Объяснение особенностей оценочных и фактических планов запросов
Фактические и предполагаемые планы выполнения могут быть запутанными. Разница заключается в том, что фактический план включает статистику о процессе выполнения, которая не фиксируется в оценочном плане. Операторы, используемые и порядок выполнения, будут совпадать с предполагаемым планом практически во всех случаях. Другое соображение заключается в том, что запись фактического плана выполнения требует выполнения запроса, что может занять много времени или невозможно. Например, инструкция UPDATE может выполняться только один раз. Однако если вам нужно просмотреть результаты запроса и план, необходимо использовать один из вариантов фактического плана.
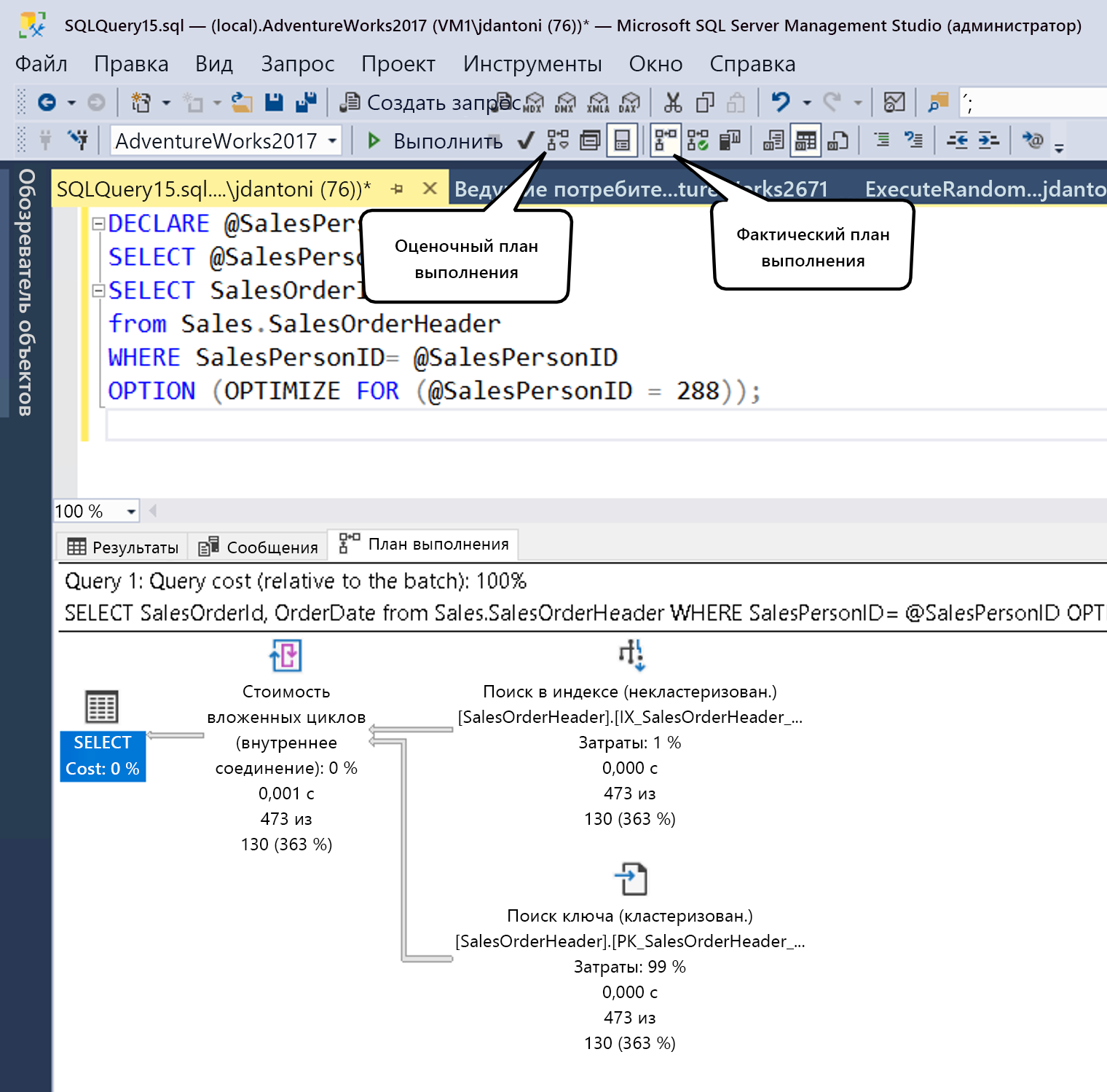
Как показано ниже, можно создать предполагаемый план в SSMS, нажав кнопку, указанную в поле предполагаемого плана запроса (или с помощью клавиши CONTROL+L). Фактический план можно создать, выбрав отображаемый значок (или с помощью клавиши CONTROL+M), а затем выполнив запрос. Две кнопки параметров работают по-разному. Кнопка "Включить предполагаемый план запроса " немедленно отвечает на любой выделенный запрос (или всю рабочую область, если ничего не выделено), в то время как кнопка "Включить фактический план запроса " требует выполнения запроса.
