Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Применимо к:![]() SQL Server
SQL Server![]() База данных
База данных![]() SQL AzureУправляемый экземпляр
SQL AzureУправляемый экземпляр![]() SQL AzureБаза данных SQL в Microsoft Fabric
SQL AzureБаза данных SQL в Microsoft Fabric
Проектирование эффективных индексов является ключом к достижению хорошей производительности базы данных и приложений. Отсутствие индексов, чрезмерное индексирование или плохо разработанные индексы являются главными источниками проблем с производительностью базы данных.
В этом руководстве описана архитектура и основы индекса, а также рекомендации по проектированию эффективных индексов в соответствии с потребностями приложений.
Дополнительные сведения о доступных типах индексов см. в разделе "Индексы".
В этом руководстве рассматриваются следующие типы индексов:
| Формат основного хранилища | Тип индекса |
|---|---|
| Дисковое хранилище строк | |
| Clustered | |
| Nonclustered | |
| Unique | |
| Filtered | |
| Columnstore | |
| Кластеризованное хранилище столбцов | |
| Некластерный колонночный индекс | |
| Memory-optimized | |
| Hash | |
| Оптимизированный для памяти некластеризованный |
Сведения о XML-индексах см. в статьях XML-индексов (SQL Server) и выборочных XML-индексов (SXI).
Сведения о пространственных индексах см. в разделе Общие сведения о пространственных индексах.
Сведения о полнотекстовых индексах см. в разделе "Заполнение полнотекстовых индексов".
Основы индекса
Подумайте о обычной книге: в конце книги есть индекс, который помогает быстро найти информацию в книге. Указатель представляет собой отсортированный список ключевых слов, а рядом с ключевым словом — номера страниц, где можно найти каждое ключевое слово.
Индекс rowstore аналогичен: это упорядоченный список значений и для каждого значения есть указатели на страницы данных, где находятся эти значения. Сам индекс также хранится на страницах, называемых страницами индекса. В обычной книге, если индекс охватывает несколько страниц, и вам нужно найти указатели на все страницы, содержащие слово SQL , например, вам придется пролистывать с начала индекса, пока не найдите страницу индекса, содержащую ключевое слово SQL. После этого можно следовать указателям на все страницы книги. Этот процесс можно оптимизировать, если в самом начале индекса создать одну страницу, содержащую алфавитный список расположения каждой буквы. Например: "A-D - страница 121", "E-g - страница 122" и т. д. Эта дополнительная страница исключит шаг листы индекса, чтобы найти начальную место. Такая страница не существует в обычных книгах, но она существует в индексе rowstore. Эта единственная страница называется корневой страницей индекса. Корневая страница — это начальная страница древовидной структуры, используемой индексом rowstore. Следуя аналогии дерева, конечные страницы, содержащие указатели на реальные данные, называются "листьями" дерева.
Индекс является структурой на диске или в памяти, которая связана с таблицей или представлением и ускоряет получение строк из таблицы или представления. Индекс rowstore содержит ключи, созданные из значений в одном или нескольких столбцах таблицы или представления. Для индексов rowstore эти ключи хранятся в древовидной структуре (B+ дерево), которая позволяет механизму базы данных находить строки, связанные с ключевыми значениями, быстро и эффективно.
Индекс rowstore сохраняет данные, логически организованные в виде таблицы с строками и столбцами, а физически их структура фиксируется в построчном формате данных под названием rowstore1. Существует альтернативный способ хранения столбцов данных с именем columnstore.
Проектирование правильных индексов для базы данных и ее рабочей нагрузки — это сложный процесс балансировки между скоростью запроса, затратами на обновление индекса и затратами на хранение. Узкие дисковые индексы rowstore или индексы с немногими столбцами в ключе индекса требуют меньше места в хранилище и меньшую издержку обновления. С другой стороны, широкие индексы могут улучшить выполнение бóльшего числа запросов. Перед поиском наиболее эффективного набора индексов, возможно, придется поэкспериментировать с несколькими различными проектами. По мере развития приложения индексы могут потребоваться измениться, чтобы обеспечить оптимальную производительность. Индексы можно добавлять, изменять и удалять, не влияя на схему базы данных или структуру приложения. Поэтому вы не должны стесняться экспериментировать с различными индексами.
Оптимизатор запросов в ядре СУБД обычно выбирает наиболее эффективные индексы для выполнения запроса. Чтобы узнать, какие индексы использует оптимизатор запросов для определенного запроса в SQL Server Management Studio, в меню "Запрос " выберите пункт "Отображение предполагаемого плана выполнения " или "Включить фактический план выполнения".
Не всегда приравнивайте использование индекса с хорошей производительностью и хорошей производительностью с эффективным использованием индекса. Если бы использование индекса всегда способствовало производительности, то работа оптимизатора запросов была бы очень простой. На самом деле, неверный выбор индекса может привести к неоптимальной производительности. Таким образом, задача оптимизатора запросов заключается в выборе индекса или сочетании индексов, только если он повышает производительность, и чтобы избежать индексированного извлечения, когда это препятствует производительности.
Распространенная ошибка проектирования заключается в создании многих индексов спекулятивно, чтобы "дать оптимизатору выбор". Результирующая переиндексация замедляет изменения данных и может вызвать проблемы параллелизма.
1 Rowstore — это традиционный способ хранения реляционных данных таблиц. Rowstore ссылается на таблицу, в которой базовый формат хранилища данных — куча, дерево B+ (кластеризованный индекс) или оптимизированная для памяти таблица. Хранилище строк на основе дисков исключает оптимизированные для памяти таблицы.
Задачи проектирования индексов
Рекомендуемая стратегия проектирования индексов включает в себя следующие задачи:
Общие сведения о характеристиках базы данных и приложения.
Например, в базе данных обработки транзакций в сети (OLTP) с частыми изменениями данных, которые должны поддерживать высокую пропускную способность, несколько узких индексов rowstore, предназначенных для наиболее критически важных запросов, будет хорошим начальным дизайном индекса. Для чрезвычайно высокой пропускной способности рассмотрите таблицы и индексы, оптимизированные под память, которые обеспечивают отсутствие блокировок и защёлок. Дополнительные сведения см. в руководстве по проектированию некластеризованных индексов, оптимизированных для памяти, и рекомендациям по проектированию хэш-индекса в этом руководстве.
И наоборот, для аналитической или хранилищной базы данных (OLAP), которая должна быстро обрабатывать очень большие наборы данных, использование кластеризованных columnstore индексов будет особенно подходящим. Дополнительные сведения см. в разделе "Индексы Columnstore: обзор " или "Архитектура индекса Columnstore " в этом руководстве.
Изучите характеристики наиболее часто используемых запросов.
Например, зная, что часто используемый запрос объединяет две или более таблиц, помогает определить набор индексов для этих таблиц.
Общие сведения о распределении данных в столбцах, используемых в предикаатах запроса.
Например, индекс может быть полезен для столбцов с большим количеством различных значений данных, но менее таким образом для столбцов с большим количеством повторяющихся значений. Для столбцов с множеством NULL или с определенными подмножествами данных можно использовать отфильтрованный индекс. Дополнительные сведения см . в руководстве по проектированию отфильтрованного индекса.
Определите, какие параметры индекса могут повысить производительность.
Например, создание кластеризованного индекса в существующей большой таблице может воспользоваться параметром
ONLINEиндекса. ЭтотONLINEпараметр позволяет продолжать параллельное действие в базовых данных во время создания или перестроения индекса. Использование сжатия данных строк или страниц может повысить производительность, уменьшая объем операций ввода-вывода и памяти индекса. Дополнительные сведения см. в разделе CREATE INDEX.Проверьте существующие индексы в таблице, чтобы предотвратить создание повторяющихся или очень похожих индексов.
Зачастую лучше изменить существующий индекс, чем создать новый, но в основном повторяющийся индекс. Например, рекомендуется добавить один или два дополнительных столбца в существующий индекс вместо создания нового индекса с этими столбцами. Это особенно важно при настройке некластеризованных индексов с отсутствующими предложениями индекса или при использовании помощника по настройке ядра СУБД, где можно предложить аналогичные варианты индексов в одной таблице и столбцах.
Общие рекомендации по проектированию индексов
Общие сведения о характеристиках базы данных, запросов и столбцов таблиц помогут вам изначально разработать оптимальные индексы и изменить дизайн по мере развития приложений.
Рекомендации по базам данных
При проектировании индекса следует учитывать следующие рекомендации:
Большое количество индексов в таблице влияет на производительность операторов
INSERT,UPDATE,DELETEиMERGE, поскольку данные в индексах могут изменяться при изменении данных в таблице. Например, если столбец используется в нескольких индексах и выполняетсяUPDATEинструкция, которая изменяет данные столбца, каждый индекс, содержащий этот столбец, также должен быть обновлен.Избегайте использования чрезмерного количества индексов для интенсивно обновляемых таблиц и следите, чтобы индексы были узкими, то есть содержали как можно меньше столбцов.
Вы можете иметь больше индексов в таблицах с небольшими изменениями данных, но большими объемами данных. Для таких таблиц различные индексы могут помочь в производительности запросов, пока затраты на обновление индекса остаются приемлемыми. Однако не создавайте индексы спекулятивно. Отслеживайте использование индекса и удаляйте неиспользуемые индексы с течением времени.
Индексирование небольших таблиц может быть неоптимальным, так как ядро СУБД может занять больше времени для обхода индекса поиска данных, чем для выполнения проверки базовой таблицы. Таким образом, индексы в небольших таблицах никогда не используются, но все равно должны обновляться по мере обновления данных в таблице.
Индексы в представлениях могут обеспечить значительный рост производительности, если представление содержит агрегаты и /или соединения. Дополнительные сведения см. в разделе "Создание индексированных представлений".
Базы данных на первичных репликах в Базе данных SQL Azure автоматически создают рекомендации по производительности Помощника по базам данных для индексов. При необходимости можно включить автоматическую настройку индекса.
Хранилище запросов помогает выявлять запросы с неоптимальной производительностью и предоставляет журнал планов выполнения запросов , которые позволяют видеть индексы, выбранные оптимизатором. Эти данные можно использовать для изменения настройки индекса наиболее эффективно, фокусируясь на наиболее частых и потребляемых ресурсах запросах.
