Общие сведения о Spark
MapReduce и аналогичные платформы обработки данных не могут эффективно выражать многие типы распределенных приложений. Spark1 ориентирован на определенное подмножество этих приложений: те из них, которые используют один и тот же рабочий набор данных в нескольких циклах вычислений. Сюда входят приложения трех категорий:
- Итеративные задания: многие алгоритмы (например, большинство машинного обучения) попадают в эту категорию. Хотя MapReduce может выражать такие вычисления, каждое задание требует перезагрузки данных с диска, что значительно снижает производительность.
- Интерактивные задания: Hadoop позволяет выполнять нерегламентированные запросы к данным с помощью таких средств, как Pig и Hive, которые позволяют пользователям выполнять задания MapReduce с помощью простых интерфейсов SQL. К сожалению, при этом возникает большая задержка, поскольку каждое задание требует загрузки всего набора данных с диска. Лучше, если платформа для выполнения запросов будет более быстрой.
- Потоковая передача заданий. Для этих моделей требуются периодические обновления. Например, системы добавочной обработки периодически обновляют сохраненные параметры в соответствии с новыми входными данными.
Проще говоря, в MapReduce нет абстракции общего доступа к данным для использования распределенной памяти. Такая абстракция предоставляет сразу нескольким приложениям параллельный доступ к данным в пределах кластера. Кроме того, неэффективное использование ресурсов (например, неадекватное использование памяти в результате переноса данных на диск после каждого задания) вызывает множество проблем с производительностью.
Одной из платформ, решающих такие проблемы, является Spark. Для поддержки итеративных, интерактивных и потоковых приложений Spark использует специальную абстракцию, которая называется RDD (устойчивые распределенные наборы данных)2. Прежде чем обсуждать RDD, рассмотрим платформу Spark в общих чертах.
Общие сведения о Spark
Цель любой распределенной платформы программирования — поддержка выполнения параллельных вычислений на нескольких узлах с высокой производительностью. Рассмотрим итеративное приложение, которое запускает алгоритм машинного обучения на большом графе. Spark сохраняет этот граф как RDD, как показано на следующем рисунке. Клиент Spark сохраняет сведения о выполняемой программе и сопоставляет ее с характерными для Spark операциями с кластером, который состоит из множества рабочих ролей. Диспетчер кластеров преобразует эти операции в задачи и выполняет их на рабочих узлах. Для любого кластера нужно, чтобы приложения были адекватно разнесены по времени — это позволит максимально повысить эффективность использования и производительность. Spark позволяет использовать различные политики для формирования графика задач в кластере с учетом таких факторов, как приоритет, длительность и ресурсы, необходимые для каждой задачи.
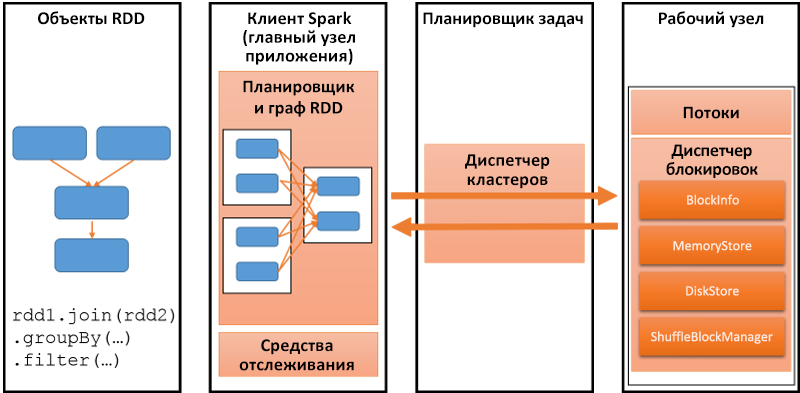
Рис. 1. Наиболее важные части платформы Spark
Spark представляет собой около 14 000 строк кода на Scala, статически типизированным высокоуровневом языке программирования для виртуальных машин на базе Java.
Spark использует RDD — абстракцию распределенной памяти для поддержки отказоустойчивых вычислений в памяти в крупных наборах данных. Программисты вызывают операции с RDD, передавая замыкания (функции) рабочим ролям. Замыкания копируются в эти рабочие роли и выполняются в них же. Рассмотрим каждую часть этой системы подробно.
Разработчики приложений Spark пишут программу-драйвер для подключения к кластеру рабочих ролей. Драйвер определяет один или несколько RDD и вызывает действия с этими RDD. Кроме того, драйвер отслеживает журнал преобразований каждого RDD, в котором история его создания отражается в виде направленного ациклического графа (DAG). Рабочие роли являются долгосрочными процессами (выполняются на протяжении всего жизненного цикла приложения), которые могут хранить разделы RDD в ОЗУ во время операций.
Объект SparkContext может подключаться к нескольким типам диспетчеров кластеров, обрабатывающих планирование приложений и задач, как показано на следующем рисунке. Диспетчер кластеров отделяет различные программы Spark друг от друга. Каждое приложение имеет собственный драйвер и выполняется в изолированных исполнителях, координируемых диспетчером кластеров. В настоящее время Spark поддерживает приложения, написанные на Scala, Java и Python.
