Сверточная нейронная сеть
- 15 мин
В предыдущем уроке мы узнали, как определить универсальную многоуровневую нейронную сеть. В этом уроке мы узнаем о сверточных нейронных сетях (CNN), которые предназначены для компьютерного зрения.
Компьютерное зрение отличается от универсальной классификации, так как при попытке найти определенный объект на рисунке, мы сканируем изображение, ищем определенные шаблоны и их сочетания. Например, при поиске кота мы сначала можем искать горизонтальные линии, которые могут формировать усы, а затем определенное сочетание усов может подсказать нам, что это на самом деле изображение кошки. Важны как положение, так и наличие определенных шаблонов. Для извлечения шаблонов мы будем использовать понятие сверточных фильтров.
Но сначала давайте загрузим все зависимости и определим вспомогательные функции, которые мы будем использовать:
import keras
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
def plot_convolution(data, t, title=''):
t = tf.constant(t, dtype=tf.float32)
t = tf.reshape(t, [*t.shape, 1, 1])
fig, ax = plt.subplots(len(data), 2)
fig.suptitle(title, fontsize=16)
for i in range(len(data)):
d = tf.reshape(tf.constant(data[i], dtype=tf.float32), [1, *data[i].shape, 1])
ax[i][0].imshow(data[i])
ax[i][1].imshow(tf.nn.conv2d(d, t, [1, 1, 1, 1], 'SAME')[0, ..., 0])
def plot_results(hist):
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(hist.history['accuracy'], label='Training acc')
plt.plot(hist.history['val_accuracy'], label='Validation acc')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(hist.history['loss'], label='Training loss')
plt.plot(hist.history['val_loss'], label='Validation loss')
plt.legend()
def display_dataset(dataset, labels=None, n=10, classes=None):
fig, ax = plt.subplots(1, n)
for i in range(n):
ax[i].imshow(dataset[i])
ax[i].axis('off')
if labels is not None:
# Handle both scalar labels (e.g. MNIST) and array labels (e.g. CIFAR-10)
lbl = int(labels[i][0]) if np.ndim(labels[i]) > 0 else int(labels[i])
ax[i].set_title(classes[lbl] if classes is not None else str(lbl))
Теперь давайте загрузим набор данных MNIST:
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = x_train.astype(np.float32) / 255.0
x_test = x_test.astype(np.float32) / 255.0
Сверточная фильтрация
Сверточные фильтры — это небольшие окна, которые проходят по каждому пикселю изображения и вычисляют взвешенное среднее соседних пикселей. Они определяются матрицами коэффициентов веса. Давайте рассмотрим примеры применения двух разных сверточных фильтров к цифрам из набора данных MNIST.
plot_convolution(x_train[:5], [[-1., 0., 1.], [-1., 0., 1.], [-1., 0., 1.]], 'Vertical edge filter')
plot_convolution(x_train[:5], [[-1., -1., -1.], [0., 0., 0.], [1., 1., 1.]], 'Horizontal edge filter')
# Expected output: Two sets of images showing original digits alongside the result of applying vertical and horizontal edge filters
Первый фильтр называется
Противоположное происходит, когда мы применяем горизонтальный краевой фильтр — горизонтальные линии усиливаются, а вертикальные — усреднены.
В классическом компьютерном зрении к изображению было применено несколько фильтров для создания признаков, которые затем использовались алгоритмом машинного обучения для создания классификатора. В глубоком обучении мы создадим сети, которые учат лучшие сверточных фильтров для решения проблемы классификации самостоятельно.
Для этого мы введем свертные слои.
Сверточные слои
Сверточные слои определяются через Conv2D класс. Нам нужно указать следующее:
-
filters— количество используемых фильтров. Мы будем использовать 9 различных фильтров, что даст сети множество возможностей для изучения того, какие фильтры лучше всего работают для нашего сценария. -
kernel_size— это размер скользящего окна. Обычно используются фильтры 3x3 или 5x5.
Самый простой CNN содержит только один свертной слой. Учитывая размер входных данных 28x28, после применения девяти фильтров 5x5 мы в конечном итоге получим тензор 24x24x9. Пространственное измерение меньше, потому что в случае по умолчанию padding='valid' не добавляется заполнение, и поэтому существует только 24 позиции, где скользящее окно размером 5 может поместиться в пределах 28 пикселей (28 − 5 + 1 = 24). Использование padding='same' позволит сохранить пространственные размеры за счет добавления нулевого заполнения вокруг входных данных.
После свертки мы расположим 24×24×9 тензор в один вектор размера 5184, а затем добавим плотный слой для создания 10 классов.
relu Функция активации применяется после свертного слоя, чтобы ввести нелинейность.
model = keras.Sequential([
keras.layers.Input(shape=(28, 28, 1)),
keras.layers.Conv2D(filters=9, kernel_size=(5, 5), activation='relu'),
keras.layers.Flatten(),
keras.layers.Dense(10)
])
model.compile(loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy'])
model.summary()
# Expected output: Model summary showing a Conv2D layer, Flatten, and Dense(10) with ~52k parameters
Видно, что эта сеть содержит около 52 кб обучаемых параметров (234 в свертываемом слое + 51 850 в плотном слое), по сравнению с около 80k в полностью подключенных многоуровневых сетях. Сверточная сеть лучше обобщает, что позволяет добиться хороших результатов на небольших наборах данных.