Соображения по запросу
При проектировании индекса следует принимать во внимание следующие рекомендации, связанные с обработкой запросов.
Создайте некластеризованные индексы для столбцов, которые часто используются в предикатах и выражениях соединения в запросах. Это ваши столбцы SARGable. Однако следует избегать добавления ненужных столбцов в индексы. Добавление слишком большого количества столбцов индекса может негативно повлиять на производительность дискового пространства и обновления индекса.
Термин SARGable в реляционных базах данных относится к универсальному предикатуSearch ARG, который может использовать индекс для ускорения выполнения запроса. Дополнительные сведения см. в руководстве по архитектуре и проектированию индексов SQL Sql Server и Azure.
Tip
Всегда убедитесь, что создаваемые индексы фактически используются рабочей нагрузкой запроса. Удалите неиспользуемые индексы.
Статистика использования индекса доступна в sys.dm_db_index_usage_stats и sys.dm_db_index_operational_stats.
Покрывающие индексы могут повысить производительность запросов, так как данные, необходимые для удовлетворения требований запроса, присутствуют в самом индексе. Таким образом, для получения запрашиваемых данных требуются только страницы индекса, а не страницы данных таблицы или кластеризованного индекса. Следовательно, уменьшается общий объем операций дискового ввода-вывода. Например, запрос по столбцам
AиBтаблицы, у которой есть составной индекс, созданный на основе столбцовA,BиC, может найти нужные данные, пользуясь только этим индексом.Note
Охватывающий индекс — это некластеризованный индекс, который удовлетворяет всем доступу к данным запросом напрямую без доступа к базовой таблице.
Такие индексы имеют все необходимые столбцы SARGable в ключе индекса и столбцы, не относящиеся к SARGable , как включенные столбцы. Это означает, что все столбцы, необходимые для запроса, либо в предложениях
WHERE,JOINиGROUP BY, либо в предложенияхSELECTилиUPDATE, присутствуют в индексе.Может потребоваться гораздо меньше операций ввода-вывода для выполнения запроса, если индекс достаточно узкий. Это означает, что он представляет собой небольшое подмножество всех столбцов по сравнению с строками и столбцами в самой таблице.
Рекомендуется использовать покрывающие индексы при извлечении небольшой части большой таблицы, где эта небольшая часть определяется фиксированным предикатом.
Избегайте создания окрывающего индекса с слишком большим количеством столбцов, так как это снижает его преимущество при переполнении хранилища баз данных, операций ввода-вывода и объема памяти.
Запросы следует составлять так, чтобы они вставляли или изменяли как можно больше строк одной инструкцией, вместо того, чтобы использовать для обновления тех же строк нескольких запросов. Это снижает нагрузку на обновление индекса.
Соображения по столбцам
При проектировании индекса, следует принимать во внимание следующие рекомендации, относящиеся к столбцам.
Держите длину ключа индекса коротким, особенно для кластеризованных индексов.
Столбцы, имеющие ntext, text, image, varchar(max), nvarchar(max), varbinary(max), json и векторные типы данных не могут быть указаны в качестве ключевых столбцов индекса. Однако столбцы с этими типами данных можно добавлять в некластеризованный индекс как неключевые (включенные) столбцы индекса. Дополнительные сведения см. в разделе "Использование столбцов, включенных в некластеризованные индексы " в этом руководстве.
Проверьте уникальность столбцов. Уникальный индекс вместо неуникационного индекса в тех же ключевых столбцах предоставляет дополнительные сведения для оптимизатора запросов, что делает индекс более полезным. Дополнительные сведения см . в руководстве по проектированию уникальных индексов.
Проверьте распределение данных в столбце. Создание индекса в столбце со многими строками, но несколько разных значений могут не повысить производительность запросов, даже если индекс используется оптимизатором запросов. В качестве примера, физический телефонный каталог, отсортированный в алфавитном порядке по фамилии, не ускоряет поиск человека, если все люди в городе носят фамилию Смит или Джонс. Дополнительные сведения о распределении данных см. в разделе Statistics.
Рекомендуется использовать отфильтрованные индексы для столбцов с хорошо определенными подмножествами, например столбцы со многими NULLs, столбцами с категориями значений и столбцами с различными диапазонами значений. Хорошо разработанный отфильтрованный индекс может повысить производительность запросов, уменьшить затраты на обновление индекса и сократить затраты на хранение, сохраняя небольшое подмножество всех строк в таблице, если это подмножество относится ко многим запросам.
Рассмотрим порядок ключевых столбцов индекса, если ключ содержит несколько столбцов. Столбец, используемый в предикате запроса в выражении равенства (
=), неравенства (>,>=,<,<=) илиBETWEEN, или участвующий в соединении, должен стоять первым. Дополнительные столбцы должны быть упорядочены по уровню различимости, то есть от наиболее четкого к наименее четкому.Например, если индекс определен как
LastName,FirstName, индекс полезен, если предикат запроса вWHEREпредложении равенWHERE LastName = 'Smith'илиWHERE LastName = Smith AND FirstName LIKE 'J%'. Однако оптимизатор запросов не будет использовать индекс для запроса, который выполняет поиск только поWHERE FirstName = 'Jane', или индекс не улучшит производительность такого запроса.Рекомендуется индексировать вычисляемые столбцы, если они включены в предикаты запросов. Дополнительные сведения см. в разделе "Индексы" для вычисляемых столбцов.
Характеристики индекса
После определения того, что индекс подходит для запроса, можно выбрать тип индекса, который лучше всего подходит для вашей ситуации. Ниже приведены характеристики индекса:
- Кластеризованный или некластеризованный
- Уникальный или неуникальный
- Один столбец или многоколонночный
- По возрастанию или убыванию ключевых столбцов в индексе
- Все строки или фильтры для некластеризованных индексов
- Columnstore или rowstore
- Хэш или некластеризованные для таблиц, оптимизированных для памяти
Размещение индекса в файловых группах или схемах секций
Во время разработки стратегии индексирования следует обратить внимание на помещение индексов в файловые группы, связанные с базой данных.
По умолчанию индексы хранятся в той же файловой группе, что и базовая таблица (кластеризованный индекс или куча), в которой создается индекс. Возможны другие конфигурации, в том числе:
Создайте некластеризованные индексы в файловой группе, отличной от файловой группы базовой таблицы.
Секционировать кластеризованные и некластеризованные индексы, чтобы они размещались в нескольких файловых группах.
Для несекционированных таблиц самый простой подход обычно является лучшим: создание всех таблиц в одной файловой группе и добавление в файловую группу столько файлов данных, сколько необходимо для использования всего доступного физического хранилища.
Более сложные подходы к размещению индексов можно учитывать при доступности многоуровневого хранилища. Например, можно создать файловую группу для часто доступных таблиц с файлами на более быстрых дисках и файловую группу для архивных таблиц на более медленных дисках.
Таблицу с кластеризованным индексом можно переместить из одной файловой группы в другую, удаляя кластеризованный индекс и указывая новую файловую группу или схему секционирования в MOVE TO предложении инструкции DROP INDEX или используя CREATE INDEX инструкцию с DROP_EXISTING предложением.
Секционированные индексы
Можно также рассмотреть возможность секционирования на несколько файловых групп куч на дисках, кластеризованных и некластеризованных индексов. Секционированные индексы секционируются горизонтально (по строкам) на основе функции секционирования. Функция секционирования определяет, как каждая строка сопоставляется с секцией на основе значений определенного столбца, указанного вами, называемого столбцом секционирования. Схема секционирования указывает сопоставление набора секций с файловой группой.
Секционирование индекса может предоставить следующие преимущества.
Сделать большие базы данных более управляемыми. Например, системы OLAP могут реализовать ETL с поддержкой секционирования, что значительно упрощает добавление и удаление данных в массовом режиме.
Ускорьте выполнение определенных типов запросов, таких как длительные аналитические запросы. Если запросы используют секционированные индексы, ядро СУБД может обрабатывать несколько секций одновременно и пропускать (исключить) секции, которые не нужны запросу.
Предупреждение
Секционирование редко повышает производительность запросов в системах OLTP, но может привести к значительным издержкам, если транзакционный запрос должен получить доступ ко многим секциям.
Дополнительные сведения см. в разделах Секционированные таблицы и индексы.
Рекомендации по проектированию порядка сортировки индексов
При определении индексов следует учитывать, должен ли каждый ключевой столбец индекса храниться в порядке возрастания или убывания. "Возрастание является значением по умолчанию." Синтаксис CREATE INDEXоператоров и CREATE TABLEALTER TABLE операторов ASC поддерживает ключевые слова (возрастание) и DESC (убывание) для отдельных столбцов в индексах и ограничениях.
Указание порядка хранения значений ключей в индексе полезно, если запросы, ссылающиеся на таблицу, имеют ORDER BY предложения, указывающие различные направления для ключевого столбца или столбцов в этом индексе. В таких случаях индекс может удалить необходимость операторасортировки в плане запроса.
Например, покупатели в отделе приобретения Adventure Works Cycles должны оценить качество продуктов, которые они покупают у поставщиков. Покупатели наиболее заинтересованы в поиске продуктов, отправленных поставщиками с высоким процентом отказов.
Как показано в следующем запросе к образцу базы данных AdventureWorks, получение данных по соответствию этому критерию требует, чтобы столбец RejectedQty в таблице Purchasing.PurchaseOrderDetail был отсортирован в порядке убывания (от большего значения к меньшему), а столбец ProductID — в порядке возрастания (от меньшего к большему).
SELECT RejectedQty,
((RejectedQty / OrderQty) * 100) AS RejectionRate,
ProductID,
DueDate
FROM Purchasing.PurchaseOrderDetail
ORDER BY RejectedQty DESC, ProductID ASC;
Следующий план выполнения для этого запроса показывает, что оптимизатор запросов использовал оператор sort для возврата результирующий набор в порядке, указанном предложением ORDER BY .

Если индекс rowstore на основе диска создается с ключевыми столбцами, которые соответствуют тем, что в клаузе ORDER BY в запросе, оператор сортировки в плане запроса удаляется, что делает план запроса более эффективным.
CREATE NONCLUSTERED INDEX IX_PurchaseOrderDetail_RejectedQty
ON Purchasing.PurchaseOrderDetail
(RejectedQty DESC, ProductID ASC, DueDate, OrderQty);
После повторного выполнения запроса следующий план выполнения показывает, что оператор сортировки больше не присутствует, и используется только что созданный некластеризованный индекс.
