не будет удалено достаточно для соответствия требованиям к памяти. При наблюдении давления на память, стоимость плана выполнения может увеличиваться и уменьшаться неоднократно. Если давление на память прекращается, СУБД SQL Server прекращает уменьшение текущей стоимости неиспользуемых планов запросов, и все планы запросов остаются в кэше планов, даже если их стоимость равна нулю.
Sql Server ядро СУБД использует монитор ресурсов и рабочие потоки пользователей для освобождения памяти от кэша планов в ответ на давление памяти. Монитор ресурсов и пользовательские рабочие потоки могут проверять параллельно выполняющиеся планы, что позволяет уменьшать текущую стоимость для каждого неиспользуемого плана выполнения. Монитор ресурсов удаляет планы выполнения из кэша планов при глобальной нехватке памяти. Он освобождает память для принудительного выполнения политик для системной памяти, памяти процессов, памяти пула ресурсов и максимального размера всех кэшей.
Максимальный размер всех кэшей — это функция размера буферного пула и не может превышать максимальный объем памяти сервера. Дополнительные сведения о настройке максимальной памяти сервера см. в параметре max server memory в sp_configure.
Пользовательские рабочие потоки удаляют планы выполнения из кэша планов при нехватке памяти в одиночном кэше. Они обеспечивают выполнение политик для максимального размера кэша и максимума записей одиночного кэша.
В следующих примерах показано, какие планы выполнения удаляются из кэша планов.
- План выполнения часто используется, поэтому его стоимость никогда не принимает значение ноль. План остается в кэше плана и не удаляется, если нет нехватки памяти, а текущая стоимость равна нулю.
- Специальный план выполнения вставляется и не упоминается снова до появления давления на память. Так как планы 'ad hoc' инициализированы с текущей стоимостью нуля, когда ядро базы данных SQL Server проверяет план выполнения, оно увидит нулевую текущую стоимость и удалит план из кэша планов. План нерегламентированного выполнения остается в кэше планов с нулевой текущей стоимостью, если давление на память отсутствует.
Чтобы вручную удалить отдельный план выполнения или все планы выполнения из кеша, используйте команду DBCC FREEPROCCACHE.
DBCC FREESYSTEMCACHE также можно использовать для очистки любого кэша, включая кэш планов. Начиная с SQL Server 2016 (13.x), используйте команду ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE для очистки кэша процедуры (плана) для базы данных в пределах контекста.
Изменение некоторых параметров конфигурации с помощью sp_configure и reconfigure также приведет к удалению планов из кэша планов. Список этих параметров конфигурации можно найти в разделе "Примечания" статьи DBCC FREEPROCCACHE. Такое изменение конфигурации приведет к записи в журнал ошибок следующего информационного сообщения:
SQL Server has encountered %d occurrence(s) of cachestore flush for the '%s' cachestore (part of plan cache) due to some database maintenance or reconfigure operations.
Переустановка планов выполнения
Некоторые изменения в базе данных могут привести к тому, что план выполнения станет неэффективным или неправильным в зависимости от нового состояния базы данных. SQL Server обнаруживает изменения, которые приводят к недействительности плана выполнения, и помечает такой план как неправильный. Для следующего подключения, при котором выполняется данный запрос, необходимо перекомпилировать план. План может стать недействительным в следующих случаях.
- Изменены таблица и представления, на которые ссылается запрос (
ALTER TABLEиALTER VIEW). - Внесение изменений в одну процедуру приводит к удалению всех планов для этой процедуры из кэша (
ALTER PROCEDURE). - Изменения индексов, используемых планом выполнения.
- Обновления касаются статистики, используемой планом выполнения, которая создается либо явно на основе
UPDATE STATISTICS, либо автоматически. - Удаление индекса, используемого в плане выполнения.
- Явный вызов
sp_recompile. - Частое изменение ключей (инструкциями
INSERTилиDELETEот пользователей, изменяющих таблицу, на которую ссылается запрос). - Если в таблицах inserted или deleted происходит значительный рост числа строк, это особенно важно для таблиц с триггерами.
- Выполнение хранимой процедуры с помощью параметра
WITH RECOMPILE.
Большинство перекомпиляций необходимы либо для обеспечения правильности инструкций, либо для потенциального ускорения выполнения планов запросов.
В версиях SQL Server до 2005 года каждый раз, когда инструкция в пакете вызывает перекомпиляцию, весь пакет, отправленный через хранимую процедуру, триггер, нерегламентированный пакет или подготовленную инструкцию, был перекомпилирован. Начиная с SQL Server 2005 (9.x) перекомпилируется только тот запрос внутри пакета команд, который вызывает повторную компиляцию. Кроме того, существуют дополнительные типы перекомпиляций в SQL Server 2005 (9.x) и более поздних версий из-за развернутого набора функций.
Перекомпиляция на уровне инструкции дает выигрыш в производительности, поскольку в большинстве случаев перекомпиляция небольшого числа инструкций и связанных с этим потерь занимает меньше ресурсов в плане использования времени ЦП и затрат на блокировки. Таким образом, эти штрафы избегаются для тех других инструкций в пакете, которые не должны быть перекомпилированы.
Расширенное sql_statement_recompile событие (XEvent) сообщает о перекомпилации уровня инструкций. Это XEvent возникает, когда рекомпиляция на уровне инструкций требуется любым пакетом. К таким пакетам относятся хранимые процедуры, триггеры, нерегламентированные пакеты и запросы. Пакеты можно отправлять через несколько интерфейсов, включая sp_executesqlдинамические SQL, методы подготовки или методы Execute.
Столбец recompile_causesql_statement_recompile XEvent содержит целый код, указывающий причину повторной компиляции. В следующей таблице приведены возможные причины.
Изменение схемы
Изменение статистики
Отложенная компиляция
Изменение параметра SET
Временная таблица изменена
Изменение удаленного набора строк
Разрешение изменено FOR BROWSE
Изменение среды уведомлений о запросах
Изменение секционированного представления
Изменение параметров курсора
OPTION (RECOMPILE) запрошено
Очистка параметризованного плана
Изменение плана из-за изменения версии базы данных.
Изменение политики форсирования плана для хранилища запросов
Сбой форсирования плана для хранилища запросов
Отсутствие плана для хранилища запросов
Примечание.
В версиях SQL Server, где XEvents недоступны, событие трассировки SQL Server Profiler SP:Recompile можно использовать для той же цели - рекомпиляции на уровне операторов.
Событие трассировки SQL:StmtRecompile также сообщает о перекомпиляции уровня инструкций и может использоваться для отслеживания и отладки перекомпиляции.
В то время как SP:Recompile генерирует только для хранимых процедур и триггеров, SQL:StmtRecompile генерирует для хранимых процедур, триггеров, нерегламентированных пакетов, пакетов, выполняемых с помощью sp_executesql, подготовленных запросов и динамического SQL.
Столбец EventSubClass для событий SP:Recompile и SQL:StmtRecompile содержит код в виде целого числа, обозначающий причину перекомпиляции. Коды описаны в классе событий SQL:StmtRecompile.
Примечание.
Если для параметра базы данных AUTO_UPDATE_STATISTICS установлено значение ON, то запросы перекомпилируются при условии, что они указывают на целевые таблицы или индексированные представления, для которых со времени последнего выполнения была изменена статистика или в значительной степени была изменена кратность.
Это поведение распространяется на стандартные пользовательские определяемые таблицы, временные таблицы, а также таблицы inserted и deleted, создаваемые триггерами DML. Если на производительность запроса оказывают влияние излишние перекомпиляции, измените значение этого параметра на OFF. Если для параметра базы данных AUTO_UPDATE_STATISTICS установлено значение OFF, перекомпиляция по причине изменения статистики или кратности не выполняется, за исключением вставляемых и удаляемых таблиц, созданных триггерами DML INSTEAD OF. Так как эти таблицы создаются в tempdb, перекомпиляция запросов, к которым они обращаются, зависит от параметра AUTO_UPDATE_STATISTICS в tempdb.
В SQL Server до 2005 года запросы продолжают перекомпилироваться на основе изменений кратности триггера DML, вставленных и удаленных таблиц, даже если этот параметр имеет значение OFF.
Повторное использование параметров и плана выполнения
Использование параметров, включая маркеры параметров в приложениях ADO, OLE DB и ODBC, может повысить уровень использования планов выполнения.
Предупреждение
Использование параметров и маркеров параметров для хранения введенных конечными пользователями значений безопаснее, чем сцепление значений в строку, которая затем выполняется с помощью метода API доступа к данным, инструкции EXECUTE или хранимой процедуры sp_executesql .
Единственная разница между следующими двумя инструкциями SELECT — в значениях, сравниваемых в предложении WHERE :
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
Единственная разница между планами выполнения для этих запросов — в значении, хранимом для сравнения со столбцом ProductSubcategoryID . Хотя цель заключается в том, чтобы SQL Server всегда распознал, что инструкции создают практически тот же план и повторно используют планы, SQL Server иногда не обнаруживает это в сложных инструкциях Transact-SQL.
Отделение констант от инструкции Transact-SQL с помощью параметров помогает реляционному механизму распознавать дубликаты планов. Параметры можно использовать следующими способами.
