Что такое языковые модели?
Созданные приложения ИИ используются языковыми моделями, которые являются специализированным типом модели машинного обучения, которую можно использовать для выполнения задач обработки естественного языка (NLP), в том числе:
- Определение тональности или иная классификация текста на естественном языке.
- Текст сводки.
- Сравнение нескольких источников текста для выявления семантического сходства.
- Генерирование нового естественного языка.
Хотя математические принципы, лежащие в основе этих языковых моделей, могут быть сложными, базовое понимание архитектуры, используемой для их реализации, может помочь вам получить концептуальное представление о том, как они работают.
Модели преобразователя
Модели машинного обучения для обработки естественного языка развивались на протяжении многих лет. Современные большие языковые модели основаны на архитектуре преобразователя, которая использует и расширяет некоторые методы, доказавшие свою успешность в моделировании словарей для поддержки задач NLP — и, в частности, в генерировании языка. Модели преобразователей обучаются на больших объемах текста, что позволяет им представлять семантические отношения между словами и использовать эти отношения для определения вероятных последовательностей текста, которые будут иметь смысл. Модели преобразователей с достаточно большим словарным запасом способны генерировать языковые ответы, которые трудно отличить от человеческих.
Архитектура модели преобразователя состоит из двух компонентов или блоков:
- Блок кодировщика, который создает семантические представления словаря обучения.
- Блок декодера, который генерирует новые языковые последовательности.
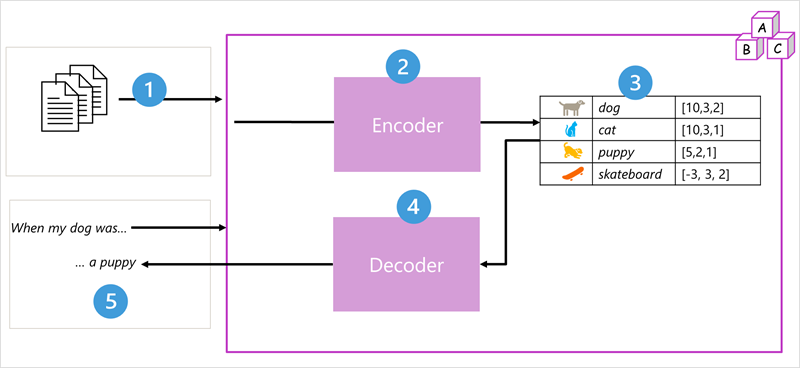
- Модель обучена большим объемом текста естественного языка, часто из Интернета или других общедоступных источников текста.
- Последовательности текста разбиваются на маркеры (например, отдельные слова) и блок кодировщика обрабатывает эти последовательности маркеров с помощью метода, вызываемого вниманием, чтобы определить связи между токенами (например, которые влияют на наличие других маркеров в последовательности, разные маркеры, которые обычно используются в одном контексте и т. д.).
- Выходные данные кодировщика — это коллекция векторов (многозначных числовых массивов), в которой каждый элемент вектора представляет семантический атрибут маркеров. Эти векторы называются внедренными.
- Блок декодировщика работает на новой последовательности текстовых маркеров и использует внедренные кодировщиком элементы, созданные кодировщиком, для создания соответствующих выходных данных естественного языка.
- Например, учитывая входную последовательность, например "Когда моя собака была", модель может использовать метод внимания для анализа входных маркеров и семантических атрибутов, закодированных в внедрениях, чтобы предсказать соответствующее завершение предложения, например "щенок".
На практике конкретные реализации архитектуры различаются — например, модель двунаправленного представления кодировщика из преобразователей (BERT), разработанная Google для поддержки своей поисковой системы, использует только блок кодировщика, а модель генеративного предварительно обученного преобразователя (GPT), разработанная OpenAI, использует только блок декодера.
Хотя полное объяснение всех аспектов моделей преобразователей выходит за рамки этого модуля, объяснение некоторых ключевых элементов преобразователя может помочь вам понять, как они поддерживают генеративный ИИ.
Выделение лексем
Первым шагом в обучении модели преобразователя является разложение обучающего текста в маркеры - другими словами, определение каждого уникального текстового значения. Для простоты вы можете думать о каждом отдельном слове в обучаемом тексте как маркер (хотя на самом деле маркеры можно создать для частичных слов или сочетаний слов и препинания).