Замечание
В большинстве практических случаев мы хотим применить свертальные слои к цветным изображениям. Таким образом, Conv2D слой ожидает, что входные данные будут иметь форму $H\times W\times C$, где $H$ и $W$ имеют высоту и ширину изображения, а $C$ — это количество цветовых каналов. Для изображений в оттенках серого нам нужна та же форма с $C=1$.
Перед началом обучения нам нужно преобразовать наши данные.
x_train_c = np.expand_dims(x_train, 3)
x_test_c = np.expand_dims(x_test, 3)
hist = model.fit(x_train_c, y_train, validation_data=(x_test_c, y_test), epochs=3)
# Expected output: Training for 3 epochs showing loss and accuracy for training and validation sets
plot_results(hist)
# Expected output: Plots showing training and validation accuracy and loss over 3 epochs
Как видите, мы можем достичь более высокой точности с меньшим количеством эпох по сравнению с полносвязными сетями из предыдущего блока. Для обучения, однако, требуется больше ресурсов и оно может быть медленнее на компьютерах без GPU.
Визуализация сверточных слоев
Мы также можем визуализировать веса наших обученных сверточных нейронных слоев, чтобы попытаться лучше понять, что происходит.
fig, ax = plt.subplots(1, 9)
l = model.layers[0].weights[0]
for i in range(9):
ax[i].imshow(l[..., 0, i])
ax[i].axis('off')
# Expected output: 9 small images showing the learned 5x5 convolutional filter weights
Вы можете увидеть, что некоторые из этих фильтров, похоже, распознают косые штрихи, в то время как другие кажутся случайными.
Многоуровневые сети CNN и уровни пула
Во-первых, свёрточные слои ищут примитивные шаблоны, такие как горизонтальные или вертикальные линии. Мы можем применить дополнительные свертальные слои на вершине их для поиска шаблонов более высокого уровня, таких как примитивные фигуры. Затем дополнительные сверточные слои могут объединить эти формы в некоторые части изображения, в окончательный объект, который мы пытаемся классифицировать.
При этом мы также можем применить один трюк: уменьшение пространственного размера изображения. Когда мы обнаружили, что в скользящем окне 3x3 есть горизонтальная линия, не так важно, на каком именно пикселе это произошло. Таким образом, можно "уменьшить" размер изображения, что достигается с помощью одного из слоев пулинга.
- Среднее объединение принимает скользящее окно (например, 2x2 пикселя) и вычисляет среднее значение по окну
- Max Pooling заменяет окно максимальным значением. Идея максимального пула заключается в обнаружении наличия определенного шаблона в скользящем окне.
Таким образом, в типичном CNN было бы несколько сверточных слоев, с объединением слоев между ними, чтобы уменьшить размеры изображения. Мы также увеличим количество фильтров, так как шаблоны становятся более сложными - есть более интересные сочетания, которые нам нужно искать.
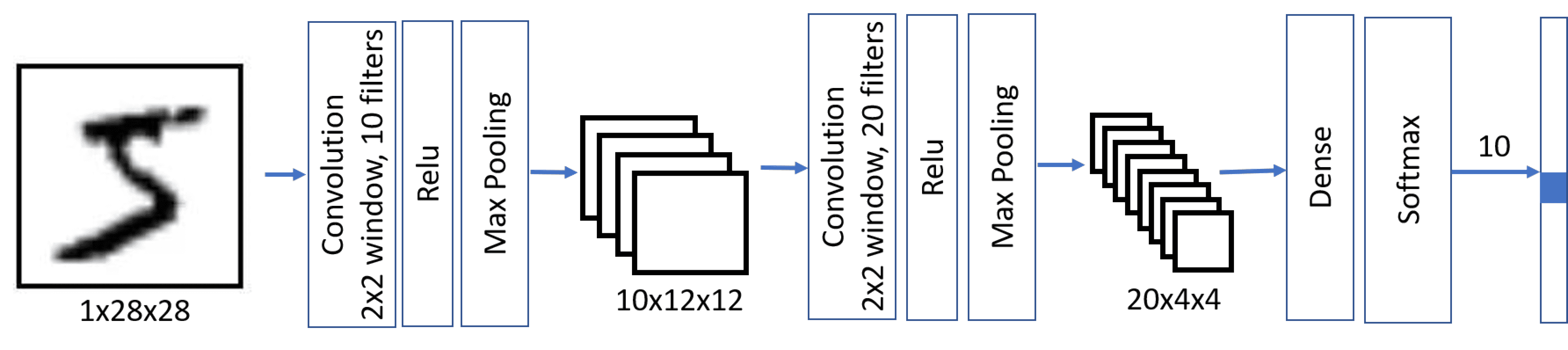
Эта архитектура также называется пирамидальной архитектурой из-за уменьшения пространственных измерений и увеличения измерений функций и фильтров.