Выполнение запроса и создание оценочного плана выполнения обуславливает дополнительную нагрузку, поэтому просмотр планов выполнения нужно использовать весьма продуманно в условиях производственной среды.
Как правило, при написании запроса можно использовать предполагаемый план выполнения, чтобы понять его характеристики производительности, определить отсутствующие индексы или обнаружить аномалии запросов. Фактический план выполнения лучше всего используется для понимания производительности выполнения запроса и, в основном, пробелов в статистических данных, которые приводят к тому, что оптимизатор запросов делает неоптимальные варианты на основе доступных данных.
Чтение плана запроса
Планы выполнения показывают, какие задачи выполняет ядро СУБД при извлечении данных, необходимых для удовлетворения требований запроса. Давайте рассмотрим план более подробно.
SELECT [stockItemName]
,[UnitPrice] * [QuantityPerOuter] AS CostPerOuterBox
,[QuantityonHand]
FROM [Warehouse].[StockItems] s
JOIN [Warehouse].[StockItemHoldings] sh ON s.StockItemID = sh.StockItemID
ORDER BY CostPerOuterBox;
Этот запрос присоединяет таблицу StockItems к таблице StockItemHoldings , где значения в столбце StockItemID равны. Ядро СУБД должно идентифицировать необходимые строки, прежде чем сможет обработать остальную часть запроса.
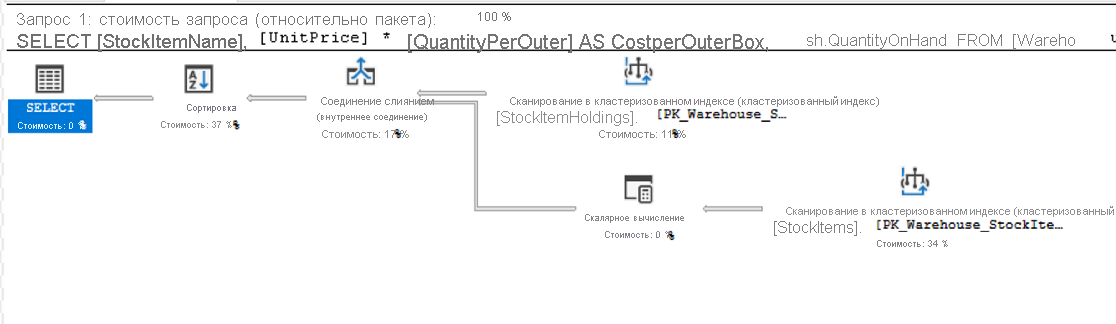
Каждый значок в плане представляет определенную операцию, которая соответствует различным действиям и решениям, которые составляют план выполнения. Ядро СУБД SQL Server имеет более 100 операторов запросов, которые могут быть частью плана выполнения. На каждом значке оператора имеется процент затрат относительно общей стоимости запроса. Даже операция, показывающая стоимость 0%, все равно представляет некоторую стоимость. Фактически, 0% из-за округления, так как затраты плана в графическом виде всегда отображаются в виде целых чисел, а реальный процент из-за этого ниже 0,5%.
Поток выполнения в плане выполнения находится справа налево и сверху вниз, поэтому в этом плане операция сканирования кластеризованного индекса в StockItemHoldings.PK_Warehouse_StockItemHoldings кластеризованном индексе является первой операцией в запросе. Ширина линий, соединяющих операторы, основана на предполагаемом количестве строк данных, передаваемых дальше к следующему оператору. Толстая стрелка обозначает передачу большого объема данных между операторами и может указывать на необходимость более тонкой настройки запроса. Вы также можете навести указатель мыши на оператор и просмотреть дополнительные сведения в подсказке.
