Общие сведения об интеллектуальной обработке запросов
В SQL Server 2017 и 2019, а также в Azure SQL корпорация Майкрософт представила множество новых функций для уровней совместимости 140 и 150. Многие из этих функций исправляют то, что раньше входило в область действия антишаблонов, например использование определяемых пользователем функций скалярных значений и использование табличных переменных.
Эти функции можно разделить на несколько категорий.
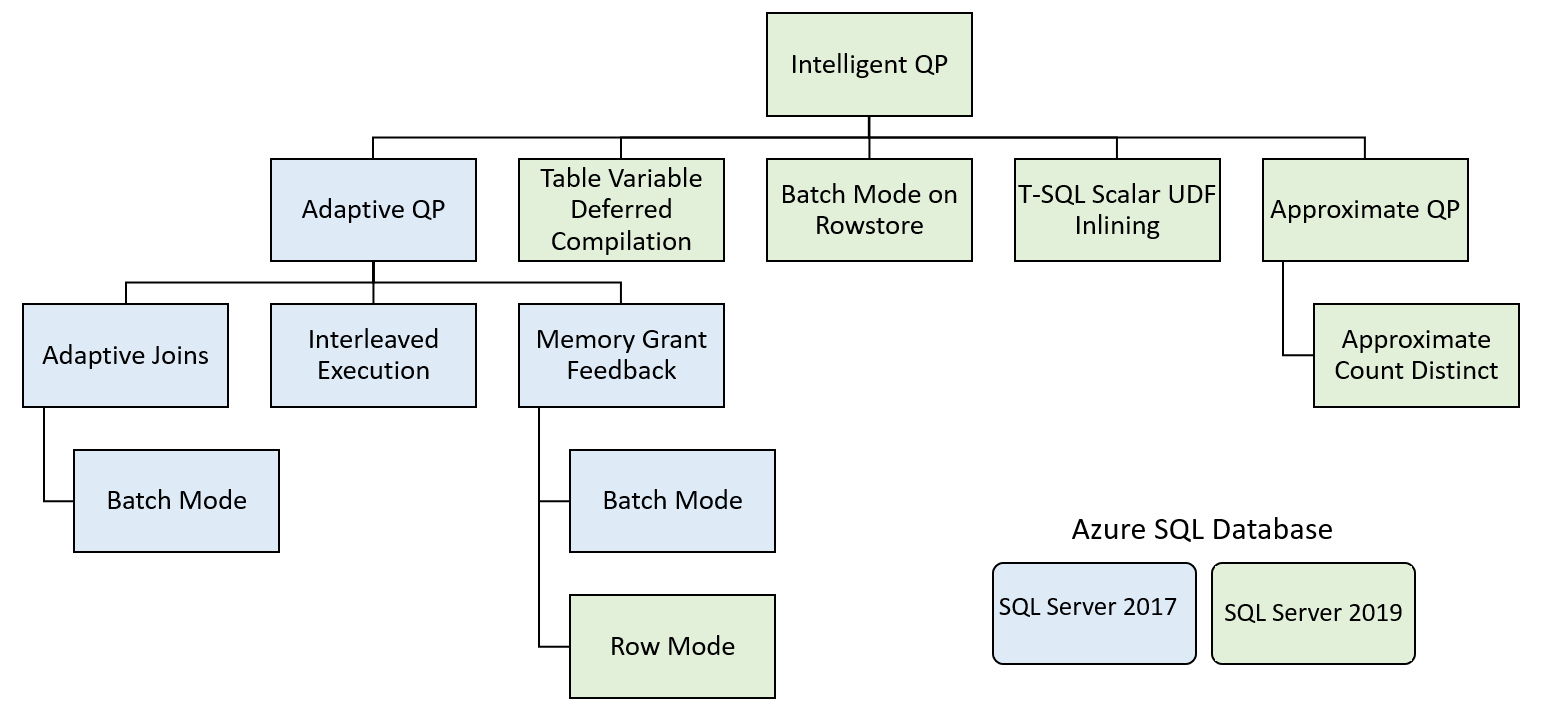
Интеллектуальная обработка запросов включает функции, которые улучшают существующую производительность рабочей нагрузки при минимальных усилиях по реализации.