Например, рассмотрим следующее предложение:
I heard a dog bark loudly at a cat
Чтобы маркеризировать этот текст, можно определить каждое дискретное слово и назначить им идентификаторы маркеров. Например:
- I (1)
- heard (2)
- a (3)
- dog (4)
- bark (5)
- loudly (6)
- at (7)
- *("a" is already tokenized as 3)*
- cat (8)
Теперь предложение может быть представлено маркерами: {1 2 3 4 5 6 7 3 8} Аналогичным образом, предложение "Я слышал кошка" может быть представлено как {1 2 3 8}.
По мере обучения модели каждая новая лексема в тексте обучения добавляется в словарь с соответствующими идентификаторами лексем:
- мюау (9)
- скейтборд (10)
- и так далее...
При достаточно большом наборе текста для обучения можно составить словарь из многих тысяч лексем.
Внедрение
Хотя может быть удобно представлять лексемы как простые идентификаторы — по сути, создавая индекс для всех слов в словаре, они ничего не говорят нам о значении слов или связях между ними. Чтобы создать словарь, который инкапсулирует семантические отношения между лексемами, мы определяем для них контекстуальные векторы, известные как векторные представления. Векторы — это многозначные числовые представления информации, например [10, 3, 1], в которых каждый числовой элемент представляет собой определенный атрибут информации. Для языковых лексем каждый элемент вектора лексемы представляет собой некоторый семантический атрибут лексемы. Конкретные категории для элементов векторов в языковой модели определяются в процессе обучения на основе того, насколько часто слова используются вместе или в схожих контекстах.
Векторы представляют собой линии в многомерном пространстве, описывающие направление и расстояние по нескольким осям (если хотите впечатлить своих друзей-математиков, можете назвать их амплитудой и величиной). Для удобства можно рассматривать элементы векторного представления для лексемы в виде шагов по некому пути в многомерном пространстве. Например, вектор с тремя элементами представляет собой путь в трехмерном пространстве, в котором значения элементов указывают на единицы, пройденные вперед/назад, влево/вправо и вверх/вниз. В целом вектор описывает направление и расстояние пути от источника до конца.
Элементы маркеров в пространстве внедрения каждый представляет некоторый семантический атрибут маркера, поэтому семантические аналогичные маркеры должны привести к векторам, имеющим аналогичную ориентацию, другими словами, они указывают в том же направлении. Метод, называемый косинусным сходством , используется для определения того, имеют ли два вектора аналогичные направления (независимо от расстояния) и поэтому представляют семантические связанные слова. В качестве простого примера предположим, что внедрение для наших маркеров состоит из векторов с тремя элементами, например:
- 4 ("собака"): [10,3,2]
- 8 ("cat"): [10,3,1]
- 9 ("щенок"): [5,2,1]
- 10 ("скейтборд"): [-3,3,2]
Эти векторы можно построить в трехмерном пространстве, как показано ниже.
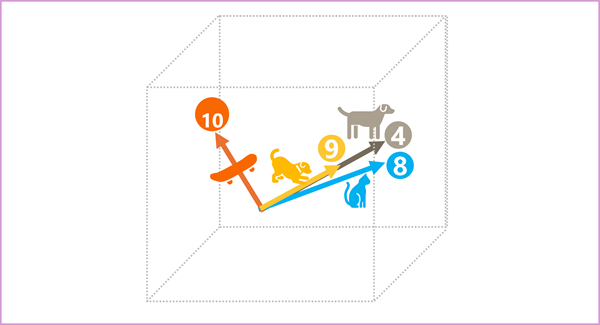
Векторы внедрения для "собака" и "щенок" описывают путь вдоль почти идентичного направления, который также довольно похож на направление для "кота". Однако вектор представления для лексемы “skateboard” описывает путь в совершенно другом направлении.
Примечание.
В предыдущем примере показана простая модель, в которой каждое векторное представление имеет только три измерения. Реальные языковые модели имеют гораздо больше измерений.
Существует множество способов вычисления соответствующих векторных представлений для заданного набора лексем, включая алгоритмы моделирования языка, такие как Word2Vec или блок кодировщика в модели преобразователя.
Внимание
Блоки кодировщика и декодировщика в модели преобразователя включают несколько слоев, которые образуют нейронную сеть для модели. Нам не нужно ознакомиться со сведениями обо всех этих слоях, но полезно рассмотреть один из типов слоев, используемых в обоих блоках: слои внимания . Внимание — это техника, используемая для изучения последовательности текстовых лексем и попытки количественно оценить силу связей между ними. В частности, самостоятельное внимание включает в себя рассмотрение того, как другие маркеры вокруг одного конкретного маркера влияют на значение этого маркера.