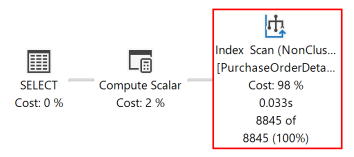
Ядро СУБД может сканировать индекс в любом направлении. Индекс, определенный как RejectedQty DESC, ProductID ASC, можно использовать для запроса, в котором направления сортировки столбцов в ORDER BY предложении обратны. Например, запрос с предложением ORDER BYORDER BY RejectedQty ASC, ProductID DESC может использовать тот же индекс.
Порядок сортировки может быть указан только для ключевых столбцов в индексе. Представление каталога sys.index_columns сообщает, хранится ли столбец индекса в порядке возрастания или убывания.
рекомендации по структуре кластеризованного индекса
Кластеризованный индекс сохраняет все строки и все столбцы таблицы. Строки сортируются в порядке значений ключа индекса. Для каждой таблицы может быть только один кластеризованный индекс.
Термин базовая таблица может относиться либо к кластеризованному индексу, либо к куче. Куча — это неортизованная структура данных на диске, содержащая все строки и все столбцы таблицы.
При некоторых исключениях каждая таблица должна иметь кластеризованный индекс. Желательные свойства кластеризованного индекса:
| Недвижимость | Description |
|---|---|
| Узкий | Ключ кластеризованного индекса является частью любого некластеризованного индекса в той же базовой таблице. Узкий ключ или ключ, в котором общая длина ключевых столбцов невелика, уменьшает объем хранилища, ввода-вывода и нагрузку на память всех индексов в таблице. Чтобы вычислить длину ключа, добавьте размеры хранилища для типов данных, используемых ключевыми столбцами. Дополнительные сведения см. в категориях типов данных. |
| Уникальный | Если кластеризованный индекс не является уникальным, 4-байтовый внутренний столбец uniqueifier автоматически добавляется в ключ индекса, чтобы обеспечить уникальность. Добавление существующего уникального столбца в кластеризованный ключ индекса позволяет избежать избыточных затрат на хранение, ввод-вывод и память от столбца uniqueifier во всех индексах таблицы. Кроме того, оптимизатор запросов может создавать более эффективные планы запросов при уникальном индексе. |
| Постоянно увеличивающееся | В постоянно увеличивающемся индексе данные всегда добавляются на последней странице индекса. Это позволяет избежать разделения страниц в середине индекса, что снижает плотность страниц и снижает производительность. |
| Неизменный | Ключ кластеризованного индекса является частью любого некластеризованного индекса. При изменении ключевого столбца кластеризованного индекса необходимо также внести изменения во все некластеризованные индексы, которые добавляют нагрузку на ЦП, ведение журнала, операции ввода-вывода и объем памяти. Накладные расходы избегаются, если ключевые столбцы кластеризованного индекса неизменяемы. |
| Имеет только столбцы, не допускающие значение NULL | Если строка имеет столбцы, допускающие значение NULL, она должна содержать внутреннюю структуру, называемую блоком NULL, который добавляет 3-4 байта хранилища на строку в индексе. Создание всех столбцов кластеризованного индекса, не допускающего значения NULL, позволяет избежать этой нагрузки. |
| Имеет только столбцы фиксированной ширины | Столбцы, использующие типы данных переменной ширины, такие как varchar или nvarchar , используют дополнительные 2 байта для каждого значения по сравнению с типами данных фиксированной ширины. Использование типов данных фиксированной ширины, таких как int , позволяет избежать этой нагрузки во всех индексах таблицы. |
При проектировании кластеризованного индекса важно стремиться удовлетворить как можно больше из этих свойств, чтобы сделать более эффективными не только сам кластеризованный индекс, но и все некластеризованные индексы в той же таблице. Производительность улучшается путем предотвращения затрат на хранение, ввод-вывод и объем памяти.
Например, кластеризованный ключ индекса с одним int или bigint , не допускающим значение NULL, имеет все эти свойства, если он заполняется IDENTITY предложением или ограничением по умолчанию с помощью последовательности и не обновляется после вставки строки.
И наоборот, кластеризованный ключ индекса с одним уникальным столбцом uniqueidentifier шире, так как он использует 16 байт хранилища вместо 4 байтов для int и 8 байт для bigint, и не удовлетворяет постоянно увеличивающееся свойство, если значения не создаются последовательно.
Tip
При создании PRIMARY KEY ограничения уникальный индекс, поддерживающий ограничение, создается автоматически. По умолчанию этот индекс кластеризован; Однако если этот индекс не удовлетворяет требуемым свойствам кластеризованного индекса, можно создать ограничение как некластеризованный и создать другой кластеризованный индекс.
Если вы не создаете кластеризованный индекс, таблица хранится как куча, которая обычно не рекомендуется.
Архитектура кластеризованного индекса
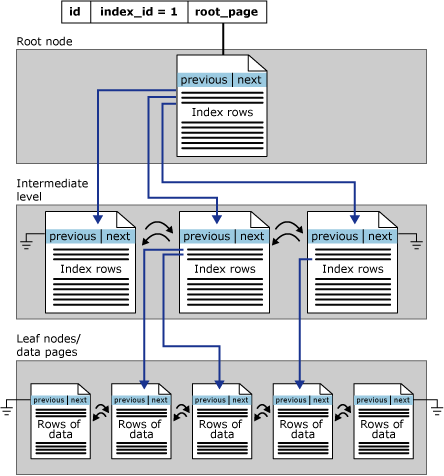
Индексы rowstore организованы в виде сбалансированных деревьев. Каждая страница в B⁺-дереве индекса называется узлом индекса. Верхний узел B⁺-дерева называется корневым. Узлы нижнего уровня индекса называются конечными. Все уровни индекса между корневыми и конечными узлами называются промежуточными. В кластеризованном индексе конечные узлы содержат страницы данных базовой таблицы. На страницах индекса корневого и промежуточного узлов находятся строки индекса. Каждая строка индекса содержит ключевое значение и указатель либо на страницу промежуточного уровня B⁺-дерева, либо на строку данных на конечном уровне индекса. Страницы на каждом уровне индекса связаны в двудвоем связанном списке.
Кластеризованные индексы имеют одну строку в sys.partitions для каждой секции, используемой индексом, с index_id = 1. По умолчанию, кластеризованный индекс занимает одну секцию. Если кластеризованный индекс содержит несколько секций, каждая секция имеет отдельную структуру дерева B+, содержащую данные для конкретной секции. Например, если кластеризованный индекс имеет четыре секции, в каждой секции есть четыре структуры дерева B+.
В зависимости от типов данных в кластеризованном индексе каждая кластеризованная структура индекса имеет одну или несколько единиц выделения, в которых следует хранить данные для определенной секции и управлять ими. Как минимум, каждый кластеризованный индекс имеет одну IN_ROW_DATA единицу выделения на секцию. Кластеризованный индекс также имеет одну LOB_DATA единицу выделения на секцию, если она содержит столбцы больших объектов (LOB), такие как nvarchar(max). Она также имеет одну ROW_OVERFLOW_DATA единицу выделения на секцию, если она содержит столбцы переменной длины, превышающие ограничение в 8 060 байтов строк.
Страницы в структуре дерева B+ упорядочены по значению кластеризованного ключа индекса. Все вставки выполняются на странице, где значение ключа в вставленной строке помещается в последовательность упорядочения между существующими страницами. На странице строки не обязательно хранятся в определённом физическом порядке. Однако страница поддерживает логическую упорядочение строк с помощью внутренней структуры, называемой массивом слотов. Записи в массиве слотов сохраняются в порядке ключа индексирования.
На следующем рисунке изображена структура кластеризованного индекса для одной секции.
Рекомендации по проектированию некластеризованных индексов
Основное различие между кластеризованным и некластеризованным индексом заключается в том, что некластеризованный индекс содержит подмножество столбцов в таблице, обычно отсортированных по-разному от кластеризованного индекса. При необходимости можно фильтровать некластеризованный индекс, что означает, что он содержит подмножество всех строк в таблице.
Некластеризованный индекс хранилища строк на основе диска содержит указатели строк, указывающие на расположение хранилища строки в базовой таблице. Можно создать несколько некластеризованных индексов для таблицы или индексированного представления. Как правило, некластеризованные индексы должны быть разработаны для повышения производительности часто используемых запросов, которые должны проверять базовую таблицу в противном случае.
Подобно тому, как читатель использует индекс в книге, оптимизатор запросов выискивает значение типа данных, просматривая некластеризованный индекс. Там он находит место расположения интересующего его значения в таблице и затем получает данные непосредственно из этого места. Благодаря этому некластеризованные индексы считаются оптимальным выбором для запросов с точным соответствием, поскольку такие индексы содержат записи, описывающие точное расположение в таблице значений типов данных, которые задаются в подобных запросах.
Например, чтобы выполнить запрос к таблице HumanResources.Employee для всех сотрудников, которые подчиняются определенному руководителю, оптимизатор запросов может использовать некластеризованный индекс IX_Employee_ManagerID, где первым ключевым столбцом является ManagerID.
ManagerID Так как значения упорядочены в некластеризованном индексе, оптимизатор запросов может быстро найти все записи в индексе, соответствующие указанному ManagerID значению. Каждая запись индекса указывает на точную страницу и строку в базовой таблице, где можно получить соответствующие данные из всех остальных столбцов. После того как оптимизатор запросов находит все записи в индексе, он может перейти непосредственно на точную страницу и строку, чтобы получить данные, а не сканировать всю базовую таблицу.
Архитектура некластеризованного индекса
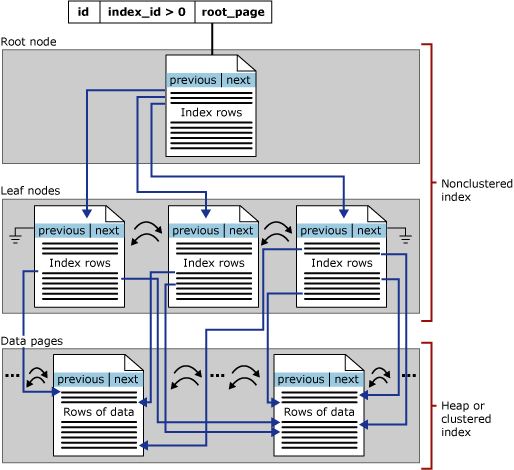
Некластеризованные индексы на основе дисков имеют ту же структуру дерева B+, что и кластеризованные индексы, за исключением следующих различий:
Некластеризованный индекс не обязательно содержит все столбцы и строки таблицы.
