Как работает Azure HDInsight
Здесь вы узнаете, как работает Azure HDInsight. Вы узнаете о следующих компонентах и о том, как они взаимодействуют для управления и контроля данных.
- Apache Hadoop
- Хранилище HDInsight
- Обработка HDInsight
Что такое Apache Hadoop?
Apache Hadoop — это облачная распределенная система обработки данных в основе HDInsight. Он содержит три компонента, которые описаны в следующей таблице:
| Компонент Apache Hadoop | Описание |
|---|---|
| HDFS (Hadoop распределённая файловая система) | Распределенная файловая система Apache Hadoop (HDFS) предоставляет хранилище для системы Hadoop. |
| ПРЯЖА | Компонент Переговорщика ресурсов Apache Hadoop (YARN) обеспечивает обработку системы. |
| MapReduce | MapReduce — это модель программирования, которая позволяет обрабатывать и анализировать данные. |
Как взаимодействуют компоненты?
На следующей схеме показаны компоненты хранения и обработки, взаимодействующие в типичном кластере HDInsight Hadoop. Он иллюстрирует следующие компоненты:
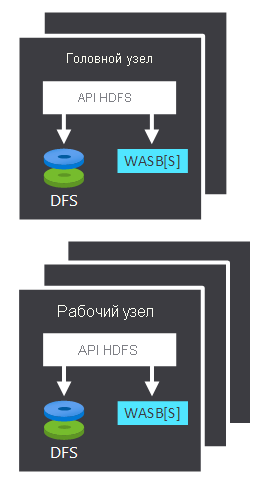
- Головной узел и рабочие узлы, которые выполняют обработку.
- Несколько хранилищ BLOB-объектов Windows Azure (WASB) внутри узлов. HDFS взаимодействует с этими контейнерами.
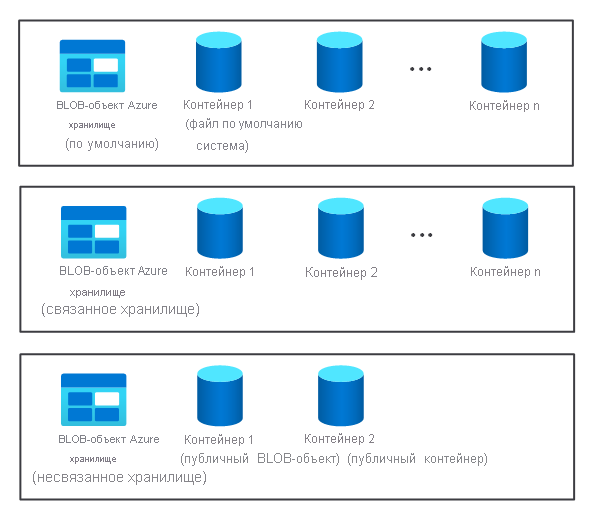
- Несколько контейнеров хранилища: по умолчанию, связанных и несвязанных. Они доступны двум узлам.
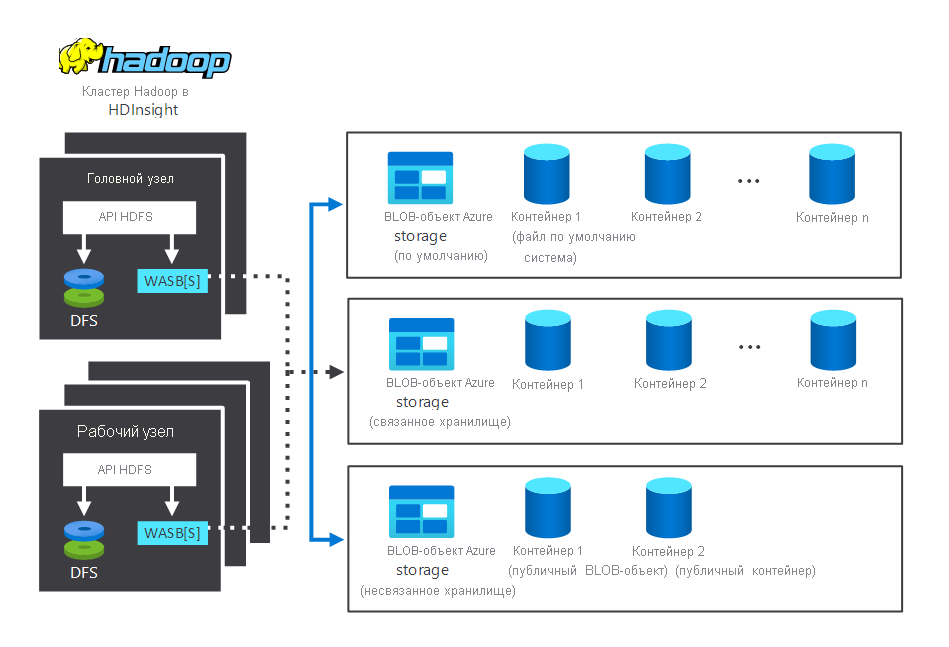
Теперь давайте рассмотрим, как работает хранилище и обработка.
Как работает хранилище?
Компонент хранилища кластера не создается автоматически при подготовке кластера HDInsight. Вместо этого она предоставляется системой, совместимой с HDFS, например службой хранилища Azure или Azure Data Lake.
Существуют преимущества разделения компонента хранилища кластера от компонента обработки. Например, можно безопасно удалить любые кластеры HDInsight, используемые только для вычислений, не беспокоясь о потере данных. При добавлении кластера HDInsight необходимо определить файловую систему по умолчанию.
Важный
Для службы хранилища Azure необходимо указать контейнер BLOB-объектов в качестве файловой системы по умолчанию.
Предоставление файловой системы по умолчанию гарантирует, что HDInsight может разрешать относительные ссылки на файлы при поиске файлов.
Совет
Если требуется увеличить доступное хранилище, можно связать и отменить связь с дополнительными файловыми системами по мере необходимости.
Как работает обработка?
При обработке данных вычислительный компонент кластера Hadoop в HDInsight разбивается на две логические области. В следующей таблице описаны две области:
| Компонент | Описание |
|---|---|
| Головной узел | Головной узел принимает клиентские запросы и управляет и передает запросы рабочим узлам. |
| Рабочий узел | Рабочие узлы обрабатывают данные. |
Заметка
Головной узел иногда называется главным узлом.
Большинство кластеров содержат два головных узла, в том числе:
- Активный головной узел, который управляет клиентскими подключениями.
- Пассивный головной узел, который обеспечивает устойчивость, если активный узел переходит в автономный режим.
Головной и рабочий узлы могут подключаться непосредственно к локально подключенному HDFS или доступу к данным, хранящимся в BLOB-объекте Azure или Azure Data Lake. Управление данными зависит от двух факторов:
- Как модель программирования MapReduce определила, как работать с данными
- Как головной узел распределяет задания
Что делает YARN?
YARN выполняет управление ресурсами в кластере HDInsight. При обработке данных эта служба управляет ресурсами и планированием заданий.
YARN находится между HDFS и вычислительной системой кластера HDInsight. Он работает с головным узлом, чтобы помочь распределить задание по рабочим узлам кластера. Это помогает обеспечить параллельное выполнение заданий обработки данных.