В Transact-SQL используйте
sp_executesql:DECLARE @MyIntParm INT SET @MyIntParm = 1 EXEC sp_executesql N'SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = @Parm', N'@Parm INT', @MyIntParmЭтот метод рекомендуется для скриптов Transact-SQL, хранимых процедур и триггеров, динамически формирующих инструкции SQL.
В технологиях ADO, OLE DB и ODBC используются маркеры параметров. Маркеры параметров — это вопросительные знаки (?), которые заменяют константу в инструкции SQL и привязаны к переменной программы. Например, в приложении ODBC можно сделать следующее:
Используется
SQLBindParameterдля привязки целочисленной переменной к первому маркеру параметра в инструкции SQL.поместить целочисленное значение в переменную;
выполнить инструкцию, указав маркер параметра (?):
SQLExecDirect(hstmt, "SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = ?", SQL_NTS);
Если в приложениях используются маркеры параметров, поставщик OLE DB для SQL Server Native Client и драйвер ODBC для SQL Server Native Client, включенные в состав SQL Server, используют для отправки инструкций в SQL Server процедуру
sp_executesql.Чтобы проектировать хранимые процедуры, использующие указанные разработчиком параметры.
Если вы явно не создаете параметры в конструкторе приложений, вы также можете использовать оптимизатор запросов SQL Server для автоматической параметризации определенных запросов с помощью поведения простой параметризации по умолчанию. В качестве альтернативы можно настроить принудительный учет параметризации всех запросов к базе данных в оптимизаторе запросов, установив для параметра PARAMETERIZATION инструкции ALTER DATABASE значение FORCED.
При включенной принудительной параметризации может также иметь место и простая параметризация. Например, следующий запрос не может быть параметризован в соответствии с правилами принудительной параметризации:
SELECT * FROM Person.Address
WHERE AddressID = 1 + 2;
Однако он может быть параметризован согласно правилам простой параметризации. В случае неуспешной попытки принудительной параметризации впоследствии производятся попытки использования простой параметризации.
Простая параметризация
В SQL Server использование параметров или маркеров параметров в инструкциях Transact-SQL повышает способность реляционного механизма сопоставлять новые инструкции Transact-SQL с существующими ранее скомпилированных планами выполнения.
Предупреждение
Использование параметров и маркеров параметров для хранения введенных конечными пользователями значений безопаснее, чем сцепление значений в строку, которая затем выполняется с помощью метода API доступа к данным, инструкции EXECUTE или хранимой процедуры sp_executesql .
Если инструкция Transact-SQL выполняется без параметров, SQL Server неявно параметризует инструкцию, чтобы увеличить возможность ее противопоставления существующему плану выполнения. Данный процесс называется простой параметризацией. В версиях SQL Server до 2005 года процесс называется автоматической параметризацией.
Рассмотрим следующее утверждение.
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
Значение 1 в конце инструкции может быть указано в виде параметра. Реляционный механизм строит план выполнения для данного пакета, как если бы параметр был указан на месте значения 1. С помощью этой простой параметризации SQL Server распознает, что следующие две инструкции формируют, по сути, одинаковый план выполнения, и повторно использует первый план для второй инструкции.
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
При обработке сложных инструкций Transact-SQL реляционный механизм может усложнять определение параметризованных выражений. Чтобы увеличить способность реляционного обработчика сопоставлять сложные инструкции Transact-SQL с существующими, неиспользуемыми планами выполнения, явно укажите параметры с помощью sp_executesql или маркеров параметров.
Примечание.
+, -, *, / или % При использовании арифметических операторов для неявного или явного преобразования константных значений типов int, smallint, tinyint или bigint в типы данных float, real, decimal или numeric, SQL Server применяет определенные правила для вычисления типа и точности результатов выражения. Однако эти правила различаются в зависимости от того, параметризован запрос или нет. Таким образом, одинаковые выражения в запросах могут в некоторых случаях давать отличающиеся результаты.
При проведении простой параметризации SQL Server по умолчанию параметризует сравнительно небольшой класс запросов. Однако можно указать, чтобы все запросы в базе данных были параметризованы в соответствии с определенными ограничениями, настроив параметр PARAMETERIZATION команды ALTER DATABASE на FORCED. Это может повысить производительность баз данных, которые испытывают большие объемы одновременных запросов, уменьшая частоту компиляции запросов.
Иначе можно указать параметризацию одного запроса и других, синтаксически равных, но отличающихся значениями параметра, запросов.
Совет
При использовании решения объектно-реляционного сопоставления (ORM), например Entity Framework (EF), запросы приложения, такие как вручную составленные деревья запросов LINQ или некоторые необработанные запросы SQL, могут не быть параметризованы, что влияет на повторное использование плана выполнения и возможность отслеживать запросы в хранилище запросов. Дополнительные сведения см. в статьях Кэширование и параметризация запросов EF и Необработанные запросы SQL EF.
Принудительная параметризация
Можно переопределить простую параметризацию, используемую по умолчанию в SQL Server, указав, что все инструкции SELECT, INSERT, UPDATEи DELETE в базе данных должны быть параметризованы (с учетом некоторых ограничений). Принудительная параметризация активируется путем установки для параметра PARAMETERIZATION значения FORCED в инструкции ALTER DATABASE . Принудительное параметризация может повысить производительность определенных баз данных, уменьшая частоту компиляций запросов и перекомпиляций. Базы данных, которые могут воспользоваться принудительной параметризацией, обычно являются теми, которые испытывают большие объемы параллельных запросов из источников, таких как приложения точки продажи.
Если параметру PARAMETERIZATION присвоено значение FORCED, любое литеральное значение, представленное в инструкции SELECT, INSERT, UPDATEили DELETE , заявленной в любой форме, преобразуется в аргумент в процессе компиляции запроса. Исключениями являются литералы, представленные в следующих конструкциях запроса.
- Инструкции
INSERT...EXECUTE. - Инструкции в теле хранимых процедур, триггеров или определяемых пользователем функций. SQL Server уже использует повторно планы запросов для этих процедур.
- Подготовленные инструкции, которые уже были параметризованы приложением на стороне клиента.
- Инструкции, содержащие вызовы метода XQuery, где метод представлен в контексте, в котором его аргументы обычно параметризуются, например в предложении
WHERE. Если метод отображается в контексте, где его аргументы не будут параметризованы, остальная часть инструкции параметризуется. - Инструкции внутри курсора Transact-SQL. (Инструкции
SELECTвнутри курсоров API-интерфейса параметризуются.) - Устаревшие конструкции запроса.
- Любая инструкция, выполняемая в контексте
ANSI_PADDINGилиANSI_NULLSсо значениемOFF. - Инструкции, содержащие более 2 097 литералов, пригодных для параметризации.
- Инструкции, ссылающиеся на переменные, такие как
WHERE T.col2 >= @bb. - Утверждения, содержащие подсказку запроса
RECOMPILE. - Утверждения, содержащие пункт
COMPUTE. - Утверждения, содержащие условие
WHERE CURRENT OF.
Кроме того, следующие клаузулы запроса не параметризованы. В таких случаях только предложения не параметризируются. Другие предложения в том же запросе могут быть допустимыми для принудительной параметризации.
- Список <select_list> любой инструкции
SELECT. Сюда входят спискиSELECTподзапросов и спискиSELECTвнутри заявленийINSERT. - Инструкции
SELECTво вложенных запросах, представленные внутри инструкцииIF. - Предложения запроса
TOP,TABLESAMPLE,HAVING,GROUP BY,ORDER BY,OUTPUT...INTOилиFOR XML. - Аргументы, прямые или в качестве подвыражений, для
OPENROWSET,OPENQUERY,OPENDATASOURCE,OPENXMLили для любого оператораFULLTEXT. - Аргументы pattern и escape_character в предложении
LIKE. - Аргумент стиля в конструкции
CONVERT. - Целочисленные константы внутри предложения
IDENTITY. - Константы, указанные использованием синтаксиса расширения ODBC.
- Свертываемые константные выражения, являющиеся аргументами операторов
+,-,*,/и%. При рассмотрении возможности принудительной параметризации SQL Server считает выражение пригодным для сокращения констант, если выполняется одно из следующих условий:- В выражении не представлены столбцы, переменные или вложенные запросы.
- Выражение содержит предложение
CASE.
- Аргументы для операторов подсказок запросов. Сюда входит аргумент number_of_rows указания запроса
FAST, аргумент number_of_processors указания запросаMAXDOPи аргумент number указания запросаMAXRECURSION.
Параметризация происходит на уровне отдельных инструкций Transact-SQL. Иными словами, параметризуются отдельные инструкции в пакете. После компиляции параметризированный запрос выполняется в контексте пакета, в котором он был изначально заявлен. Если план выполнения для запроса кэшируется, можно определить, был ли запрос параметризован путем ссылки на столбец SQL динамического административного sys.syscacheobjects представления. Если запрос параметризован, имена и типы данных аргументов располагаются перед текстом заявленного пакета в этом столбце, например (@1 tinyint).
Примечание.
Имена параметров произвольны. Пользователи или приложения не должны опираться на какой-либо конкретный порядок именования. Кроме того, следующие аспекты могут изменяться между версиями SQL Server и накопительными обновлениями (CU): имена параметров, выбор параметризуемых литералов и интервалов в параметризованном тексте.
Типы данных параметров
Когда SQL Server параметризует литералы, аргументы преобразовываются в следующие типы данных.
