Идентификация проблемных планов запросов
Типичный подход администраторов баз данных для устранения неполадок с производительностью запросов заключается в том, чтобы сначала определить проблемный запрос, обычно тот, который потребляет наибольшее количество системных ресурсов, а затем получить его план выполнения. Существует два основных сценария. Один из сценариев заключается в том, что запрос постоянно показывает плохие результаты. Это может быть связано с различными проблемами, такими как ограничения ресурсов оборудования (хотя это обычно не влияет на один запрос, выполняемый в изоляции), неоптимальную структуру запросов, параметры совместимости базы данных, отсутствующие индексы или плохие варианты плана оптимизатором запросов. Второй сценарий заключается в том, что запрос иногда выполняется хорошо, но плохо в других случаях. Это несоответствие может быть вызвано такими факторами, как отклонение данных в параметризованном запросе, который имеет эффективный план для некоторых выполнений и плохой для других. Другие распространенные факторы включают блокировку, при которой запрос ожидает завершения другого запроса, чтобы получить доступ к таблице, или конфликт оборудования.
Рассмотрим каждый из этих сценариев более подробно.
Аппаратные ограничения
Ограничения оборудования обычно не манифестируются во время выполнения одного запроса, но становятся очевидными при рабочей нагрузке, когда потоки ЦП и память ограничены. Проблемы с процессором можно обнаружить, наблюдая счетчик производительности "% время процессора", который измеряет использование процессора сервера. В SQL Server типы ожидания SOS_SCHEDULER_YIELD и CXPACKET могут указывать на давление ЦП. Низкая производительность системы хранения может замедлить даже оптимизированные выполнение одного запроса. Производительность хранилища лучше всего отслеживается на уровне операционной системы с помощью счетчиков мониторов Disk Seconds/Read производительности и Disk Seconds/Write, которые измеряют время завершения операций ввода-вывода. SQL Server регистрирует низкую производительность хранилища, если операций ввода-вывода занимает более 15 секунд. Высокие ожидания PAGEIOLATCH_SH в SQL Server могут указывать на проблемы с производительностью хранилища. Производительность оборудования обычно оценивается в начале процесса устранения неполадок из-за простоты оценки.
Большинство проблем с производительностью базы данных связаны с неоптимальными шаблонами запросов, что может оказать чрезмерное давление на оборудование. Например, отсутствующие индексы могут привести к нехватке ЦП, хранилища и памяти путем получения большего количества данных, чем это необходимо. Перед решением проблем с оборудованием рекомендуется устранять и настраивать неоптимальные запросы. Далее мы рассмотрим настройку запросов.
Неоптимальные конструкции запросов
Реляционные базы данных лучше всего выполняются при выполнении операций на основе набора, которые управляют данными (INSERT, UPDATEDELETE, иSELECT) в наборах, создавая одно значение или результирующий набор. Альтернативой является обработка на основе строк с помощью курсоров или циклов, которая увеличивает затраты линейно с числом влияемых строк — что приводит к проблемному масштабированию по мере роста объемов данных.
Обнаружение неоптимального использования операций на основе строк с курсорами или циклами WHILE важно, но существуют и другие антишаблоны SQL Server для распознавания. Функции с табличным значением (TVF), особенно многооператорные TVF, вызывали проблемные шаблоны планов выполнения до SQL Server 2017. Разработчики часто используют многооператорные табличные функции для выполнения нескольких запросов в одной функции и агрегирования результатов в одну таблицу. Однако использование TVFs может привести к падению производительности.
SQL Server имеет два типа многострочных табличных функций (TVF): встроенные и многооператорные. Встроенные ТВФ обрабатываются как представления, а многооператорные ТВФ обрабатываются как таблицы во время обработки запросов. Так как TVFs являются динамическими и не имеют статистики, SQL Server использует фиксированное число строк для оценки затрат на план запросов. Это может быть хорошо для небольшого количества строк, но неэффективно для тысяч или миллионов строк.
Другим антитипом является использование скалярных функций, которые имеют аналогичные проблемы оценки и выполнения. Корпорация Майкрософт значительно улучшила производительность с помощью интеллектуальной обработки запросов в соответствии с уровнями совместимости 140 и 150.
SARGability
Термин SARGable в реляционных базах данных относится к предикату (условию), отформатированному таким образом, чтобы использовать индекс для ускорения выполнения запроса. Предикаты в правильном формате называются "Аргументы поиска" или SARG. В SQL Server использование SARG означает, что оптимизатор оценивает использование некластеризованного индекса в столбце, на который ссылается SARG для операции SEEK , вместо сканирования всего индекса или таблицы для получения значения.
