Моделирование небольших сущностей поиска
Наша модель данных включает две небольшие сущности ссылочных данных, ProductCategory и ProductTag. Эти сущности используются для ссылочных значений и связаны с другими сущностями через 1:Many relationship.
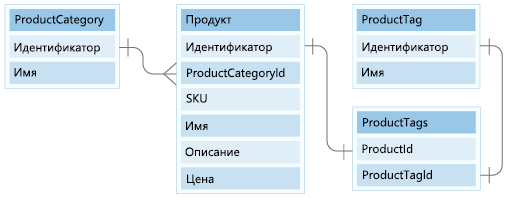
В этом уроке мы будем моделировать сущности ProductCategory и ProductTag в нашей модели документов.
Категории моделей продуктов
Для категорий мы будем моделировать данные с помощью столбцов ID и Name в качестве свойств и поместим их в новый контейнер с именем .
Далее нужно выбрать ключ секции. Давайте рассмотрим операции, которые необходимо выполнить с этими данными.
Необходимо создать новую категорию продуктов, затем изменить категорию продуктов и, наконец, перечислить все категории продуктов. Создание и изменение категорий продуктов не являются часто выполняемыми операциями. Наше приложение электронной коммерции будет часто выводить список всех категорий продуктов, когда клиенты посещают веб-сайт. Поэтому последняя операция будет наиболее часто исполняемой.
Запрос для этой последней операции будет выглядеть следующим образом: SELECT * FROM c.
Если выбран идентификатор в качестве ключа секции, этот запрос теперь будет охватывать разные секции, даже если мы пытаемся оптимизировать эти операции с интенсивной нагрузкой чтения, чтобы использовать только одну секцию. Мы также понимаем, что данные для категории продукта никогда не разрастутся до 20 ГБ, так что эта информация поможет нам в моделировании данных таким образом, чтобы при перечислении всех категорий продуктов было достаточно запроса для одной секции.

Чтобы объединить этот небольшой объем данных обратно в одну секцию, мы можем добавить в схему свойство дискриминатора сущностей и использовать его в качестве ключа секции для этого контейнера. Присвоив этому свойству постоянное значение для всех документов этого типа в контейнере, мы гарантированно получим запрос одной секции. В этом случае мы вызовем свойство type и присвоим ему постоянное значение category. Теперь наш запрос выглядит следующим образом: SELECT * FROM c WHERE c.type = ”category”.

Теги продукта модели
Далее следует сущность ProductTag. Эта сущность в функции почти идентична сущности ProductCategory, о которой мы говорили в предыдущем разделе. Давайте рассмотрим тот же подход и смоделируем документ таким образом, чтобы он содержал свойства идентификатора и имени и создавал свойство дискриминатора сущностей под названием type, в данном случае с постоянным значением tag. Давайте создадим новый контейнер с именем ProductTag и создадим type новый ключ секции.

Некоторые люди находят эту методику моделирования небольших таблиц подстановки странной. Но моделирование данных таким образом дает нам возможность выполнить дальнейшую оптимизацию, которой мы займемся в следующем модуле.