- Целочисленные литералы, размер которых позволяет, параметризуются в int. Более крупные целочисленные литералы, являющиеся частью предикатов, включающих любой оператор сравнения (включая
<,<=,=,!=,>,>=,!<,!>,<>,ALL,ANY,SOME,BETWEENиIN), параметризуются в numeric(38,0). Большие литералы, не являющиеся частью предикатов, которые включают в себя операторы сравнения, параметризуются в числовой тип с точностью достаточно большой, чтобы поддержать их размер, и с масштабом 0. - Числовые литералы с фиксированной запятой, являющиеся частью предикатов, которые включают в себя операторы сравнения, параметризуются в числовой тип с точностью 38 и масштабом достаточно большим, чтобы поддержать их размер. Числовые литералы с фиксированной запятой, не являющиеся частью предикатов, которые включают в себя операторы сравнения, параметризуются в числовой тип с точностью и масштабом достаточно большими, чтобы поддержать их размер.
- Числовые литералы с плавающей запятой параметризуются в float(53).
- Строковые литералы не в формате Юникод параметризуются в varchar(8000), если размер литерала не превышает 8000 символов, и в varchar(max), если он больше 8000 символов.
- Строковые литералы в Юникоде параметризуются в nvarchar(4000), если они содержат не более 4000 символов Юникода, и в nvarchar(max), если их размер превышает 4000 символов.
- Двоичные литералы параметризуются как varbinary(8000), если размер литерала не превышает 8000 байт. Если он больше 8000 байт, он преобразуется в varbinary(max).
- Денежные литералы параметризуются в тип money.
Рекомендации по использованию принудительной параметризации
Устанавливая для параметра PARAMETERIZATION значение FORCED, примите во внимание следующие сведения.
- Принудительная параметризация, в сущности, преобразует литеральные константы в запросе в параметры при компиляции запроса. Поэтому оптимизатор запросов может выбирать неоптимальные планы для запросов. В частности, уменьшается вероятность того, что оптимизатор запросов сопоставит запрос с индексированным представлением или индексом по вычисляемому столбцу. Он также может выбрать неоптимальные планы для запросов, создаваемых в секционированных таблицах и распределенных секционированных представлениях. Принудительную параметризацию не следует использовать в средах, которые сильно зависят от индексированных представлений и индексов вычисляемых столбцов. Как правило, этот
PARAMETERIZATION FORCEDпараметр следует использовать только опытными специалистами по базам данных после определения того, что это не негативно влияет на производительность. - Распределенные запросы, ссылающиеся на более чем одну базу данных, пригодны для принудительной параметризации, если для параметра
PARAMETERIZATIONзадано значениеFORCEDв базе данных, в контексте которой выполняется запрос. - Установка опции
PARAMETERIZATIONвFORCEDочищает все планы запросов из кэша планов базы данных, за исключением тех, которые в настоящий момент компилируются, перекомпилируются или выполняются. Планы для запросов, которые компилируются или выполняются в момент изменения настроек, параметризуются при следующем выполнении запроса. - Настройка параметра
PARAMETERIZATIONвыполняется в режиме в сети и не требует монопольных блокировок на уровне базы данных. - Текущая настройка параметра
PARAMETERIZATIONсохраняется при повторном присоединении или восстановлении базы данных.
Можно перекрывать поведение принудительной параметризации, предписав выполнение попытки простой параметризации для отдельного запроса, а также всех остальных запросов с таким же синтаксисом, отличающихся только значениями аргументов. Справедливо и обратное: можно потребовать выполнения попытки принудительной параметризации для отдельного набора синтаксически эквивалентных запросов, даже если принудительная параметризация в базе данных отключена. В этих целях используются руководства по планированию.
Примечание.
PARAMETERIZATION Если задан FORCED параметр, отчет о сообщениях об ошибках может отличаться от того, когда задан PARAMETERIZATIONSIMPLE параметр: при принудительной параметризации можно получать несколько сообщений об ошибках, где при простой параметризации сообщений об ошибках будет меньше, а также номера строк, в которых происходят ошибки, могут быть указаны неверно.
Подготовка инструкций SQL
В реляционном механизме SQL Server введена полная поддержка подготовки инструкций Transact-SQL перед их выполнением. Если приложению требуется выполнить инструкцию Transact-SQL несколько раз, то оно может использовать API базы данных следующим образом.
- Однократная подготовка заявления. Инструкция Transact-SQL компилируется в план выполнения.
- Выполняйте предкомпилированный план выполнения каждый раз, когда необходимо выполнить инструкцию. Это избавляет от необходимости повторно компилировать инструкцию Transact-SQL при каждом последующем выполнении. Подготовка и выполнение инструкций контролируется функциями и методами API. Это не является частью языка Transact-SQL. Модель подготовки и выполнения инструкций Transact-SQL поддерживается поставщиком OLE DB для собственного клиента SQL Server, а также драйвером ODBC для собственного клиента SQL Server. При запросе на подготовку поставщик или драйвер отправляет в SQL Server инструкцию с запросом на подготовку инструкции. SQL Server компилирует план выполнения и возвращает его дескриптор поставщику или драйверу. При запросе на выполнение поставщик или драйвер отправляет на сервер запрос на выполнение плана, связанного с этим дескриптором.
Подготовленные инструкции нельзя использовать для создания временных объектов в SQL Server. Подготовленные инструкции не могут ссылаться на системные хранимые процедуры, которые создают временные объекты, такие как временные таблицы. Эти процедуры следует выполнять напрямую.
Злоупотребление моделью подготовки и выполнения может отрицательно сказаться на производительности. Если инструкция выполняется только один раз, то для прямого выполнения потребуется только один цикл приема-передачи с сервером. Для подготовки и выполнения инструкции Transact-SQL, которая выполняется только один раз, потребуется дополнительная сеть для передачи данных: один цикл для подготовки инструкции и один цикл для её выполнения.
Подготовка инструкции более эффективна, если используются маркеры параметров. Предположим, что приложение случайно запросило сведения о продукте из образца базы данных AdventureWorks . Приложение может выполнить это двумя способами.
Используя первый способ, приложение может выполнять отдельный запрос для каждого запрошенного продукта.
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductID = 63;
С помощью второго способа приложение выполняет следующее.
Подготавливается оператор, содержащий маркер параметра (?):
SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductID = ?;Затем оно связывает переменную программы с этим маркером.
Каждый раз, когда требуются сведения о продукте, приложение присваивает связанной переменной ключевое значение и выполняет инструкцию.
Второй способ более эффективен, если инструкция выполняется более трех раз.
В SQL Server модель подготовки и выполнения не дает существенного прироста производительности по сравнению с непосредственным выполнением из-за того, каким образом SQL Server повторно использует планы выполнения. В SQL Server предусмотрены эффективные алгоритмы для сопоставления текущих инструкций Transact-SQL и планов выполнения, созданных для предыдущих случаев выполнения той же инструкции Transact-SQL. Если приложение несколько раз выполняет инструкцию Transact-SQL с маркерами параметров, то со второго выполнения SQL Server будет использовать готовый план выполнения (если этот план не будет удален из кэша планов). Впрочем, у модели подготовки и выполнения есть следующие достоинства:
- Поиск плана выполнения по идентификационному дескриптору более эффективен, чем алгоритмы, используемые для сопоставления инструкции Transact-SQL с существующими планами выполнения.
- приложение может управлять временем создания и повторного использования плана выполнения;
- Модель подготовки и выполнения можно переносить в другие базы данных, включая более ранние версии SQL Server.
Чувствительность параметров
Чувствительность параметров, также известная как "sniffing параметров", относится к процессу, в котором SQL Server определяет текущие значения параметров во время компиляции или перекомпиляции и передает их оптимизатору запросов для использования в генерировании потенциально более эффективных планов выполнения запросов.
Значения параметров сканируются во время компиляции или перекомпиляции для следующих типов пакетов:
- Хранимые процедуры
- Запросы, отправленные командой
sp_executesql - Подготовленные запросы
Дополнительные сведения об устранении неполадок, связанных с хитроумным поиском параметров, см. в:
- Изучение и устранение проблем с учетом параметров
- Параметры и повторное использование планов выполнения
- Оптимизация плана выполнения, чувствительного к параметрам
- Устранение неполадок с запросами, связанными с планом выполнения с учетом параметров, в База данных SQL Azure
- Устранение неполадок запросов, чувствительных к параметрам, с проблемами планов выполнения в Управляемый экземпляр SQL Azure
Когда запрос в SQL Server использует OPTION (RECOMPILE) подсказку, оптимизатор запросов преобразует параметры и локальные переменные в константы времени компиляции, которые могут быть преобразованы и сведены к литералам. Это означает, что во время компиляции оптимизатор знает и может использовать текущие значения параметров и локальных переменных, как они существуют непосредственно перед этой инструкцией. Параметр (RECOMPILE) позволяет оптимизатору создавать наиболее подходящий план запросов, адаптированный к конкретным значениям, и максимально использовать лучшие доступные индексы в процессе выполнения. Для параметров этот процесс относится не к значениям, первоначально переданным пакету или хранимой процедуре, но к их значениям во время повторной компиляции. Эти значения могли быть изменены в ходе процедуры перед достижением инструкции, содержащей RECOMPILE. Это поведение может повысить производительность запросов с высокой переменной или сложенными входными данными.