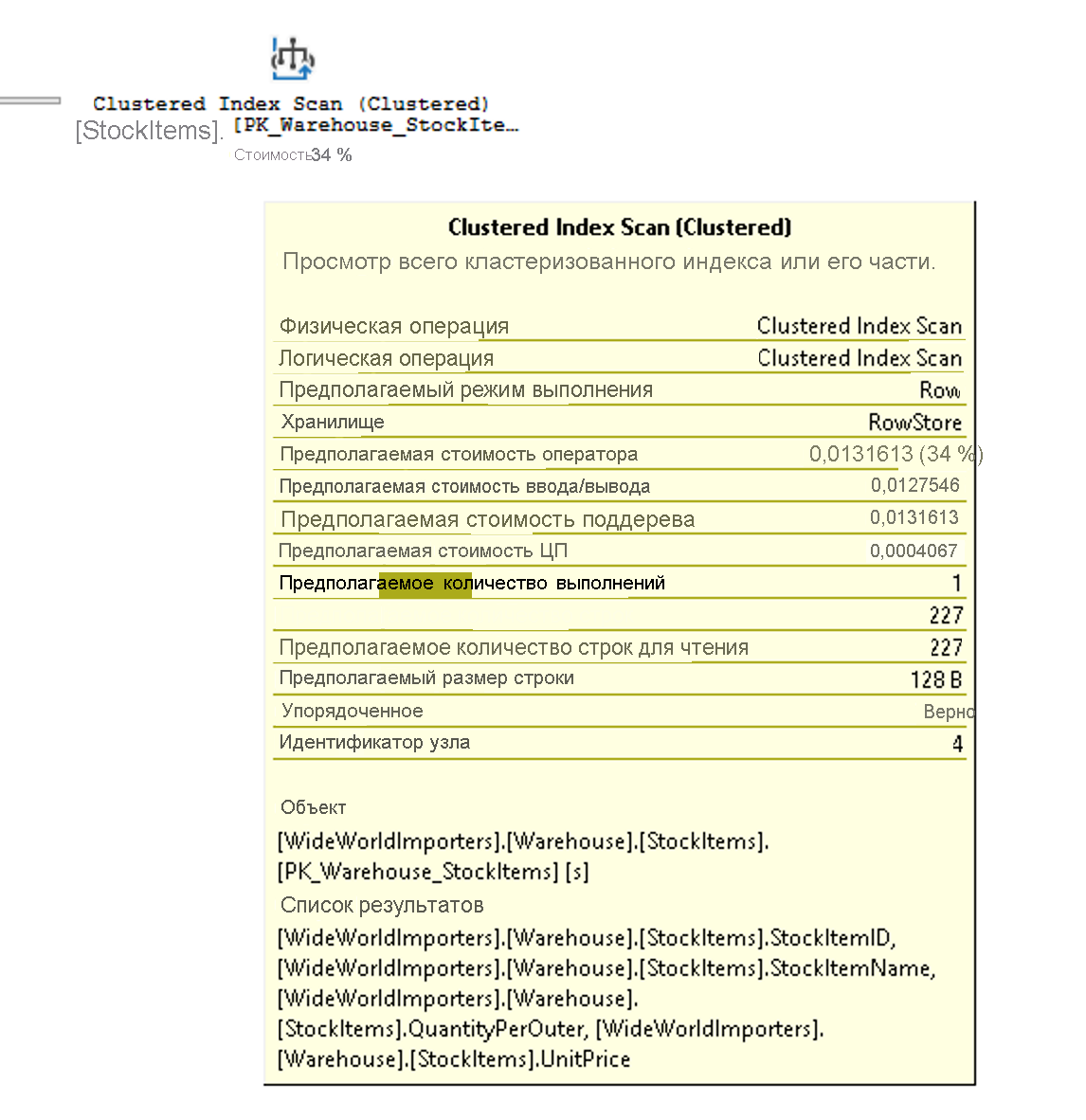
Подсказка выделяет затраты и оценки для предполагаемого плана, а для фактического плана — сравнения с фактическими строками и затратами. Каждый оператор также имеет свойства, предоставляющие дополнительные сведения, чем подсказка. Щелкнув правой кнопкой мыши конкретный оператор, можно выбрать параметр "Свойства" в контекстном меню, чтобы просмотреть полный список свойств. Этот параметр открывает отдельную область свойств в SQL Server Management Studio, которая по умолчанию находится справа. При открытии области свойств, выбор любого оператора заполняет список свойств подробными сведениями об этом операторе. Кроме того, можно открыть панель "Свойства", выбрав "Вид " в главном меню SQL Server Management Studio и выбрав "Свойства".