конечный уровень некластеризованного индекса состоит из страниц индекса вместо страниц данных. Страницы индекса на уровне листьев некластеризованного индекса содержат ключевые столбцы. Кроме того, они могут содержать подмножество других столбцов в таблице в виде включенных столбцов, чтобы избежать их извлечения из базовой таблицы.
Указатели строк в строках некластеризованных индексов являются указателем на строку или являются кластеризованным ключом индекса для строки, описаны следующим образом:
Если для таблицы имеется кластеризованный индекс или индекс построен на индексированном представлении, то указатель строки — это ключ кластеризованного индекса для строки.
Если таблица является кучей, то есть у нее нет кластеризованного индекса, указатель строки является указателем на строку. Указатель строится на основе идентификатора файла (ID), номера страницы и номера строки на странице. Весь указатель целиком называется идентификатором строки (RID).
Указатели строк также обеспечивают уникальность для строк некластеризованного индекса. В следующей таблице описывается, как ядро СУБД добавляет указатели строк в некластеризованные индексы:
| Базовый тип таблицы | Тип некластеризованного индекса | Указатель строк |
|---|---|---|
| Heap | ||
| Nonunique | RID добавлен в ключевые столбцы | |
| Unique | RID добавлен во включенные столбцы | |
| Уникальный кластеризованный индекс | ||
| Nonunique | Ключи кластеризованного индекса, добавленные в ключевые столбцы | |
| Unique | Ключи кластеризованного индекса, добавленные во включенные столбцы | |
| Неуникальный кластеризованный индекс | ||
| Nonunique | Ключи кластеризованного индекса и уникальный идентификатор (при наличии) добавлены в ключевые столбцы | |
| Unique | Ключи кластеризованного индекса и уникальный идентификатор (при наличии) добавлены во включенные столбцы |
Ядро СУБД никогда не сохраняет заданный столбец более одного раза в некластеризованном индексе. Порядок ключа индекса, указанный пользователем при создании некластеризованного индекса, всегда учитывается: все столбцы указателя строк, которые необходимо добавить в ключ некластеризованного индекса, добавляются в конце ключа после столбцов, указанных в определении индекса. Локаторы строк ключей кластеризованного индекса в некластеризованном индексе могут быть использованы при обработке запросов, независимо от того, указаны ли они явно в определении индекса или добавлены неявно.
В следующих примерах показано, как указатели строк реализуются в некластеризованных индексах:
| Кластеризованный индекс | Определение некластеризованного индекса | Определение некластеризованного индекса с указателями строк | Explanation |
|---|---|---|---|
Уникальный кластеризованный индекс с ключевыми столбцами (A, B, C) |
Неуниковый некластеризованный индекс с ключевыми столбцами (B, A) и включенными столбцами (E, G) |
Ключевые столбцы (B, A, C) и включенные столбцы (E, G) |
Некластеризованный индекс неуникален, поэтому указатель строк должен присутствовать в ключах индекса. Столбцы B и A из указателя строки уже существуют, поэтому добавляется только столбец C. Столбец C добавляется в конец списка ключевых столбцов. |
Уникальный кластеризованный индекс с ключевым столбцом (A) |
Неуниковый некластеризованный индекс с ключевыми столбцами (B, C) и включенными столбцами (A) |
Ключевые столбцы (B, C, A) |
Некластеризованный индекс неуникален, поэтому указатель строки добавляется в ключ. Столбец A еще не указан в качестве ключевого столбца, поэтому он добавляется в конец списка ключевых столбцов. Столбец A теперь находится в ключе, поэтому не нужно хранить его как включенный столбец. |
Уникальный кластеризованный индекс с ключевым столбцом (A, B) |
Уникальный некластеризованный индекс с ключевым столбцом (C) |
Ключевой столбец (C) и включенные столбцы (A, B) |
Некластеризованный индекс уникален, поэтому указатель строки добавляется во включенные столбцы. |
Некластеризованные индексы имеют одну строку в sys.partitions для каждой секции, используемой индексом, с index_id > 1. По умолчанию некластеризованный индекс включает одну секцию. Если некластеризованный индекс состоит из нескольких секций, каждая секция имеет структуру B⁺-дерева, в которой содержатся индексные строки для этой конкретной секции. Например, если некластеризованный индекс имеет четыре секции, в каждой секции есть четыре структуры дерева B+.
В зависимости от типов данных в некластеризованном индексе каждая некластеризованная структура индекса имеет одну или несколько единиц распределения, в которых следует хранить данные для определенной секции и управлять ими. Как минимум, каждый некластеризованный индекс имеет одну IN_ROW_DATA единицу выделения на секцию, в которой хранятся страницы дерева индекса B+ . Некластеризованный индекс также имеет одну LOB_DATA единицу выделения на секцию, если она содержит столбцы больших объектов (LOB), такие как nvarchar(max). Кроме того, он имеет одну ROW_OVERFLOW_DATA единицу выделения на секцию, если она содержит столбцы переменной длины, превышающие ограничение размера строки в 8 060 байтов.
На следующей иллюстрации показана структура некластеризованного индекса, состоящего из одной секции.
Использование включенных столбцов в некластеризованных индексах
Помимо ключевых столбцов, некластеризованный индекс также может содержать неключевые столбцы, хранящиеся на уровне листьев. Эти неключевые столбцы называются включенными столбцами и указываются в INCLUDE предложении инструкции CREATE INDEX .
Индекс с включенными неключевыми столбцами может значительно повысить производительность запросов, когда он охватывает запрос, то есть если все столбцы, используемые в запросе, находятся в индексе как ключевые или неключевые столбцы. Повышение производительности достигается, так как ядро СУБД может находить все значения столбцов в индексе; Доступ к базовой таблице не выполняется, что приводит к меньшему объему операций ввода-вывода диска.
Если столбец должен быть извлечен запросом, но не используется в предикатах запроса, агрегированиях и сортировках, добавьте его в качестве включенного столбца, а не в качестве ключевого столбца. Это имеет следующие преимущества:
Включенные столбцы могут использовать типы данных, которые не разрешены в качестве ключевых столбцов индекса.
Включенные столбцы не учитываются ядром СУБД при вычислении количества ключевых столбцов индекса или размера ключа индекса. При использовании включенных столбцов размер ключа не ограничен максимальным размером 900 байтов. Вы можете создавать более широкие индексы, охватывающие дополнительные запросы.
При перемещении столбца из ключа индекса в включенные столбцы сборка индекса занимает меньше времени, так как операция сортировки индекса становится быстрее.
Если в таблице есть кластеризованный индекс, столбец или столбцы, определенные в кластеризованном ключе индекса, автоматически добавляются в каждый некластеризованный индекс таблицы. Не обязательно указывать их в некластеризованном ключе индекса или как включенные столбцы.
Рекомендации по индексам с включенными столбцами
При разработке некластеризованных индексов с включенными столбцами следует учитывать следующие рекомендации.
Включенные столбцы можно определить только в некластеризованных индексах в таблицах или индексированных представлениях.
Допускаются данные всех типов, за исключением text, ntextи image.
Вычисляемые столбцы, являющиеся детерминированными и точными или неточными, могут быть включенными столбцами. Дополнительные сведения см. в разделе "Индексы" для вычисляемых столбцов.
Как и в ключевых столбцах, вычисляемые столбцы, производные от изображений, ntext и текстовых типов данных, могут быть включены в столбцы, если вычисляемый тип данных столбца разрешен в включенном столбце.
Имена столбцов нельзя указывать как в списке,
INCLUDEтак и в списке ключевых столбцов.Имена столбцов не могут повторяться в списке
INCLUDE.В индексе должен быть определен по крайней мере один ключевой столбец. Максимальное число включенных столбцов — 1023. Это на 1 меньше, чем максимальное количество столбцов таблицы.
Независимо от наличия включенных столбцов, ключевые столбцы индекса должны соответствовать существующим ограничениям размера индекса максимум 16 ключевых столбцов, а общий размер ключа индекса составляет 900 байт.
Рекомендации по проектированию индексов с включенными столбцами
Рекомендуется изменить некластеризованные индексы с большим размером ключа индекса, чтобы только столбцы, используемые в предикаатах запросов, агрегированиях и сортировках были ключевыми столбцами. Все остальные столбцы, покрывающие запрос, сделайте включенными неключевыми столбцами. Таким образом, у вас есть все столбцы, необходимые для покрытия запроса, но сам ключ индекса является небольшим и эффективным.
Например, нужно спроектировать индекс, покрывающий следующий запрос:
SELECT AddressLine1,
AddressLine2,
City,
StateProvinceID,
PostalCode
FROM Person.Address
WHERE PostalCode BETWEEN N'98000' AND N'99999';
Для покрытия запроса необходимо включить в индекс все его столбцы. Хотя можно определить все столбцы как ключевые, размер ключа составит 334 байт. Поскольку единственным столбцом, используемым в качестве условий поиска, является PostalCode столбец, длина которых составляет 30 байт, лучшее проектирование индекса определяется PostalCode как ключевой столбец и включает все остальные столбцы в качестве неключевых столбцов.
Следующая инструкция создает индекс с включенными столбцами, покрывающий данный запрос.
CREATE INDEX IX_Address_PostalCode
ON Person.Address (PostalCode)
INCLUDE (AddressLine1, AddressLine2, City, StateProvinceID);
Чтобы проверить, что индекс охватывает запрос, создайте индекс, а затем отобразите предполагаемый план выполнения. Если план выполнения показывает оператор поиска индекса для IX_Address_PostalCode индекса, запрос охватывается индексом.
Рекомендации по производительности индексов с включенными столбцами
Избегайте создания индексов с очень большим количеством включенных столбцов. Несмотря на то, что индекс может охватывать больше запросов, его преимущество производительности уменьшается, так как:
Меньше строк индекса, помещаемых на страницу. Это повышает эффективность операций ввода-вывода на диске и снижает эффективность кэша.