Наличие SARG не гарантирует использование индекса для SEEK. Алгоритмы затрат оптимизатора по-прежнему могут определить, что индекс слишком дорогой, особенно если SARG относится к большому проценту строк в таблице. Отсутствие SARG означает, что оптимизатор не будет оценивать ПОИСК по некластеризованному индексу.
Примеры не SARGable выражений включают предложения с подстановочным знаком в начале строки, например LIKE. Иные, не являющиеся SARGable предикаты возникают при использовании функций в столбце, например WHERE CONVERT(CHAR(10), CreateDate,121) = '2020-03-22'. Эти запросы обычно определяются путем изучения планов выполнения для проверки индекса или таблицы, где поиски должны происходить в противном случае.
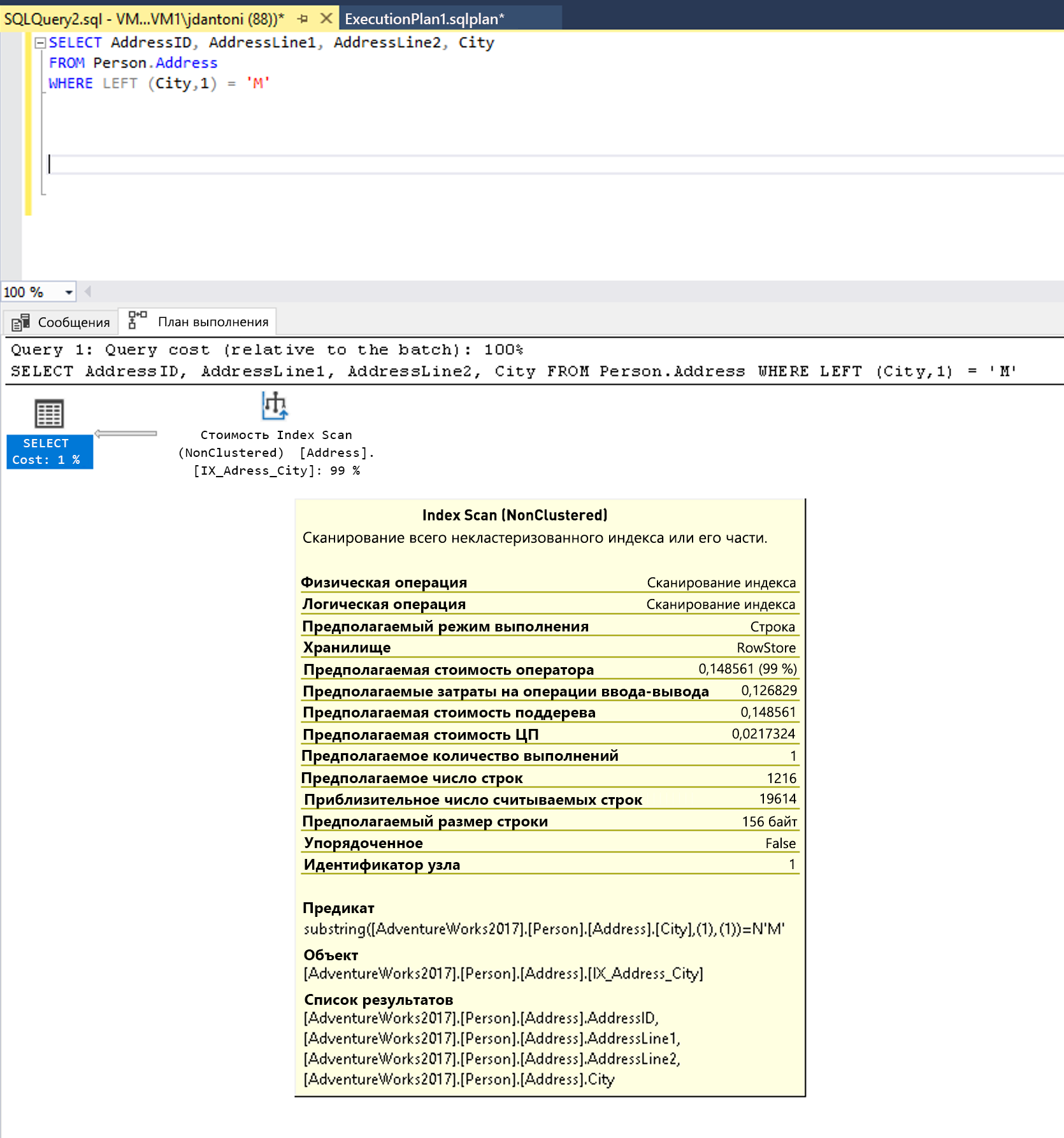
Существует индекс в столбце City , который используется в WHERE предложении запроса, и при его использовании в этом плане выполнения выше можно увидеть, что индекс сканируется, что означает, что весь индекс считывается. Функция LEFT в предикате делает это выражение не оптимизируемым. Оптимизатор не будет выполнять оценку с использованием поиска по индексу в столбце Город.
