Считывание страниц
Область применения: ![]() SQL Server
SQL Server
Операции ввода-вывода из экземпляра SQL Server ядро СУБД включают логические и физические операции чтения. Логическое чтение происходит каждый раз, когда ядро СУБД запрашивает страницу из кэша буфера. Если в этот момент страница не находится в кэше, то сначала при помощи операции физического чтения она копируется в него с диска.
Запросы на чтение, созданные экземпляром ядро СУБД, управляются реляционным ядром и оптимизированы подсистемой хранилища. Реляционный механизм подбирает наиболее эффективный метод доступа (просмотр таблицы, просмотр индекса или чтение по ключу). Компонент метода доступа и диспетчер буферов подсистемы хранилища определяют общий шаблон считывания и оптимизируют операции чтения для реализации метода доступа. Поток, выполняющий пакет, планирует операции считывания.
Упреждающее чтение
Ядро СУБД поддерживает механизм оптимизации производительности, называемый чтением вперед. Он заключается в том, что система пытается предугадать, какие именно страницы данных и индексов понадобятся для плана выполнения запроса, и помещает эти страницы в буферный кэш, прежде, чем в них возникнет реальная необходимость. Это позволяет распараллелить операции вычисления и ввода-вывода, полностью задействовав процессорные и дисковые мощности.
Механизм чтения позволяет ядро СУБД читать до 64 смежных страниц (512 КБ) из одного файла. Эта операция выполняется как единая последовательность разборки-сборки для соответствующего числа буферов в буферном кэше (возможно, расположенных не последовательно). Если какая-либо из страниц этого диапазона уже присутствует в буферном кэше, то соответствующая страница по окончании считывания будет удалена из памяти. Кроме того, диапазон страниц может быть «усечен» с начала или с конца, если соответствующие страницы уже находятся в кэше.
Упреждающее чтение бывает двух видов: для страниц данных и для страниц индексов.
Чтение страниц данных
Проверки таблиц, используемые для чтения страниц данных, очень эффективны в ядро СУБД. Страницы карты распределения индекса (IAM) в базе данных SQL Server содержат указатели на экстенты, используемые таблицей или индексом. Подсистема хранилища может считывать IAM для построения отсортированного списка адресов на диске, которые необходимо считать. Это позволяет подсистеме хранилища оптимизировать операции ввода-вывода выполняемые последовательно в виде больших операций чтения на основе их размещения на диске. Дополнительные сведения о страницах IAM см. в статье Управление дисковым пространством, занятым объектами.
Считывание страниц индекса
Подсистема хранилища считывает страницы индекса последовательно, в порядке значений ключей. На приведенном ниже рисунке показан пример упрощенного представления набора конечных страниц, которое содержит набор ключей и промежуточный узел индекса, сопоставляющий концевые страницы. Дополнительные сведения о структуре страниц в индексе см. в статье Структуры кластеризованного индекса.
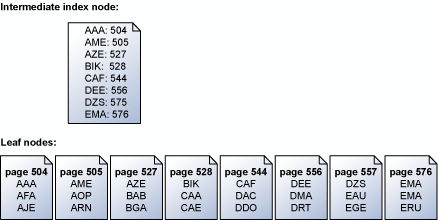
Подсистема хранилища использует данные промежуточной страницы индекса выше конечного уровня для организации последовательного упреждающего чтения страниц, содержащих значения ключей. При обработке запроса на все ключи от «ABC» до «DEF» вначале подсистема хранилища считывает страницу индекса выше конечной страницы. Однако он не просто последовательно считывает все страницы данных от 504-й до 556-й, то есть последней, на которой находятся значения ключей заданного диапазона. Вместо этого подсистема хранилища просматривает промежуточную страницу индекса и строит список конечных страниц для считывания. Затем подсистема хранилища планирует все операции ввода-вывода в порядке следования ключей. Кроме того, подсистема хранилища определяет, что страницы 504/505 и 527/528 являются смежными, и считывает содержащиеся на них данные за одну операцию, после чего выполняет сборку данных. Если в последовательной операции необходимо получить много страниц, то планируется целый блок операций чтения за один раз. По завершении этого подмножества операций чтения планируется такое же количество новых, и так до тех пор, пока все нужные страницы не будут запрошены.