Для хранения индекса требуется больше места на диске. В частности, добавление varchar(max), nvarchar(max), varbinary(max)или xml-типов данных в включенных столбцах может значительно увеличить требования к дисковой области. Это обусловлено тем, что значения столбцов копируются на конечный уровень индекса. Поэтому они находятся и в индексе, и в базовой таблице.
Производительность изменения данных уменьшается, так как многие столбцы должны быть изменены как в таблице на основе, так и в некластеризованном индексе.
Необходимо определить, перевешивает ли повышение производительности запросов снижение производительности изменения данных и увеличение требований к месту на диске.
Рекомендации по проектированию уникальных индексов
Уникальный индекс гарантирует, что ключ индекса не содержит повторяющихся значений. Создание уникального индекса возможно только в том случае, если уникальность является характеристикой самого данных. Например, если вы хотите убедиться, что значения в NationalIDNumber столбце таблицы HumanResources.Employee уникальны, если первичный ключ имеет EmployeeIDзначение, создайте UNIQUE ограничение для столбца NationalIDNumber . Ограничение отклоняет любую попытку ввести строки с повторяющимися номерами национальных идентификаторов.
В случае уникальных индексов по нескольким столбцам индекс гарантирует, что каждая комбинация значений в ключе индекса уникальна. Например, если уникальный индекс создается в сочетании LastNameFirstNameстолбцов и MiddleName столбцов, в таблице не может быть одинаковых значений для этих столбцов.
Как кластеризованные, так и некластеризованные индексы могут быть уникальными. Вы можете создать уникальный кластеризованный индекс и несколько уникальных некластеризованных индексов в одной таблице.
Преимущества уникальных индексов включают:
- Бизнес-правила, требующие уникальности данных, применяются.
- Предоставляются дополнительные сведения, полезные оптимизатору запросов.
PRIMARY KEY Создание или UNIQUE ограничение автоматически создает уникальный индекс для указанных столбцов. Нет существенных различий UNIQUE между созданием ограничения и созданием уникального индекса независимо от ограничения. Проверка данных выполняется таким же образом, и оптимизатор запросов не отличается от уникального индекса, созданного ограничением или созданным вручную. Однако необходимо создать UNIQUE или PRIMARY KEY ограничение для столбца, если применение бизнес-правил является целью. Таким образом, цель индекса понятна.
Рекомендации по уникальному индексу
Уникальный индекс, ограничение или
UNIQUEограничение нельзя создать,PRIMARY KEYесли в данных существуют повторяющиеся значения ключей.Если данные уникальны и если нужно и далее требовать этой уникальности, создание уникального индекса вместо неуникального для тех же сочетаний столбцов предоставит дополнительные сведения оптимизатору запросов, который может создать более эффективные планы выполнения.
UNIQUEВ этом случае рекомендуется создать ограничение или уникальный индекс.Уникальный некластеризованный индекс может содержать любые неключевые столбцы. Дополнительные сведения см. в разделе "Использование включенных столбцов в некластеризованных индексах".
В отличие от
PRIMARY KEYограничения,UNIQUEограничение или уникальный индекс можно создать со столбцом, допускающим значение NULL, в составе ключа индекса. В целях обеспечения уникальности два NULL считаются равными. Например, это означает, что в уникальном индексе одного столбца столбец может иметь значение NULL только для одной строки в таблице.
Рекомендации по проектированию отфильтрованного индекса
Отфильтрованный индекс — это оптимизированный некластеризованный индекс, особенно подходящий для запросов, требующих небольшого подмножества данных в таблице. Он использует предикат фильтра в определении индекса для индексирования части строк в таблице. Хорошо разработанный отфильтрованный индекс может повысить производительность запросов, уменьшить затраты на обновление индекса и сократить затраты на хранение индексов по сравнению с полно табличным индексом.
Отфильтрованные индексы могут предоставить следующие преимущества по сравнению с индексами, построенными на всей таблице.
Улучшение производительности запроса и качества плана
Хорошо разработанный отфильтрованный индекс повышает производительность запросов и качество плана выполнения, так как он меньше, чем полно табличный некластеризованный индекс. Отфильтрованный индекс имеет отфильтрованную статистику, которая является более точной, чем статистика полной таблицы, так как они охватывают только строки в отфильтрованном индексе.
Сокращение затрат на обновление индекса
Обновление индекса происходит только в случае, если операторы языка обработки данных (DML) влияют на данные в нем. Отфильтрованный индекс снижает затраты на обновление индекса по сравнению с некластеризованным индексом полной таблицы, так как он меньше и обновляется только при влиянии данных в индексе. Можно иметь большое количество отфильтрованных индексов, особенно если они содержат данные, затронутые редко. Аналогичным образом, если отфильтрованный индекс содержит только часто затронутые данные, меньший размер индекса снижает затраты на обновление статистики.
Снижение затрат на хранение индекса
Создание отфильтрованного индекса может уменьшить объем дискового хранилища для некластеризованных индексов, если не требуется полно табличный индекс. Вы можете заменить некластеризованный индекс полной таблицей несколькими отфильтрованными индексами, не увеличивая требования к хранилищу.
Отфильтрованные индексы полезны, если столбцы содержат четко определенные подмножества данных. Ниже приведены примеры.
Столбцы, содержащие множество NULL-значений.
Разнородные столбцы, содержащие категории данных.
Столбцы, содержащие диапазоны значений, таких как суммы, время и даты.
Снижение затрат на обновление отфильтрованных индексов наиболее заметно, если количество строк в индексе меньше по сравнению с полно табличным индексом. Если отфильтрованный индекс включает большую часть строк в таблице, его обслуживание может быть более затратным по сравнению с полнотабличным индексом. В этом случае нужно использовать полнотабличный индекс вместо отфильтрованного.
Отфильтрованные индексы определены в одной таблице и поддерживают только простые операторы сравнения. Если требуется выражение фильтра с сложной логикой или ссылки на несколько таблиц, необходимо создать индексированный вычисляемый столбец или индексированное представление.
Рекомендации по проектированию отфильтрованного индекса
Чтобы разработать эффективные отфильтрованные индексы, важно понять, какие запросы использует приложение и как они связаны с подмножествами данных. Некоторые примеры данных, которые имеют четко определенные подмножества, являются столбцами со многими NULLs, столбцами с разнородными категориями значений и столбцов с различными диапазонами значений.
Следующие рекомендации по проектированию дают несколько сценариев, когда отфильтрованный индекс может предоставлять преимущества по сравнению с полно табличными индексами.
Отфильтрованные индексы для подмножеств данных
Если столбец имеет только несколько соответствующих значений для запросов, можно создать отфильтрованный индекс в подмножестве значений. Например, если столбец в основном имеет значение NULL, запрос требует только ненулевого значения, можно создать отфильтрованный индекс, содержащий строки, отличные от NULL.
Например, в примере базы данных AdventureWorks есть Production.BillOfMaterials таблица с 2679 строками. Столбец EndDate содержит только 199 строк, содержащих значение, отличное от NULL, и другие строки 2480 содержат ЗНАЧЕНИЕ NULL. Следующий отфильтрованный индекс охватывает запросы, возвращающие столбцы, определенные в индексе, и требующие только строки с ненулевым значением для EndDate.
CREATE NONCLUSTERED INDEX FIBillOfMaterialsWithEndDate
ON Production.BillOfMaterials (ComponentID, StartDate)
WHERE EndDate IS NOT NULL;
Отфильтрованный индекс FIBillOfMaterialsWithEndDate допустим для следующего запроса.
Отображение предполагаемого плана выполнения, чтобы определить, использовал ли оптимизатор запросов отфильтрованный индекс.
SELECT ProductAssemblyID,
ComponentID,
StartDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL
AND ComponentID = 5
AND StartDate > '20080101';
Дополнительные сведения о создании отфильтрованных индексов и определении выражения предиката отфильтрованного индекса см. в разделе "Создание отфильтрованных индексов".
Отфильтрованные индексы для разнородных данных
Если таблица содержит строки с разнородными данными, можно создать отфильтрованный индекс для одной или более категорий данных.
Например, продукты, содержащиеся в таблице Production.Product , связаны с идентификатором ProductSubcategoryID, который в свою очередь связан с категориями продуктов, такими как велосипеды, запчасти, одежда или аксессуары. Эти категории являются разнородными, так как их значения столбцов в Production.Product таблице не тесно коррелируются. Например, столбцы Color, ReorderPoint, ListPrice, Weight, Classи Style имеют уникальные характеристики для каждой категории продукта. Предположим, что существуют частые запросы на аксессуары, которые имеют подкатегории от 27 до 36 включительно. Можно повысить результативность запросов на аксессуары, создав отфильтрованный индекс по подкатегориям аксессуаров, как показано в следующем примере.
CREATE NONCLUSTERED INDEX FIProductAccessories
ON Production.Product (ProductSubcategoryID, ListPrice)
INCLUDE (Name)
WHERE ProductSubcategoryID >= 27 AND ProductSubcategoryID <= 36;
Отфильтрованный индекс охватывает следующий запрос, так как результаты запроса содержатся в индексе FIProductAccessories , а план запроса не требует доступа к базовой таблице. Например, выражение предиката запроса ProductSubcategoryID = 33 — это подмножество предиката отфильтрованного индекса ProductSubcategoryID >= 27 и ProductSubcategoryID <= 36, а столбцы ProductSubcategoryID и ListPrice в предикате запроса являются ключевыми столбцами в индексе. Имя сохраняется на конечном уровне индекса в качестве включенного столбца.
SELECT Name,
ProductSubcategoryID,
ListPrice
FROM Production.Product
WHERE ProductSubcategoryID = 33
AND ListPrice > 25.00;
Ключ и включенные столбцы в отфильтрованных индексах
Рекомендуется добавить небольшое количество столбцов в отфильтрованном определении индекса, только если это необходимо для оптимизатора запросов, чтобы выбрать отфильтрованный индекс для плана выполнения запроса. Оптимизатор запросов может выбрать отфильтрованный индекс для запроса независимо от того, выполняется ли он или не охватывает запрос. Однако оптимизатор запросов с большей вероятностью выберет отфильтрованный индекс, если он перекрывает запрос.