В области свойств содержатся дополнительные сведения и отображается список выходных данных, подробные сведения о столбцах, передаваемых следующему оператору. Эти столбцы могут указывать на то, что некластеризованный индекс необходим для повышения производительности запросов при анализе с помощью кластеризованного сканирования индекса. Так как операция сканирования кластеризованного индекса считывает всю таблицу, некластеризованный индекс столбца StockItemID в каждой таблице может быть более эффективным в этом сценарии.
Упрощенное профилирование запросов
При создании фактических планов выполнения, независимо от того, используется ли SSMS или инфраструктура мониторинга расширенных событий, это может привести к значительным затратам. Поэтому этот процесс обычно зарезервирован для действий по устранению неполадок с динамическими сайтами. Издержки наблюдения, как очевидно, являются затратами на мониторинг работающего приложения. В некоторых сценариях это может быть всего несколько процентных точек использования ЦП, но в других случаях, таких как запись фактических планов выполнения, это может значительно замедлить производительность отдельных запросов. Устаревшее профилирование в движке SQL Server может создавать до 75% накладных расходов при записи сведений о запросах, в то время как легковесное профилирование имеет максимальную нагрузку около 2%.
В первой версии упрощенное профилирование собирало информацию о количестве строк и об использовании ввода-вывода (число логических и физических операций чтения и записи, выполняемых ядром СУБД для обработки определенного запроса). Кроме того, было введено новое расширенное событие с именем query_thread_profile , позволяющее проверять данные от каждого оператора в плане запроса. Для использования начальной версии упрощенного профилирования необходимо, чтобы флаг трассировки 7412 был включен глобально.
Если упрощённое профилирование не включено глобально, можно использовать подсказку запроса USE HINT с QUERY_PLAN_PROFILE, чтобы включить упрощённое профилирование на уровне запроса. Когда запрос с этим указанием завершит выполнение, создается query_plan_profile расширенное событие, предоставляющее фактический план выполнения. Ниже приведен пример запроса с этим указанием:
SELECT [stockItemName]
,[UnitPrice] * [QuantityPerOuter] AS CostPerOuterBox
,[ QuantityonHand]
FROM [Warehouse].[StockItems] s
JOIN [Warehouse].[StockItems] sh ON s.StockItemID = sh.StockItemID
ORDER BY CostPerOuterBox
OPTION(USE HINT ('QUERY_PLAN_PROFILE'));
Статистика последних планов запроса
Упрощенное профилирование по умолчанию включено как в SQL Server 2019, так и в Базе данных SQL Azure и управляемом экземпляре. Упрощенное профилирование также доступно в виде параметра конфигурации на уровне базы данных, который обозначается как LIGHTWEIGHT_QUERY_PROFILING. С помощью этого параметра уровня базы данных можно отключать эту функцию для любой пользовательской базы данных независимо друг от друга.
Кроме того, есть динамическая функция sys.dm_exec_query_plan_stats управления, которая может показать последний известный фактический план выполнения запроса для данного дескриптора плана. Чтобы просмотреть последний известный фактический план запроса с помощью этой функции, можно включить флаг трассировки 2451 на уровне сервера. Кроме того, эту функцию можно включить с помощью параметра конфигурации уровня базы данных, который называется LAST_QUERY_PLAN_STATS.
Эту функцию можно объединить с другими объектами, чтобы получить последний план выполнения для всех кэшированных запросов:
SELECT *
FROM sys.dm_exec_cached_plans AS cp
CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS st
CROSS APPLY sys.dm_exec_query_plan_stats(plan_handle) AS qps;
GO
Эта функция позволяет быстро получить статистику о процессе выполнения для последнего выполнения любого запроса в системе с минимальными издержками. На следующем рисунке показано, как получить план. Если выбрать XML-код плана выполнения, который будет первым столбцом результатов, он отображает план выполнения, показанный на втором рисунке ниже.