Локальные переменные
Если запрос использует локальные переменные, SQL Server не может снюхать их значения во время компиляции, поэтому он оценивает кратность с помощью доступной статистики или эвристики. Если статистика существует, обычно используется значение All Density (также известное как средняя плотность) из статистической гистограммы для оценки количества строк, соответствующих предикату. Однако, если для столбца нет статистики, SQL Server использует эвристические оценки, предполагая селективность 10% для предикатов равенства и 30% для предикатов неравенства и диапазонов, что может привести к менее точным планам выполнения. Ниже приведен пример запроса, использующего локальную переменную.
DECLARE @ProductId INT = 100;
SELECT * FROM Products WHERE ProductId = @ProductId;
В этом случае SQL Server не использует значение 100 для оптимизации запроса. В нем используется общая оценка.
Параллельная обработка запросов
SQL Server обеспечивает параллельную обработку запросов, оптимизирующую выполнение запросов и операции с индексами на компьютерах, где установлено несколько микропроцессоров (ЦП). Так как SQL Server может выполнять операции запроса или индекса параллельно с помощью нескольких рабочих потоков операционной системы, операция может быть выполнена быстро и эффективно.
Во время оптимизации запроса SQL Server пытается обнаружить запросы и операции с индексами, которые можно ускорить за счет параллельного выполнения. Для таких запросов SQL Server вставляет в план выполнения операторы обмена, чтобы подготовить запрос к параллельной обработке. Оператор обмена — это оператор в плане выполнения запроса, который обеспечивает управление процессом, перераспределение данных и управление потоком. Оператор обмена включает логические операторы Distribute Streams, Repartition Streams и Gather Streams в качестве подтипов, один или несколько из которых могут появляться в выводе Showplan плана запроса для параллельного запроса.
Внимание
Некоторые конструкции препятствуют использованию параллелизма для всего плана выполнения или его частей в SQL Server.
Конструкции, которые блокируют параллелизм, включают перечисленные ниже.
Скалярные UDF
Дополнительные сведения об определяемых пользователем скалярных функциях см. в разделе Создание определяемых пользователем функций. Начиная с SQL Server 2019 (15.x), ядро СУБД SQL Server может выполнять встроение этих функций и использовать параллелизм во время обработки запросов. Для получения дополнительной информации о встраивании скалярных пользовательских функций см. раздел Интеллектуальная обработка запросов в базах данных SQL.Удаленный запрос
Дополнительные сведения о Remote Query см. в разделе Справочник по логическим и физическим операторам Showplan.Динамические курсоры
Дополнительные сведения о курсорах см. в описании DECLARE CURSOR.Рекурсивные запросы
Дополнительные сведения о рекурсии см. в разделах Рекомендации по созданию и использованию рекурсивных обобщенных табличных выражений и Рекурсия в T-SQL.Функции с табличным значением с несколькими инструкциями (MSTVF)
Дополнительные сведения о функциях MSTVF см. в разделе Создание определяемых пользователем функций (ядро СУБД).Ключевое слово TOP
Дополнительные сведения см. в разделе TOP (Transact-SQL).
План выполнения запроса может содержать атрибут NonParallelPlanReason в элементе QueryPlan , который описывает, почему параллелизм не использовался. Значения этого атрибута:
| Значение NonParallelPlanReason | Описание |
|---|---|
| MaxDOPSetToOne | Максимальной степени параллелизма задано значение 1. |
| Предполагаемый DOP равен одному | Ожидаемая степень параллелизма — 1. |
| Нет параллельного выполнения с удаленным запросом | Параллелизм не поддерживается для удаленных запросов. |
| NoParallelDynamicCursor | Параллельные планы не поддерживаются для динамических курсоров. |
| Отсутствие параллельного быстрого сдвига курсора | Курсоры ускоренной перемотки вперед не поддерживают параллельные планы выполнения. |
| Без параллельного получения курсора по закладке | Параллельные планы не поддерживаются курсорами, которые извлекают данные по закладкам. |
| НетПараллельногоСозданияИндексаВНеEnterpriseВерсии | Параллельное создание индексов не поддерживается в выпусках, отличных от Enterprise. |
| Нет параллельного планирования в Desktop или Express Edition | Выпуски Desktop и Express не поддерживают параллельные планы. |
| Непараллелизуемая внутренняя функция | Запрос ссылается на встроенную функцию, которая не поддерживает параллелизм. |
| Пользовательская функция CLR требует доступ к данным | Параллелизм не поддерживается для функции CLR, которая требует доступа к данным. |
| Пользовательские функции TSQL не параллелизуемы | Запрос ссылается на определяемую пользователем функцию T-SQL, которая не была параллелизируемой. |
| Транзакции таблицы переменной не поддерживают параллельные вложенные транзакции. | Транзакции табличных переменных не поддерживают параллельные вложенные транзакции. |
| DMLЗапросВозвращаетРезультатКлиенту | Запрос DML возвращает выходные данные клиенту и не параллелизуется. |
| Смешанная последовательная и параллельная онлайн сборка индекса не поддерживается | Неподдерживаемый набор последовательных и параллельных планов для одной сборки индекса в сети. |
| Не удалось создать корректный параллельный план (CouldNotGenerateValidParallelPlan) | Сбой проверки параллельного плана, возврат к последовательному плану. |
| NoParallelForMemoryOptimizedTables | Таблицы OLTP в памяти, на которые ссылаются, не поддерживают параллелизм. |
| Нет параллельного выполнения DML на таблице с оптимизированной памятью | DML-операции на таблице In-Memory OLTP не поддерживают параллелизм. |
| НетПараллельностиДляНативноСкомпилированногоМодуля | Нативно скомпилированные модули, на которые имеются ссылки, не поддерживают параллелизм. |
| СозданиеБезДиапазоновВосстанавливаемого | Ошибка создания диапазона для возобновляемой операции. |
После вставки операторов обмена получается план параллельного выполнения запроса. План параллельного выполнения запроса может использовать несколько рабочих потоков. План последовательного выполнения, который используется для обработки непараллельных (серийных) запросов, использует только один рабочий поток. Фактическое количество рабочих потоков для параллельного выполнения запроса определяется при инициализации плана выполнения запроса и зависит от сложности и степени параллелизма плана.
Степень параллелизма (DOP) определяет максимальное количество используемых ЦП; Это не означает количество используемых рабочих потоков. Ограничение DOP задается для каждой задачи. Это не ограничение на один запрос или один запрос к базе данных. Это значит, что во время параллельного выполнения один запрос может порождать несколько задач, назначаемых планировщику. Более процессоров, чем указано MAXDOP, могут использоваться одновременно в любой точке выполнения запроса, если различные задачи выполняются одновременно. Дополнительные сведения см. в статье Руководство по архитектуре потоков и задач.
Оптимизатор запросов SQL Server не использует параллельный план выполнения для запроса, если одно из следующих условий имеет значение true:
- План последовательного выполнения является тривиальным или не превышает пороговое значение затрат для параметра параллелизма.
- План последовательного выполнения имеет более низкую общую стоимость поддерев, чем любой параллельный план выполнения, исследуемый оптимизатором.
- Запрос содержит скалярные или реляционные операторы, которые не могут выполняться параллельно. Определенные операторы могут привести к выполнению участка запроса или всего плана целиком в последовательном режиме.
Примечание.
Общая предполагаемая стоимость поддерев параллельного плана может быть ниже порогового значения затрат для параметра параллелизма. Это означает, что общая оценочная стоимость поддерева последовательного плана превысила её, и был выбран план запроса с более низкой общей оценочной стоимостью поддерева.
Степень параллелизма (DOP)
SQL Server автоматически обнаруживает высшую степень параллелизма для каждого экземпляра параллельного выполнения запроса или операции языка DDL с индексами. Это осуществляется на основе следующих критериев.
Работает ли SQL Server на компьютере с несколькими микропроцессорами или ЦП, например симметричным многопроцессорным компьютером (SMP). Использовать параллельные запросы могут только компьютеры, имеющие более одного ЦП.
Достаточно ли доступных рабочих потоков. Каждый запрос или операция с индексами требуют определенного числа рабочих потоков. Для выполнения параллельного плана требуется больше рабочих потоков, чем для выполнения последовательного плана, и по мере увеличения степени параллелизма число необходимых рабочих потоков возрастает. Если требование рабочего потока параллельного плана для определенной степени параллелизма не может быть удовлетворено, ядро базы данных SQL Server автоматически уменьшает степень параллелизма или полностью отказывается от параллельного плана в указанном контексте рабочей нагрузки. В этом случае выполняется последовательный план (один поток рабочего процесса).
Тип выполняемого запроса или операции с индексами. Операции с индексами, которые создают или перестраивают индекс или удаляют кластеризованный индекс и запросы, интенсивно использующие циклы ЦП, являются лучшими кандидатами для параллельного плана. Например, хорошими кандидатами являются соединения больших таблиц, агрегация больших данных и сортировка больших результирующих наборов. Простые запросы, часто встречающиеся в приложениях для обработки транзакций, обнаруживают, что требуемая дополнительная координация для параллельного выполнения запроса перевешивает потенциальное увеличение производительности. Чтобы отличить запросы, которые пользуются параллелизмом и теми, которые не получают преимущества, SQL Server ядро СУБД сравнивает предполагаемые затраты на выполнение операции запроса или индекса с пороговым значением параллелизма. Пользователи могут изменить значение по умолчанию 5 при помощи sp_configure, если при надлежащем тестировании найдено другое значение, которое больше подходит для выполнения рабочей нагрузки.