В некоторых случаях отфильтрованный индекс перекрывает запрос, не включая в определение отфильтрованного индекса в качестве ключевых или включенных столбцов столбцы из выражения отфильтрованного индекса. Следующие правила содержат описание того, должен ли быть столбец в выражении отфильтрованного индекса ключевым или включенным столбцом в определении отфильтрованного индекса. В примерах используется ранее созданный отфильтрованный индекс FIBillOfMaterialsWithEndDate .
Столбец в отфильтрованном выражении индекса не должен быть ключом или включенным столбцом в определение отфильтрованного индекса, если отфильтрованное выражение индекса эквивалентно предикату запроса, и запрос не возвращает столбец в отфильтрованном выражении индекса с результатами запроса. Например, охватывает следующий запрос, FIBillOfMaterialsWithEndDate так как предикат запроса эквивалентен выражению фильтра и EndDate не возвращается с результатами запроса. Индекс FIBillOfMaterialsWithEndDate не требует включения EndDate в качестве ключа или столбца в определении отфильтрованного индекса.
SELECT ComponentID,
StartDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL;
Столбец в отфильтрованном выражении индекса должен быть ключом или включенным столбцом в определение отфильтрованного индекса, если предикат запроса использует столбец в сравнении, который не эквивалентен выражению отфильтрованного индекса. Например, отфильтрованный индекс FIBillOfMaterialsWithEndDate допустим для следующего запроса, поскольку этот запрос выбирает подмножество строк из отфильтрованного индекса. Однако он не охватывает следующий запрос, так как EndDate используется в сравнении EndDate > '20040101', который не эквивалентен выражению отфильтрованного индекса. Обработчик запросов не может выполнить этот запрос, не проверяя значения EndDate. Поэтому в определении отфильтрованного индекса EndDate должен быть ключевым или включенным столбцом.
SELECT ComponentID,
StartDate
FROM Production.BillOfMaterials
WHERE EndDate > '20040101';
Столбец в выражении отфильтрованного индекса должен быть ключевым или включенным столбцом в определении отфильтрованного индекса, если этот столбец содержится в результирующем наборе запроса. Например, не охватывает следующий запрос, FIBillOfMaterialsWithEndDate так как он возвращает EndDate столбец в результатах запроса. Поэтому в определении отфильтрованного индекса EndDate должен быть ключевым или включенным столбцом.
SELECT ComponentID,
StartDate,
EndDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL;
Ключ кластеризованного индекса таблицы не должен быть ключом или включенным столбцом в определение отфильтрованного индекса. Ключ кластеризованного индекса автоматически включается во все некластеризованные индексы, в том числе отфильтрованные индексы.
Операторы преобразования данных в предикате фильтра
Если оператор сравнения, указанный в отфильтрованном выражении индекса, приводит к неявным или явным преобразованиям данных, ошибка возникает, если преобразование происходит слева от оператора сравнения. Решением является запись отфильтрованного выражения индекса с помощью оператора преобразования данных (CAST или CONVERT) справа от оператора сравнения.
В следующем примере создается таблица со столбцами различных типов данных.
CREATE TABLE dbo.TestTable
(
a INT,
b VARBINARY(4)
);
В следующем отфильтрованном определении индекса столбец b неявно преобразуется в целый тип данных для сравнения его с константой 1. Это вызывает сообщение об ошибке 10611, поскольку преобразование выполняется в левой части оператора в отфильтрованном предикате.
CREATE NONCLUSTERED INDEX TestTabIndex
ON dbo.TestTable (a, b)
WHERE b = 1;
Решением является преобразование константы в правой части к типу столбца b, как показано в следующем примере.
CREATE INDEX TestTabIndex
ON dbo.TestTable (a, b)
WHERE b = CONVERT (VARBINARY(4), 1);
Перемещение преобразования данных из левой части оператора сравнения в правую может изменить значение преобразования. В предыдущем примере когда CONVERT оператор добавили справа, сравнение изменилось с int на varbinary.
Архитектура индексов columnstore
Индекс columnstore — это технология хранения, извлечения и управления данными с помощью формата данных columnar, называемого columnstore. Дополнительные сведения см. в разделе "Индексы Columnstore: обзор".
Сведения о версии и сведения о новых возможностях см . в новых индексах columnstore.
Знание этих основных элементов упрощает понимание других статей на тему columnstore, которые объясняют, как эффективно использовать эту технологию.
Хранилище данных использует колонночное хранилище и строковое хранилище.
При обсуждении индексов columnstore для обозначения формата хранения данных используются термины rowstore и columnstore. Индексы columnstore используют оба типа хранилища.
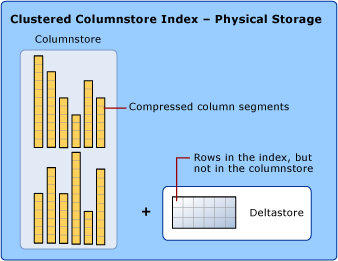
columnstore — это данные, логически организованные в виде таблицы, состоящей из строк и столбцов, и физически хранящиеся как столбцы
Индекс columnstore физически сохраняет большинство данных в формате columnstore. В этом формате данные представлены столбцами, которые можно сжимать и распаковывать. Нет необходимости распаковывать другие значения в каждой строке, которая не запрашивается запросом. Благодаря этому можно быстро просматривать целые столбцы большой таблицы.
rowstore — это данные, логически организованные в виде таблицы, состоящей из строк и столбцов, и физически хранящиеся как строки. Это стандартный способ хранения реляционных данных таблиц Это был традиционный способ хранения данных реляционной таблицы, таких как кластеризованный индекс дерева B+ или куча.
Индекс columnstore также физически сохраняет некоторые строки в формате rowstore под названием deltastore. Deltastore, также называемый разностными группами строк, является местом хранения для строк, которые слишком мало числа, чтобы претендовать на сжатие в columnstore. Каждая дельта-группа строк реализуется как кластеризованный индекс B+ дерева, который является хранилищем строк.
Операции выполняются в сегментах групп строк и столбцов
Индексы columnstore группируют строки в управляемые элементы. Каждый из этих элементов называется группой строк. Для повышения производительности количество строк в группе строк достаточно большое, чтобы повысить коэффициент сжатия и достаточно мало, чтобы воспользоваться операциями с памятью.
В группах строк индекс columnstore может выполнять следующие операции:
сжимает группы строк в columnstore (выполняется в каждом сегменте столбца в группе строк);
Объединяет группы строк во время
ALTER INDEX ... REORGANIZEоперации, включая удаление удаленных данных.Повторно создает все группы строк во время
ALTER INDEX ... REBUILDоперации.отправляет отчеты об исправности и фрагментации групп строк в динамических административных представлениях.
deltastore состоит из одной или нескольких групп строк, которые называются разностными группами строк. Каждая дельта-группа строк — это кластеризованный индекс дерева B+, в котором хранятся небольшие массовые загрузки и вставка, до тех пор пока группа строк не содержит 1,048,576 строк, и в этот момент процесс, называемый tuple-mover, автоматически сжимает закрытую группу строк в columnstore.
Дополнительные сведения о состоянии группы строк см. в sys.dm_db_column_store_row_group_physical_stats.
Tip
Слишком большое количество небольших групп строк ухудшает качество индекса columnstore. Операция реорганизации объединяет небольшие группы строк, следуя внутренней политике порогового значения, которая определяет, как удалить удаленные строки и объединить сжатые группы строк. После слияния качество индекса улучшается.
В SQL Server 2019 (15.x) и более поздних версиях перемещение кортежей поддерживается задачей фонового слияния, которая автоматически сжимает небольшие открытые дельта-группы строк, существующие в течение некоторого времени в соответствии с внутренним пороговым значением, или объединяет сжатые дельта-группы строк, из которых было удалено большое количество строк.
Каждый столбец содержит несколько собственных значений в каждой группе строк. Эти значения называются сегментами столбцов. Каждая rowgroup содержит один сегмент столбца для каждого столбца в таблице. Каждый столбец содержит один сегмент столбца в каждой группе строк.
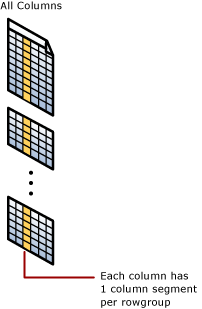
Когда индекс columnstore сжимает группу строк, он отдельно сжимает каждый сегмент столбца. Чтобы распаковать целый столбец, индексу columnstore необходимо распаковать только один сегмент столбца из каждой группы строк.
Небольшие загрузки и вставки переносятся в deltastore
Индекс columnstore улучшает сжатие и производительность columnstore за счет сжатия как минимум 102 400 строк в индекс columnstore за раз. Чтобы выполнить массовое сжатие строк, индекс columnstore накапливает небольшие загрузки и вставки в deltastore. Операции deltastore обрабатываются в фоновом режиме. Чтобы вернуть результаты запроса, кластеризованный индекс columnstore объединяет результаты запроса как из columnstore, так и deltastore.
Переход строк в deltastore происходит в следующих случаях:
если они вставляются с помощью инструкции
INSERT INTO ... VALUES;В конце массовой нагрузки и меньше 102 400.
Updated. (каждое обновление реализуется как операция удаления или вставки).
В deltastore также хранится список идентификаторов для удаленных строк, которые были помечены как удаленные, но еще не удалены физически из columnstore.
Когда разностные группы строк заполнены, они сжимаются в columnstore
Прежде чем сжать группу строк в columnstore, кластеризованные индексы собирают 1 048 576 строк в каждой разностной группе строк. Это повышает степень сжатия индекса columnstore. Когда разностная группа строк достигает максимального количества строк, она переходит из OPENCLOSED состояния в состояние. Фоновый процесс, который называется задачей переноса кортежей, проверяет наличие закрытых групп строк. При обнаружении закрытой группы строк она сжимается и сохраняется в columnstore.
Когда разностная группа строк была сжата, существующая разностная группа строк переходит в TOMBSTONE состояние, которое будет удалено позже перемещением кортежей, когда нет ссылки на нее, и новая сжатые группы строк помечаются как COMPRESSED.
Дополнительные сведения о состоянии группы строк см. в sys.dm_db_column_store_row_group_physical_stats.