Этот запрос можно записать для использования предиката, который является SARGable. Затем оптимизатор будет оценивать поиск по индексу в столбце "Город". Оператор поиска индекса в данном случае считывает меньший набор строк.
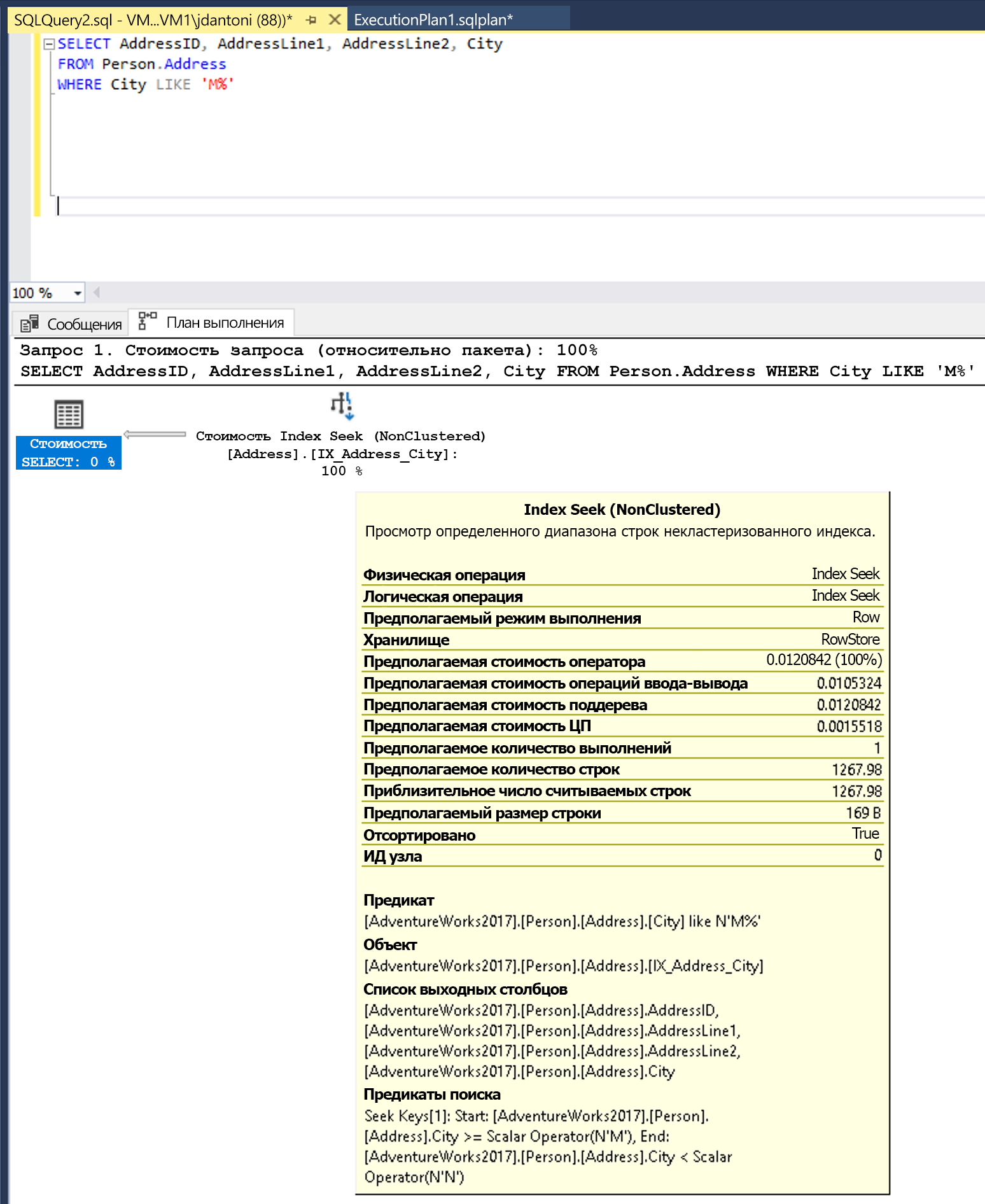
Изменение функции LEFT на LIKE приводит к поиску по индексу.