Достаточно ли количество строк, подлежащих обработке. Если оптимизатор запросов определяет, что количество строк слишком низко, он не вводит операторы обмена для распределения строк. Таким образом, операторы выполняются последовательно. Обработка операторов в последовательном плане позволяет избежать сценариев, когда стоимость запуска, распределения и координации превышает преимущества, достигнутые параллельной обработкой оператора.
Доступна ли текущая статистика распределения. Если самая высокая степень параллелизма невозможна, рассматриваются более низкие уровни, прежде чем отказаться от параллельного плана. Например, при создании кластеризованного индекса в представлении статистика распределения не может быть оценена, так как кластеризованный индекс еще не существует. В этом случае SQL Server ядро СУБД не может обеспечить самую высокую степень параллелизма для операции индекса. Однако некоторые операторы, такие как сортировка и сканирование, по-прежнему могут выигрывать от параллельной обработки.
Примечание.
Параллельные операции с индексами доступны только в выпусках SQL Server Developer Edition, Evaluation Edition и Enterprise Edition.
Во время выполнения Ядро базы данных SQL Server определяет, позволяют ли текущая системная рабочая нагрузка и сведения о конфигурации, описанные ранее, параллельное выполнение. Если параллельное выполнение оправдано, SQL Server ядро СУБД определяет оптимальное количество рабочих потоков и распределяет выполнение параллельного плана по этим рабочим потокам. Если запрос или операция с индексами начинает параллельно выполняться в нескольких рабочих потоках, это же число рабочих потоков используется до тех пор, пока операция не будет завершена. SQL Server ядро СУБД повторно проверяет оптимальное количество решений рабочего потока каждый раз, когда план выполнения извлекается из кэша планов. Например, при первом выполнении запроса может использоваться последовательный план, при повторном выполнении того же запроса — параллельный план с тремя рабочими потоками, при третьем выполнении — параллельный план с четырьмя рабочими потоками.
Операторы обновления и удаления в параллельном плане выполнения запросов выполняются последовательно, но предложение WHERE инструкции UPDATE или DELETE может выполняться параллельно. В таком случае изменения фактических данных последовательно применяются к базе данных.
До SQL Server 2012 (11.x) оператор вставки также выполняется последовательно. Однако часть SELECT инструкции INSERT может выполняться параллельно. В таком случае изменения фактических данных последовательно применяются к базе данных.
Начиная с SQL Server 2014 (12.x) и уровня совместимости базы данных 110 оператор SELECT ... INTO можно выполнять параллельно. Другие формы операторов вставки работают так же, как описано для SQL Server 2012 (11.x).
Начиная с SQL Server 2016 (13.x) и уровня совместимости базы данных 130, оператор INSERT ... SELECT может выполняться параллельно при вставке в кучи или кластеризованные индексы столбцов (CCI), используя подсказку TABLOCK. Операции вставки в локальные временные таблицы (определяемые префиксом #) и глобальные временные таблицы (определяемые префиксами ##) также поддерживают параллелизм с использованием указания TABLOCK. Дополнительные сведения см. в статье Инструкция INSERT (Transact-SQL).
Статические курсоры и курсоры, управляемые набором ключей, могут быть заполнены параллельными планами выполнения. Однако поведение динамических курсоров может поддерживаться только последовательным выполнением. Оптимизатор запросов всегда формирует последовательный план выполнения для запроса, являющегося частью динамического курсора.
Переопределение степеней параллелизма
Максимальная степень параллелизма задает количество процессоров, используемых при одновременном исполнении планов. Эту конфигурацию можно задать на различных уровнях:
Уровень сервера, с использованием параметра конфигурации сервера
max degree of parallelism (MAXDOP) . Область применения: SQL ServerПримечание.
SQL Server 2019 (15.x) представляет автоматические рекомендации по настройке параметра конфигурации сервера MAXDOP во время установки. Пользовательский интерфейс программы установки позволяет либо принять рекомендуемые параметры, либо задать свое значение. Дополнительные сведения см. в разделе Конфигурация ядра СУБД — страница MaxDOP.
Уровень рабочей нагрузки с помощью параметра конфигурации группы рабочей нагрузки MAX_DOP в диспетчере ресурсов.
Область применения: SQL ServerУровень базы данных с использованием конфигурации области видимости базы данных
MAXDOP .Применяется к: SQL Server и База данных SQL Azure На уровне инструкции запроса или индекса — с помощью подсказки запросаMAXDOP или параметра индекса MAXDOP. Например, с помощью параметра MAXDOP можно увеличить или уменьшить число процессоров, выделенных для операций с индексами в сети. Таким образом, можно сбалансировать ресурсы, используемые операцией индекса, с одновременными пользователями.
Применимо к: SQL Server и База данных SQL Azure
Установка параметра максимального уровня параллелизма значение 0 (по умолчанию) позволяет SQL Server использовать все доступные процессоры до максимум 64 процессоров в параллельном выполнении плана. Хотя SQL Server устанавливает целевой показатель для работы в среде выполнения с 64 логическими процессорами, если параметр MAXDOP установлен на 0, при необходимости можно вручную установить другое значение. Назначение параметру MAXDOP значения 0 для запросов и индексов позволяет SQL Server использовать все доступные процессоры (максимально допустимое количество процессоров равно 64) для данных запросов и индексов при выполнении параллельного плана. MAXDOP — это не принудительное значение для всех параллельных запросов, а предварительное назначение для всех запросов, доступных для параллелизма. Это означает, что если в среде выполнения недостаточно рабочих потоков, запрос может выполняться с более низкой степенью параллелизма, чем параметр конфигурации сервера MAXDOP.
Совет
Для получения дополнительной информации см. рекомендации MAXDOP по настройке MAXDOP на уровне сервера, базы данных, запроса или подсказки.
Пример параллельного запроса
В нижеследующем запросе подсчитывается количество заказов, размещенных в течение указанного квартала, начиная с 1 апреля 2000, в которых хотя бы один элемент из списка заказанных товаров был получен заказчиком позже фиксированной даты. В этом запросе представлен подсчет таких заказов, сгруппированных в соответствии со срочностью каждого заказа и отсортированных в возрастающем порядке.
В этом примере используются теоретические имена таблицы и столбцов.
SELECT o_orderpriority, COUNT(*) AS Order_Count
FROM orders
WHERE o_orderdate >= '2000/04/01'
AND o_orderdate < DATEADD (mm, 3, '2000/04/01')
AND EXISTS
(
SELECT *
FROM lineitem
WHERE l_orderkey = o_orderkey
AND l_commitdate < l_receiptdate
)
GROUP BY o_orderpriority
ORDER BY o_orderpriority
Предположим, что в таблицах lineitem и orders определены следующие индексы:
CREATE INDEX l_order_dates_idx
ON lineitem
(l_orderkey, l_receiptdate, l_commitdate, l_shipdate)
CREATE UNIQUE INDEX o_datkeyopr_idx
ON ORDERS
(o_orderdate, o_orderkey, o_custkey, o_orderpriority)
Вот один из возможных параллельных планов, созданный для запроса, показанного выше:
|--Stream Aggregate(GROUP BY:([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=COUNT(*)))
|--Parallelism(Gather Streams, ORDER BY:
([ORDERS].[o_orderpriority] ASC))
|--Stream Aggregate(GROUP BY:
([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=Count(*)))
|--Sort(ORDER BY:([ORDERS].[o_orderpriority] ASC))
|--Merge Join(Left Semi Join, MERGE:
([ORDERS].[o_orderkey])=
([LINEITEM].[l_orderkey]),
RESIDUAL:([ORDERS].[o_orderkey]=
[LINEITEM].[l_orderkey]))
|--Sort(ORDER BY:([ORDERS].[o_orderkey] ASC))
| |--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([ORDERS].[o_orderkey]))
| |--Index Seek(OBJECT:
([tpcd1G].[dbo].[ORDERS].[O_DATKEYOPR_IDX]),
SEEK:([ORDERS].[o_orderdate] >=
Apr 1 2000 12:00AM AND
[ORDERS].[o_orderdate] <
Jul 1 2000 12:00AM) ORDERED)
|--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([LINEITEM].[l_orderkey]),
ORDER BY:([LINEITEM].[l_orderkey] ASC))
|--Filter(WHERE:
([LINEITEM].[l_commitdate]<
[LINEITEM].[l_receiptdate]))
|--Index Scan(OBJECT:
([tpcd1G].[dbo].[LINEITEM].[L_ORDER_DATES_IDX]), ORDERED)
На рисунке показан план запросов, который выполняется со степенью параллелизма, равной 4, и включает соединение двух таблиц.
Параллельный план содержит три оператора параллелизма. Оба оператора, Index Seek для индекса o_datkey_ptr и Index Scan для индекса l_order_dates_idx, выполняются параллельно. В результате создаются несколько эксклюзивных потоков. Это можно определить по ближайшим операторам параллелизма над операторами Index Scan и Index Seek соответственно. Оба перераспределяют тип обмена. То есть они всего лишь перегруппируют данные между потоками и выдают в результате столько же потоков на выходе, сколько их было на входе. Количество потоков равно степени параллелизма.