Чтобы перестроить или реорганизовать индекс, вы можете принудительно сжать разностную группу строк в columnstore с помощью ALTER INDEX. Если во время сжатия возникает давление памяти, индекс columnstore может уменьшить количество строк в сжатой группе строк.
Каждая секция таблицы содержит собственные группы строк и разностные группы
Концепция секционирования одинакова в кластеризованном индексе, куче и индексе columnstore. При секционировании таблица разделяется на небольшие группы строк в соответствии с диапазоном значений столбцов. Часто используется для управления данными. Например, можно создать секцию для каждого года данных, а затем использовать переключение секций для архивации старых данных в менее дорогое хранилище.
Группы строк всегда определяются в пределах секции таблицы. При секционировании индекса columnstore каждая секция получает свои собственные сжатые группы строк и разностные группы строк. Неразделённая таблица содержит один раздел.
Tip
Если вам нужно удалить данные из columnstore, попробуйте использовать секционирование таблиц. Выключение и усечение секций, которые больше не нужны, является эффективной стратегией удаления данных без введения фрагментации в columnstore.
Каждая секция может содержать несколько разностных групп строк
Каждая секция может содержать несколько разностных групп строк. Если индекс columnstore должен добавить данные в делта группу строк, но она заблокирована другой транзакцией, индекс columnstore пытается получить блокировку для другой делта группы строк. Если нет разностных групп строк, индекс columnstore создает новую разностную группу строк. Например, у таблицы с 10 секциями может быть 20 и более разностных групп строк.
Объединение индексов columnstore и rowstore в одной таблице
Некластеризованный индекс содержит копию всех или части строк и столбцов в базовой таблице. Индекс определяется как один или несколько столбцов таблицы и включает дополнительное условие для фильтрации строк.
Можно создать обновляемый некластеризованный индекс columnstore в таблице rowstore. Индекс columnstore сохраняет копию данных, так что вам обязательно потребуется дополнительное хранилище. Однако данные в индексах columnstore сжимаются до гораздо меньшего размера, чем требуют таблицы rowstore. Это позволяет выполнять аналитику по индексу columnstore и рабочим нагрузкам OLTP в индексе rowstore одновременно. Columnstore обновляется при изменении данных в таблице rowstore, поэтому оба индекса работают с одинаковыми данными.
Таблица типа rowstore может иметь один некластеризованный индекс columnstore. Дополнительные сведения см. в руководстве по проектированию индексов Columnstore.
В кластеризованной таблице columnstore можно использовать один или несколько некластеризованных индексов rowstore. Это обеспечивает эффективность поиска по таблицам на основе базового индекса columnstore. Кроме того, появляется доступ к другим возможностям. Например, можно применить уникальность с помощью UNIQUE ограничения в таблице rowstore. Если неуникальное значение не вставляется в таблицу rowstore, СУБД также не вставляет это значение в columnstore.
Некластеризованные columnstore соображения по производительности
Определение некластеризованного индекса columnstore поддерживает использование отфильтрованных условий. Чтобы свести к минимуму влияние на производительность добавления индекса columnstore, используйте выражение фильтра для создания некластеризованного индекса columnstore только в подмножестве данных, необходимых для аналитики.
Оптимизированная по памяти таблица может иметь один колоночный индекс. Вы можете создать столбец при создании таблицы или добавить его позже с помощью команды ALTER TABLE.
Дополнительные сведения см. в разделе индексы Columnstore — производительность запросов.
Рекомендации по проектированию хэш-индекса, оптимизированного для памяти
При использовании In-Memory OLTP все оптимизированные для памяти таблицы должны иметь по крайней мере один индекс. Для оптимизированной для памяти таблицы каждый индекс также оптимизирован для памяти. Хэш-индексы являются одним из возможных типов индексов в таблице, оптимизированной для памяти. Дополнительные сведения см. в разделе "Индексы для таблиц, оптимизированных для памяти".
Архитектура хэш-индекса, оптимизированная для памяти
Хэш-индекс состоит из массива указателей. Каждый элемент массива называется хэш-контейнером.
- Каждый контейнер имеет размер 8 байт, в которых хранится адрес списка ссылок на записи ключей.
- Каждая запись представляет собой значение ключа индекса, к которому добавляется адрес соответствующей строки в оптимизированной для памяти таблице.
- Каждая запись указывает на следующую запись в списке ссылок на записи, связанных с текущим контейнером.
Количество контейнеров должно быть указано во время создания индекса:
- Чем ниже соотношение сегментов к строкам таблицы или к отдельным значениям, тем длиннее среднее значение списка ссылок на контейнеры.
- Короткие списки обладают большим быстродействием по сравнению с длинными.
- Максимальное число контейнеров в хэш-индексах составляет 1 073 741 824.
Tip
Сведения о том, как определить право BUCKET_COUNT для данных, см. в разделе "Настройка количества сегментов хэш-индекса".
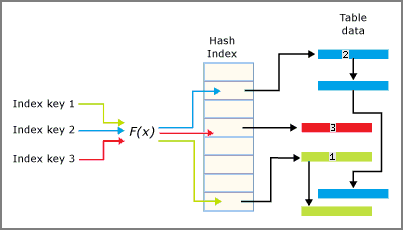
Хэш-функция применяется к ключевым столбцам индекса, и результат функции определяет, к какому контейнеру относится ключ. Каждый контейнер содержит указатель на строки, хэшированные значения ключей которых сопоставлены с этим контейнером.
Функция, используемая для хэширования индексов, имеет следующие характеристики.
- Ядро СУБД имеет одну хэш-функцию, используемую для всех хэш-индексов.
- Хэш-функция является детерминированной. Одно значение входного ключа всегда связано с одним контейнером в хэш-индексе.
- Несколько ключей индекса могут быть сопоставлены с тем же хэш-контейнером.
- Хэш-функция сбалансирована, а это означает, что распределение значений ключей индекса, связанных с хэш-контейнерами, соответствует распределению Пуассона или нормальному распределению, а не плоскому линейному распределению.
- Распределение Poisson не является даже распределением. Значения ключа индекса равномерно не распределяются в хэш-контейнерах.
- Если два ключа индекса сопоставлены с тем же хэш-контейнером , возникает конфликт хэша. Большое количество хэш-конфликтов может повлиять на производительность операций чтения. Реалистичная цель состоит в том, чтобы 30 процентов контейнеров содержали два разных ключевых значения.
Взаимозависимость хэш-индекса и контейнеров иллюстрируется на следующем рисунке.
Настройка количества сегментов хэш-индекса
Число контейнеров хэш-индекса указывается в момент создания индекса и может быть изменено с помощью синтаксиса ALTER TABLE...ALTER INDEX REBUILD.
В большинстве случаев число корзин должно составлять от 1 до 2 раз больше, чем количество различных значений в ключе индекса.
Вы не всегда можете предсказать, сколько значений имеет определенный ключ индекса. Производительность обычно хороша, если BUCKET_COUNT значение находится в пределах 10 раз от фактического количества ключевых значений, а переоценка обычно лучше, чем недооценка.
Слишком мало контейнеров может иметь следующие недостатки:
- Возникает больше конфликтов хэша из-за уникальных значений ключей.
- Каждое уникальное значение вынуждено использовать один и тот же контейнер с другим уникальным значением.
- Средняя длина цепочки для контейнера возрастает.
- Чем длиннее цепочка контейнеров, тем медленнее скорость выполнения проверки на равенство индексов.
Слишком много контейнеров может иметь следующие недостатки:
- Слишком большое количество контейнеров может привести к более пустым контейнерам.
- Пустые контейнеры влияют на производительность полной проверки индекса. Если сканирование выполняется регулярно, рассмотрите возможность выбора количества контейнеров, близкого к количеству уникальных значений ключа индекса.
- Пустые контейнеры задействуют память, хотя каждый контейнер использует всего 8 байт.
Note
При добавлении большего числа контейнеров цепочка записей, которые имеют повторяющееся значение, не уменьшается. Частота дублирования значений используется для определения того, является ли хэш-индекс или некластеризованный индекс соответствующим типом индекса, а не для вычисления количества сегментов.
Рекомендации по производительности хэш-индексов
Производительность хэш-индекса обладает следующими характеристиками.
- Отличная, если предикат в предложении
WHEREзадает точное значение каждого столбца в ключе хэш-индекса. Хэш-индекс возвращается к сканированию с заданным предикатом неравенства. - Низкая, если в предикате в предложении
WHEREуказан диапазон значений ключа индекса. - Плохо, если предикат в
WHEREпредложении предусматривает одно конкретное значение для первого столбца ключа хэш-индекса двух столбцов, но не указывает значение для других столбцов ключа.
Tip
Предикат должен включать все столбцы в ключ хеш-индекса. Хэш-индекс требует всего ключа для поиска по индексу.
Если используется хэш-индекс, и число уникальных ключей индекса более чем в 100 раз меньше, чем количество строк, рассмотрите возможность увеличения числа корзин, чтобы избежать длинных цепочек строк, или используйте некластеризованный индекс.
Создание хэш-индекса
При создании хэш-индекса следует учитывать:
- Хэш-индекс может существовать только для таблицы, оптимизированной для памяти. Он не может существовать в таблице на основе диска.
- Хэш-индекс по умолчанию не уникален, но может быть объявлен как уникальный.
В следующем примере создается уникальный хэш-индекс:
ALTER TABLE MyTable_memop ADD INDEX ix_hash_Column2
UNIQUE HASH (Column2) WITH (BUCKET_COUNT = 64);
Версии строк и сборка мусора в оптимизированных для памяти таблицах
В оптимизированной для памяти таблице, когда строка затрагивается оператором UPDATE, таблица создает обновленную версию строки. Во время транзакции обновления другие сеансы могут считывать старую версию строки, поэтому избежать замедления производительности, связанного с блокировкой строки.
Хэш-индекс также может иметь разные версии своих записей для размещения обновления.
Позже, когда старые версии больше не требуются, поток сборки мусора перебирает список контейнеров и их списки ссылок, удаляя старые записи. Поток сборки мусора работает быстрее, если списки ссылок короткие. Дополнительные сведения см. в статье Сборка мусора OLTP в памяти.
Рекомендации по проектированию некластеризованных индексов, оптимизированные для памяти
Помимо хэш-индексов, некластеризованные индексы являются другими возможными типами индексов в оптимизированной для памяти таблице. Дополнительные сведения см. в разделе "Индексы для таблиц, оптимизированных для памяти".