Чтобы рабочие нагрузки автоматически подходили для интеллектуальной обработки запросов, измените соответствующий уровень совместимости базы данных на 150. Например:
ALTER DATABASE [WideWorldImportersDW] SET COMPATIBILITY_LEVEL = 150;
Адаптивная обработка запросов
Адаптивная обработка запросов включает ряд параметров, которые делают обработку запросов более динамичной на основе контекста выполнения запроса. Эти параметры содержат несколько функций, улучшающих обработку запросов.
Адаптивные соединения — ядро СУБД может отложить выбор метода "Хэш-соединение" или "Соединение вложенными циклами" в зависимости от количества строк, передаваемых в соединение. Сейчас адаптивные соединения работают только в режиме пакетного выполнения.
Выполнение с чередованием — сейчас эта функция поддерживает функции с табличным значением из нескольких инструкций (MSTVF). До SQL Server 2017 функции MSTVF использовали оценку фиксированного числа строк либо для одной строки, либо для ста строк в зависимости от версии SQL Server. Если функция возвращала гораздо больше строк, эта оценка могла приводить к неоптимальным планам запросов. При выполнении с чередованием фактическое число строк создается из функции MSTVF до компиляции остальной части плана.
Обратная связь по временно предоставляемому буферу памяти — SQL Server создает временно предоставляемый буфер памяти в первоначальном плане запроса на основе оценок количества строк из статистики. Существенное неравномерное распределение данных может привести либо к завышению, либо к занижению количества строк, результатом которого может стать предоставление чрезмерного объема памяти, что способствует уменьшению степени параллелизма, или предоставление недостаточного объема памяти, тогда запрос может сбрасывать данные в tempdb. С помощью функции обратной связи по временно предоставляемому буферу памяти SQL Server определяет эти условия и уменьшает или увеличивает объем памяти, предоставляемый запросу, чтобы избежать сброса или чрезмерного выделения.
Эти функции автоматически включены в режиме совместимости 150. Для их активации не требуются никакие другие изменения.
Отложенная компиляция табличных переменных
Как и функции MSTVF, табличные переменные в планах выполнения SQL Server проводили оценку фиксированного числа строк для одной строки. Подобно MSTVFs, эта фиксированная оценка привела к плохой производительности, когда переменная имела большее число строк, чем ожидалось. В SQL Server 2019 табличные переменные анализируются и имеют фактическое число строк. Отложенная компиляция схожа с выполнением с чередованием для MSTVF, за исключением того, что она выполняется при первой компиляции запроса, а не динамически в рамках плана выполнения.
Пакетный режим в хранилище строк
Режим пакетного выполнения позволяет обрабатывать данные пакетами, а не построчно. Запросы, которые несут значительные затраты на ЦП для вычислений и агрегирования, видят наибольшее преимущество от этой модели обработки. За счет разделения пакетной обработки и индексов columnstore преимущества обработки в пакетом режиме становятся доступны большому числу рабочих нагрузок.
Встраивание скалярной функции, определяемой пользователем
В более ранних версиях SQL Server производительность скалярных функций была низкой по нескольким причинам. Скалярные функции выполнялись итеративно, обрабатывая одну строку за раз. У них не было надлежащей оценки затрат в плане выполнения, и они не допускали параллелизм в плане запроса. За счет встраивания определяемой пользователем функции эти функции преобразуются в скалярные вложенные запросы вместо оператора определяемой пользователем функции в плане выполнения. Это преобразование может привести к значительному повышению производительности запросов, использующих вызовы скалярных функций.
Счетчик приблизительного количества уникальных значений
Стандартный шаблон запросов к хранилищу данных предназначен для подсчета количества уникальных заказов или пользователей. Этот шаблон запроса может быть дорогостоящим, если использовать его для большой таблицы. Приблизительное различное подсчет предлагает более быстрый метод подсчета различающихся элементов путем группировки строк. Эта функция обеспечивает частоту ошибок, составляющую 2 %, с доверительным интервалом, равным 97 %.