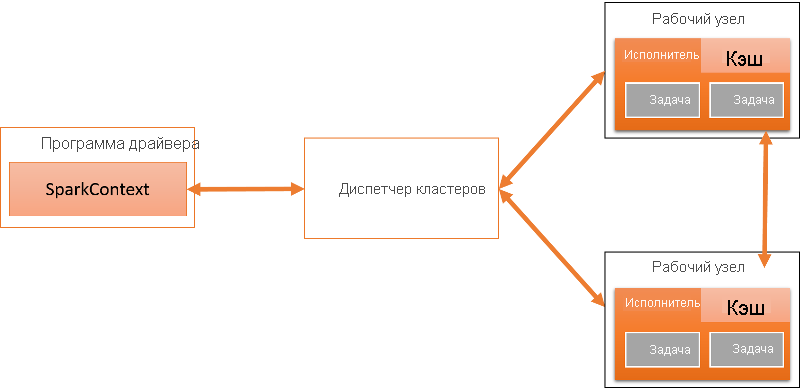
Рис. 2. Архитектура Spark
Каждое приложение Spark выполняется как независимый набор процессов в распределенном кластере. Драйвер — это процесс, который запускает функцию main() приложения и создает объект SparkContext. Приложения Spark координируются объектом SparkContext. Объект SparkContext, в свою очередь, подключается к диспетчеру кластеров, а тот выделяет ресурсы для всех приложений в кластере. Объект SparkContext также содержит ряд неявных преобразований и параметров для использования с различными функциями Spark.
В настоящее время система поддерживает три диспетчера кластеров:
- Автономный: Spark включает простой диспетчер кластеров, который упрощает настройку кластера. Группа приложений, отправляемых в автономном режиме, выполняется в порядке поступления, и каждое приложение будет пытаться использовать все доступные узлы.
- Apache Mesos3. Это общий диспетчер кластеров, который также может запускать Hadoop MapReduce и другие распределенные приложения. Mesos позволяет использовать статистический и динамический общий доступ приложений к ядрам ЦПУ.
- Hadoop YARN 4. Мы рассмотрели Hadoop YARNв предыдущем модуле. Spark поддерживает два режима развертывания в YARN. В режиме кластера YARN драйвер Spark выполняется внутри главного процесса приложения, управляемого YARN. Таким образом, единственная роль клиента — это запуск приложения. В режиме клиента YARN драйвер выполняется в клиентском процессе, а класс управления приложением (AM) используется только для запроса ресурсов из YARN. При выполнении в YARN Spark поддерживает динамическое выделение ресурсов, которое возвращает бездействующие ресурсы, выделенные приложению, обратно в общий пул.
Как только SparkContext подключается к ClusterManager, Spark получает исполнителей на рабочих узлах. Исполнители — это фактические процессы, которые выполняют вычисления и в которых хранятся данные. Получив исполнитель, система отправляет ему код Java/Python/Scala и запускает его как задачи. Обратите внимание на то, что каждое приложение имеет собственные процессы исполнителей, которые выполняют задачи в нескольких потоках. Исполнитель существует в течение всего жизненного цикла приложения.
Преимущество этого подхода в том, что приложения изолированы друг от друга. Решения по планированию выполняются отдельными драйверами, не зависящими от других приложений. Кроме того, исполнители для разных приложений изолируются, так как каждый из них выполняется на отдельной виртуальной машине Java. Недостаток же заключается в том, что обмен данными между приложениями при этом затрудняется.
Драйвер — это процесс, в котором выполняется метод main() программы. Он имеет две основные роли:
- Преобразование пользовательской программы в задачи. На высоком уровне программа Spark неявно создает логический DAG операций. Драйвер преобразует его в физический план выполнения. На этом этапе выполняются несколько операций оптимизации, преобразующих граф выполнения в набор этапов, где каждый этап включает несколько задач.
- Планирование задач для исполнителей: после создания физического плана выполнения драйвер планирует выполнение отдельных задач на исполнителях. Драйвер обеспечивает глобальное представление всех исполнителей.
Исполнители — это рабочие процессы, которые создаются при запуске приложения Spark и выполняются вплоть до завершения работы приложения. Исполнители выполняют задачи, запланированные драйвером, и возвращают результаты. Каждый исполнитель состоит из BlockManager, который предоставляет хранилище в памяти для кэширования RDD.
Основу Spark составляет выполнение и хранение RDD, о котором мы расскажем в следующем уроке.
Примечание об оболочке Spark
Помимо написания программ Spark предоставляет интерактивную оболочку. Она позволяет легко изучить API Spark и служит инструментом для интерактивного анализа больших наборов данных. Оболочка поддерживает как Python, так и Scala (но не Java).
Ссылки
- Zaharia, Matei and Chowdhury, Mosharaf and Franklin, Michael J and Shenker, Scott and Stoica, Ion (2010). Spark: cluster computing with working sets Proceedings of the 2nd USENIX conference on Hot topics in cloud computing
- Zaharia, Matei and Chowdhury, Mosharaf and Das, Tathagata and Dave, Ankur and Ma, Justin and McCauley, Murphy and Franklin, Michael J and Shenker, Scott and Stoica, Ion (2012). Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing Proceedings of the 9th USENIX conference on Networked Systems Design and Implementation
- Hindman, Benjamin and Konwinski, Andy and Zaharia, Matei and Ghodsi, Ali and Joseph, Anthony D and Katz, Randy H and Shenker, Scott and Stoica, Ion (2012). Mesos: A Platform for Fine-Grained Resource Sharing in the Data Center. NSDI
- Vavilapalli, Vinod Kumar and Murthy, Arun C and Douglas, Chris and Agarwal, Sharad and Konar, Mahadev and Evans, Robert and Graves, Thomas and Lowe, Jason and Shah, Hitesh and Seth, Siddharth and others (2013). Apache Hadoop YARN: Yet another resource negotiator Proceedings of the 4th annual Symposium on Cloud Computing