Оператор параллелизма над оператором Index Scan l_order_dates_idx перераспределяет входные потоки, используя значение L_ORDERKEY как ключ. В этом случае те же значения L_ORDERKEY оказываются в том же выходном потоке. Одновременно в выходных потоках сохраняется порядок в столбце L_ORDERKEY для соответствия требованиям оператора Merge Join к входным данным.
Оператор параллелизма над оператором Index Seek перераспределяет свои входные потоки с использованием значения O_ORDERKEY. Поскольку входные данные не отсортированы по значениям столбца O_ORDERKEY, и это столбец соединения в операторе Merge Join, оператор сортировки между операторами параллелизма и объединения обеспечивает сортировку входных данных для оператора Merge Join по столбцам соединения. Оператор Sort, как и оператор Merge Join, выполняется параллельно.
Первый оператор параллелизма объединяет результаты из нескольких потоков в один. Результаты частичной статистической обработки, выполняемой оператором Stream Aggregate под оператором параллелизма, затем собираются в единое значение SUM для каждого отдельного значения O_ORDERPRIORITY в операторе Stream Aggregate над оператором параллелизма. Так как этот план состоит из двух сегментов обмена со степенью параллелизма, равной 4, в этом плане используется восемь рабочих потоков.
Дополнительные сведения об операторах, которые используются в данном примере, см. справочник Showplan Logical and Physical Operators Reference.
Параллельные операции с индексами
Планы запросов, созданные для операций создания или перестроения индекса либо удаления кластеризованного индекса, поддерживают возможность параллельной обработки в нескольких рабочих потоках на многопроцессорных компьютерах.
Примечание.
Параллельные операции индексов доступны только в выпуск Enterprise, начиная с SQL Server 2008 (10.0.x).
SQL Server использует те же алгоритмы, чтобы определить степень параллелизма (общее количество отдельных рабочих потоков для выполнения) для операций с индексами, как и для других запросов. Максимальная степень параллелизма для операции с индексом определяется параметром конфигурации сервера max degree of parallelism . Значение максимальной степени параллелизма можно переопределить для отдельных операций с индексами установкой параметра индекса MAXDOP в CREATE INDEX, ALTER INDEX, DROP INDEX и ALTER TABLE.
Когда SQL Server ядро СУБД создает план выполнения индекса, число параллельных операций устанавливается в качестве наименьшего значения из следующих:
- Число микропроцессоров (ЦП) в компьютере.
- Число, указанное в опции конфигурации сервера "максимальная степень параллелизма".
- Количество процессоров, которые еще не превысили порог рабочего объема для потоков рабочих SQL Server.
Например, на компьютере с восемью ЦП, на котором максимальная степень параллелизма равна 6, для операций с индексами создается не более шести параллельных рабочих потоков. Если пять процессоров на компьютере превышают пороговое значение SQL Server при построении плана выполнения для индекса, план выполнения указывает только три параллельных рабочих потока.
Главные фазы параллельных операций с индексами таковы.
- Координирующий рабочий поток быстро и случайным образом просматривает таблицу для оценки распределения ключей индекса. Координирующий рабочий поток устанавливает ключевые границы, образующие число диапазонов ключей, равное степени параллелизма. Каждый диапазон должен покрывать примерно одинаковое число строк. Например, если в таблице четыре миллиона строк, а степень параллелизма равна 4, то координирующий рабочий поток определит ключевые значения, которые разделят все строки на четыре набора строк по одному миллиону строк в каждом. Если не удается установить достаточное количество диапазонов ключей для использования всех ЦП, степень параллелизма уменьшается соответствующим образом.
- Координирующий рабочий поток запускает рабочие потоки, количество которых равно степени параллелизма операций, и ожидает завершения этих потоков. Каждый из рабочих потоков просматривает базовую таблицу с использованием фильтра, который отделяет только строки со значениями ключей в диапазоне, назначенном этому рабочему потоку. Каждый рабочий поток создает структуру индекса для строк в своем диапазоне ключей. В случае секционированного индекса каждый из рабочих потоков создает заданное число секций. Разделы не разделяются между рабочими потоками.
- После завершения работы всех параллельных рабочих потоков координирующий рабочих поток связывает компоненты индекса в единый индекс. Эта фаза применяется только для операций с индексами оффлайн.
В отдельных инструкциях CREATE TABLE или ALTER TABLE могут содержаться несколько ограничений, требующих создания индекса. Эти операции создания индекса выполняются последовательно, хотя каждая отдельная операция создания индекса может быть параллельной операцией на компьютере с несколькими ЦП.
Архитектура распределенных запросов
Microsoft SQL Server поддерживает два метода обращения к разнородным источникам данных OLE DB в инструкциях языка Transact-SQL.
Имена связанных серверов
Системные хранимые процедурыsp_addlinkedserverиsp_addlinkedsrvloginиспользуются для задания серверного имени источнику данных OLE DB. К объектам на этих связанных серверах можно обращаться в инструкциях языка Transact-SQL по четырехкомпонентным именам. Например, если имя связанного сервераDeptSQLSrvrопределено для другого экземпляра SQL Server, для обращения к таблице на таком сервере используется следующая инструкция:SELECT JobTitle, HireDate FROM DeptSQLSrvr.AdventureWorks2022.HumanResources.Employee;Имя связанного сервера можно также указать в инструкции
OPENQUERYдля открытия набора строк из источника данных OLE DB. К этому набору строк можно обращаться в инструкциях языка Transact-SQL так же, как и к таблице.Имена специальных коннекторов
Для нечастых обращений к источнику данных используются функцииOPENROWSETилиOPENDATASOURCE, которым задаются данные, необходимые для подключения к связанному серверу. Затем можно обращаться к набору строк в инструкциях языка Transact-SQL тем же путем, что и к таблице.SELECT * FROM OPENROWSET('Microsoft.Jet.OLEDB.4.0', 'c:\MSOffice\Access\Samples\Northwind.mdb';'Admin';''; Employees);
В SQL Server для коммуникации между реляционным модулем и подсистемой хранилища используется технология OLE DB. Реляционный модуль разбивает каждую инструкцию языка Transact-SQL на последовательные операции над простыми наборами строк OLE DB, открываемые подсистемой хранилища из базовых таблиц. Это означает, что реляционный механизм может также открывать простые наборы строк OLE DB на любом источнике данных OLE DB.
В реляционном механизме используется прикладной программный интерфейс (API) OLE DB для открытия наборов строк на связанных серверах, выборки строк и управления транзакциями.
Для каждого источника данных OLE DB, доступ к которому осуществляется как к связанному серверу, на сервере с запущенной службой SQL Server должен быть поставщик OLE DB. Набор операций языка Transact-SQL, которые можно использовать с конкретным источником данных OLE DB, зависит от возможностей поставщика OLE DB.
Для каждого экземпляра SQL Server члены фиксированной серверной роли sysadmin могут включить или отключить использование имен соединителей, задаваемых по мере необходимости, для поставщика OLE DB с помощью свойства SQL Server DisallowAdhocAccess. Если включен нерегламентированный доступ, любой пользователь, вошедший в этот экземпляр, может выполнять инструкции Transact-SQL, содержащие имена нерегламентированных соединителей, ссылаясь на любой источник данных в сети, к которому можно получить доступ с помощью этого поставщика OLE DB. Чтобы управлять доступом к источникам данных, члены sysadmin роли могут отключить нерегламентированный доступ для этого поставщика OLE DB, тем самым ограничивая пользователей только источниками данных, на которые ссылаются связанные имена серверов, определенные администраторами. По умолчанию для поставщика OLE DB SQL Server включен специальный доступ и отключен для всех других поставщиков OLE DB.
Распределенные запросы могут давать пользователям доступ к другому источнику данных (например, файлам, нереляционным источникам данных типа службы Active Directory и т. д.) с помощью контекста безопасности учетной записи Microsoft Windows, под которой запущена служба SQL Server. SQL Server имитирует имя входа соответствующим образом для имен входа Windows; однако это невозможно для имен входа SQL Server. Это может позволить пользователю распределенного запроса получить доступ к другому источнику данных, для которого у них нет разрешений, но учетная запись, в которой выполняется служба SQL Server, имеет разрешения. Для указания конкретных имен входа, которым будет разрешен доступ к соответствующему связанному серверу, используется процедура sp_addlinkedsrvlogin . Этот элемент управления недоступен для нерегламентированных имен, поэтому используйте осторожность при включении поставщика OLE DB для нерегламентированного доступа.
По возможности SQL Server принудительно отправляет реляционные операции (соединения, ограничения, проекции, сортировки и группировки по операциям) к источнику данных OLE DB. SQL Server не используется по умолчанию для сканирования базовой таблицы в SQL Server и выполнения реляционных операций. Эта служба запрашивает поставщика OLE DB, чтобы определить уровень поддерживаемой им грамматики SQL, и на основе этих данных направляет поставщику максимально возможное число реляционных операций.
SQL Server указывает поставщику OLE DB механизм возвращения статистики распределения ключевых значений в пределах источника данных OLE DB. Это позволяет оптимизатору запросов SQL Server лучше проанализировать шаблон данных в источнике данных на соответствие требованиям для каждой инструкции Transact-SQL, что позволяет более эффективно создавать оптимальные планы выполнения.