Затем подсистема хранилища использует упреждающую выборку для ускорения поиска в таблицах по некластеризованным индексам. Конечные строки в некластеризованном индексе содержат указатели на строки данных, в которых хранятся все определенные значения ключей. По мере чтения по конечным страницам некластеризованного индекса подсистема хранилища также начинает планирование асинхронных операций чтения строк данных по уже полученным указателям на них. Это позволяет приступить к извлечению строк данных из базовой таблицы еще до завершения просмотра некластеризованного индекса. Этот процесс выполняется независимо от наличия в таблице кластеризованного индекса. SQL Server Enterprise использует упреждающую выборку в большей степени, чем другие выпуски SQL Server, выполняя упреждающее чтение большего числа страниц. Уровень упреждающей выборки нельзя настраивать ни в одном из выпусков. Дополнительные сведения о некластеризованных индексах см. в статье Структуры некластеризованных индексов.
Расширенный просмотр
Функция расширенного просмотра в SQL Server Enterprise позволяет нескольким задачам совместно выполнять полный просмотр таблиц. Если для плана выполнения инструкции Transact-SQL требуется сканирование страниц данных в таблице, а ядро СУБД обнаруживает, что таблица уже сканируется для другого плана выполнения, ядро СУБД присоединяет вторую проверку к первой, в текущем расположении второго сканирования. Ядро СУБД считывает каждую страницу по одному разу и передает строки из каждой страницы в оба плана выполнения. Это продолжается до тех пор, пока не будет достигнут конец таблицы.
На этой стадии первый план выполнения получит полные результаты просмотра, а второй план до сих пор не получил страницы данных, находящиеся ранее места присоединения. Поэтому для него производится возврат к первой странице данных, и просмотр повторяется до этой точки. Таким образом, можно объединять любое количество просмотров. Ядро СУБД будет продолжать циклироваться по страницам данных, пока не завершится все проверки. Этот механизм называется также «кольцевым просмотром» и демонстрирует, почему порядок строк, возвращаемых в результате выполнения инструкции SELECT, без предложения ORDER BY не гарантирован.
Например, допустим, что некая таблица содержит 500 000 страниц. Пользователь UserA выполняет инструкцию Transact-SQL, требующую просмотра таблицы. По первому запросу просмотрено уже 100 000 страниц, после чего пользователь UserB выполняет еще одну инструкцию Transact-SQL, требующую просмотра той же таблицы. Ядро СУБД планирует один набор запросов на чтение страниц после 100 001 и передает строки из каждой страницы обратно в обе проверки. По достижении 200 000 страницы пользователь UserC выполняет еще одну инструкцию Transact-SQL, требующую просмотра той же таблицы. Начиная с страницы 20000001, ядро СУБД передает строки с каждой страницы, считываемой обратно во все три сканирования. После считывания 500000-й строки просмотр для пользователя UserA завершается, а для пользователей UserB и UserC чтение снова начинается с первой страницы. Когда ядро СУБД возвращается на страницу 100 000, проверка на UserB завершается. Просмотр для пользователя UserC продолжает выполняться до тех пор, пока не будет достигнута 200000-я страница. Только после этого операция просмотра для всех пользователей будет завершена.
Без возможности расширенного просмотра все пользователи были бы вынуждены состязаться за буферное пространство, что вызвало бы значительную нагрузку на дисковый накопитель. Затем те же страницы считывались бы каждым из пользователей, вместо того чтобы загрузить их один раз для нескольких пользователей.
См. также
Руководство по архитектуре страниц и экстентов
Запись страниц