model = keras.Sequential([
keras.layers.Input(shape=(28, 28, 1)),
keras.layers.Conv2D(filters=10, kernel_size=(5, 5), activation='relu'),
keras.layers.MaxPooling2D(),
keras.layers.Conv2D(filters=20, kernel_size=(5, 5), activation='relu'),
keras.layers.MaxPooling2D(),
keras.layers.Flatten(),
keras.layers.Dense(10)
])
model.compile(loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy'])
model.summary()
# Expected output: Model summary showing Conv2D, MaxPooling, Conv2D, MaxPooling, Flatten, Dense with ~8.5k parameters
Обратите внимание, что количество обучаемых параметров (~8,5K) значительно меньше, чем в предыдущих случаях. Это происходит потому, что у сверточных слоев обычно мало параметров, а размерность изображения уменьшается перед применением окончательного плотного слоя.
hist = model.fit(x_train_c, y_train, validation_data=(x_test_c, y_test), epochs=3)
# Expected output: Training for 3 epochs showing loss and accuracy for training and validation sets
plot_results(hist)
# Expected output: Plots showing training and validation accuracy and loss over 3 epochs
Обратите внимание, что мы можем достичь более высокой точности при использовании нескольких слоев, и модель нуждается в меньшем числе эпох. Это означает, что более сложная сетевая архитектура требует меньше данных, чтобы выяснить, что происходит, и извлечь универсальные шаблоны из наших образов. Однако каждая эпоха включает в себя больше вычислений из-за дополнительных сверточных операций, поэтому обучение с графическим процессором проходит быстрее.
Работа с реальными изображениями из набора данных CIFAR-10
Хотя наша проблема распознавания рукописных чисел может показаться игрушечной задачей, мы теперь готовы сделать что-то более серьезное. Давайте рассмотрим более сложный набор данных изображений различных объектов, называемых CIFAR-10. Он содержит 60k 32x32 изображения, разделенные на 10 классов.
Замечание
С этого момента мы перезагрузим x_train, y_train, x_test и y_test с набором данных CIFAR-10, заменив данные MNIST, использованные ранее в этом модуле. Развернутые переменные x_train_c и x_test_c больше не нужны.
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
x_train = x_train.astype(np.float32) / 255.0
x_test = x_test.astype(np.float32) / 255.0
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
display_dataset(x_train, y_train, classes=classes)
# Expected output: A row of 10 CIFAR-10 images with their class labels
Классическая архитектура CNN — LeNet, предложенная Яном ЛеКуном первоначально для распознавания рукописных цифр. Давайте адаптируем его для CIFAR-10. Он следует тем же принципам, что и описано выше, основное различие состоит из 3 входных цветовых каналов вместо 1.
model = keras.Sequential([
keras.layers.Input(shape=(32, 32, 3)),
keras.layers.Conv2D(filters=6, kernel_size=5, strides=1, activation='relu'),
keras.layers.MaxPooling2D(pool_size=2, strides=2),
keras.layers.Conv2D(filters=16, kernel_size=5, strides=1, activation='relu'),
keras.layers.MaxPooling2D(pool_size=2, strides=2),
keras.layers.Flatten(),
keras.layers.Dense(120, activation='relu'),
keras.layers.Dense(84, activation='relu'),
keras.layers.Dense(10)
])
model.summary()
# Expected output: Model summary showing the LeNet architecture with Conv2D, MaxPooling, Dense layers
Обучение этой сети занимает значительное время и должно выполняться на вычислительных ресурсах с поддержкой GPU.
model.compile(optimizer='adam', loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy'])
hist = model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=10)
# Expected output: Training for 10 epochs showing loss and accuracy for training and validation sets
plot_results(hist)
# Expected output: Plots showing training and validation accuracy and loss over 10 epochs
Точность, которую нам удалось достигнуть с использованием только нескольких эпох обучения, просто приемлема. Помните, что наша проблема значительно сложнее, чем классификация цифр MNIST. Достижение точности выше 60% является хорошим результатом за такое короткое время обучения, хотя передовые модели могут достичь более 95% на CIFAR-10, используя более глубокие архитектуры, увеличение данных и более длительное обучение.
Общие выводы
В этом уроке мы узнали основную концепцию нейронных сетей компьютерного зрения — сверточных сетей. Реальные архитектуры, которые используют классификацию изображений, обнаружение объектов и даже сети создания изображений, основаны на CNN, просто с большими уровнями и некоторыми дополнительными трюками обучения.
Проверьте свои знания
Обратная связь
Были ли сведения на этой странице полезными?
Нет
Нужна помощь с этой темой?
Хотите попробовать использовать Ask Learn для уточнения или руководства по этой теме?