Улучшения обработки запросов для секционированных таблиц и индексов
SQL Server 2008 (10.0.x) улучшил производительность обработки запросов в секционированных таблицах для многих параллельных планов, изменяет способ представления параллельных и серийных планов, а также улучшает сведения о секционировании, предоставляемые как в планах выполнения во время компиляции, так и во время выполнения. В этой статье описываются эти улучшения, приводятся рекомендации по интерпретации планов выполнения запросов секционированных таблиц и индексов, а также рекомендации по улучшению производительности запросов в секционированных объектах.
Примечание.
До SQL Server 2014 (12.x) секционированные таблицы и индексы поддерживаются только в выпусках SQL Server Enterprise, Developer и Evaluation. Начиная с SQL Server 2016 (13.x) с пакетом обновления 1 (SP1), секционированные таблицы и индексы также поддерживаются в выпуске SQL Server Standard.
Новая операция поиска с поддержкой разбиения на разделы
В SQL Server внутреннее представление секционированной таблицы изменено таким образом, что таблица представляется обработчику запросов как индекс по нескольким столбцам с PartitionID в качестве начального столбца.
PartitionID представляет собой скрытый внутренний вычисляемый столбец для представления ID секции, содержащей определенную строку. Например, предположим, что таблица T, определенная как T(a, b, c), секционирована по столбцу a и содержит кластеризованный индекс по столбцу b. В SQL Server эта секционированная таблица обрабатывается внутри как несекционированная таблица со схемой T(PartitionID, a, b, c) и кластеризованным индексом по составному ключу (PartitionID, b). Это позволяет оптимизатору запросов выполнять операции поиска на основе PartitionID по любой секционированной таблице или индексу.
Устранение разделов теперь осуществляется в этом процессе поиска.
Кроме того, оптимизатор запросов расширен таким образом, что операция поиска или сканирования с одним условием может быть выполнена по PartitionID (в качестве логического начального столбца) и, возможно, по другим ключевым столбцам индекса. После этого может быть выполнен поиск второго уровня с другим условием по одному или нескольким дополнительным столбцам для каждого уникального значения, удовлетворяющего критериям операции поиска первого уровня. Операция, называемая "просмотр с пропуском", позволяет оптимизатору запросов выполнять операцию поиска или просмотра по одному условию для определения секций, к которым будет осуществляться доступ, и операцию поиска индекса второго уровня с помощью этого оператора для выборки строк из этих секций, удовлетворяющих другому условию. Например, рассмотрим следующий запрос.
SELECT * FROM T WHERE a < 10 and b = 2;
В данном примере, предположим, таблица T, определенная как T(a, b, c), секционирована по столбцу a и содержит кластеризованный индекс по столбцу b. Границы секции для таблицы T определены следующей функцией секционирования:
CREATE PARTITION FUNCTION myRangePF1 (int) AS RANGE LEFT FOR VALUES (3, 7, 10);
Для разрешения запроса обработчик запросов выполняет операцию поиска первого уровня для нахождения каждой секции, содержащей строки, удовлетворяющие условию T.a < 10. Это позволяет выявить секции, к которым необходимо получить доступ. В каждой выявленной секции обработчик выполняет поиск второго уровня по кластеризованному индексу по столбцу b для нахождения строк, удовлетворяющих условию T.b = 2 и T.a < 10.
На следующем рисунке изображено логическое представление операции пропускающего сканирования. На нем изображена таблица T с данными в столбцах a и b. Секции пронумерованы от 1 до 4, а границы секций показаны вертикальными штриховыми линиями. Операция поиска первого уровня для секций (на иллюстрации не показана) определила, что секции 1, 2 и 3 удовлетворяют условию поиска, предполагаемого секционированием, определенным для таблицы и предиката по столбцу a. то есть T.a < 10. Путь, который проходит часть операции skip scan по поиску второго уровня, изображен изогнутой линией. Фактически операция просмотра с пропуском выполняет поиск строк, удовлетворяющих условию b = 2в каждой их этих секций. Общие затраты на выполнение операции по пропуску при сканировании такие же, как и у трех отдельных запросов по индексу.
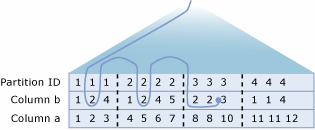
Отображение сведений о секционированиях в планах выполнения запросов
Планы выполнения запросов в секционированных таблицах и индексах могут быть исследованы с помощью инструкций SET языка Transact-SQL, SET SHOWPLAN_XML или SET STATISTICS XML, либо с помощью графического представления плана выполнения в среде SQL Server Management Studio. Например, можно отобразить план выполнения на этапе компиляции, выбрав Отобразить предполагаемый план выполнения на панели инструментов Редактора запросов, а план выполнения во время выполнения, выбрав Включить фактический план выполнения.
С помощью этих средств можно получить следующую информацию:
- операции, такие как
scans,seeks,inserts,updates,mergesиdeletes, которые осуществляют доступ к секционированным таблицам или индексам. - разделы, к которым запрос получает доступ например, в планах времени выполнения приведено общее число секций, к которым получен доступ, и диапазоны смежных секций, к которым получен доступ;
- Когда операция пропуска используется в операции поиска или сканирования для извлечения данных из одного или нескольких разделов.
Улучшения сведений о разделах
SQL Server содержит расширенные сведения о секционировании как для планов времени компиляции, так и для планов времени выполнения. Планы выполнения теперь содержат следующую информацию.
- Дополнительный атрибут
Partitionedуказывает, что оператор, напримерseek,scan,insert,update,mergeилиdelete, выполняется в отношении секционированной таблицы. - Новый элемент
SeekPredicateNewс вложенным элементомSeekKeys, который включаетPartitionIDв роли ведущего столбца индекса и условия фильтра, определяющие диапазонные поисковые запросы вPartitionID. Наличие двух подэлементовSeekKeysуказывает на то, что в отношенииPartitionIDиспользуется операция просмотра с пропуском. - Сводные данные об общем числе секций, к которым получен доступ. Эта информация доступна только в планах выполнения.
Для демонстрации отображения этой информации как в графическом плане выполнения, так и в отчете XML Showplan рассмотрим следующий запрос в секционированной таблице fact_sales. Этот запрос обновляет данные в двух секциях.
UPDATE fact_sales
SET quantity = quantity - 2
WHERE date_id BETWEEN 20080802 AND 20080902;
На следующем рисунке показаны свойства оператора Clustered Index Seek в плане выполнения этого запроса в среде выполнения. Чтобы просмотреть определение fact_sales таблицы и определение партиции, см. раздел "Пример" в этой статье.

Разделённый атрибут
Если оператор, такой как поиск индекса, выполняется в секционированной таблице или индексе, Partitioned атрибут отображается в плане времени компиляции и времени выполнения и имеет True значение (1). Атрибут не отображается, если задано значение False (0).
Атрибут Partitioned может встречаться в следующих физических и логических операторах:
- Сканирование таблиц
- Сканирование индекса
- Поиск в индексе
- Вставить
- Обновить
- Удалить
- Слияние
Как показано на предыдущей иллюстрации, этот атрибут отображается в свойствах оператора, в котором он определен. В отчете инструкции XML Showplan этот атрибут появляется как Partitioned="1" в узле RelOp оператора, в котором он определен.
Новый предикат поиска
В выводе XML Showplan элемент SeekPredicateNew появляется в операторе, в котором он определен. Он может содержать до двух экземпляров подэлемента SeekKeys. Первый элемент SeekKeys определяет операцию поиска первого уровня на уровне идентификатора секции логического индекса. То есть эта операция поиска определяет секции, к которым должен быть осуществлен доступ для удовлетворения условий запроса. Второй элемент SeekKeys определяет часть операции пропуска сканирования на втором уровне поиска, которая выполняется в каждом разделе, определенном поиском первого уровня.
Сводная информация о разделе
В планах времени выполнения сводка по секциям содержит данные о числе секций, к которым осуществлен доступ, и фактический перечень секций, к которым осуществлен доступ. С помощью этих данных можно проверить, к правильным ли секциям обращается запрос и исключены ли из рассмотрения остальные секции.
Предоставляется следующая информация: Actual Partition Countи Partitions Accessed.
Actual Partition Count — это общее число секций, к которым запрос получает доступ.
Partitions Accessed в выводе XML Showplan представляет собой сводные данные по секциям, которые появляются в новом элементе RuntimePartitionSummary в узле RelOp оператора, в котором он определен. В следующем примере показано содержимое элемента RuntimePartitionSummary , указывающее, что получен доступ только к двум секциям (секции 2 и 3).