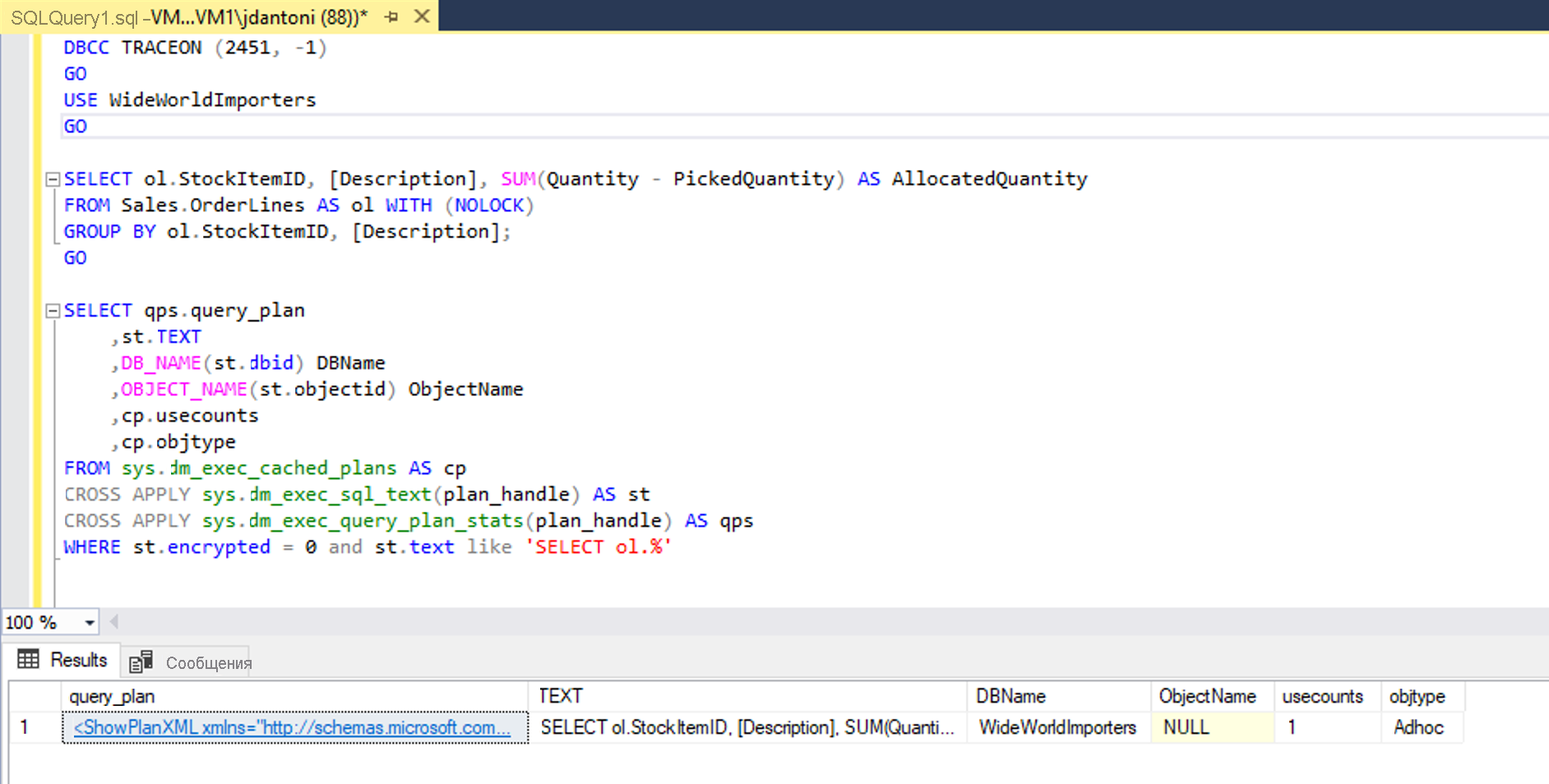
Как видно из свойств сканирования индекса Columnstore на следующем рисунке, план, полученный из кэша, имеет фактическое число строк, полученных в результате выполнения запроса.