Замечание
Ключевое LIKE слово в этом примере не имеет подстановочного знака слева, поэтому ищет города, начинающиеся с M. Если бы оно было "двухсторонним" или начиналось с подстановочного знака ("%M%" или "%M"), оно было бы не-SARGируемым. По оценкам, операция поиска возвращает 1267 строк или приблизительно 15% оценки запроса с предикатом, не допускающего САРГ.
Некоторые другие антишаблоны разработки баз данных рассматривают базу данных как службу, а не хранилище данных. Использование базы данных для преобразования данных в JSON, управление строками или выполнение сложных вычислений может привести к чрезмерному использованию ЦП и увеличению задержки. Запросы, которые пытаются получить все записи, а затем выполнять вычисления в базе данных могут привести к чрезмерному использованию операций ввода-вывода и ЦП. В идеале следует использовать базу данных для операций доступа к данным и оптимизированных конструкций базы данных, таких как агрегирование.
Отсутствующие индексы
Наиболее распространенные проблемы с производительностью администраторов баз данных возникают из-за отсутствия полезных индексов, что приводит к чтению больше страниц, чем необходимо для возврата результатов запроса. Хотя индексы используют ресурсы (влияющие на производительность записи и потребление места), их производительность часто перевешивает дополнительные затраты на ресурсы. Планы выполнения с этими проблемами можно определить с помощью оператора запроса Clustered Index Scan или сочетания некластеризованного поиска индекса и поиска ключей, указывая отсутствующие столбцы в существующем индексе.
Движок базы данных помогает выявлять недостающие индексы в плане выполнения. Имена и сведения о рекомендуемых индексах доступны в динамическом представлении sys.dm_db_missing_index_detailsуправления. Другие динамические административные представления, такие как sys.dm_db_index_usage_stats и sys.dm_db_index_operational_stats, выделяют использование существующих индексов.
Удаление неиспользуемого индекса может быть разумным. Отсутствующие представления управления индексами и предупреждения по плану должны служить отправными точками для оптимизации запросов. Важно понимать ключевые запросы и создавать индексы для их поддержки. Не рекомендуется создавать все отсутствующие индексы, не оценивая их в контексте.
Отсутствующие и устаревшие статистические данные
Важно понимать важность статистики столбцов и индексов для оптимизатора запросов. Кроме того, важно распознавать условия, которые могут привести к устаревшей статистике и тому, как эта проблема может проявляться в SQL Server. Предложения Azure SQL по умолчанию имеют включенную функцию автоматического обновления статистики. До SQL Server 2016 по умолчанию статистика автосовмещения не обновлялась до тех пор, пока число изменений в столбцах индекса не достигало примерно 20% от числа строк в таблице. Это может привести к значительным изменениям данных, которые изменяют производительность запросов, не обновляя статистику, что приводит к неоптимальным планам на основе устаревшей статистики.
Перед SQL Server 2016 флаг трассировки 2371 можно было бы использовать для изменения требуемого количества изменений в динамическом значении, поэтому по мере роста таблицы процент изменений строк, необходимых для активации обновления статистики, снизился. Новые версии SQL Server, Базы данных SQL Azure и Управляемого экземпляра SQL Azure по умолчанию поддерживают это поведение. Функция динамического управления sys.dm_db_stats_properties отображает статистику последнего времени обновления и количество изменений с момента последнего обновления, что позволяет быстро определить статистику, которая может потребовать обновления вручную.
Плохой выбор оптимизатора
Хотя оптимизатор запросов выполняет хорошую работу по оптимизации большинства запросов, существуют некоторые пограничные случаи, когда оптимизатор на основе затрат может принимать важные решения, которые не полностью понятны. Существует множество способов решения этой проблемы, включая использование подсказок запроса, флагов трассировки, принудительного выполнения плана выполнения и других настроек, чтобы достичь стабильного и оптимального плана запроса. Корпорация Майкрософт имеет службу поддержки, которая может помочь устранить эти сценарии.