<RunTimePartitionSummary>
<PartitionsAccessed PartitionCount="2" >
<PartitionRange Start="2" End="3" />
</PartitionsAccessed>
</RunTimePartitionSummary>
Отображение информации о разделе с использованием других методов Showplan
Методы SHOWPLAN_ALL, SHOWPLAN_TEXT, и STATISTICS PROFILE Showplan не сообщают информацию о разделах, описанную в этой статье, кроме одного исключения. Как часть предиката SEEK , секции, к которым необходимо получить доступ, обозначаются предикатом по диапазону в вычисляемом столбце, представляющем идентификатор секций. В следующем примере показан предикат SEEK для оператора Clustered Index Seek . К секциям 2 и 3 происходит обращение, и оператор поиска производит фильтрацию по строкам, удовлетворяющим условию date_id BETWEEN 20080802 AND 20080902.
|--Clustered Index Seek(OBJECT:([db_sales_test].[dbo].[fact_sales].[ci]),
SEEK:([PtnId1000] >= (2) AND [PtnId1000] \<= (3)
AND [db_sales_test].[dbo].[fact_sales].[date_id] >= (20080802)
AND [db_sales_test].[dbo].[fact_sales].[date_id] <= (20080902))
ORDERED FORWARD)
Интерпретация планов выполнения для секционированных куч
Секционированная куча обрабатывается как логический индекс по идентификатору секции. Устранение секций на секционированной куче представлено в плане выполнения в виде оператора Table Scan с предикатом SEEK по идентификатору секции. Следующий пример отображает сведения Showplan:
|-- Table Scan (OBJECT: ([db].[dbo].[T]), SEEK: ([PtnId1001]=[Expr1011]) ORDERED FORWARD)
Интерпретация планов выполнения для коллокированных соединений
Выравнивание соединений может происходить, когда две таблицы разбиваются по одной и той же или эквивалентной функции секционирования, и столбцы секционирования с обеих сторон соединения указаны в условии соединения запроса. Оптимизатор запросов может сформировать план, в котором секции каждой таблицы, имеющие равные идентификаторы, соединяются отдельно. Коллокированные соединения могут выполняться быстрее, чем неколлокированные, поскольку они могут требовать меньшего объёма памяти и времени обработки. Оптимизатор запросов выбирает план без выравнивания или план с выравниванием на основе оценок стоимости.
В распределенных планах соединение Nested Loops считывает одну или более секций для объединяемых таблиц или индексов с внутренней стороны соединения. Цифры в операторах Constant Scan представляют собой номера секций.
Если для секционированных таблиц или индексов формируются параллельные планы для совместных соединений, то между операторами соединения Constant Scan и Nested Loops появляется оператор Parallelism. В этом случае несколько рабочих потоков на внешней стороне операции соединения считывают разные разделы и работают с разными разделами.
Следующий рисунок демонстрирует план параллельного запроса для совмещенных соединений.
Стратегия параллельного выполнения запросов для секционированных объектов
Обработчик запросов использует стратегию параллельного выполнения для запросов, производящих выборку из секционированных объектов. В рамках стратегии выполнения обработчик запросов определяет секции таблиц, необходимые для запроса, и долю рабочих потоков, выделяемых для каждой секции. В большинстве случаев обработчик запросов выделяет равное или почти равное количество рабочих потоков для каждой секции, а затем выполняет запрос параллельно на всех секциях. В следующих параграфах более подробно объясняется выделение рабочих потоков.
Если число рабочих потоков меньше числа секций, обработчик запросов назначает каждому рабочему потоку отдельную секцию, первоначально оставляя одну или несколько секций без назначенного рабочего потока. Когда рабочий поток завершает работу с секцией, обработчик запросов назначает этот поток следующей секции. Это продолжается до тех пор, пока у каждой секции не будет по одному рабочему потоку. Это единственный случай, когда обработчик запросов перераспределяет рабочие потоки к другим секциям.
Отображает рабочий поток, повторно назначенный после завершения. Если число рабочих потоков равно числу секций, обработчик запросов назначает каждой секции по одному рабочему потоку. Когда рабочий поток завершится, он не будет перераспределирован в другую секцию.

Если число рабочих потоков больше числа секций, обработчик запросов назначает каждой секции одинаковое число рабочих потоков. Если число рабочих потоков не является точным числом секций, обработчик запросов выделяет один дополнительный рабочий поток для некоторых секций, чтобы использовать все доступные рабочие потоки. Если существует только один раздел, все рабочие потоки будут назначены этому разделу. На приведенном ниже рисунке показаны четыре секции и 14 рабочих потоков. Каждой секции назначено по 3 рабочих потока, у двух секций есть дополнительные рабочие потоки; всего назначено 14 рабочих потоков. Когда рабочий поток завершится, он не переназначется другому разделу.

В приведенных выше примерах демонстрируется достаточно прямолинейный способ распределения рабочих потоков. Реальная стратегия более сложна; она учитывает другие факторы, которые возникают при выполнении запроса. Например, если таблица секционирована и имеет кластеризованный индекс для столбца А, а в запросе используется предложение предиката WHERE A IN (13, 17, 25), то обработчик запросов выделит один рабочий поток или несколько каждому из трех искомых значений из значений поиска (A=13, A=17 и A=25), а не каждой секции таблицы. Запрос необходимо выполнить только в секциях, содержащих эти значения; если все предикаты поиска будут расположены в одной секции таблицы, все рабочие потоки будут назначены этой секции.
Другой пример: предположим, что таблица имеет четыре секции для столбца A с граничными точками (10, 20, 30), индекс на столбце B, а в запросе содержится предикат WHERE B IN (50, 100, 150). Так как секции таблицы основаны на значениях A, значения столбца B могут появляться во всех секциях таблицы. Поэтому обработчик запросов будет искать каждое из этих трех значений столбца B (50, 100, 150) в каждой из четырех секций таблицы. Обработчик запросов распределит рабочие потоки пропорционально, чтобы эти 12 операций сканирования запроса могли выполняться параллельно.
| Секции таблицы основаны на столбце А | Ищет столбец B в каждом разделе таблицы |
|---|---|
| Раздел таблицы 1: A < 10 | B = 50, B = 100, B = 150 |
| Секция таблицы 2: A >= 10 И A < 20 | B = 50, B = 100, B = 150 |
| Часть таблицы 3: A >= 20 И A < 30 | B = 50, B = 100, B = 150 |
| Раздел таблицы 4: A >= 30 | B = 50, B = 100, B = 150 |
Лучшие практики
Для увеличения производительности запросов, обращающихся к большому количеству данных из больших секционированных таблиц и индексов, предлагаются следующие рекомендации.
- Распределяйте каждую секцию по нескольким дискам. Это особенно актуально при использовании шпиндельных жестких дисков.
- По возможности используйте сервер с достаточной основной памятью, чтобы соответствовать часто используемым секциям или всем секциям в памяти, чтобы сократить затраты на ввод-вывод.
- Если данные, которые вы запрашиваете, не будут помещаться в память, сжимайте таблицы и индексы. Это позволит снизить затраты на ввод-вывод.
- Чтобы в полной мере реализовать возможности параллельной обработки запросов, используйте сервер с быстрыми процессорами и как можно большим числом процессорных ядер.
- Обеспечьте достаточную пропускную способность контроллера ввода-вывода для сервера.
- Чтобы воспользоваться оптимизациями сканирования B-дерева, создайте кластеризованный индекс по каждой большой секционированной таблице.
- При массовой загрузке данных в секционированные таблицы следуйте рекомендациям, приведенным в техническом документе The Data Loading Performance Guide (Руководство по эффективной загрузке данных).
Пример
В следующем примере показано создание тестовой базы данных, состоящей из одной таблицы с семью секциями. Чтобы при выполнении запросов в этом примере просматривать сведения о секционировании в планах времени компиляции и времени выполнения, следует пользоваться инструментами, описанными ранее.
Примечание.
В данном примере в таблицу вставляется более 1 миллиона строк. Выполнение этого примера может занять несколько минут в зависимости от оборудования. Перед выполнением этого примера следует убедиться, что на диске 1,5 ГБ свободного места.
USE master;
GO
IF DB_ID (N'db_sales_test') IS NOT NULL
DROP DATABASE db_sales_test;
GO
CREATE DATABASE db_sales_test;
GO
USE db_sales_test;
GO
CREATE PARTITION FUNCTION [pf_range_fact](int) AS RANGE RIGHT FOR VALUES
(20080801, 20080901, 20081001, 20081101, 20081201, 20090101);
GO
CREATE PARTITION SCHEME [ps_fact_sales] AS PARTITION [pf_range_fact]
ALL TO ([PRIMARY]);
GO
CREATE TABLE fact_sales(date_id int, product_id int, store_id int,
quantity int, unit_price numeric(7,2), other_data char(1000))
ON ps_fact_sales(date_id);
GO
CREATE CLUSTERED INDEX ci ON fact_sales(date_id);
GO
PRINT 'Loading...';
SET NOCOUNT ON;
DECLARE @i int;
SET @i = 1;
WHILE (@i<1000000)
BEGIN
INSERT INTO fact_sales VALUES(20080800 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
GO
DECLARE @i int;
SET @i = 1;
WHILE (@i<10000)
BEGIN
INSERT INTO fact_sales VALUES(20080900 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
PRINT 'Done.';
GO
-- Two-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080802 AND 20080902
GROUP BY date_id ;
GO
SET STATISTICS XML OFF;
GO
-- Single-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080801 AND 20080831
GROUP BY date_id;
GO
SET STATISTICS XML OFF;
GO
Связанный контент
- справочник по оператору Логический и физический оператор showplan
- Обзор расширенных событий
- Рекомендации по мониторингу рабочих нагрузок с помощью Хранилища запросов
- Оценка кардинальности (SQL Server)
- Интеллектуальная обработка запросов в базах данных SQL
- Приоритет оператора (Transact-SQL)
- Обзор плана выполнения
- Центр производительности для базы данных SQL Azure и ядра СУБД SQL Server