Использование модели с поддержкой визуального зрения на портале Microsoft Foundry
Подсказка
Дополнительные сведения см. на вкладке "Текст и изображения ".
Для обработки запросов, включающих изображения, необходимо развернуть многомодальную модель искусственного интеллекта. Другими словами, модель, которая поддерживает не только входные данные на основе текста, но и входные данные на основе изображений (и в некоторых случаях звуковые данные). Многомодальные модели, доступные в Microsoft Foundry, включают (среди прочего):
- Microsoft Phi-4-multimodal-instruct
- OpenAI gpt-4.1
- OpenAI gpt-4.1-mini
Подсказка
Дополнительные сведения о доступных моделях в Microsoft Foundry см. в статье об обзоре моделей Microsoft Foundry в документации по Microsoft Foundry.
Тестирование многомодальных моделей с помощью запросов на основе изображений
После развертывания мультимодальной модели его можно протестировать на портале Microsoft Foundry на площадке чата.
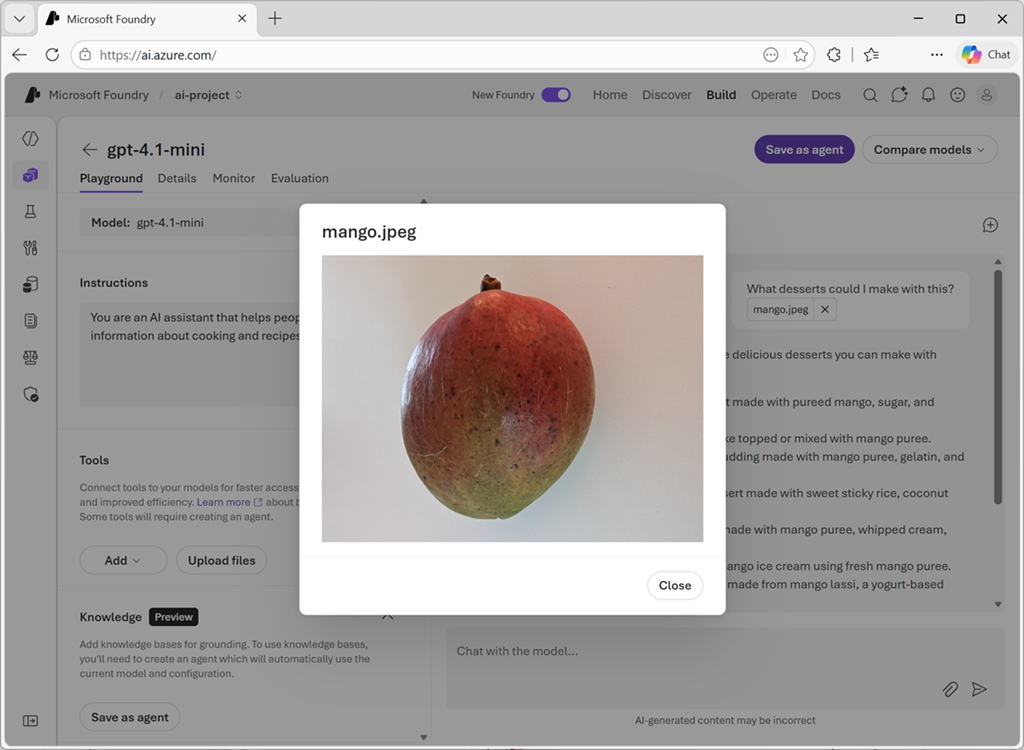
На игровой площадке чата можно отправить изображение из локального файла и добавить текст в сообщение, чтобы вызвать ответ из многомодальной модели.