В блоке кодировщика каждый маркер тщательно проверяется в контексте, и для внедрения вектора определяется соответствующая кодировка. Значения вектора основаны на связях между лексемой и другими лексемами, с которыми она часто встречается. Этот контекстуализированный подход означает, что одно и то же слово может иметь несколько внедрения в зависимости от контекста, в котором он используется - например, "кора дерева" означает что-то другое для "Я слышал собаку лай".
В блоке декодера слои внимания используются для прогнозирования следующих лексем в последовательности. Для каждой сгенерированной лексемы модель имеет слой внимания, который учитывает последовательность лексем до этого момента. Модель учитывает, какие из лексем являются наиболее влиятельными при рассмотрении вопроса о том, какой должна быть следующая лексема. Например, учитывая последовательность "Я слышал собаку", уровень внимания может назначить больший вес маркерам "услышан" и "собака" при рассмотрении следующего слова в последовательности:
Я слышал собаку [лай]
Помните, что слой внимания работает с числовыми векторными представлениями лексем, а не с самим текстом. В декодере процесс начинается с получения последовательности векторных представлений лексем, представляющих текст, который необходимо завершить. Первое, что происходит, заключается в том, что другой уровень позиционной кодировки добавляет значение к каждому внедрению, чтобы указать его положение в последовательности:
- [1,5,6,2] (I)
- [2,9,3,1] (слышал)
- [3,1,1,2] (a)
- [4,10,3,2] (собака)
Во время обучения задача состоит в том, чтобы прогнозировать вектор для последней лексемы в последовательности на основе предшествующих. Слой внимания присваивает числовой вес каждой лексеме в последовательности на данный момент. Он использует это значение для вычисления взвешенных векторов, что дает оценку внимания, которая может быть использована для вычисления возможного вектора для следующей лексемы. На практике техника, называемая многопутевое внимание, использует различные элементы векторных представлений для расчета нескольких показателей внимания. Затем нейронная сеть оценивает все возможные лексемы, чтобы определить наиболее вероятную, с которой можно продолжить последовательность. Процесс продолжается итеративно для каждой лексемы в последовательности, при этом выходная последовательность используется регрессивно как входная для следующей итерации — по сути, мы строим вывод по одной лексеме за раз.
Следующая анимация показывает упрощенное представление того, как это работает, — в действительности вычисления, выполняемые слоем внимания, более сложны, но принципы можно упростить, как показано далее:

- Последовательность векторных представлений лексем поступает в слой внимания. Каждая лексема представлена в виде вектора числовых значений.
- Задача декодера — спрогнозировать следующую лексему в последовательности, которая также будет вектором, соответствующим векторному представлению в словаре модели.
- Слой внимания оценивает последовательность до этого момента и присваивает вес каждой лексеме, чтобы отразить их относительное влияние на следующую лексему.
- Значения веса могут быть использованы для вычисления нового вектора для следующей лексемы с оценкой внимания. Многопутевое внимание использует различные элементы в векторных представлениях для вычисления нескольких альтернативных лексем.
- Полностью подключенная нейронная сеть использует показатели вычисленных векторов для прогнозирования наиболее вероятной лексемы из всего словаря.
- Прогнозируемый результат добавляется к последовательности, которая используется в качестве входных данных для следующей итерации.
Во время обучения фактическая последовательность лексем известна — мы просто маскируем те, которые идут позже в последовательности, чем рассматриваемая в данный момент позиция лексемы. Как и в любой другой нейронной сети, спрогнозированное значение вектора лексемы сравнивается с фактическим значением следующего вектора в последовательности, и вычисляется потеря. Затем значения веса постепенно корректируются, чтобы уменьшить потери и улучшить модель. При использовании для вывода (прогнозирование новой последовательности лексем) обученный слой внимания применяет значения веса, которые прогнозируют наиболее вероятную лексему из словаря модели, семантически соответствующую данной последовательности.
Все это означает, что модель преобразователя, такая как GPT-4 (модель, лежащая в основе ChatGPT и Bing), предназначена для приема текстового ввода (называемого подсказкой) и генерирования синтаксически правильного вывода (называемого заполнением). По сути, «магия» модели заключается в том, что она способна составить связное предложение. Эта способность не подразумевает никаких «знаний» или «интеллекта» со стороны модели; просто большой словарь и способность генерировать осмысленные последовательности слов. Однако, что делает такую большую языковую модель, как GPT-4, настолько мощной, так это огромный объем данных, на которых она была обучена (публичные и лицензионные данные из Интернета), и сложность сети. Это позволяет модели генерировать результаты, основанные на связях между словами в словаре, на котором она была обучена; зачастую заполнение неотличимо от ответа человека на ту же подсказку.