Архитектура некластеризованного индекса, оптимизированная для памяти
Некластеризованные индексы в таблицах, оптимизированных для памяти, реализуются с помощью структуры данных, называемой деревом Bw-tree, первоначально представленной и описанной в Microsoft Research в 2011 году. BW-дерево — это разновидность сбалансированного дерева без блокировок и кратковременных блокировок. Дополнительные сведения см. в разделе "Дерево Bw: дерево B для новых аппаратных платформ".
На высоком уровне дерево Bw представляет собой карту страниц, упорядоченных по ID страницы (PidMap), механизм для выделения и повторного использования ID страниц (PidAlloc), и набор страниц, связанных друг с другом и с картой страниц. Эти три высокоуровневых подкомпоновки составляют базовую внутреннюю структуру дерева Bw-дерева.
Эта структура схожа со структурой обычного сбалансированного дерева в том плане, что каждая страница имеет набор упорядоченных ключевых значений и в индексе есть уровни, каждый из которых указывает на нижележащий уровень, а конечные уровни указывают на строки данных. Тем не менее есть несколько отличий.
Как и в хэш-индексах, для поддержки управления версиями можно связать несколько строк данных. Указателями на страницы между уровнями являются идентификаторы логических страниц, которые представляют собой смещения в таблице сопоставления страниц, которая, в свою очередь, содержит физические адреса всех страниц.
Изменение страниц индекса на месте не производится. Поэтому были введены новые разностные страницы.
- Для изменения страницы блокировка или кратковременная блокировка не требуется.
- Страницы индекса не являются фиксированным размером.
Ключевое значение на каждой странице уровня, не являющаяся листовой, является самым высоким значением, которое содержится в дочернем элементе, на который она указывает, кроме того, каждая строка содержит логический идентификатор страницы. Страница конечного уровня, помимо значения ключа, содержит физический адрес строки данных.
Поисковые запросы по точкам похожи на деревья B, за исключением того, что страницы связаны только в одном направлении, система управления базами данных следует указателям на правую страницу, где каждая внутренняя страница имеет наибольшее значение своего дочернего элемента, а не наименьшее значение, как в дереве B.
Если страница уровня листа должна измениться, движок базы данных не изменяет саму страницу. Вместо этого ядро СУБД создает разностную запись, описывающую изменение, и добавляет ее на предыдущую страницу. Затем оно также меняет адрес этой прежней страницы в таблице сопоставления страниц на адрес разностной записи, который теперь становится физическим адресом страницы.
Существует три различных операции, которые могут потребоваться для управления структурой дерева Bw: консолидации, разделения и слияния.
Консолидация разностных данных
Длинная цепочка разностных записей может в конечном итоге снизить производительность поиска, так как это может потребовать длинных обходов цепочки при поиске по индексу. Если новая разностная запись добавляется в цепочку, которая уже содержит 16 элементов, изменения в разностных записях объединяются на страницу индекса со ссылкой, а затем перестроена страница, включая изменения, указанные новой разностной записью, которая вызвала консолидацию. У вновь созданной страницы есть тот же идентификатор страницы, но новый адрес памяти.
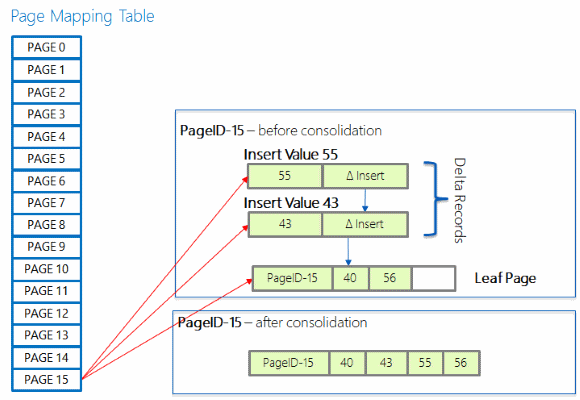
Разделить страницу
Страница индекса в дереве Bw растет по мере необходимости, начиная с хранения одной строки до хранения не более 8 КБ. После роста страницы индекса до 8 КБ новая вставка одной строки приводит к разделию страницы индекса. Для внутренней страницы это означает, что при добавлении другого ключевого значения и указателя на конечную страницу строка будет слишком большой, чтобы поместиться на страницу после включения всех разностных записей. Сведения о статистике в заголовке страницы для конечной страницы отслеживают, сколько пространства требуется для консолидации разностных записей. Эти сведения корректируются при добавлении каждой новой разностной записи.
Операция разделения выполняется в двух атомарных шагах. На следующей схеме предполагается, что на конечной странице выполняется разделение, так как ключ со значением 5 вставляется, а нелебезопасная страница указывает на конец текущей страницы конечного уровня (ключевое значение 4).

Шаг 1. Выделите две новые страницы P1 и P2разделите строки со старой P1 страницы на эти новые страницы, включая только что вставленную строку. Новый слот в таблице сопоставления страниц используется для хранения физического адреса страницы P2. Страницы P1 и P2 недоступны для параллельных операций. Кроме того, задается логический указатель на P1P2 объект. Затем на одном атомарном шаге обновите таблицу сопоставления страниц, чтобы изменить указатель с старого P1 на новое P1.
Шаг 2. Нелиафетная страница указывает на P1 то, что нет прямого указателя на нелебезопасную страницу P2.
P2 доступен только через P1. Чтобы создать указатель на небезопасную страницу, выделите новую нелифайлую страницу P2(внутреннюю страницу индекса), скопируйте все строки из старой небезопасной страницы и добавьте новую строку для указания P2. После этого в одном атомарном шаге обновите таблицу сопоставления страниц, чтобы изменить указатель с старой нелиафетной страницы на новую нелегивую страницу.
Страница слияния
DELETE Если операция приводит к тому, что страница имеет менее 10 процентов максимального размера страницы (8 КБ) или с одной строкой на ней, эта страница объединяется с непрерывной страницей.
При удалении строки со страницы добавляется разностная запись для операции удаления. Кроме того, выполняется проверка, чтобы определить, подходит ли индексная страница (нелистовая страница) для слияния. Эта проверка проверяет, не превышает ли оставшееся пространство после удаления строки меньше 10 процентов максимального размера страницы. Если это применимо, слияние выполняется в трех атомарных шагах.
На следующем рисунке предполагается, что DELETE операция удаляет значение ключа 10.

Шаг 1. Создается разностная страница, представляющая значение 10 ключа (синий треугольник), и его указатель на небезопасную страницу устанавливается на новую разностную страницу Pp1 . Кроме того, создается специальная страница слияния -delta (зеленый треугольник), которая связана с указанием разностной страницы. На этом этапе обе страницы (разностная и разностная страница) не отображаются для любой параллельной транзакции. На одном атомарном шаге указатель на страницу конечного уровня в таблице сопоставления страниц обновляется, чтобы указать на страницу P1 слияния-разностной страницы. На этом шаге запись для значения 10 ключа в Pp1 настоящее время указывает на страницу слияния-delta.
Шаг 2. Строка, представляющая ключевое значение 7 на странице Pp1 , отличной от нелифлекса, должна быть удалена, а запись для значения 10 ключа обновлена для указания P1. Для этого выделяется новая неклафовая страница Pp2 , а все строки Pp1 из них копируются, за исключением строки, представляющей значение 7ключа, а затем строка для значения 10 ключа обновляется, чтобы указать на страницу P1. После этого на одном атомарном шаге точка входа Pp1 таблицы сопоставления страниц обновляется до точки Pp2.
Pp1 больше недоступен.
Шаг 3. Страницы P2 конечного уровня и объединены, P1 а разностные страницы удалены. Для этого выделяется новая страница, а строки из P3 и P2 объединяются, а изменения разностной страницы P1 включаются в новуюP3. Затем на одном атомарном шаге запись таблицы сопоставления страниц, указывающей на страницу, обновляется, чтобы указать на страницу P1P3.
Рекомендации по производительности для некластеризованных индексов, оптимизированных для памяти
Производительность некластеризованного индекса лучше, чем с хэш-индексами при запросе оптимизированной для памяти таблицы с предикатами неравенства.
Столбец в таблице, оптимизированной для памяти, может быть частью хэш-индекса и некластеризованного индекса.
Если ключевой столбец в некластеризованном индексе имеет много повторяющихся значений, производительность может снизиться для обновлений, вставок и удаления. Одним из способов повышения производительности в этой ситуации является добавление столбца, который имеет лучшую выборку в ключе индекса.
Метаданные индекса
Чтобы проверить метаданные индекса, такие как определения индекса, свойства и статистика данных, используйте следующие системные представления:
- sys.objects
- sys.indexes
- sys.index_columns
- sys.columns
- sys.types
- sys.partitions
- sys.internal_partitions
- sys.dm_db_index_usage_stats
- sys.dm_db_partition_stats
- sys.dm_db_index_operational_stats
Предыдущие представления применяются ко всем типам индексов. Для индексов columnstore используйте также следующие представления:
- sys.column_store_row_groups
- sys.column_store_segments
- sys.column_store_dictionaries
- sys.dm_column_store_object_pool
- sys.dm_db_column_store_row_group_operational_stats
- sys.dm_db_column_store_row_group_physical_stats
Все столбцы в индексах columnstore хранятся в метаданных как включенные столбцы. Индекс columnstore не имеет ключевых столбцов.
Для индексов в таблицах, оптимизированных для памяти, также используйте следующие представления:
- sys.hash_indexes
- sys.dm_db_xtp_hash_index_stats
- sys.dm_db_xtp_index_stats
- sys.dm_db_xtp_nonclustered_index_stats
- sys.dm_db_xtp_object_stats
- sys.dm_db_xtp_table_memory_stats
- sys.memory_optimized_tables_internal_attributes
Связанный контент
- Инструкция CREATE INDEX (Transact-SQL)
- Оптимизация обслуживания индексов позволяет повысить производительность запросов и снизить уровень потребления ресурсов
- Секционированные таблицы и индексы
- Индексы для оптимизированных для памяти таблиц
- Индексы Columnstore: обзор
- Индексы вычисляемых столбцов
- Настройка некластеризованных индексов с предложениями отсутствующих индексов