В приведенном ниже примере из базы данных AdventureWorks2017 используется подсказка для запросов, чтобы указать оптимизатору базы данных всегда использовать название города Сиэтл. Это указание не гарантирует лучший план выполнения для всех значений города, но оно предсказуемо. Значение ‘Сиэтл’ для @city_name будет использоваться только во время оптимизации. Во время выполнения используется фактическое предоставленное значение (‘Ascheim’) .
DECLARE @city_name nvarchar(30) = 'Ascheim',
@postal_code nvarchar(15) = 86171;
SELECT *
FROM Person.Address
WHERE City = @city_name
AND PostalCode = @postal_code
OPTION (OPTIMIZE FOR (@city_name = 'Seattle');
Как показано в примере, в запросе используется подсказка (предложение OPTION), чтобы уведомить оптимизатор о необходимости использования определенного значения переменной для создания плана выполнения.
Сниффинг параметров
SQL Server кэширует планы выполнения запросов для дальнейшего использования. Так как процесс извлечения плана выполнения основан на хэш-значении запроса, текст запроса должен быть идентичным для каждого выполнения запроса для использования кэшированного плана. Для поддержки нескольких значений в одном запросе многие разработчики используют параметры, передаваемые через хранимые процедуры, как показано в следующем примере:
CREATE PROC GetAccountID (@Param INT)
AS
<other statements in procedure>
SELECT accountid FROM CustomerSales WHERE sales > @Param;
<other statements in procedure>
RETURN;
-- Call the procedure:
EXEC GetAccountID 42;
Запросы также могут быть явно параметризованы с помощью процедуры sp_executesql. Однако параметризация отдельных запросов явно осуществляется через приложение с определенной формой (в зависимости от API) PREPARE и EXECUTE. Когда ядро СУБД выполняет этот запрос в первый раз, он оптимизирует запрос на основе начального значения параметра, в данном случае 42. Это поведение, называемое сниффинг параметров, позволяет сократить общую рабочую нагрузку компиляции запросов на сервере. Однако если есть отклонение данных, производительность запросов может значительно отличаться.
Например, таблица с 10 миллионами записей и 99% этих записей имеют идентификатор 1, а остальные 1% являются уникальными числами, производительность основана на том, какой идентификатор изначально использовался для оптимизации запроса. Эта сильно изменяющаяся производительность свидетельствует об отклонении данных и не является неотъемлемой проблемой прослушивания параметров. Это довольно распространенная проблема с производительностью, о которую следует знать. Вы должны понять варианты устранения проблемы. Есть несколько способов решения этой проблемы, но каждый из них сопровождается компромиссами.
- Используйте
RECOMPILEподсказку в вашем запросе илиWITH RECOMPILEопцию выполнения в ваших хранимых процедурах. Это указание приводит к повторной компиляции запроса или процедуры при каждом выполнении, что увеличивает загрузку ЦП на сервере, но всегда будет использовать текущее значение параметра. - Вы можете использовать подсказку
OPTIMIZE FOR UNKNOWNзапроса. Это указание заставляет оптимизатор не считывать параметры, а сравнивать значение с гистограммой данных столбца. Этот параметр не приведет к наилучшему плану, но позволит обеспечить постоянный план выполнения. - Перепишите процедуру или запросы, добавив логику для значений параметров, чтобы использовать RECOMPILE только для известных проблемных параметров. В приведенном ниже примере, если параметр SalesPersonID имеет значение NULL, запрос выполняется с
OPTION (RECOMPILE).
CREATE OR ALTER PROCEDURE GetSalesInfo (@SalesPersonID INT = NULL)
AS
DECLARE @Recompile BIT = 0
, @SQLString NVARCHAR(500)
SELECT @SQLString = N'SELECT SalesOrderId, OrderDate FROM Sales.SalesOrderHeader WHERE SalesPersonID = @SalesPersonID'
IF @SalesPersonID IS NULL
BEGIN
SET @Recompile = 1
END
IF @Recompile = 1
BEGIN
SET @SQLString = @SQLString + N' OPTION(RECOMPILE)'
END
EXEC sp_executesql @SQLString
,N'@SalesPersonID INT'
,@SalesPersonID = @SalesPersonID
GO
Этот пример является хорошим решением, но он требует довольно больших усилий по разработке и твердого понимания распределения данных. Необходимо проводить обслуживание по мере изменения данных.